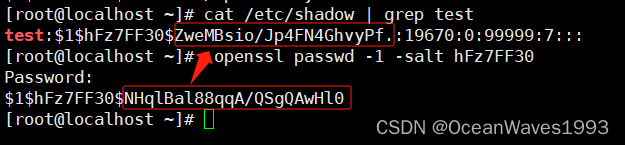
作者:Ninoslav Miskovic
通过使用 ES|QL 直接从 Discover 创建聚合、可视化和警报,缩短获得见解的时间。
什么是 ES|QL(Elasticsearch 查询语言)?
ES|QL(Elasticsearch 查询语言)是 Elastic® 全新的创新管道查询语言,旨在通过提供强大的计算和聚合功能来加速数据分析和调查流程。
轻松高效地应对识别正在发生的网络攻击或查明生产问题的复杂性。
ES|QL 不仅简化了海量数据集的搜索、聚合和可视化,还为用户提供了查找(lookup)和实时处理等高级功能,所有这些都可以在 Discover 的单个屏幕上完成。
ES|QL 为 Elastic Stack 增加 3 项强大功能
- 一个新的、快速的分布式和专用查询引擎,为 _query 提供支持。 新的 ES|QL 查询引擎通过并发处理提供高级搜索功能,无论数据源和结构如何,都可以提高速度和效率。 新引擎的性能经过测量并公开。 请在公共仪表板中查看性能基准测试。
- 一种新的、强大的管道语言。 ES|QL 是 Elastic 的新型管道语言,可转换、丰富和简化数据调查。 在文档中了解有关 ES|QL 语言功能的更多信息。
- 一种全新的、统一的数据探索/调查体验,通过从一个屏幕创建聚合和可视化来加速解决问题,从而提供不间断的工作流程。
为什么我们要在 ES|QL 上投入时间和精力?
我们的用户需要敏捷的工具,这些工具不仅可以呈现数据,还可以提供有效的方法来理解数据,以及根据实时见解采取行动并进行数据摄取后处理的能力。
Elastic 致力于增强用户的数据探索体验,这促使我们投资 ES|QL。 它旨在为初学者提供方便,为专家提供强大功能。 借助 ES|QL 直观的界面,用户可以快速启动并深入研究数据,而无需艰难的学习曲线。 自动完成和应用程序内文档可确保制作高级查询成为一个简单的工作流程。
