系列文章目录
- 2024年java面试(一)–spring篇
- 2024年java面试(二)–spring篇
- 2024年java面试(三)–spring篇
- 2024年java面试(四)–spring篇
- 2024年java面试–集合篇
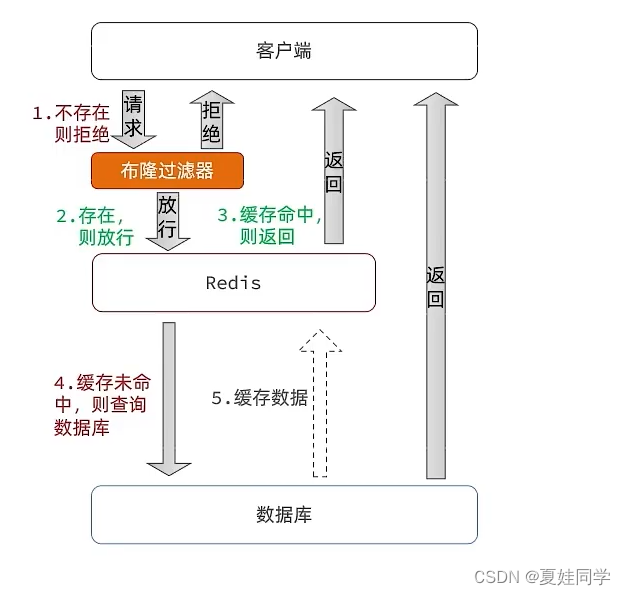
- 2024年java面试–redis(1)
- 2024年java面试–redis(2)
文章目录
- 系列文章目录
- 索引
- 索引的含义
- 创建索引
- 索引的作用与缺点
- 索引的使用场景
- 索引的底层原理
- B-Tree
- B+Tree
- B-树和B+树的区别
- 四种树
- B+树的优势
- Innodb和Myisam引擎
- 存储引擎的选择
- InnoDB和MyISAM区别
- InnoDB事务
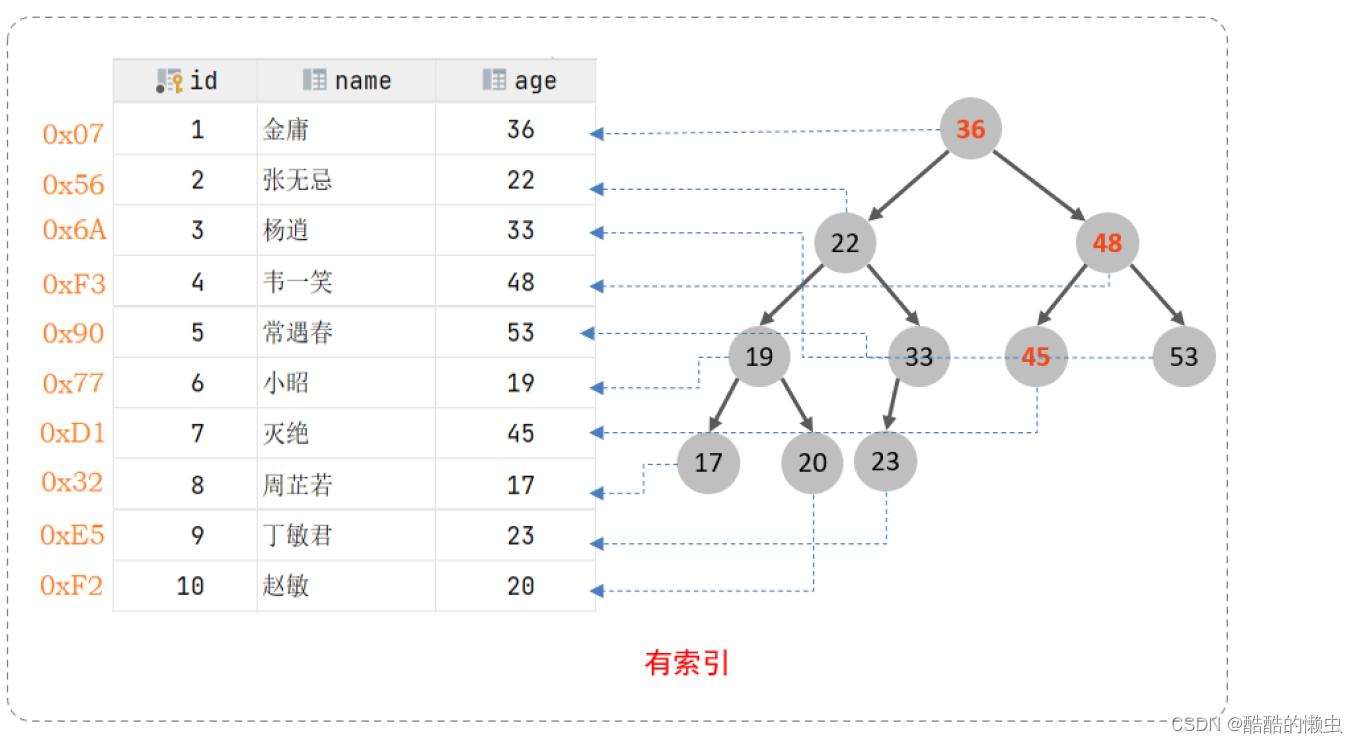
索引
索引的含义
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库中表的数据。索引的实现通常使用B树和变种的B+树(MySQL常用的索引就是B+树)。除了数据之外,数据库系统还维护为满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这种数据结构就是索引。简言之,索引就类似于书本,字典的目录。
- 主键索引:一张表只能有一个主键索引,主键索引列不能有空值和重复值
- 唯一索引:唯一索引不能有相同值,但允许为空
- 普通索引:允许出现重复值
- 组合索引:对多个字段建立一个联合索引,减少索引开销,遵循最左匹配原则
- 全文索引:myisam引擎支持,通过建立倒排索引提升检索效率,广泛用于搜索引擎
创建索引
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名(字段名) [USING 索引方法];
说明:
UNIQUE:可选。表示索引为唯一性索引。
FULLTEXT:可选。表示索引为全文索引。
INDEX和KEY:用于指定字段为索引,两者选择其中之一就可以了,作用是一样的。
索引名:可选。给创建的索引取一个新名称。
字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。
注:索引方法默认使用B+TREE。
索引的作用与缺点
作用
通过创建索引,可以再查询的过程中,提高系统的性能
通过创建唯一性索引,可以保持数据库表中每一行数据的唯一性
在使用分组和排序子句进行数据检索时,可以减少查询中分组和排序的时间
缺点
创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增大
索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大
在对表中的数据进行增删改时需要耗费较多的时间,因为索引也要动态地维护
索引的使用场景
应创建索引的场景
1.经常需要搜索的列上
2.作为主键的列上
3.经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度
4.经常需要根据范围进行搜索的列上
5.经常需要查询条件(where)、排序(order by)、分组(group by)的列上
6.如果是字符串类型,字符串长度比较长,可以针对字段的特点,建立前缀索引
索引的底层原理
