前言
想写这篇文章的原因是最近碰见了一个比较棘手的事情,如果想把一个目标检测模型及其相关的后处理移到嵌入式设备上,不能用c++的opencv库,也就不能用cv2.dnn.nms这个函数来进行nms的后处理,需要用c实现,那就必须了解nms的过程并手写一个c的nms,于是我去网上找了softnms的python源码尝试解读,其实softnms和nms的区别无非在nms时每个框的分数乘的权重不同,所以这篇文章也可以看作是对nms的源码解读。
思想
鉴于有些入门的人可能不了解nms,我先在这里讲一下总体过程和思想。
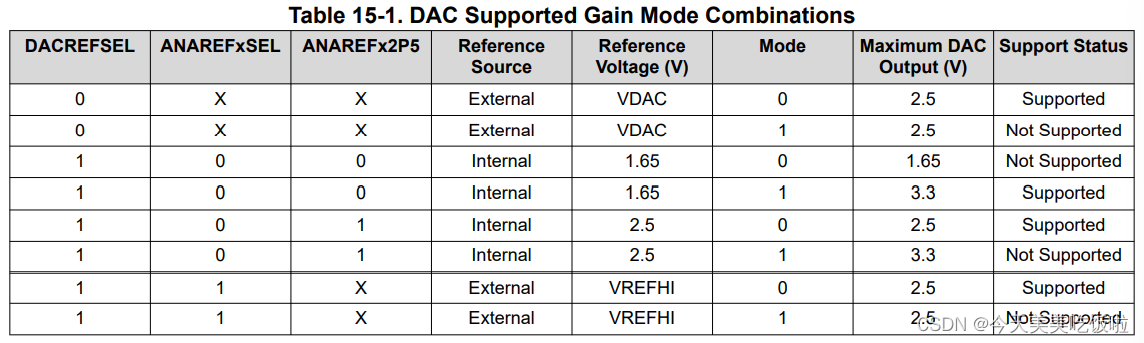
比如yolov5s的coco预训练权重导出的onnx模型,你会发现它的输出是一个float32[1,20160,85]向量。
1表示batch,这个基本概念就不说了。
85表示coco80个分类+4个坐标(x1,x2,y1,y2)+1个置信度(confidence)。
20160表示输出有20160个行,也就是有这么多框,那我们当然不可能把所有的框都算作我们的目标,画出来你会发现图上都是杂乱无章的框,所以就需要一个方法来帮助我们筛选掉多余的框,而nms的思想简单理解就是将每一个框和其余的框进行iou的计算,去掉超过设定iou阈限的框。
关于iou,见下图,转自wiki iou:

也就是两个框的重叠面积除以它们总共覆盖的面积,交集除以并集。
代码和关键问题
代码选自softnms,加了一些方便理解的print函数并去掉了tensorflow的依赖。
import numpy as np
import time
def py_cpu_softnms(dets, sc, Nt=0.3, sigma=0.5, thresh=0.001, method=2):
"""
py_cpu_softnms
:param dets: boexs 坐标矩阵 format [y1, x1, y2, x2]
:param sc: 每个 boxes 对应的分数
:param Nt: iou 交叠门限
:param sigma: 使用 gaussian 函数的方差
:param thresh: 最后的分数门限
:param method: 使用的方法
:return: 留下的 boxes 的 index
"""
# 就是在框矩阵的最后一列加上从0开始的序号
N = dets.shape[0]
indexes = np.array([np.arange(N)])
dets = np.concatenate((dets, indexes.T), axis=1)
print(f'dets is {dets}\n')
# 顺序是y1,x1,y2,x2
y1 = dets[:, 0]
x1 = dets[:, 1]
y2 = dets[:, 2]
x2 = dets[:, 3]
print(y1)
print(x1)
print(y2)
print(x2)
scores = sc
print(f'scores is {scores}\n')
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
print(f'areas is {areas}\n')
for i in range(N):
# 临时存储方便后面参数交换
tBD = dets[i, :].copy()
print(f'tBD before is{tBD}')
tscore = scores[i].copy()
print(f'tscore is {tscore}')
tarea = areas[i].copy()
pos = i + 1
# 选取最大分数
if i != N-1:
maxscore = np.max(scores[pos:], axis=0)
print(f'maxscore is : {maxscore}')
maxpos = np.argmax(scores[pos:], axis=0)
print(f'maxpos is : {maxpos}')
# 这里如果是最后一位了就直接选取它自己,节省时间
else:
maxscore = scores[-1]
maxpos = 0
if tscore < maxscore:
print(1)
dets[i, :] = dets[maxpos + i + 1, :]
dets[maxpos + i + 1, :] = tBD
tBD = dets[i, :]
print(f'dets After is{dets}')
print(f'tBD After is{tBD}')
scores[i] = scores[maxpos + i + 1]
scores[maxpos + i + 1] = tscore
tscore = scores[i]
areas[i] = areas[maxpos + i + 1]
areas[maxpos + i + 1] = tarea
tarea = areas[i]
# IoU 计算
xx1 = np.maximum(dets[i, 1], dets[pos:, 1])
yy1 = np.maximum(dets[i, 0], dets[pos:, 0])
xx2 = np.minimum(dets[i, 3], dets[pos:, 3])
yy2 = np.minimum(dets[i, 2], dets[pos:, 2])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[pos:] - inter)
print(ovr)
# 三种方法: 1.linear 2.gaussian 3.原始的NMS
if method == 1: # linear
weight = np.ones(ovr.shape)
weight[ovr > Nt] = weight[ovr > Nt] - ovr[ovr > Nt]
elif method == 2: # gaussian
weight = np.exp(-(ovr * ovr) / sigma)
else: # 原始的NMS
weight = np.ones(ovr.shape)
weight[ovr > Nt] = 0
scores[pos:] = weight * scores[pos:]
print(f'scores [pos:] is {scores[pos:]}')
# 选择正确的box序号
inds = dets[:, 4][scores > thresh]
keep = inds.astype(int)
return keep
def test():
# 模拟数据
boxes = np.array([[200, 200, 400, 400], [220, 220, 420, 420], [200, 240, 400, 440], [240, 200, 440, 400], [1, 1, 2, 2]], dtype=np.float32)
print(boxes.shape)
boxscores = np.array([0.9, 0.8, 0.7, 0.6, 0.5], dtype=np.float32)
index = py_cpu_softnms(boxes, boxscores, method=3)
print(index)
if __name__ == '__main__':
test()
这里估计很多人疑惑的是这个for循环为什么搞的这么复杂,不是只要每个和其他所有框计算iou不就行了吗?
其实这就是这个代码的精妙之处,假如我像上面代码模拟的五个框,如果我是每个和其他所有框计算iou,我得计算5x4=20次。
但如果我每次选取后面最大的分数,然后如果当前的分数小于它,我就把它们的位置交换,这样计算iou的次数变成了4+3+2+1=5x4/2=10次,节省了一半的时间,如果不能理解,建议自己运行一遍,这个用言语还是很难传达,得细品。
那原始nms和soft-nms的区别在代码中体现在哪里呢?
注意代码中的weights矩阵,这里的weights有三种方法选取,每次计算一遍weights后会和当前分数矩阵相乘,如果是原始nms,会把所有与它重叠分数大于阈限的值全部置为0,等于说在接下来的计算过程中那些框就被无视了,但如果是softnms,不管是linear还是gaussian,都会给框保留一定的分数,这样还能起一些作用,其实这种方法在很多算法中都有体现,但能否提高现实中模型的表现,这个是不确定的,得试过才知道。