文章目录
- 一、Transformer in Transformer
- 二、Bottleneck Transformer
- 三、Pyramid Vision Transformer v2
- 四、Class-Attention in Image Transformers
- 五、Co-Scale Conv-attentional Image Transformer
- 六、XCiT
- 七、Focal Transformers
- 八、CrossViT
- 九、ConViT
- 十、CrossTransformers
- 十一、nnFormer
- 十二、VATT
- 十三、Convolution-enhanced image Transformer
- 十四、DeepViT
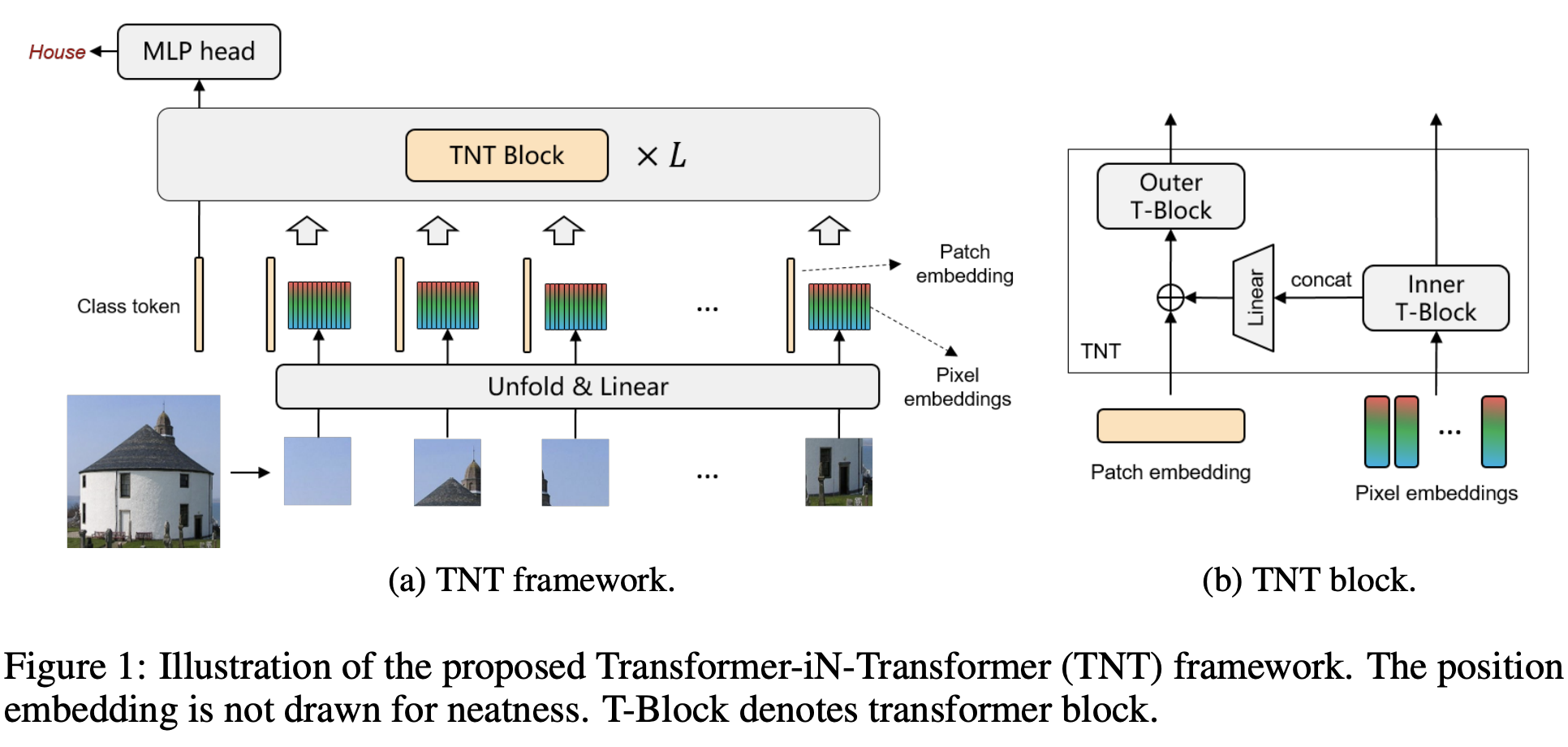
一、Transformer in Transformer
Transformer 是一种最初应用于 NLP 任务的基于自注意力的神经网络。 最近,提出了纯基于变压器的模型来解决计算机视觉问题。 这些视觉转换器通常将图像视为一系列补丁,而忽略每个补丁内部的内在结构信息。 