C/C++标准输入输出函数最全解析(含C/C++的输出控制符)
- 一、标准输入流
- 1、C 标准输入
- 1.1 标准输入流及对缓冲区的理解
- 1.2 scanf()
- 1.2.1 scanf()简介
- 1.2.2 ANSI C中scanf()的转换说明
- 1.2. 3 scanf()转换说明中的修饰符
- 1.3 gets() - 不建议
- 1.4 fgets()
- 1.5 fgetc() & getc()
- 1.6 getchar()
- 2、 C++ 标准输入
- 2.1 cin
- 2.2 cin.get()
- 2.3 cin.getline()
- 2.4 getline()
- 总结
- 二、标准输出流
- 1、C 标准输出
- 1.1 标准输出流及对缓冲区的理解
- 1.2 printf()
- 1.2.1 printf()简介
- 1.2.2 格式控制字符串详解
- 1.2.2.1 类型(type)
- 1.2.2.2 标志(flags)
- 1.2.2.3 输出最小宽度(width)
- 1.2.2.4 精度(.precision)
- 1.2.2.5 类型长度(length)
- 1.2.2.6 转义字符
- 1.2.2.7 关于printf缓冲
- 1.2.2.8 小结
- 1.3 puts()
- 1.4 fputs()
- 1.5 fputc() & putc()
- 1.6 putchar()
- 1.7 fflush()
- 2、C++ 标准输出
- 2.1 cout
- 2.1.1 `std::endl`
- 2.1.2 `std::setw(int n)`
- 2.1.3 `std::setprecision(int n)`
- 2.1.4 `std::fixed`
- 2.1.5 `std::scientific`
- 2.1.6 `std::left` 和 `std::right`
- 2.1.7 `std::setfill(char c)`
- 2.2 cerr
- 2.3 clog
- 2.4 总结
一、标准输入流
1、C 标准输入
C语言使用标准输入输出函数,需要包含头文件
<stdio.h>。而在 C++ 中,只要包含头文件<iostream>,就完全可以使用这些 C 中的输入输出函数。
1.1 标准输入流及对缓冲区的理解
stdin是一个文件描述符(Linux)或句柄(Windows),它在 C 程序启动时就被默认分配好。在 Linux 中一切皆文件,stdin也相当于一个可读文件,它对应着键盘设备的输入。因为它不断地被输入,又不断地被读取,像流水一样,因此通常称作输入流。
stdin是一种行缓冲I/O。当在键盘上键入字符时,它们首先被存放在键盘设备自身的缓存中(属于键盘硬件设备的一部分)。只有输入换行符时,操作系统才会进行同步,将键盘缓存中的数据读入到stdin的输入缓冲区(存在于内存中)。所有从stdin读取数据的输入流,都是从内存中的输入缓冲区读入数据。当输入缓冲区为空时,函数将被阻塞。
若无特殊说明,以下所有的**“缓冲区”**均是指内存中的stdin输入缓冲区。用户程序中自定义的buffer数组、str数组等,将称作“数组”、“变量”,以免产生混淆。
1.2 scanf()
1.2.1 scanf()简介
前言
scanf()和printf()类似, 也是使用格式字符串和参数列表.。
scanf中的格式字符串表明字符输入流的目标整数类型。
两个函数主要的区别在参数列表中. printf()函数使用变量, 常量和表达式, 而scanf()函数使用指向变量的指针。
使用scanf()有一下两个规则:
如果用scanf()读取基本变量类型的值, 在变量名前加上一个&;
如果用scanf()把字符串读入字符串数组中, 不要使用&.
格式:
#include <stdio.h>
int scanf(const char *restrict format,…)
成功:指定的输入项数;出错:返回EOF;输入出错或在任意变换前已到达文件结尾:EOF;
返回值:(详见CPrimerPlus P95)
- 返回成功读取的项数
- 如果没有读取任何项,如需要读取一个数字而用户却输入一个非数值字符串,scanf()返回0.
