目录
- 0 专栏介绍
- 1 动态障碍建模
- 2 DWA基本原理
- 2.1 采样窗口
- 2.2 评价函数
- 3 DWA算法流程
- 4 仿真实现
- 4.1 ROS C++实现
- 4.2 Python实现
- 4.3 Matlab实现
0 专栏介绍
🔥附C++/Python/Matlab全套代码🔥课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。
🚀详情:图解自动驾驶中的运动规划(Motion Planning),附几十种规划算法
1 动态障碍建模
室内移动机器人研究的最终目标之一是构建能够在危险和人口密集的环境中安全执行任务的机器人。例如,协助人类在室内办公环境中的服务机器人应能够对意外变化做出快速反应,并在各种外部情况下完成其任务。然而,大多数运动规划器依赖于对环境的准确、静态建模,因此如果人类或其他不可预测的障碍物阻挡了它们的路径,它们往往会停止工作。为了构建自主移动机器人,我们需要构建能够感知环境、对不可预见的情况做出反应并进行动态规划以完成任务的系统
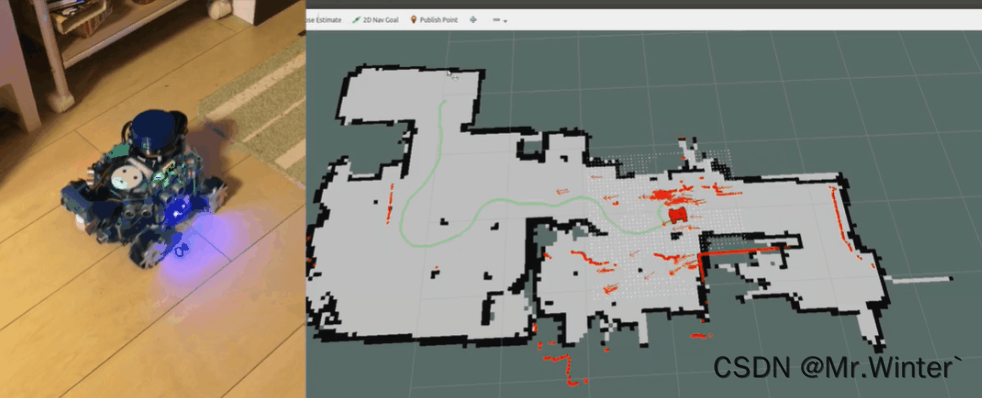
动态窗口算法(Dynamic Window Approach)应运而生,它是一种在机器人路径规划和导航领域中广泛应用的算法,应用背景可以追溯到无人驾驶车辆、自主移动机器人和其他智能系统需要在复杂环境中高效运动的情况。DWA通过将机器人的运动状态和环境信息建模为一个动态窗口,来实现快速的路径规划和避碰决策。该算法通过评估当前机器人状态下可能的速度和方向组合,利用启发式方法选择最佳动作,以避免与障碍物发生碰撞并尽快到达目标点。
2 DWA基本原理
2.1 采样窗口
DWA关注一个问题
如何对静态/动态障碍物进行反应性避碰?
DWA特别设计用于处理由有限速度和加速度所施加的约束,这些约束直接从移动机器人的运动学模型导出。简言之,DWA仅在计算下一个控制指令时周期性地考虑一个短时间间隔,以避免处理一般运动规划问题所带来的巨大复杂性。在这样的时间间隔内,通过将轨迹近似为圆曲率,得到了一个二维搜索空间,包括平移和旋转速度。此搜索空间被缩小到允许机器人安全停止的合法速度。由于有限加速度,速度受到进一步的限制:机器人只考虑在下一个时间间隔内可以到达的速度。这些速度形成了动态窗口,其在速度空间中围绕机器人当前速度中心。
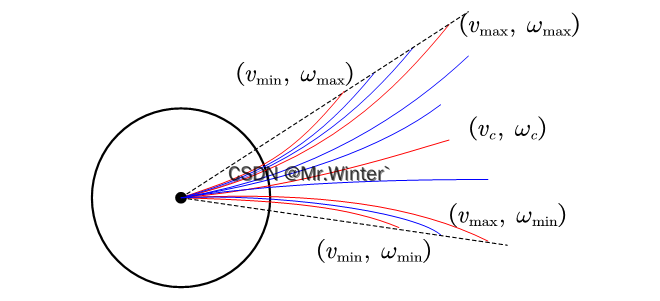
在DWA中,构造如下的采样窗口
{ w i n ( v ) = [ max { v min , v − a v d t } , min { v max , v + a v d t } ] w i n ( ω ) = [ max { ω min , ω − a ω d t } , min { ω max , ω + a ω d t } ] \begin{cases} win\left( v \right) =\left[ \max \left\{ v_{\min},v-a_v\mathrm{d}t \right\} , \min \left\{ v_{\max}, v+a_v\mathrm{d}t \right\} \right]\\ win\left( \omega \right) =\left[ \max \left\{ \omega _{\min},\omega -a_{\omega}\mathrm{d}t \right\} , \min \left\{ \omega _{\max}, \omega +a_{\omega}\mathrm{d}t \right\} \right]\\\end{cases} {win(v)=[max{vmin,v−avdt},min{vmax,v+avdt}]win(ω)=[max{ωmin,ω−aωdt},min{ωmax,ω+aωdt}]
2.2 评价函数
接着在窗口内采样二元点对 ( v , ω ) \left( v,\omega \right) (v,ω),设置仿真时间 t t t,模拟出机器人从当前位置开始以 ( v , ω ) \left( v,\omega \right) (v,ω)恒速行进的轨迹,并对轨迹进行评价
G ( v , ω ) = α ⋅ h e a d i n g ( v , ω ) + β ⋅ d i s t ( v , ω ) + γ ⋅ v e l o c i t y ( v , ω ) G\left( v,\omega \right) =\alpha \cdot \mathrm{heading}\left( v,\omega \right) +\beta \cdot \mathrm{dist}\left( v,\omega \right) +\gamma \cdot \mathrm{velocity}\left( v,\omega \right) G(v,ω)=α⋅heading(v,ω)+β⋅dist(v,ω)+γ⋅velocity(v,ω)
其中方向角评价函数
h e a d i n g ( v , ω ) = π − ∣ θ g o a l − θ ∗ ∣ \mathrm{heading}\left( v,\omega \right) =\pi -\left| \theta _{\mathrm{goal}}-\theta ^* \right| heading(v,ω)=π−∣θgoal−θ∗∣