此外,ES|QL 不仅仅向你显示数字;它还向你显示数据。 它使它们栩栩如生。 由 Lens 建议引擎提供支持的上下文可视化会自动适应你的查询的性质,从而提供你的见解的清晰视图。
此外,直接集成到仪表板和警报功能反映了我们对有凝聚力的端到端体验的愿景。
从本质上讲,我们对 ES|QL 的投资是对社区不断变化的需求的直接响应 —— 朝着更加互联、富有洞察力和高效的工作流程迈出的一步。
深入研究安全性和可观察性用例
我们对 ES|QL 的承诺还源于对用户(例如站点可靠性工程师 (SRE)、DevOps 和威胁猎手)所面临的挑战的深刻理解。
对于 SREs 来说,可观察性至关重要。 每一秒的停机或故障都会对用户体验产生连锁反应,从而影响利润。 ES|QL 的警报功能就是一个例子:它强调突出孤立事件的有意义的趋势,SRE 可以主动查明并解决系统效率低下或故障的问题。 这可以减少噪音并确保他们对系统稳定性的真正威胁做出反应,从而使他们的响应更加及时和有效。
DevOps 团队始终与时间赛跑,部署多个更新、补丁和新功能。 借助 ES|QL 全新且强大的数据探索和数据可视化,他们可以快速评估每次部署的影响、监控系统运行状况并接收实时反馈。 这不仅提高了部署质量,还可以确保在需要时快速修正方向。
对于威胁猎手来说,安全形势在不断发展和变化。 ENRICH 功能是 ES|QL 如何在不断变化的环境中为他们提供支持的一个例子。 此功能使他们能够跨不同数据集查找数据,从而揭示可能表明安全威胁的隐藏模式或异常情况。 此外,上下文可视化意味着他们不仅可以看到原始数据,还能获得以视觉方式呈现的可操作的见解。 这大大减少了识别潜在威胁所需的时间,确保对漏洞做出更快的反应。
无论你是试图破译服务器负载峰值的 SRE、评估最新版本影响的 DevOps 专业人员,还是调查潜在漏洞的威胁猎人,ES|QL 都能为用户提供补充,而不是让整个过程变得复杂。
博客文章的下一部分将帮助你开始使用 ES|QL 并展示一些具体示例,说明它在探索数据时的强大功能。