在本文中,我们提出了一种新颖的 Transformer-iN-Transformer (TNT) 模型,用于对块级和像素级表示进行建模。 在每个 TNT 块中,外部变压器块用于处理补丁嵌入,内部变压器块从像素嵌入中提取局部特征。 像素级特征通过线性变换层投影到补丁嵌入的空间,然后添加到补丁中。 通过堆叠 TNT 块,我们构建了用于图像识别的 TNT 模型。
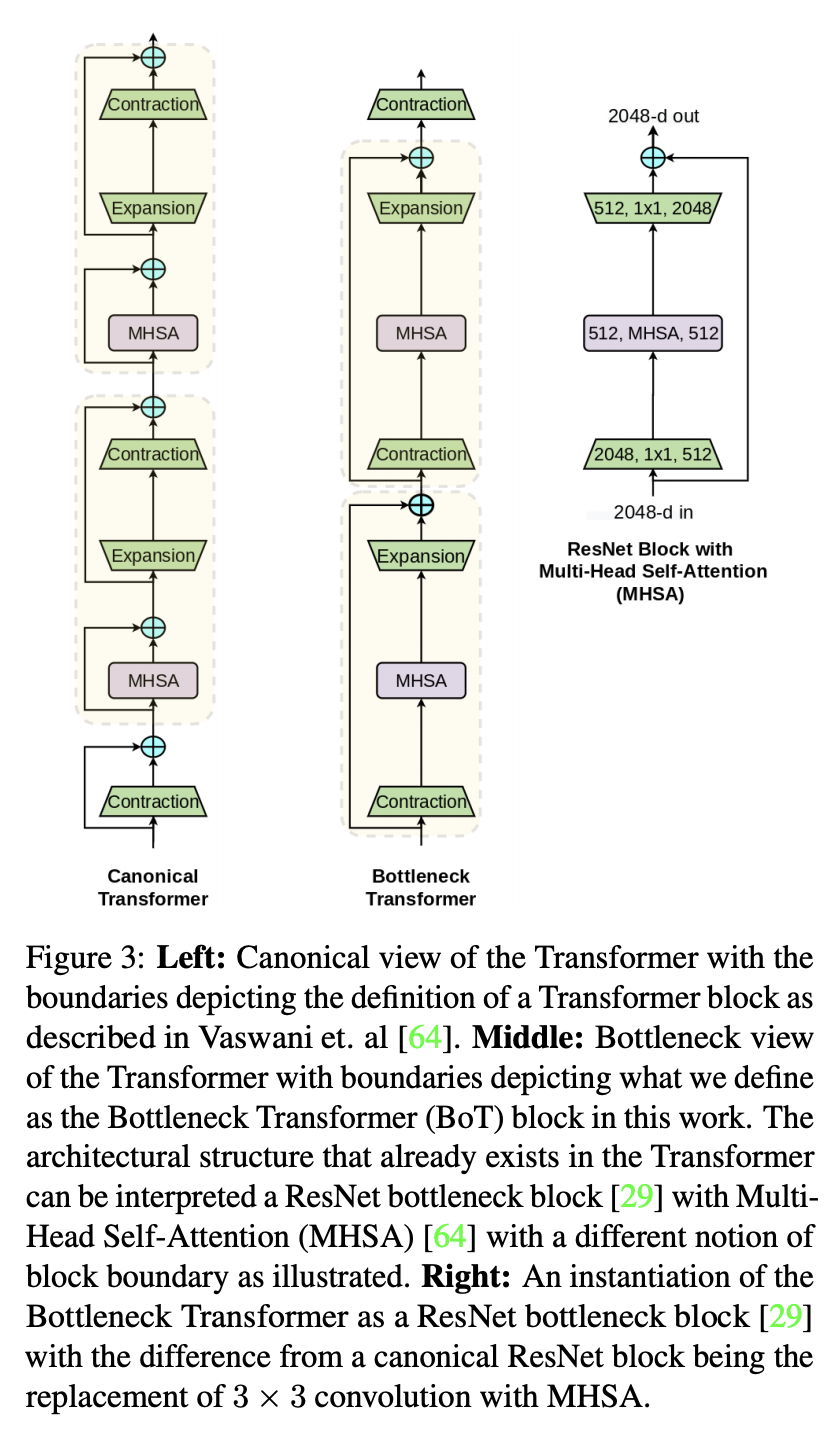
二、Bottleneck Transformer
Bottleneck Transformer (BoTNet) 是一种图像分类模型,它结合了多种计算机视觉任务的自注意力,包括图像分类、对象检测和实例分割。 通过仅在 ResNet 的最后三个瓶颈块中将空间卷积替换为全局自注意力,并且没有其他任何更改,该方法在实例分割和对象检测方面显着改进了基线,同时还减少了参数,并且延迟开销最小。
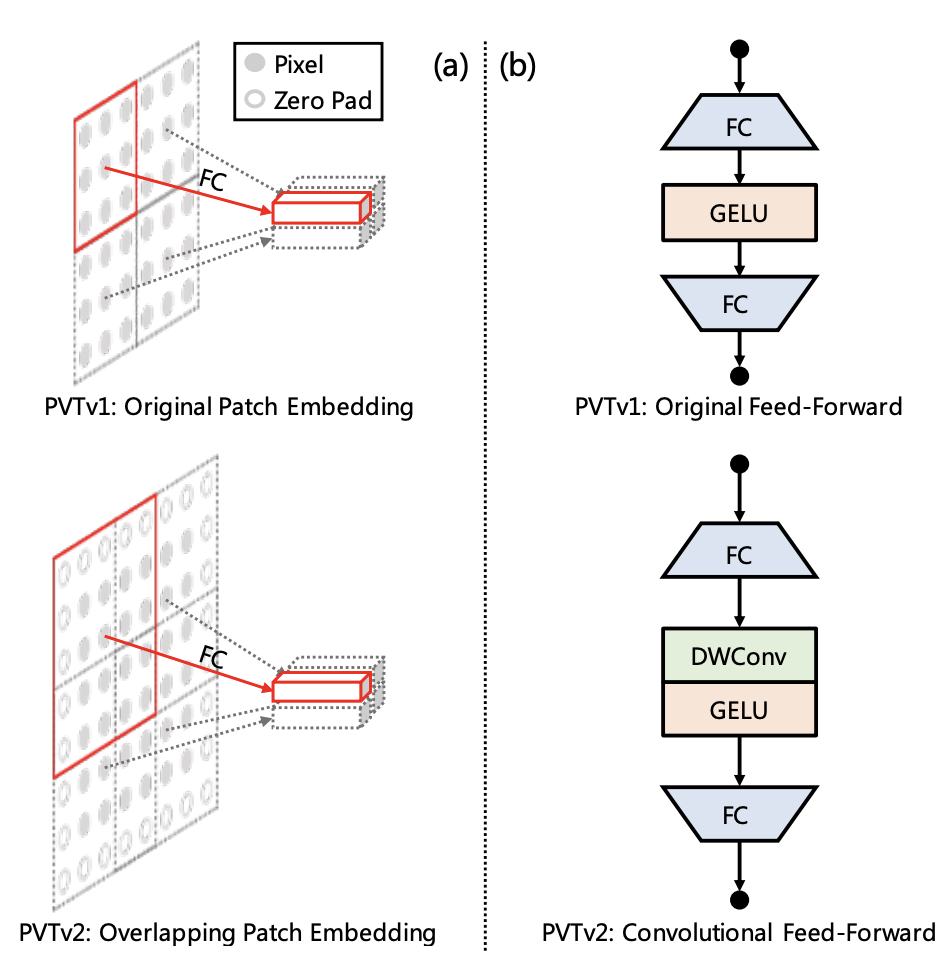
三、Pyramid Vision Transformer v2
