Redis(Remote Dictionary Server) 由Salvator Sanfilippo在2009年开源的使用 ANSI C 语言编写、高性能、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API 的非关系型数据库。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 Redis 被广泛应用于缓存,每秒可处理超过 10 万次读写操作,是已知性能最快的 Key-Value 数据库。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。 Redis已经成为分布式缓存的事实标准,有必要学习好Redis。
为什么使用Redis
(1) 读写性能优异。 Redis使用内存存储数据,可以满足实时,高并发场景的应用。Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s。
(2) 键值数据模型。Redis使用键值模型作为其数据模型。在键值模型中,键唯一,且通过键实现数据的CRUD操作。Redis数据库中,键的数据类型只能是字符串,值可以是字符串、列表、集合、GEO等多种数据类型中的一种。键值数据模型可以提供高效的读写效率。
(3) 提供多种数据类型。Redis使用键值存储。尽管Redis的键的数据类型只能是string,但Redis的值的类型支持多种数据类型:string(字符串)、list(列表)、set(集合)、zset(有序集合)、hash(哈希)、bitmap(位图)、geo(地理信息)等。
(4) 支持持久化。内存数据库存储的数据会因系统崩溃或服务器宕机而丢失。使用Redis存储数据时,为减少或避免数据的意外丢失,可使用持久化机制将写命令数据同步到磁盘中。对作为缓存的Redis来说,持久化机制可加快系统崩溃或服务器宕机时缓存数据恢复速度。但持久化功能会降低Redis性能。Redis提供RDB(Redis DataBase)和AOF(Append Only File)两种持久化模式。RDB持久化,通过生成一个子进程的方式,将数据库某一时刻存储的数据保存到基于磁盘的RDB文件中。RDB文件记录Redis数据库在某个时刻存储的数据,该文件相当于某一时刻Redis数据库存储数据,也称一次快照(snapshot),所以也可称其为快照文件。AOF持久化使用Redis自定义的协议格式——RESP(Redis Serialization Protocol)记录每次写命令数据,并将其追加到指定的AOF文件中。AOF文件本质上是一个写日志文件。(持久化文件,对于缓存来说,可以实现数据的快速回复;对于内存数据库来说,保证了可靠性)
(5) 支持集群。从3.0版本开始Redis正式提供集群功能。
(6) 支持主从复制。Redis的主从复制功能可避免单个Redis服务器发生故障造成的服务不可用,或单个服务器处理请求负载过大造成服务延迟等情况的发生。Redis在主从复制中实现的冗余备份、读写分离等功能,可极大提高整个系统的可用性、可靠性和性能。主从复制虽然能够提高数据可用性和系统性能、保证系统可靠性,但作为数据复制技术,会带来数据一致性维护问题。
(7) 支持简单事务。Redis提供事务功能。Redis虽然支持事务功能,但相比传统的关系型数据库,Redis提供的事务不支持回滚。Redis之所以不支持事务回滚,一方面是因为事务回滚实现复杂,这与Redis简单高效的设计目标不符;另一方面是因为Redis事务执行错误是由编程错误(语法错误和键持有错误的数据类型)造成。编程错误属于程序性错误,只会在开发环境中产生,在实际生产中很少出现,因此选择将其忽略。另外,由于事务功能可能涉及多个keys和多个节点,所以Redis在集群模式下不再支持事务功能,除非这些keys存储在同一个节点上。
Redis高性能的原因
(1) 基于内存实现,相比硬盘,内存的读写效率更高。
(2) 命令执行时是单线程,可以减少上下文切换,同时保证原子性。
(3) 在接收命令时,基于IO多路复用实现,可以保证高吞吐量。
(4) 自定义了一些高级数据结构(如 SDS、Hash以及跳表等),优化了读写性能。
Redis支持的数据类型及实现
数据类型
Redis 常用的数据类型有五种:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)。此外,还有bitmap(位图)、geo(地理信息)等类型。
(1) string
