GO-SLAM
位姿估计效果很好,有高效的回环检测和 full BA(每个关键帧),适用于单目、双目和 RGB-D。
一、简介
消费级深度传感器容易产生噪声,这就导致 RGB-D SLAM 会丢失一些几何细节,导致过度平滑。使用轻量级的相机传感器是一种趋势,然而,它们的 representations(点云、曲面、volume)在形状提取时缺乏灵活性,重建的准确度就会下降。
基于 NeRF 的视觉 SLAM 可以在小尺度场景中实现精确的三维重建和相机位姿估计。然而目前的工作由于缺乏全局在线优化,如 loop closure 和 全局 BA,会导致随着帧数的增加,相机偏移误差累积,三维重建会迅速崩溃。
GO-SLAM 就是完善这些工作的。
二、相关
Online 3D Reconstruction and SLAM
采用离散和有限的表征(基于点、面或体素),会出现位姿误差累积和重建失真。DROID-SLAM 使用神经网络来利用图像中更丰富的环境信息,但它仅在离线状态下,即在跟踪结束时执行全局 BA。但是在线 BA 对于即时漂移校正很重要。
NeRF-based Visual SLAM
在视觉 SLAM 中使用神经隐式表征实现了更好的场景完整性,特别是对于未观察到的区域,而且还能以任意分辨率进行连续三维建模。像代表性的 iMAP等适用于 RGB-D 环境,还有一些工作移除了深度传感器,Orbeez-slam 使用 ORB-SLAM2 进行准确的位姿估计,但没有 LC 和 full BA。
三、方法
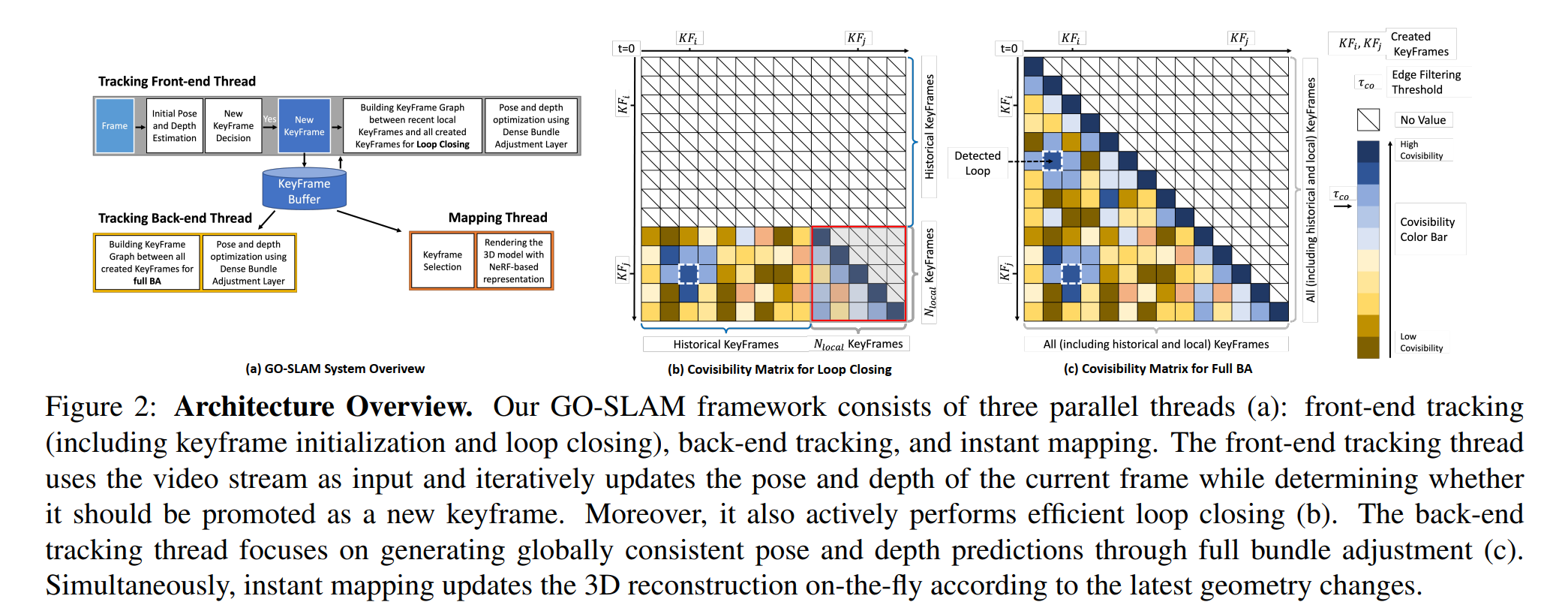
3.1. Tracking with Global Optimization
GO-SLAM 在前端的跟踪中,如果观察到足够的运动,就会初始化一个关键帧,并且引入 LC。后端则进行 full BA。
Front-End Tracking
将单目、双目或 RGB-D 作为输入,并应用基于 RAFT 的循环更新算子计算每个新帧与上一关键帧相比的光流。如果平均光流大于阈值 τ flow,就会创建一个新的关键帧,并将其添加到关键帧缓冲区中。
使用关键帧集来构建关键帧图 (V,E),以执行 LC。计算 N local 关键帧与所有 N KF 关键帧之间大小为 N local × N KF 的共视度矩阵。代码中,共视度是通过关键帧对之间的平均光流来表示的,使用反向投影过滤掉共视度低的关键帧对,即平均光流大于 τ co 的关键帧对。
