本章概要
- 中间操作
- 跟踪和调试
- 流元素排序
- 移除元素
- 应用函数到元素
- 在 map() 中组合流
中间操作
中间操作用于从一个流中获取对象,并将对象作为另一个流从后端输出,以连接到其他操作。
跟踪和调试
peek() 操作的目的是帮助调试。它允许你无修改地查看流中的元素。代码示例:
Peeking.java
class Peeking {
public static void main(String[] args) throws Exception {
FileToWords.stream("Cheese.dat")
.skip(21)
.limit(4)
.map(w -> w + " ")
.peek(System.out::print)
.map(String::toUpperCase)
.peek(System.out::print)
.map(String::toLowerCase)
.forEach(System.out::print);
}
}
FileToWords.java
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Pattern;
import java.util.stream.Stream;
public class FileToWords {
public static Stream<String> stream(String filePath)
throws Exception {
return Files.lines(Paths.get(filePath))
.skip(1) // First (comment) line
.flatMap(line ->
Pattern.compile("\\W+").splitAsStream(line));
}
}
Cheese.dat
// streams/Cheese.dat
Not much of a cheese shop really, is it?
Finest in the district, sir.
And what leads you to that conclusion?
Well, it's so clean.
It's certainly uncontaminated by cheese.
输出结果:

FileToWords 稍后定义,但它的功能实现貌似和之前我们看到的差不多:产生字符串对象的流。之后在其通过管道时调用 peek() 进行处理。
因为 peek() 符合无返回值的 Consumer 函数式接口,所以我们只能观察,无法使用不同的元素来替换流中的对象。
流元素排序
在 Randoms.java 中,我们熟识了 sorted() 的默认比较器实现。其实它还有另一种形式的实现:传入一个 Comparator 参数。代码示例:
import java.util.*;
public class SortedComparator {
public static void main(String[] args) throws Exception {
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.skip(10)
.limit(10)
.sorted(Comparator.reverseOrder())
.map(w -> w + " ")
.forEach(System.out::print);
}
}
输出结果:

sorted() 预设了一些默认的比较器。这里我们使用的是反转“自然排序”。当然你也可以把 Lambda 函数作为参数传递给 sorted()。
移除元素
distinct():在Randoms.java类中的distinct()可用于消除流中的重复元素。相比创建一个 Set 集合来消除重复,该方法的工作量要少得多。filter(Predicate):过滤操作,保留如下元素:若元素传递给过滤函数产生的结果为true。
在下例中,isPrime() 作为过滤函数,用于检测质数。
import java.util.stream.*;
import static java.util.stream.LongStream.*;
public class Prime {
public static Boolean isPrime(long n) {
return rangeClosed(2, (long) Math.sqrt(n))
.noneMatch(i -> n % i == 0);
}
public LongStream numbers() {
return iterate(2, i -> i + 1)
.filter(Prime::isPrime);
}
public static void main(String[] args) {
new Prime().numbers()
.limit(10)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
new Prime().numbers()
.skip(90)
.limit(10)
.forEach(n -> System.out.format("%d ", n));
}
}
输出结果:
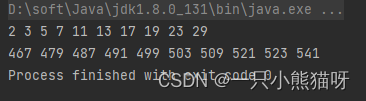
rangeClosed() 包含了上限值。如果不能整除,即余数不等于 0,则 noneMatch() 操作返回 true,如果出现任何等于 0 的结果则返回 false。 noneMatch() 操作一旦有失败就会退出。
应用函数到元素
map(Function):将函数操作应用在输入流的元素中,并将返回值传递到输出流中。mapToInt(ToIntFunction):操作同上,但结果是 IntStream。mapToLong(ToLongFunction):操作同上,但结果是 LongStream。mapToDouble(ToDoubleFunction):操作同上,但结果是 DoubleStream。
在这里,我们使用 map() 映射多种函数到一个字符串流中。代码示例:
import java.util.*;
import java.util.stream.*;
import java.util.function.*;
class FunctionMap {
static String[] elements = {"12", "", "23", "45"};
static Stream<String>
testStream() {
return Arrays.stream(elements);
}
static void test(String descr, Function<String, String> func) {
System.out.println(" ---( " + descr + " )---");
testStream()
.map(func)
.forEach(System.out::println);
}
public static void main(String[] args) {
test("add brackets", s -> "[" + s + "]");
test("Increment", s -> {
try {
return Integer.parseInt(s) + 1 + "";
} catch (NumberFormatException e) {
return s;
}
}
);
test("Replace", s -> s.replace("2", "9"));
test("Take last digit", s -> s.length() > 0 ?