Pyramid Vision Transformer v2 (PVTv2) 是一种用于检测和分割任务的 Vision Transformer。 它通过多项设计改进对 PVTv1 进行了改进:(1) 重叠补丁嵌入,(2) 卷积前馈网络,以及 (3) 与 PVTv1 框架正交的线性复杂性注意层。
四、Class-Attention in Image Transformers
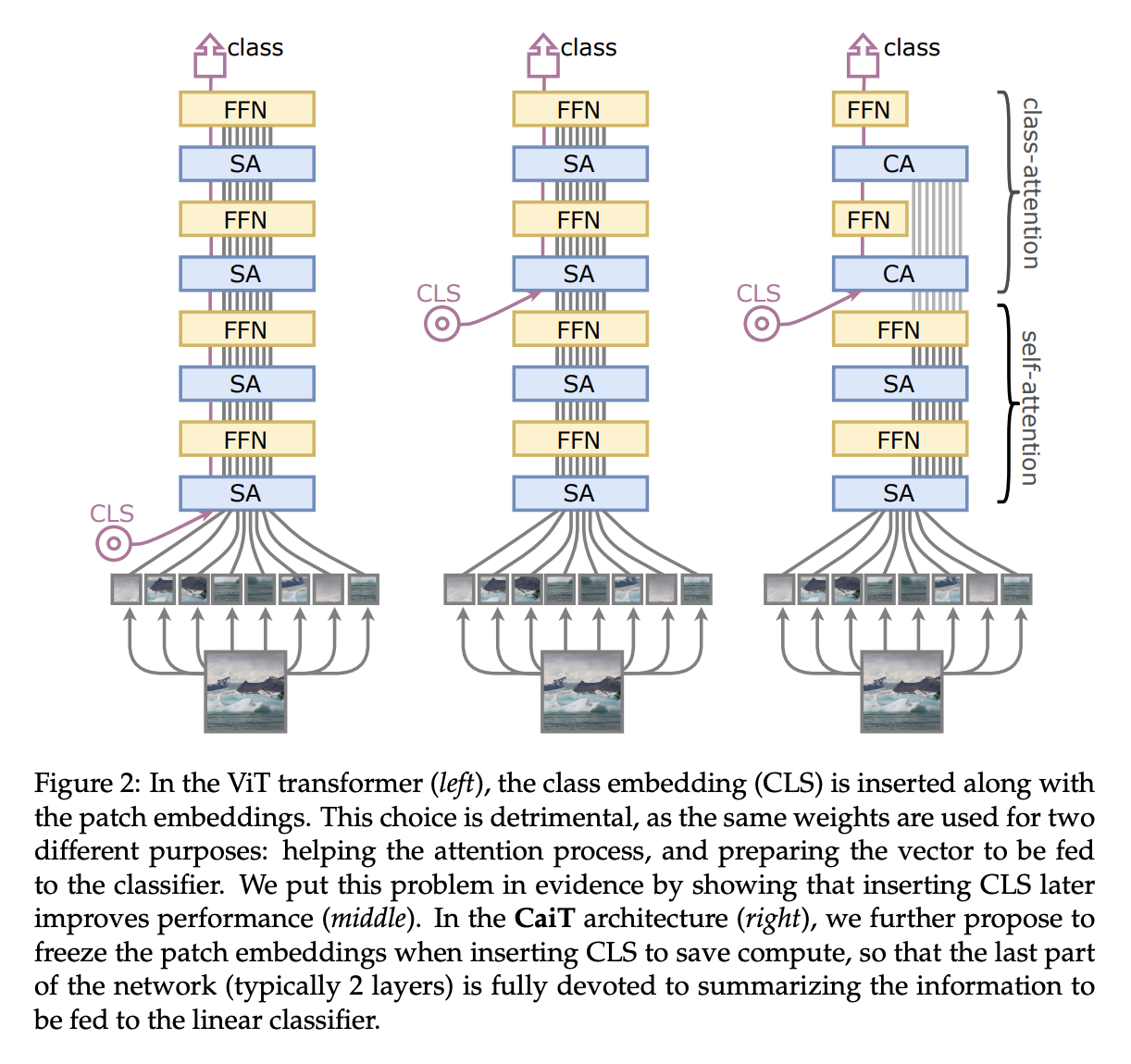
CaiT(图像变换器中的类注意力)是一种视觉变换器,在原始 ViT 的基础上进行了一些设计更改。 首先使用一种称为 LayerScale 的新层缩放方法,在每个残差块的输出上添加可学习的对角矩阵,初始化为接近(但不是)0,从而提高了训练动态。 其次,该架构中引入了类注意层。 这创建了一个架构,其中涉及补丁之间自注意力的变换器层与类注意力层明确分离——类注意力层致力于将处理后的补丁的内容提取到单个向量中,以便可以将其馈送到线性分类器。
五、Co-Scale Conv-attentional Image Transformer
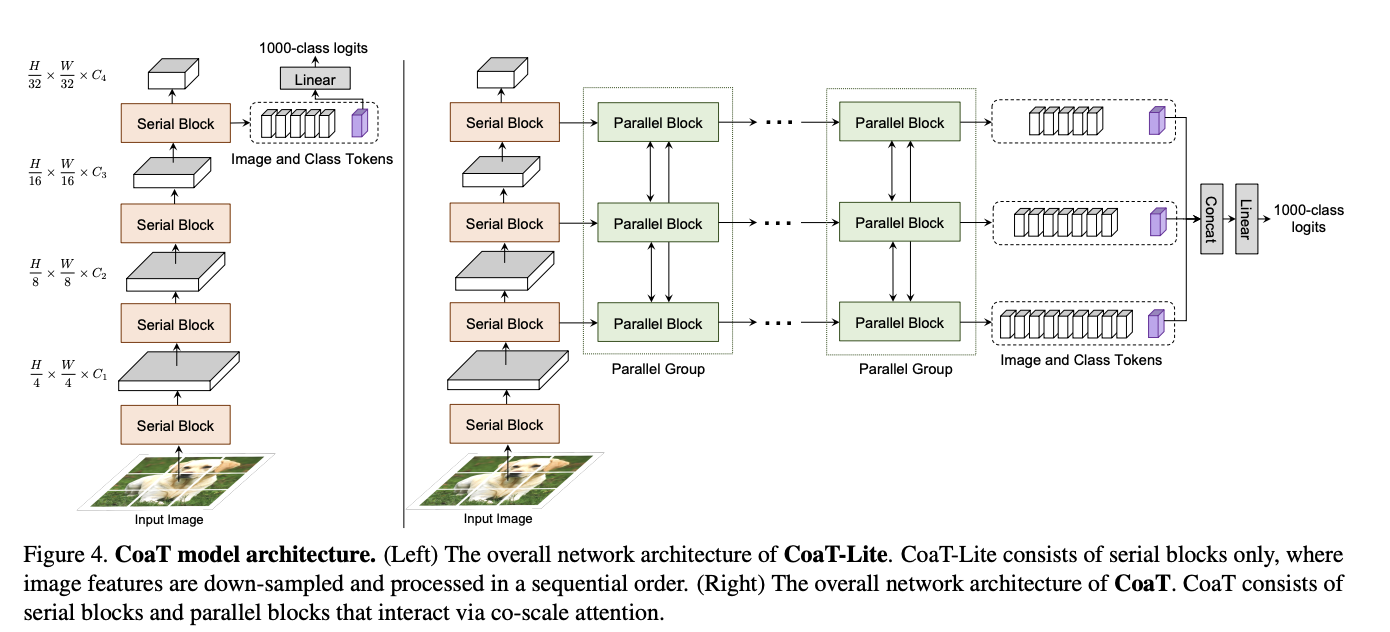
