原文:使用GPT-4训练数据微调GPT-3.5 RAG管道 - 知乎
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能
也就是说,我们现在可以使用GPT-4生成训练数据,然后用更便宜的API(gpt-3.5 turbo)来进行微调,从而获得更准确的模型,并且更便宜。所以在本文中,我们将使用NVIDIA的2022年SEC 10-K文件来仔细研究LlamaIndex中的这个新功能。并且将比较gpt-3.5 turbo和其他模型的性能。
RAG vs 微调
微调到底是什么?它和RAG有什么不同?什么时候应该使用RAG和微调?以下两张总结图:


这两个图像总结了它们基本的差别,为我们选择正确的工具提供了很好的指导。
但是,RAG和微调并不相互排斥。将两者以混合方式应用到同一个应用程序中是完全可行的。

RAG/微调混合方法
LlamaIndex提供了在RAG管道中微调OpenAI gpt-3.5 turbo的详细指南。从较高的层次来看,微调可以实现下图中描述的关键任务:

- 使用DatasetGenerator实现评估数据集和训练数据集的数据生成自动化。
- 在微调之前,使用第1步生成的Eval数据集对基本模型gpt-3.5-turbo进行Eval。
- 构建向量索引查询引擎,调用gpt-4根据训练数据集生成新的训练数据。
- 回调处理程序OpenAIFineTuningHandler收集发送到gpt-4的所有消息及其响应,并将这些消息保存为.jsonl (jsonline)格式,OpenAI API端点可以使用该格式进行微调。
- OpenAIFinetuneEngine是通过传入gpt-3.5-turbo和第4步生成的json文件来构造的,它向OpenAI发送一个微调调用,向OpenAI发起一个微调作业请求。
- OpenAI根据您的要求创建微调的gpt-3.5-turbo模型。
- 通过使用从第1步生成的Eval数据集来对模型进行微调。
简单的总结来说就是,这种集成使gpt-3.5 turbo能够对gpt-4训练的数据进行微调,并输出更好的响应。
步骤2和7是可选的,因为它们仅仅是评估基本模型与微调模型的性能。
我们下面将演示这个过程,在演示时,使用NVIDIA 2022年的SEC 10-K文件。
主要功能点
1、OpenAIFineTuningHandler
这是OpenAI微调的回调处理程序,用于收集发送到gpt-4的所有训练数据,以及它们的响应。将这些消息保存为.jsonl (jsonline)格式,OpenAI的API端点可以使用该格式进行微调。
2、OpenAIFinetuneEngine
微调集成的核心是OpenAIFinetuneEngine,它负责启动微调作业并获得一个微调模型,可以直接将其插件到LlamaIndex工作流程的其余部分。
使用OpenAIFinetuneEngine, LlamaIndex抽象了OpenAI api进行微调的所有实现细节。包括:
- 准备微调数据并将其转换为json格式。
- 使用OpenAI的文件上传微调数据。创建端点并从响应中获取文件id。
- 通过调用OpenAI的FineTuningJob创建一个新的微调作业。创建端点。
- 等待创建新的微调模型,然后使用新的微调模型。
我们可以使用OpenAIFinetuneEngine的gpt-4和OpenAIFineTuningHandler来收集我们想要训练的数据,也就是说我们使用gpt-4的输出来训练我们的自定义的gpt-3.5 turbo模型
from llama_index import ServiceContext
from llama_index.llms import OpenAI
from llama_index.callbacks import OpenAIFineTuningHandler
from llama_index.callbacks import CallbackManager
# use GPT-4 and the OpenAIFineTuningHandler to collect data that we want to train on.
finetuning_handler = OpenAIFineTuningHandler()
callback_manager = CallbackManager([finetuning_handler])
gpt_4_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-4", temperature=0.3),
context_window=2048, # limit the context window artifically to test refine process
callback_manager=callback_manager,
)
# load the training questions, auto generated by DatasetGenerator
questions = []
with open("train_questions.txt", "r") as f:
for line in f:
questions.append(line.strip())
from llama_index import VectorStoreIndex
# create index, query engine, and run query for all questions
index = VectorStoreIndex.from_documents(documents, service_context=gpt_4_context)
query_engine = index.as_query_engine(similarity_top_k=2)
for question in questions:
response = query_engine.query(question)
# save fine-tuning events to jsonl file
finetuning_handler.save_finetuning_events("finetuning_events.jsonl")
from llama_index.finetuning import OpenAIFinetuneEngine
# construct OpenAIFinetuneEngine
finetune_engine = OpenAIFinetuneEngine(
"gpt-3.5-turbo",
"finetuning_events.jsonl"
)
# call finetune, which calls OpenAI API to fine-tune gpt-3.5-turbo based on training data in jsonl file.
finetune_engine.finetune()
# check current job status
finetune_engine.get_current_job()
# get fine-tuned model
ft_llm = finetune_engine.get_finetuned_model(temperature=0.3)需要注意的是,微调函数需要时间,对于我测试的169页PDF文档,从在finetune_engine上启动finetune到收到OpenAI的电子邮件通知我新的微调工作已经完成,这段时间大约花了10分钟。下面的电子邮件如下。

