本文整理于上周六(10月21日)Data Infra 第 16 期的活动内容。本次活动由 Databend 研发工程师-王旭东为大家带来了一场主题为《Databend hash join spill 设计与实现》的分享,让我们一起回顾一下吧~
以下是本次活动的相关视频、资料及文字:
通过本次分享,我们能更加了解 Databend 的 hash join spill 的设计与实现,以及学习如何使用 spill 功能。
本次活动回放也可在 B 站上找到:
🔗 Databend hash join spill 设计与实现|Data Infra 研究社第16期_哔哩哔哩_bilibili
《 Databend hash join spill 设计与实现 》
此次活动的讲稿和相关资料都可以在 Data Infra 第 16 期的 PDF 文件中找到:🔗 https://github.com/databendcn/data-infra/tree/main/第16期-20231021
Hash join 在 pipeline 架构下的设计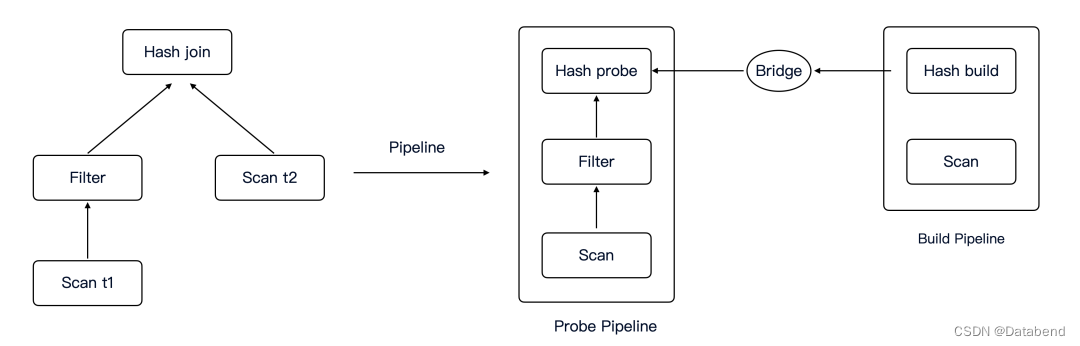
左侧是一个典型的两表 join plan,通过 pipeline builder 会生成右侧的 pipeline,包括 main pipeline 和一条子 pipeline ( build pipeline )。
probe pipeline 和 build pipeline 之间通过 bridge 结构关联,hash table 以及 build 和 probe 共用的一些 states 都会存在 bridge 里面,等 hash join build 侧生成 hash table 后会通过 bridge 把 hash table 给 probe 侧用。
Hash join 是多线程的,假设 build side 有 N 个 threads,probe side 有 M 个 threads。Probe 需要等待 build 完成后才能开始。因为两条 pipeline 是同时开始的,我们没法确定 build 先到达还是 probe 先到达,所以 probe 可能先于 build 发生,又因为是多线程执行,可能所有 probe 的线程都先与build 线程到达,也可能发生交错,这时提前到达的 probe 线程需要异步等待状态。
最直观的想法是用 notify 来控制 build 和 probe 之间的等待,因为是多线程的,所以考虑 notify waiters(),但是 notify 不知道预知有多少 waiters,它只会唤醒 register 过的 waiters,在 build 和 probe 这种模式下找到合适的地方进行注册不太可能的,所以不考虑 notify 而是用 tokio 的 watch channel 来解决 Hash join 的多线程模型。
channel 中的初始值是 0,当 build 侧完成后,最后一个 build 线程把 1 发送到 channel 中来唤醒所有的 probe 线程。probe 在开始等待 build 的时候会订阅 watcher channel,得到一个 receiver,如果此时已经是 1,可以直接进行 probe, 否则就要等待 channel 中发生 change,及 build 的最后一个线程把 1 写到 channel 里。
pub async fn wait_first_round_build_done(&self) -> Result<()> {
let mut rx = self.build_done_watcher.subscribe();
if *rx.borrow() == 1_u8 {
return Ok(());
}
rx.changed()
.await
.map_err(|_| ErrorCode::TokioError("build_done_watcher's sender is dropped"))?;
debug_assert!(*rx.borrow() == 1_u8);
Ok(())
}梳理完 build 和 probe 之间的交互后,看一下 build 的状态。不考虑 spill 的时候,它的状态比较简单,只有三个 steps,不同的 step 对应不同的 event,触发不同的行为,有异步的有同步的,一些比较重的 IO 会进行异步,还有线程之间的等待也会异步,比如在 finalize 之前需要等所有的 threads 都完成 running step (即搜集完所有的 data )。
enum HashJoinBuildStep {
// The running step of the build phase.
