`torch.nn.LSTM`是PyTorch中用于创建长短时记忆网络(Long Short-Term Memory)的类。LSTM是一种用于处理序列数据的循环神经网络(Recurrent Neural Network,RNN)变体。
官方给出的LSTM API 文档
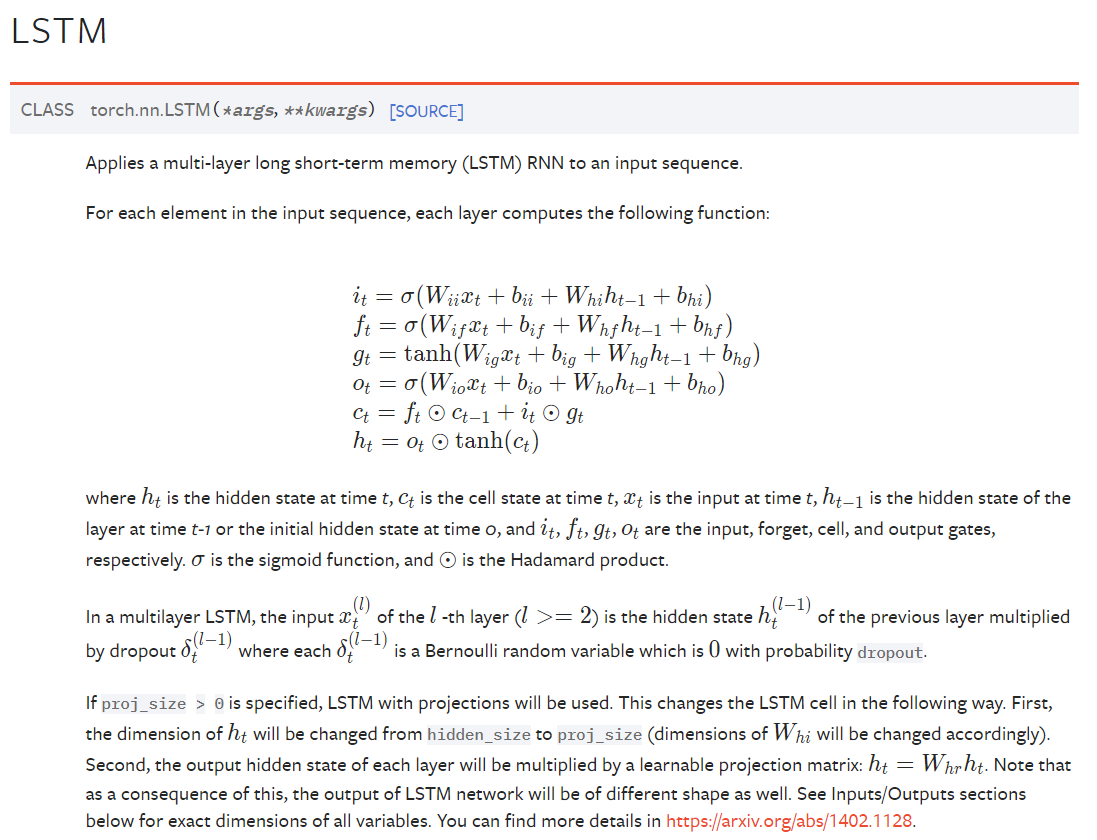
 以下是 `torch.nn.LSTM` 的主要参数(用于配置和定制 LSTM 层的行为):
以下是 `torch.nn.LSTM` 的主要参数(用于配置和定制 LSTM 层的行为):
1. `input_size`(必需参数):输入数据的特征维度大小。这是输入序列的特征向量的维度。
2. `hidden_size`(必需参数):LSTM 单元的隐藏状态的维度大小。这决定了 LSTM 层的输出和内部隐藏状态的维度。
3. `num_layers`(可选参数,默认为 1):LSTM 层的堆叠层数。你可以将多个 LSTM 层叠加在一起,以增加模型的容量和表示能力。
4. `bias`(可选参数,默认为 True):一个布尔值,确定是否在 LSTM 单元中包含偏置项。
5. `batch_first`(可选参数,默认为 False):一个布尔值,指定输入数据的形状。如果设置为 True,输入数据的形状应为 `(batch_size, sequence_length, input_size)`,否则为 `(sequence_length, batch_size, input_size)`。
6. `dropout`(可选参数,默认为 0.0):应用于除最后一层外的每个 LSTM 层的丢弃率。这有助于防止过拟合。
7. `bidirectional`(可选参数,默认为 False):一个布尔值,指定是否使用双向 LSTM。如果设置为 True,LSTM 将具有前向和后向的隐藏状态,以更好地捕捉序列的上下文信息。
8. `batch_first`(可选参数,默认为 False):一个布尔值,用于指定输入数据的形状。如果设置为 True,则输入数据应为 `(batch_size, sequence_length, input_size)`,否则为 `(sequence_length, batch_size, input_size)`。
9. `device`(可选参数):指定要在哪个设备上创建 LSTM 层,例如 CPU 或 GPU。
10. `dtype`(可选参数):指定数据类型,例如 `torch.float32` 或 `torch.float64`。
11. `return_sequences`(可选参数,默认为 False):一个布尔值,指定是否返回每个时间步的输出序列。如果设置为 True,则返回完整的输出序列;否则,只返回最后一个时间步的输出。
这些参数允许你根据具体的任务和模型架构来配置 LSTM 层。根据你的需求,你可以灵活地选择不同的参数值来构建不同的 LSTM 模型。
LSTM的输入

`torch.nn.LSTM` 层的输入通常是一个包含两个元素的元组 `(input, (h_0, c_0))`,调用方法为:
output, (h_n, c_n) = torch.nn.LSTM(input, (h_0,c_0))
其中:
(1)
input 通常是一个三维张量,具体形状取决于是否设置了 `batch_first` 参数。输入张量包括以下维度:
