背景
现如今,随着企业业务系统越来越复杂,单指标时间序列预测已不能满足大部分企业需求。在复杂的系统内,如果采用单一的指标进行时间序列预测,由于各个指标相互作用的关系,因此会因为漏掉部分指标因素导致出现预测精确度下降的情况。基于以上背景,多指标时间序列预测出现了。多指标时间序列预测可以将目标值涉及到的所有因素均考虑在内,因此提高了预测的准确性。
时间序列概念
时间序列是一组按照时间发生先后顺序进行排列的数据点序列。具有以下特点:
-
通常一组时间序列的时间间隔为一恒定值;
-
往往具有有意义的可探究的特征,如趋势性、周期性等;
-
时间序列会包含一定程度的噪音,即随机特征。
预测的基本任务
单指标时序预测任务是给定某一个指标的历史变化情况,预测其在未来一段时间内的变化。多指标时序预测任务则是给定某几个指标的历史变化情况,预测其在未来一段时间内的变化。多指标时序预测任务与单指标时序预测任务的区别在于几个指标之间不一定相互独立,而是存在某种影响。
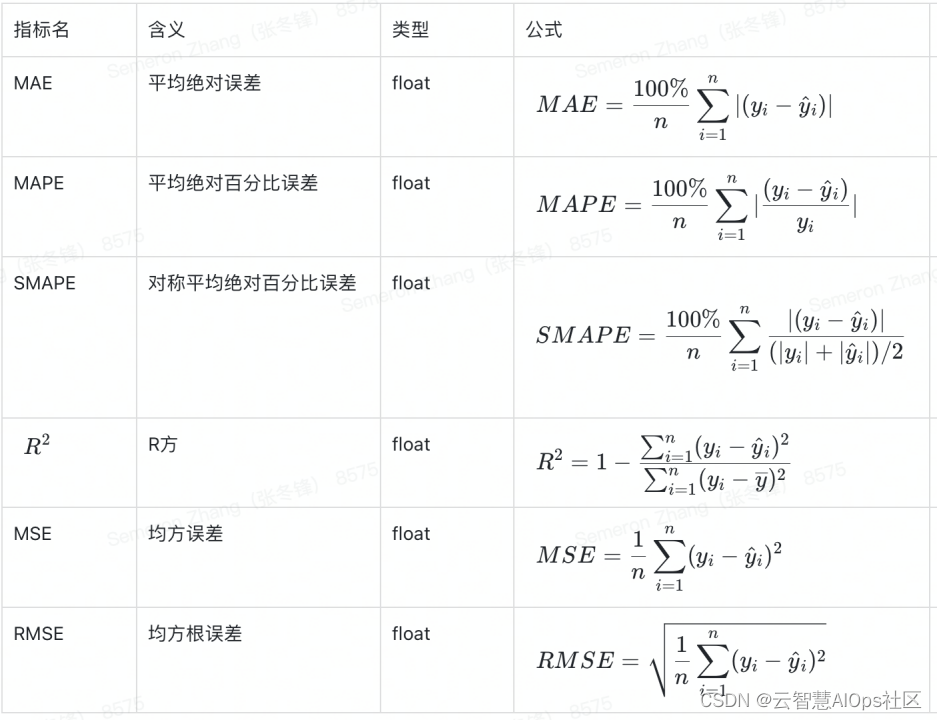
评价指标
下图为时间序列模型常用评价指。在使用过程中,需根据实际的数据特征和指标特性进行选择。
预测方式
