文章目录
- Pytorch提供的优化器
- 所有优化器的基类`Optimizer`
- 实际操作
- 实验
- 参考资料
优化器
根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签的工具
学习目标

Pytorch提供的优化器
优化器的库torch.optim
优化器举例:

所有优化器的基类Optimizer
optimizer定义
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
Optimizer属性
defaults:存储优化器的超参数,举个例子
# 使用的超参数包括:学习率lr,动量momentum,阻尼动量抑制项dampening,权重衰减weight_decay,nesterov——bool值,决定是否使用Nesterov动量方法
{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}
state: 参数缓存
# defaultdict类型的参数缓存,存储的是一个tensor键值对,key值为一个需要计算梯度的模型参数,value值为一个momentum_buffer的键值对存储动量缓冲张量
defaultdict(<class 'dict'>, {tensor([[ 0.3864, -0.0131],
[-0.1911, -0.4511]], requires_grad=True):{'momentum_buffer': tensor([[0.0052, 0.0052],
[0.0052, 0.0052]])}})
param_groups: 参数组,一个list,每个元素是一个字典,字典的key值顺序是params,lr,momentum,dampening,weight_decay,nesterov
# 'params'参数对应的是一个存储待优化参数的list
[{'params': [tensor([[-0.1022, -1.6890],[-1.5116, -1.7846]], requires_grad=True)], 'lr': 1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
Optimizer方法
zero_grad()方法、step()方法、add_param_group()方法、load_state_dict()方法、state_dict()方法
zero_grad(): 清空所管理参数的梯度,由于Tensor的梯度不会自动清零,因而每次backward时均需要清空梯度
def zero_grad(self, set_to_none: bool = False);
for group in self.param_groups: # 遍历optimizer的参数组,不同参数组往往有着不同的超参数
for p in group['params']: # 遍历参数组中的tensor参数
if p.grad is not None: #梯度不为空,即需要优化的参数
if set_to_none:
p.grad = None # 将参数的梯度设置为None,表示在backward过程中不再跟踪这个梯度的计算图
else:
if p.grad.grad_fn is not None: # 判断参数的梯度是否有梯度函数
p.grad.detach_() # 有梯度函数的参数梯度,即其是通过某个操作计算得到,使用`detach_`方法将其从计算图中分离
else:
p.grad.requires_grad_(False) # 没有梯度函数的参数梯度,通过`requires_grad`方法设置其不需要梯度
p.grad.zero_()# 梯度设置为0
step():执行一步梯度更新,参数更新
def step(self, closure):
raise NotImplementedError # 在Optimizer基类中,step()函数被定义为抛出`NotImplementedError`异常,表明继承Optimizer的优化器类必须实现自己的step方法
add_param_group():添加参数组
def add_param_group(self, param_group):
# 参数类型检查:检查传入的`param_group`是否为字典类型,如果不是则抛出异常
assert isinstance(param_group, dict), "param group must be a dict"
# 参数整理:获取传入参数组中的`params`字段,将其整理为list形式
# 检查类型是否为tensor
params = param_group['params']
if isinstance(params, torch.Tensor):
param_group['params'] = [params]
elif isinstance(params, set):
# 如果参数为set类型,抛出异常
raise TypeError('optimizer parameters need to be organized in ordered collections, but the ordering of tensors in sets will change between runs. Please use a list instead.')
else:
param_group['params'] = list(params)
# 参数检查:对每个参数进行检查,确保是 leaf Tensor 类型
for param in param_group['params']:
if not isinstance(param, torch.Tensor):
raise TypeError("optimizer can only optimize Tensors, but one of the params is " + torch.typename(param))
if not param.is_leaf:
raise ValueError("can't optimize a non-leaf Tensor")
# 超参数设置检查:检查在该优化器defaults中要求的超参数是否被提供,若未提供则抛出异常
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " + name)
else:
param_group.setdefault(name, default)
# 检查当前提供的参数组中是否有重复参数,若有则抛出warning
params = param_group['params']
if len(params) != len(set(params)):
warnings.warn("optimizer contains a parameter group with duplicate parameters; in future, this will cause an error; see github.com/PyTorch/PyTorch/issues/40967 for more information", stacklevel=3)
# 上面好像都在进行一些类的检测,报Warning和Error
# 参数集合检查:检查当前参数组的参数是否与之前已有的参数组参数集合没有交集
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 添加参数
self.param_groups.append(param_group)
load_state_dict():加载状态参数字典,可以实现模型的断点续训练
def load_state_dict(self, state_dict):
r"""Loads the optimizer state.
