(笔记总结自《黑马点评》项目)
一、产生原因
用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力。
常见的解决方式有缓存空对象和布隆过滤器。
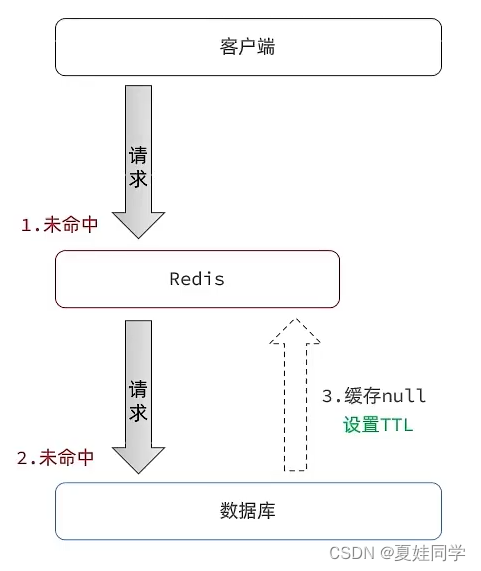
二、缓存空对象
思路:当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了。
优点:实现简单,维护方便
缺点:额外的内存消耗;可能造成短期的不一致
示例代码:
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
//从redis中查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
//判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
//存在,返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//判断命中的是否是空值(存在但是不是null,也就是空字符串)
if (shopJson != null) {
//返回一个错误信息
return Result.fail("店铺信息为空");
}
//不存在,根据id查询数据库
Shop shop = getById(id);
//不存在,返回错误
if(shop == null){
//将空值写入redis
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
//返回错误信息
return Result.fail("店铺不存在!");
}
//存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL , TimeUnit.MINUTES);
//返回
return Result.ok(shop);
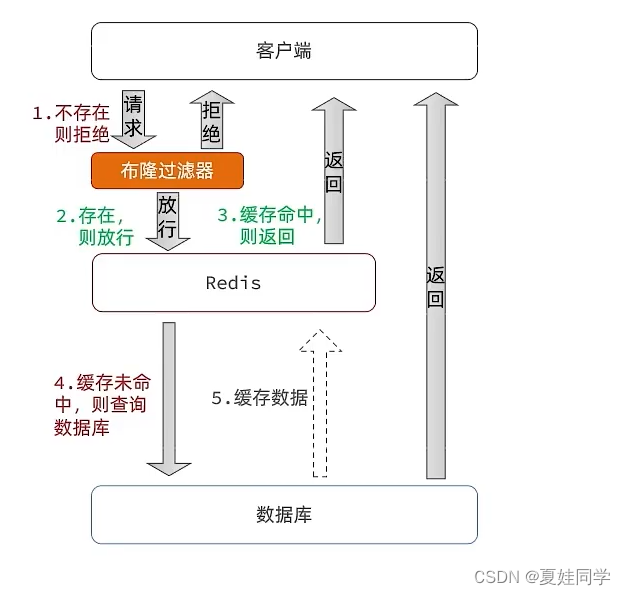
}三、布隆过滤器
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回。
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突。(判断不存在则一定不存在,判断存在有可能不存在)
四、其他方法
①增强id的复杂度,避免被猜测id规律。
②做好数据的基础格式校验。
③加强用户权限校验。
④做好热点参数的限流。