Co-Scale Conv-Attentional Image Transformer (CoaT) 是一种基于 Transformer 的图像分类器,配备了 co-scale 和 conv-attention 机制。 首先,共尺度机制保持了 Transformers 编码器分支在各个尺度上的完整性,同时允许在不同尺度上学习的表示有效地相互通信。 其次,通过在因子化注意力模块中实现相对位置嵌入公式来设计卷积注意力机制,并采用高效的类似卷积的实现。 CoaT 为图像 Transformers 提供了丰富的多尺度和上下文建模功能。
六、XCiT
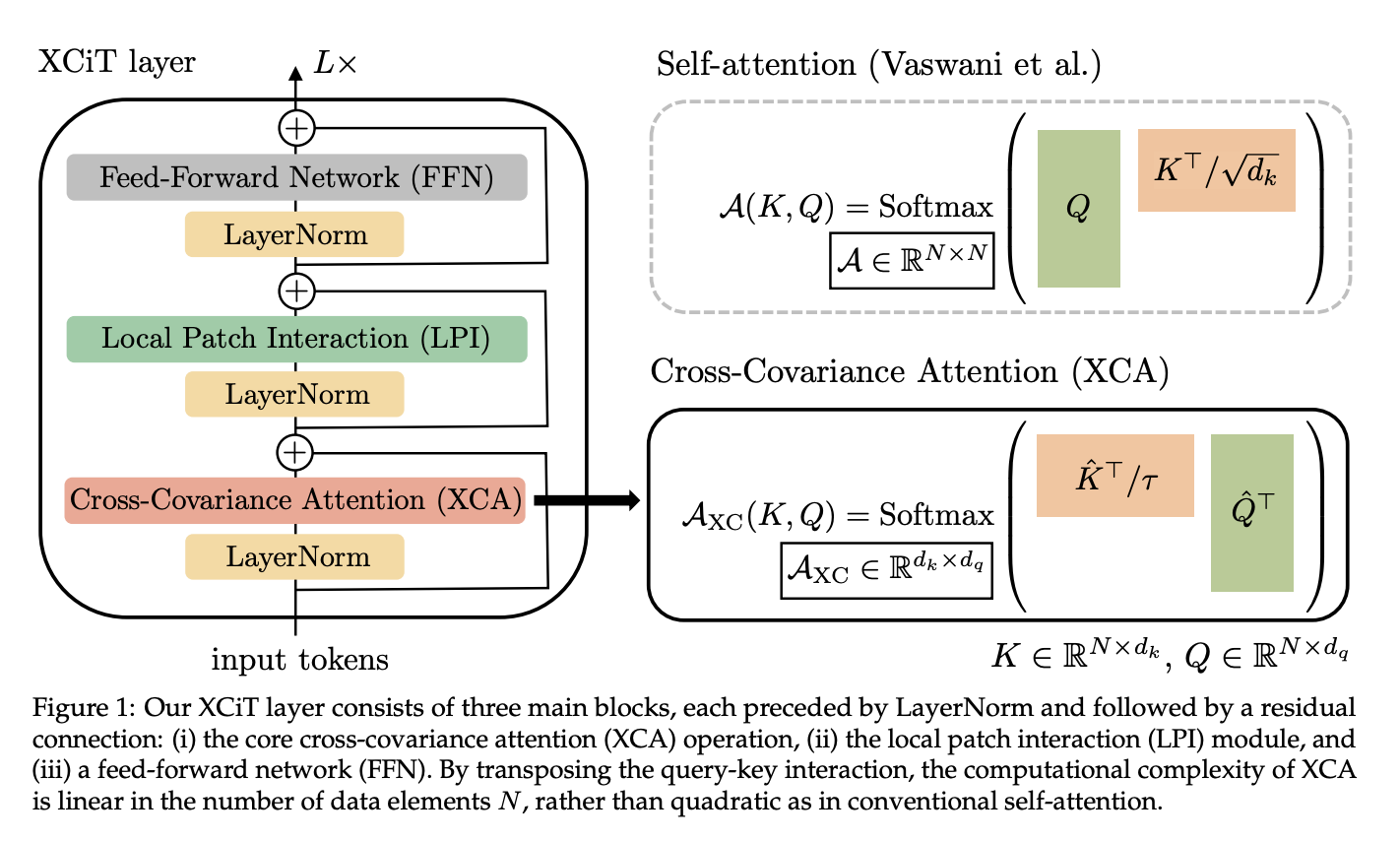
交叉协方差图像变换器(XCiT)是一种视觉变换器,旨在将传统变换器的准确性与卷积架构的可扩展性结合起来。
变压器底层的自注意力操作产生所有标记(即单词或图像块)之间的全局交互,并且能够对超出卷积局部交互的图像数据进行灵活建模。 然而,这种灵活性伴随着时间和内存的二次复杂性,阻碍了长序列和高分辨率图像的应用。 作者提出了一种称为交叉协方差注意力的自注意力“转置”版本,它跨特征通道而不是令牌进行操作,其中交互基于键和查询之间的交叉协方差矩阵。