Arguments:
state_dict (dict): optimizer state. Should be an object returned from a call to :meth:`state_dict`.
"""
# deepcopy, to be consistent with module API
state_dict = deepcopy(state_dict)
# Validate the state_dict: 检验状态字典的参数组是否和当前优化器的参数组一致
groups = self.param_groups
saved_groups = state_dict['param_groups']
# 检验参数组长度和参数组下tensor参数长度
if len(groups) != len(saved_groups):
raise ValueError("loaded state dict has a different number of parameter groups")
param_lens = (len(g['params']) for g in groups)
saved_lens = (len(g['params']) for g in saved_groups)
if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):
raise ValueError("loaded state dict contains a parameter group that doesn't match the size of optimizer's group")
# Update the state
# 创建id映射,将状态字典中的参数与当前优化器中的参数对应起来
id_map = {old_id: p for old_id, p in zip(chain.from_iterable((g['params'] for g in saved_groups)), chain.from_iterable((g['params'] for g in groups)))}
def cast(param, value):
r"""Make a deep copy of value, casting all tensors to device of param."""
.....
# Copy state assigned to params (and cast tensors to appropriate types).
# State that is not assigned to params is copied as is (needed for backward compatibility).
# 转换并更新状态:将状态字典中的状态转换并更新到当前优化器中。
state = defaultdict(dict)
for k, v in state_dict['state'].items():
if k in id_map:
param = id_map[k]
state[param] = cast(param, v)
else:
state[k] = v
# Update parameter groups, setting their 'params' value
def update_group(group, new_group):
...
# 更新参数组
param_groups = [update_group(g, ng) for g, ng in zip(groups, saved_groups)]
# 调用`__setstate__`方法,实现将更新后的状态设置到当前优化器中
self.__setstate__({'state': state, 'param_groups': param_groups})
state_dict():获取优化器当前状态信息字典
def state_dict(self):
r"""Returns the state of the optimizer as a :class:`dict`.
It contains two entries:
* state - a dict holding current optimization state. Its content differs between optimizer classes.
* param_groups - a dict containing all parameter groups
"""
# Save order indices instead of Tensors
param_mappings = {}
start_index = 0
# 将Optimizer类的状态字典进行打包操作
def pack_group(group):
......
# 使用pack_group函数对param_groups中所有参数组进行打包
param_groups = [pack_group(g) for g in self.param_groups]
# Remap state to use order indices as keys
# 遍历当前优化器状态字典(`self.state`)中的每一项,将键映射到参数组的顺序索引
packed_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): v for k, v in self.state.items()}
return {
'state': packed_state,
'param_groups': param_groups,
}
实际操作
代码示例
import os
import torch
# 设置权重
weight = torch.randn((2,2), requires_grad=True)
# 设置梯度
weight.grad = torch.ones((2,2))
# 输出当前权重和梯度
print("The data of weight before step:\n{}".format(weight.data))
print("The grad of weight before step:\n{}".format(weight.grad))
# 实例化优化器
optimizer = torch.optim.SGD([weight], lr=0.1, momentum=0.9)
# 一步优化操作
optimizer.step()
# 查看一步更新后的参数结果
print("The data of weight before step:\n{}".format(weight.data))
print("The grad of weight before step:\n{}".format(weight.grad))
# 权重清零
optimizer.zero_grad()
# 检验清零是否成功
print("The grad of weight after optimizer.zero_grad():\n{}".format(weight.grad))
# 输出优化器参数
print("optimizer.params_group is \n{}".format(optimizer.param_groups))
# 查看参数位置 --optimizer和weight的位置一样
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
# 添加参数
weight2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({'params':weight2, 'lr': 0.0001, 'nesterov':True})
# 查看现有参数
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
# 查看当前优化器的状态信息
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
# 进行5次step操作
for _ in range(50):
optimizer.step()
# 输出现有状态信息
print("state_dict after step:\n", optimizer.state_dict())
# 保存参数信息 --路径自行更换
torch.save(optimizer.state_dict(), os.path.join(r"D:\pythonProject\Attention_Unet", "optimizer_state_dict.pkl"))
print("Done!")