string 是 Redis 最基本的数据类型。一个 key 对应一个 value。string 是二进制安全的。也就是说 Redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512 MB。这是因为Redis字符串是以字节数组存储的。
(2) hash
Redis hash 是一个键值对(key - value)集合。Redis hash 是一个 string 类型的 key 和 value 的映射表,hash 特别适合用于存储对象。并且可以像数据库中一样只对某一项属性值进行存储、读取、修改等操作。hash的最大存储范围是取决于可用内存的大小,它没有严格的存储限制。
(3) list(双向链表)
Redis 列表是简单的字符串列表,按照插入顺序排序。我们可以向列表的左边或者右边添加元素。 list 就是一个简单的字符串集合,和 Java 中的 list 相差不大,区别就是这里的 list 存放的是字符串。list 内的元素是可重复的。可以做消息队列或最新消息排行等功能。list 的最大存储取决于可用内存的大小,没有严格的存储限制。
(4) set
Redis 的 set 是字符串类型的无序集合。集合是通过哈希表实现的,因此添加、删除、查找的复杂度都是 O(1)。Redis 的 set 是一个 key 对应着多个字符串类型的 value,也是一个字符串类型的集合,和 Redis 的 list 不同的是 set 中的字符串集合元素不能重复,但是 list 可以。利用唯一性,可以统计访问网站的所有独立 ip。Redis Set 的最大存储范围是
2
3
2
−
1
2^32 - 1
232−1个元素,即4294967295个元素。
(5) zset
Redis zset 和 set 一样都是字符串类型元素的集合,并且集合内的元素不能重复。不同的是 zset 每个元素都会关联一个 double 类型的分数。Redis 通过分数来为集合中的成员进行从小到大的排序。zset 的元素是唯一的,但是分数(score)却可以重复。可用作排行榜等场景。Redis ZSet的最大存储范围是
2
3
2
−
1
2^32 - 1
232−1个。
数据结构
SDS
Redis为了将字符串符合自己的使用要求,创建了自己的字符串结构—Simple Dynamic String(简单动态字符串,SDS)。SDS是Redis中最基本的底层数据结构,它既是Redis的String类型的底层实现,也是实现Hash、List和Set 等复合类型的基石。
双端链表
链表作为一种常用的数据结构,普遍内置到一些高级的编程语言里,因为Redis使用的C语言没有内置这种数据结构,所以Redis构建了自己的链表实现。
字典(重难点)
计算机科学中,字典又称符号表(symbol table)、关联数组(Associative Array)或映射(Map),是一种用于保存键值对(key-value pair)的抽象的数据结构。
字典经常作为一种数据结构内置在很多的高级编程语言里,如C++,但Redis所使用的C语言并没有内置该数据结构,因此需要构建字典实现。
字典在Redis中的应用非常广泛,如Redis的数据库的底层实现就是使用Hash,而对数据库的增删改查亦是构建在对字典的操作之上。除了用来表示数据库外,字典还是哈希的底层实现之一,当一个哈希键包含的键值对比较多,或者键值对中的元素都是比较长的字符串时,就会使用字典作为哈希键的底层实现。
跳跃表
《算法:C语言实现》中跳跃表的定义是:跳跃表(skiplist)是一种有序链表,其中每个节点包含不定数量的链接,节点中的第i个链接构成的单向链表跳过含有少于i个链接的节点。实现了节点的快速访问。
Redis只在两个地方使用到了跳跃表:实现有序集合(Sorted Set);在集群节点中用作内部数据结构。
整数集合
整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis便使用整数集合作为集合键的底层实现。整数集合(inset)实现了有序、无重复地保存多个整数值。
压缩列表
压缩列表(ziplist)是Redis为了节约内存而设计的特殊编码双端链表。压缩列表(ziplist)可以存储字符串和整数,且整数的实际保存形式是整数,不是字符数组。
压缩列表(ziplist)是列表和哈希的底层实现之一。当列表键中只包含少量的列表项或哈希键只包含少量的键值对,且每个列表项或哈希键除了是小整数值就是短字符串时,Redis就使用压缩列表来做列表键或哈希键的底层实现。
Redis使用场景
Redis 设计之初是用来作为内存数据库,但是也被用作缓存、消息队列、分布式锁。