如何在 Kibana 中开始使用 ES|QL
要开始使用 ES|QL,请导航到 Discover,然后只需从数据视图选择器中选择 Try ES|QL。 它用户友好且简单。
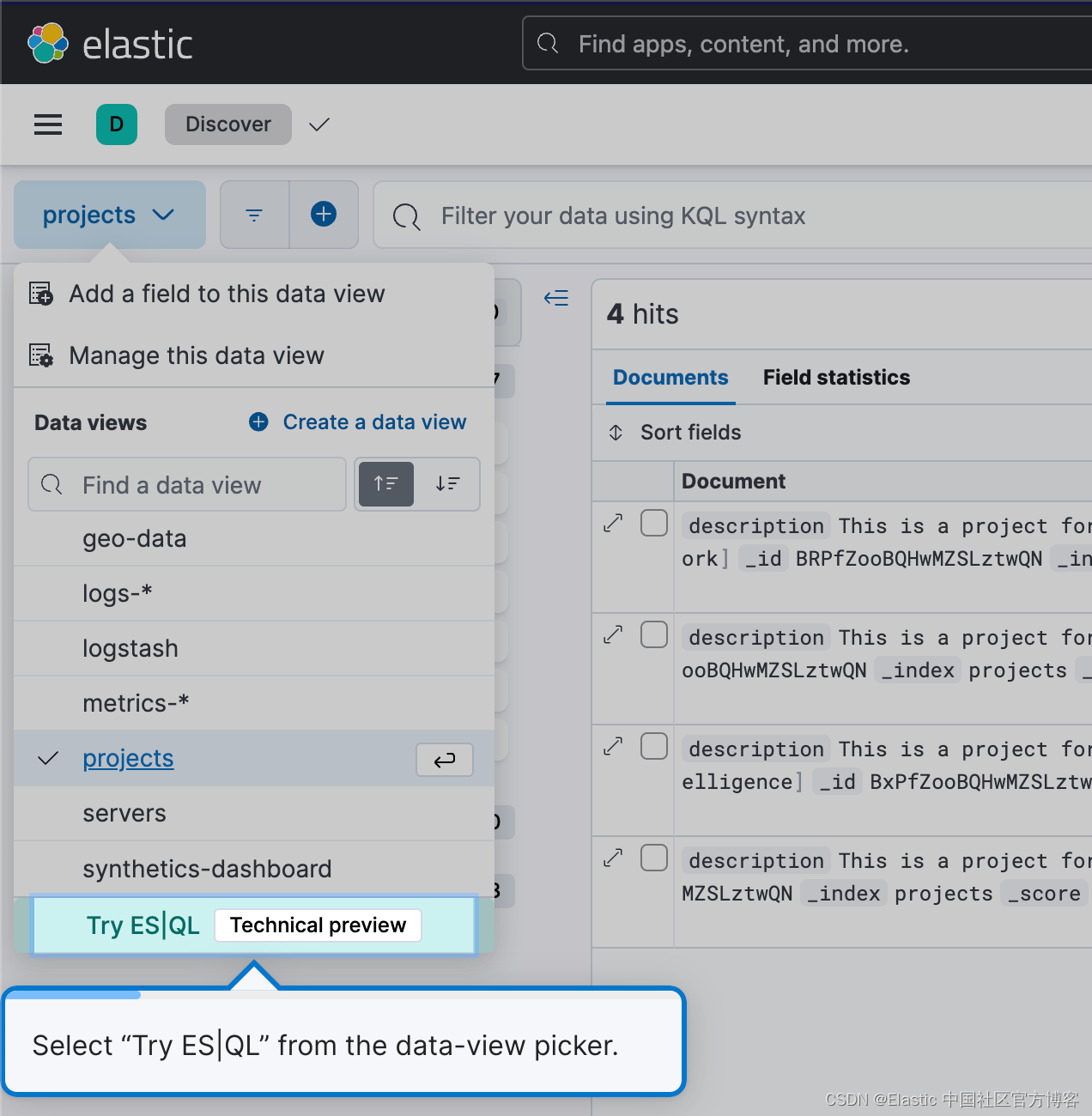
这将使你进入 Discover 中的 ES|QL 模式。
高效、简单的查询构建
Discover 中的 ES|QL 提供自动完成和应用内文档,让你可以轻松地直接从查询栏创建强大的查询。

如何使用 ES|QL 分析和可视化数据
借助 ES|QL,你可以进行全面而强大的数据探索。 它允许你直接从查询生成器在 Discover 中进行临时数据探索、创建聚合、转换数据、丰富数据集等。 结果以表格格式或可视化形式呈现 - 这取决于你正在执行的查询。
下面你将找到用于可观察性的 ES|QL 查询的示例,以及结果如何以表格格式和可视化表示形式表示。
带有指标用例的 ES|QL 查询:
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10上面的查询展示了如何使用以下源命令、聚合函数和处理命令:
from 源命令(文档)
from metrics*:这将从与模式 “metrics*” 匹配的索引模式发起查询。 星号 (*) 充当通配符,这意味着它将从名称以 “metrics” 开头的所有索引模式中选择数据。
stats…by...按聚合(文档)、max(文档)和 by(文档)
该部分根据特定统计数据聚合数据。 其分解如下:
- max_cpu=max(kubernetes.pd.cpu.usage.node.pct):对于每个不同的 “kubernetes.pod.name”,它会查找最大 CPU 使用百分比并将该值存储在名为 “max_cpu” 的新列中。