1. 批量维度(Batch Dimension):这是数据中的样本数量。如果 `batch_first` 设置为 True,那么批量维度将是第一个维度;否则,批量维度将是第二个维度。
2. 序列长度维度(Sequence Length Dimension):这是时间步的数量,也是序列的长度。它是输入序列中数据点的数量。
3. 特征维度(Feature Dimension):这是输入数据点的特征数量。它表示每个时间步的输入特征向量 xt 的维度。
根据上述描述,以下是两种常见的输入形状:
- 如果 `batch_first` 为 True:
- 输入张量的形状为 `(batch_size, sequence_length, input_size)`。
- `batch_size` 是批量大小,表示同时处理的样本数量。
- `sequence_length` 是序列的长度,即时间步的数量。
- `input_size` 是输入特征向量的维度。
- 如果 `batch_first` 为 False:
- 输入张量的形状为 `(sequence_length, batch_size, input_size)`。
- `sequence_length` 是序列的长度,即时间步的数量。
- `batch_size` 是批量大小,表示同时处理的样本数量。
- `input_size` 是输入特征向量的维度。
要注意的是,这只是输入的形状,LSTM 层的参数(例如 `input_size` 和 `hidden_size`)必须与输入形状相匹配。根据你的具体任务和数据,你需要将输入数据整理成适当形状的张量,然后将其传递给 `torch.nn.LSTM` 层以进行前向传播。
(2)
`(h_0, c_0)`:是包含初始隐藏状态和初始细胞状态的元组。
- `h_0`:是初始隐藏状态,其形状为 `(num_layers * num_directions, batch_size, hidden_size)`。`num_layers` 是 LSTM 层的堆叠层数,`num_directions` 是 1 或 2,取决于是否使用双向 LSTM。
- `c_0`:是初始细胞状态,其形状也为 `(num_layers * num_directions, batch_size, hidden_size)`。
LSTM的输出

`torch.nn.LSTM` 层的输出通常是一个包含两个元素的元组 `(output, (h_n, c_n))`,其中:
1. `output`:是一个包含每个时间步的 LSTM 输出的张量。其形状为 `(batch_size, sequence_length, num_directions * hidden_size)`【batch_first = True的情况下】,其中:
- `sequence_length` 是序列的长度,即时间步的数量。
- `batch_size` 是批量大小,表示同时处理的样本数量。
- `num_directions` 是 1 或 2,取决于是否使用双向(bidirectional)LSTM。
- `hidden_size` 是 LSTM 单元的隐藏状态的维度大小。
2. `(h_n, c_n)`:是包含最后一个时间步的隐藏状态和细胞状态的元组。
- `h_n`:是最后一个时间步的隐藏状态,其形状为 `(num_layers * num_directions, batch_size, hidden_size)`。`num_layers` 是 LSTM 层的堆叠层数,`num_directions` 是 1 或 2,取决于是否使用双向 LSTM。