其中 θ g o a l \theta _{\mathrm{goal}} θgoal是机器人在模拟轨迹末端和终点连线与 x x x轴的夹角, θ ∗ \theta ^* θ∗是机器人在模拟轨迹末端的姿态角,旨在选出目标角度与指向角度间差值较小的轨迹,使机器人的前进方向对准终点。障碍物评价函数
d i s t ( v , ω ) = { d 0 , d > d 0 d , d s a f e ⩽ d ⩽ d 0 0 , d < d s a f e \mathrm{dist}\left( v,\omega \right) =\begin{cases} d_0\,\,, d>d_0\\ d\,\, , d_{\mathrm{safe}}\leqslant d\leqslant d_0\\ 0 , d<d_{\mathrm{safe}}\\\end{cases} dist(v,ω)=⎩ ⎨ ⎧d0,d>d0d,dsafe⩽d⩽d00,d<dsafe
旨在选出与障碍物距离较远的轨迹,避免机器人运行过程中发生碰撞, d d d表示预测轨迹与障碍物的最近距离; d 0 d_0 d0为障碍物评分最大值,若预测轨迹与障碍物间距超过 d 0 d_0 d0则认为该轨迹安全; d s a f e d_{\mathrm{safe}} dsafe是机器人与障碍的安全间距,若预测轨迹与障碍物间距小于 d s a f e d_{\mathrm{safe}} dsafe则认为该轨迹发生碰撞。速度评价函数
v e l o c i t y ( v , ω ) = ∣ v ∣ \mathrm{velocity}\left( v,\omega \right) =\left| v \right| velocity(v,ω)=∣v∣
旨在选出线速度较大的轨迹,使机器人的运动速度尽量快。综上所述,评价函数的物理意义是使机器人以较快的速度朝着目标运动并进行自主避障,实际应用中可根据需要改变评价函数及其权重系数
3 DWA算法流程
DWA算法流程如下所示

4 仿真实现
4.1 ROS C++实现
构造动态窗口
generator_.initialise(pos,
vel,
goal,
&limits,
vsamples_);
在这个函数内部构造了采样窗口
max_vel[0] = std::min(max_vel_x, vel[0] + acc_lim[0] * sim_period_);
max_vel[1] = std::min(max_vel_y, vel[1] + acc_lim[1] * sim_period_);
max_vel[2] = std::min(max_vel_th, vel[2] + acc_lim[2] * sim_period_);
min_vel[0] = std::max(min_vel_x, vel[0] - acc_lim[0] * sim_period_);
min_vel[1] = std::max(min_vel_y, vel[1] - acc_lim[1] * sim_period_);
min_vel[2] = std::max(min_vel_th, vel[2] - acc_lim[2] * sim_period_);
再通过迭代器
VelocityIterator x_it(min_vel[0], max_vel[0], vsamples[0]);
VelocityIterator y_it(min_vel[1], max_vel[1], vsamples[1]);
VelocityIterator th_it(min_vel[2], max_vel[2], vsamples[2]);
遍历所有可能的速度组合,存入sample_params_中,生成最优轨迹
std::vector<base_local_planner::Trajectory> all_explored;
scored_sampling_planner_.findBestTrajectory(result_traj_, &all_explored);
在findBestTrajectory中主要分为两步:
- 轨迹生成
这里的gen_->nextTrajectory(loop_traj);gen_会通过已构造的sample_params_遍历所有可能的速度组合,通过其generateTrajectory()函数生成轨迹返回 - 轨迹评价
这里实际上调用代价函数栈对轨迹进行逐一评价loop_traj_cost = scoreTrajectory(loop_traj, best_traj_cost);
而这些代价函数可以自定义,它们已经在上一步完成了更新。for (std::vector<TrajectoryCostFunction *>::iterator score_function = critics_.begin(); score_function != critics_.end(); ++score_function) { TrajectoryCostFunction *score_function_p = *score_function; double cost = score_function_p->scoreTrajectory(traj); ... }
最后选择代价最小的轨迹返回即可。
4.2 Python实现
核心代码如下所示
