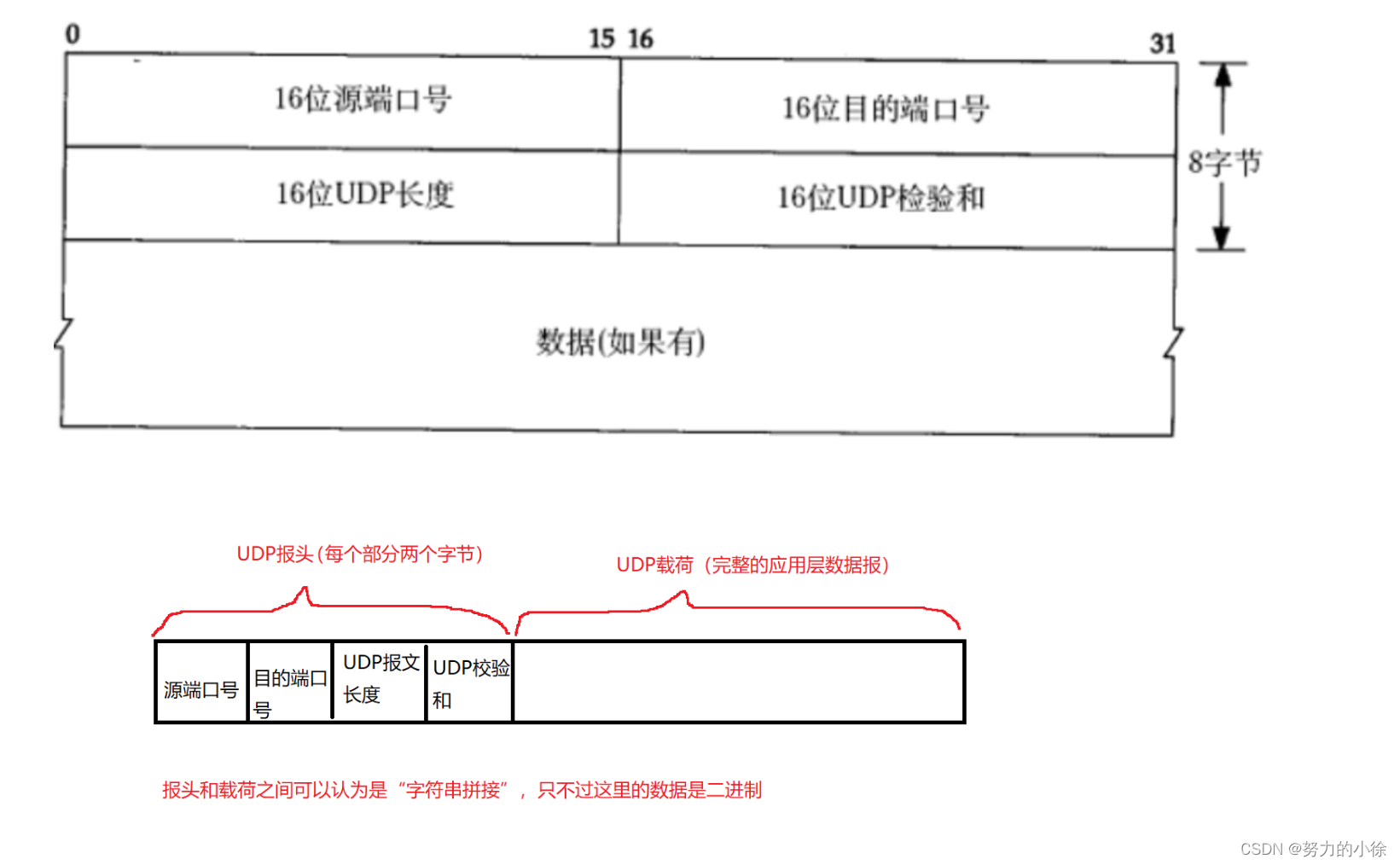
1. 什么是散列表
散列表(Hash Table)也叫哈希表,是根据给定关键字(Key)来计算出该关键字在表中存储地址的数据结构。也就是说,散列表建立了关键字与存储地址之间的一种直接映射关系,将关键字映射到表中记录的地址,这加快了查找速度。
使用函数表达式来表示,应为:hash(key)=v,其中key为关键字,hash()为散列函数,v为散列地址。
1.1 相关术语
- 关键字(Key):关键字是散列表的查找对象,也是散列函数的参数。其可以是记录本身,也可以是记录的唯一索引,这取决于散列表的设计。
- 散列函数(Hash Function):将关键字映射为散列表中适当存储地址的函数称为散列函数,也叫做哈希函数。
- 散列地址(Hash Address):将关键字通过散列函数计算出的地址称为散列地址,也叫做散列值、哈希值。
- 散列表(Hash Table):这种使用散列技术来存储数据记录的表称为散列表。
- 散列冲突(Hash Collision):当不同的关键字具有相同的散列地址,这种现象称为冲突,也叫做哈希冲突。而这些关键字对该散列函数来说是同义词。
- 表长:散列表的大小,即能够存储散列地址的数量。用m表示。
1.2 举个例子
一个比较通俗的例子,就是我们手机中的通讯录。通讯录用于存储联系人的姓名及电话号码信息,它是一个按照姓名首字母进行顺序排列的表。比如我们找“嬴政”就可以通过字母“Y”进行快速定位,并找到“嬴政”。
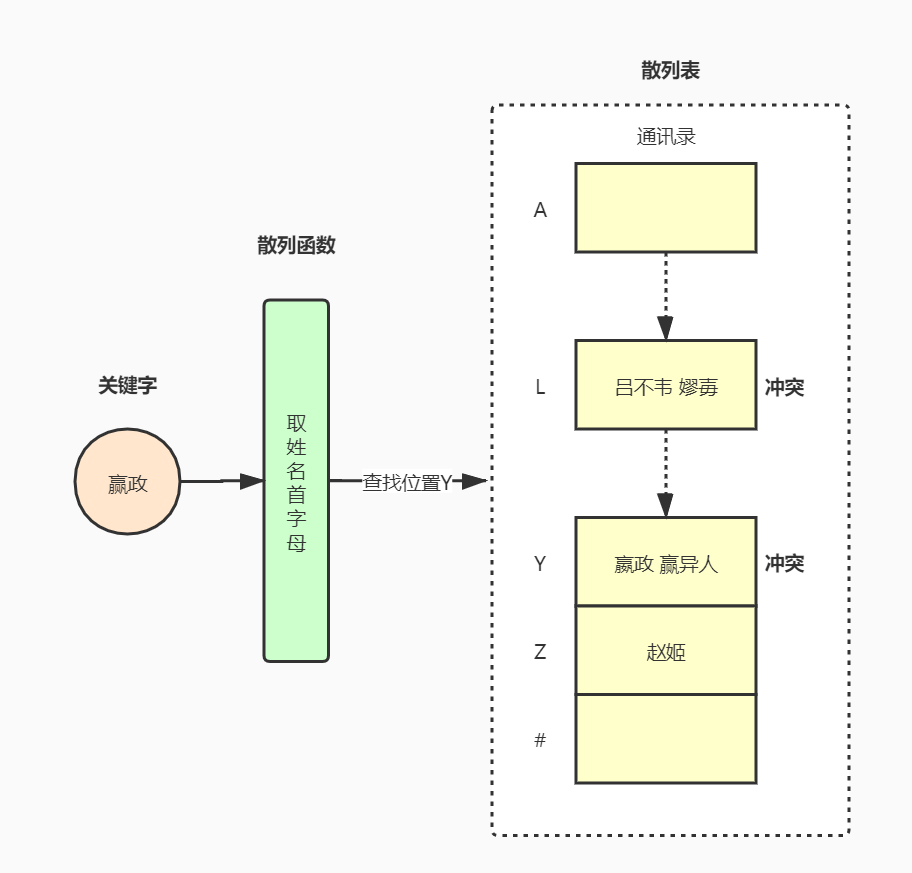
- 在该例子中,姓名“嬴政”便是关键字。
- 取姓名的首字母的算法便是散列函数。即:hash(嬴政) = Y。
- 通过
- 当我们定位到“Y”地址后,不仅有“赢政”,还有“赢异人”,也就是说,通过关键字“赢异人”也能找到“Y”的地址,这种现象便是冲突。即:hash(嬴政) = hash(嬴异人) = Y。
- 而“赢政”与“赢异人”对该散列函数来说是同义词。