- `c_n`:是最后一个时间步的细胞状态,其形状也为 `(num_layers * num_directions, batch_size, hidden_size)`。
你可以选择是否要使用输出中的全部时间步的输出,或者只使用最后一个时间步的输出,具体取决于你的任务需求。
通常,如果你只关心最终的输出,你可以使用 `output[-1]` 或 `h_n`。如果你需要完整的时间步输出序列,可以使用 `output`。这些输出可以传递到其他层或用于任务的后续处理。
LSTM的权重参数

`torch.nn.LSTM`具有以下主要的权重参数(用于捕捉序列中的长期依赖关系):
1. `weight_ih_l[k]`:这是输入到LSTM单元的权重参数,其中k表示LSTM层的索引。`weight_ih_l[k]`的维度是(4 * hidden_size,input_size),其中hidden_size是LSTM隐藏状态的大小,input_size是输入数据的特征维度。这个权重参数控制着输入数据如何影响LSTM单元的状态。
2. `weight_hh_l[k]`:这是隐藏状态到LSTM单元的权重参数,其中k表示LSTM层的索引。`weight_hh_l[k]`的维度是(4 * hidden_size,hidden_size)。这个权重参数控制着前一个时间步的隐藏状态如何影响当前时间步的隐藏状态。
3. `bias_ih_l[k]`和`bias_hh_l[k]`:这是输入到LSTM单元和隐藏状态到LSTM单元的偏置参数,其中k表示LSTM层的索引。`bias_ih_l[k]`的维度是(4 * hidden_size),`bias_hh_l[k]`的维度也是(4 * hidden_size)。这些偏置参数用于调整输入和隐藏状态的影响。
以上权重参数中的4表示LSTM单元的门控机制,通常被称为输入门(input gate)、遗忘门(forget gate)、输出门(output gate)和细胞状态(cell state)。LSTM使用这些门来控制信息的流动,以捕捉长期依赖关系。
要访问和修改这些权重参数,您可以使用`state_dict`属性来获取或设置模型的权重。例如,如果您有一个名为`lstm_model`的`torch.nn.LSTM`模型,您可以使用以下代码来获取权重参数的字典:lstm_weights = lstm_model.state_dict()。然后,您可以从`lstm_weights`字典中提取和修改特定的权重参数。请注意,修改权重参数可能会影响模型的性能,因此需要谨慎操作。
你还可以使用:
for k, v in lstm_model.named_parameters():
print(k, v) # 打印权重参数名称及数值
方法得到模型的权重参数。
代码部分
下述代码包括了官方API以及手写的LSTM源码。
# 视频链接:
# https://www.bilibili.com/video/BV1zq4y1m7aH/?spm_id_from=333.788&vd_source=fb7bfda367c76676e2483b9b60485e57
# 实现LSTM 源码
# 定义常量
import torch
import torch.nn as nn