将Redis作为缓存
使用Redis作为数据库缓存时,需要处理读写两种场景:
读取:
(1) 先尝试从Redis中读取(get),如果数据存在,则直接返回数据;
(2) 如果数据不存在(未命中),则读取数据库(db),并将db的数据写入(set)到Redis
写入:
(1) 删除(delete)Redis存储数据;
(2) 将数据写入数据库
在写入的过程中,之所以先删除,是为了防止写入数据库成功,但Redis存储数据未删除如网络原因,导致两个过程不能都执行),从而导致数据库数据和缓存数据不一致的问题。而使用这种方式(先删除缓存再写入数据库),则不会出现这种问题。
缓存穿透、缓存雪崩、缓存击穿
(1) 缓存穿透
缓存穿透,是指查询一个数据库一定不存在的数据。这样,请求每次都会访问数据库。
正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
例如,传入一个数据库没有存储的数据,那么每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就可以利用这个漏洞,对数据库造成压力,甚至压垮数据库。
解决方案:
(a) 缓存空值
采用缓存空值的方式,也就是说,如果从数据库查询的对象为空,也放入缓存。
空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
(b) 布隆过滤器拦截
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为 O(n),O(log n),O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
(2) 缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,是因为大多数缓存数据的过期时间一致,当时间到达时,如果再次大量请求这些数据,则必须请求数据库。
解决方案:
(a)缓存时间增加随机值
对于“因缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”的情况,一种常见的解决策略是在缓存数据时,给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
Redis节点宕机引起的雪崩:
数据集中过期不是非常致命,比较致命的是缓存服务器某个节点宕机或断网。因为缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。对于“Redis挂掉了,请求全部走数据库”这种情况,可以有以下的思路:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:Redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
(3) 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
使用互斥锁
如mutex或synchronized关键字修饰的同步代码块(客户端)
使用分布式锁
将Redis作为数据库
使用Redis的hash类型可以表示关系数据库的表。–不适合复杂查询场景
Redis还可以用作存储(storage)。将Redis用作存储时,充分利用了内存数据库高效的读写性能。由于内存价格相对硬盘或SSD的价格差距仍然很大,完全使用Redis这种内存数据库存储数据仍不是很现实,目前大多数企业会将那些对读写性能要求较高的需求,且单条记录的尺寸不是很大的数据存储到Redis中,并根据应用场景选择合适的持久化策略。与缓存场景不同的是:使用Redis做存储时,数据可以不持久化到磁盘,而使用Redis做存储,必须将数据持久化到磁盘(保证数据掉电不丢失)。
将Redis作为消息队列
Redis使用列表类型可以实现消息队列。使用Redis的lpush + brpop命令组合实现阻塞队列,生产者客户端使用lpush从列表左侧插入元素,多个消费者客户端使用brpop阻塞式“抢”列表尾部元素。
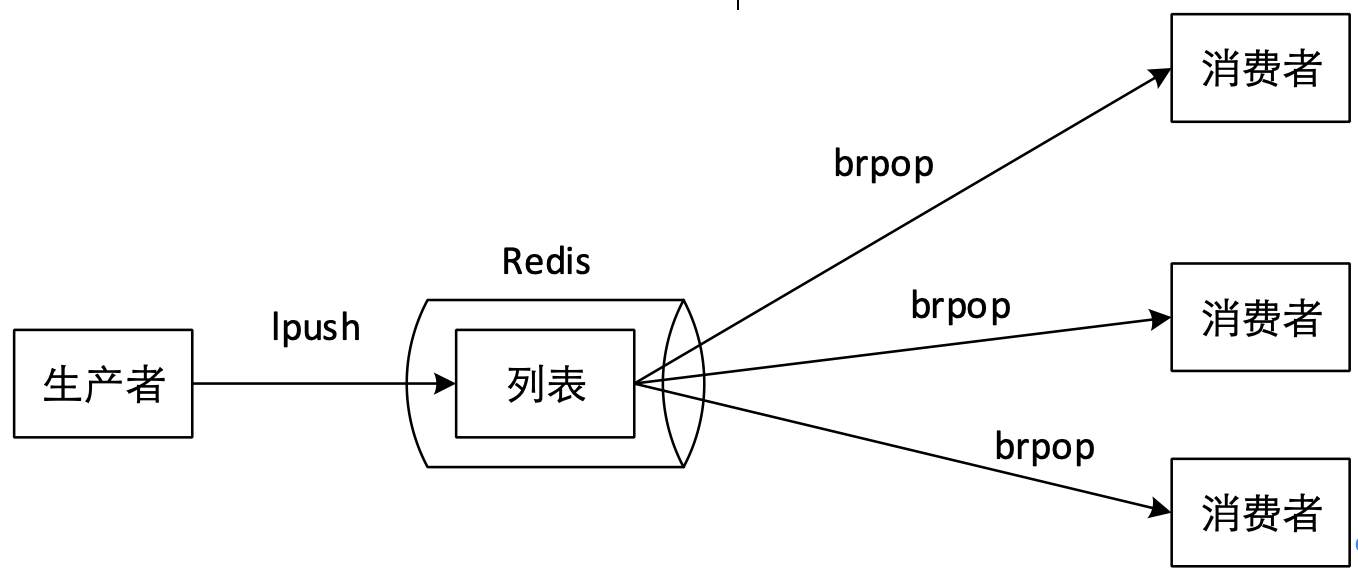
将Redis作为分布式锁
分布式锁是控制分布式系统或不同系统之间共同访问同一资源的一种锁实现,如果不同的系统或同一个系统的不同主机之间共享了某个资源时,往往需要互斥来防止彼此干扰保证一致性。(多个系统间对共享资源的访问一致性)
