文章目录
- 一、题目链接
- 二、准备工作
- 三、SQL 语句执行流程
- 四、BusTub 表结构
- 五、Task #1 - Access Method Executors
- 5.1 顺序扫描执行器
- 5.2 插入执行器
- 5.3 删除执行器
- 5.4 索引扫描执行器
- 六、Task #2 - Aggregation & Join Executors
- 6.1 聚合执行器
- 6.2 循环连接执行器
- 6.3 索引连接执行器
- 七、评测结果

一、题目链接
二、准备工作
Project #3 中的执行器需要通过 sqllogictest 进行测试,执行以下三条命令即可完成编译及运行:
atreus@AtreusMBP 9:18 bustub % cd build
atreus@AtreusMBP 9:18 build % make -j$(nproc) sqllogictest
atreus@AtreusMBP 9:19 build % ./bin/bustub-sqllogictest ../test/sql/p3.06-simple-agg.slt --verbose
此外也可以通过 CLion 进行运行和调试,具体配置如下,其中程序实参中的 slt 文件路径与工作目录需要根据自己的项目结构进行修改,建议自己新建一个 slt 文件专门用于调试,这样每次只要修改这个自定义 slt 文件的内容即可,而不需要修改编译参数。

其他准备工作见 CMU 15-445 Project #0 - C++ Primer 中的准备工作。
三、SQL 语句执行流程

根据 bustub 的架构图,在收到一条 SQL 语句后,查询处理层首先会通过解析器 Parser 将 SQL 语句解析为一颗抽象句法树 AST(Abstracct Syntax Tree)。接下来绑定器 Binder 会遍历这棵句法树,将表名、列名等映射到数据库中的实际对象上,并由计划器 Planner 生成初步的查询计划。查询计划会以树的形式表示,数据从叶子节点流向父节点。最后,优化器 Optimizer 会优化生成最终的查询计划,然后交由查询执行层的执行器执行,而这里面的部分执行器需要我们来实现。
以下面的 explain select * from test_1; 为例,绑定器将表名 test_1 绑定到 oid 为 20 的 test_1 实体表中,将 * 绑定到该表的所有列上。接下来计划器会生成对应的查询计划,这个查询计划包括 Projection 和 SeqScan 两个计划节点,数据会先由 SeqScan 处理,然后交给 Projection 处理。不过最后优化器会优化掉这里的投影操作,因为要查找的是所有字段,并不需要进行投影运算。最终,查询执行层会执行 SeqScan 对应的执行器完成实际的查询。
bustub> explain select * from test_1;
=== BINDER ===
BoundSelect {
table=BoundBaseTableRef { table=test_1, oid=20 },
columns=[test_1.colA, test_1.colB, test_1.colC, test_1.colD],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
=== OPTIMIZER ===
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)bustub> explain select * from test_1;
四、BusTub 表结构
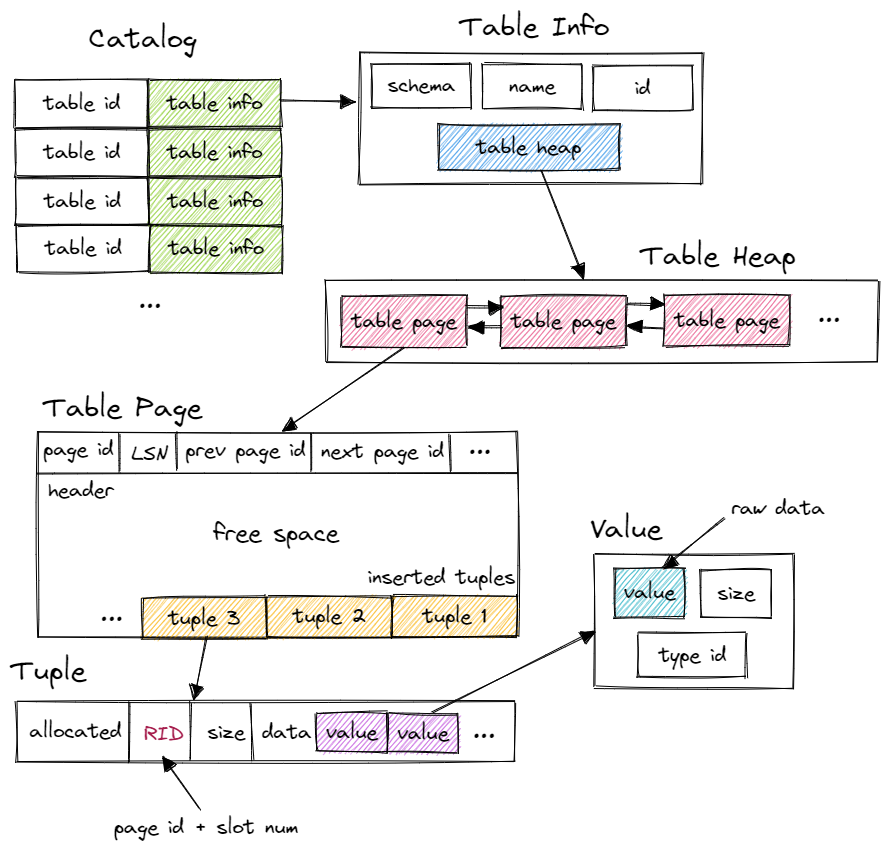
以上图片来自于 https://blog.eleven.wiki/posts/cmu15-445-project3-query-execution/,这位博主对 BusTub 中的表结构进行了直观的说明。
首先,我们从所有执行器的基类抽象执行器 AbstractExecutor 入手,抽象执行器实现了一个 tuple-at-a-time 形式的火山迭代器模型,它主要包括 Init() 和 Next() 两个成员函数,tuple-at-a-time 表明每次调用 Next() 函数会从当前执行器获取一个 tuple,火山模型则表明数据从子执行器向父执行器传递,根节点的输出即为最终的执行结果。
AbstractExecutor 只有执行器上下文 ExecutorContext 这一个成员变量,它包括当前事务 Transaction、缓冲池管理器 BufferPoolManager、事务管理器 TransactionManager、锁管理器 LockManager 以及目录 Catalog。不过在抽象执行器的实现类中,除了执行器上下文往往还会有一个计划节点 AbstractPlanNode 的实现类,用于表明将要执行的计划,这个后续也会被用到。
与表管理直接相关的就是执行器上下文中的目录 Catalog(见上图),在 DBMS 中,目录通常是非持久的,主要为数据库执行引擎中的执行器而设计。它可以解决表创建、表查找、索引创建和索引查找等操作。目录中主要包含了一个表标识符到表信息 TableInfo 的映射 std::unordered_map<table_oid_t, std::unique_ptr<TableInfo>> 和一个表名到表标识符的映射 std::unordered_map<std::string, table_oid_t>。
表信息 TableInfo 主要保存了有关表的一些元数据,其中最主要的就是 TableHeap,TableHeap 表示磁盘上的物理表,它是一个双向链表的页集合,通过 TableHeap 即可得到首个表页面 TablePage 中首个元组 Tuple(每个元组对应表中的一行数据)的迭代器,从而实现表遍历。
一个物理页面的大小为 4096 字节,其内部结构大致如下:
+-------------------+-------------------+ -----------------
| PageID(4) | LSN(4) |
+-------------------+-------------------+
| PrevPageId(4) | NextPageId(4) |
+-------------------+-------------------+
|FreeSpacePointer(4)| TupleCount(4) |
+-------------------+-------------------+
| Tuple_1 offset(4) | Tuple_1 size(4) | HEADER
+-------------------+-------------------+
| Tuple_2 offset(4) | Tuple_2 size(4) |
+-------------------+-------------------+
| Tuple_3 offset(4) | Tuple_3 size(4) |
+-------------------+-------------------+ -----------------
| ... |
+---------------------------------------+ FREE SPACE
| ... |