s.charAt(s.length() - 1) + "" : s);
}
}
输出结果:
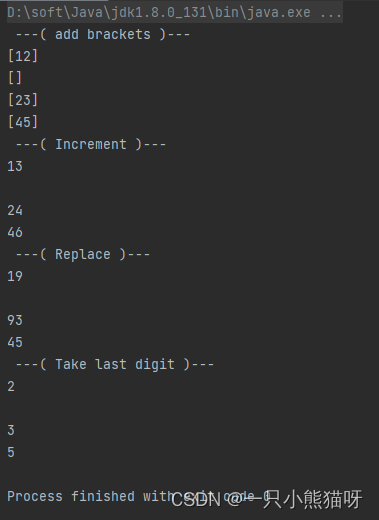
在上面的自增示例中,我们用 Integer.parseInt() 尝试将一个字符串转化为整数。如果字符串不能被转化成为整数就会抛出 NumberFormatException 异常,此时我们就回过头来把原始字符串放到输出流中。
在以上例子中,map() 将一个字符串映射为另一个字符串,但是我们完全可以产生和接收类型完全不同的类型,从而改变流的数据类型。下面代码示例:
// Different input and output types (不同的输入输出类型)
import java.util.stream.*;
class Numbered {
final int n;
Numbered(int n) {
this.n = n;
}
@Override
public String toString() {
return "Numbered(" + n + ")";
}
}
class FunctionMap2 {
public static void main(String[] args) {
Stream.of(1, 5, 7, 9, 11, 13)
.map(Numbered::new)
.forEach(System.out::println);
}
}
输出结果:
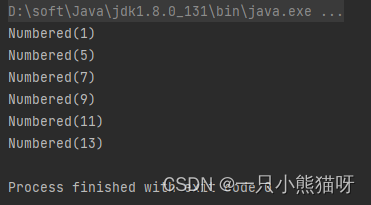
我们将获取到的整数通过构造器 Numbered::new 转化成为 Numbered 类型。
如果使用 Function 返回的结果是数值类型的一种,我们必须使用合适的 mapTo数值类型 进行替代。代码示例:
// Producing numeric output streams( 产生数值输出流)
import java.util.stream.*;
class FunctionMap3 {
public static void main(String[] args) {
Stream.of("5", "7", "9")
.mapToInt(Integer::parseInt)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Stream.of("17", "19", "23")
.mapToLong(Long::parseLong)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Stream.of("17", "1.9", ".23")
.mapToDouble(Double::parseDouble)
.forEach(n -> System.out.format("%f ", n));
}
}
输出结果:
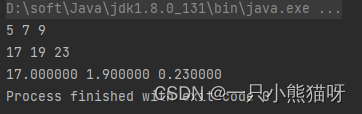
遗憾的是,Java 设计者并没有尽最大努力去消除基本类型。
在 map() 中组合流
假设我们现在有了一个传入的元素流,并且打算对流元素使用 map() 函数。现在你已经找到了一些可爱并独一无二的函数功能,但是问题来了:这个函数功能是产生一个流。我们想要产生一个元素流,而实际却产生了一个元素流的流。
flatMap() 做了两件事:将产生流的函数应用在每个元素上(与 map() 所做的相同),然后将每个流都扁平化为元素,因而最终产生的仅仅是元素。
flatMap(Function):当 Function 产生流时使用。
flatMapToInt(Function):当 Function 产生 IntStream 时使用。
flatMapToLong(Function):当 Function 产生 LongStream 时使用。
flatMapToDouble(Function):当 Function 产生 DoubleStream 时使用。
为了弄清它的工作原理,我们从传入一个刻意设计的函数给 map() 开始。该函数接受一个整数并产生一个字符串流:
import java.util.stream.*;
public class StreamOfStreams {
public static void main(String[] args) {
Stream.of(1, 2, 3)
.map(i -> Stream.of("Gonzo", "Kermit", "Beaker"))
.map(e -> e.getClass().getName())
.forEach(System.out::println);
}
}
输出结果:

我们天真地希望能够得到字符串流,但实际得到的却是“Head”流的流。我们可以使用 flatMap() 解决这个问题:
import java.util.stream.*;