batch_size, T, input_size, hidden_size = 2, 3, 4, 5
input = torch.randn(batch_size, T, input_size)
c_0 = torch.randn(batch_size, hidden_size) # 初始细胞单元,不参与网络训练
h_0 = torch.randn(batch_size, hidden_size) # 初始隐藏状态
# 调用官方API
lstm_layer = nn.LSTM(input_size=input_size, hidden_size=hidden_size, batch_first=True)
output, (h_n, c_n) = lstm_layer(input, (h_0.unsqueeze(0), c_0.unsqueeze(0)))
print("LSTM API")
print("output:\n", output)
print("h_n:\n", h_n)
print("c_n:\n", c_n)
# for k, v in lstm_layer.named_parameters():
# print(k, v)
lstm_weight = lstm_layer.state_dict() # 使用`state_dict`属性来获取或设置模型的权重
print("lstm_weight:\n", lstm_weight)
# 自己写一个LSTM模型
def lstm_forward(input, initial_states, w_ih, w_hh, b_ih, b_hh):
"""
:param input:
:param initial_states:
:param w_ih:
:param w_hh:
:param b_ih:
:param b_hh:
:return:
"""
h_0, c_0 = initial_states # 初始状态
batch_size, T, input_size = input.shape
hidden_size = w_ih.shape[0] // 4
prev_h = h_0
prev_c = c_0
batch_w_ih = w_ih.unsqueeze(0).tile(batch_size, 1, 1) # [batch_size, 4*hidden_size, input_size]
batch_w_hh = w_hh.unsqueeze(0).tile(batch_size, 1, 1) # [batch_size, 4*hidden_size, hidden_size]
output_size = hidden_size
output = torch.zeros(batch_size, T, output_size) # 输出序列
for t in range(T):
x = input[:, t, :] # 当前时刻的输入向量,[batch_size*input_size]
w_times_x = torch.bmm(batch_w_ih, x.unsqueeze(-1)) # [batch_size, 4*hidden_size, 1]
w_times_x = w_times_x.squeeze(-1) # [batch_size, 4*hidden_size]
w_times_h_prev = torch.bmm(batch_w_hh, prev_h.unsqueeze(-1)) # [batch_size, 4*hidden_size, 1]