示例:假设一个时间序列为 [1,2,3,4,5,6,7,8,9,10,X,Y,Z],通过 [1,2,3,4,5,6,7,8,9,10] 预测 [X,Y,Z]。
-
单步预测
单步预测是用 [8,9,10] 预测 [X]。即通过过去三个时间戳的值 [8,9,10] 来预测未来一个时间点的值,该模型也叫三阶滞后模型。
-
直接多步预测
直接多步预测是先通过 [8,9,10] 预测 [X],同样的方法通过 [8,9,10] 预测 [Y] 和 [Z]。该方式的缺点是预测多少个时间点的值就需要构建多少个模型,因此计算的时间和空间复杂度均非常高。
-
model1:[1,2,3,4,5,6,7,8,9],[X] -
model2:[1,2,3,4,5,6,7,8,9],[Y] -
model3:[1,2,3,4,5,6,7,8,9],[Z]
-
-
递归多步预测
递归多步预测是通过 [8,9,10] 预测 [X],随后根据预测到的 [X] 加 [9,10] 预测 [Y]。该方式由于是通过预测得到的值再次预测,因此会造成误差累计的情况,从而预测结果的精准度会持续下降。
-
[8,9,10] 得到 prediction(X); -
[9,10,prediction(x)],然后 prediction(y),依次类推。
-
-
混合模型