- max_mem = max(kubernettes.pod.memory.usage.bytes):对于每个不同的 “kubernetes.pod.name”,它会找到最大内存使用量(以字节为单位)并将该值存储在名为 “avg_mem” 的新列中。
sort (文档)
sort max_cpu desc:按 “max_cpu” 列降序对结果数据行进行排序。 这意味着 “max_cpu” 值最高的行将位于顶部。
limit(文档)
这将排序后的输出限制为前 10 行。
总之,查询:
- 使用索引模式对所有指标索引的数据进行分组
- 聚合数据以查找每个不同 Kubernetes Pod 的最大 CPU 使用率百分比和最大内存使用率
- 按最大 CPU 使用率降序对聚合数据进行排序
- 仅输出 CPU 使用率最高的前 10 行
上下文可视化:在 Discover 中编写 ES|QL 查询时,你将收到由 Lens 建议引擎提供支持的视觉表示。 你的查询的性质决定了你获得的可视化类型,无论是指标、直方图热图等。
下面是上述查询的条形图形式的直观表示和表格表示,其中包含 max_cpu、avg_mem 和 kubernetes.pod.name 列:

具有可观察性和时间序列数据用例的 ES|QL 查询示例:
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts desc上面的查询展示了如何使用以下源命令、聚合函数、处理命令和函数。
from 源命令(文档)
来自 apache-logs:这将从名为 “apache-logs” 的索引发起查询。 该索引包含与 Apache Web 服务器流量相关的日志条目。
where (文档)
其中 url.original==”/login”:将记录过滤为仅包含 “url.original” 字段等于 “/login” 的记录。 这意味着我们只对与登录尝试或访问登录页面有关的日志条目感兴趣。
eval (文档) 及 auto_bucket (文档)
- eval time_buckets =... :这将创建一个名为 “time_buckets” 的新列。
