目录
1. Zookeeper简介
2. Zookeeper安装
2.1 首先,要确保已经完成了集群化环境前置准备环节的全部内容
2.2 【node1上操作】下载Zookeeper安装包,并解压
2.3 【node1上操作】创建软链接
2.4 【node1上操作】修改配置文件
2.5 【node1上操作】配置myid
2.6 【在node2和node3上操作】,创建文件夹
2.7 【node1上操作】将Zookeeper 复制到node2和node3
2.8 【在node2上操作】
2.9 【在node3上操作】
2.10 【在node1、node2、node3上分别执行】启动Zookeeper
2.11 【在node1、node2、node3上分别执行】检查Zookeeper进程是否启动
2.12 【node1上操作】验证Zookeeper
3. Kafka简介
4. Kafka安装
4.1 确保已经跟随前面步骤,安装并部署了JDK和Zookeeper服务
4.2 【在node1操作】下载并上传Kafka的安装包
4.3 【在node1操作】解压
4.4 【在node1操作】修改Kafka目录内的config目录内的server.properties 文件
4.5 【在node1操作】将node1的kafka复制到node2和node3
4.6 【在node2操作】
4.7 【在node3操作】
4.8 启动kafka
4.9 验证Kafka启动
5. 测试Kafka能否正常使用
5.1 创建测试主题
5.2 运行测试,请在FinalShell中打开2个node1的终端页面
1. Zookeeper简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
除了为Hadoop和HBase提供协调服务外,Zookeeper也被其它许多软件采用作为其分布式状态一致性的依赖,比如Kafka,又或者一些软件项目中,也经常能见到Zookeeper作为一致性协调服务存在。
Zookeeper不论是大数据领域亦或是其它服务器开发领域,涉及到分布式状态一致性的场景,总有它的身影存在。
2. Zookeeper安装
Zookeeper是一款分布式的集群化软件,可以在多台服务器上部署,并协同组成分布式集群一起工作。
2.1 首先,要确保已经完成了集群化环境前置准备环节的全部内容
链接:集群化环境前置准备_时光の尘的博客-CSDN博客
2.2 【node1上操作】下载Zookeeper安装包,并解压
# 下载
wget
http://archive.apache.org/dist/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
# 确保如下目录存在,不存在就创建
mkdir -p /export/server
# 解压
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /export/server2.3 【node1上操作】创建软链接
ln -s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper2.4 【node1上操作】修改配置文件
vim /export/server/zookeeper/conf/zoo.cfg
tickTime=2000
# zookeeper数据存储目录
dataDir=/export/server/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:38882.5 【node1上操作】配置myid
# 1. 创建Zookeeper的数据目录
mkdir /export/server/zookeeper/data
# 2. 创建文件,并填入1
vim /export/server/zookeeper/data/myid
# 在文件内填入1即可2.6 【在node2和node3上操作】,创建文件夹
mkdir -p /export/server2.7 【node1上操作】将Zookeeper 复制到node2和node3
cd /export/server
scp -r apache-zookeeper-3.5.9 node2:`pwd`/
scp -r apache-zookeeper-3.5.9 node3:`pwd`/2.8 【在node2上操作】
# 1. 创建软链接
ln -s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为22.9 【在node3上操作】
# 1. 创建软链接
ln -s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为32.10 【在node1、node2、node3上分别执行】启动Zookeeper
# 启动命令
/export/server/zookeeper/bin/zkServer.sh start
# 启动Zookeeper2.11 【在node1、node2、node3上分别执行】检查Zookeeper进程是否启动
jps
# 结果中找到有:QuorumPeerMain 进程即可2.12 【node1上操作】验证Zookeeper
/export/server/zookeeper/zkCli.sh
# 进入到Zookeeper控制台中后,执行
ls /
# 如无报错即配置成功3. Kafka简介
4. Kafka安装
4.1 确保已经跟随前面步骤,安装并部署了JDK和Zookeeper服务
Kafka 的运行依赖 JDK 环境和 Zookeeper 请确保已经有了 JDK 环境和Zookeeper
4.2 【在node1操作】下载并上传Kafka的安装包
# 下载安装包
wget
http: / archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz4.3 【在node1操作】解压
mkdir -p /export/server # 此文件夹如果不存在需先
创建
# 解压
tar -zxvf kafka_2.12-2.4.1.tgz -C /export/server/
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka4.4 【在node1操作】修改Kafka目录内的config目录内的server.properties 文件
cd /export/server/kafka/config
# 指定broker的id
broker.id=1
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT: / node1:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:21814.5 【在node1操作】将node1的kafka复制到node2和node3
cd /export/server
# 复制到node2同名文件夹
scp -r kafka_2.12-2.4.1 node2:`pwd`/
# 复制到node3同名文件夹
scp -r kafka_2.12-2.4.1 node3:$PWD4.6 【在node2操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=2
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT: / node2:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:21814.7 【在node3操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=3
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT: / node3:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:21814.8 启动kafka
# 请先确保Zookeeper已经启动了
# 方式1:【前台启动】分别在node1、2、3上执行如下语句
/export/server/kafka/bin/kafka-server-start.sh
/export/server/kafka/config/server.properties
# 方式2:【后台启动】分别在node1、2、3上执行如下语句
nohup /export/server/kafka/bin/kafka-server-start.sh
/export/server/kafka/config/server.properties 2>&1
>> /export/server/kafka/kafka-server.log &4.9 验证Kafka启动
# 在每一台服务器执行
jps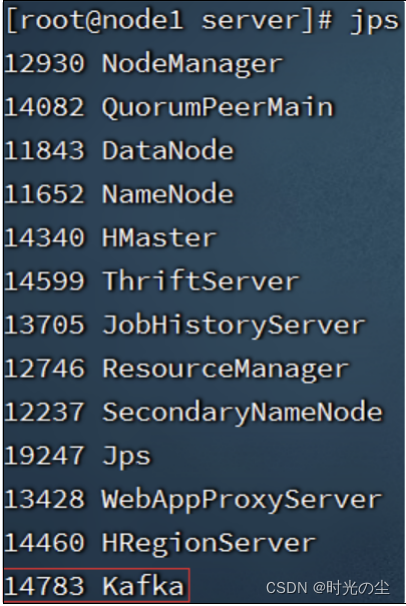
5. 测试Kafka能否正常使用
5.1 创建测试主题
# 在node1执行,创建一个主题
/export/server/kafka_2.12-2.4.1/bin/kafka-topics.sh create --zookeeper node1:2181
--replication-factor 1 --partitions 3 --topic test5.2 运行测试,请在FinalShell中打开2个node1的终端页面
# 打开一个终端页面,启动一个模拟的数据生产者
/export/server/kafka_2.12-2.4.1/bin/kafka-console--producer.sh --broker-list node1:9092
--topic test
# 再打开一个新的终端页面,在启动一个模拟的数据消费者
/export/server/kafka_2.12-2.4.1/bin/kafka-console--consumer.sh --bootstrap-server node1:9092 --topic test --from-beginning