七、Focal Transformers
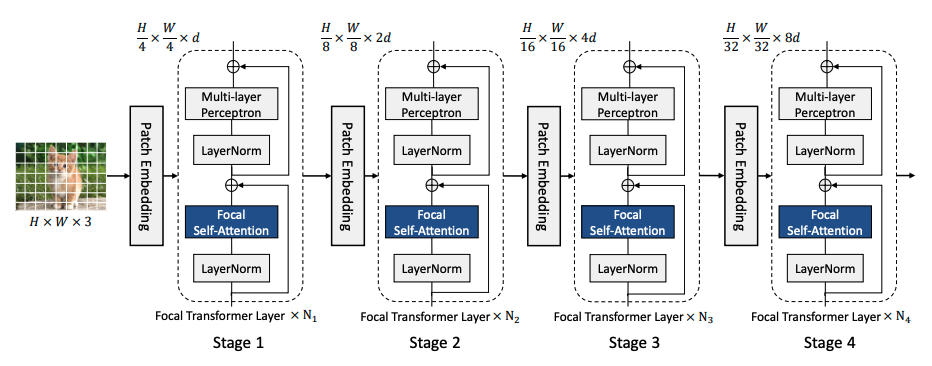
焦点自注意力的构建是为了使 Transformer 层可扩展到高分辨率输入。 该方法不是以细粒度处理所有令牌,而是仅在本地处理细粒度令牌,而在全局处理汇总令牌。 因此,它可以覆盖与标准自注意力一样多的区域,但成本要低得多。 图像首先被分割成块,从而产生视觉标记。 然后是补丁嵌入层,由具有相同大小的滤波器和步长的卷积层组成,将补丁投影到隐藏特征中。 然后,该空间特征图被传递到焦点 Transformer 块的四个阶段。
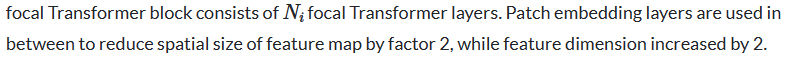
八、CrossViT
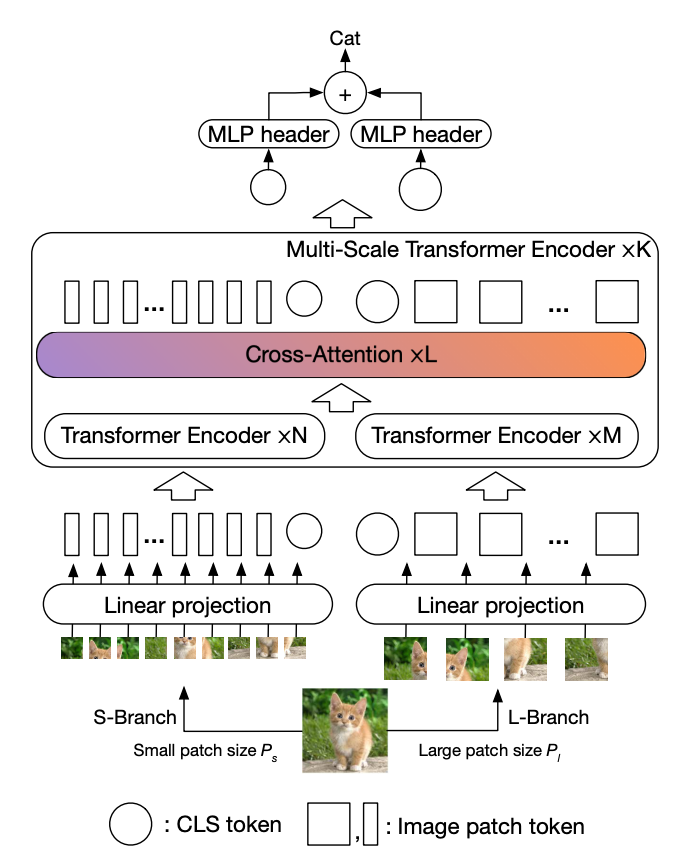
CrossViT 是一种视觉转换器,它使用双分支架构来提取多尺度特征表示以进行图像分类。 该架构结合了不同大小的图像块(即变压器中的标记),以产生更强的图像分类视觉特征。 它使用不同计算复杂度的两个独立分支处理小型和大型补丁令牌,并且这些令牌多次融合在一起以相互补充。