在分布式场景(如一个服务存在多个实例)下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX (Set if not exists)命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
为什么要用 Redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例(集群模式)的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 Redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 Redis 或 memcached服务的高可用,整个程序架构上较为复杂。
本地缓存和分布式缓存的关系,可类比局部变量、全局变量,本地缓存相当于局部变量,而分布式缓存想短语全局变量。
Redis持久化
Redis提供两种持久化模式。RDB和AOF。
RDB
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
RDB持久化具有以下优点:
1、只有一个文件 dump.rdb,方便持久化。
2、容灾性好,一个文件可以保存到安全的磁盘。
3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis 的高性能。
4、相对于数据集大时,比 AOF 的启动效率更高。
同时,RDB持久化也有以下缺点:
1、数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 Redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
AOF
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
AOF持久化具有以下优点:
1、数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
2、通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
3、AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
同时,AOF持久化也有以下缺点:
1、AOF 文件比 RDB 文件大,且恢复速度慢。
2、数据集大的时候,比 rdb 启动效率低。
AOF的同步频率依赖 redis.conf 中的 appendfsync 配置。具体有以下三种值可选:
(1) always:每一次系统 serverCorn 函数调用就刷新一次缓存区。
(2) everysec:每秒执行一次磁盘写入,期间所有的命令都会存储在 AOF 缓存区。
(3) no:不做控制,任由操作系统决定什么时候刷新缓冲区。
RDB和AOF的选择
RDB和AOF并不是二选一,可以根据业务需要,选择合适的持久化方式。如果需要对数据进行备份,且期望能快速恢复,可以使用RDB持久化。如果不能容忍数据丢失,且不要求数据恢复速度,可以使用AOF持久化。
过期键删除策略
常见的数据库过期键的删除策略有三种:定时删除、惰性删除、定期删除。
定时删除
在设置键的过期时间时,创建一个定时器。当定时器触发执行时,执行对该键的删除操作。(为键设置过期时间的同时,创建定时器,定时器执行时,删除该键。Redis时间事件使用列表存储,时间复杂度是O(n),执行效率低)
惰性删除
放任键不管,但每次从键空间读取键时,检查取得的键是否过期,如果过期,就删除该键,此时不会返回该键;如果没有过期就返回该键。(读取键时,如果已经过期,则删除)
定期删除
每隔一段时间,程序就对数据库进行一次检查,主动删除其中的过期键。(定期检测,主动删除过期键)
Redis过期键删除策略选择
Redis采用的过期键删除策略是惰性删除策略和定期删除策略。Redis之所以选用这两种过期键删除策略是因为:
定时删除虽然对内存友好:定时删除策略保证过期键尽快被删除,并使用其占用的内存空间,但是这种删除策略对CPU极其不友好:过期键数量较多情况下,删除过期键会占用一部分CPU时间,在CPU紧张情况下会对服务器的响应时间和吞吐量造成影响。特别的,Redis使用无序列表存储时间事件,其查找复杂度是O(N),其执行效率较低。所以Redis没有选择这种删除策略。
惰性删除对CPU友好:只在读取该键时才对键进行过期检查,从而保证CPU时间不会被浪费。但这种策略对内存不友好:对于一个已过期的键,如果在很长的一段时间内都不被读取,则该过期键占用的内存也不会被释放。对于大内存Redis来说,这个特性还是可以容忍。由于还采用定期删除机制可以有效弥补惰性删除策略的缺点,所以Redis还是选用了惰性删除策略。
