💡💡💡本文独家改进:提供各种卷积变体DCNV3、DCNV2、ODConv、SCConv、PConv、DynamicSnakeConvolution、DAT,引入CVPR2023、ICCV2023等改进方案,为Yolov8创新保驾护航,提供各种科研对比实验

💡💡💡Yolov8魔术师,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络
💡💡💡重点:通过本专栏的阅读,后续你也可以自己魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
专栏介绍:
https://blog.csdn.net/m0_63774211/category_12289773.html
✨✨✨原创魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉持续更新中,定期更新不同数据集涨点情况
目录
1. 动态蛇形卷积(Dynamic Snake Convolution) ICCV2023
2. DCNV3 CPVR2023
3. DCNV2 CVPR 2022
4. Partial Convolution CPVR2023
5. Deformable Attention Transformer CVPR 2022
6. SCConv CPVR2023
7. ODCONV ICLR2022
1.动态蛇形卷积(Dynamic Snake Convolution)

论文: 2307.08388.pdf (arxiv.org)
摘要:血管、道路等拓扑管状结构的精确分割在各个领域都至关重要,确保下游任务的准确性和效率。 然而,许多因素使任务变得复杂,包括薄的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊性,并利用这些知识来指导我们的 DSCNet 在三个阶段同时增强感知:特征提取、特征融合、 和损失约束。 首先,我们提出了一种动态蛇卷积,通过自适应地关注细长和曲折的局部结构来准确捕获管状结构的特征。 随后,我们提出了一种多视图特征融合策略,以补充特征融合过程中多角度对特征的关注,确保保留来自不同全局形态的重要信息。 最后,提出了一种基于持久同源性的连续性约束损失函数,以更好地约束分割的拓扑连续性。 2D 和 3D 数据集上的实验表明,与多种方法相比,我们的 DSCNet 在管状结构分割任务上提供了更好的准确性和连续性。
主要的挑战源于细长微弱的局部结构特征与复杂多变的全局形态特征。本文关注到管状结构细长连续的特点,并利用这一信息在神经网络以下三个阶段同时增强感知:特征提取、特征融合和损失约束。分别设计了动态蛇形卷积(Dynamic Snake Convolution),多视角特征融合策略与连续性拓扑约束损失。


首发Yolov8涨点神器:动态蛇形卷积(Dynamic Snake Convolution),实现暴力涨点 | ICCV2023_AI小怪兽的博客-CSDN博客
2. DCNV3

论文:https://arxiv.org/abs/2211.05778
代码:GitHub - OpenGVLab/InternImage: [CVPR 2023 Highlight] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions

研究者基于DCNv2算子,重新设计调整并提出DCNv3算子,具体改进包括以下几个部分。
(1) 共享投射权重。与常规卷积类似,DCNv2中的不同采样点具有独立的投射权重,因此其参数大小与采样点总数呈线性关系。为了降低参数和内存复杂度,借鉴可分离卷积的思路,采用与位置无关的权重代替分组权重,在不同采样点之间共享投影权重,所有的采样位置依赖性都得以保留。
(2) 引入多组机制。多组设计最早是在分组卷积中引入,并在Transformer的多头自注意力中广泛使用,它可以与自适应空间聚合配合,有效地提高特征的多样性。受此启发,研究者将空间聚合过程分成若干组,每个组都有独立的采样偏移量。自此,单个DCNv3层的不同组拥有不同的空间聚合模式,从而产生丰富的特征多样性。
(3) 采样点调制标量归一化。为了缓解模型容量扩大时的不稳定问题,研究者将归一化模式设定为逐采样点的Softmax归一化,这不仅使大规模模型的训练过程更加稳定,而且还构建了所有采样点的连接关系。

涨点神器:Yolov8引入CVPR2023 InternImage:注入新机制,扩展DCNv3,助力涨点,COCO新纪录65.4mAP!_AI小怪兽的博客-CSDN博客
3.DCNV2
论文:https://arxiv.org/abs/2008.13535
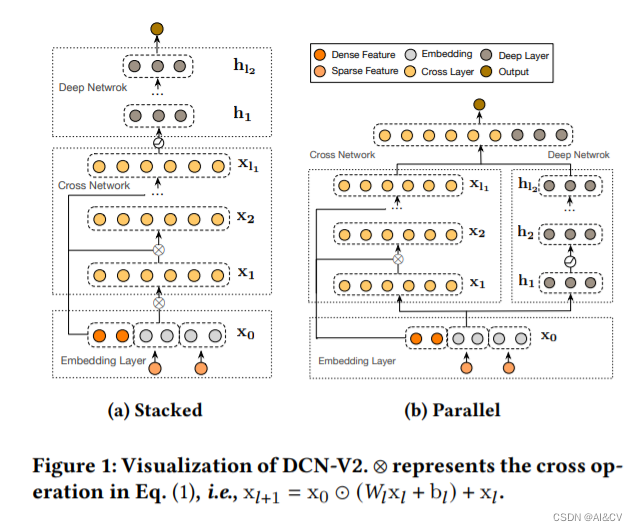
作者通过在DCN的基础上,增加了2个创新点,分别是调制模块和使用多个调制后的DCN模块,从形成了DCN的升级版本——DCN-v2!
①调制模块:
除了学习偏移参数Δ p \Delta pΔp(offset)之外,还要通过调制学习一个变化幅度Δ m \Delta mΔm。通过这个幅度来进一步合理控制新采样点的偏移范围。经过调制后的单个DCN我们记为mDCN(modulated-DCN)。
②多个调制DCN的堆积:
通过堆积多个调制mDCN来增加offset的偏移范围,同时显然多个块的堆积对偏移的精确性也是有一定校正细化的作用的,即进一步增强其对抗空间变化的能力(coarse-to-fine)。
涨点技巧:卷积变体DCNV2引入Yolov8,助力小目标涨点_AI小怪兽的博客-CSDN博客
4. Partial Convolution
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。

