文章目录
- 前言
- 一、hash 类型相关命令
- 1.1 HSET 和 HSETNX
- 1.2 HGET 和 HMGET
- 1.3 HKEYS、HVALS 和 HGETALL
- 1.4 HEXISTS 和 HDEL
- 1.5 HLEN
- 1.6 HINCRBY 和 HINCRBYFLOAT
- 1.7 哈希相关命令总结
- 二、hash 类型内部编码
- 三、hash 类型的应用场景
- 四、原生,序列化,哈希类型缓存方式对比
- 4.1 原生字符串类型
- 4.2 序列化字符串类型(例如JSON格式)
- 4.3 哈希类型
- 4.4 总结
前言
在构建和优化应用程序时,数据缓存是提高性能和降低数据库负载的关键策略之一。Redis(Remote Dictionary Server)是一个高性能的内存数据库,广泛用于数据缓存和快速数据访问。其中,哈希类型(Hash)是 Redis 中的一种强大数据结构,通常用于存储对象、映射关系和键值对等数据。
在本文中,我们将深入探讨Redis中的哈希类型。我们将从哈希类型的基本命令入手,逐步介绍它们的使用方法、内部编码方式以及在实际应用场景中的应用。通过学习和理解 Redis 哈希类型,可以帮助我们够更好地利用 Redis 来优化数据存储和访问,提高应用程序的性能。
接下来,让我们深入了解 Redis 哈希类型的相关内容。
一、hash 类型相关命令
1.1 HSET 和 HSETNX
HSET
-
作用 : 指定的哈希表中设置字段的值,如果字段存在则更新,否则创建。并且可以同时设置多组字段。
-
语法:
HSET key field value [field value ... ]
HSETNX
- 作用:仅在字段不存在时,在指定的哈希表中设置字段的值。设置成功返回 1,否则返回 0。
- 语法:
HSETNX key field value
- 使用示例

1.2 HGET 和 HMGET
HGET
- 作用:获取指定哈希表中字段的值。
- 语法:
HGET key field
HMGET
- 作用:是获取指定哈希表中多个字段的值。
- 语法:
HMGET key field1 [field2 ...]
- 使用示例

当然,我会继续完善下面的部分,以涵盖哈希类型相关命令的详细说明:
1.3 HKEYS、HVALS 和 HGETALL
HKEYS
- 作用:获取指定哈希表中所有字段的名称。
- 语法:
HKEYS key
HVALS
- 作用:获取指定哈希表中所有字段的值。
- 语法:
HVALS key
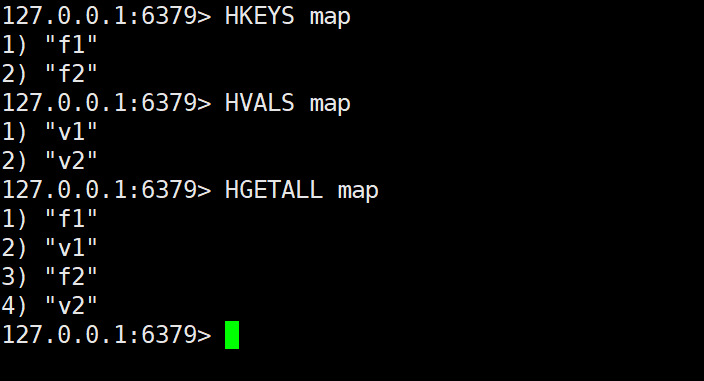
HGETALL
- 作用:获取指定哈希表中所有字段和对应的值。
- 语法:
HGETALL key
- 使用案例
1.4 HEXISTS 和 HDEL
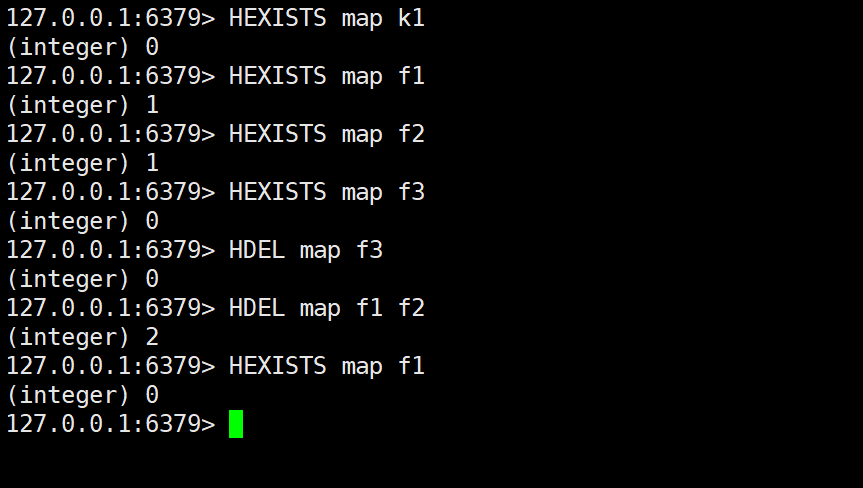