融合是通过高效的交叉注意力模块实现的,其中每个变压器分支创建一个非补丁令牌作为代理,通过注意力与其他分支交换信息。 这允许在融合中线性时间生成注意力图,而不是二次时间。
九、ConViT
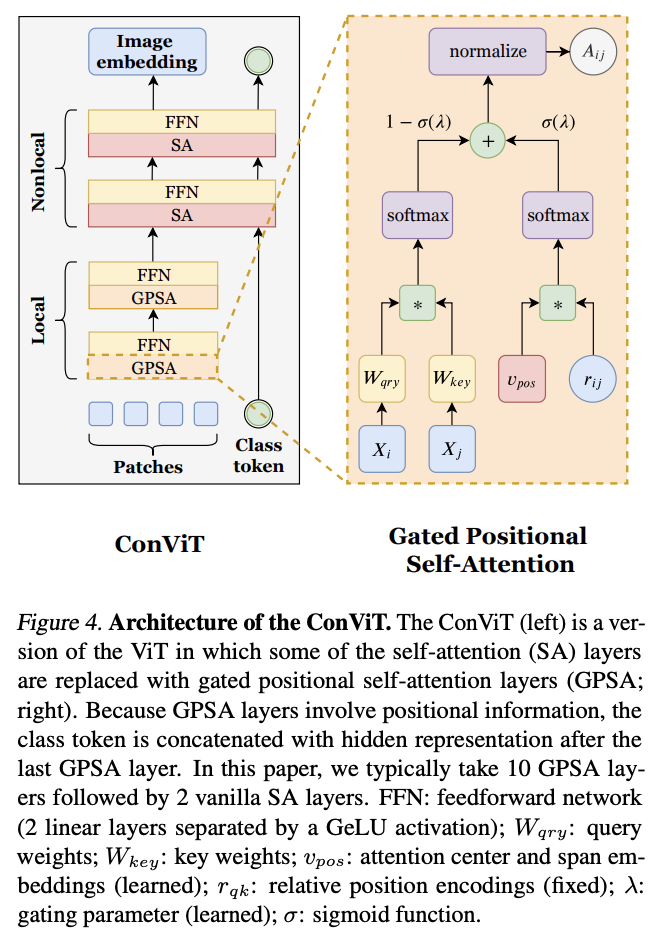
ConViT 是一种视觉变换器,它使用门控位置自注意力模块(GPSA),这是一种位置自注意力形式,可以配备“软”卷积归纳偏置。 GPSA 层被初始化为模仿卷积层的局部性,然后通过调整控制对位置与内容信息的注意力的门控参数,使每个注意力头可以自由地逃避局部性。
十、CrossTransformers
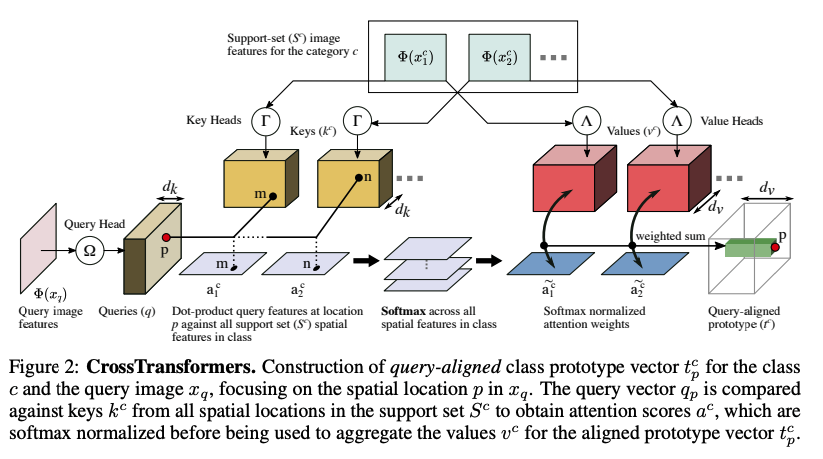
CrossTransformers 是一种基于 Transformer 的神经网络架构,它可以采用少量标记图像和未标记查询,找到查询和标记图像之间的粗略空间对应关系,然后通过计算空间对应特征之间的距离来推断类成员关系。
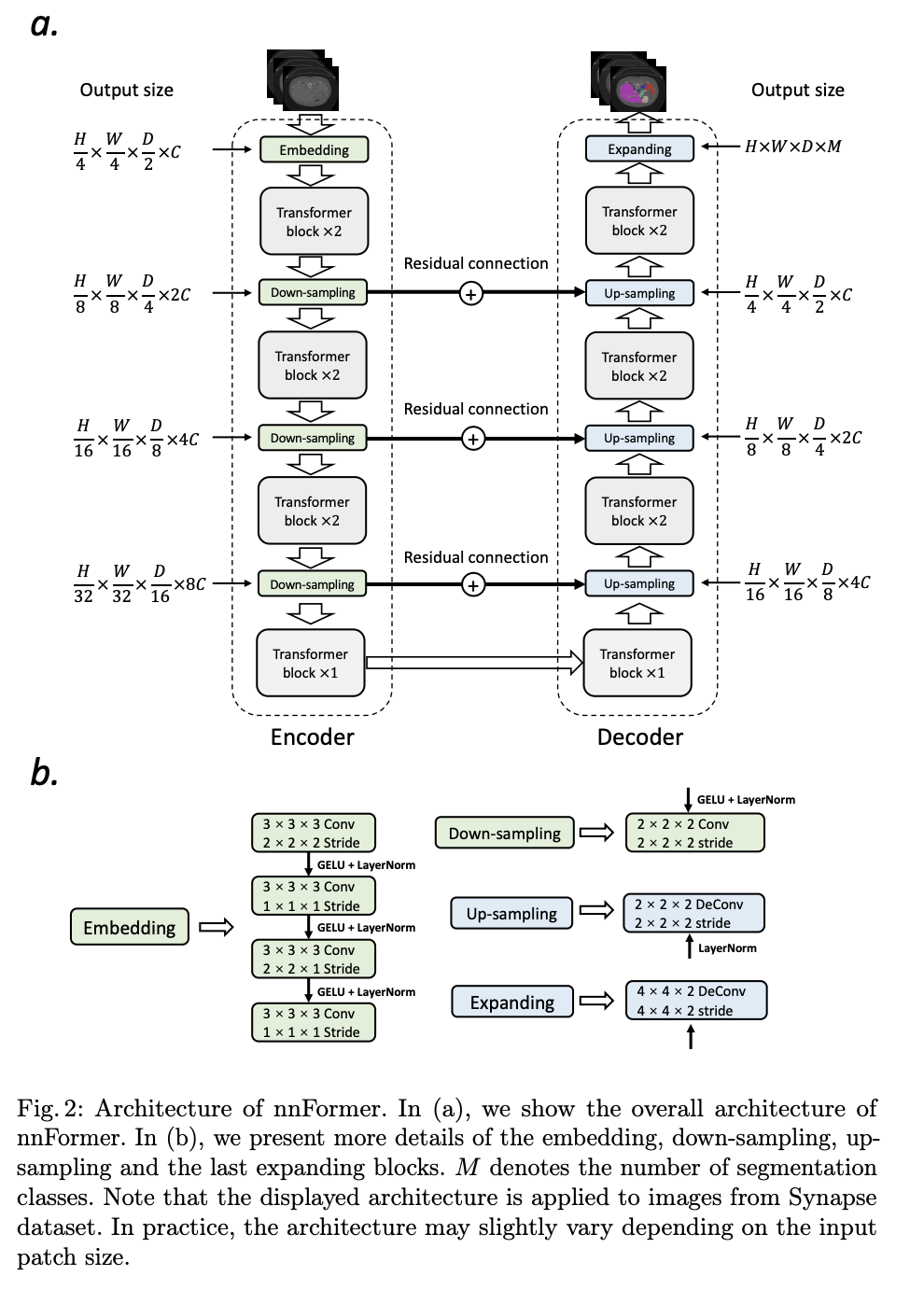
十一、nnFormer