- 当scanf()检测到“文件结尾”时,会返回EOF(EOF是字符串中的特殊值,通常手动用#define指令把它定义为-1)(在CPrimerPlus第六章中讨论文件结尾相关内容以及如何利用scanf()返回值,可以使用scanf()返回值检测和处理不匹配的输入)
实现:标准输入流->格式转换->内存变量中。用于分析输入字符串,并将字符序列转换成指定类型的变量。格式之后的各个参数包含了变量的地址,以用转换结果初始化这些变量。
原因:要在流中做格式转换,再将结果放到内存变量中
补充:(详见CPrimerPlus P95)
- 如果使用%s转换说明,scanf()会读取除空白字符外的所有字符。scanf()跳过空白字符开始读取第一个非空白字符,并保存非空白字符直到遇到下以恶搞空白字符,这意味这%s转换说明只能读取不包含空白地府的字符串,scanf会在字符序列的末尾加上\0,让数组中的内容形成一个字符串。(空格符,制表符,换行符统称为空白字符)
- 注意以%d为例,如果scanf()函数读取到非数字字符它会把非数字字符放回输入,这意味着程序在下一次读取输入时,首先读取到的是上一次读取丢失的非数字字符。
- C语言还可以使用其它的输入函数来处理一些特殊情况,如getchar()和fputs()。这两个函数更适合处理一些特殊情况,如读取单个字符或包含空格的字符串。
- 除了%c,其它的转换说明都会自动跳过待输入值前面的空白。
注意
读写无符号、短的和长的整数使用的一些转换说明符。
- 当读或写无符号整数时,使用字母u、o或x代替转换说明中的d。如果使用了u说明符,那么读(或写)的数是十进制形式;o指明是八进制形式,而x指明是十六进形式。
- 当读或写短整形数时,在d、o、u、x前面加上字母h
- 当读或写长整形数时,在d、o、u、x前面加上字母l。
转换说明符%e、%f、%g用于读和写单精度浮点数,而double和long double类型值则要求略微不同的转换。
- 当读写double类型的数值时,在e、f、g前放置字母l: 注意:只能在scanf函数格式串中使用l,不能在printf函数格式串中使用。在printf函数格式串中,转换e、f、g可以用来写float型或double型值。
- 当读或写long double类型的值时,在e、f、g、前放置字母L
转换说明符%c允许scanf函数和printf函数对单独一个字符进行读写操作。在读入字符前,scanf 函数不会跳过空白字符。如果下一个未读字符是空格,那么scanf 函数将读入空格。为了强制scanf 函数在读入字符前跳过空白字符,需要在格式串转换说明符%c前面加上一个空格。
可以使用getchar 函数和 putchar 函数來代替调用scanf 函数和printf 函数。每次调用getchar 函数时,它会读入一个字符,并返回这个字符。需要使用复制操作将返回值存储在变量中。和scanf 函数一样,getchar 函数也不会在读取时跳过空白字符。putchar 函数用来写单独的一个字符,如putchar(ch)。
1.2.2 ANSI C中scanf()的转换说明
详见CPrimerPlus P93
| 转换说明符 | 意义 |
|---|---|
| %c | 把输入解释成一个字符 |
| %d | 把输入解释成一个有符号十进制整数 |
| %e,%f,%g,%a | 把输入解释成 一个浮点数(%a是C99标准) |
| %E,%F,%G,%A | 把输入解释成一个浮点数(%A是C99标准) |
| %i | 把输入解释成一个有符号十进制整数 |
| %o | 把输入解释成一个有符号八进制数 |
| %p | 把输入解释成一个指针(地址) |
| %s | 把输入解释成一个字符串;输入的内容以一个非空白字符作为开始,并且包含直到下一个空白字符的全部字符 |
| %u | 把输入解释成一个无符号十进制整数 |
| %x,%X | 把输入解释成一个有符号十六进制整数 |
1.2. 3 scanf()转换说明中的修饰符
详见CPrimerPlus P94
| 修饰符 | 意义 |
|---|---|
| * | 滞后赋值。示例:“%*d“ |
| digit(s) | 最大字段宽度;在达到最大字段宽度或者遇到第一个空白字符时(不管哪一个先发生都一样)停止对输入项的读取。示例:“%10s“ |
| hh | 把整数读作signed char 或者 unsigned char 。示例:“%hhd“ ”%hhu“ |
| ll | 把整数读作long long 或者 unsigned long long (C99)。示例:“%lld“ ”%llu“ |
| h,l或L | “%hd“ 和 “%hi“指示该值将会存储在一个short int 中。 “%ho“ 和 “%hx“ 和“%hu“指示该值将会存储在一个unsigned short int中。 “%ld“ 和 “%li“指示该值将会存储在一个long中。 “%lo“ 和 “%lx“ 和 “%lu“ 指示该值将会存储在一个unsigned long中。 “%le“ 和 “%lf“ 和 “%lg“知识该值以double类型存储。将L(而非l)与e、f和g一起使用指示该值以long double类型存储。 如果没有这些修饰符,d、i、o、和x知识int类型,而e、f和g指示float类型 |
