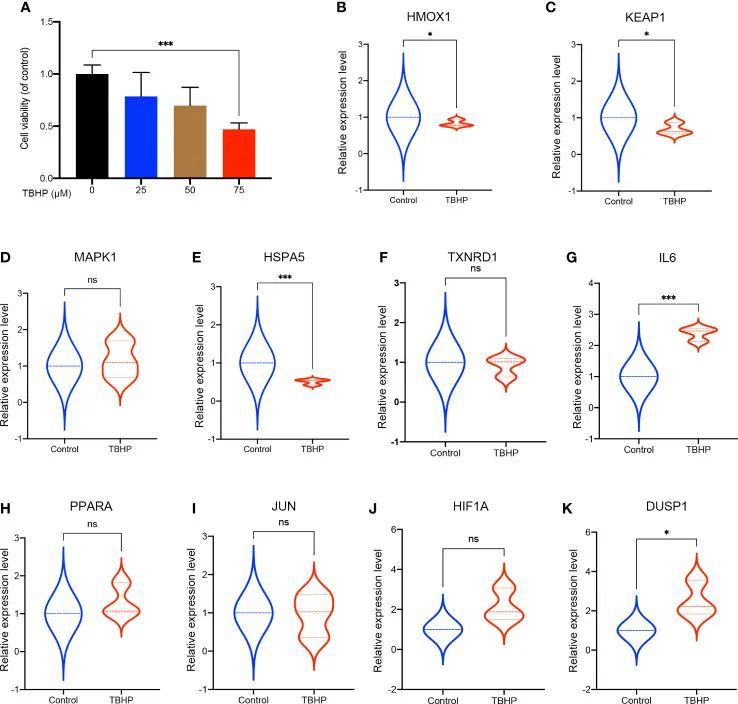
import detect
detect.UAPI(source="data/images")通过在YOLOv5中的detect.py的代码中,对检测函数进行封装,之后其他代码通过已经封装好的函数进行调用,从而实现简单便捷的YOLOv5代码调用。
代码的主要修改部分就是如何detect.py中的配置代码封装到调用的函数中:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))对于这部分我们可以直接进行修改
def run(
weights=ROOT / 'runs/train/exp/weights/best.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/mogu.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
vid_stride=1, # video frame-rate stride
):剩余的代码基本可以使用detect.py中默认的detect中的文件
之后其他代码甚至可以删除
对文件夹中的图片进行检测可实现的结果:
前提是视频文件夹下有图片,或者直接指定某个图片

对文件夹中的视频进行检测
只需要把相应的图片文件夹改为视频文件夹即可
前提是视频文件夹下有视频文件,或者直接指定某个视频
import detect
detect.UAPI(source="data/video")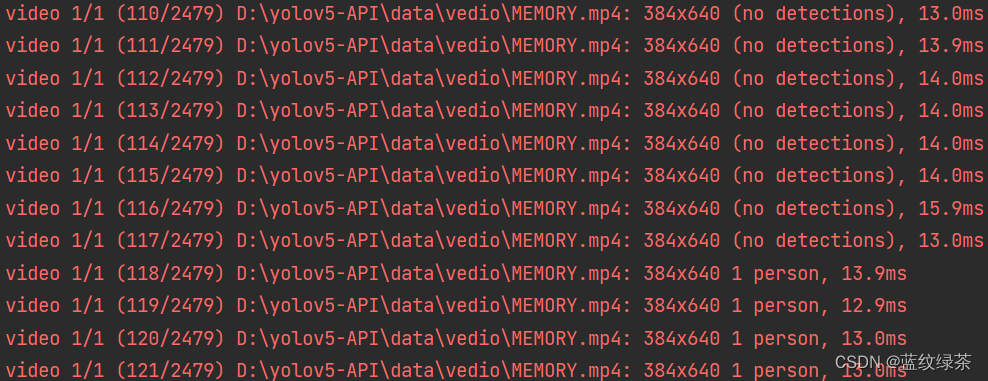


![[代码解读] A ConvNet for the 2020s](https://img-blog.csdnimg.cn/1c61f6366920485d896ccf59710001b8.png)