+---------------------------------------+ -----------------
| Tuple_3 |
+-------------------------+-------------+ INSERTED TUPLES
| Tuple_2 | Tuple_1 |
+-------------------------+-------------+ -----------------
五、Task #1 - Access Method Executors
5.1 顺序扫描执行器
bustub> explain select * from test_1;
=== BINDER ===
BoundSelect {
table=BoundBaseTableRef { table=test_1, oid=20 },
columns=[test_1.colA, test_1.colB, test_1.colC, test_1.colD],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
=== OPTIMIZER ===
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)bustub> explain select * from test_1;
/**
* The SeqScanExecutor executor executes a sequential table scan.
*/
class SeqScanExecutor : public AbstractExecutor {
public:
/**
* Construct a new SeqScanExecutor instance.
* @param exec_ctx The executor context
* @param plan The sequential scan plan to be executed
*/
SeqScanExecutor(ExecutorContext *exec_ctx, const SeqScanPlanNode *plan)
: AbstractExecutor(exec_ctx), plan_(plan), table_iter_(nullptr, RID(), nullptr) {}
/** Initialize the sequential scan */
void Init() override {
TableInfo *table_info = exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid());
table_heap_ = dynamic_cast<TableHeap *>(table_info->table_.get());
table_iter_ = table_heap_->Begin(exec_ctx_->GetTransaction());
}
/**
* Yield the next tuple from the sequential scan.
* @param[out] tuple The next tuple produced by the scan
* @param[out] rid The next tuple RID produced by the scan
* @return `true` if a tuple was produced, `false` if there are no more tuples
*/
auto Next(Tuple *tuple, RID *rid) -> bool override {
// 遍历结束返回 false
if (table_iter_ == table_heap_->End()) {
return false;
}
// 填充元组信息及元组的 rid
*tuple = *table_iter_;
*rid = tuple->GetRid();
table_iter_++;
return true;
}
/** @return The output schema for the sequential scan */
auto GetOutputSchema() const -> const Schema & override {
return plan_->OutputSchema();
}
private:
/** The sequential scan plan node to be executed */
const SeqScanPlanNode *plan_;
/** 待扫描表的表堆 */
TableHeap *table_heap_;
/** 待扫描表的迭代器 */
TableIterator table_iter_;
};
5.2 插入执行器
bustub> explain insert into test_1 values (1000, 1, 1, 1);
=== BINDER ===
BoundInsert {
table=BoundBaseTableRef { table=test_1, oid=20 },
select= BoundSelect {
table=BoundExpressionListRef { identifier=__values#0, values=[[1000, 1, 1, 1]] },
columns=[__values#0.0, __values#0.1, __values#0.2, __values#0.3],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
}
=== PLANNER ===
Insert { table_oid=20 } | (__bustub_internal.insert_rows:INTEGER)
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (__values#0.0:INTEGER, __values#0.1:INTEGER, __values#0.2:INTEGER, __values#0.3:INTEGER)
Values { rows=1 } | (__values#0.0:INTEGER, __values#0.1:INTEGER, __values#0.2:INTEGER, __values#0.3:INTEGER)
=== OPTIMIZER ===
Insert { table_oid=20 } | (__bustub_internal.insert_rows:INTEGER)
Values { rows=1 } | (__values#0.0:INTEGER, __values#0.1:INTEGER, __values#0.2:INTEGER, __values#0.3:INTEGER)
/**
* InsertExecutor executes an insert on a table.
* Inserted values are always pulled from a child executor.
*/
class InsertExecutor : public AbstractExecutor {
public:
/**
* Construct a new InsertExecutor instance.