| j | 在整形转换说明后面时,表面使用intmax_t或uintmax_t类型(C99) |
| z | 在整型转换说明后面时,表明使用sizeof的返回类型(C99) |
| t | 在整形转换说明后面时,表明使用表示两个指针插值的类型(C99) |
1.3 gets() - 不建议
按下回车键时,从stdin读取一行。
用法示例:
char str[100];
gets(str);
对空白字符的处理:
- 所有空格、Tab等空白字符均被读取,不忽略。
- 按下回车键时,缓冲区末尾的换行符被丢弃,字符串末尾没有换行符
\n,缓冲区也没有残留的换行符\n。
注意,gets()不能指定读取上限,因此容易发生数组边界溢出,造成内存不安全。C11 使用了gets_s()代替gets(),但有时编译器未必支持,因此总体来说不建议使用gets()函数来读取输入。
gets()对应的输出函数是puts()。
1.4 fgets()
从指定输入流读取一行,输入可以是stdin,也可以是文件流,使用时需要显式指定。
读取文件流示例:
char str[100];
memset(str, 0, sizeof(str));
int i = 1;
FILE *fp = fopen("...test.txt", "r");
if (fp == NULL) {
printf("File open Error!\n");
exit(1);
}
while (fgets(str, sizeof(str), fp) != NULL)
printf("line%d [len %d]: %s", i++, strlen(str), str);
fclose(fp);
读取stdin示例:
char str[100];
memset(str, 0, sizeof(str));
int i = 1;
while (fgets(str, sizeof(str), stdin) != NULL)
printf("line%d [len %d]: %s", i++, strlen(str), str);
对空白字符的处理:
- 所有空格、Tab等空白字符均被读取,不忽略。
- 按下回车键时,缓冲区末尾的换行符也被读取,字符串末尾将有一个换行符
\n。例如,输入字符串hello,再按下回车,则读到的字符串长度为6。
fgets()函数会自动在字符串末尾加上\0结束符。
第 2 个参数n指定了读取的最大长度。函数读到n-1个字符(包括换行符\n)就会停止,并在末尾加上\0结束符。剩余字符将残留在缓冲区。
建议使用fgets()完全替代gets()。
fgets()对应的输出函数是fputs()。
1.5 fgetc() & getc()
从指定输入流读取一个字符,输入可以是stdin,也可以是文件流,使用时需要显式指定。
这两个函数完全等效,getc()由fgetc()宏定义而来。不同的是,前述的gets()和fgets()相互之间没有关系。
用法示例:
char a, b;
a = fgetc(stdin);
b = getc(stdin);
对空白字符的处理:
- 所有空格、Tab、换行等空白字符,无论在缓冲区开头、中间还是结尾,均会被读取,不忽略。
- 因为只读取一个字符,所以如果输入多于
1个字符(包括换行符),则它们均会残留在缓冲区。具体地说,如果什么字符都不输入,直接按下回车键,则读取到的是换行符\n,缓冲区无任何残留;如果输入一个字符如a,然后按下回车键,则读取到的是字符a,同时换行符\n残留在缓冲区。
fgetc()和getc()对应的输出函数是fputc()和putc()。
1.6 getchar()
从stdin读取一个字符。
getchar()实际上也由fgetc()宏定义而来,只是默认输入流为stdin。
用法示例:
char a;
a = getchar();
getchar()常常用于清理缓冲区开头残留的换行符。当知道缓冲区开头有\n残留时,可以调用getchar()但不赋值给任何变量,即可实现冲刷掉\n的效果。
getchar()对应的输出函数是putchar()。
2、 C++ 标准输入
C++中使用标准输入输出需要包含头文件<iostream>。一般使用iostream类进行流操作,其封装很完善,也比较复杂,本文只介绍一部分。
2.1 cin
cin是 C++ 的标准输入流对象,即istream类的一个对象实例。cin有自己的缓冲区,但默认情况下是与stdin同步的,因此在 C++ 中可以混用 C++ 和 C 风格的输入输出(在不手动取消同步的情况下)。
cin与stdin一样是行缓冲,即遇到换行符时才会将数据同步到输入缓冲区。
cin的用法非常多,只列举常用的几种。最常用的就是使用>>符号(我认为该符号形象地体现了“流”的特点)。
用法示例:
int a, b;
cin >> a >> b;
char str[20];