抛开其他的数据库索引实现,主讲MySQL的索引底层实现,其底层是通过B+树来实现的数据结构存储。 数据结构存储,决定了数据查找和操作时的效率,包括时间复杂度和空间复杂度,而在取舍的时候,也无非就是时间换空间,空间换时间的权衡罢了,所以,这就很好的解释了,为什么MySQL在索引的底层设计上,选用了B+树,而没有选用B-树,或是红黑树,AVL树等等其他数据结构。总之,就是使用B+树作为索引的结构存储,能在I/O性能上得到一个较大的优势。
B-Tree
B-树是一种多路自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。 注:B-Tree就是我们常说的B树 那么m阶B-Tree是满足下列条件的数据结构: 所有键值分布在整棵树中 搜索有可能在非叶子节点结束,在关键字全集内做一次查找,性能逼近二分查找 每个节点最多拥有m个子树 根节点至少有2个子树 分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点) 所有叶子节点都在同一层,每个节点最多可以有m-1个key,并且以升序排列 但同时B-Tree也存在问题: 每个节点中有key,也有data,而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小。 当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率
B+Tree
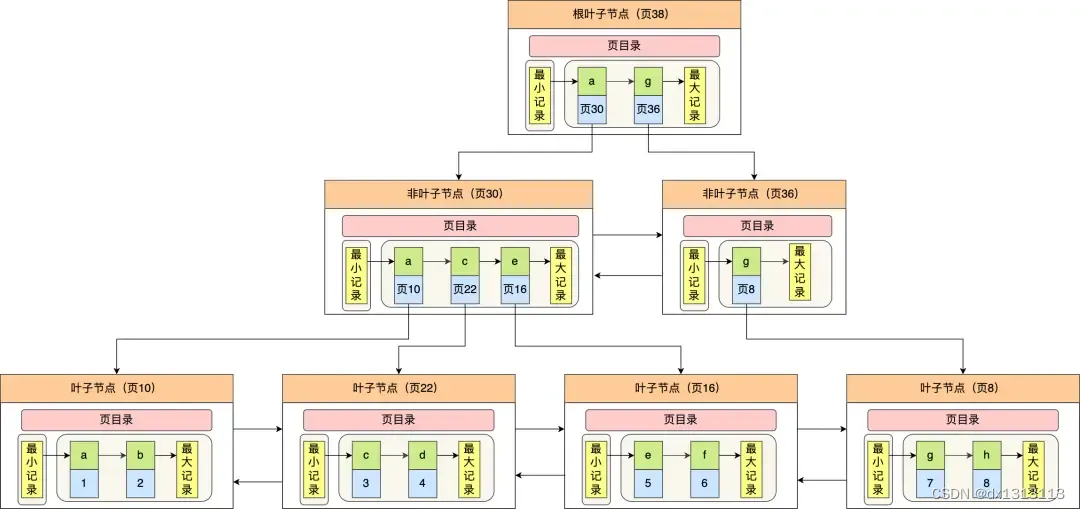
B+Tree是在B-Tree基础上的一种优化,InnoDB存储引擎就是用B+Tree实现其索引结构。它带来的变化点: B+树每个节点可以包含更多的节点,这样做有两个原因,一个是降低树的高度。另外一个是将数据范围变为多个区间,区间越多,数据检索越快 非叶子节点存储key,叶子节点存储key和数据 叶子节点两两指针相互链接(符合磁盘的预读特性),顺序查询性能更高
B+树的磁盘读写代价低,更少的查询次数,查询效率更加稳定,有利于对数据库的扫描
B+树是B树的升级版,B+树只有叶节点存放数据,其余节点用来索引。索引节点可以全部加入内存,增加查询效率,叶子节点可以做双向链表,从而提高范围查找的效率,增加索引的范围
在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树与B+树可以有多个子女,从几十到上千,可以降低树的高度。
注:MySQL的InnoDB存储引擎在设计时是将根节点常驻内存,因此力求达到树的深度不超过3,也就是说I/O不需要超过3次。 通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构,因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找的分页查找,另一种是从根节点开始,进行随机查找。
B-树和B+树的区别
B+树内节点不存储数据,所有数据存储在叶节点导致查询时间复杂度固定为log n
B-树查询时间复杂度不固定,与Key在树中的位置有关,最好为O(1)
B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等
B+树更适合外部存储(存储磁盘数据)。由于内节点无data域,每个节点能索引的范围更大更精确。
四种树
二叉树:索引字段有序,极端情况会变成链表形式
AVL数:树的高度不可控
B数:控制了树的高度,但是索引值和data都分布在每个具体的节点当中,若要进行范围查询,要进行多次回溯,IO开销大
B+树:非叶子节点只存储索引值,叶子节点再存储索引+具体数据,从小到大用链表连接在一起,范围查询可直接遍历不需要回溯7