定期删除是定时删除和惰性删除的一种折中。定期删除会定期执行一次过期键删除操作,并通过限制删除操作执行的时长和频率来减少其对CPU时间的影响。定期删除策略的难点是确定删除操作执行的时长和频率。合理的设置删除操作执行时长和频率可以避免CPU的过多消耗(删除操作执行频率过搞,退化成定时删除操作)和内存的不必要的浪费(删除操作执行频率过低,退化成惰性删除操作)。
注意:定期删除并不是一次运行就检查所有的库,所有的键,而是随机检查一定数量的键。
定期删除函数的运行频率,在Redis2.6版本中,规定每秒运行10次,大概100ms运行一次。在Redis2.8版本后,可以通过修改配置文件Redis.conf 的 hz 选项来调整这个次数。(每秒执行的次数)
内存不足时,Redis的内存淘汰策略有哪些
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。根据被淘汰的数据所属的键空间,可以将内存淘汰策略分为两类:(1) 全局的键空间选择性移除;(2)设置过期时间的键空间选择性移除。
全局的键空间选择性移除
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(拒绝策略)
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的,lru)
allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。(频率最低)
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。(random)
设置过期时间的键空间选择性移除
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
Redis内存淘汰策略总结
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
Redis事务
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。总结说:Redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis事务的三个阶段
事务开始 MULTI、命令入队、事务执行 EXEC。
事务执行过程中,如果服务端收到有EXEC、DISCARD、WATCH、MULTI之外的请求,将会把请求放入队列中排队(排队等候)。
Redis事务相关命令
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的。Redis会将一个事务中的所有命令序列化,然后按顺序执行。
(1) Redis 不支持回滚,“Redis 在事务失败时不进行回滚,而是继续执行余下的命令”,所以 Redis 的内部可以保持简单且快速。
(2) 如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
(3) 如果在一个事务中出现运行错误,那么正确的命令会被执行。
WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
MULTI命令用于开启一个事务,它总是返回OK。 MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。 当操作被打断时,返回空值 nil 。
通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。
UNWATCH命令可以取消watch对所有key的监控
Redis事务实现程度
Redis的事务总是具有ACID中的一致性和隔离性,其他特性是不支持的。当服务器运行在AOF持久化模式下,并且appendfsync选项的值为always时,事务也具持久性。
Redis 在命令执行时是单线程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis事务是总是带有隔离性的。
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
Redis事务其他实现
基于Lua脚本,Redis可以保证脚本内的命令一次性、按顺序地执行,其同时也不提供事务运行错误的回滚,执行过程中如果部分命令运行错误,剩下的命令还是会继续运行完。