cin >> str;
cin对空白字符的处理与scanf一致。即:跳过开头空白字符,遇到空白字符停止读取,且空白字符(包括换行符)残留在缓冲区。
如果不想跳过空白字符,可以使用流控制关键词noskipws(no skip white space),但这只对单个字符有效(类似于scanf中的%c)。
char c;
cin >> noskipws >> c;
注意,cin对象属于命名空间std,如果想使用cin对象,必须在 C++ 文件开头写using namespace std,或者在每次用到的时候写成std::cin。
2.2 cin.get()
读取单个或指定长度的字符,包括空白字符。
用法示例:
char a, b;
char str[20];
// 读取一个字符,读取失败时返回0,多余字符残留在缓冲区(包括换行符)
a = cin.get();
// 读取一个字符,读取失败时返回EOF,多余字符残留在缓冲区(包括换行符)
cin.get(b);
// 在遇到指定终止字符(参数3)前,至多读取n-1个(参数2)字符
// 当不指定终止字符时,默认为换行符\n
// 如果输入的字符个数小于等于n-1(不含终止字符),则终止字符不残留在缓冲区
// 如果输入的字符个数多于n-1(不含终止字符),则余下字符将残留在缓冲区
cin.get(str, sizeof(str), '\n');
cin.get()读取单个字符时,类似于 C 中的fgetc(),对空白字符的处理也与其一致。cin.get()读取的字符也可以赋值给整型变量。
cin.get()读取指定长度个字符时,类似于 C 中的fgets(),但在换行符的处理上不同。它们都不会使换行符残留在缓冲区,但fgets()会将缓冲区末尾的换行符\n也写入字符串,而cin.get()会丢弃缓冲区末尾的\n。即:当输入test时,用fgets()读取得到的字符串长度为5,用cin.get()读取得到的字符串长度为4。
2.3 cin.getline()
读取指定长度的字符,包括空白字符。
用法示例:
char str[20];
cin.getline(str, sizeof(str)); // 第3个参数也可以指定终止字符
cin.getline()与cin.get()指定读取长度时的用法几乎一样。区别在于,如果输入的字符个数大于指定的最大长度n-1(不含终止符),cin.get()会使余下字符残留在缓冲区,等待下次读取;而cin.getline()会给输入流设为 Fail 状态,在主动恢复之前,无法再进行正常输入。
2.4 getline()
getline()并不是标准输入流istream的函数,而是字符串流sstream的函数,只能用于读取数据给**string类对象**,使用时也需要包含头文件<string>。
如果使用getline()读取标准输入流的数据,需要显式指定输入流。
用法示例:
string str;
getline(cin, str);
getline()会读取所有空白字符,且缓冲区末尾的换行符会被丢弃,不残留也不写到字符串结尾。同时,由于string对象的空间是动态分配的,所以会一次性将缓冲区读完,不存在读不完残留在缓冲区的问题。
需要注意的是,假如缓冲区开头就是换行符(比如可能是上一次cin残留的),则getline()会直接读取到空字符串并结束,不会给键盘输入的机会。所以这种情况下要注意先清除开头的换行符。
总结
在 C 中,建议使用scanf()进行格式化读取,用fgets()读取整行,用fgetc()或getchar()读取单个字符。
在 C++ 中,建议使用cin >>进行格式化读取,而cin.get()、cin.getline、getline(string)有各自的适用情况。
注意fgets()和cin.get()在对换行符的清理方面有所区别。
二、标准输出流
1、C 标准输出
1.1 标准输出流及对缓冲区的理解
相应于输入流的stdin,输出流也有其默认的文件描述符stdout,对应着命令行终端(Windows 中称为控制台)的显示。此外,还有对应错误输出的stderr,默认也是终端的显示。它们都可以被重定向到文件中以便持久保存和查看,在此不作赘述。
stdout也是行缓冲I/O,它与stdin类似也有三者之间的数据同步:从用户程序到stdout的输出缓冲区,由用户程序决定;从stdout的输出缓冲区到终端的显示,只有缓冲区末尾遇到换行符\n才会进行。如果输出缓冲区末尾没有换行符\n,是不会打印显示输出的。
例如以下程序:
// 程序 1
int main(int argc, char* argv[])
{
printf("Hello World!\n");
while(1){}
return 0;
}
// 程序 2
int main(int argc, char* argv[])
{
printf("Hello World!");
while(1){}
return 0;
}
// 程序 3
int main(int argc, char* argv[])
{
printf("Hello World!")