# 加载参数信息
state_dict = torch.load(r"D:\pythonProject\Attention_Unet\optimizer_state_dict.pkl") # 需要修改为你自己的路径
optimizer.load_state_dict(state_dict)
print("load state_dict successfully\n{}".format(state_dict))
# 输出属性信息
print("\n{}".format(optimizer.defaults))
print("\n{}".format(optimizer.state))
print("\n{}".format(optimizer.param_groups))
注意事项
- 每个优化器都是一个类,只有其经过实例化之后才能使用
class Net(nn.Module):
...
net = Net()
optim = torch.optim.SGD(net.parameters(), lr = lr)
optim.step
- optimizer的操作分为两步:梯度置零,梯度更新
optimizer = torch.optim.SGD(net.parameters(), lr=1e-5)
for epoch in range(EPOCH):
...
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
- 以层为单位,设置每个优化器更新的参数权重
from torch import optim
from torchvision.models import resnet18
net = resnet18
optimizer = optim.SGD([
{'params': net.fc.parameters()},
{'params': net.layer4[0].conv1.parameters(), 'lr': 1e-2}
], lr=1e-5)
实验
数据生成
a = torch.linspace(-1, 1, 1000)
# 利用unsqueeze进行升维操作
x = torch.unsqueeze(a, dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(x.size()))
# 数据可视化
import matplotlib.pyplot as plt
plt.scatter(x,y)
plt.title('Generated Data')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.show()
网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = nn.Linear(1, 20)
self.predict = nn.Linear(20, 1)
def forward(self, x):
x = self.hidden(x)
x = F.relu(x)
x = self.predict(x)
return x
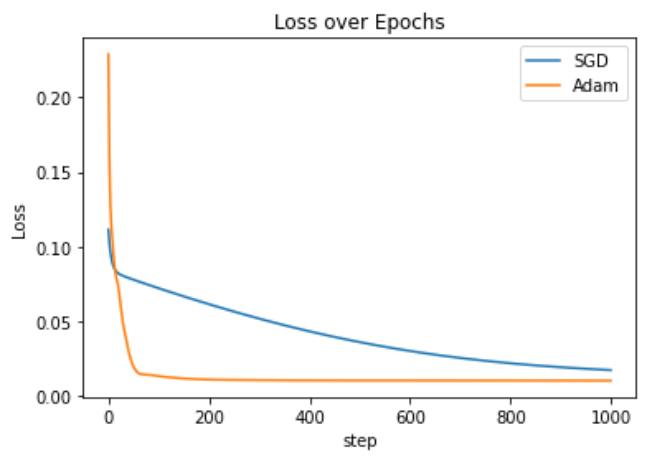
利用不同的优化器对该网络结构的权重参数进行优化,并绘制loss随着step变化的图示,得到收敛速度
import torch.optim as optim
import torch.nn.functional as F
# 定义模型
model1 = Net()
model2 = Net()
# 定义损失函数
criterion = nn.MSELoss()
# 定义两个不同的优化器
optimizer1 = optim.SGD(model1.parameters(), lr=0.01)
optimizer2 = optim.Adam(model2.parameters(), lr=0.01)
# 训练模型
num_epochs = 1000
losses1, losses2 = [], []
for epoch in range(num_epochs):
# 将数据转换为 PyTorch 张量
x_tensor = torch.FloatTensor(x).view(-1, 1)
y_tensor = torch.FloatTensor(y).view(-1, 1)
# 使用第一个优化器进行训练
optimizer1.zero_grad()
outputs1 = model1(x_tensor)
loss1 = criterion(outputs1, y_tensor)
loss1.backward()
optimizer1.step()
losses1.append(loss1.item())
# 使用第二个优化器进行训练
optimizer2.zero_grad()
outputs2 = model2(x_tensor)
loss2 = criterion(outputs2, y_tensor)
loss2.backward()
optimizer2.step()
losses2.append(loss2.item())
# 绘制损失变化图
import matplotlib.pyplot as plt
plt.plot(range(num_epochs), losses1, label='SGD')
plt.plot(range(num_epochs), losses2, label='Adam')
plt.title('Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
训练结果图示:
问题说明
使用不同的optimizer对相同数据进行优化时,应该要用不同的模型,因为如果使用相同的模型,两个优化器的优化过程是相互干扰的
总结一下就是,相同输入数据,不同model实例,不同optimizer,相同criterion标准
参考资料
- datawhale through-pytorch repo