* @param exec_ctx The executor context
* @param plan The insert plan to be executed
* @param child_executor The child executor from which inserted tuples are pulled
*/
InsertExecutor(ExecutorContext *exec_ctx, const InsertPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor)
: AbstractExecutor(exec_ctx), plan_(plan), child_executor_(std::move(child_executor)) {}
/** Initialize the insert */
void Init() override {
child_executor_->Init();
}
/**
* Yield the number of rows inserted into the table.
* @param[out] tuple The integer tuple indicating the number of rows inserted into the table
* @param[out] rid The next tuple RID produced by the insert (ignore, not used)
* @return `true` if a tuple was produced, `false` if there are no more tuples
*
* NOTE: InsertExecutor::Next() does not use the `rid` out-parameter.
* NOTE: InsertExecutor::Next() returns true with number of inserted rows produced only once.
*/
auto Next([[maybe_unused]] Tuple *tuple, RID *rid) -> bool override {
// 插入完毕返回 false
if (has_inserted_) {
return false;
}
has_inserted_ = true;
// 获取待插入的表信息及其索引列表
TableInfo *table_info = exec_ctx_->GetCatalog()->GetTable(plan_->TableOid());
std::vector<IndexInfo *> index_info = exec_ctx_->GetCatalog()->GetTableIndexes(table_info->name_);
// 从子执行器 Values 中逐个获取元组并插入到表中,同时更新所有的索引
int insert_count = 0;
while (child_executor_->Next(tuple, rid)) {
table_info->table_->InsertTuple(*tuple, rid, exec_ctx_->GetTransaction());
for (const auto &index: index_info) {
// 根据索引的模式从数据元组中构造索引元组,并插入到索引中
Tuple key_tuple = tuple->KeyFromTuple(child_executor_->GetOutputSchema(), index->key_schema_,
index->index_->GetMetadata()->GetKeyAttrs());
index->index_->InsertEntry(key_tuple, *rid, exec_ctx_->GetTransaction());
}
insert_count++;
}
// 这里的 tuple 不再对应实际的数据行,而是用来存储插入操作的影响行数
std::vector<Value> result{Value(INTEGER, insert_count)};
*tuple = Tuple(result, &plan_->OutputSchema());
return true;
}
/** @return The output schema for the insert */
auto GetOutputSchema() const -> const Schema & override {
return plan_->OutputSchema();
};
private:
/** The insert plan node to be executed */
const InsertPlanNode *plan_;
/** 子执行器,对于插入操作来说通常是 Values 执行器 */
std::unique_ptr<AbstractExecutor> child_executor_;
/** 标识是否已经完成插入操作 */
bool has_inserted_ = false;
};
5.3 删除执行器
bustub> explain delete from test_1 where colA = 1000;
=== BINDER ===
Delete { table=BoundBaseTableRef { table=test_1, oid=20 }, expr=(test_1.colA=1000) }
=== PLANNER ===
Delete { table_oid=20 } | (__bustub_internal.delete_rows:INTEGER)
Filter { predicate=(#0.0=1000) } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
=== OPTIMIZER ===
Delete { table_oid=20 } | (__bustub_internal.delete_rows:INTEGER)
SeqScan { table=test_1, filter=(#0.0=1000) } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
/**
* DeletedExecutor executes a delete on a table.
* Deleted values are always pulled from a child.
*/
class DeleteExecutor : public AbstractExecutor {
public:
/**
* Construct a new DeleteExecutor instance.
* @param exec_ctx The executor context
* @param plan The delete plan to be executed
* @param child_executor The child executor that feeds the delete
*/
DeleteExecutor(ExecutorContext *exec_ctx, const DeletePlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor)
: AbstractExecutor(exec_ctx), plan_(plan), child_executor_(std::move(child_executor)) {}
/** Initialize the delete */
void Init() override {
child_executor_->Init();
}
/**
* Yield the number of rows deleted from the table.
* @param[out] tuple The integer tuple indicating the number of rows deleted from the table
* @param[out] rid The next tuple RID produced by the delete (ignore, not used)
* @return `true` if a tuple was produced, `false` if there are no more tuples
*
* NOTE: DeleteExecutor::Next() does not use the `rid` out-parameter.
* NOTE: DeleteExecutor::Next() returns true with the number of deleted rows produced only once.
*/
auto Next([[maybe_unused]] Tuple *tuple, RID *rid) -> bool override {
// 删除完毕返回 false
if (has_deleted_) {
return false;
}
has_deleted_ = true;
// 获取待删除的表信息及其索引列表
TableInfo *table_info = exec_ctx_->GetCatalog()->GetTable(plan_->TableOid());
std::vector<IndexInfo *> index_info = exec_ctx_->GetCatalog()->GetTableIndexes(table_info->name_);
// 从子执行器 Values 中逐个获取元组并插入到表中,同时更新所有的索引
int delete_count = 0;
while (child_executor_->Next(tuple, rid)) {
table_info->table_->MarkDelete(*rid, exec_ctx_->GetTransaction());
for (const auto &index: index_info) {
// 根据索引的模式从数据元组中构造索引元组,并从索引中删除
Tuple key_tuple = tuple->KeyFromTuple(child_executor_->GetOutputSchema(), index->key_schema_,
index->index_->GetMetadata()->GetKeyAttrs());
index->index_->DeleteEntry(key_tuple, *rid, exec_ctx_->GetTransaction());
}
delete_count++;
}
// 这里的 tuple 不再对应实际的数据行,而是用来存储插入操作的影响行数
std::vector<Value> result{Value(INTEGER, delete_count)};
*tuple = Tuple(result, &plan_->OutputSchema());
return true;
}
/** @return The output schema for the delete */
auto GetOutputSchema() const -> const Schema & override {
return plan_->OutputSchema();
};
private:
/** The delete plan node to be executed */
const DeletePlanNode *plan_;
/** The child executor from which RIDs for deleted tuples are pulled */
std::unique_ptr<AbstractExecutor> child_executor_;
/** 标识是否已经完成删除操作 */
bool has_deleted_ = false;
};
5.4 索引扫描执行器
bustub> create index index_colA on test_1(colA);
Index created with id = 0
bustub> explain select * from test_1 order by colA;
=== BINDER ===
BoundSelect {
table=BoundBaseTableRef { table=test_1, oid=20 },
columns=[test_1.colA, test_1.colB, test_1.colC, test_1.colD],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[BoundOrderBy { type=Default, expr=test_1.colA }],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Sort { order_bys=[(Default, #0.0)] } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
=== OPTIMIZER ===
IndexScan { index_oid=0 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
/**
* IndexScanExecutor executes an index scan over a table.