public class FlatMap {
public static void main(String[] args) {
Stream.of(1, 2, 3)
.flatMap(i -> Stream.of("Gonzo", "Fozzie", "Beaker"))
.forEach(System.out::println);
}
}
输出结果:
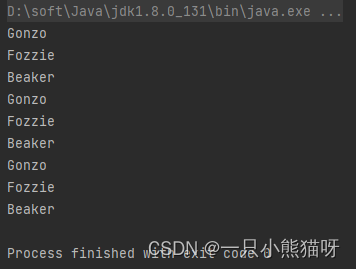
从映射返回的每个流都会自动扁平为组成它的字符串。
下面是另一个演示,我们从一个整数流开始,然后使用每一个整数去创建更多的随机数。
import java.util.*;
import java.util.stream.*;
public class StreamOfRandoms {
static Random rand = new Random(47);
public static void main(String[] args) {
Stream.of(1, 2, 3, 4, 5)
.flatMapToInt(i -> IntStream.concat(
rand.ints(0, 100).limit(i), IntStream.of(-1)))
.forEach(n -> System.out.format("%d ", n));
}
}
输出结果:

在这里我们引入了 concat(),它以参数顺序组合两个流。 如此,我们在每个随机 Integer 流的末尾添加一个 -1 作为标记。你可以看到最终流确实是从一组扁平流中创建的。
因为 rand.ints() 产生的是一个 IntStream,所以我必须使用 flatMap()、concat() 和 of() 的特定整数形式。
让我们再看一下将文件划分为单词流的任务。我们最后使用到的是 FileToWordsRegexp.java,它的问题是需要将整个文件读入行列表中 —— 显然需要存储该列表。而我们真正想要的是创建一个不需要中间存储层的单词流。
下面,我们再使用 flatMap() 来解决这个问题:
import java.nio.file.*;
import java.util.stream.*;
import java.util.regex.Pattern;
public class FileToWords {
public static Stream<String> stream(String filePath) throws Exception {
return Files.lines(Paths.get(filePath))
.skip(1) // First (comment) line
.flatMap(line ->
Pattern.compile("\\W+").splitAsStream(line));
}
}
stream() 现在是一个静态方法,因为它可以自己完成整个流创建过程。
注意:\\W+ 是一个正则表达式。表示“非单词字符”,+ 表示“可以出现一次或者多次”。小写形式的 \\w 表示“单词字符”。
我们之前遇到的问题是 Pattern.compile().splitAsStream() 产生的结果为流,这意味着当我们只是想要一个简单的单词流时,在传入的行流(stream of lines)上调用 map() 会产生一个单词流的流。幸运的是,flatMap() 可以将元素流的流扁平化为一个简单的元素流。或者,我们可以使用 String.split() 生成一个数组,其可以被 Arrays.stream() 转化成为流:
.flatMap(line -> Arrays.stream(line.split("\\W+"))))
因为有了真正的流(而不是FileToWordsRegexp.java 中基于集合存储的流),所以每次需要一个新的流时,我们都必须从头开始创建,因为流不能被复用:
public class FileToWordsTest {
public static void main(String[] args) throws Exception {
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.limit(7)
.forEach(s -> System.out.format("%s ", s));
System.out.println();
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.skip(7)
.limit(2)
.forEach(s -> System.out.format("%s ", s));
}
}
输出结果:
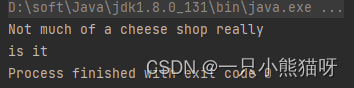
在 System.out.format() 中的 %s 表明参数为 String 类型。