nnFormer,或者不是另一个 transFormer,是一种语义分割模型,具有基于自注意力和卷积的经验组合的交错架构。 首先,在变压器块之前使用轻量级卷积嵌入层。 与直接展平原始像素并应用 1D 预处理相比,卷积嵌入层对精确(即像素级)空间信息进行编码,并提供低级但高分辨率的 3D 特征。 在嵌入块之后,变压器和卷积下采样块交织在一起,以将长期依赖关系与各种尺度的高级和分层对象概念完全纠缠在一起,这有助于提高学习表示的泛化能力和鲁棒性。
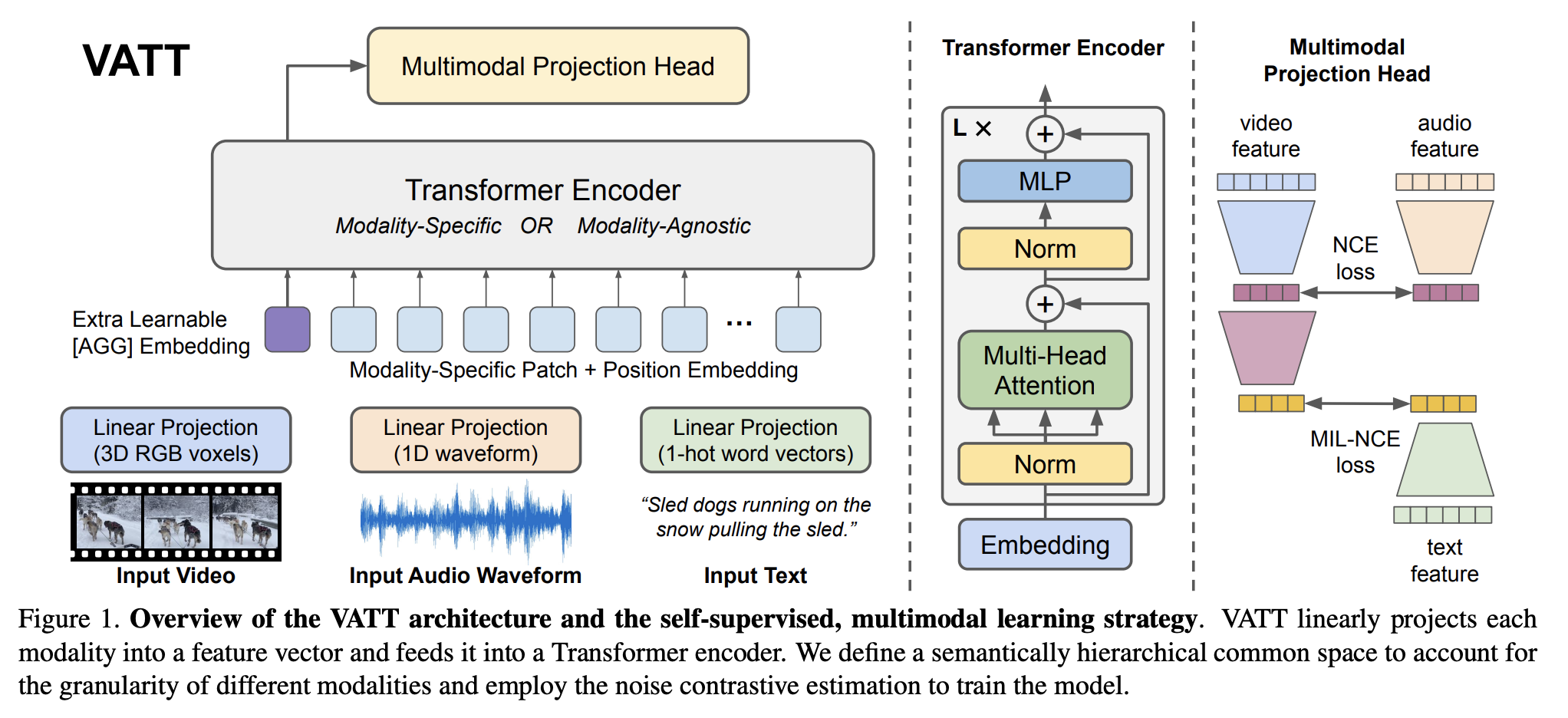
十二、VATT
视频-音频-文本 Transformer(VATT)是一个使用无卷积 Transformer 架构从未标记数据中学习多模态表示的框架。 具体来说,它以原始信号作为输入,并提取足够丰富的多维表示,以有利于各种下游任务。 VATT 借用了 BERT 和 ViT 的确切架构,除了为每种模态分别保留的标记化层和线性投影。 该设计遵循与 ViT 相同的精神,对架构进行最小的更改,以便学习的模型可以将其权重转移到各种框架和任务中。
VATT 将每种模态线性投影到特征向量中,并将其输入到 Transformer 编码器中。 定义语义分层公共空间来考虑不同模态的粒度,并采用噪声对比估计来训练模型。