*/
class IndexScanExecutor : public AbstractExecutor {
public:
/**
* Creates a new index scan executor.
* @param exec_ctx the executor context
* @param plan the index scan plan to be executed
*/
IndexScanExecutor(ExecutorContext *exec_ctx, const IndexScanPlanNode *plan)
: AbstractExecutor(exec_ctx), plan_(plan) {}
void Init() override {
IndexInfo *index_info = exec_ctx_->GetCatalog()->GetIndex(plan_->GetIndexOid());
tree_ = dynamic_cast<BPlusTreeIndexForOneIntegerColumn *>(index_info->index_.get());
table_iter_ = tree_->GetBeginIterator();
table_heap_ = exec_ctx_->GetCatalog()->GetTable(index_info->table_name_)->table_.get();
}
auto Next(Tuple *tuple, RID *rid) -> bool override {
// 遍历结束返回 false
if (table_iter_ == tree_->GetEndIterator()) {
return false;
}
// 获取元组的 rid 并填充元组内容
*rid = (*table_iter_).second;
table_heap_->GetTuple(*rid, tuple, exec_ctx_->GetTransaction());
++table_iter_;
return true;
}
auto GetOutputSchema() const -> const Schema & override {
return plan_->OutputSchema();
}
private:
/** The index scan plan node to be executed. */
const IndexScanPlanNode *plan_;
/** 待扫描表的 B+ 树索引 */
BPlusTreeIndexForOneIntegerColumn *tree_;
/** 待扫描表的 B+ 树索引迭代器 */
BPlusTreeIndexIteratorForOneIntegerColumn table_iter_;
/** 待扫描表的表堆 */
TableHeap *table_heap_;
};
六、Task #2 - Aggregation & Join Executors
6.1 聚合执行器
bustub> explain select sum(colA) from test_1;
=== BINDER ===
BoundSelect {
table=BoundBaseTableRef { table=test_1, oid=20 },
columns=[sum([test_1.colA])],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0] } | (<unnamed>:INTEGER)
Agg { types=[sum], aggregates=[#0.0], group_by=[] } | (agg#0:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
=== OPTIMIZER ===
Agg { types=[sum], aggregates=[#0.0], group_by=[] } | (<unnamed>:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
| id | name | position | camp |
|---|---|---|---|
| 0 | Ezreal | ADC | Piltover |
| 1 | Vi | JUN | Piltover |
| 2 | Jayce | TOP | Piltover |
| 3 | Zed | MID | Ionia |
| 4 | Xayah | ADC | Ionia |
| 5 | Thresh | SUP | Shadow Isles |
我们以分组聚合查询语句 select count(name) from table group by camp; 为例简要说明一下聚合执行器的执行流程:
Init()函数首先从子执行器中逐行获取数据,并根据每行数据构建聚合键和聚合值。其中聚合键用于标识该行数据属于哪一个聚合组,这里是按照阵营camp分组,因此聚合键会有Piltover、Ionia和Shadow Isles三种取值,这样所有数据被分成三个聚合组。当然,如果没group by子句,那么所有数据都会被分到同一个聚合组中,这个聚合组的聚合键为一个group_bys_.size() = 0的AggregateKey。而聚合值就是待聚合的列的值,这里的聚合列是name,因此这五个 Tuple 中生成的聚合值即为对应的name属性的值。- 对于每个提取的数据行,
Init()函数还会通过InsertCombine()将相应的聚合值聚合到到相应的聚合组中。具体的聚合规则由CombineAggregateValues()函数中的实现来决定。 - 经过
Init()函数的处理,以上六条数据会被整理为[{"Piltover": 3}, {"Ionia": 2}, {"Shadow Isles": 1}]三个聚合组(对应于聚合哈希表中的三个键值对)。 - 最后,
Next()函数会通过哈希迭代器依次获取每个聚合组的键与值,返回给父执行器。
/**
* A simplified hash table that has all the necessary functionality for aggregations.
*/
class SimpleAggregationHashTable {
public:
/**
* Construct a new SimpleAggregationHashTable instance.
* @param agg_exprs the aggregation expressions
* @param agg_types the types of aggregations
*/
SimpleAggregationHashTable(const std::vector<AbstractExpressionRef> &agg_exprs,
const std::vector<AggregationType> &agg_types)
: agg_exprs_{agg_exprs}, agg_types_{agg_types} {}
/** @return The initial aggregate value for this aggregation executor */
auto GenerateInitialAggregateValue() -> AggregateValue {
std::vector<Value> values{};
for (const auto &agg_type: agg_types_) {
switch (agg_type) {
case AggregationType::CountStarAggregate:
// Count start starts at zero.
values.emplace_back(ValueFactory::GetIntegerValue(0));
break;
case AggregationType::CountAggregate:
case AggregationType::SumAggregate:
case AggregationType::MinAggregate:
case AggregationType::MaxAggregate:
// Others starts at null.
values.emplace_back(ValueFactory::GetNullValueByType(TypeId::INTEGER));
break;
}
}
return {values};
}
/**
* Combines the input into the aggregation result.