HEXISTS
- 作用:检查指定哈希表中是否存在某个字段。
- 语法:
HEXISTS key field
HDEL
- 作用:删除指定哈希表中的一个或多个字段。
- 语法:
HDEL key field1 [field2 ...]
- 使用案例
1.5 HLEN
HLEN
- 作用:获取指定哈希表中字段的数量(即哈希表的大小)。
- 语法:
HLEN key
- 使用案例

1.6 HINCRBY 和 HINCRBYFLOAT
HINCRBY
- 作用:将哈希表中指定字段的值增加一个整数。
- 语法:
HINCRBY key field increment
HINCRBYFLOAT
- 作用:将哈希表中指定字段的值增加一个浮点数。
- 语法:
HINCRBYFLOAT key field increment
- 使用案例

1.7 哈希相关命令总结
以下是哈希类型相关命令的总结,包括命令、作用和时间复杂度:
| 命令 | 作用 | 时间复杂度 |
|---|---|---|
| HSET | 在哈希表中设置字段的值,存在则更新,否则创建。可同时设置多组字段。 | O(1) |
| HSETNX | 仅在字段不存在时,在哈希表中设置字段的值,成功返回1,否则返回0。 | O(1) |
| HGET | 获取指定哈希表中字段的值。 | O(1) |
| HMGET | 获取指定哈希表中多个字段的值。 | O(N),N为字段数 |
| HKEYS | 获取指定哈希表中所有字段的名称。 | O(N),N为字段数 |
| HVALS | 获取指定哈希表中所有字段的值。 | O(N),N为字段数 |
| HGETALL | 获取指定哈希表中所有字段和对应的值。 | O(N),N为字段数 |
| HEXISTS | 检查指定哈希表中是否存在某个字段。 | O(1) |
| HDEL | 删除指定哈希表中的一个或多个字段。 | O(N),N为被删除的字段数 |
| HLEN | 获取指定哈希表中字段的数量(即哈希表的大小)。 | O(1) |
| HINCRBY | 将哈希表中指定字段的值增加一个整数。 | O(1) |
| HINCRBYFLOAT | 将哈希表中指定字段的值增加一个浮点数。 | O(1) |
二、hash 类型内部编码
Redis 是一种高性能的内存数据库,支持多种数据结构,包括哈希(Hash)。在 Redis 中,哈希数据类型有两种内部编码方式,分别是 ziplist(压缩列表)和 hashtable(哈希表)。这两种编码方式的选择取决于哈希的大小和存储特性。
1. ziplist(压缩列表):
ziplist 是 Redis 中用于内部编码较小哈希的紧凑数据结构。以下是一些关于 ziplist 的关键特性:
- 当哈希类型的元素个数相对较少,且所有字段和对应的值都满足一定的限制条件时,Redis 会使用 ziplist 作为哈希的内部实现。