混合模型集合了直接多步预测和递归多步预测的优点。通过 [8,9,10] 预测 [X],随后根据预测到的 [X] 加 [8,9,10] 预测 [Y]。
-
[8,9,10] 预测 [X], -
[8,9,10,pre(X)] 预测 [Y]
-
-
多输出预测
多输出预测是通过 [8,9,10] 直接一次性将 [X,Y,Z] 预测出来。
-
[8,9,10] 预测 [X,Y,Z]
-
时序特征工程
经调研,时序特征工程应从时间戳衍生特征、时序值衍生特征、属性变量衍生特征以及特殊周期性构造四方面着手。
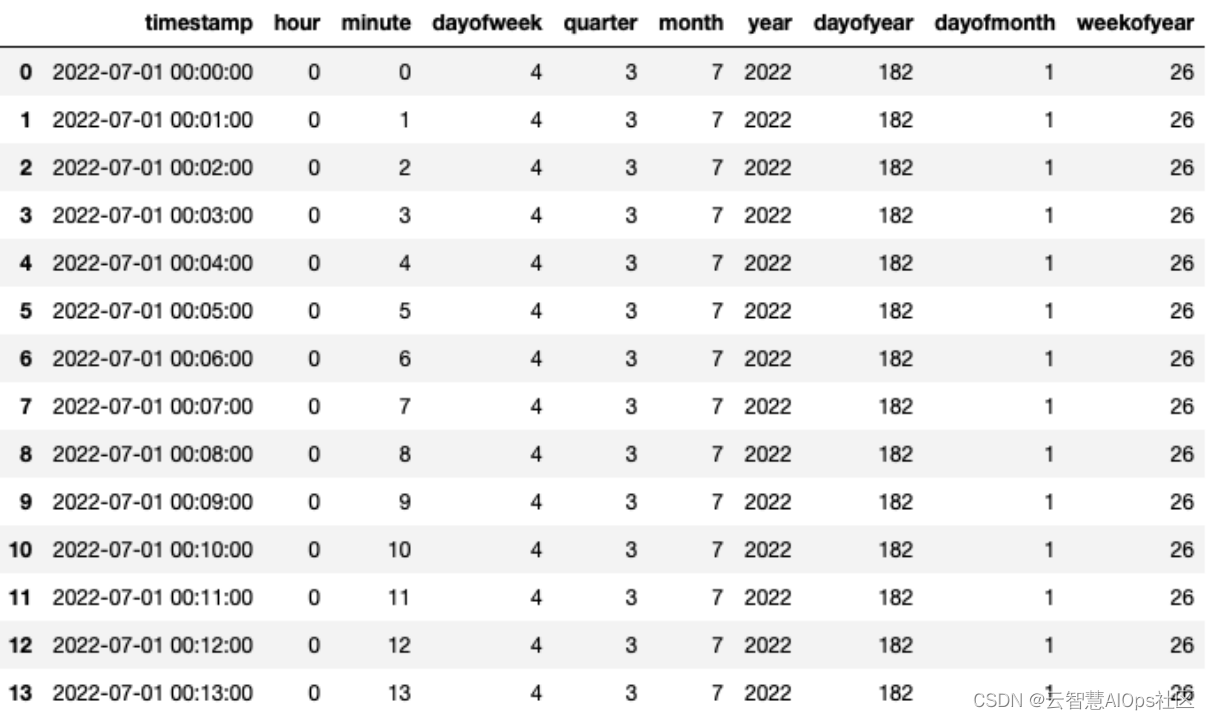
时间戳衍生
时间戳衍生出来的变量包含时间特征、布尔特征、时间差特征三大类。
时间特征: 包含年、季度、月、周、天(一年、一月、一周的第几天)、小时、分钟等。
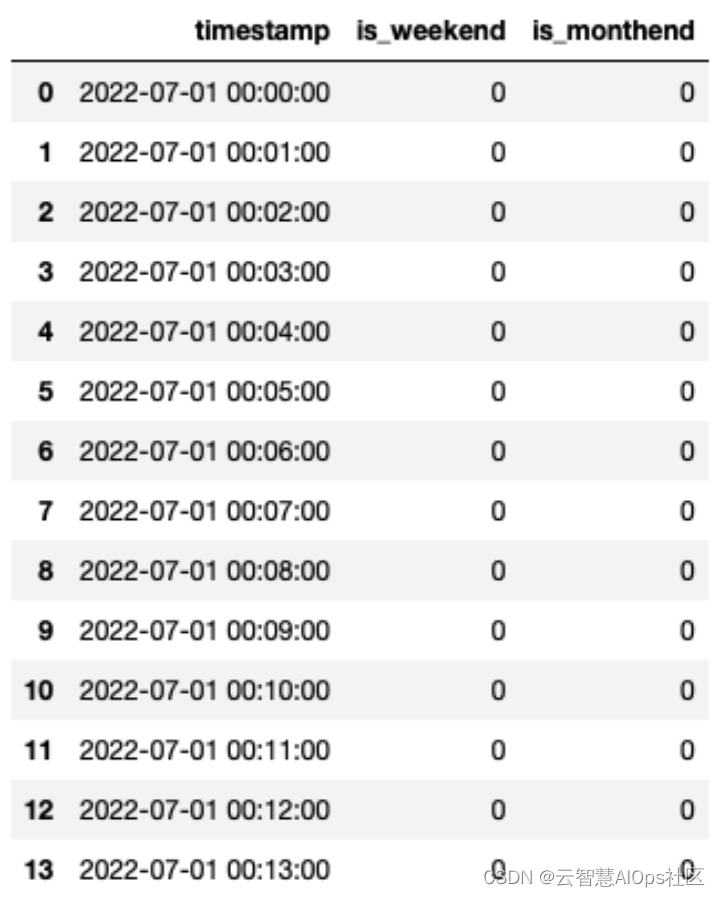
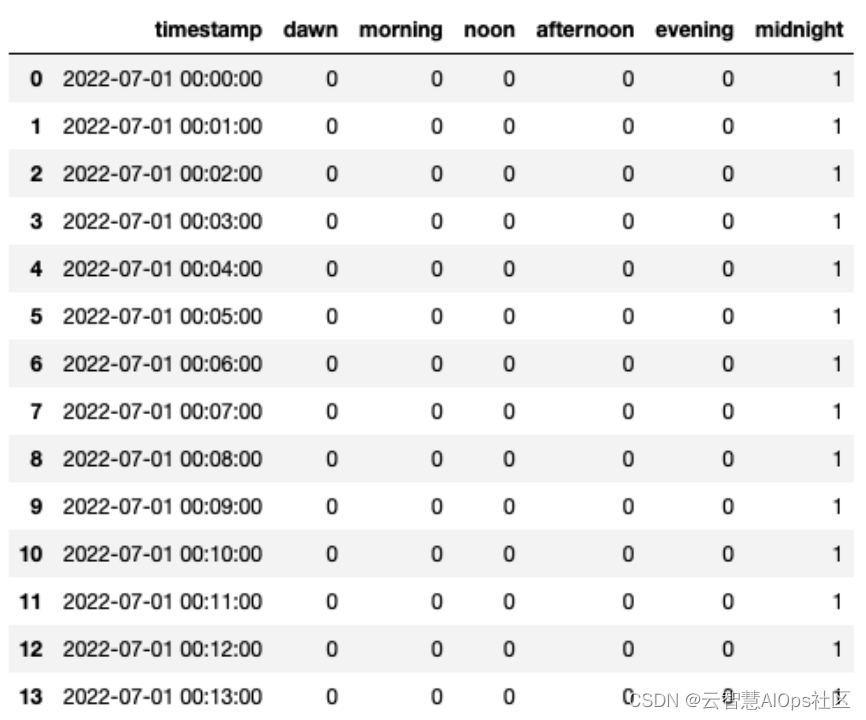
布尔特征: 包含是否年初/年末、是否月初/月末、是否周末、是否节假日、是否特殊日期、是否早上/中午/晚上等。
时间差特征: 包含距离年初/年末的天数、距离月初/月末的天数、距离周末的天数、距离节假日的天数以及距离特殊日期的天数等。