* @param[out] result The output aggregate value
* @param input The input value
*/
void CombineAggregateValues(AggregateValue *result, const AggregateValue &input) {
for (uint32_t i = 0; i < agg_exprs_.size(); i++) {
auto &result_value = result->aggregates_[i];
auto &input_value = input.aggregates_[i];
switch (agg_types_[i]) {
case AggregationType::CountStarAggregate:
// count(*) 对每一行都执行 +1 操作
result_value = result_value.Add(ValueFactory::GetIntegerValue(1));
break;
case AggregationType::CountAggregate:
// count(column) 只对非空行进行 +1 操作,同时 bustub 不支持 count(distinct column) 聚合操作
if (!input_value.IsNull()) {
// 如果 result_value 为空需要从 ValueFactory 中获取
if (result_value.IsNull()) {
result_value = ValueFactory::GetIntegerValue(0);
}
result_value = result_value.Add(ValueFactory::GetIntegerValue(1));
}
break;
case AggregationType::SumAggregate:
// sum(column) 只处理非空行
if (!input_value.IsNull()) {
// 如果 result_value 为空初始化为 input_value ,否则直接累加
if (result_value.IsNull()) {
result_value = input_value;
} else {
result_value = result_value.Add(input_value);
}
}
break;
case AggregationType::MinAggregate:
// min(column) 只处理非空行
if (!input_value.IsNull()) {
// 如果 result_value 为空初始化为 input_value ,否则取最小值
if (result_value.IsNull()) {
result_value = input_value;
} else {
result_value = result_value.Min(input_value);
}
}
break;
case AggregationType::MaxAggregate:
// max(column) 只处理非空行
if (!input_value.IsNull()) {
// 如果 result_value 为空初始化为 input_value ,否则取最大值
if (result_value.IsNull()) {
result_value = input_value;
} else {
result_value = result_value.Max(input_value);
}
}
break;
default:
throw Exception("unknown AggregationType");
}
}
}
/**
* 检查当前表是否为空,如果为空生成默认的聚合值,对于 count(*) 来说是 0,对于其他聚合函数来说是 integer_null
* 等指定了具体类型的空值。 之所以要进行这次额外检查,是因为空表的聚合操作不是没有返回值,而是返回了一个默认的聚合值。
*
* @param[out] value 对应于不同聚合操作生成的初始聚合值。
* @return `true` 当前表为空,需要返回一个初始聚合值,`false` 不需要返回初始聚合值。
*/
auto CheckIsNullTable(AggregateValue *value) -> bool {
// 从未检查过或者表不为空
if (is_checked_ || !ht_.empty()) {
return false;
}
is_checked_ = true;
// 遍历聚合表达式列表,为每个聚合函数生成初始的聚合值
for (size_t i = 0; i < agg_exprs_.size(); i++) {
*value = GenerateInitialAggregateValue();
}
return true;
}
/**
* Inserts a value into the hash table and then combines it with the current aggregation.
* @param agg_key the key to be inserted
* @param agg_val the value to be inserted
*/
void InsertCombine(const AggregateKey &agg_key, const AggregateValue &agg_val) {
if (ht_.count(agg_key) == 0) {
ht_.insert({agg_key, GenerateInitialAggregateValue()});
}
CombineAggregateValues(&ht_[agg_key], agg_val);
}
/**
* Clear the hash table
*/
void Clear() { ht_.clear(); }
/** An iterator over the aggregation hash table */
class Iterator {
public:
/** Creates an iterator for the aggregate map. */
explicit Iterator(std::unordered_map<AggregateKey, AggregateValue>::const_iterator iter) : iter_{iter} {}
/** @return The key of the iterator */
auto Key() -> const AggregateKey & { return iter_->first; }
/** @return The value of the iterator */
auto Val() -> const AggregateValue & { return iter_->second; }
/** @return The iterator before it is incremented */
auto operator++() -> Iterator & {
++iter_;
return *this;
}
/** @return `true` if both iterators are identical */
auto operator==(const Iterator &other) -> bool { return this->iter_ == other.iter_; }
/** @return `true` if both iterators are different */
auto operator!=(const Iterator &other) -> bool { return this->iter_ != other.iter_; }
private:
/** Aggregates map */
std::unordered_map<AggregateKey, AggregateValue>::const_iterator iter_;
};
/** @return Iterator to the start of the hash table */
auto Begin() -> Iterator { return Iterator{ht_.cbegin()}; }
/** @return Iterator to the end of the hash table */
auto End() -> Iterator { return Iterator{ht_.cend()}; }
private:
/** The hash table is just a map from aggregate keys to aggregate values */
std::unordered_map<AggregateKey, AggregateValue> ht_{};
/** The aggregate expressions that we have */
const std::vector<AbstractExpressionRef> &agg_exprs_;
/** The types of aggregations that we have */
const std::vector<AggregationType> &agg_types_;
/** 标识是否进行过空表检查 */
bool is_checked_ = false;
};
/**
* AggregationExecutor executes an aggregation operation (e.g. COUNT, SUM, MIN, MAX)
* over the tuples produced by a child executor.
*/
class AggregationExecutor : public AbstractExecutor {
public:
/**
* Construct a new AggregationExecutor instance.
* @param exec_ctx The executor context
* @param plan The insert plan to be executed
* @param child_executor The child executor from which inserted tuples are pulled (may be `nullptr`)
*/
AggregationExecutor(ExecutorContext *exec_ctx, const AggregationPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child)
: AbstractExecutor(exec_ctx),
plan_(plan),
child_(std::move(child)),
aht_(plan->GetAggregates(), plan->GetAggregateTypes()),
aht_iterator_(aht_.Begin()) {}
/** Initialize the aggregation */
void Init() override {
child_->Init();
Tuple tuple;
RID rid;
// 将每个 tuple 分配到指定的聚合分组,并更新该分组的聚合值
while (child_->Next(&tuple, &rid)) {
// 获取该 tuple 对应聚合键,这个聚合键表明了它的所属分组,聚合键的本质是用于分组的列的值
AggregateKey agg_key = this->MakeAggregateKey(&tuple);
// 获取该 tuple 对应的聚合值,聚合值的本质是待聚合的列的值
AggregateValue agg_value = this->MakeAggregateValue(&tuple);
// 将该 tuple 的聚合值合并到对应聚合分组的聚合值中,对于不同的聚合函数有不同的聚合方式
aht_.InsertCombine(agg_key, agg_value);
}
aht_iterator_ = aht_.Begin();
}
/**
* Yield the next tuple from the insert.