return 0;
}
// 程序 1
int main(int argc, char* argv[])
{
printf("Hello World!\nABCDE");
while(1){}
return 0;
}
程序 1 中,printf()输出内容的最后有换行符\n,所以将在屏幕上输出Hello World!并换行,然后进入while(1)循环阻塞住。
程序 2 中,把\n去掉了,此时终端不会显示任何内容。因为程序进入死循环后,没有机会向stdout中写入\n使其清空缓冲。
程序 3 中,虽然没有写入换行符,但是依然能够在终端打印Hello World!(只是没有换行)。这是因为程序结束时会自动清空缓冲区。(除此之外,当缓冲区被填满时也会自动清空)
程序 4 能够进一步加深对行缓冲的理解。它在程序 1 的基础上,在换行符之后又加上了几个字符。运行可以发现终端只打印了Hello World!并换行,而没有打印ABCDE。
输出函数通常没有针对对空格、制表符的特殊行为,比输入要简单一些。特殊的处理一般只有换行符。
1.2 printf()
1.2.1 printf()简介
printf()是C语言标准库函数,用于将格式化后的字符串输出到标准输出。标准输出,即标准输出文件,对应终端的屏幕。
printf()申明于头文件stdio.h。
函数原型:
int printf ( const char * format, ... );
返回值: 正确:返回输出的字符总数;错误:返回负值。
与此同时,输入输出流错误标志将被置值,可由指示器ferror来检查输入输出流的错误标志。
调用格式: printf()函数的调用格式为:printf("格式化字符串",输出表列)。
格式化字符串包含三种对象,分别为:
(1)字符串常量; (2)格式控制字符串; (3)转义字符。
字符串常量原样输出,在显示中起提示作用。输出表列中给出了各个输出项,要求格式控制字符串和各输出项在数量和类型上应该一一对应。
其中格式控制字符串是以%开头的字符串,在%后面跟有各种格式控制符,以说明输出数据的类型、宽度、精度等。
**注:**本文的所有示例代码均在Linux环境下以g++ 4.4.6编译成64位程序的执行。
1.2.2 格式控制字符串详解
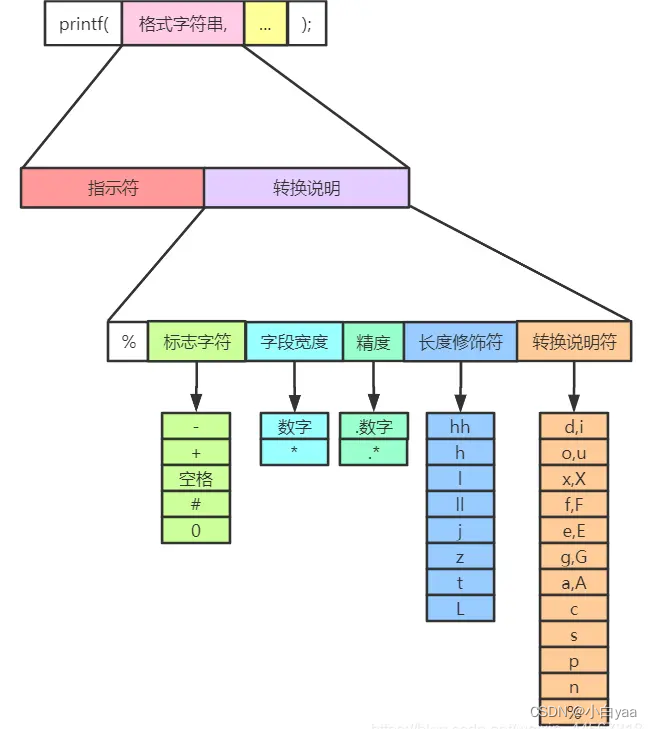
printf的格式控制字符串组成如下:
%[flags][width][.prec][length]type
%[标志][最小宽度][.精度][类型长度]类型
1.2.2.1 类型(type)
首先说明类型,因为类型是格式控制字符串的重中之重,是必不可少的组成部分,其它的选项都是可选的。type用于规定输出数据的类型,含义如下:
| 字符 | 对应数据类型 | 含义 | 示例 |
|---|---|---|---|
| d/i | int | 输出十进制有符号32bits整数,i是老式写法 | printf(“%i”,123);输出123 |
| o | unsigned int | 无符号8进制(octal)整数(不输出前缀0) | printf(“0%o”,123);输出0173 |
| u | unsigned int | 无符号10进制整数 | printf(“%u”,123);输出123 |
| x/X | unsigned int | 无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF(不输出前缀0x) | printf(“0x%x 0x%X”,123,123);输出0x7b 0x7B |
| f/lf | float(double) | 单精度浮点数用f,双精度浮点数用lf(printf可混用,但scanf不能混用) | printf(“%.9f %.9lf”,0.000000123,0.000000123);输出0.000000123 0.000000123。注意指定精度,否则printf默认精确到小数点后六位(单精度是六位,双精度是八位) |
| e/E | float(double) | 科学计数法,使用指数(Exponent)表示浮点数,此处”e”的大小写代表在输出时“e”的大小写 | printf(“%e %E”,0.000000123,0.000000123);输出1.230000e-07 1.230000E-07 |
| g | float(double) | 根据数值的长度,选择以最短的方式输出,%f或%e | printf(“%g %g”,0.000000123,0.123);输出1.23e-07 0.123 |
| G | float(double) | 根据数值的长度,选择以最短的方式输出,%f或%E | printf(“%G %G”,0.000000123,0.123);输出1.23E-07 0.123 |
| c | char | 字符型。可以把输入的数字按照ASCII码相应转换为对应的字符 | printf(“%c\n”,64)输出A |