时序值衍生
时序值衍生出来的变量包含滞后特征、滑动窗口统计、扩展窗口统计三大类型。
滑动窗口统计: 时间序列的一个重要特性就是当前或未来预测值与历史值是息息相关的,通过滑动窗口构造窗口统计量则可以解决数值之前这种强相互关系的问题。
扩展窗口统计: 扩展窗口用来统计的数据是整个序列全部的数据,统计值可以是平均数、中位数、标准差、最大值、最小值等,这种特征一般是用在多序列建模,比如不同的股票价格,可能会有着不同的内在属性,在预测的时候用这个特征作为区分也是一种方式。

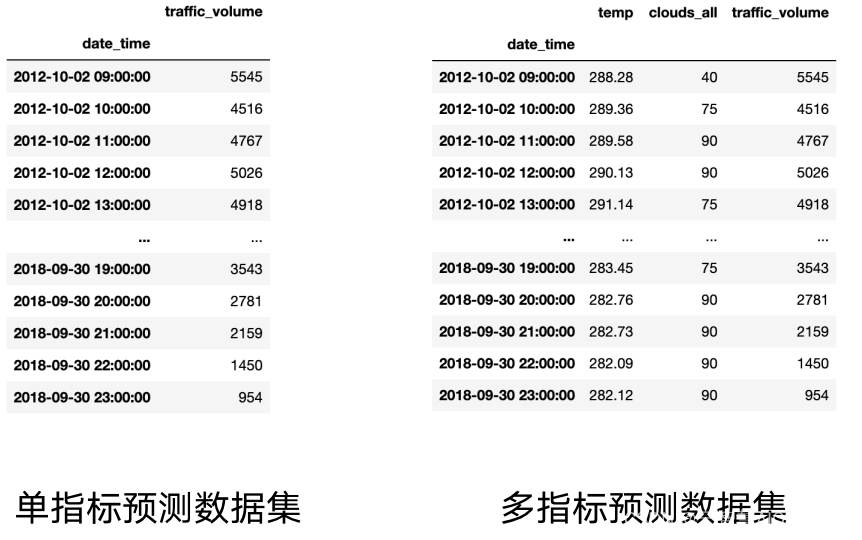
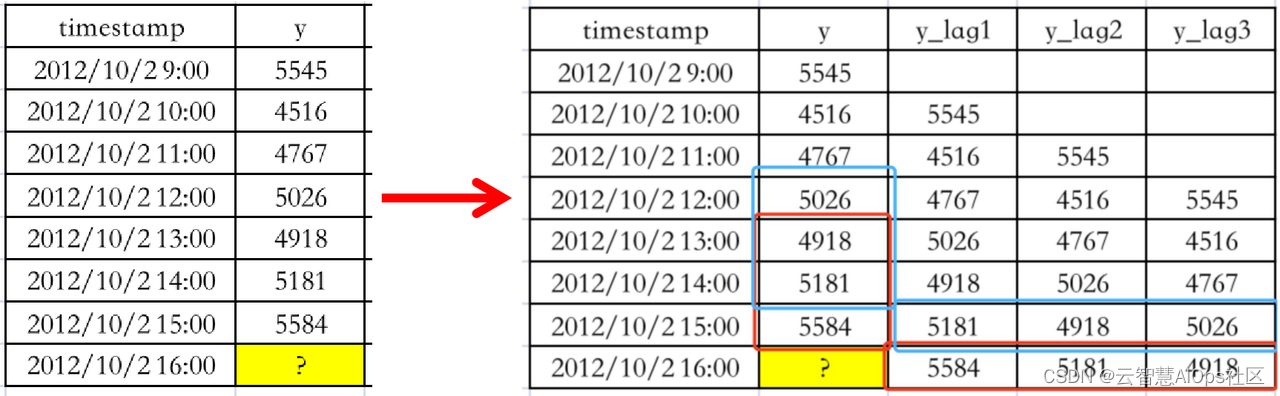
滞后特征: 滞后特征是一种特殊的滑动窗口。如下图所示,若需预测2012/10/2/ 15:00 的值 [5584],假设时间窗口长度为3,则可以使用 [5026,4918,5181] 进行预测。如果将 y 向下移动一个时间窗口,构造多个时间特征,则可以看出下图竖列的蓝色框可以变成横向的蓝色框,此时如需预测下图黄色框问号处的值,必定采用的是 [4918,5181,5584]。
属性变量衍生的特征
连续变量衍生
