当一项变革性技术出现后,以此为基础的技术就会像雨后春笋般蔓延。
就像Transformer出现后,以此为基础的大语言模型ChatGPT,视觉基础模型Segment Anything相继横空出世,并展现出强大的涌现能力。生成式AI可谓百花齐鸣,争相绽放。
继纯语言,纯视觉大模型后,多模态大模型也粉墨登场,最近Google DeepMind重磅推出Robotic Transformer 2(RT2),也被称为视觉-语言-行动模型(Vision-Language-Action)。用一句话概括:RT2可以将机器人对世界的观察(图片)以及用户的指令(文本)转换成机器人的控制指令(文本)。
论文地址:
https://robotics-transformer2.github.io/assets/rt2.pdf
官方文档:
https://robotics-transformer2.github.io
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action
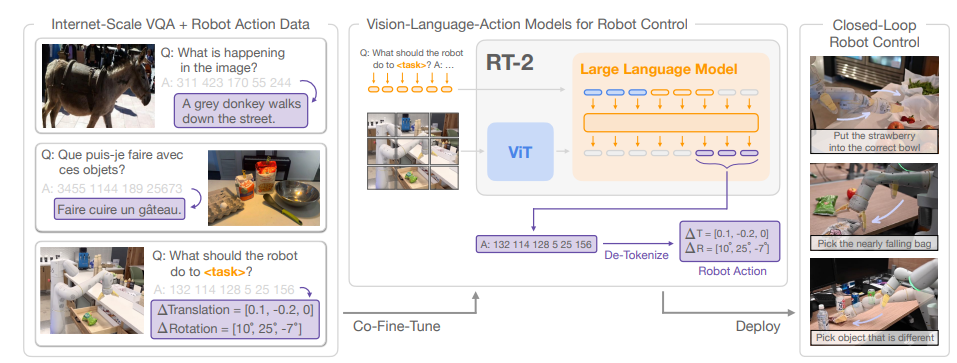
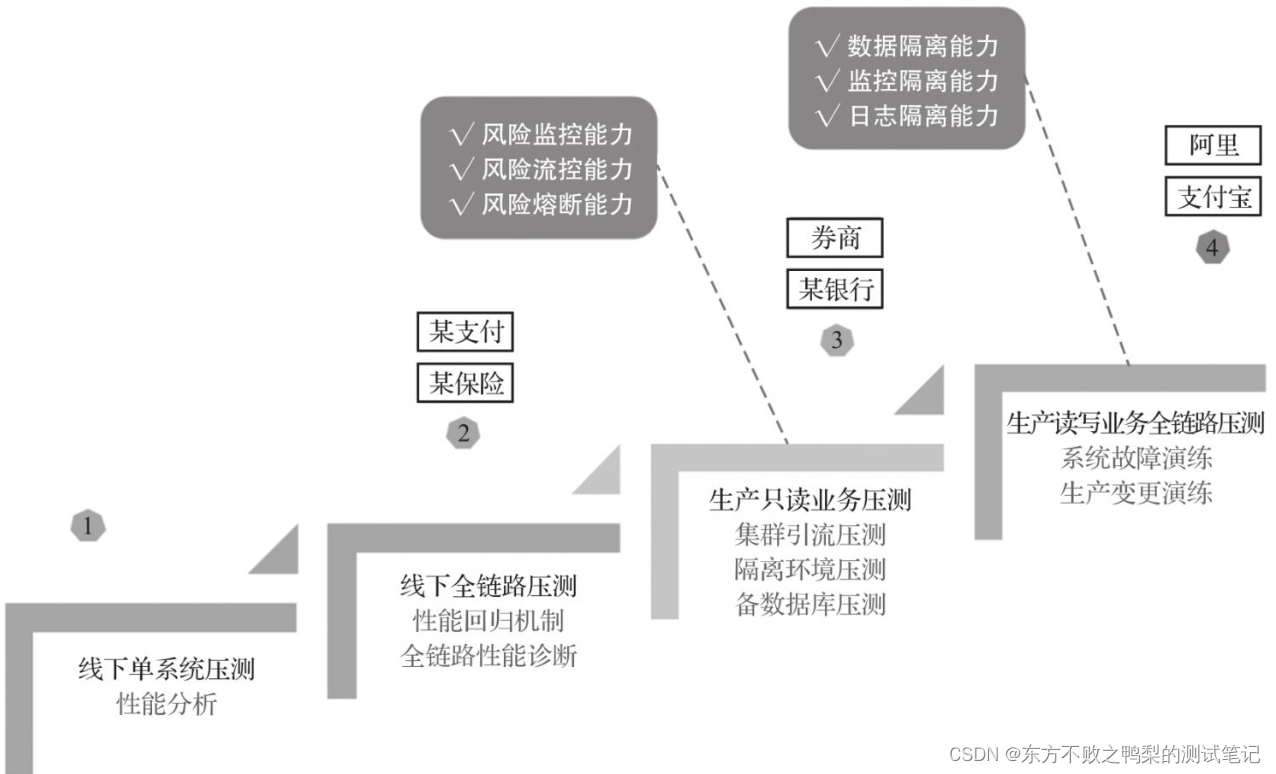
整体流程图
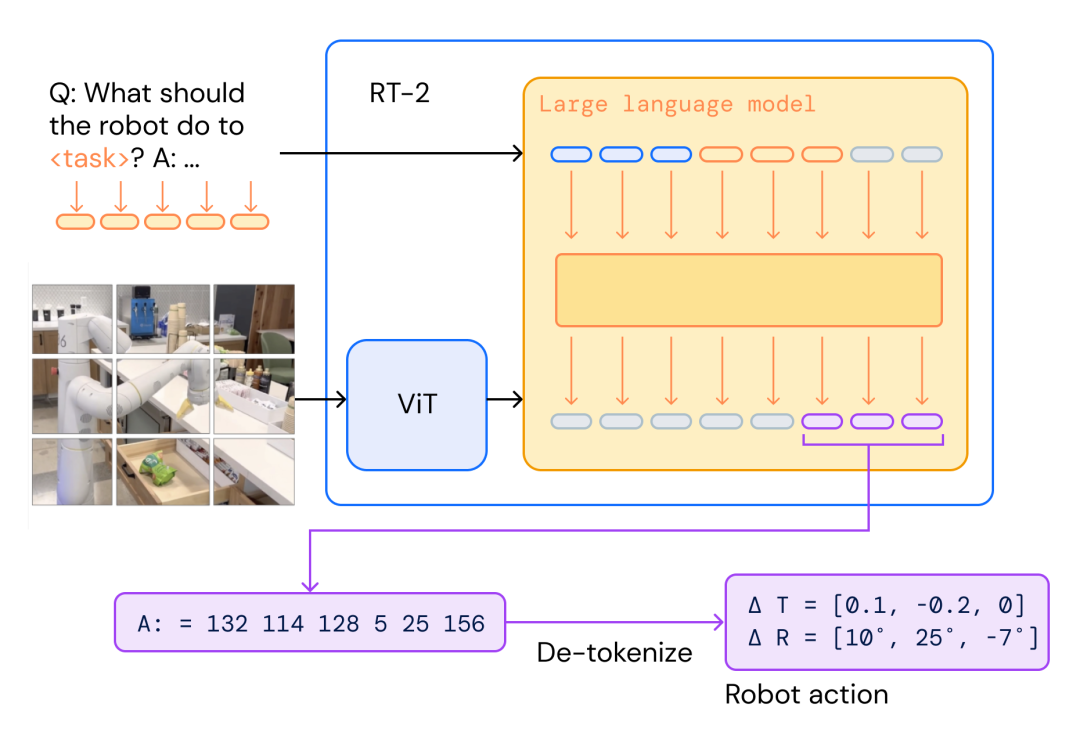
整体流程如上图所示,机器人接受人类的语音指令,将其转换为文本,同时利用自身的摄像头对现实场景进行拍照,将文本和图片同时输入到RT2中,模型输出机器人控制指令文本,最后将指令文本解码成机器人能识别的指令格式下达给机器人控制器。

机器人指令文本格式
机器人对人类下达的文本指令(pick robot)原本一无所知,但通过RT2将人类指令文本(pick robot)和机器人指令文本(A:=132 114 128 5 25 156)映射到了同一个向量空间,通过大量数据训练后,那么两者就具有相同的语义了。
纯语言模型和纯视觉模型的输入大多是单模态的,也就是只有文本或者图片,而RT2的输入既有文本也有图片,这种能够处理多模态信息的模型被称为视觉语言模型,目前有两种主流方法。