在收到该电子邮件之前,如果在finetune_engine上运行get_finetuned_model,会得到一个错误,提示微调作业还没有准备好。
3、ragas框架
ragas是RAG Assessment的缩写,它提供了基于最新研究的工具,使我们能够深入了解RAG管道。
ragas根据不同的维度来衡量管道的表现:忠实度、答案相关性、上下文相关性、上下文召回等。对于这个演示应用程序,我们将专注于衡量忠实度和答案相关性。
忠实度:衡量给定上下文下生成的答案的信息一致性。如果答案中有任何不能从上下文推断出来的主张,则会被扣分。
答案相关性:指回答直接针对给定问题或上下文的程度。这并不考虑答案的真实性,而是惩罚给出问题的冗余信息或不完整答案。
在RAG管道中应用ragas的详细步骤如下:
- 收集一组eval问题(最少20个,在我们的例子中是40个)来形成我们的测试数据集。
- 在微调之前和之后使用测试数据集运行管道。每次使用上下文和生成的输出记录提示。
- 对它们中的每一个运行ragas评估以生成评估分数。
比较分数就可以知道微调对性能的影响有多大。
代码如下:
contexts = []
answers = []
# loop through the questions, run query for each question
for question in questions:
response = query_engine.query(question)
contexts.append([x.node.get_content() for x in response.source_nodes])
answers.append(str(response))
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import answer_relevancy, faithfulness
ds = Dataset.from_dict(
{
"question": questions,
"answer": answers,
"contexts": contexts,
}
)
# call ragas evaluate by passing in dataset, and eval categories
result = evaluate(ds, [answer_relevancy, faithfulness])
print(result)
import pandas as pd
# print result in pandas dataframe so we can examine the question, answer, context, and ragas metrics
pd.set_option('display.max_colwidth', 200)
result.to_pandas()

评估结果 最后我们可以比较一下微调前后的eval结果。 基本gpt-3.5-turbo的评估请看下面的截图。answer_relevance的评分不错,但忠实度有点低。
经过微调,模型的性能在答案相关性中略有提高,从0.7475提高到0.7846,提高了4.96%。