* @param[out] tuple The next tuple produced by the aggregation
* @param[out] rid The next tuple RID produced by the aggregation
* @return `true` if a tuple was produced, `false` if there are no more tuples
*/
auto Next(Tuple *tuple, RID *rid) -> bool override {
if (aht_iterator_ == aht_.End()) {
// 如果存在 group by 子句,则不需要对每个分组的聚合结果进行进一步的聚合
if (!plan_->GetGroupBys().empty()) {
return false;
}
AggregateValue result_value;
// 如果对空表执行聚合操作直接返回初始化后的元组
if (aht_.CheckIsNullTable(&result_value)) {
*tuple = Tuple(result_value.aggregates_, &plan_->OutputSchema());
*rid = tuple->GetRid();
return true;
}
return false;
}
// 获取当前迭代器对应聚合分组的聚合键和和聚合值
AggregateKey agg_key = aht_iterator_.Key();
AggregateValue agg_value = aht_iterator_.Val();
std::vector<Value> values;
values.reserve(agg_key.group_bys_.size() + agg_value.aggregates_.size());
// 向结果集中追加聚合分组的键
for (const auto &group_by_key: agg_key.group_bys_) {
values.emplace_back(group_by_key);
}
// 向结果集中追加聚合分组的聚合值
for (const auto &group_by_value: agg_value.aggregates_) {
values.emplace_back(group_by_value);
}
*tuple = Tuple(values, &plan_->OutputSchema());
*rid = tuple->GetRid();
++aht_iterator_;
return true;
}
/** @return The output schema for the aggregation */
auto GetOutputSchema() const -> const Schema & override { return plan_->OutputSchema(); };
/** Do not use or remove this function, otherwise you will get zero points. */
auto GetChildExecutor() const -> const AbstractExecutor * { return child_.get(); }
private:
/** @return The tuple as an AggregateKey */
auto MakeAggregateKey(const Tuple *tuple) -> AggregateKey {
std::vector<Value> keys;
for (const auto &expr: plan_->GetGroupBys()) {
keys.emplace_back(expr->Evaluate(tuple, child_->GetOutputSchema()));
}
return {keys};
}
/** @return The tuple as an AggregateValue */
auto MakeAggregateValue(const Tuple *tuple) -> AggregateValue {
std::vector<Value> vals;
for (const auto &expr: plan_->GetAggregates()) {
vals.emplace_back(expr->Evaluate(tuple, child_->GetOutputSchema()));
}
return {vals};
}
private:
/** The aggregation plan node */
const AggregationPlanNode *plan_;
/** The child executor that produces tuples over which the aggregation is computed */
std::unique_ptr<AbstractExecutor> child_;
/** Simple aggregation hash table */
SimpleAggregationHashTable aht_;
/** Simple aggregation hash table iterator */
SimpleAggregationHashTable::Iterator aht_iterator_;
};
一个用于演示分组聚合和空表聚合执行流程的测试用例:
statement ok
create table legends(name varchar(128), camp varchar(128));
statement ok
insert into legends values ('Ezreal', 'Piltover'), ('Vi', 'Piltover'), ('Jayce', 'Piltover'), ('Zed', 'Ionia'), ('Xayah', 'Ionia');
statement ok
select count(name) from legends group by camp;
statement ok
delete from legends;
query
select count(*) from legends;
----
0
query
select count(camp) from legends;
----
integer_null
6.2 循环连接执行器
bustub> EXPLAIN SELECT * FROM test_1 LEFT OUTER JOIN test_2 ON test_1.colA = test_2.colA;
=== BINDER ===
BoundSelect {
table=BoundJoin { type=Left, left=BoundBaseTableRef { table=test_1, oid=20 }, right=BoundBaseTableRef { table=test_2, oid=21 }, condition=(test_1.colA=test_2.colA) },
columns=[test_1.colA, test_1.colB, test_1.colC, test_1.colD, test_2.colA, test_2.colB, test_2.colC],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3, #0.4, #0.5, #0.6] } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER, test_2.colA:INTEGER, test_2.colB:INTEGER, test_2.colC:INTEGER)
NestedLoopJoin { type=Left, predicate=(#0.0=#1.0) } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER, test_2.colA:INTEGER, test_2.colB:INTEGER, test_2.colC:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_2 } | (test_2.colA:INTEGER, test_2.colB:INTEGER, test_2.colC:INTEGER)
=== OPTIMIZER ===
HashJoin { type=Left, left_key=#0.0, right_key=#0.0 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER, test_2.colA:INTEGER, test_2.colB:INTEGER, test_2.colC:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
SeqScan { table=test_2 } | (test_2.colA:INTEGER, test_2.colB:INTEGER, test_2.colC:INTEGER)
数据库中的连接运算
/**
* NestedLoopJoinExecutor executes a nested-loop JOIN on two tables.
*/
class NestedLoopJoinExecutor : public AbstractExecutor {
public:
/**
* Construct a new NestedLoopJoinExecutor instance.