一种方法是CLIP,它的思路很简单,就是将图片和文本分别编码到同一个共享空间,在这个空间中,“a cat”和一只猫的图片余弦相似度最大。
另一种方法是具有{vision, text} → {text} 映射形式的模型,类似于视觉问答,这种方法也是本文RT2所采用的方法。
采用这种方法的另一个好处是不需要从零开始训练模型,目前已经有在大量网络数据上进行训练的视觉语言预训练模型,例如,PaLI-X PaLM-E,但只有网络通用数据无法直接应用于机器人领域,所以需要在预训练模型的基础上继续用专门的机器人训练数据进行微调,其整体训练过程如下。
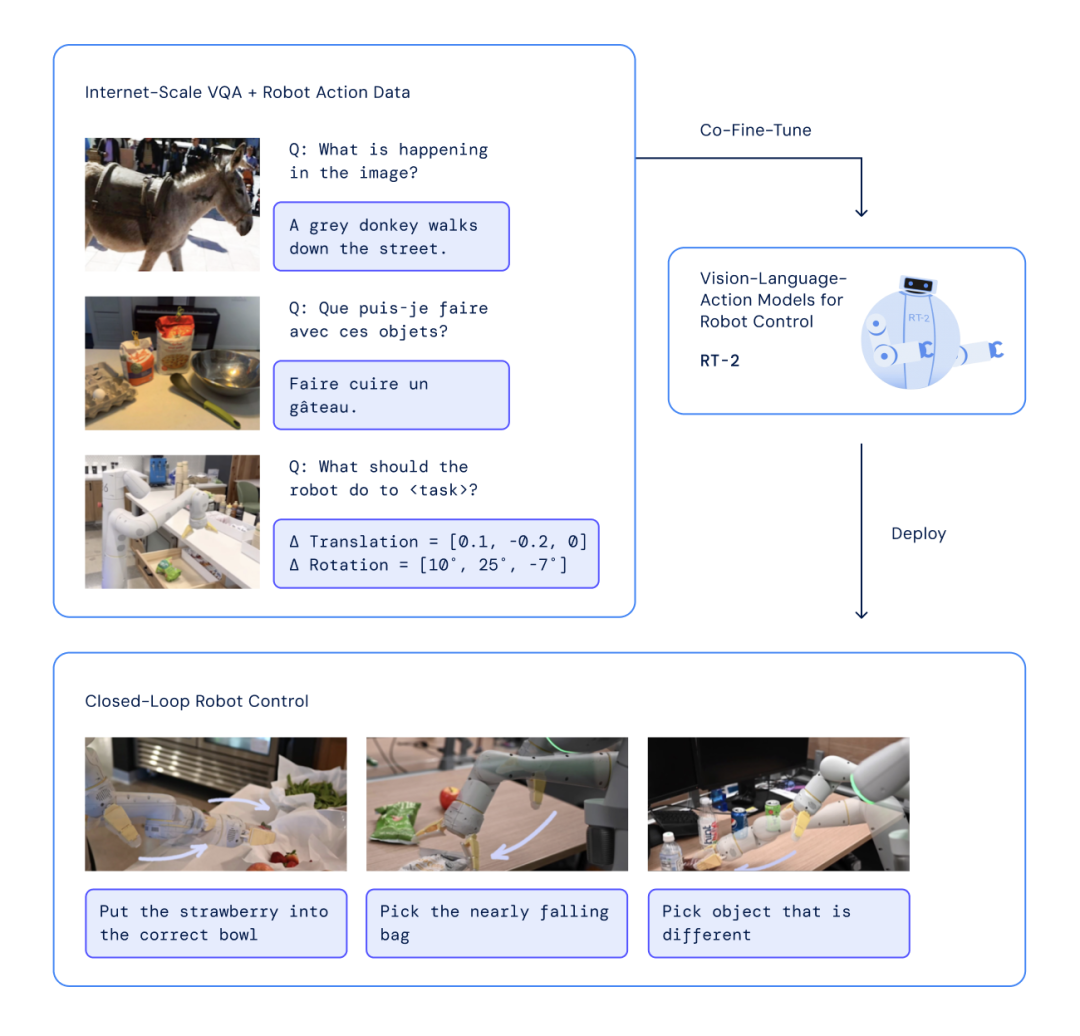
训练过程
为了适应机器人场景,需要将用户文本指令进行简单的装饰后再送入网络进行训练,例如,用户的指令是:pick the football,装饰后的文本就是What robot should do to pick the football? 最后与图片一起送入网络。