主流推荐算法

协同过滤算法
协同过滤算法的原理
根据用户群体对产品偏好的数据,发现用户之间的相似性或者物品之间的相似性,并基于这些相似性为用户作推荐。
- 基于用户的协同过滤算法(User-based Collaborative Filtering)
其本质是:寻找相似的用户,进而对用户推荐相似用户关注的产品。
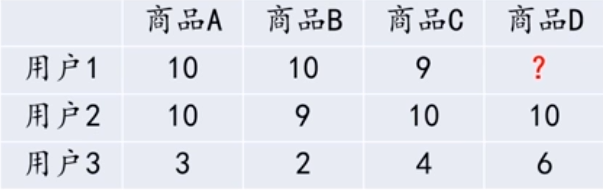
如下表所示,用户1和用户2都给商品A,B,C打了高分,那么可以将用户1和用户2划分在同一个用户群体,此时若用户2还给商品D打了高分,那么就可以将商品D推荐给用户1。
- 基于物品的协同过滤算法(Item-based Collaborative Filtering)
其本质是:根据用户的历史偏好信息,将类似的物品推荐给用户
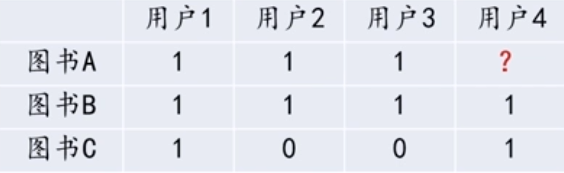
如下表所示,图书A和图书B都被用户1,2,3购买过(1表示购买,0表示未购买),那么可以认为图书A和图书B具有较强的相似度,即可判断喜欢图书A的用户同样也会喜欢图书B。当用户4购买图书B时,根据图书A和图书B的相似性,可将图书A推荐给用户4。
大多应用场景偏向于使用基于物品的协同过滤算法。主要有如下两个原因:
原因一:通常用户的数量是非常庞大的(如淘宝数亿的用户群体),而物品的数量相对有限,因此计算不同物品之间的相似度往往比计算不同用户的相似度容易很多。
原因二:用户的喜好较为多变,而物品属性较明确不随时间变化,过去用户对物品的评分长期有效,所以物品间的相似度比较固定,因此可以预先离线计算好物品间的相似度,把结果存在表中,向客户进行推荐时再使用
协同过滤算法简单实例
import numpy as np
# 创建一个用户-物品评分矩阵(示例数据)
ratings = np.array([
[5, 4, 0, 0, 1],
[4, 0, 0, 0, 2],
[0, 5, 3, 0, 0],
[0, 0, 0, 4, 5]
])
# 计算用户相似度(使用余弦相似度)
def cosine_similarity(user1, user2):
mask = (user1 > 0) & (user2 > 0)
if np.sum(mask) == 0:
return 0
else:
dot_product = np.sum(user1[mask] * user2[mask])
norm_user1 = np.linalg.norm(user1[mask])
norm_user2 = np.linalg.norm(user2[mask])
return dot_product / (norm_user1 * norm_user2)
# 根据用户相似度进行推荐
def user_based_collaborative_filtering(ratings, user_id, num_recommendations):
num_users, num_items = ratings.shape
recommendations = np.zeros(num_items)
for i in range(num_users):
if i != user_id:
similarity = cosine_similarity(ratings[user_id], ratings[i])
recommendations += similarity * ratings[i]
# 找到用户未评分的物品
unrated_items = (ratings[user_id] == 0)
# 对用户未评分的物品进行推荐
recommended_items = np.argsort(recommendations)[::-1]
return recommended_items[unrated_items][:num_recommendations]
# 示例:为用户0进行协同过滤推荐
user_id = 0
num_recommendations = 2
recommendations = user_based_collaborative_filtering(ratings, user_id, num_recommendations)
print("为用户0推荐的物品索引:", recommendations)






![WGCNA分析教程五 | [更新版]](https://img-blog.csdnimg.cn/img_convert/6b3ed167c11bfa4e4ccedc5e49452045.png)