- 这个用于存储联系人的通讯录便是散列表。
1.3 小结
本章节介绍了散列表的概念及相关术语,并以一个通讯录的例子来加深对散列表的了解。但还有一些问题等待我们解决,那就是“散列冲突”。我们一方面可以通过精心设计散列函数来尽量减少冲突的次数,另一方面仍需要提供解决冲突的方法。后面章节会详细介绍散列函数的设计和解决冲突的方法。
2. 散列函数的设计
散列函数的设计原则应该遵循计算简单、散列地址分布均匀。下面我们介绍几种常用的散列函数的构造方法。
2.1 直接定址法
取关键字或关键字的某个线性函数值为散列地址。即hash(key) = key 或 hash(key) = a * key + b,其中a、b 为常数。这种散列函数也叫做自身函数。
如下图中,我们要获取某个岗位级别的信息,就可以使用级别减去1来作为地址,即:hash(key) = key - 1
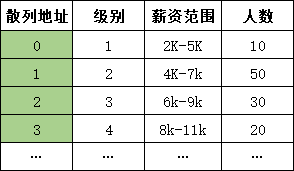
直接定址法的优点是简单、均匀也不会产生冲突。但由于这是一种拿空间换时间的方式,所以适合查找表较小且连续的情况。比如年龄、岗位级别等。
2.2 数字分析法
通过分析一组数据,这些数据中可能出现的关键字都是事先知道的,则可以取关键字的若干数位组成散列地址。取出的这部分数据要在其数位上出现的频率小,这样出现冲突的几率就会很小。
比如手机号码,其前3位为网络识别号,中间4位为地区编码,而后4位才是真正的用户号码。那么在某个公司中,其员工的手机号码前7位出现冲突的概率会很大,而后4位出现冲突的概率会很小,则可以取后四位做为散列地址。

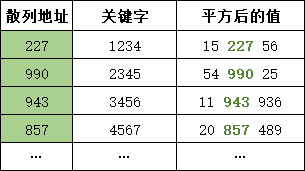
2.3 平方取中法
取关键字平方后的中间几位作为散列地址。该方法是一个产生伪随机数的方法,由冯·诺伊曼在1946年提出。
2.4 折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址。这种方法比较适用于关键字位数很多的情况。
