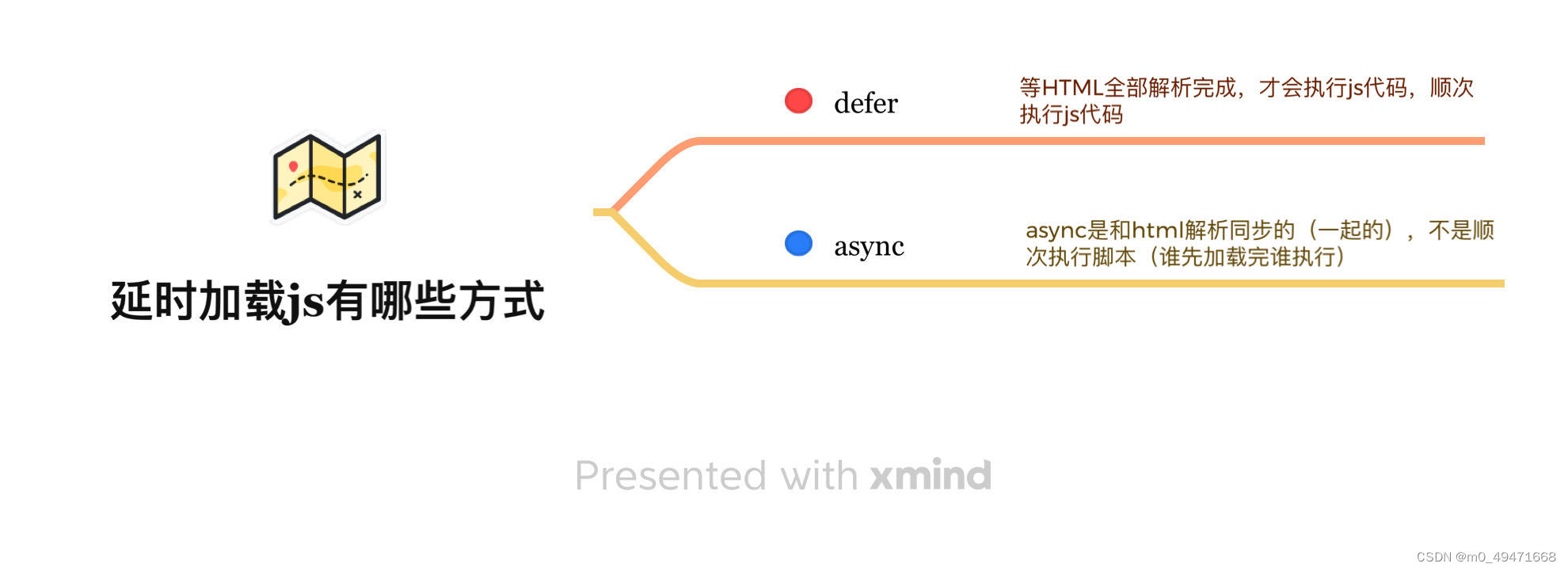
1.定义
随机森林是一种集成学习方法,它利用多棵树对样本进行训练并预测。
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器,每棵树都由随机选择的一部分特征进行训练和构建。通过多棵树的集成,可以增加模型的多样性和泛化能力。
在训练过程中,对于每个决策节点,随机选择一部分特征进行分裂,可以减少模型的过拟合。同时,通过对样本进行随机抽样,可以使模型更好地处理异常值和噪声。
在预测过程中,每棵树都会对输入样本进行独立预测,然后以多数投票的方式确定最终的预测结果。这种方法可以增加模型的可靠性和稳定性。
2.随机森林的工作流程




3.优点
随机森林是一种非常强大的机器学习算法,具有许多优点。以下是它的主要优点:
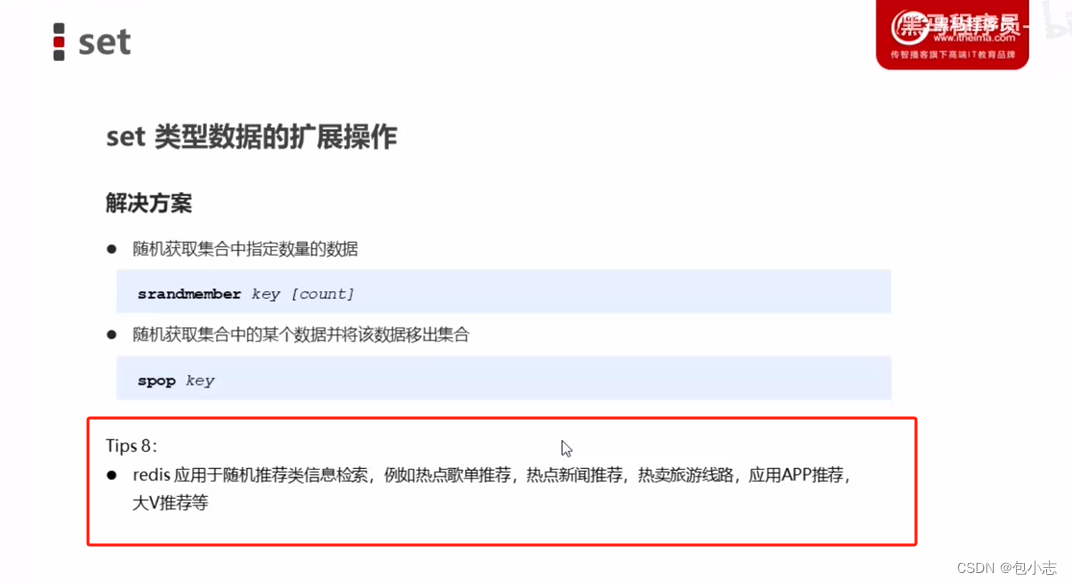
- 高准确度:对于许多种资料,随机森林可以产生高准确度的分类器。
- 处理大量输入变量:随机森林可以处理大量的输入变量,即使在输入变量维度非常高的情况下,也能保持较高的准确度。
- 评估变量重要性:在构建森林时,随机森林可以在内部对于一般化后的误差产生不偏差的估计,并评估每个变量对于预测结果的重要性。
- 侦测交互:它可以学习变量之间的交互关系,并且通过实验方法可以侦测出变量之间的相互作用关系。
- 处理不平衡数据集:对于不平衡的分类资料集来说,随机森林可以平衡误差。