Running,
// The finalize step is waiting all build threads to finish and build the hash table.
Finalize,
// The fast return step indicates there is no data in build side,
// so we can directly finish the following steps for hash join and return empty result.
FastReturn,
// Wait to spill
WaitSpill,
// Start the first spill
FirstSpill,
// Following spill after the first spill
FollowSpill,
// Wait probe
WaitProbe,
// The whole build phase is finished.
Finished,
}首先所有的线程都开始运行,进入第一个 step—running,这一步主要收集 input data,到 chunk 里面,一个线程完成当前任务后需要等待其他完成,这里我们可以用 Barrier 这个 sync 结构。最后一个线程负责切分 finalize tasks 和初始化 hash table,之后所有的线程进入 finalize 阶段,并行的写 hash table。
FastReturn 是一个 fast path,如果 build side 数据为空,那么对于一些特定的 join 类型,probe 可以直接返回,不需要 probe 一个 空的 hash table。
接下来看下 probe 的状态
enum HashJoinProbeStep {
// The step is to wait build phase finished.
WaitBuild,
// The running step of the probe phase.
Running,
// The final scan step is used to fill missing rows for non-inner join.
FinalScan,
// The fast return step indicates we can directly finish the probe phase.
FastReturn,
// Spill step is used to spill the probe side data.
Spill,
// Async running will read the spilled data, then go to probe
AsyncRunning,
}第一个 step 就是我们之前提到的:等待 build 的阶段。这个阶段完成后,进入 probe 阶段。等所有的线程都完成了 probe,对于 non-inner join 要进行 Final Scan,来进行 补 NULL。
Spiller 模块的设计
Spiller 是一个比较独立的模块,也就是说不局限在某一个 operator 上,所有有 spill 需求的 operator 都可以利用 Spiller 模块完成 spill 操作。
具体来说,spiller 负责以下工作:
- 收集需要 spill 的数据
- partition 需要 spill 的数据
- 序列化和反序列化数据
- 与存储进行读写交互
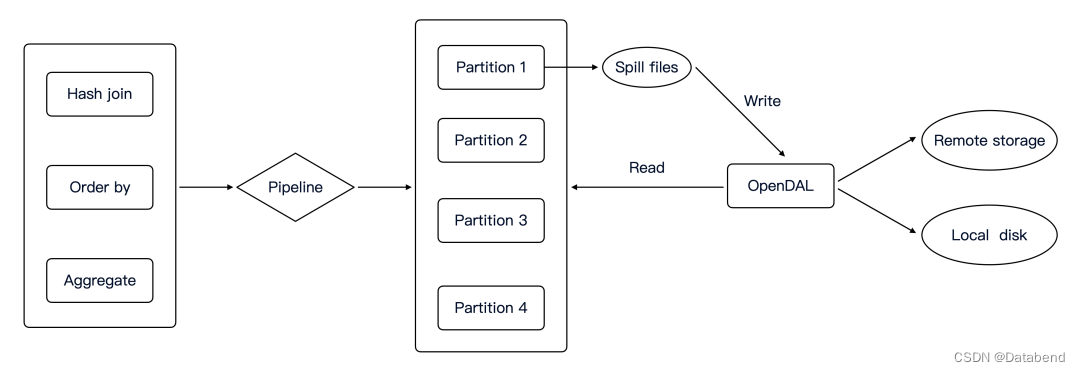
每一个 partition 都有一个 file lists,通过 opendal 把对应的 files 写到存储上。
Hash join spill 设计与实现
首先看一下 build 侧,80% 的工作量都在 build 侧,probe 只需要根据 build 的 spill 信息进行 spill 就可以。
enum HashJoinBuildStep {
// The running step of the build phase.
Running,
// The finalize step is waiting all build threads to finish and build the hash table.
Finalize,
// The fast return step indicates there is no data in build side,
// so we can directly finish the following steps for hash join and return empty result.
FastReturn,
// Wait to spill
WaitSpill,
// Start the first spill
FirstSpill,
// Following spill after the first spill
FollowSpill,
// Wait probe
WaitProbe,
// The whole build phase is finished.