- 默认情况下,Redis 会选择 ziplist。具体来说,如果哈希的元素个数不超过 512 个,并且所有值都小于 64 字节,那么 ziplist 就是首选的编码方式。
- Ziplist 是一种紧凑的数据结构,它能够在节省内存方面表现得比 hashtable 更出色。它将多个哈希元素连续存储在一起,有效地减少了内存占用。
2. hashtable(哈希表):
hashtable 是 Redis 中用于存储大规模哈希数据的内部编码方式。以下是 hashtable 的关键特性:
- 当哈希类型的元素个数超过了 ziplist 的配置限制,或者有字段对应的值大于 64 字节时,Redis 会将内部编码切换为 hashtable。
- Hashtable 是一种散列表数据结构,它具有 O(1) 的读写时间复杂度,适用于大规模的哈希数据集。
- 切换到 hashtable 可以提供更好的性能和内存管理,特别是在处理大型哈希或包含大值的情况下。
根据上述描述,下面是一些示例演示哈希数据类型的内部编码以及在何种条件下会发生编码转换:
示例 1:使用 ziplist 编码
> hmset hashkey f1 v1 f2 v2
OK
> object encoding hashkey
"ziplist"
在此示例中,由于字段数较少且值满足条件,Redis 使用 ziplist 作为内部编码。
示例 2:切换到 hashtable 编码
> hset hashkey f3 "one string is bigger than 64 bytes ..." 1
OK
> object encoding hashkey
"hashtable"
在此示例中,因为有一个字段对应的值大于 64 字节,Redis 将内部编码切换为 hashtable。
示例 3:切换到 hashtable 编码
> hmset hashkey f1 v1 h2 v2 f3 v3 ... (超过 512 个字段) ...
OK
> object encoding hashkey
"hashtable"
在此示例中,由于字段数超过了 512 个,Redis 将内部编码转换为 hashtable。
这些内部编码方式的选择是为了在不同情况下平衡内存占用和性能。Redis 会根据需要自动进行这些编码转换,以优化存储和操作效率。无论您的哈希数据集大小如何,Redis 都会根据配置和数据特性智能地选择适当的内部编码方式。这种自动优化确保了 Redis 在各种工作负载下的出色性能表现。
三、hash 类型的应用场景
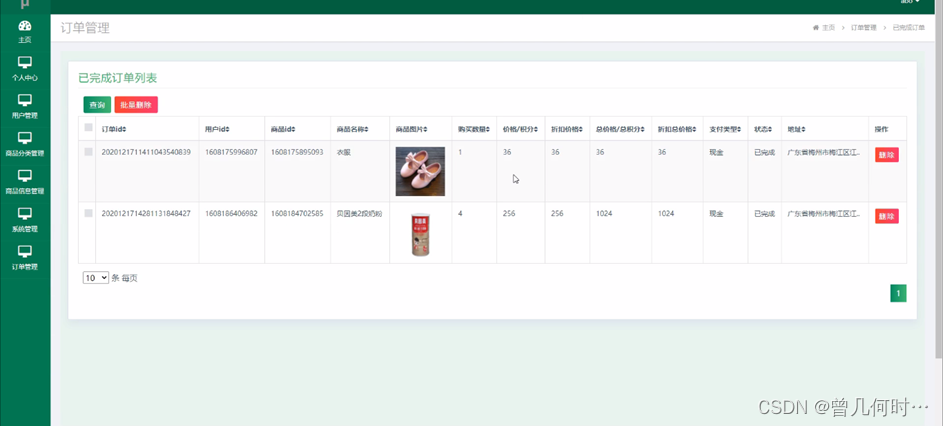
在本部分,我们将探讨哈希类型在应用程序中的实际应用场景。首先,让我们回顾一下关系型数据库中保存用户信息的结构。
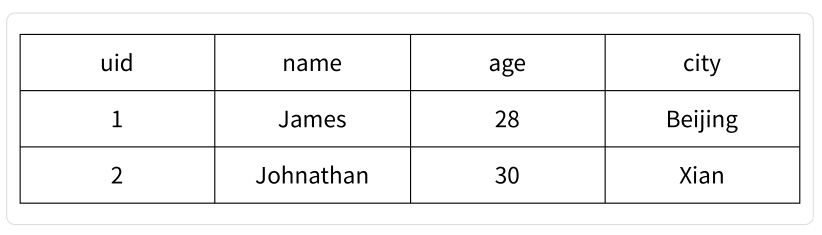