- “auto_bucket” 函数创建人性化的存储桶,并为每行返回一个与该行所属的结果存储桶相对应的日期时间值。
- “@timestamp” 是包含每个日志条目的时间戳的字段。
- “50” 是桶的数量。
- “2023-09-11T21:54:05.000Z”:分桶开始时间
- “2023-09-12T00:40:35.000Z”:分桶结束时间
这意味着从 “2023-09-11T21:54:05.000Z” 到 “2023-09-12T00:40:35.000Z” 的日志条目将被分为 50 个等间隔的间隔,并且每个条目将与特定间隔相关联基于其时间戳。
目标不是提供准确的目标存储桶数量,而是选择一个你满意的范围,最多提供目标存储桶数量。 如果你要求更多的存储桶,那么 auto_bucket 可以选择较小的范围。
stats…by 聚合 (文档), count (文档), 及 by (文档)
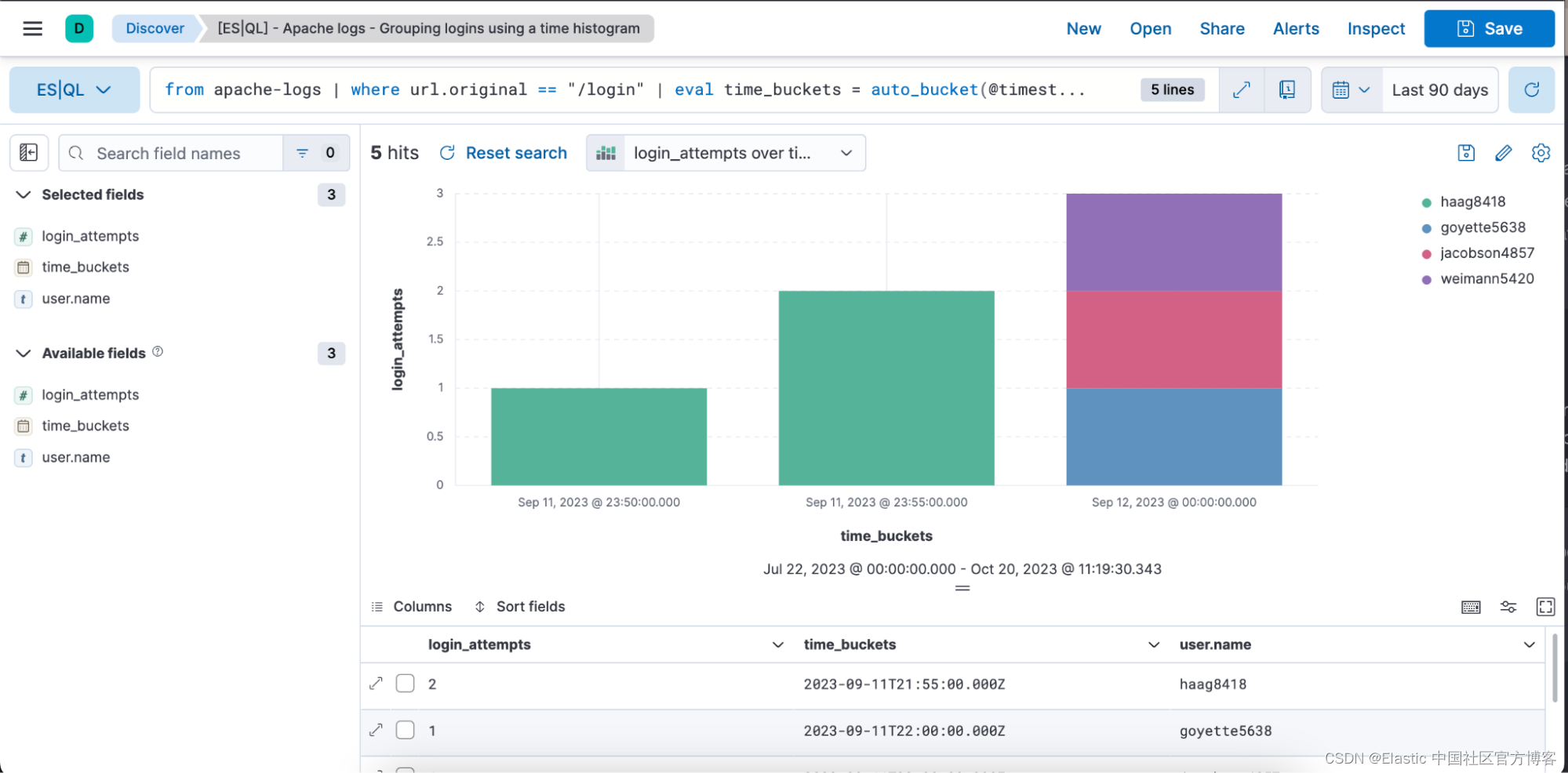
stats login_attempts = count(user.name) by time_buckets, user.name:聚合数据以计算登录尝试次数。 它通过计算 “user.name”(代表尝试登录的唯一用户)的出现次数来实现这一点。
计数按 “time_buckets”(我们创建的时间间隔)和 “user.name” 分组。 这意味着对于每个时间段,我们将看到每个用户尝试登录的次数。
sort (文档)
sort login_attempts desc:最后,聚合结果按 “login_attempts” 列降序排序。 这意味着结果将在顶部显示最多的登录尝试次数。
总之,查询:
- 从 “apache-logs” 索引中选择数据
- 过滤与登录页面相关的日志条目
- 将这些条目存储到特定的时间间隔中
- 计算每个时间间隔内每个用户的登录尝试次数
- 首先输出按登录尝试次数最高排序的结果