在 local 关键帧之间,为共视度高或相邻的关键帧对建边。为了避免冗余,一旦关键帧图中添加了边(例如 KFi ↔KFj),就会抑制 i ± r local 与 j ± r local 之间所有可能的边,其中 r local 是表示时间半径的超参数。
回环检测按照共视度从高到低的顺序对边进行采样,并抑制半径为 r loop(= N local / 2,这使得 local 区域和一个重访区域之间只有一个闭合) 的相邻边。要 accept 一个候选循环,需要连续检测三个候选循环,如果它们的平均光流小于 τ co,就会进行验证。除了 local 关键帧内的边外,根据当前 local 区域被重访的次数,关键帧图中还会增加几条额外的循环边。一般来说,图中边的数量与 N local 成线性关系,上限为 N local × N local + 少数闭合。
通过相邻边抑制和共视度过滤,进一步限制了关键帧图中的边的数量,从而进一步保证了整个关键帧图(即整个前端)的优化效率。
之后,使用可微 Dense BA(DBA)来解决成本函数上的非线性最小二乘优化问题,以修正关键帧图中每个关键帧的相机位姿 G∈ SE(3) 和反深度 d:
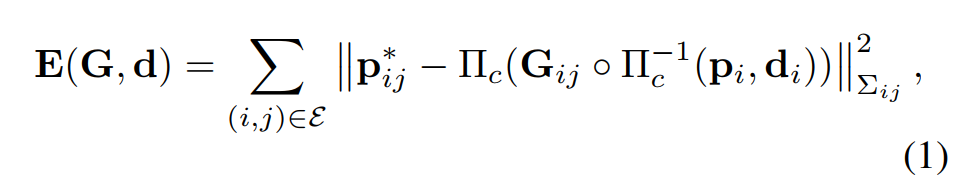
其中,(i,j) ∈ E 表示关键帧图中的任意一条边,Πc 和 Πc- 1 是投影和反投影函数,pi 是关键帧 KFi 的反投影像素位置,Gij 是关键帧 KFi 到 KFj 的位姿变换、pij 和 wij 是预测光流和相关置信度图,Σij = diag wij , ∥·∥Σ 是马哈拉诺比斯距离,根据置信度权重 wij 对误差项进行加权。成本函数允许更新相机位姿和每个像素深度,使其与 RAFT 预测的光流 pij 的兼容性最大化。为了提高效率,只计算与 local 关键帧的深度和位姿相关的雅可比。在计算每次迭代的残差和雅可比后,采用阻尼高斯-牛顿法找出所有 local 关键帧的最佳位姿和深度。
Back-End Tracking
为了解决 full BA 的效率问题,采用在单独的线程中在线运行 full BA,允许系统继续跟踪新帧并进行 LC。与前端跟踪类似,建立一个新的关键帧图,并插入共视度高和时间上相邻的关键帧对。由于最新关键帧的轨迹误差已通过 LC 以全局几何为特征进行了修正,因此降低了对 full BA 的实时性要求。