B+树的优势
(1)IO代价更低。B+树由于非叶子节点中不存放data,因此可以存放更多的索引值(单个大节点的容量固定,每个小单位size变小了),从而使得树的高度更低,磁盘IO次数更少。
(2)查询效率稳定。B+树由于所有data都放在叶子节点中,因此每次查询都要走完整的根节点到叶子节点的路径,所有查询的路径长度相同,查询效率更加稳定。
(3)更利于范围查询。B+树叶子节点之间有指针,注意是双向的指针,更利于范围查询。
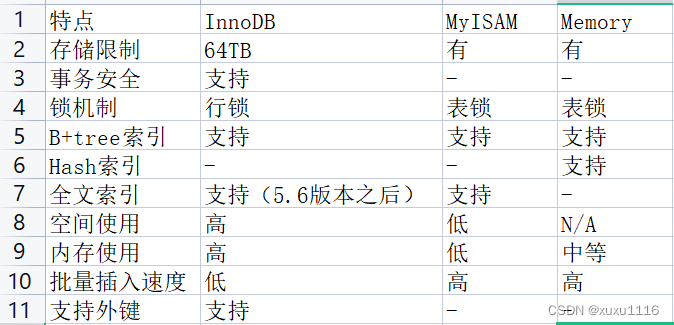
Innodb和Myisam引擎
Myisam: 支持表锁,适合读密集的场景,不支持外键,不支持事务,索引与数据在不同的文件
Innodb: 支持行、表锁,默认为行锁,适合并发场景,支持外键,支持事务,索引与数据同一文件
- InnoDB使用的都是聚簇索引
- Myisam使用的都是非聚簇索引
存储引擎的选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。(日志相关数据、电商中足迹、评论相关数据)
- MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。(通常用来做缓存)
InnoDB和MyISAM区别
-
InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
-
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。 -
InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件);
-
Innodb不支持全文索引,而MyISAM支持全文索引,在涉及全文索引领域的查询效率上MyISAM速度更快高;PS:5.7以后的InnoDB支持全文索引了
-
MyISAM表格可以被压缩后进行查询操作
-
InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。潜台词是,如果访问没有命中索引,也无法使用行锁,将要退化为表锁。 -
InnoDB表必须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列Row_id来充当默认主键),而Myisam可以没有
-
Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
InnoDB事务
一致性、持久性:(redo log)
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件((redo log file) ,前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
原子性: (undo log)
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和MVCC(多版本并发控制)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁: undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储: undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment回滚段中,内部包含1024个undo log segment。