基于中间标记变量,通过另外的标记变量来标识事务是否执行完成,读取数据时先读取该标记变量判断是否事务执行完成。但这样会需要额外写代码实现,比较繁琐。
Redis Pipeline
管道(Pipeline)可以一次性发送多条命令给服务端,服务端依次处理完完毕后,通过一条响应一次性将结果返回,Pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。
注意,Pipeline是非原子性,如果执行中间某一个指令发生异常,将会继续执行后续的命令。如果需要保证原子性,可以使用Redis提供的事务能力。同时,Pipeline无法保证时序性。Pipeline中的命令发送到服务器端时,尽管命令是使用队列的方式实现的,但是命令中间可能会穿插其他客户端发送来的命令。此外,使用Pipe组装命令时,数量不能太多,且要考虑可能引入的性能问题。
Redis 复制
Redis支持主从复制,复制的实现原理后续补充。
Redis与Lua脚本
Redis客户端可以使用Lua脚本实现命令的组合,以实现特定的业务。如基于Redission实现的分布式锁就是基于Lua脚本实现。
Redis分布式
Redis分布式是一个很大的话题,这里不再展开学习,有兴趣的同学可以自行学习。 常见的话题有:Redis集群如何分片、如何处理节点失效、如何迁移数据、如何选主、如何通信、如何实现一致性hash等等。
Redis高可用
Redis提供多种高可用方案,具体来说有:主从模式、哨兵模式、集群模式。 各个模式的实现这里不再展开,有兴趣的同学可以自行学习。
Redis 使用优化
慢查询
Redis 可以记录执行时间超过某个阈值的命令,这个阈值由参数 slowlog-log-slower-than 控制,单位是微秒,默认值 10000。
Redis 底层是使用列表来存储慢查询日志,slowlog-max-len 就是列表的最大长度。当慢查询数达到该参数配置的值时,如果继续有新增的慢查询,则最早插入的慢查询会被删除。
可以使用slowlog get命令获取所有的慢查询命令,使用slowlog len命令获取慢查询日志的个数。
获取了慢查询记录后,接下来就是分析之所以慢的原因。常见的情况有:命令使用不当(如使用了Redis种高危命令,导致读写性能较差,如keys命令)、设计不合理(提供更优的算法)等等。
处理bigkey
bigkey通常都会以数据大小与成员数量来判定,并没有统一的标准。举例来说,以下情况可以被认定为bigkey:
一个STRING类型的Key,它的值为5MB(数据过大)
一个LIST类型的Key,它的列表数量为20000个(列表数量过多)
一个ZSET类型的Key,它的成员数量为10000个(成员数量过多)
一个HASH格式的Key,它的成员数量虽然只有1000个但这些成员的value总大小为100MB(成员体积过大)
需要说明的是,上面的数值只是一个参考值,不同的业务场景因业务需要,其值大小有差异。
bigkey带来以下问题:
(1) bigkey关联的数据读写性能变慢。
(2) 内存不断变大引发OOM,或达到maxmemory设置值引发写阻塞或重要Key被淘汰。
(3) 删除一个bigKey造成主库较长时间的阻塞并引发同步中断或主从切换。
产生bigkey,主要是由业务规划不合理、无效的数据堆积、访问突增等问题导致。举例来说:
(1) 将Redis用在并不适合其能力的场景,造成Key的value过大,如使用String类型的Key存放大体积二进制文件型数据(大Key);
(2) 业务上线前规划设计考虑不足没有对Key中的成员进行合理的拆分,造成个别Key中的成员数量过多(大Key);
(3) 没有对无效数据进行定期清理,造成如HASH类型Key中的成员持续不断的增加(大Key);
(4) 使用LIST类型Key的业务消费侧代码故障,造成对应Key的成员只增不减(大Key);
解决bigkey问题,首先要定位出bigkey。常见的定位手段有:
(1) 针对不同的数据结构,选用其高效的命令。具体如下:
| 数据结构 | 命令 | 时间复杂度 | 返回结果 |
|---|---|---|---|
| String | STRLEN | O(1) | 对应key的value的字节数 |
| Hash | HLEN | O(1) | 对应Key的成员数量 |
| Set | SCARD | O(1) | 对应Key的成员数量 |
| Zset | ZCARD | O(1) | 对应Key的成员数量 |
| List | LLEN | O(1) | 对应Key的列表长度 |