一个序列可能会伴有多个连续变量的特征,比如说对于股票数据,除了收盘价,可能还会有成交量、开盘价等伴随的特征,对于销量数据,可能还会伴随有价格的特征。对于这种连续变量,可以直接作为一个特征,也可以像之前时序值衍生的特征那样做处理,或者也可以与先前的数据做差值,比如t时刻的价格减去t-1时刻的价格。
类别变量衍生
对于类别型变量,如果类别比较少,一般在机器学习里做的处理是one-hot encoding,但是如果类别一多,那么生成的特征是会很多的,容易造成维度灾难,但是也不能随便用label encoding,因为很多时候类别是不反应顺序的,如果给他编码成1、2、3、4、5,对于一些树模型来说,在分裂节点的时候可不管这些是类别型还是连续型,通通当作连续型来处理,这是有先后顺序的,肯定不能这么做。所以就有这么一种方式,就是和y做特征交互,比如预测销量,有一个特征是产品类别,那么就可以统计下这个产品类别下的销量均值、标准差等,这种其实也算是上面扩展窗口统计的一种。
特殊周期性变化
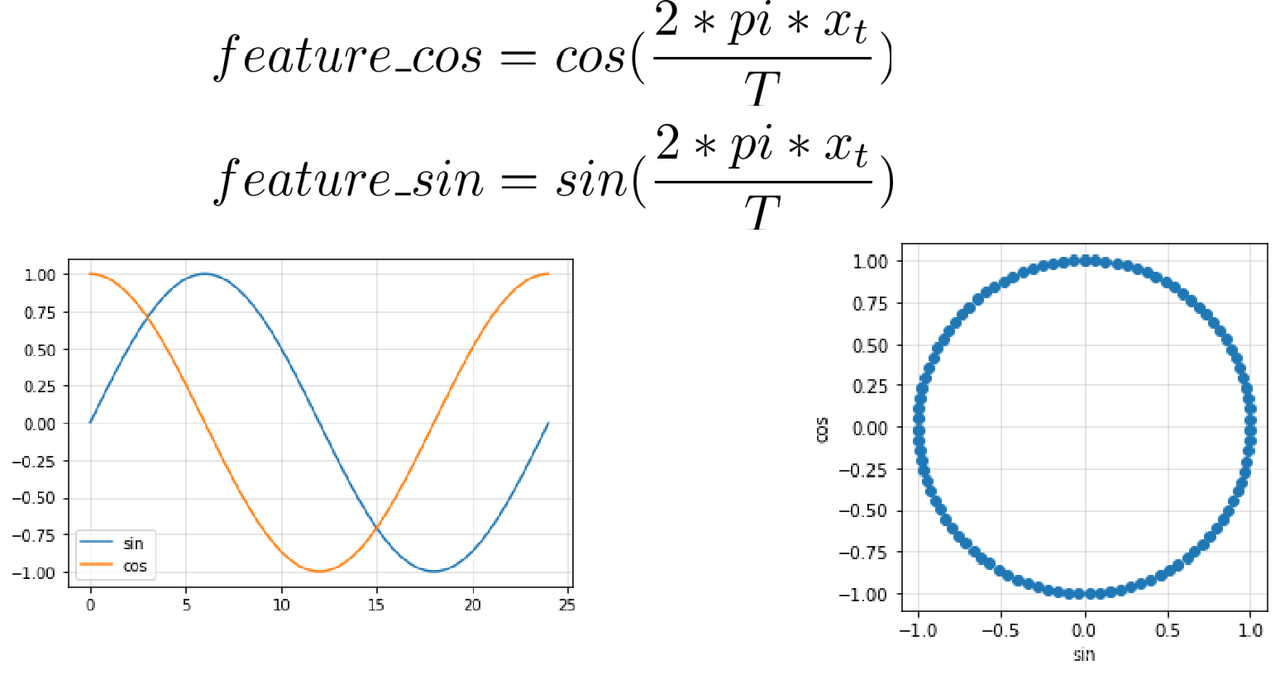
时间序列是有周期性的,比如一天、一周或是一年。由于 sin 与 cos 函数均只能体现半周期性,故时间序列的周期性需通过构造 sin 与 cos 函数作为两列特征来提前全周期性。
时间序列整体预测流程