下面是上述查询的条形图形式的直观表示和表格表示,其中包含登录尝试、时间桶和用户名列。
Discover 及 Dashboard 中的内嵌可视化编辑
直接在 Discover 和仪表板中编辑 ES|QL 可视化。 无需导航到 Lens 即可进行快速编辑; 你可以无缝地进行更改。
你可以在下面观看端到端工作流程的视频或阅读分步指南:
- 编写 ES|QL 查询
- 根据查询的性质获取上下文可视化
- 内联编辑可视化
- 将其保存到仪表板
- 能够从仪表板编辑可视化
ES
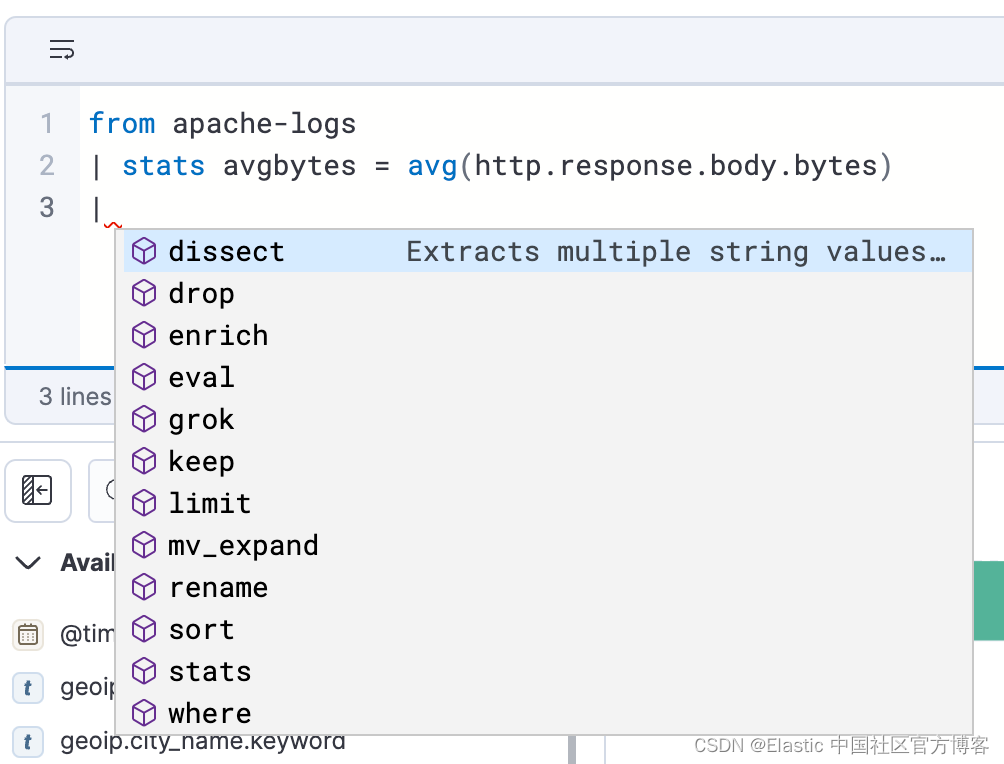
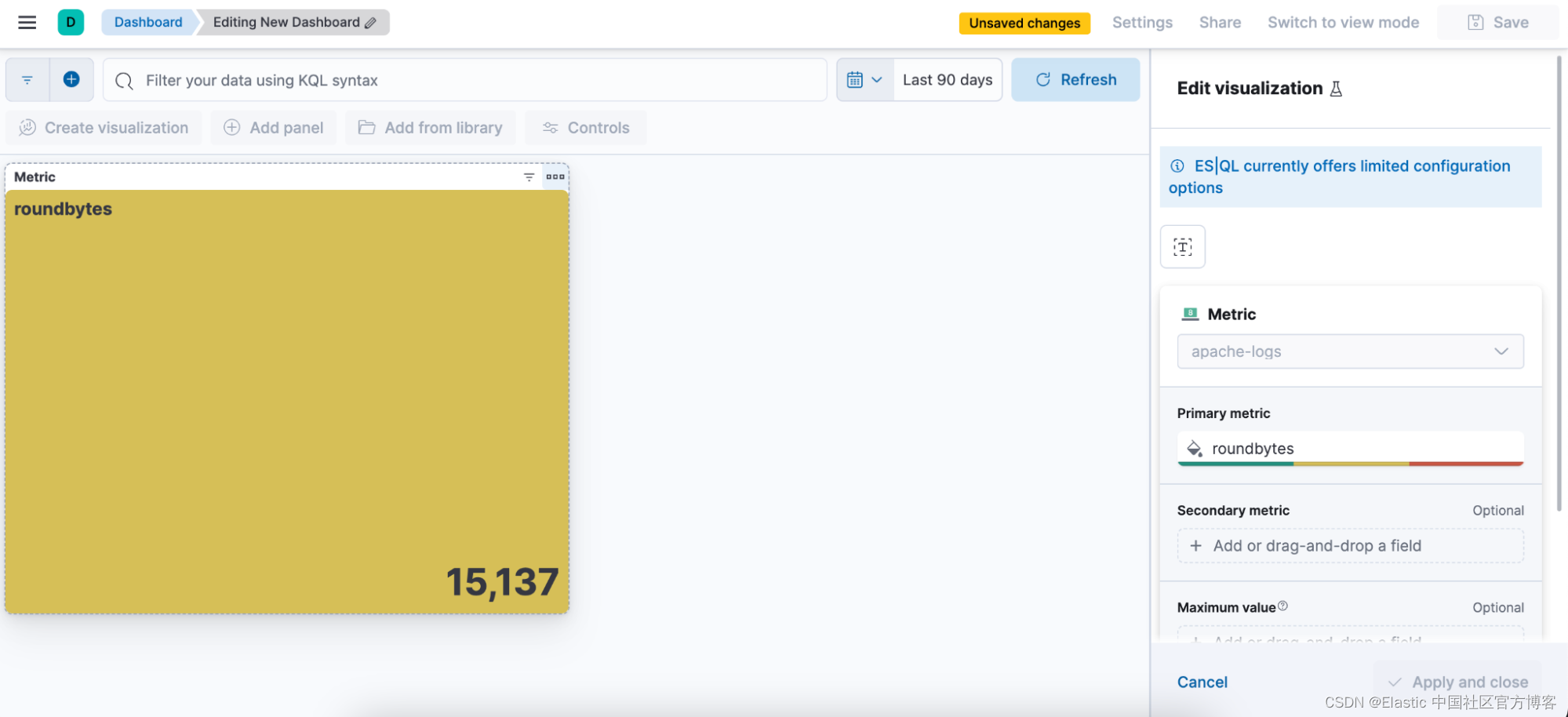
步骤 1. 编写 ES|QL 查询。 生成指标可视化的查询示例:
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
| drop avgbytes步骤 2. 根据查询的性质获取上下文可视化(在本例中为指标可视化)
然后,你可以选择铅笔图标进入内联编辑模式。
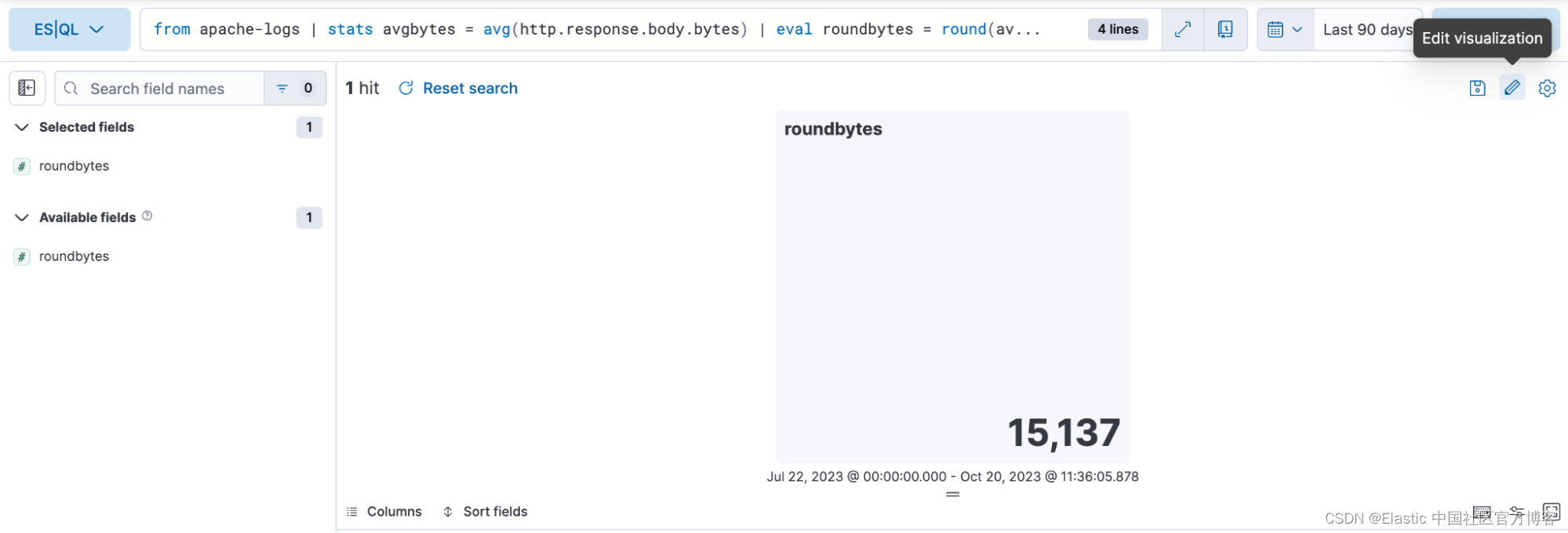
步骤 3. 使用内联编辑模式编辑可视化
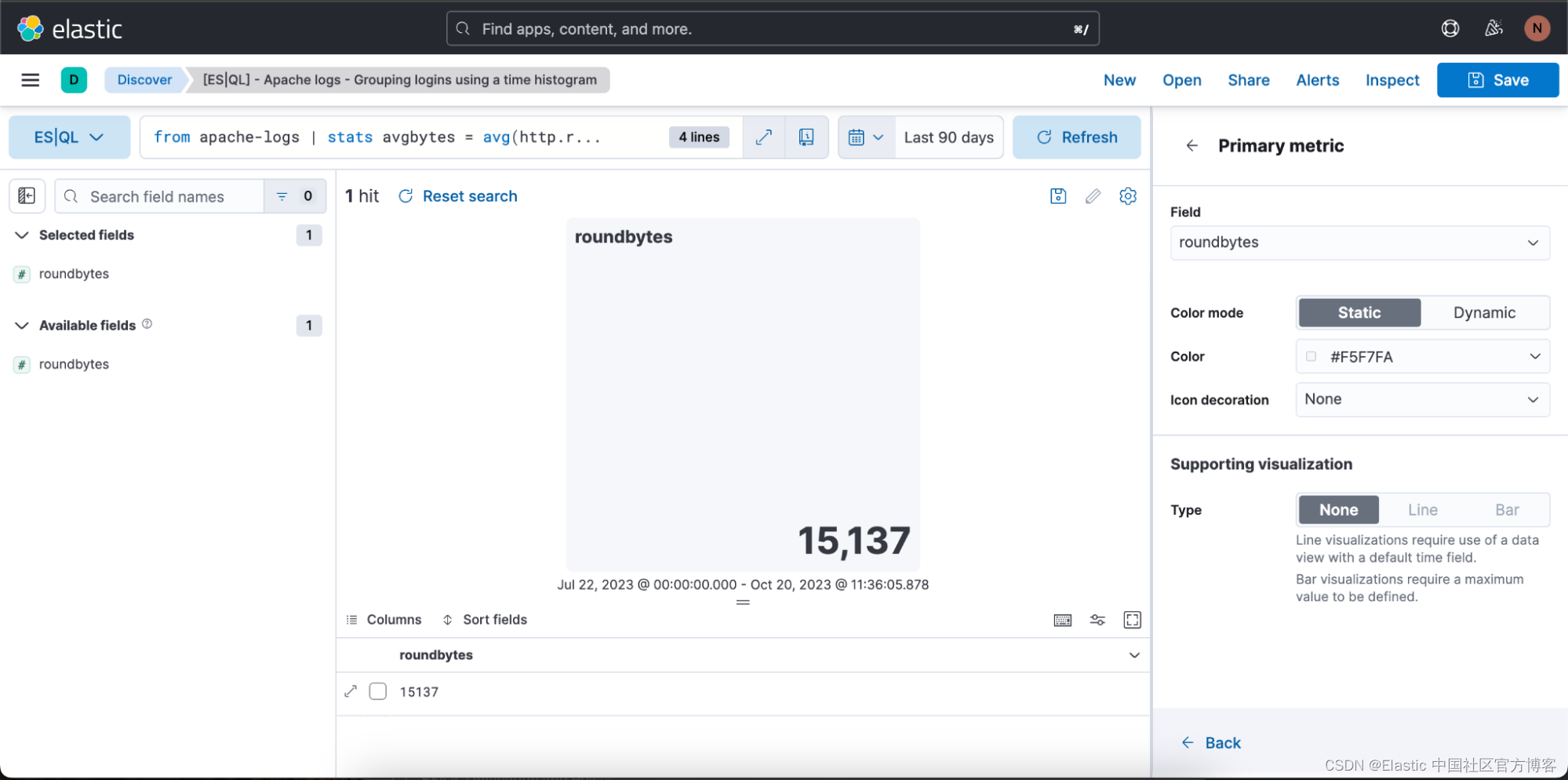
在上述情况下,我们希望可视化处于动态(dynamic)颜色模式,因此我们将其切换为 “Dynamic”。
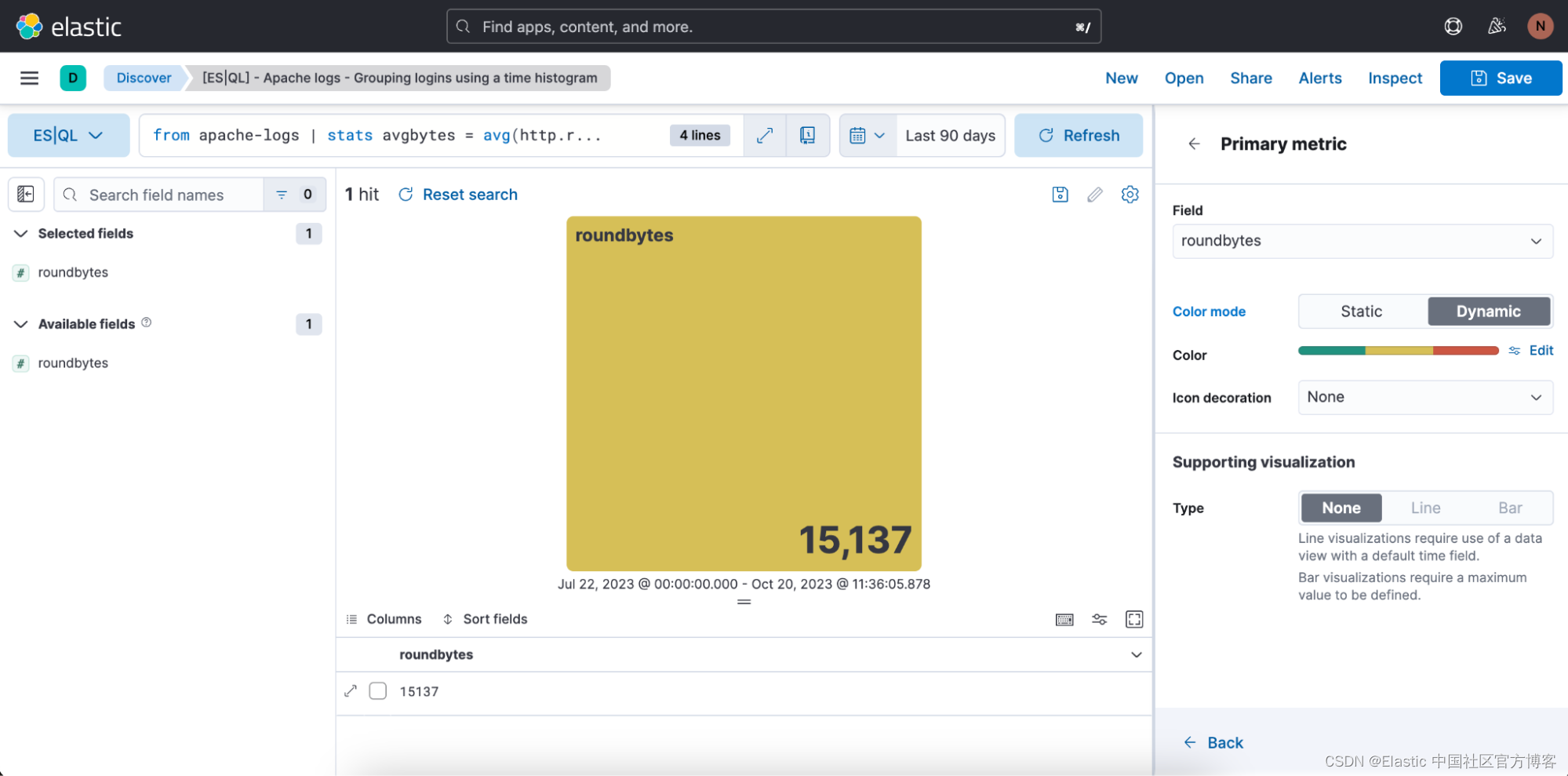
我们还有机会定义我们想要使用的颜色范围:
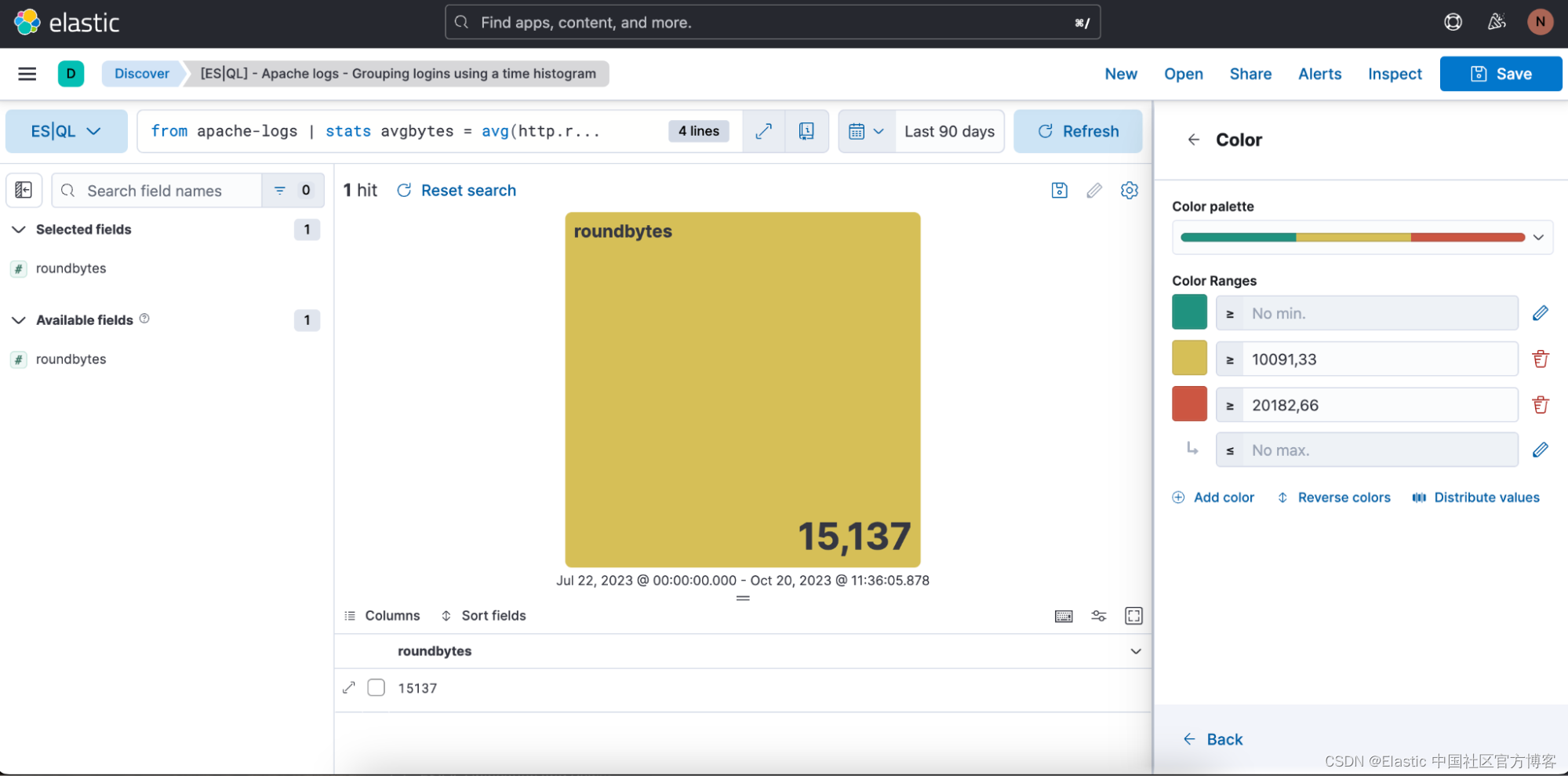
步骤 4. 保存到仪表板
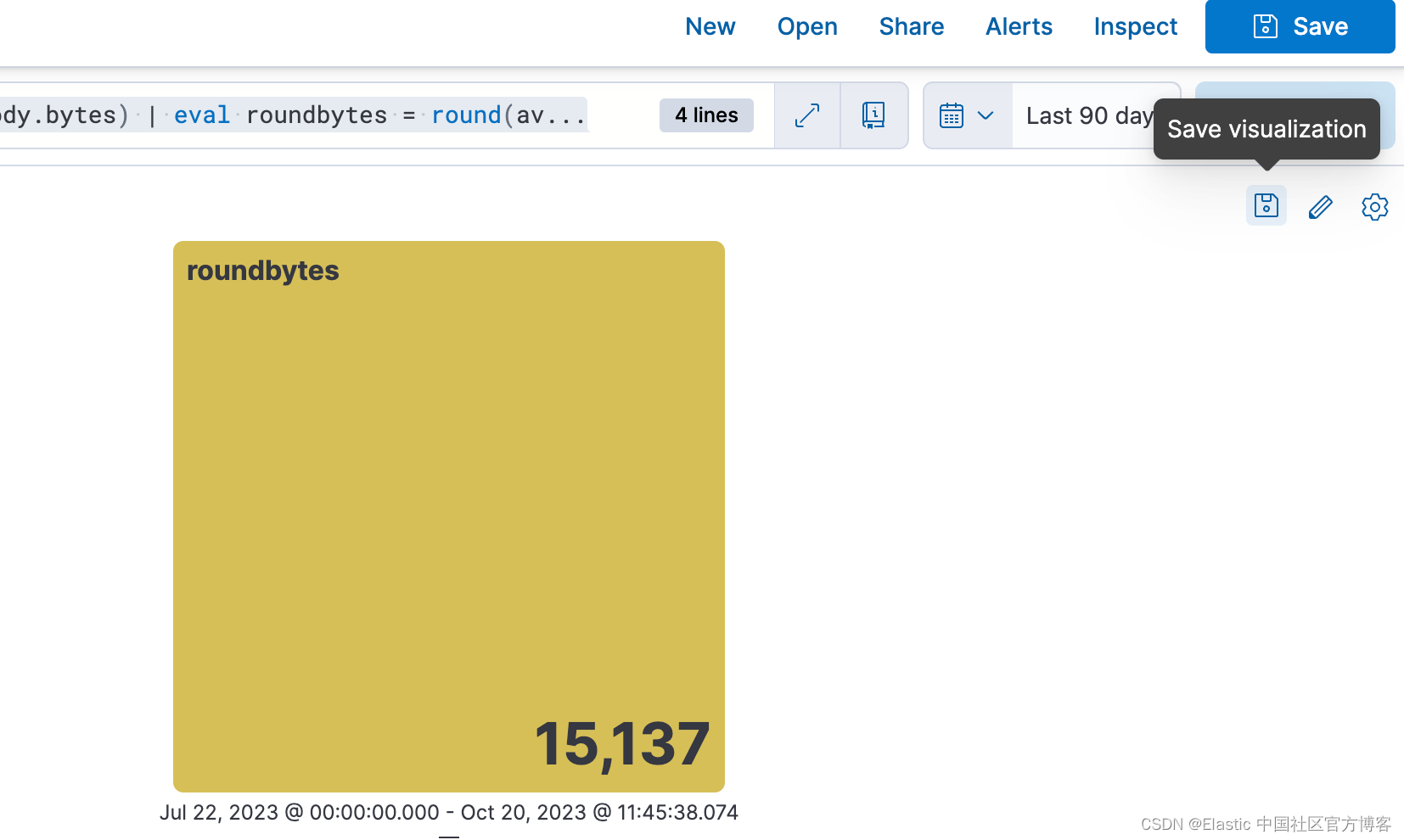
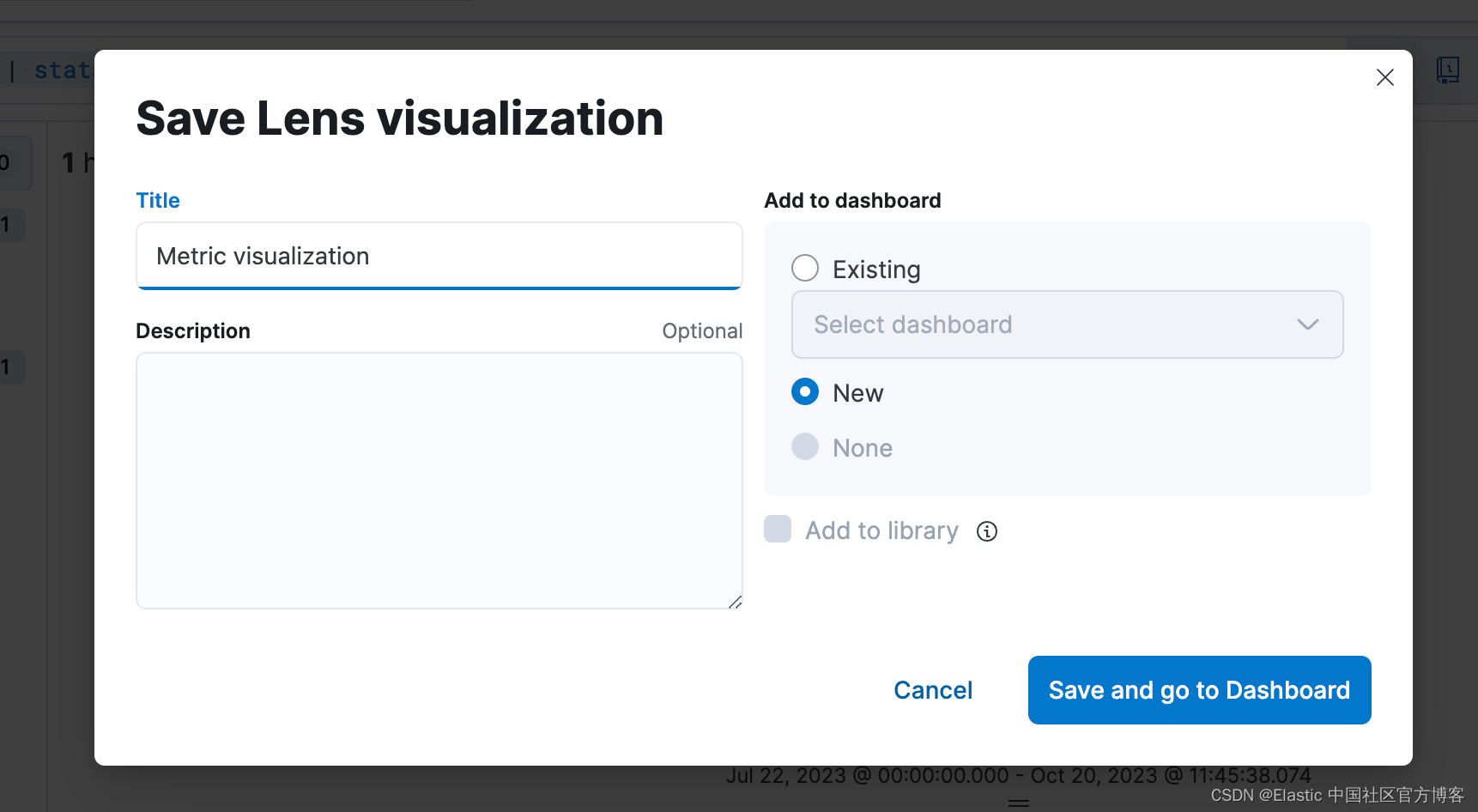
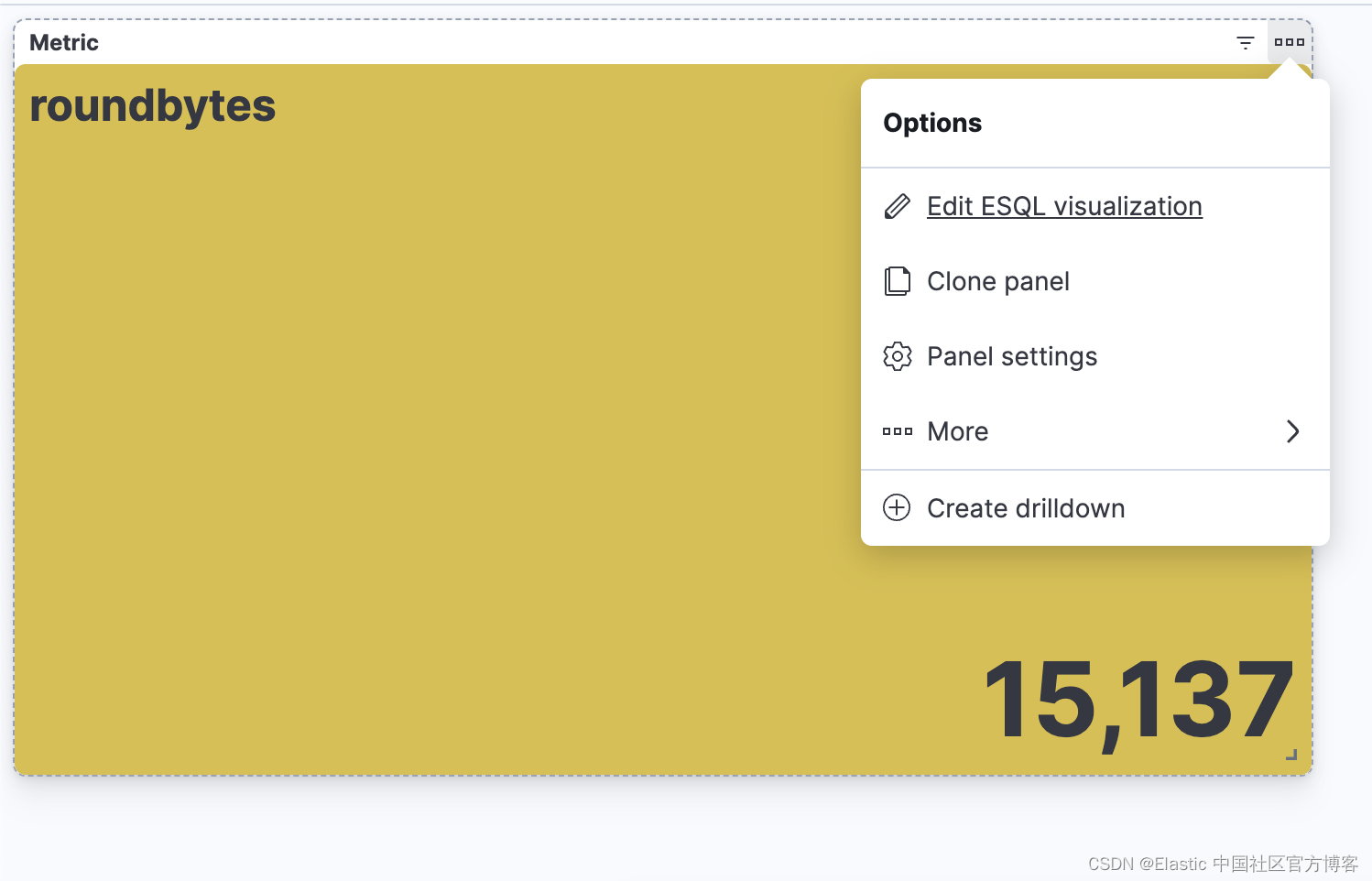