| s | char* | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以空字符’\0‘结尾) | printf(“%s”,“测试test”);输出:测试test |
| S | wchar_t* | 宽字符串。输出字符串中的字符直至字符串中的空字符(宽字符串以两个空字符’\0‘结尾) | setlocale(LC_ALL,“zh_CN.UTF-8”); wchar_t wtest[]=L"测试Test"; printf(“%S\n”,wtest); 输出:测试test |
| p | void* | 以16进制形式输出指针 | printf(“%010p”,“lvlv”);输出:0x004007e6 |
| n | int* | 什么也不输出。%n对应的参数是一个指向signed int的指针,在此之前输出的字符数将存储到指针所指的位置 | int num=0; printf(“lvlv%n”,&num); printf(“num:%d”,num); 输出:lvlvnum:4 |
| % | 字符% | 输出字符‘%’(百分号)本身 | printf(“%%”);输出:% |
| m | 无 | 打印errno值对应的出错内容 | printf(“%m\n”); |
| a/A | float(double) | 十六进制p计数法输出浮点数,a为小写,A为大写 | printf(“%a %A”,15.15,15.15);输出:0x1.e4ccccccccccdp+3 0X1.E4CCCCCCCCCCDP+3 |
注意: (1)使用printf输出宽字符时,需要使用setlocale指定本地化信息并同时指明当前代码的编码方式。除了使用%S,还可以使用%ls。
(2)%a和%A是C99引入的格式化类型,采用十六进制p计数法输出浮点数。p计数法类似E科学计数法,但不同。数以0x开头,然后是16进制浮点数部分,接着是p后面是以 2为底的阶码。以上面输出的15.15为例,推算输出结果。15.15转换成二进制为1111.00 1001 1001 1001 1001 ...,因为二进制表示数值的离散特点,计算机对于小数有时是不能精确表示的,比如0.5可以精确表示为
(3)格式控制字符串除了指明输出的数据类型,还可以包含一些其它的可选的格式说明,依序有 flags, width, .precision and length。下面一一讲解。
1.2.2.2 标志(flags)
flags规定输出样式,取值和含义如下:
| 字符 | 名称 | 说明 |
|---|---|---|
| - | 减号 | 结果左对齐,右边填空格。默认是右对齐,左边填空格。 |
| + | 加号 | 输出符号(正号或负号) |
| space | 空格 | 输出值为正时加上空格,为负时加上负号 |
| # | 井号 | type是o、x、X时,增加前缀0、0x、0X。 type是a、A、e、E、f、g、G时,一定使用小数点。默认的,如果没有小数部分则不输出小数点。 type是g、G时,尾部的0保留。 |
| 0 | 数字零 | 将输出的前面补上0,直到占满指定列宽为止(不可以搭配使用“-”) |
示例:
printf("%5d\n",1000);//默认右对齐,左边补空格
printf("%-5d\n",1000); //左对齐,右边补空格
printf("%+d %+d\n",1000,-1000); //输出正负号
printf("% d % d\n",1000,-1000); //正号用空格替代,负号输出
printf("%x %#x\n",1000,1000); //输出0x
printf("%.0f %#.0f\n",1000.0,1000.0)//当小数点后没有值时依然输出小数点
printf("%g %#g\n",1000.0,1000.0); //保留小数点后后的0
printf("%05d\n",1000); //前面补0
输出结果:
1000
1000
+1000 -1000
1000 -1000
3e8 0x3e8
1000 1000.
1000 1000.00
01000

1.2.2.3 输出最小宽度(width)
用十进制整数来表示输出的最少位数。若实际位数多于指定的宽度,则按实际位数输出,若实际位数少于定义的宽度则补以空格或0。width的可能取值如下:
| width | 描述 | 示例 |
|---|---|---|
| 数值 | 十进制整数 | printf(“%06d”,1000); 输出:001000 |
| * | 星号。不显示指明输出最小宽度,而是以星号代替,在printf的输出参数列表中给出 | printf(“%0*d”,6,1000); 输出:001000 |
1.2.2.4 精度(.precision)
精度格式符以“.”开头,后跟十进制整数。可取值如下:
| .precision | 描述 |
|---|---|