比如关键字为 1234567890,散列表的表长为3位: (1)将关键字分为4组: 123|456|789|0 (2)将它们叠加求和:123 + 456 + 789 + 0 = 1368 (3)舍去进位,得:368 ,即为最终散列地址
2.5 除留余数法
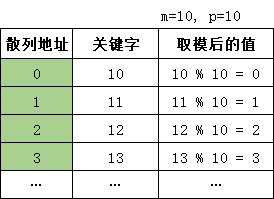
假定散列表的表长为m,取一个不大于m但最接近或等于m的质数p,通过关键字对p取模运算来转换为散列地址。散列函数为:hash(key) = key % p,其中p ≤ m。
不仅可以对关键字直接取模,也可以在折叠法、平方取中法等运算后取模。对p的选择很重要,若选择不好很容易产生冲突。
3. 散列冲突的处理方法
解决冲突的方法有几种,这里我们将讨论其中最简单的两种:开放定址法和链地址法(拉链法)。
3.1 开放定址法
将产生冲突的散列地址做为自变量,通过某种冲突解决函数得到一个新的空闲散列地址。即当产生冲突后,寻找下一个空闲的散列地址。根据寻找的方式不同又分为几种方法,下面来介绍。
3.1.1 线性探测法
当产生冲突时, 顺序探测表中下一地址,直探测到一个空闲(自由)的地址,将记录插入。若一直探测到表尾地址m-1,则下一探测地址为表首地址0。当表满的时候,则探测失败。
比如下图散列表的散列函数使用除留余数法(m=10, p=10)。那么我们顺序插入12、13、24时顺利插入到对应地址中,再插入34、44时会产生冲突,使用线发探测法,继续探测下一地址,将插入到空闲地址上。

线性探测法会造成大量元素在相邻的散列地址上“聚集”起来,使得我们要不断处理冲突,这大大降低查找和存入效率。
3.1.2 平方探测法
平方探测法是消除线性探测法中的聚集问题的一种冲突解决方法。设发生冲突的地址为d,那么使用平方探测法得到的新的地址序列为d ± 1^2、d ± 22、d ± 32...d ± ���2(key ≤ m/2)。
还是刚才那个例子,当插入34时,在下标为4的位置产生冲突,我们先计算一下在该位置探测的序列: 4 + 12 = 5、4 - 12 = 3、4 + 22 = 8、4 - 22 = 0,即:5、2、8、0,所以34应该被放到5的位置。而44应该放到8的位置。