- 亲近度计算:它可以计算各例中的亲近度,对于数据挖掘、侦测偏离者(outlier)和将资料视觉化非常有用。
- 未标记资料的应用:随机森林可以延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。
4.缺点
以下是随机森林的一些主要缺点:
- 过拟合:如果训练数据存在噪声或异常值,随机森林可能会过度拟合这些数据,导致在新的、未见过的数据上表现不佳。
- 特征重要性评估:虽然随机森林可以评估每个特征对于分类或回归结果的重要性,但这些评估结果并不一定总是准确的。有时,某些重要特征的重要性可能被低估或不准确地评估。
- 计算复杂度:构建随机森林需要大量的计算资源和时间,特别是当输入变量维度很高时,训练过程可能会非常缓慢。
- 训练过程中的随机性:由于随机森林的训练过程中引入了随机性,因此每次训练的结果可能会有所不同。这可能导致模型的不确定性增加,也可能导致某些重要特征的重要性被低估或不准确地评估。
- 对数据量的要求:随机森林需要相对较大的数据集才能充分发挥其潜力,对于较小的数据集,其性能可能会不如一些其他算法。
- 对异常值和离群点的敏感性:随机森林算法可能会受到数据中的异常值和离群点的影响,这可能会影响其性能。
- 可能产生过拟合:由于随机森林是一种基于树的集成学习算法,如果训练数据集存在大量的噪声或者异常值,它可能会产生过拟合,导致模型在新的、未见过的数据上表现不佳。
5.随机森林的特征重要性评估