.数值 | 十进制整数。 (1)对于整型(d,i,o,u,x,X),precision表示输出的最小的数字个数,不足补前导零,超过不截断。 (2)对于浮点型(a, A, e, E, f ),precision表示小数点后数值位数,默认为六位,不足补后置0,超过则截断。 (3)对于类型说明符g或G,表示可输出的最大有效数字。 (4)对于字符串(s),precision表示最大可输出字符数,不足正常输出,超过则截断。 precision不显示指定,则默认为0 |
| .* | 以星号代替数值,类似于width中的*,在输出参数列表中指定精度。 |
示例:
printf("%.8d\n",1000); //不足指定宽度补前导0,效果等同于%06d
printf("%.8f\n",1000.123456789); //超过精度,截断
printf("%.8f\n",1000.123456); //不足精度,补后置0
printf("%.8g\n",1000.123456); //最大有效数字为8位
printf("%.8s\n",“abcdefghij”); //超过指定长度截断
输出结果:
00001000
1000.12345679
1000.12345600
1000.1235
abcdefgh
**注意,**在对浮点数和整数截断时,存在四舍五入。
1.2.2.5 类型长度(length)
类型长度指明待输出数据的长度。因为相同类型可以有不同的长度,比如整型有16bits的short int,32bits的int,也有64bits的long int,浮点型有32bits的单精度float和64bits的双精度double。为了指明同一类型的不同长度,于是乎,类型长度(length)应运而生,成为格式控制字符串的一部分。
因为Markdown表格不支持单元格合并,背景颜色等样式,所以直接引用printf.C++ reference的表格。

**注意:**黄色背景行标识的类型长度说明符和相应的数据类型是C99引入的。
示例代码:
printf("%hhd\n",'A'); //输出有符号char
printf("%hhu\n",'A'+128); //输出无符号char
printf("%hd\n",32767); //输出有符号短整型short int
printf("%hu\n",65535); //输出无符号短整型unsigned short int
printf("%ld\n",0x7fffffffffffffff); //输出有符号长整型long int
printf("%lu\n",0xffffffffffffffff); //输出有符号长整型unsigned long int
输出结果:
65
193
32767
65535
9223372036854775807
18446744073709551615
注意: long int到底是32bits还是64bits跟生成的程序是32bits还是64bits一一对应,如果使用g++编译程序的话,可通过-m32或-m64选项分别生成32bits和64bits的程序。因本人测试代码编译生成的是64bits的程序,所以long int也就是64btis。
1.2.2.6 转义字符
转义字符在字符串中会被自动转换为相应操作命令。printf()使用的常见转义字符如下:
| 转义字符 | 意义 |
|---|---|
| \a | 警报(响铃)符 |
| \b | 回退符 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 横向制表符 |
| \v | 纵向制表符 |
| \ | 反斜杠 |
| \” | 双引号 |
1.2.2.7 关于printf缓冲
在printf的实现中,在调用write之前先写入IO缓冲区,这是一个用户空间的缓冲。系统调用是软中断,频繁调用,需要频繁陷入内核态,这样的效率不是很高,而printf实际是向用户空间的IO缓冲写,在满足条件的情况下才会调用write系统调用,减少IO次数,提高效率。
printf在glibc中默认为行缓冲,遇到一下几种情况会刷新缓冲区,输出内容: (1)缓冲区填满; (2)写入的字符中有换行符\n或回车符\r; (3)调用fflush手动刷新缓冲区; (4)调用scanf要从输入缓冲区中读取数据时,也会将输出缓冲区内的数据刷新。
可使用setbuf(stdout,NULL)关闭行缓冲,或者setbuf(stdout,uBuff)设置新的缓冲区,uBuff为自己指定的缓冲区。也可以使用setvbuf(stdout,NULL,_IOFBF,0);来改变标准输出为全缓冲。全缓冲与行缓冲的区别在于遇到换行符不刷新缓冲区。
printf在VC++中默认关闭缓冲区,且只能设置全缓冲。输出时会及时的输到屏幕
Linux和Windows下的缓冲区管理可见:C的全缓冲、行缓冲和无缓冲。
1.2.2.8 小结
关于本文,个人存在两个疑问。第一个是C++ Reference中还提到了一个type:%F,目前还没有发现该type的用处与%f的区别所在,也请知之者留言告知,万分感谢。第二个是在输出宽字符串时,发现将printf和wprintf同时使用时,wprintf无法输出,具体不知原因,这里建议不要同时使用printf和wprintf,以免发生错误。知道为何的读者也请告知,谢谢!