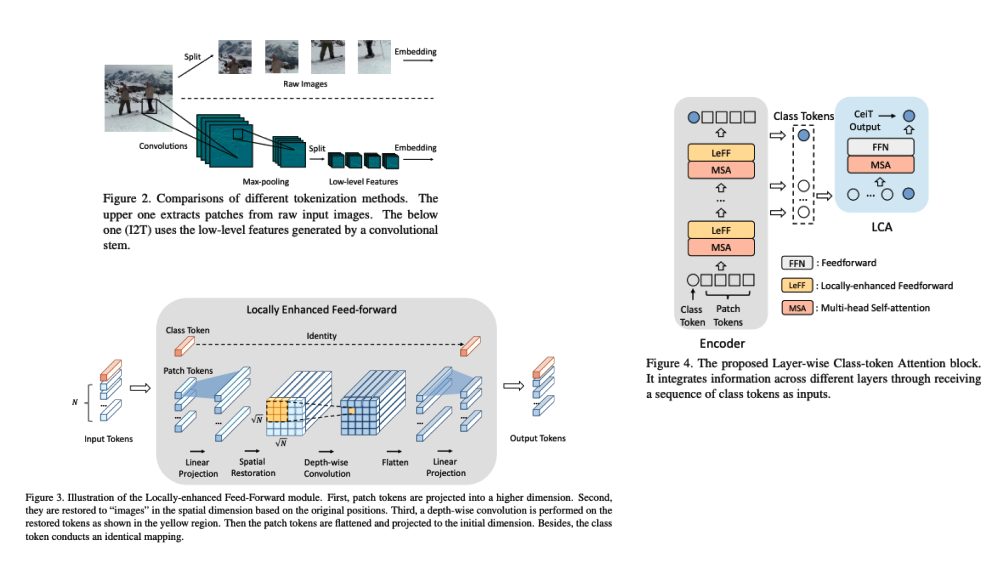
十三、Convolution-enhanced image Transformer
卷积增强图像 Transformer (CeiT) 结合了 CNN 在提取低级特征、加强局部性方面的优势以及 Transformer 在建立远程依赖关系方面的优势。 对原始 Transformer 进行了三处修改:1)我们设计了一个图像到令牌(I2T)模块,该模块从生成的低级特征中提取补丁,而不是直接从原始输入图像进行令牌化; 2)每个编码器块中的前馈网络被替换为局部增强前馈(LeFF)层,该层促进空间维度上相邻标记之间的相关性; 3)分层类令牌注意力(LCA)附加在利用多层表示的 Transformer 的顶部。
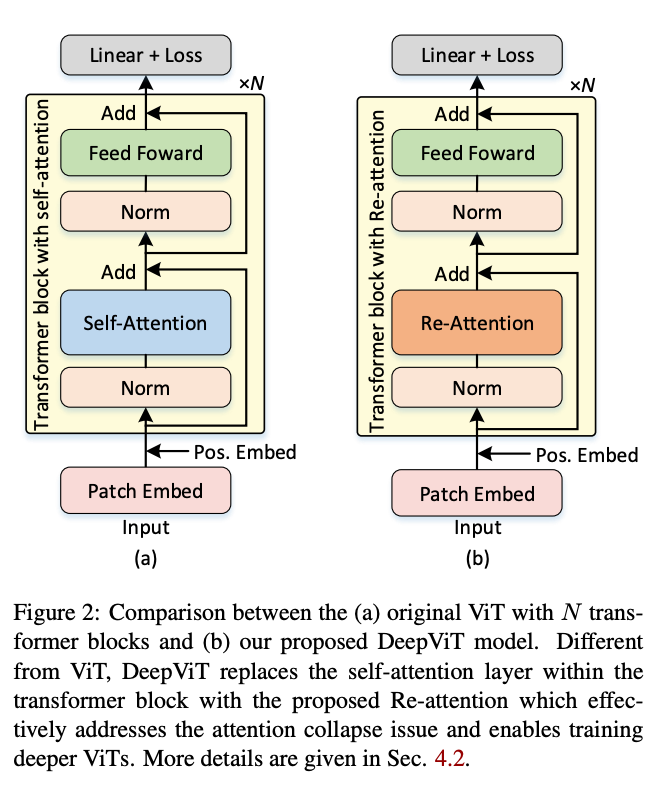
十四、DeepViT
DeepViT 是一种视觉 Transformer,它用 Re-attention 模块取代 Transformer 模块中的自注意力层,以解决注意力崩溃问题,并能够训练更深层次的 ViT。