3.2. Instant Mapping
Keyframe Selection
在每次重建更新开始时,建图线程首先会对所有关键帧的位姿和深度进行快照,以确保一致性。在选择关键帧时,优先选择在优化更新上最相关的关键帧。
首先,确保总是包含最新的两个关键帧和那些没有经过优化的关键帧。然后,将所有关键帧按照当前和上次更新状态之间的位姿差降序排序,并从列表中选择前 10 个关键帧。最后,为了防止遗忘之前的图形,采用分层抽样的方法从所有可用的关键帧中选择 10 个关键帧。
Rendering
与 Instant-NGP 类似,在给定深度 D(由反深度 d 转换而来)、位姿 G 和每个选定关键帧的图像 I 的情况下,随机选择 M 个像素点进行训练。然后沿射线生成 N ray = N strat + N imp 总采样点,其中 N strat 个点使用分层抽样,而 N imp 点在深度值附近选择。对于每个采样点 x,将其映射为多分辨率哈希编码 hΘhash(x),并在哈希表的每个条目中设置可训练的编码参数 Θhash。由于哈希编码 hΘhash(x) 明确存储了每个空间位置的几何和亮度信息,可以使用浅层网络预测 SDF Φ(x) 和颜色 Ω(x)。
SDF 网络 fΘsdf 由一个具有可学习参数 Θsdf 的 MLP 组成,将点位置 x 和相应的哈希编码 hΘhash(x) 作为输入,预测 SDF:
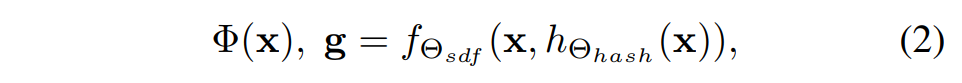
g 是学习到的几何特征向量。
颜色网络 fΘcolor 处理 g、x 和 SDF n 相对于 x 的梯度,预测颜色 Ω(x):
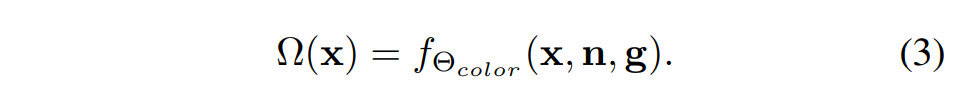
其中,Θcolor 是颜色网络(即双层 MLP)的可学习参数。 每个像素/光线的深度和颜色都是按照 NeuS 的方法通过无偏体积渲染计算得出的。具体来说,对于沿射线的点 xi, i∈ {1, - - - , Nray},给定相机中心 o、视图方向 v 和采样深度 Di,可表示为 xi = o + Di v。同时,该点的无偏终止概率模型为 wi = αi Π(1-αj) (j=1~i-1),其中不透明度值 αi 的计算公式为:
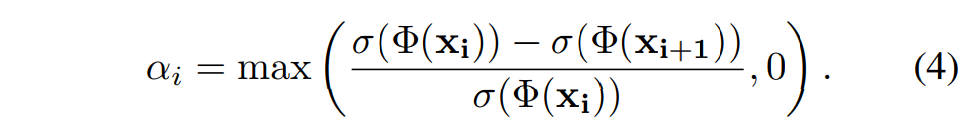