* @param exec_ctx The executor context
* @param plan The NestedLoop join plan to be executed
* @param left_executor The child executor that produces tuple for the left side of join
* @param right_executor The child executor that produces tuple for the right side of join
*/
NestedLoopJoinExecutor(ExecutorContext *exec_ctx, const NestedLoopJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&left_executor,
std::unique_ptr<AbstractExecutor> &&right_executor)
: AbstractExecutor(exec_ctx),
plan_(plan),
left_executor_(std::move(left_executor)),
right_executor_(std::move(right_executor)) {}
/** Initialize the join */
void Init() override {
left_executor_->Init();
right_executor_->Init();
// 从 left_executor_ 和 right_executor_ 中获取两张表中的所有元组
Tuple tuple;
RID rid;
std::vector<Tuple> left_tuples;
std::vector<Tuple> right_tuples;
while (left_executor_->Next(&tuple, &rid)) {
left_tuples.emplace_back(tuple);
}
while (right_executor_->Next(&tuple, &rid)) {
right_tuples.emplace_back(tuple);
}
// 依次连接 left_tuples 和 right_tuples 中的所有元组
Schema left_schema = left_executor_->GetOutputSchema();
Schema right_schema = right_executor_->GetOutputSchema();
for (auto &left_tuple: left_tuples) {
// 标识 left_tuple 是否需要进行左外连接
bool need_left_join = true;
for (auto &right_tuple: right_tuples) {
// 如果 left_tuple 中的连接字段与 right_tuple 中的连接字段的值相匹配,则 left_tuple 不需要进行左外连接
Value join_result = plan_->predicate_->EvaluateJoin(&left_tuple, left_schema, &right_tuple, right_schema);
if (!join_result.IsNull() && join_result.GetAs<bool>()) {
// left_tuple 不需要进行左外连接
need_left_join = false;
// 依次将 left_tuple 和 right_tuple 中的值追加到结果集中
std::vector<Value> values;
for (size_t i = 0; i < left_schema.GetColumnCount(); i++) {
values.emplace_back(left_tuple.GetValue(&left_schema, i));
}
for (size_t i = 0; i < right_schema.GetColumnCount(); i++) {
values.emplace_back(right_tuple.GetValue(&right_schema, i));
}
results_.emplace(values, &plan_->OutputSchema());
}
}
// 对 left_tuple 进行左外连接,right_tuple 中的字段均以对应的空值追加到结果集中
if (need_left_join && plan_->GetJoinType() == JoinType::LEFT) {
std::vector<Value> values;
for (size_t i = 0; i < left_schema.GetColumnCount(); i++) {
values.emplace_back(left_tuple.GetValue(&left_schema, i));
}
for (size_t i = 0; i < right_schema.GetColumnCount(); i++) {
values.emplace_back(ValueFactory::GetNullValueByType(right_schema.GetColumn(i).GetType()));
}
results_.emplace(values, &plan_->OutputSchema());
}
}
}
/**
* Yield the next tuple from the join.
* @param[out] tuple The next tuple produced by the join
* @param[out] rid The next tuple RID produced, not used by nested loop join.
* @return `true` if a tuple was produced, `false` if there are no more tuples.
*/
auto Next(Tuple *tuple, RID *rid) -> bool override {
// 从结果集队列中依次获取所有连接后的元组
if (results_.empty()) {
return false;
}
*tuple = results_.front();
results_.pop();
*rid = tuple->GetRid();
return true;
}
/** @return The output schema for the insert */
auto GetOutputSchema() const -> const Schema & override { return plan_->OutputSchema(); };
private:
/** The NestedLoopJoin plan node to be executed. */
const NestedLoopJoinPlanNode *plan_;
/** 左表子执行器,对于循环连接操作来说通常是左表上的 Scan 执行器 */
std::unique_ptr<AbstractExecutor> left_executor_;
/** 右表子执行器,对于循环连接操作来说通常是右表上的 Scan 执行器 */
std::unique_ptr<AbstractExecutor> right_executor_;
/** 连接结果集 */
std::queue<Tuple> results_;
};
statement ok
create table provinces
(
province_name varchar(255),
country_name varchar(255),
capital_name varchar(255)
);
statement ok
insert into provinces
values ('Guangdong', 'China', 'Guangzhou'),
('Sichuan', 'China', 'Chengdu'),
('Jiangsu', 'China', 'Nanjing'),
('California', 'USA', 'Sacramento'),
('Hawaii', 'USA', 'Honolulu'),
('Texas', 'USA', 'Houston');
statement ok
create table capital
(
capital_name varchar(255),
population int
);
statement ok
insert into capital
values ('Guangzhou', 15000000),
('Nanjing', 8000000),
('Sacramento', 500000),
('Honolulu', 380000),
('Tokyo', 14000000),
('London', 9000000);
statement ok
create index capital_name_index on capital(capital_name);
query rowsort
select *
from provinces
join capital on provinces.capital_name = capital.capital_name;
----
Guangdong China Guangzhou Guangzhou 15000000
Jiangsu China Nanjing Nanjing 8000000
California USA Sacramento Sacramento 500000
Hawaii USA Honolulu Honolulu 380000
6.3 索引连接执行器
bustub> CREATE TABLE t1(v1 int, v2 int);
Table created with id = 22
bustub> CREATE TABLE t2(v3 int, v4 int);
Table created with id = 23
bustub> CREATE INDEX t2v3 on t2(v3);
Index created with id = 0
bustub> EXPLAIN SELECT * FROM t2 INNER JOIN t1 ON v1 = v3;
=== BINDER ===
BoundSelect {
table=BoundJoin { type=Inner, left=BoundBaseTableRef { table=t2, oid=23 }, right=BoundBaseTableRef { table=t1, oid=22 }, condition=(t1.v1=t2.v3) },
columns=[t2.v3, t2.v4, t1.v1, t1.v2],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (t2.v3:INTEGER, t2.v4:INTEGER, t1.v1:INTEGER, t1.v2:INTEGER)
NestedLoopJoin { type=Inner, predicate=(#1.0=#0.0) } | (t2.v3:INTEGER, t2.v4:INTEGER, t1.v1:INTEGER, t1.v2:INTEGER)
SeqScan { table=t2 } | (t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER)
=== OPTIMIZER ===
HashJoin { type=Inner, left_key=#0.0, right_key=#0.0 } | (t2.v3:INTEGER, t2.v4:INTEGER, t1.v1:INTEGER, t1.v2:INTEGER)
SeqScan { table=t2 } | (t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER)
bustub> EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON v1 = v3;
=== BINDER ===
BoundSelect {
table=BoundJoin { type=Inner, left=BoundBaseTableRef { table=t1, oid=22 }, right=BoundBaseTableRef { table=t2, oid=23 }, condition=(t1.v1=t2.v3) },
columns=[t1.v1, t1.v2, t2.v3, t2.v4],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
ctes=,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
NestedLoopJoin { type=Inner, predicate=(#0.0=#1.0) } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER)
SeqScan { table=t2 } | (t2.v3:INTEGER, t2.v4:INTEGER)
=== OPTIMIZER ===
NestedIndexJoin { type=Inner, key_predicate=#0.0, index=t2v3, index_table=t2 } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER)
/**
* IndexJoinExecutor executes index join operations.