printf和wprintf不能同时输出宽字符串的示例代码如下:
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main(int argc,char* argv[]){
char test[]="测试Test"; setlocale(LC_ALL,"zh_CN.UTF-8");
wchar_t wtest[]=L"0m~K0m~UTest";
printf("printf:%S\n",wtest);
//语句1:可正常输出"测试Test" wprintf(L"wprintf:%S\n",wtest);
//语句2:无任何内容输出
}
上面的代码中语句1和语句二不能同时存在,否则只能正常输出第一个。原因尚不清楚,估计和wprintf和printf内部实现有关,也不知道在Windows平台是否也存在这种问题,有兴趣的读者可以尝试一下。
1.3 puts()
将字符串和一个尾随的换行符\n写入到stdout的缓冲区。根据行缓冲的性质,终端也会立即进行打印显示。
用法示例:
puts("hello"); // 立即输出hello并换行
puts()对换行符的处理与gets()“相反”。gets()会自动丢弃一个换行符,而puts()则是自动写入一个换行符。
1.4 fputs()
将字符串写入指定输出流,可以是文件流、stdout或stderr等。stderr是标准错误流,它是无缓冲的,会立即输出到屏幕,而不是等待换行符才输出。
用法示例:
fputs("hello world", stdout); // 不会立即输出
fputs("hello world\n", stdout); // 立即输出
fputs("hello world", stderr); // 立即输出
与fgets()一样,fputs()不会主动操作换行符。如果希望立即输出,需要自己加上换行符\n。
1.5 fputc() & putc()
将一个字符写入指定输出流,可以是文件流、stdout或stderr等。
用法示例:
char c = 'q';
fputc(c, stdout);
c = '\n';
putc(c, stdout);
fputc()和putc()只是把字符写入stdout,没有任何额外操作。因此如果希望立即输出,需要自己加上换行符\n。
1.6 putchar()
将一个字符写入到标准输出流stdout。
用法示例:
char c = 'x';
putchar(c);
同上,putchar()不操作换行符。如果希望立即输出,需要自己加上换行符\n。
1.7 fflush()
该函数的功能是强制刷新缓冲区,将数据立即写到对应的文件(或设备)。其参数可以是文件流指针,也可以是stdout。
用法示例:
fputs("Hello World!", stdout);
fflush(stdout);
while (1);
上面的程序在进入死循环前,会输出Hello World!字符串到屏幕。
注意:不能够将
fflush()用于stdin!这可能导致不可预料的后果。
2、C++ 标准输出
2.1 cout
cout是ostream类的一个实例。cout是行缓冲的。
用法示例:
char str[] = "hello world";
cout << "str: " << str << endl;
插入endl对象时,将立即清空输出缓冲区并显示,然后输出一个换行符\n。
也有cout.put()等函数,不常用。
C++中的输出控制符是一种用于格式化输出文本的特殊标记或指令,它们通常与输出流对象(如cout)一起使用,以定义如何在屏幕上显示数据。C++提供了一系列内置的输出控制符,以便于开发人员更好地控制输出的格式和布局。以下是一些常见的C++输出控制符以及它们的用法和效果:
2.1.1 std::endl
-
作用:插入一个换行符并刷新输出缓冲区。
-
用法示例:
std::cout << "Hello, World!" << std::endl;
2.1.2 std::setw(int n)
-
作用:设置字段宽度,用于指定下一个输出项的最小字符数。
-
用法示例:
#include <iomanip> std::cout << std::setw(10) << 42 << std::endl; // 输出: 42
2.1.3 std::setprecision(int n)
-
作用:设置浮点数的输出精度(小数位数)。
-
用法示例:
#include <iomanip> double pi = 3.141592653589793; std::cout << std::setprecision(3) << pi << std::endl; // 输出:3.14
2.1.4 std::fixed
-
作用:指定浮点数的输出格式为固定小数点表示法。
-
用法示例:
#include <iomanip> double value = 12.3456; std::cout << std::fixed << value << std::endl; // 输出:12.345600
2.1.5 std::scientific
-
作用:指定浮点数的输出格式为科学计数法表示法。
-
用法示例:
#include <iomanip> double value = 0.00012345; std::cout << std::scientific << value << std::endl; // 输出:1.234500e-04
2.1.6 std::left 和 std::right
-
作用:指定输出文本的对齐方式,左对齐或右对齐。
-
用法示例:
std::cout << std::left << std::setw(10) << "Hello" << std::setw(10) << "World" << std::endl; // 输出:Hello World
2.1.7 std::setfill(char c)
-
作用:设置填充字符,用于填充字段的空白部分。
-
用法示例:
#include <iomanip> std::cout << std::setfill('*') << std::setw(10) << 42 << std::endl; // 输出:********42
2.1.8 std::hex 和 std::oct
-
作用:指定整数的输出格式为十六进制或八进制。
-
用法示例:
int value = 255; std::cout << std::hex << value << std::endl; // 输出:ff std::cout << std::oct << value << std::endl; // 输出:377
这些输出控制符可以单独或组合使用,以满足特定的输出格式需求。通过使用这些控制符,你可以更好地控制输出的外观,使其适应你的应用程序的需要。注意,在使用<iomanip>头文件之前,你需要包含合适的标准库头文件。
2.2 cerr
cerr是标准错误流,也是ostream类的一个实例,并默认输出设备为显示屏上的命令行终端。它默认与stderr同步。
cerr是非缓冲的,即插入数据时会立即输出。
用法示例:
char str[] = "File open FAILED!";
cerr << "[Error] " << str;
2.3 clog
clog是标准日志流,也是ostream类的一个实例,并默认输出设备为显示屏上的命令行终端。
clog是有缓冲的,但具体的刷新条件没有找到资料。实测以下代码是可以输出在屏幕的:
clog << "Failed!";
while(1){}
2.4 总结
标准输出相比输入来说较为简单。需要注意的是stdout和cout是行缓冲的,而stderr和cerr是无缓冲的。