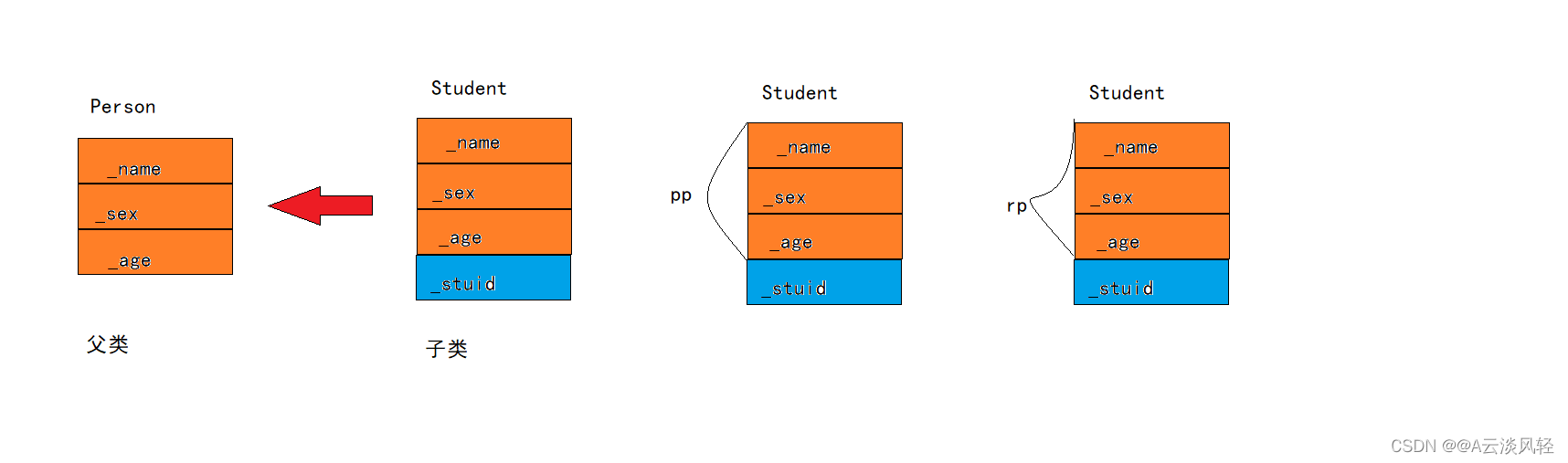
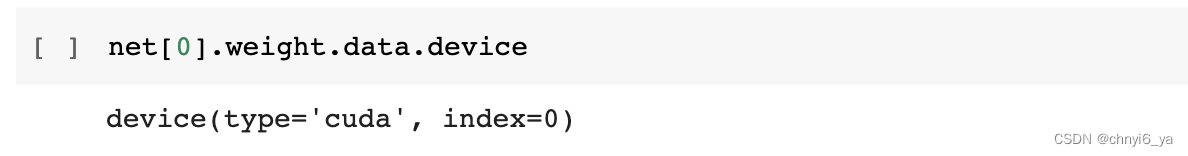在PyTorch中,CPU和GPU可以用torch.device(‘cpu’) 和torch.device(‘cuda’)表示。 应该注意的是,cpu设备意味着所有物理CPU和内存, 这意味着PyTorch的计算将尝试使用所有CPU核心。 然而,gpu设备只代表一个卡和相应的显存。 如果有多个GPU,我们使用torch.device(f’cuda:{i}') 来表示第块GPU(从0开始)。 另外,cuda:0和cuda是等价的。
1.计算设备
import torch
from torch import nn
torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')

我们可以查询可用gpu的数量。
torch.cuda.device_count()

从运行结果可以看出,没有gpu
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
因为没有gpu,所以都返回cpu。
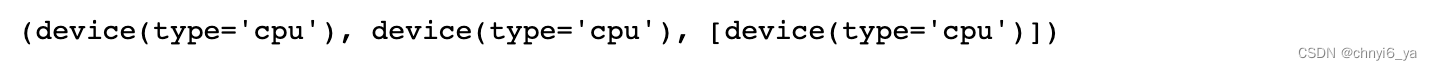
2. 张量与GPU
我们可以查询张量所在的设备。 默认情况下,张量是在CPU上创建的。
x = torch.tensor([1, 2, 3])
x.device # 张量x所在的设备是cpu