上图展示了关系型数据表记录的两条用户信息,其中用户的属性表现为表的列,每条用户信息则表现为行。如果我们想在 Redis 中映射这两个用户信息,可以使用哈希类型。
使用哈希类型映射用户信息:
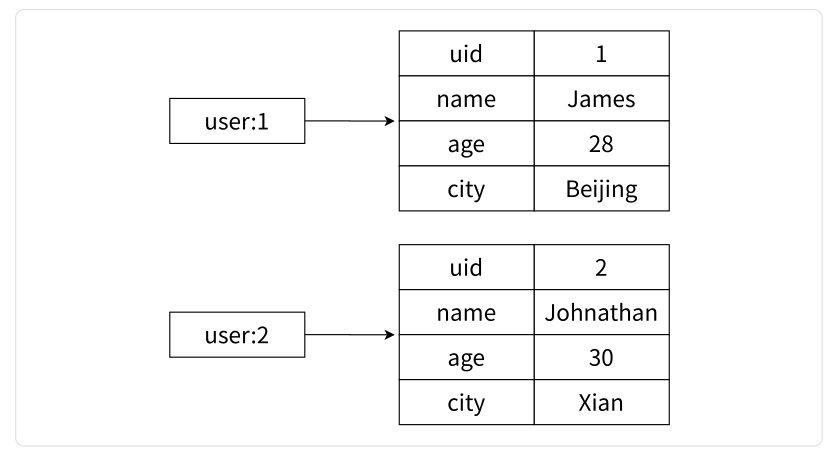
相比于使用 JSON 格式的字符串缓存用户信息,哈希类型更加直观,并且在更新操作上更加灵活。我们可以将每个用户的 ID 定义为键的后缀,然后使用多个 field-value 对应用户的各个属性,类似以下伪代码:
UserInfo getUserInfo(long uid) {
// 根据 uid 得到 Redis 的键
String key = "user:" + uid;
// 尝试从 Redis 中获取对应的值
userInfoMap = Redis 执行命令:hgetall key;
// 如果缓存命中(hit)
if (userInfoMap != null) {
// 将映射关系还原为对象形式
UserInfo userInfo = 利用映射关系构建对象(userInfoMap);
return userInfo;
}
// 如果缓存未命中(miss)
// 从数据库中,根据 uid 获取用户信息
UserInfo userInfo = MySQL 执行 SQL:select * from user_info where uid = <uid>;
// 如果表中没有 uid 对应的用户信息
if (userInfo == null) {
响应 404;
return null;
}
// 将缓存以哈希类型保存
Redis 执行命令:hmset key name userInfo.name age userInfo.age city userInfo.city;
// 写入缓存,为了防止数据腐烂(rot),设置过期时间为 1 小时(3600 秒)
Redis 执行命令:expire key 3600;
// 返回用户信息
return userInfo;
}
上述代码演示了一个常见的缓存策略,首先尝试从 Redis 缓存中获取数据,如果未命中则从数据库中检索,并将结果存储到 Redis 中以便后续访问。这种策略可以提高访问性能并减轻数据库负担。
然而,需要注意的是哈希类型和关系型数据库存在两个主要差异:
-
哈希类型的稀疏性: 哈希类型允许每个键具有不同的 field,而关系型数据库在添加新的列时需要为所有行设置值,即使是 null。
-
复杂关系查询的不适用性: 关系型数据库支持复杂的关系查询,而 Redis 不适用于模拟关系型复杂查询,例如联表查询和聚合查询,维护成本较高。
关系型数据库的稀疏性示例:
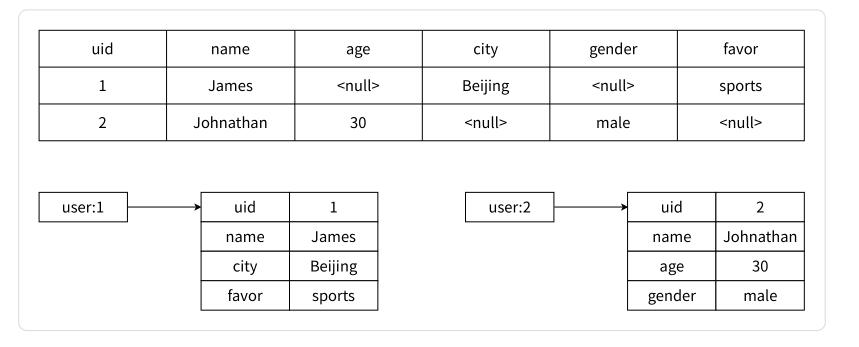
通过哈希类型,我们可以更直观地映射和存储用户信息,适应不同应用场景的需求。哈希类型的使用方式简单、直观、灵活,特别适合局部属性的变更和查询操作,同时也具有较好的内存效率。