Finished,
}引入 spill 后,build step 多了四个主要的 step,WaitSpill、FirstSpill 以及 FollowSpill 和 WaitProbe。
每个线程都有自己的 Spiller,否则这个线程的 spill 工作,不同线程的 spill 通过 BuildSpillCoordinator 来协调。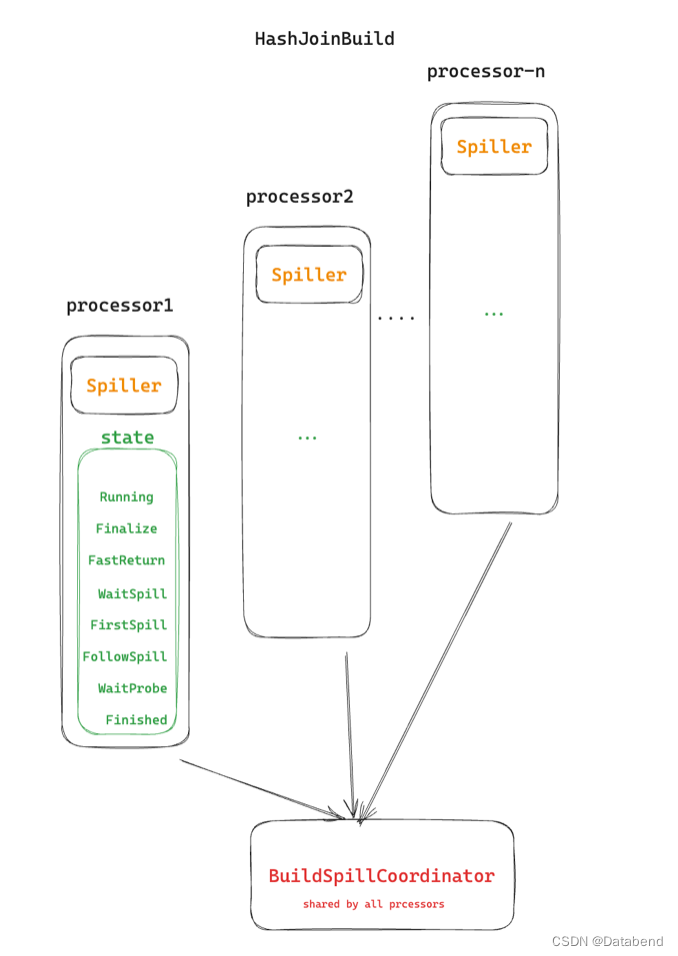
如果一个线程对当前内存数据大小进行判断,发现需要 spill 后,会进入 WaitSpill 状态,BuildSpillCoordinator会记录当前等待 spill 的线程数量,最后一个线程不会进入等待状态,而是直接作为 coordinator,来协调第一次 spill,它会把 buffer 中所有等待 spill 的数据收集起来,进行 partition,均匀的生成 tasks,分发给每个线程,每个线程的 partition set 都是一样的。完成第一次 spill 后,之后的 spill 不需要再 buffer 数据,如果数据有对应的 partition 可以直接进行 spill,否则 buffer 起来,看后续是否还需要 spill,如果内存够用,可以直接生成 hash table。
等所有的 spill 工作完成后对内存中的数据,进行正常的 hash join build 过程,生成 hash table,通过 bridge 发给 probe 后进入 wait probe 状态。
接下来先看下 hash join probe 侧 spill 的工作,然后再回到 build。
probe 和 build 一样,每个线程都有一个 Spiller。
enum HashJoinProbeStep {
// The step is to wait build phase finished.
WaitBuild,
// The running step of the probe phase.
Running,
// The final scan step is used to fill missing rows for non-inner join.
FinalScan,
// The fast return step indicates we can directly finish the probe phase.
FastReturn,
// Spill step is used to spill the probe side data.
Spill,
// Async running will read the spilled data, then go to probe
AsyncRunning,
}有了 spill 后,当 WaitBuild 阶段结束后,就要进入 Spill 阶段了。
build 会通过 bridge 把它的 partition set 发过来,比如 {0, 1, 2 3},probe 也会利用 Spiller 对数据计算 partition,如果 partition id 在 build 的 partition set 中,会下刷,对于不在的数据,如果是第一轮,会跟 build 发送过来的 hash table 进行 probe。
spill 完成后,会选出一个 partition id,发送给 build,build 拿到 id 后,会把相关 partition 的数据读上来,进行正常的 hash join build 流程,生成 hash table 给 probe,probe 也会读取对应 id 的数据进行 probe,这就是正常的 hash join 过程。每完成一轮,就取一个 partition id,直到没有需要读取的 partition。
未来规划
- 支持递归 spill
- 应用具体的场景
- 进一步优化
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
- Databend Website
- GitHub Discussions
- Slack Channel