1. 存储在GPU上
有几种方法可以在GPU上存储张量。 例如,我们可以在创建张量时指定存储设备。
接 下来,我们在第一个gpu上创建张量变量X。 在GPU上创建的张量只消耗这个GPU的显存。 我们可以使用nvidia-smi命令查看显存使用情况。 一般来说,我们需要确保不创建超过GPU显存限制的数据。
X = torch.ones(2, 3, device=try_gpu())
X
因为没有gpu,于是到colab上去运行这段代码:

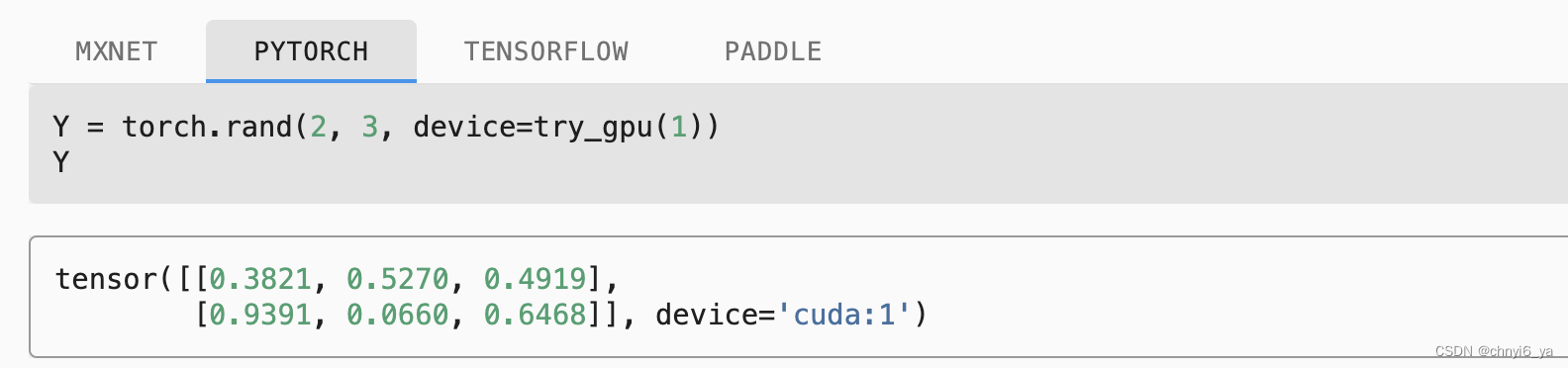
假设我们至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量。(因为在colab上也只会分配一个GPU,所以接下来需要两个gpu的部分代码代码以及运行结果是复制讲义的)
2. 复制
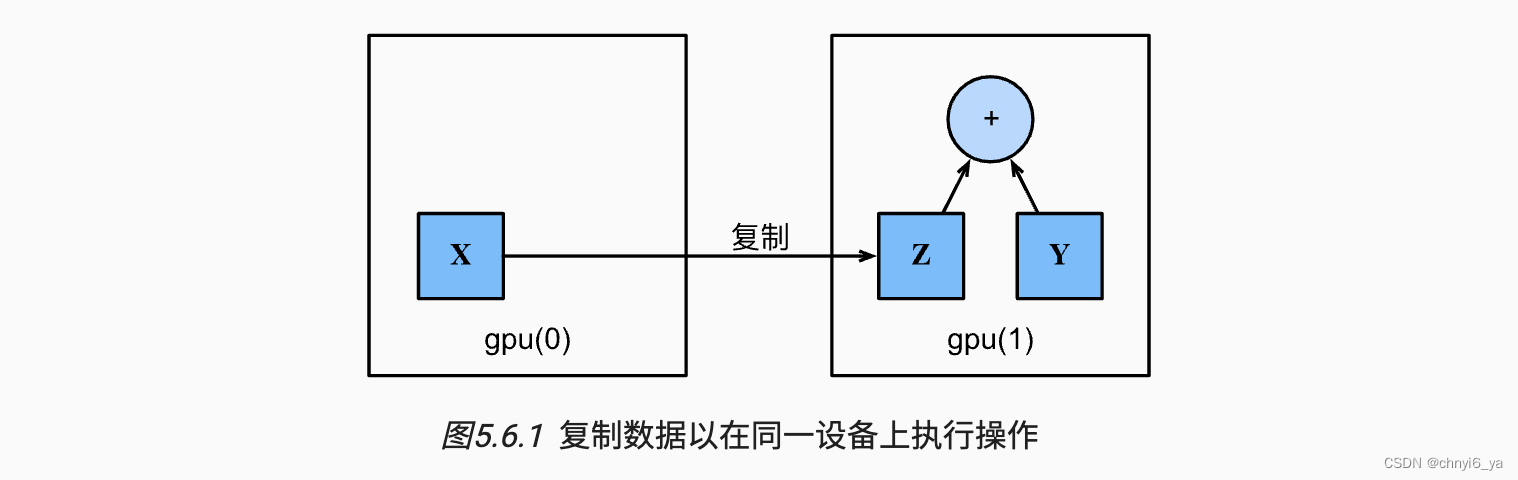
如果我们要计算X + Y,我们需要决定在哪里执行这个操作。 例如,如 图所示, 我们可以将X传输到第二个GPU并在那里执行操作。 不要简单地X加上Y,因为这会导致异常, 运行时引擎不知道该怎么做:它在同一设备上找不到数据会导致失败。 由于Y位于第二个GPU上,所以我们需要将X移到那里, 然后才能执行相加运算。
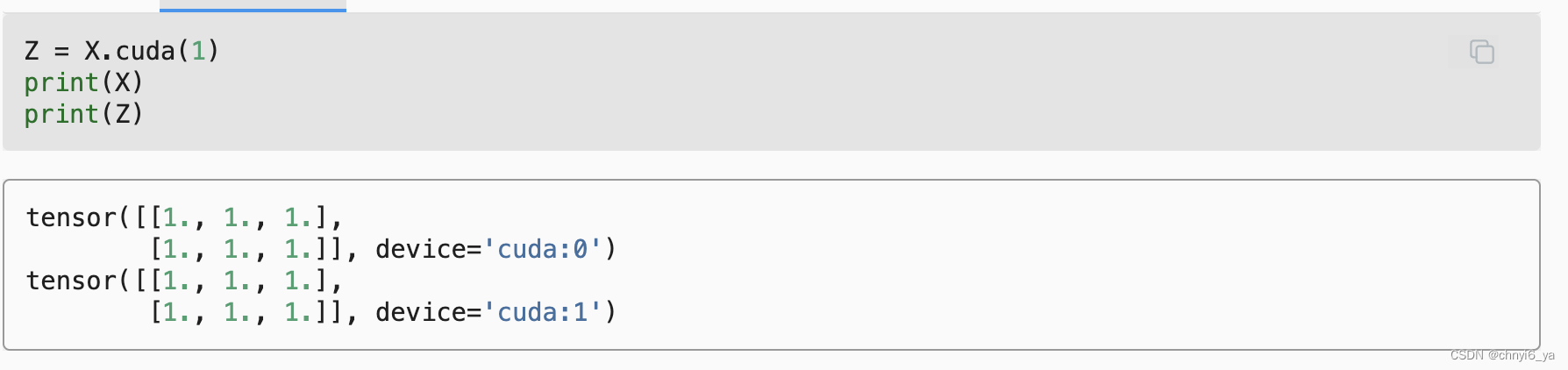
现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。

假设变量Z已经存在于第二个GPU上。 如果我们还是调用Z.cuda(1)会发生什么? 它将返回Z,而不会复制并分配新内存。

3. 旁注
人们使用GPU来进行机器学习,因为单个GPU相对运行速度快。 但是在设备(CPU、GPU和其他机器)之间传输数据比计算慢得多。 这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收), 然后才能继续进行更多的操作。
这就是为什么拷贝操作要格外小心。 根据经验,多个小操作比一个大操作糟糕得多。 此外,一次执行几个操作比代码中散布的许多单个操作要好得多。 如果一个设备必须等待另一个设备才能执行其他操作, 那么这样的操作可能会阻塞。 这有点像排队订购咖啡,而不像通过电话预先订购: 当客人到店的时候,咖啡已经准备好了。
最后,当我们打印张量或将张量转换为NumPy格式时, 如果数据不在内存中,框架会首先将其复制到内存中, 这会导致额外的传输开销。 更糟糕的是,它现在受制于全局解释器锁,使得一切都得等待Python完成。
3. 神经网络与GPU
类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上。
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
当输入为GPU上的张量时,模型将在同一GPU上计算结果。

让我们确认模型参数存储在同一个GPU上。