四、原生,序列化,哈希类型缓存方式对比
当涉及到缓存用户信息时,有多种不同的缓存方式可供选择。以下是对三种常见的缓存方式进行详细比较和分析:原生字符串类型、序列化字符串类型(例如JSON格式),以及哈希类型。这里探讨它们的实现方法、优点和缺点,以帮助您更好地选择适用于您应用程序的缓存策略。
4.1 原生字符串类型
实现方法: 使用原生字符串类型,将每个用户属性存储为单独的键值对,例如:
set user:1:name James
set user:1:age 23
set user:1:city Beijing
优点:
- 实现简单,每个属性都以单独的键存储,易于理解和维护。
- 针对个别属性变更很灵活。
缺点:
- 占用过多的键,导致内存占用量较大。
- 用户信息在Redis中分散存储,缺少内聚性,不便于批量操作和管理。
- 不适用于需要一次性获取完整用户信息的情况,需要大量的键操作。
适用场景: 这种方式适合于需要对用户属性进行个别、频繁变更的场景,但不适用于需要一次性获取完整用户信息的情况。
4.2 序列化字符串类型(例如JSON格式)
实现方法: 使用序列化字符串类型,将用户信息以JSON格式等方式序列化后存储为一个键值对,例如:
set user:1 {"name": "James", "age": 23, "city": "Beijing"}
优点:
- 适用于以整体作为操作单元的信息存储,编程较为简单。
- 可以高效地使用内存,特别适合存储大对象或数据结构。
缺点:
- 序列化和反序列化需要一定开销。
- 不适合频繁进行个别属性的更新或查询,缺乏灵活性。
适用场景: 这种方式适用于需要一次性获取完整用户信息的场景,特别是当用户信息是复杂对象或数据结构时。
4.3 哈希类型
实现方法: 使用哈希类型,将用户信息存储为Redis的哈希类型,例如:
hmset user:1 name James age 23 city Beijing
优点:
- 简单、直观、灵活。
- 适用于信息的局部变更或获取操作,支持对单个属性的读写。
- 内部编码可以是 ziplist 或 hashtable,具有较好的灵活性和内存效率。
缺点:
- 需要控制哈希在 ziplist 和 hashtable 两种内部编码之间的转换,可能会带来内存消耗。
- 不适合需要一次性获取完整用户信息的情况,可能需要多次读取。
适用场景: 哈希类型适用于需要对用户属性进行局部变更或频繁单独属性操作的场景,也适合需要对属性进行灵活查询的情况。
4.4 总结
选择合适的缓存方式应根据具体的应用需求和访问模式来确定。通常情况下,可以根据不同的数据特点和操作需求,综合考虑这三种缓存方式,并在应用程序中进行适当的组合和使用,以获得最佳性能和灵活性。
例如,可以使用哈希类型缓存来处理局部属性的变更和查询,同时使用序列化字符串类型缓存来获取完整用户信息。这样,可以充分发挥Redis的优势,提高数据访问的效率,同时保持灵活性和可维性。