步骤 5. 能够从仪表板编辑可视化
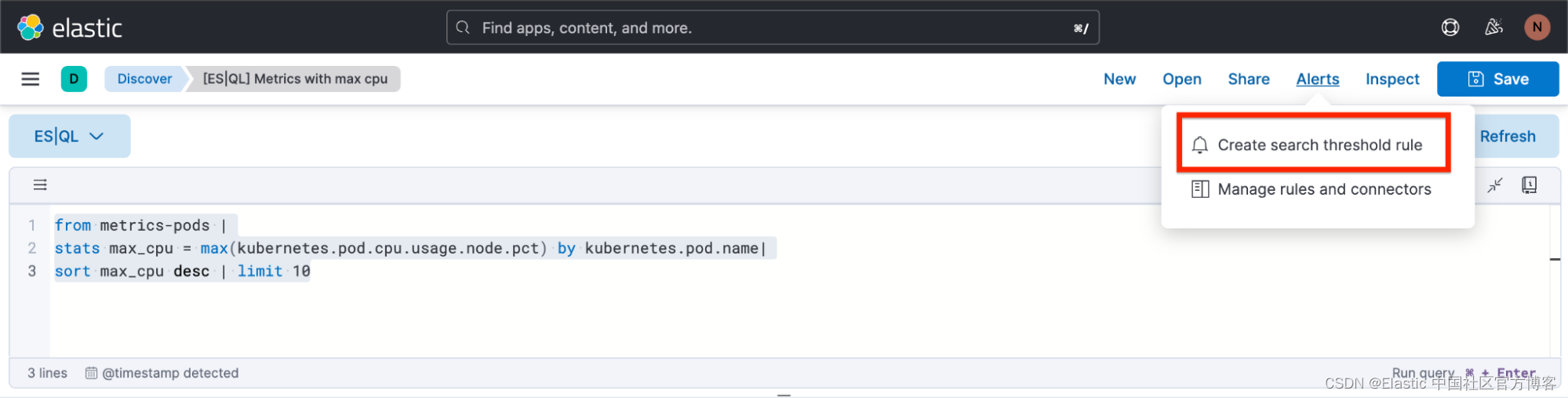
直接从 Discover 创建 ES|QL 警报
你可以使用 ES|QL 进行可观察性和安全警报,将聚合值设置为阈值。 通过强调有意义的趋势而非孤立事件,减少误报,提高检测准确性并接收可操作的通知。
下面,我们将重点介绍如何从 Discover 创建 ES|QL 警报规则类型。
新的警报规则类型可在现有 Elasticsearch 规则类型下使用。 此规则类型带来了 ES|QL 中可用的所有新功能,并解锁了新的警报用例。
使用新类型,用户将能够根据定义的 ES|QL 查询生成单个警报,并在保存规则之前预览查询结果。 当查询返回空结果时,不会生成警报。
警报的查询示例:
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10如何从 Discover 创建警报
步骤 1. 单击 “Alerta”,然后单击 “Create search threshold rule”
你可以在查询栏中定义 ES|QL 查询之后或定义 ES|QL 查询之前开始创建 ES|QL 警报规则类型。 定义后执行此操作的好处是查询会自动粘贴到 “Create Alert” 弹出窗口中。
步骤 2. 开始定义 ES|QL 警报规则类型
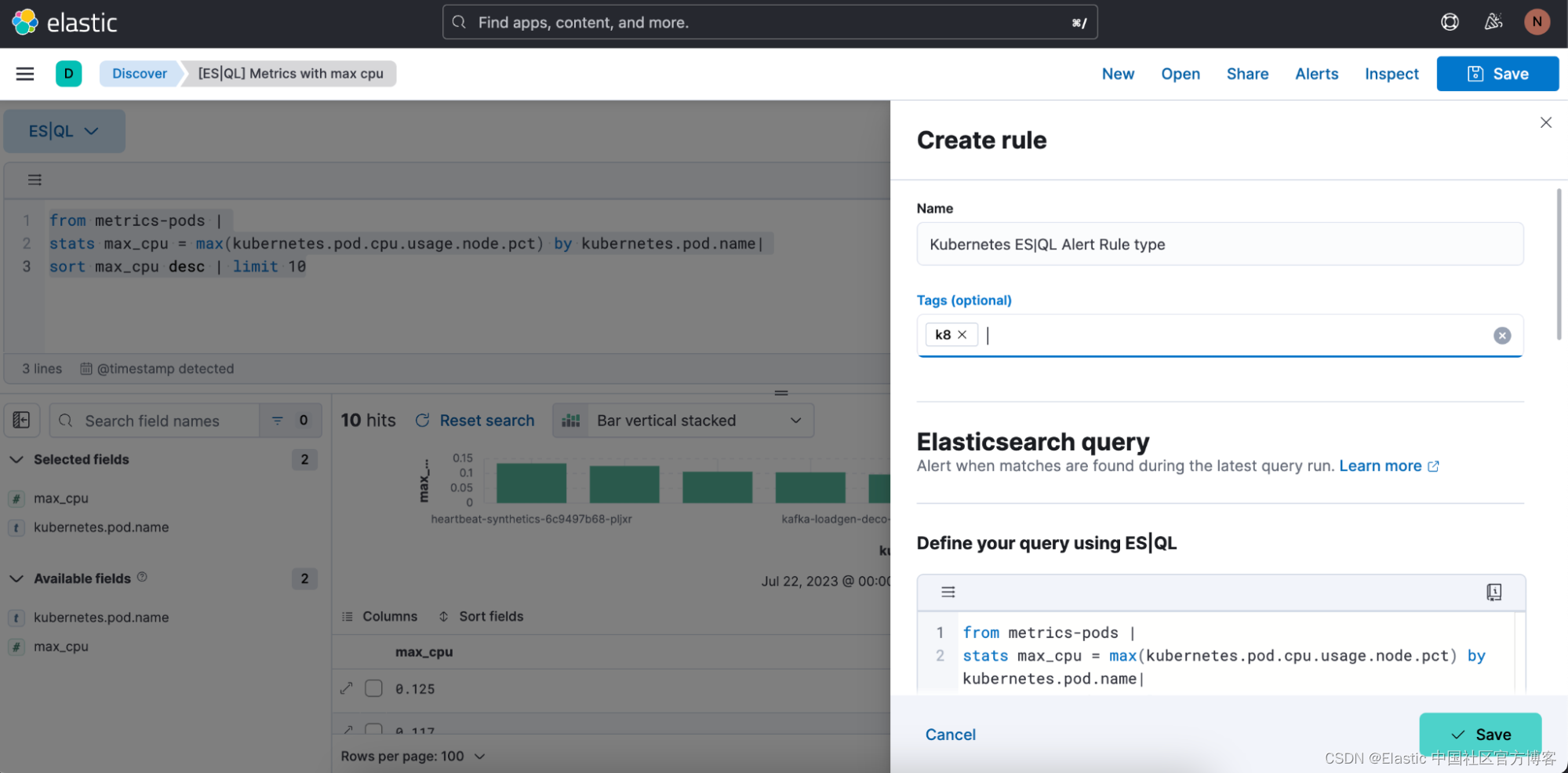
步骤 3. 测试你的警报规则类型查询
你可以迭代粘贴的 ES|QL 查询,并通过单击 “Test query” 对其进行测试。 这将为你提供表格中结果的预览。
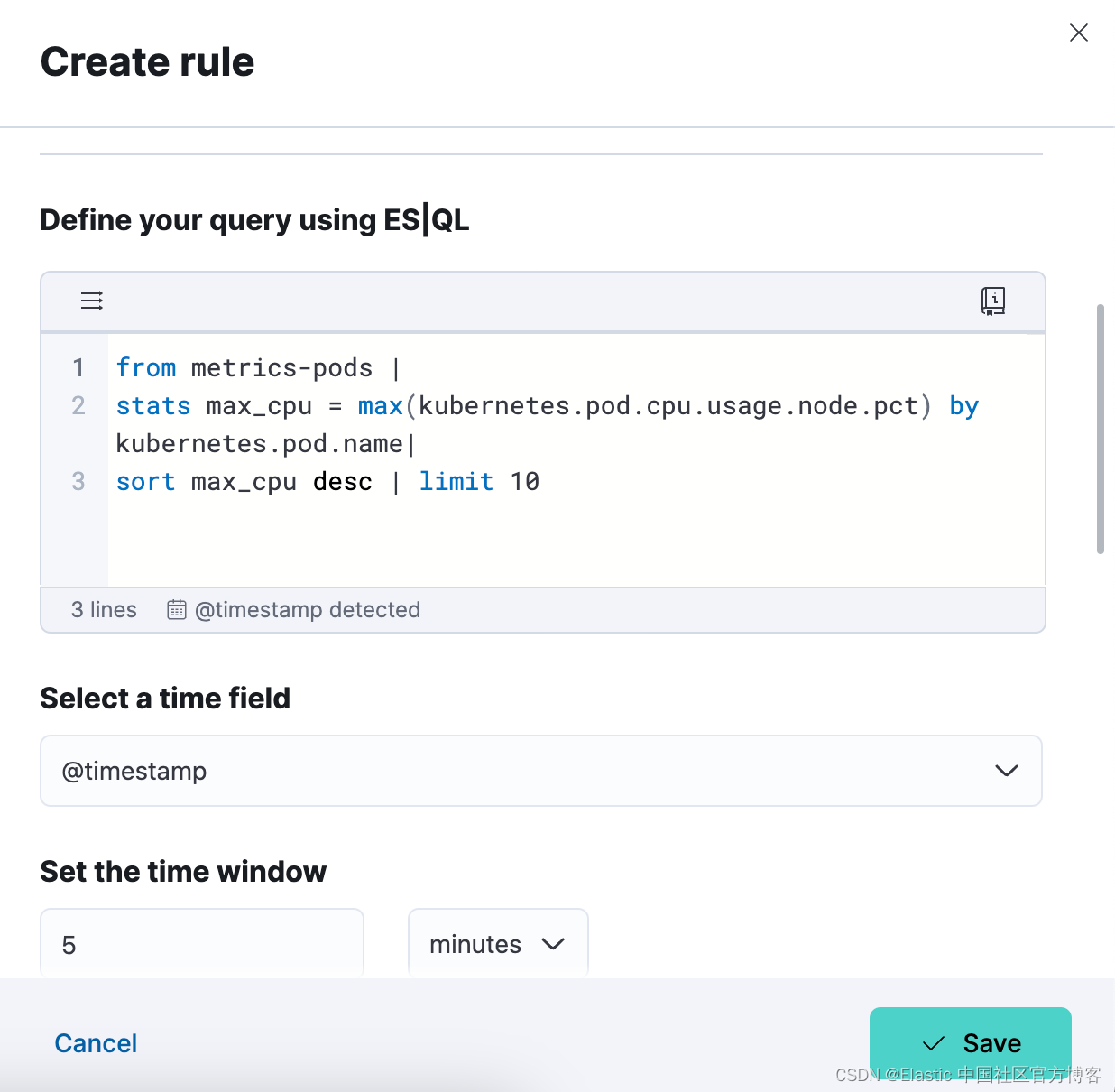
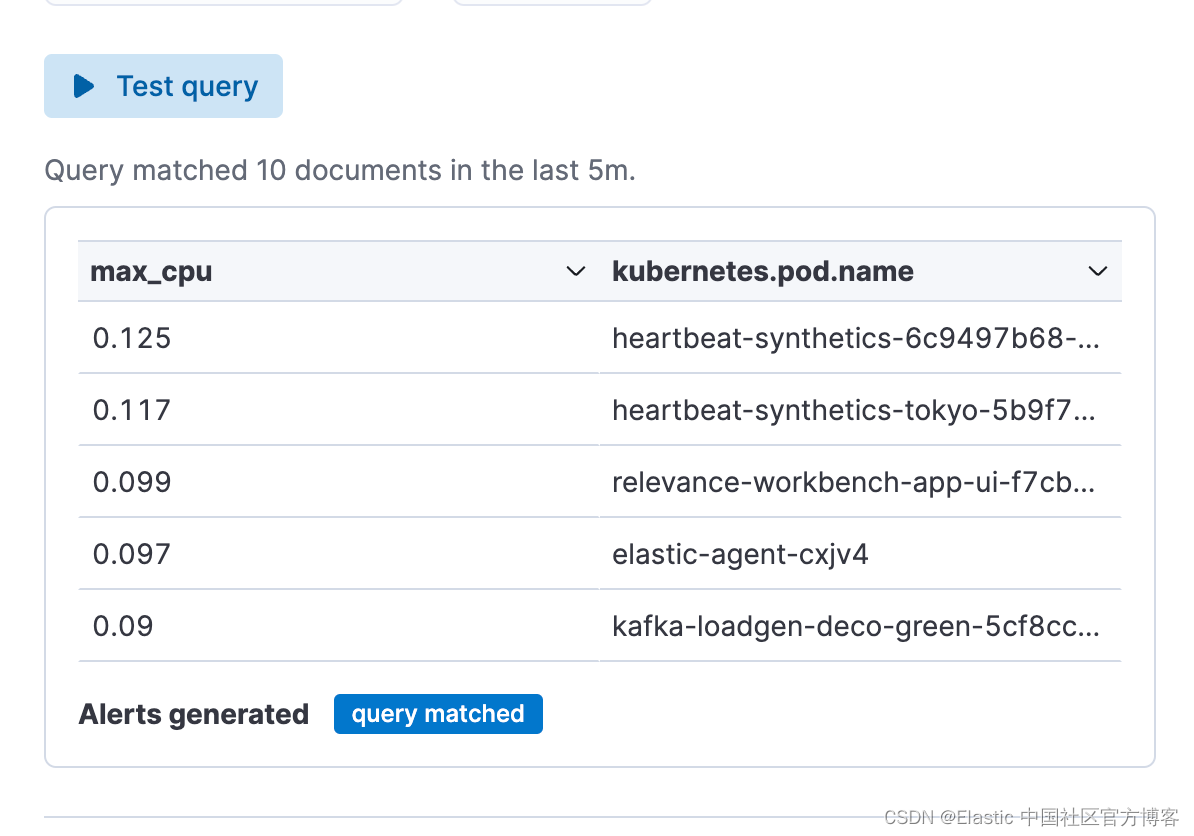
第 4 步:设置连接器并“保存”。
你现在已成功创建 ES|QL 警报规则类型!