w_times_h_prev = w_times_h_prev.squeeze(-1) # [batch_size, 4*hidden_size]
# 分别计算输入门(i)、遗忘门(f)、cell(g)、输出门(o)
i_t = torch.sigmoid(w_times_x[:, :hidden_size] + w_times_h_prev[:, :hidden_size]
+b_ih[ :hidden_size] + b_hh[ :hidden_size])
f_t = torch.sigmoid(w_times_x[:, hidden_size:2*hidden_size] + w_times_h_prev[:, hidden_size:2*hidden_size]
+ b_ih[hidden_size:2*hidden_size] + b_hh[hidden_size:2*hidden_size])
g_t = torch.tanh(w_times_x[:, 2*hidden_size:3*hidden_size] + w_times_h_prev[:, 2*hidden_size:3*hidden_size]
+ b_ih[2*hidden_size:3*hidden_size] + b_hh[2*hidden_size:3*hidden_size])
o_t = torch.sigmoid(w_times_x[:, 3*hidden_size:4*hidden_size] + w_times_h_prev[:, 3*hidden_size:4*hidden_size]
+ b_ih[3*hidden_size:4*hidden_size] + b_hh[3*hidden_size:4*hidden_size])
prev_c = f_t * prev_c + i_t * g_t
prev_h = o_t * torch.tanh(prev_c)
output[:, t, :] = prev_h
return output, (prev_h, prev_c)
output_custom, (h_final_custom, c_final_custom) = lstm_forward(input=input, initial_states = (h_0, c_0), w_ih=lstm_layer.weight_ih_l0,
w_hh=lstm_layer.weight_hh_l0, b_ih=lstm_layer.bias_ih_l0, b_hh=lstm_layer.bias_hh_l0)
print("LSTM custom")
print("output_custom:\n", output_custom)
print("h_final_custom:\n", h_final_custom)
print("c_final_custom:\n", c_final_custom)LSTM模型输入输出可视化理解

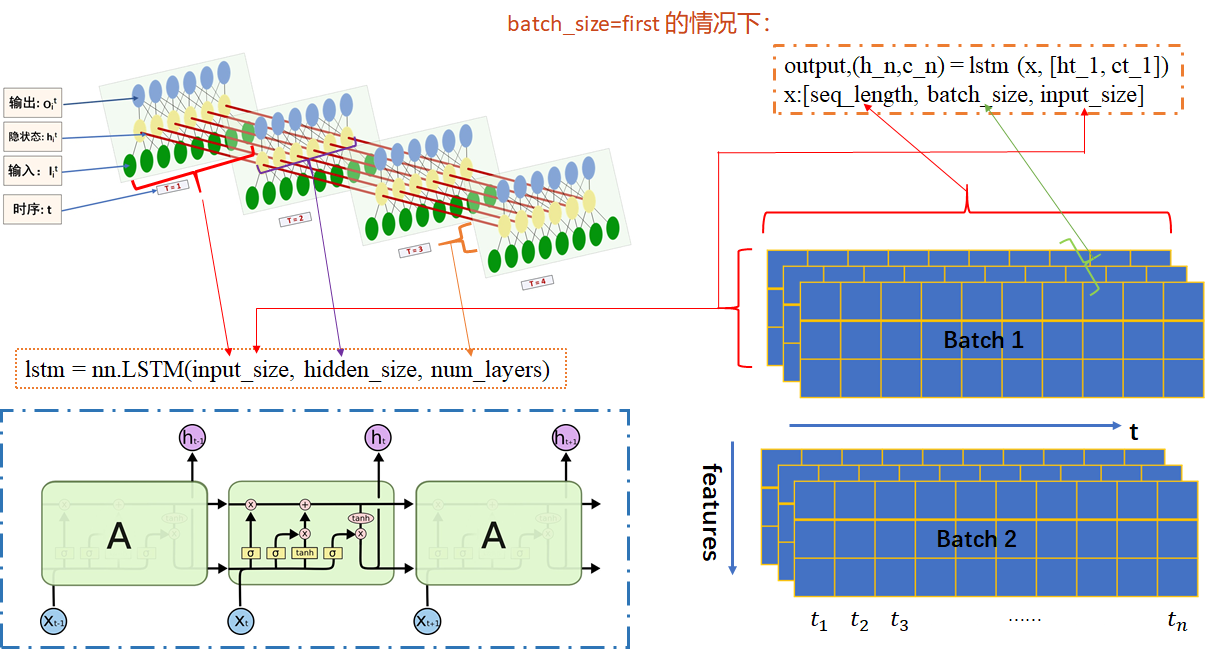
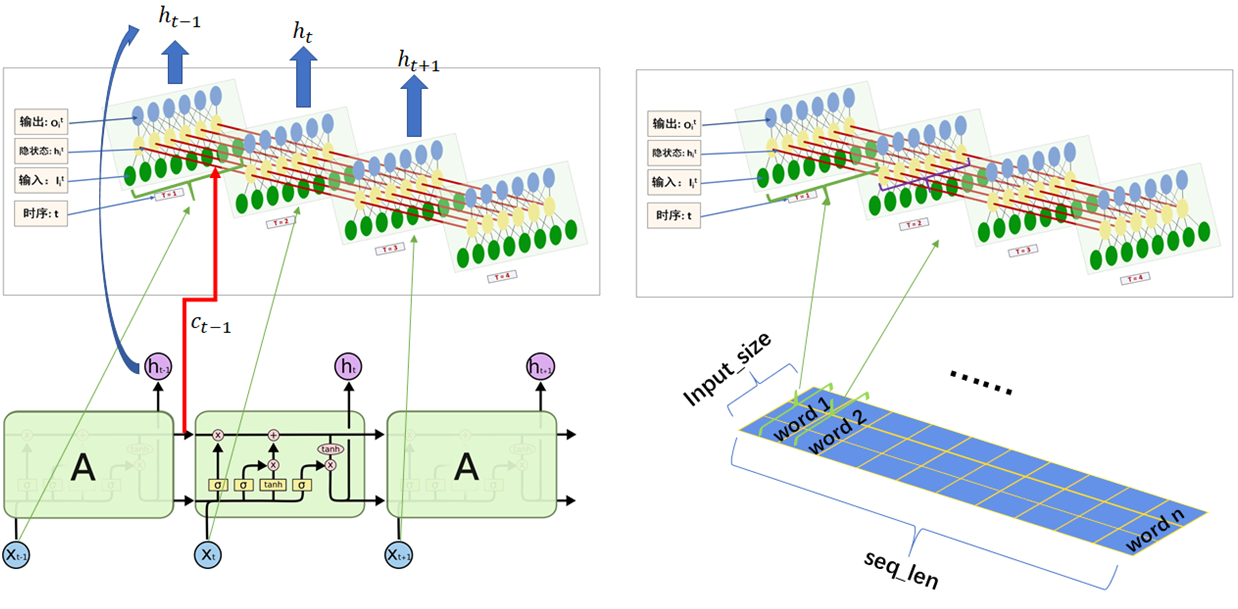
图文来自:pytorch中LSTM参数详解(一张图帮你更好的理解每一个参数)_pytorch lstm 参数一图_xjtuwfj的博客-CSDN博客