服务端缓存
在透明多级分流系统中,我们以流量从客户端中发出开始,以流量到达服务器集群中真正处理业务的节点结束。一起探索了在这个过程中与业务无关的一些通用组件,包括DNS、CDN、客户端缓存,等等。
实际上,服务端缓存也是一种通用的技术组件,它主要用于减少多个客户端相同的资源请求,缓解或降低服务器的负载压力。所以,说它是一种分流手段也是很合理的。
引入缓存的理由
关于服务端缓存,首先需要明确的问题是,在为系统引入缓存之前,它是否真的需要缓存?
软件开发中并不像硬件缓存(如CPU L1/2/3缓存、磁盘缓存,等等)那样多多益善,在软件开发中,引入缓存的负作用明显要大于硬件的缓存。主要有下面几个原因:
- 从开发角度来说,引入缓存会提高系统的复杂度,因为需要考虑缓存失效、更新、一致性等问题;
- 从运维角度来说,缓存会掩盖掉一些缺陷,让问题在更久的时间以后出现;
- 从安全角度来说,缓存可能泄漏某些保密数据,这也是容易收到攻击的薄弱点;
那么为什么要引入缓存?主要有下面两种理由,
- 为了缓解CPU压力而做缓存:把需要实时计算的结果提前算好,并对公共数据进行复用,从而提升响应性能;
- 为了缓解I/O压力而做缓存:通过引入缓存,把原本对网络、磁盘等较慢介质的读写访问,变为对内存等较快介质的访问;把原本对单点部件(如数据库)的读写访问,变为对可扩缩部件(如缓存中间件)的访问,等等,典型的以空间换时间来提升性能的手段。当然,如果可以通过升级硬件来增强CPU、I/O性能的话,多花点钱会比引入缓存的风险更低;
缓存属性
在设计或选择缓存时,需要考虑下面四个维度的属性。
- 吞吐量:缓存的吞吐量使用OPS(每秒操作数,Operations per Second,ops/s)来衡量,反映了对缓存进行并发读、写操作的效率;