注意,在定位bigkey时,一定不要使用可能引起阻塞的分析命令,如MEMORY USAGE命令、MONITOR命令等。
(2) 使用开源工具发现bigkey。
如果希望按照自己的标准精确的分析一个Redis实例中所有Key的真实内存占用并避免影响线上服务,redis-rdb-tools是非常好的选择。
(3) 依靠公有云的Redis分析服务发现大Key及热Key。
如果期望能够实时的对Redis实例中的所有Key进行分析并发现当前存在的大Key及热Key、了解Redis在运行时间线中曾出现过哪些大Key热Key,使自己对整个Redis实例的运行状态有一个全面而又准确的判断,那么公有云的Redis控制台将能满足这个需求。
定位出bigkey后,接下来就是处理bigkey,常见的处理方法有:
(1) 对大Key进行拆分
如将一个含有数万成员的HASH Key拆分为多个HASH Key,并确保每个Key的成员数量在合理范围。
(2) 对大Key进行清理
将不适合Redis能力的数据存放至其它存储,并在Redis中删除此类数据。需要注意的是,一个过大的Key删除可能引发Redis集群同步的中断,Redis自4.0起提供了UNLINK命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的Key,通过UNLINK,可以安全的删除大Key甚至特大Key。
(3) 时刻监控Redis的内存水位
可以通过监控系统并设置合理的Redis内存报警阈值来提醒此时可能有大Key正在产生,如:Redis内存使用率超过70%,Redis内存1小时内增长率超过20%等。
通过此类监控手段可以在问题发生前解决问题,如:LIST的消费程序故障造成对应Key的列表数量持续增长,将告警转变为预警从而避免故障的发生。
(4) 对失效数据进行定期清理
例如在HASH结构中以增量的形式不断写入大量数据而忽略了这些数据的时效性,这些大量堆积的失效数据会造成大Key的产生,可以通过定时任务的方式对失效数据进行清理。在此类场景中,建议使用HSCAN并配合HDEL对失效数据进行清理,这种方式能够在不阻塞的前提下清理无效数据。
处理hotkey
hotkey是以其接收到的请求频率、数量来判定,并没有统一的标准。示例如下:
某Redis实例的每秒总访问量为10000,而其中一个Key的每秒访问量达到了7000(访问次数显著高于其它Key)
对一个拥有上千个成员且总大小为1MB的HASH Key每秒发送大量的HGETALL(带宽占用显著高于其它Key)
对一个拥有数万个成员的ZSET Key每秒发送大量的ZRANGE(CPU时间占用显著高于其它Key)
hotkey带来以下问题:
(1) 占用大量的Redis CPU时间使其性能变差并影响其它请求;
(2) 对hotkey的请求量过大超出Redis处理能力造成问题;
(3) 请求压力数量超出Redis的承受能力造成缓存击穿,此时大量强求将直接指向后端存储将其打挂并影响到其它业务;
产生hotkey,zhu8yao是由预期外的访问量陡增(热Key)导致。
解决hotkey问题,首先要定位出hotkey。常见的定位手段有:
(1) 使用Redis内置的命令发现hotkey。
redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢,且会对服务器造成一定的压力,谨慎使用。
注意,在定位hotkey时,一定不要使用可能引起阻塞的分析命令,如MONITOR命令等。
(2) 使用工具发现hotkey。
针对hotkey,可以借助工具发现,如内源的监控工具或开源的监控工具。
(3) 依靠公有云的Redis分析服务发现hotKey。
如果期望能够实时的对Redis实例中的所有Key进行分析并发现当前存在的hotkey、了解Redis在运行时间线中曾出现过哪些hotkey,使自己对整个Redis实例的运行状态有一个全面而又准确的判断,那么公有云的Redis控制台将能满足这个需求。
定位出hotkey后,接下来就是处理hotkey,常见的处理方法有:
(1) 使用本地缓存
在发现热key以后,可以考虑把hotkey放到本地缓存。使用本地缓存,不仅可以减少与Redis交互次数,也能降低Redis的请求压力。但是,这只适用于数据量不大的场景。
(2) 备份hotkey
针对hotkey,还可以考虑让hotkey分散到多个实例上。比如可以把这个key,在多个redis上存储。接下来,有热key请求进来的时候,就在有备份的redis上随机选取一台,进行访问取值,返回数据。这种方式会带来多个副本的一致性问题。或者使用集群模式,然后加上随机数,将数据分开存储。