*/
class NestIndexJoinExecutor : public AbstractExecutor {
public:
/**
* Creates a new nested index join executor.
* @param exec_ctx the context that the hash join should be performed in
* @param plan the nested index join plan node
* @param child_executor the outer table
*/
NestIndexJoinExecutor(ExecutorContext *exec_ctx, const NestedIndexJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&child_executor)
: AbstractExecutor(exec_ctx), plan_(plan), left_executor_(std::move(child_executor)) {}
auto GetOutputSchema() const -> const Schema & override {
return plan_->OutputSchema();
}
void Init() override {
left_executor_->Init();
Schema left_schema = left_executor_->GetOutputSchema();
// 获取右表中的索引
IndexInfo *right_index_info = exec_ctx_->GetCatalog()->GetIndex(plan_->GetIndexOid());
Index *right_index = right_index_info->index_.get();
TableInfo *right_table_info = exec_ctx_->GetCatalog()->GetTable(plan_->GetInnerTableOid());
Schema right_schema = right_table_info->schema_;
TableHeap *right_table = right_table_info->table_.get();
Tuple left_tuple;
RID left_rid;
while (left_executor_->Next(&left_tuple, &left_rid)) {
// 标识 left_tuple 是否需要进行左外连接
bool need_left_join = true;
// 根据左表中的连接字段的值在 right_index 中查找所有匹配的 RID
Value left_key_value = plan_->KeyPredicate()->Evaluate(&left_tuple, left_schema);
Tuple left_key_tuple = Tuple(std::vector<Value>{left_key_value}, &right_index_info->key_schema_);
std::vector<RID> result_rids;
right_index->ScanKey(left_key_tuple, &result_rids, nullptr);
// 依次处理右表中所有匹配的 RID
for (auto &right_rid: result_rids) {
// 当前左元组不需要进行左外连接
need_left_join = false;
// 依次将左元组和右元组中的值追加到结果集中
Tuple right_tuple;
right_table->GetTuple(right_rid, &right_tuple, exec_ctx_->GetTransaction());
std::vector<Value> values;
for (size_t i = 0; i < left_schema.GetColumnCount(); i++) {
values.emplace_back(left_tuple.GetValue(&left_schema, i));
}
for (size_t i = 0; i < right_schema.GetColumnCount(); i++) {
values.emplace_back(right_tuple.GetValue(&right_schema, i));
}
results_.emplace(values, &plan_->OutputSchema());
}
// 对当前左元组进行左外连接
if (need_left_join && plan_->join_type_ == JoinType::LEFT) {
std::vector<Value> values;
for (size_t i = 0; i < left_schema.GetColumnCount(); i++) {
values.emplace_back(left_tuple.GetValue(&left_schema, i));
}
for (size_t i = 0; i < right_schema.GetColumnCount(); i++) {
values.emplace_back(ValueFactory::GetNullValueByType(right_schema.GetColumn(i).GetType()));
}
results_.emplace(values, &plan_->OutputSchema());
}
}
}
auto Next(Tuple *tuple, RID *rid) -> bool override {
// 从结果集队列中依次获取所有连接后的元组
if (results_.empty()) {
return false;
}
*tuple = results_.front();
results_.pop();
*rid = tuple->GetRid();
return true;
}
private:
/** The nested index join plan node. */
const NestedIndexJoinPlanNode *plan_;
/** 左表子执行器,对于索引连接操作来说通常是左表上的 Scan 执行器 */
std::unique_ptr<AbstractExecutor> left_executor_;
/** 连接结果集 */
std::queue<Tuple> results_;
};
statement ok
create table provinces
(
province_name varchar(255),
country_name varchar(255),
capital_id int
);
statement ok
insert into provinces
values ('Guangdong', 'China', 1),
('Sichuan', 'China', 2),
('Jiangsu', 'China', 3),
('California', 'USA', 4),
('Hawaii', 'USA', 5),
('Texas', 'USA', 6);
statement ok
create table capital
(
capital_id int,
population int
);
statement ok
insert into capital
values (1, 15000000),
(3, 8000000),
(4, 500000),
(5, 380000),
(7, 14000000),
(8, 9000000);
statement ok
create index capital_id_index on capital(capital_id);
query rowsort
select *
from provinces
join capital on provinces.capital_id = capital.capital_id;
----
Guangdong China 1 1 15000000
Jiangsu China 3 3 8000000
California USA 4 4 500000
Hawaii USA 5 5 380000
七、评测结果

参考:
https://blog.eleven.wiki/posts/cmu15-445-project3-query-execution/
https://blog.csdn.net/AntiO2/article/details/131147264
https://www.bilibili.com/video/BV1184y137rG/