使用gpt-4生成训练数据对gpt-3.5 turbo进行微调确实看到了改善。
一些有趣的发现
1、对小文档进行微调会导致性能下降
最初用一个小的10页PDF文件进行了实验,我发现eval结果与基本模型相比性能有所下降。然后又继续测试了两轮,结果如下:
第一轮基本模型:Ragas_score: 0.9122, answer_relevance: 0.9601, faithfulness: 0.8688
第一轮微调模型:Ragas_score: 0.8611, answer_relevance: 0.9380, faithfulness: 0.7958
第二轮基本模型:Ragas_score: 0.9170, answer_relevance: 0.9614, faithfulness: 0.8765
第二轮微调模型:Ragas_score: 0.8891, answer_relevance: 0.9557, faithfulness: 0.8313
所以换衣小文件可能是微调模型比基本模型表现更差的原因。所以使用了NVIDIA长达169页的SEC 10-K文件。对上面的结果做了一个很好的实验——经过微调的模型表现得更好,忠实度增加了4.96%。
2、微调模型的结果不一致
原因可能是数据的大小和评估问题的质量
尽管169页文档的微调模型获得了预期的评估结果,但我对相同的评估问题和相同的文档运行了第二轮测试,结果如下:
第二轮基本模型:Ragas_score: 0.8874, answer_relevance: 0.9623, faithfulness: 0.8233
第二轮微调模型:Ragas_score: 0.8218, answer_relevance: 0.9498, faithfulness: 0.7242
是什么导致了eval结果的不一致?
数据大小很可能是导致不一致的微调计算结果的根本原因之一。“至少需要1000个微调数据集的样本。”这个演示应用显然没有那么多的微调数据集。
另一个根本原因很可能在于数据质量,也就是eval问题的质量。我将eval结果打印到一个df中,列出了每个问题的问题、答案、上下文、answer_relevance和忠实度。
通过目测,有四个问题在忠实度中得分为0。而这些答案在文件中没有提供上下文。这四个问题质量很差,所以我从eval_questions.txt中删除了它们,重新运行了评估,得到了更好的结果:
基本模型eval:Ragas_score: 0.8947, answer_relevance: 0.9627, faithfulness: 0.8356

微调模型eval:Ragas_score: 0.9207, answer_relevance: 0.9596, faithfulness: 0.8847

可以看到在解决了这四个质量差的问题后,微调版的上升了5.9%。所以评估问题和训练数据需要更多的调整,以确保良好的数据质量。这确实是一个非常有趣的探索领域。
3、微调的成本
经过微调的gpt-3.5-turbo的价格高于基本模型的。我们来看看基本模型、微调模型和gpt-4之间的成本差异:
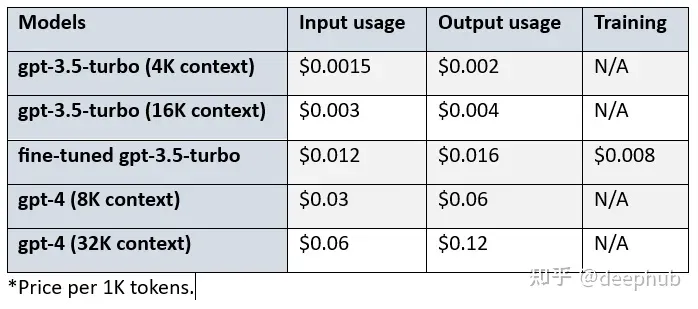
比较gpt-3.5-turbo (4K环境)、微调gpt-3.5-turbo和gpt-4 (8K环境),可以看到:
- 经过微调的gpt-3.5 turbo在输入和输出使用方面的成本是基本模型的8倍。
- 对于输入使用,Gpt-4的成本是微调模型的2.5倍,对于输出使用则是3.75倍。
- 对于输入使用,Gpt-4的成本是基本模型的20倍,对于输出使用情况是30倍。
- 另外使用微调模型会产生$0.008/1K 令牌的额外成本。
总结
本文探索了LlamaIndex对OpenAI gpt-3.5 turbo微调的新集成。我们通过NVIDIA SEC 10-K归档分析的RAG管道,测试基本模型性能,然后使用gpt-4收集训练数据,创建OpenAIFinetuneEngine,创建了一个新的微调模型,测试了它的性能,并将其与基本模型进行了比较。
可以看到,因为GPT4和gpt-3.5 turbo的巨大成本差异(20倍),在使用微调后,我们可以得到近似的效果,并且还能节省不少成本(2.5倍)
如果你对这个方法感兴趣,源代码在这里:
https://colab.research.google.com/github/wenqiglantz/nvidia-sec-finetuning/blob/main/nvidia_sec_finetuning.ipynb
作者:Wenqi Glantz
发布于 2023-09-06 10:09・IP 属地北京






![[文件读取]lanproxy 文件读取 (CVE-2021-3019)](https://img-blog.csdnimg.cn/705b8985f9e14fd8913860e0f073dadf.png)