平方探测法的缺点是不能探测到散列表上所有的地址,但至少能探测到一半地址。
3.1.3 伪随机探测法
伪随机探测法是当发生地址冲突时,地址增量为伪随机数序列。
伪随机数是说,如果我们设置随机种子相同,则不断调用随机函数可以生成不会重复的数列,我们在查找时,用同样的随机种子,它每次得到的数列是相同的,相同的地址当然可以得到相同的散列地址。
3.1.4 双散列
双散列顾名思义是使用了两个散列函数,当执行第一个散列函数得到的地址发生冲突时,则执行第二个散列函数来计算该关键字的地址增量。
一种常见的算法是:(hash1(key) + i * hash2(key)) mod m,其中i为冲突次数,hash1()为第一个散列函数,hash2()为第二个散列函数,m为散列表大小。当发生冲突后,我们通过重复增加步长i来寻址。
还是以上面的例子为例。第一个散列函数为hash1(key) = key mod 10,第二个散列函数设为hash2(key) = key mod 3。
通过上面公式,可以计算出关键字34的散列地址: (34 mod 10 + 1 * (34 mod 3)) mod 10 = (4 + 1 * 1) mod 10 = 5。而关键字44的散列地址为:(44 mod 10 + 2 * (44 mod 3)) mod 10 = (4 + 2 * 2) mod 10 = 8
3.2 链地址法
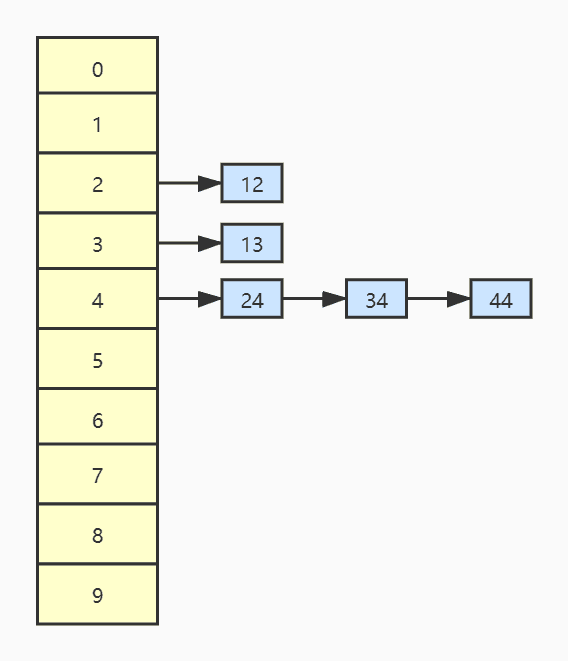
链地址法又称拉链法,是利用链表来解决冲突的一种方法,即把具有相同散列地址的关键字记录存入到同一个单链表中,该链表称为同义词链表。每一个散列地址都有一个对应的链表。
还是上面的例子,使用链地址法的存储模型如下图所示。

![[文件读取]lanproxy 文件读取 (CVE-2021-3019)](https://img-blog.csdnimg.cn/705b8985f9e14fd8913860e0f073dadf.png)