使用另一个数据集中的字段丰富你的查询数据集
你可以使用 enrich 命令(文档)使用另一个数据集中的字段来增强查询数据集,并为所选策略提供上下文建议(即提示匹配字段和丰富列)。
使用 ENRICH 的查询示例,其中通过查询使用丰富策略:“servers-to-project” 来通过 name、server_hostname 和 cost 来丰富数据集:
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc
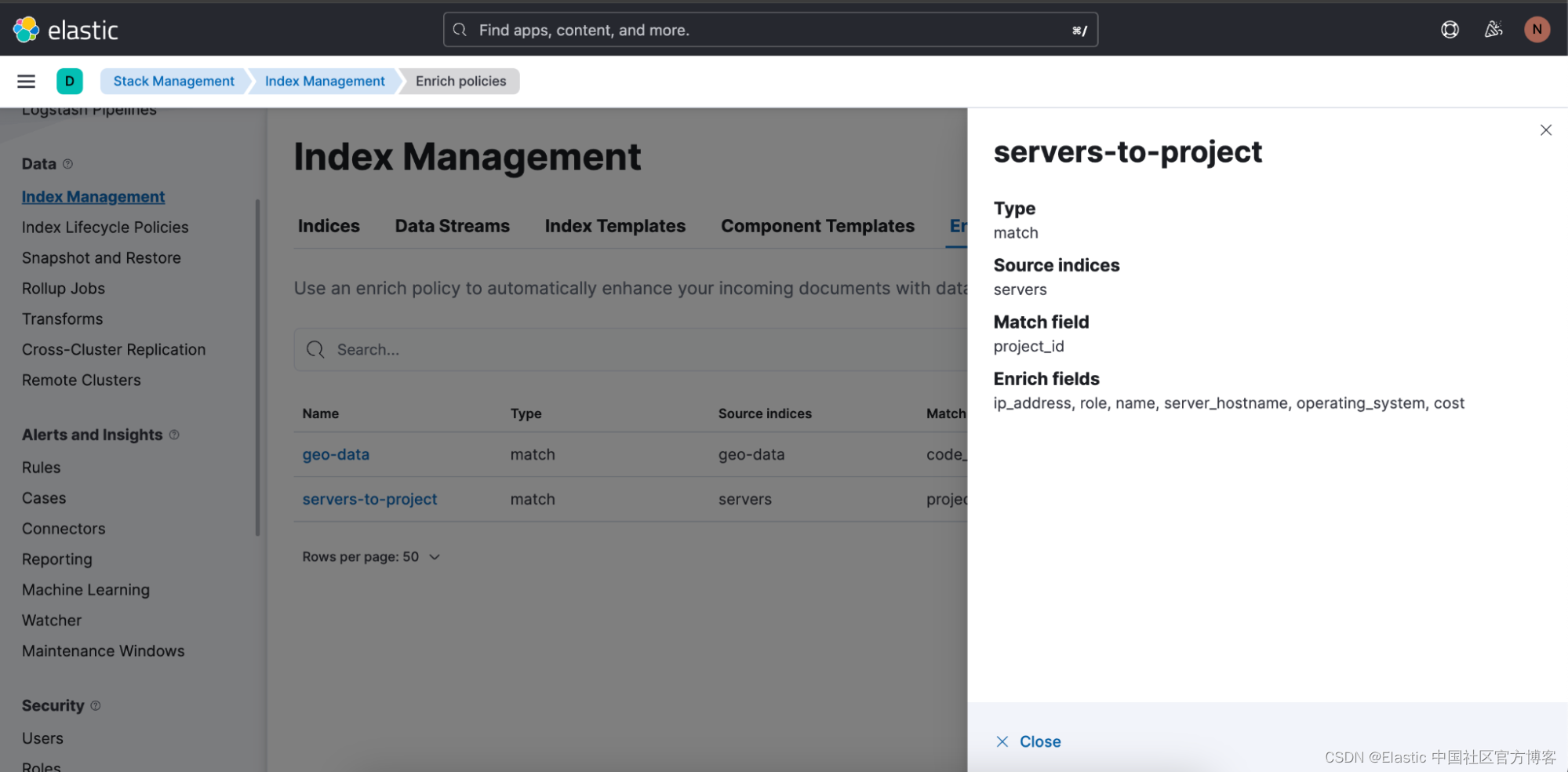
我们还通过添加概述和创建丰富策略的向导,使用户可以轻松创建丰富策略。
要查找丰富策略的概述,请导航到 Stack Management ⇒ Index Management,你将在其中看到一个名为 Enrich Policies 的选项卡:

以下是上述查询中使用的丰富策略:“servers-to-project”:
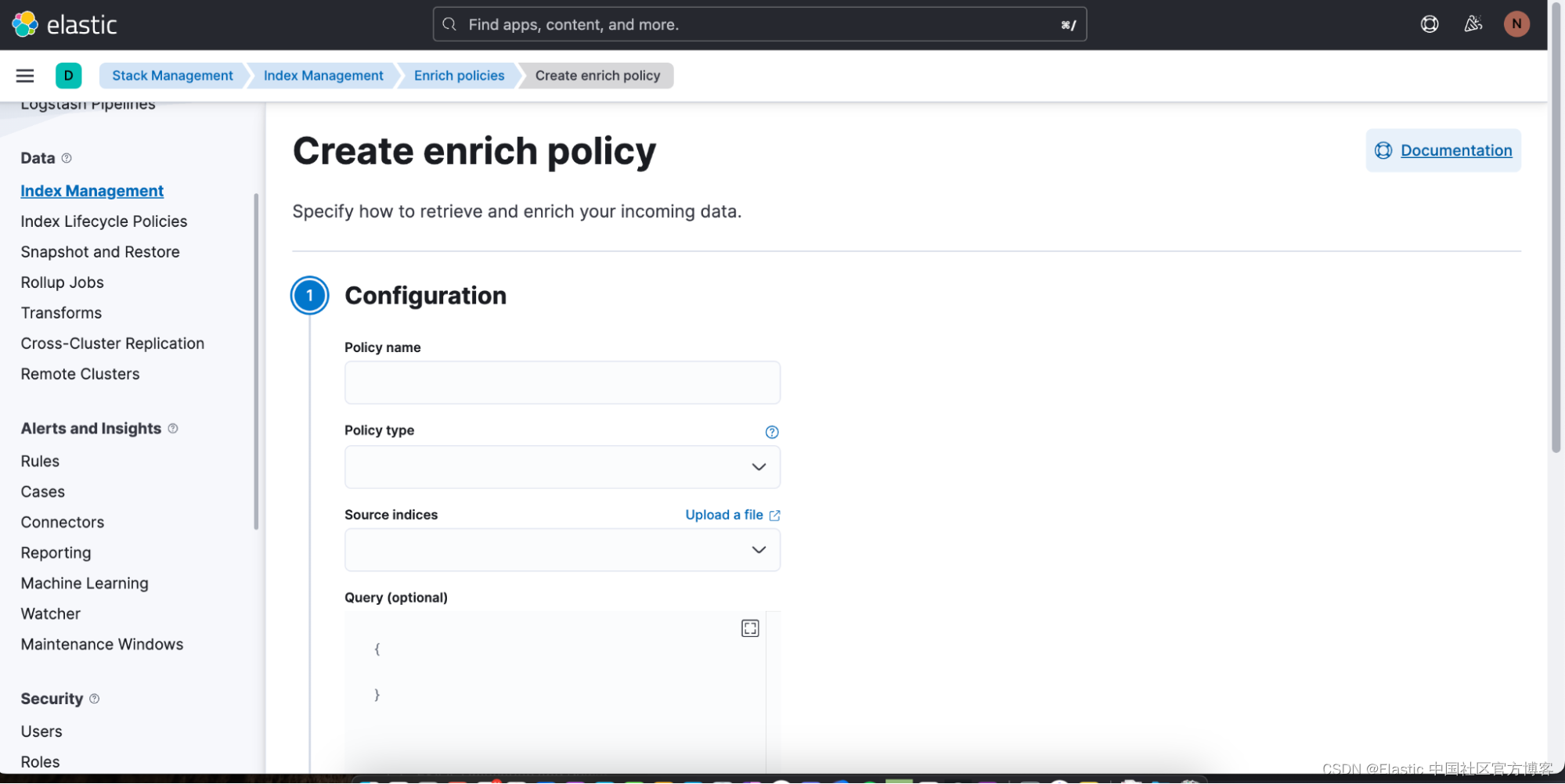
你可以通过单击 “Create enrich policy” 轻松开始创建新的丰富策略。 一旦你创建并执行了一个,就可以在 Discover 中的 ES|QL 查询中使用它。
在此处了解有关丰富策略的更多信息,以及在此处了解有关 ES|QL 中的 ENRICH 命令的更多信息。
提升数据探索:ES|QL 的力量和前景
ES|QL 是 Elastic 推进数据分析和探索的最新创新。 这不仅仅是展示数据; 它是为了使其易于理解、可操作且具有视觉吸引力。 ES|QL 由快速、分布式和专用查询引擎提供支持,设计为一种新的管道语言,并包含统一的数据探索体验,可以满足站点可靠性工程师(site reliability engineer - SRE)、DevOps、威胁猎人和其他类型的分析师的挑战。。
ES|QL 使 SRE 能够有效解决系统效率低下的问题,帮助 DevOps 确保高质量部署,并为威胁搜寻者提供快速识别潜在安全威胁的工具。 它直接集成到仪表板、内嵌可视化编辑、警报功能以及丰富命令等功能,提供了无缝且高效的工作流程。 ES|QL 界面结合了强大功能和用户友好性,允许用户深入研究数据,使他们的分析更简单、更有洞察力。 ES|QL 的推出只是 Elastic 围绕增强数据探索体验和满足用户社区不断变化的需求而努力的延续。
你今天就可以尝试 ES|QL 的所有功能! 为此,请注册 Elastic 试用帐户或在我们的公共演示环境中进行测试。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Getting started with ES|QL (Elasticsearch Query Language) | Elastic Blog
![文件包含 [ZJCTF 2019]NiZhuanSiWei1](https://img-blog.csdnimg.cn/b7e62b4fb0f34c8bb28efaef82e61a14.png)