(3) 使用读写分离架构
如果hotkey的产生来自于读请求,那么读写分离是一个很好的解决方案。在使用读写分离架构时可以通过不断的增加从节点来降低每个Redis实例中的读请求压力。
然而,读写分离架构在业务代码复杂度增加的同时,同样带来了Redis集群架构复杂度的增加:不仅要为多个从节点提供转发层(如Proxy,LVS等)来实现负载均衡,还要考虑从节点数量显著增加后带来的故障率增加的问题,Redis集群架构变更的同时为监控、运维、故障处理带来了更大的挑战。
但是,读写分离架构同样存在缺点,在请求量极大的场景下,读写分离架构会产生不可避免的延迟,此时会有读取到脏数据的问题,因此,在读写压力都较大写对数据一致性要求很高的场景下,读写分离架构并不合适。
(4) 时刻监控Redis的hotkey
可以通过监控系统并设置合理的Redis报警阈值来提醒此时可能有hotkey正在产生,如:某个key近5min中连续被访问50000次+等。
通过此类监控手段可以在问题发生前识别出问题,并尽早采取应对措施。
Redis 多线程
Redis 6.0支持多线程。之所以支持多线程,主要还是进一步优化Redis的性能。因为多线程有人如下好处:
(1) 可以充分利用服务器 CPU 资源。
(2) 多线程任务可以分摊 Redis 同步 IO 读写负荷。
需要说明的是,Redis 6.0 的多线程功能默认是禁用的。如需开启需要修改 redis.conf 配置文件中的 io-threads-do-reads yes。并设置线程数,否则是不生效的。修改 redis.conf 文件中的 io-threads 的配置。
关于线程数的设置,官方有一个建议:4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为 6 个线程,线程数一定要小于机器核数。
此外,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以不需要去考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
参考
https://www.Redis.com.cn/Redis-interview-questions.html Redis面试题
https://www.cnblogs.com/extjs4/p/14433962.html Redis面试题
https://www.jianshu.com/p/6c970eb652d5 Redis架构原理及应用实践
https://www.jianshu.com/p/21110d3130bc Redis 分布式高可用终极指南
https://cloud.tencent.com/developer/article/1497348 SpringBoot-Redis 实现分布式锁
https://cloud.tencent.com/developer/article/1444057 Redis集群模式的工作原理
https://thinkwon.blog.csdn.net/article/details/103522351 Redis面试题
https://blog.csdn.net/adminpd/article/details/122934938 Redis面试题总结
https://developer.aliyun.com/article/773205 布隆过滤器,这一篇给你讲的明明白白
https://www.cnblogs.com/ysocean/p/12422635.html Redis详解(十一)------ 过期删除策略和内存淘汰策略
https://zhuanlan.zhihu.com/p/134049112 一篇文章快速搞懂Redis的慢查询分析
https://zhuanlan.zhihu.com/p/404095378 一文详解 Redis 中 BigKey、HotKey 的发现与处理
https://www.cnblogs.com/rjzheng/p/10874537.html 【原创】谈谈redis的热key问题如何解决
https://juejin.cn/post/6844904127001001991 Redis Pipeline介绍及应用










![2023年中国超硬材料制品分析及超硬刀具市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/c6b209830e68c87b18ab77b174bc6a9a.png)