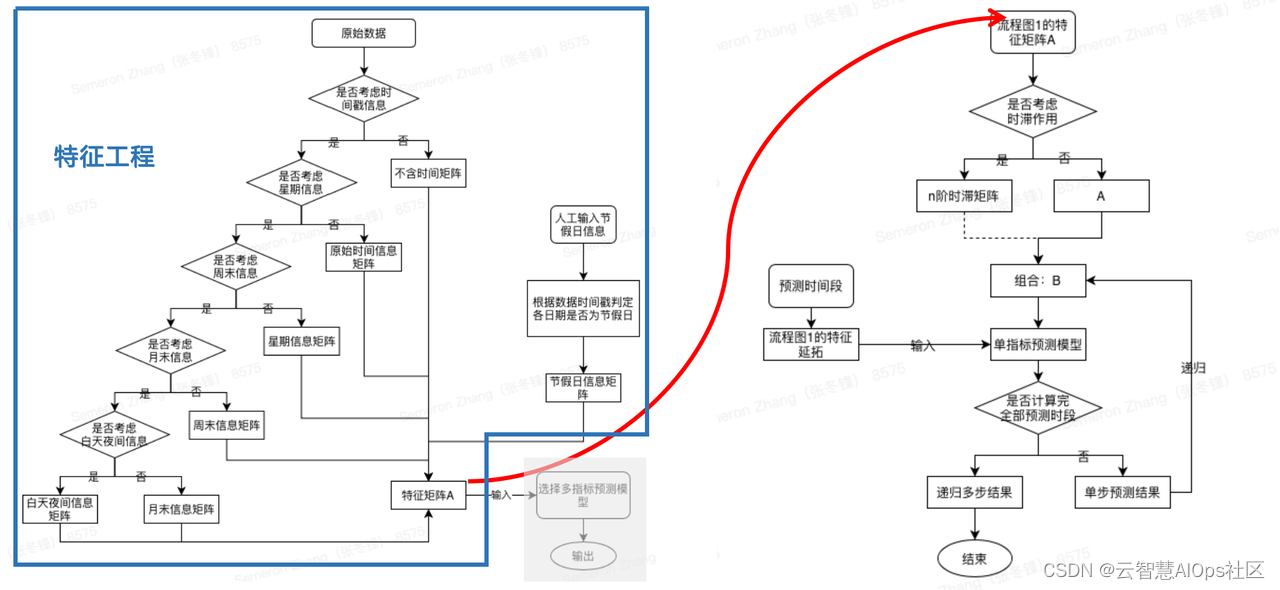
下图为时间序列整体预测流程图。左边蓝色框为特征工程,当获取到原始数据时,需先判断是否考虑时间戳信息,是否考虑星期信息,是否考虑周末信息等。随后与人工输入的节假日信息矩阵形成特征矩阵A。此时,所有的时间戳信息均已考虑完整,但是仍缺少了时间序列本身的滞后特性。此时,随红色箭头达到下图右侧,判断是否考虑时间序列滞后特性,判断完毕后,形成全新组合B,随后将组合B输入进模型,通过连续递归计算最终数值。
开源项目推荐
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
如果喜欢我们的项目,请不要忘记点击下方代码仓库地址,在 GitHub / Gitee 仓库上点个 Star,我们需要您的鼓励与支持。此外,即刻参与 FlyFish 项目贡献成为 FlyFish Contributor 的同时更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址: https://gitee.com/CloudWise/fly-fish







初印象.assets/image-20221116223203420.png)