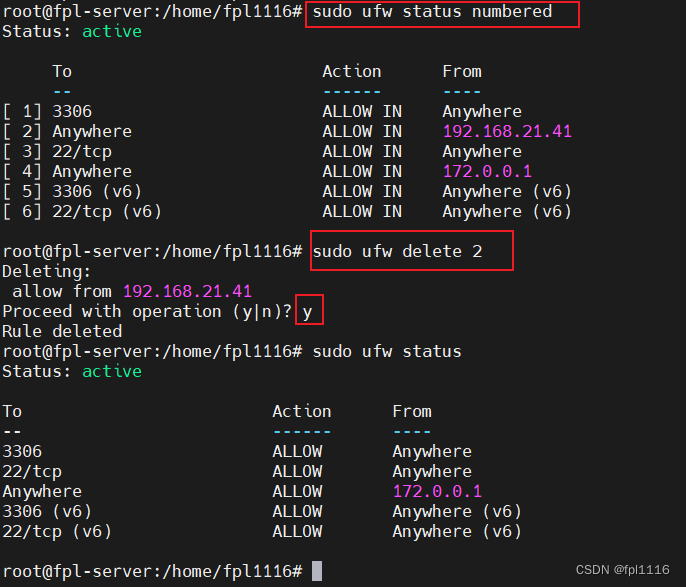
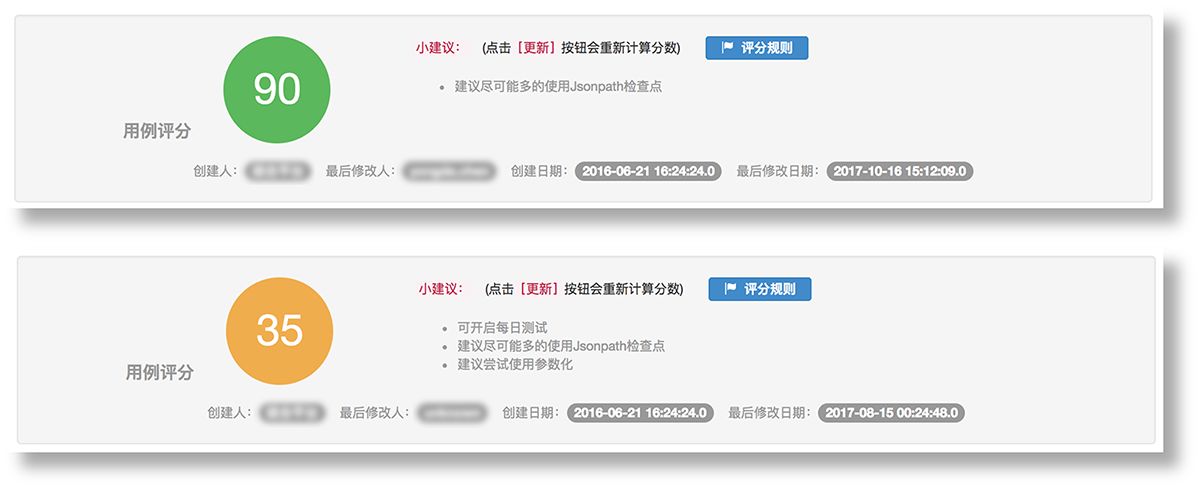
torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)num_workers 参数是 DataLoader 类的一个参数,它指定了数据加载器使用的子进程数量。通过增加 num_workers 的数量,可以并行地读取和预处理数据,从而提高数据加载的速度。
通常情况下,增加 num_workers 的数量可以提高数据加载的效率,因为它可以使数据加载和预处理工作在多个进程中同时进行。然而,当 num_workers 的数量超过一定阈值时,增加更多的进程可能不会再带来更多的性能提升,甚至可能会导致性能下降。
这是因为增加 num_workers 的数量也会增加进程间通信的开销。当 num_workers 的数量过多时,进程间通信的开销可能会超过并行化所带来的收益,从而导致性能下降。
此外,还需要考虑到计算机硬件的限制。如果你的计算机 CPU 核心数量有限,增加 num_workers 的数量也可能会导致性能下降,因为每个进程需要占用 CPU 核心资源。
因此,对于 num_workers 参数的设置,需要根据具体情况进行调整和优化。通常情况下,一个合理的 num_workers 值应该在 2 到 8 之间,具体取决于你的计算机硬件配置和数据集大小等因素。在实际应用中,可以通过尝试不同的 num_workers 值来找到最优的配置。
综上所述,当 num_workers 的值从 4 增加到 8 时,如果你的计算机硬件配置和数据集大小等因素没有发生变化,那么两者之间的性能差异可能会很小,或者甚至没有显著差异。
测试代码如下
import torch
import torchvision
import matplotlib.pyplot as plt
import torchvision.models as models
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
import time
if __name__ == '__main__':
mp.freeze_support()
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU...')
else:
print('CUDA is available! Training on GPU...')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 4
# 设置数据预处理的转换
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((512,512)), # 调整图像大小为 224x224
torchvision.transforms.ToTensor(), # 转换为张量
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
dataset = torchvision.datasets.ImageFolder('C:\\Users\\ASUS\\PycharmProjects\\pythonProject1\\cats_and_dogs_train',
transform=transform)
val_ratio = 0.2
val_size = int(len(dataset) * val_ratio)
train_size = len(dataset) - val_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_dataset = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)
val_dataset = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True,num_workers=4, pin_memory=True)
model = models.resnet18()
num_classes = 2
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(
nn.Dropout(),
nn.Linear(model.fc.in_features, num_classes),
nn.LogSoftmax(dim=1)
)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss().to(device)
model.to(device)
filename = "recognize_cats_and_dogs.pt"
def save_checkpoint(epoch, model, optimizer, filename):
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}
torch.save(checkpoint, filename)
num_epochs = 3
train_loss = []
for epoch in range(num_epochs):
running_loss = 0
correct = 0
total = 0
epoch_start_time = time.time()
for i, (inputs, labels) in enumerate(train_dataset):
# 将数据放到设备上
inputs, labels = inputs.to(device), labels.to(device)
# 前向计算
outputs = model(inputs)
# 计算损失和梯度
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
# 更新模型参数
optimizer.step()
# 记录损失和准确率
running_loss += loss.item()
train_loss.append(loss.item())
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
accuracy_train = 100 * correct / total
# 在测试集上计算准确率
with torch.no_grad():
running_loss_test = 0
correct_test = 0
total_test = 0
for inputs, labels in val_dataset:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss_test += loss.item()
_, predicted = torch.max(outputs.data, 1)
correct_test += (predicted == labels).sum().item()
total_test += labels.size(0)
accuracy_test = 100 * correct_test / total_test
# 输出每个 epoch 的损失和准确率
epoch_end_time = time.time()
epoch_time = epoch_end_time - epoch_start_time
print("Epoch [{}/{}], Time: {:.4f}s, Loss: {:.4f}, Train Accuracy: {:.2f}%, Loss: {:.4f}, Test Accuracy: {:.2f}%"
.format(epoch + 1, num_epochs,epoch_time,running_loss / len(val_dataset),
accuracy_train, running_loss_test / len(val_dataset), accuracy_test))
save_checkpoint(epoch, model, optimizer, filename)
plt.plot(train_loss, label='Train Loss')
# 添加图例和标签
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss')
# 显示图形
plt.show()不同num_workers的结果如下