def evaluation(self, vr):
v_start, v_end, w_start, w_end = vr
v = np.linspace(v_start, v_end, num=int((v_end - v_start) / self.robot.V_RESOLUTION)).tolist()
w = np.linspace(w_start, w_end, num=int((w_end - w_start) / self.robot.W_RESOLUTION)).tolist()
eval_win, traj_win = [], []
for v_, w_ in product(v, w):
# trajectory prediction, consistent of poses
traj = self.generateTraj(v_, w_)
end_state = traj[-1].squeeze().tolist()
# heading evaluation
theta = self.angle((end_state[0], end_state[1]), self.goal)
heading = np.pi - abs(end_state[2] - theta)
# obstacle evaluation
dist_vector = np.array(tuple(self.obstacles)) - np.array([end_state[0], end_state[1]])
dist_vector = np.sqrt(np.sum(dist_vector**2, axis=1))
distance = np.min(dist_vector)
if distance > self.eval_param["R"]:
distance = self.eval_param["R"]
# velocity evaluation
velocity = abs(v_)
# braking evaluation
dist_stop = v_ * v_ / (2 * self.robot.V_ACC)
# collision check
if distance > dist_stop and distance >= 1:
eval_win.append((v_, w_, heading, distance, velocity))
traj_win.append(traj)
...
# evaluation
factor = np.array([[1, 0, 0],
[0, 1, 0],
[0, 0, self.eval_param["heading"]],
[0, 0, self.eval_param["distance"]],
[0, 0, self.eval_param["velocity"]]])
return eval_win @ factor, traj_win
4.3 Matlab实现
核心代码如下所示
function [eval_win, traj_win] = evaluation(robot, vr, goal, obstacle, kinematic, eval_param)
eval_win = []; traj_win = [];
for v = vr(1):kinematic.V_RESOLUTION:vr(2)
for w=vr(3):kinematic.W_RESOLUTION:vr(4)
% trajectory prediction, consistent of poses
[robot_star, traj] = generate_traj(robot, v, w, eval_param(4), eval_param(5));
% heading evaluation
theta = angle([robot_star.x, robot_star.y], goal(1:2));
heading = pi - abs(robot_star.theta - theta);
% obstacle evaluation
dist_vector = dist(obstacle, [robot_star.x; robot_star.y]);
distance = min(dist_vector);
if distance > eval_param(6)
distance = eval_param(6);
end
% velocity evaluation
velocity = abs(v);
% braking evaluation
dist_stop = v * v / (2 * kinematic.V_ACC);
% collision check
if distance > dist_stop && distance >= 1
eval_win = [eval_win; [v w heading distance velocity]];
traj_win = [traj_win; traj];
end
end
end
% normalization
...
eval_win = [eval_win(:, 1:2), eval_win(:, 3:5) * eval_param(1:3)'];
end

完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …