代码地址:https://github.com/facebookresearch/ConvNeXt
ConvNeXt/models/convnext.py整体的代码结构如下:
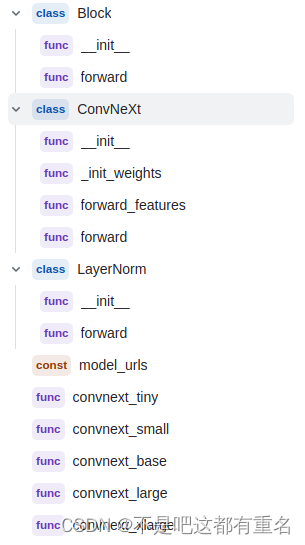
接下来我们一部分一部分来看。
1.Block类:
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
在这个类的注释中有写到两种等价的操作:
(1)DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2)DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
在这个类中作者用了第二种,因为他们发现在pytorch中第二种方式稍微快一点。
1.1 初始化方法
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
在初始化函数中,定义了depthwise卷积self.dwconv,具体实现是用输入通道=输出通道=groups的逐通道卷积,其核大小为7,padding为3。然后是归一化层self.norm,具体实现是LayerNorm。之后定义了pointwise/1x1卷积,由于上面所提到的原因,这里具体使用线性层来实现的。接下来是激活函数,依照论文中的结论,这里的激活函数为GELU。DropPath提供了一种针对网络分支的网络正则化方法。
1.2前向传播
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
前向传播过程就如(2)DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back中所示,最后这个block的示意图如下:
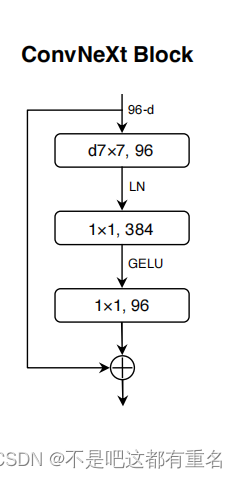
图中主要画出的关键步骤是一个depthwise卷积和两个pointwise卷积以及一个残差连接结构,在经过这样一个block后,输入输出的通道维度不变。
**总结:**在block类的具体代码中我们可以看到文章中所提到的一些设计要点,包括:分组数等于通道数的分组卷积、两头小中间大的逆瓶颈结构(以及自然而然的上移的深度卷积层)、使用了7x7卷积核的深度卷积、GeLU激活函数、一个块中只有一个归一化层和一个激活层和使用LN。
2.ConvNeXt类
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
在这个类中除了初始化方法外还包括初始化权重方法_init_weights,以及前向传播方法forward_features和forward。
2.1 初始化方法
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
首先定义了一个self.downsample_layers用来装载根块和三个中间的下采样层。根块由步长为4的4x4一个卷积层和一个LN层构成,下采样层由一个LN层加一个步长为2的2x2卷积层构成,下采样一共有三个。然后定义了self.stages用来装载4个stage块,每个stage块由depths[i]所指定的n个ConvNeXt Block构成。之后定义了最后的一层归一化层self.norm,最后是用Linear定义了一个self.head,用来最终输出。
2.2初始化权重
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
用截断正态分布来对权重初始化,偏置初始化为0。
2.3前向传播
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
整个前向传播过程就是上面初始化过程中所定义的块的堆叠,整个网络结构图如下图所示:
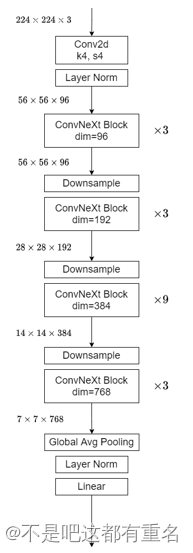
总结
在b这个类的具体代码中我们可以看到文章中所提到的其他的设计要点,包括:使用3:3:9:3的阶段比、使用核大小为4×4,步长为4的卷积层来实现patchify层。
3.结束语
总的来看ConvNeXt的确是非常简单,无论从结构还是思路上。用的大部分的设计都在之前的研究中有过讨论,同时也借鉴了Transformers出现后所带来的一些新的思路,在当时确实在兼顾效率的情况下展现了不错的性能。重新认识卷积在计算机视觉领域的作用是十分必要的。