其中,σ 是modulated Sigmoid函数。在权重 w 的作用下,像素颜色 cˆ 和深度 Dˆ 的预测值沿射线累积:
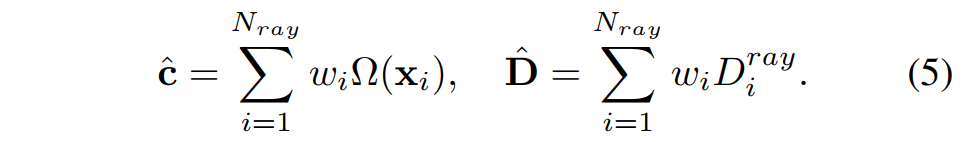
Training Losses
为了优化渲染网络,以关键帧图像 I 和深度 D 为 gt,对选定的 M 个像素施加的 RGB 损失 Lc 和深度损失 Ldep 分别为 :
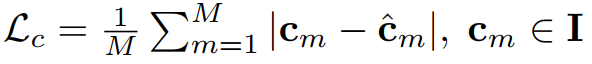
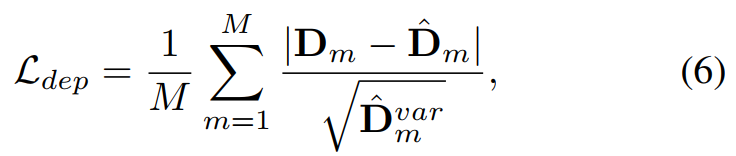
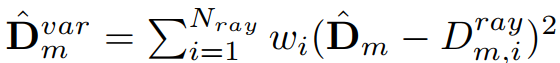
Dˆ var 是预测深度方差,用于降低重建几何中不确定区域的权重。
对预测的 SDF 进行正则化处理。采用 Eikonal 项:
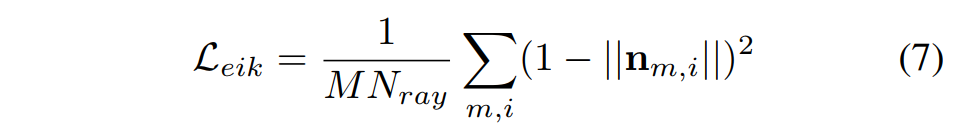
此外,为了监督 SDF 以实现精确重建,通过计算关键帧深度与采样点 xi 的距离来近似得到采样点 xi 的 gt SDF:
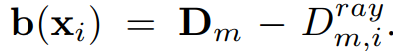
对于 SDF 的学习,有 |Φ(xi)| ≤ |b(xi)|, ∀xi。为了满足这一约束,对于近表面点(|b(xi)| ≤ τ trunc,其中 τ trunc 是一个超参数,表示截断阈值,设置为 16cm),SDF 损失定义为 L near = |Φ(xi) -b(xi)|,而对于其他地方采用宽松损失:
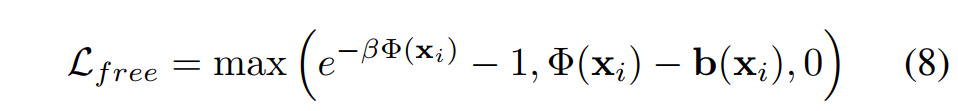
其中,β 是一个超参数,用于在自由空间中预测的 SDF Φ(xi) 为负值时进行惩罚。因此,总的 SDF 损失定义为:
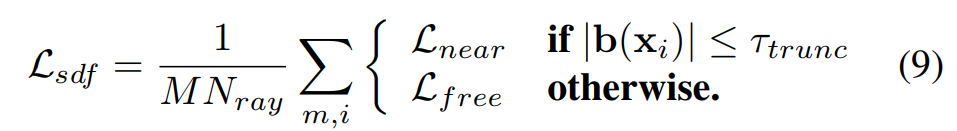
总损失定义为:
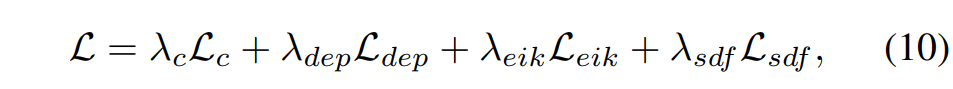
四、实验
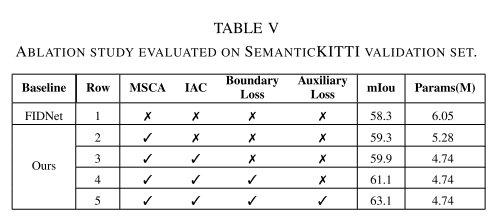
metrics:Absolute Trajectory Error(ATE) RMSE、Accuracy[cm], Completion [cm], Completion Ratio [< 5cm %]、F-score [< 5cm %]
引入 full BA 会降低 GO-SLAM 的速度,但会显著改善全局位姿估计。