- 命中率:成功从缓存中返回结果次数与总请求次数的比值,它反映了引入缓存的价值高低,命中率越低、引入缓存的收益越小;
- 扩展功能:比如最大容量、失效时间、失效事件、命中率统计等等;
- 分布式支持:缓存可以分为”进程内缓存“和”分布式缓存“两大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存的数据不能在各个服务节点中共享,后者相反;
吞吐量
缓存的吞吐量只有在并发场景中才有统计的意义,而无论采用怎样的实现方法,线程安全措施都会带来一定的吞吐量损失。
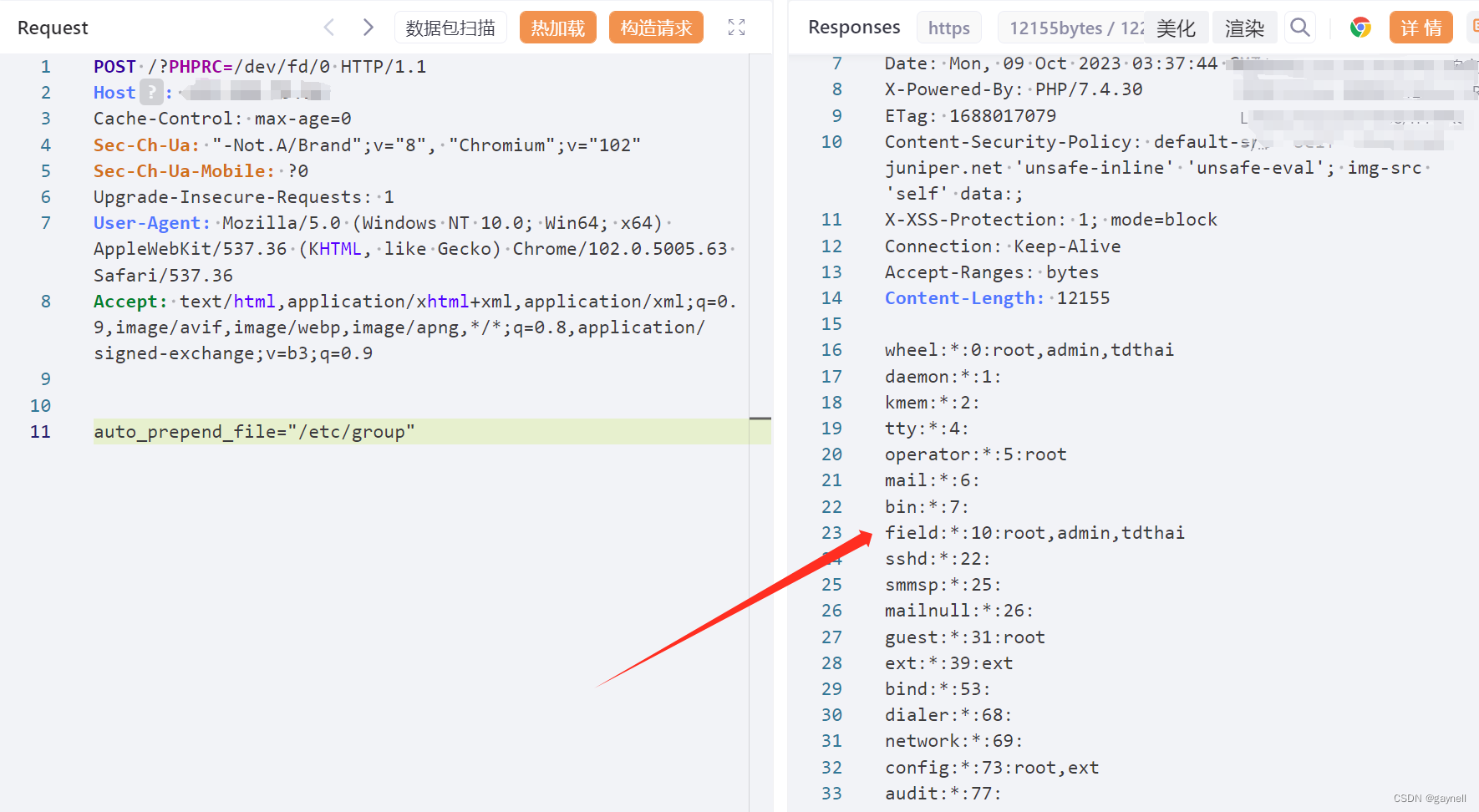
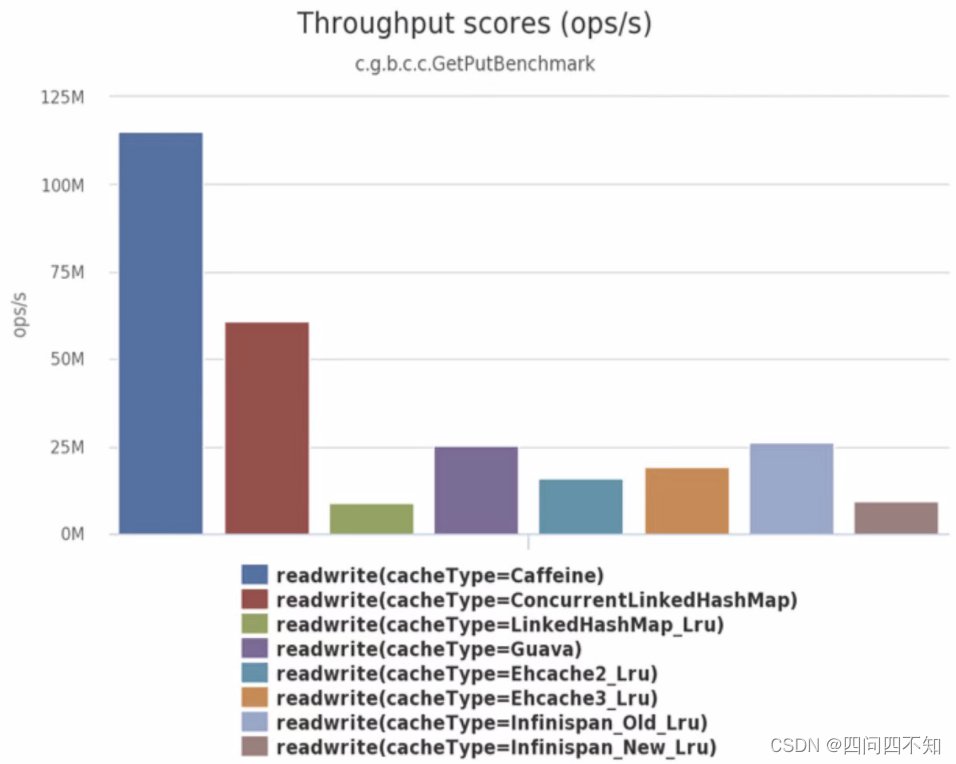
根据Caffeine给出的一组目前业界主流进程内缓存的实现方案,包括了Caffeine、ConcurrentLinkedHashMap、LinkedHashMap、GuavaCache、EhCache和Infinispan Embedded等缓存组件库的对比。从它们在8线程、75%读操作、25%写操作下的吞吐量表现Benchmarks来看,各个缓存组件库的性能差异还是十分明显的,如下图,



![[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]](https://img-blog.csdnimg.cn/482933ab62254fb5b19232ef99b2d975.png)


![[硬件基础]-快速了解555定时器](https://img-blog.csdnimg.cn/4e4777f47be444f580dcdab1209f35ac.png#pic_center)