涨点神器:Yolov8改进CVPR2023 FasterNet远超ShuffleNet、MobileNet、MobileViT,引入PConv结构map涨点的同时进一步降低参数量_AI小怪兽的博客-CSDN博客
5.Deformable Attention Transformer

CVPR 2022 视觉领域顶级学术会议上,该项工作进入了 Best Paper 奖项的候选角逐。
本文提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。研究者们让所有 query 都跟同一组 key 和 value 交互,通过对每个输⼊图像学习⼀组偏移量,移动 key 和 value 到重要的位置。这种设计不仅增强了 sparse attention 的表征能⼒,同时具有线性空间复杂度。
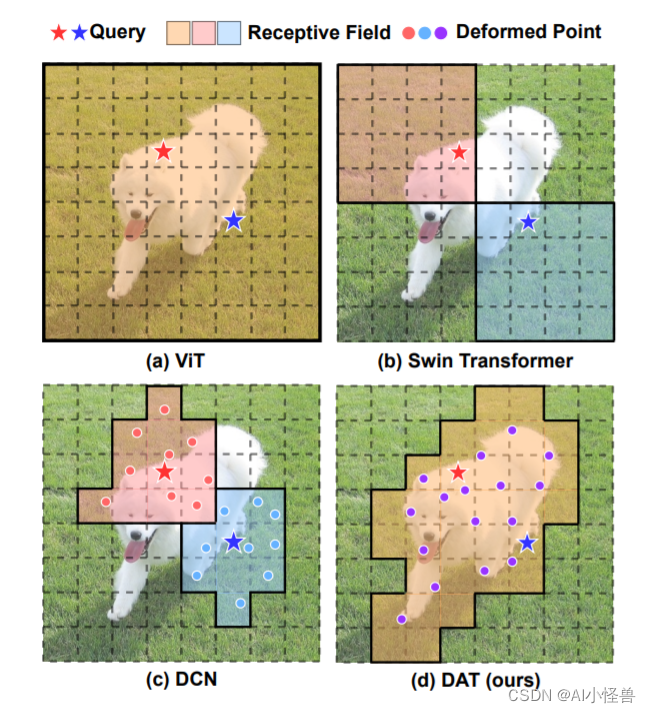
YoloV8改进:原创独家首发 | 可变形自注意力Attention,暴力涨点 | 即插即用系列_AI小怪兽的博客-CSDN博客
6. SCConv
论文:https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
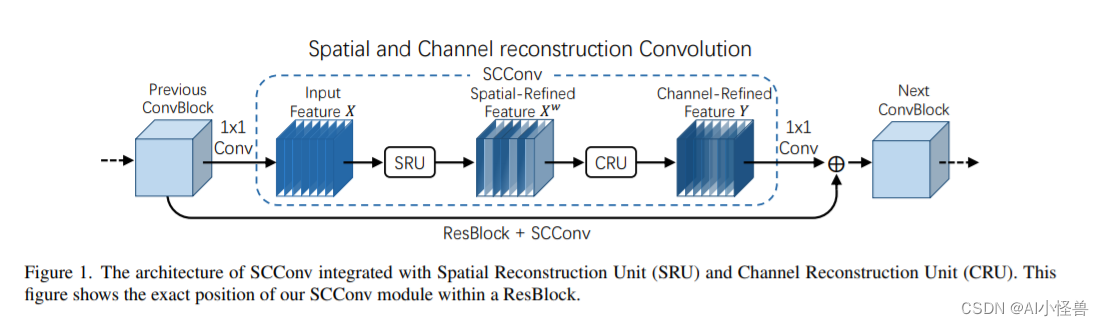
卷积神经网络(CNN)已经实现在各种计算机视觉任务中表现出色,但这是以巨大的计算成本为代价的资源,部分原因是卷积层提取冗余特征。 在本文中,我们尝试利用特征之间的空间和通道冗余,针对 CNN 压缩,提出了一种高效的卷积模块,称为 SCConv(空间和通道重建卷积),以减少冗余计算,并促进代表性特征学习。 提出的 SCConv 由两个单元组成:空间重建单元(SRU)和通道重建单元(CRU)。 SRU利用分离重建方法来抑制空间冗余,而CRU使用分割-变换-融合策略来减少通道冗余。 此外,SCConv 是一个即插即用的架构单元,可以可以直接用来替代各种卷积神经网络中的标准卷积。 实验结果表明SCConv 嵌入式模型能够实现更好的效果
通过减少冗余特征来显着降低复杂性和计算成本来提高性能。
SCConv 的结构包括了空间重建单元(SRU)和通道重建单元(CRU)。 下图显示了我们的 SCConv 模块添加在 ResBlock 中的确切位置 。
Yolov8引入CVPR2023 SCConv:空间和通道重建卷积,即插即用,助力检测_AI小怪兽的博客-CSDN博客
7. ODCONV

普通的卷积神经网络的卷积核是静态的,最近的动态卷积表明对卷积核权重的线性组合实现conv对输入数据的注意力加权,可以显著提升轻量级cnn的准确性,同时保持高速的推理。ODCONV认为现有的动态卷积(CondConv和DyConv)仅关注到conv-kernel数量的动态性,而忽略了spatial,input-channel,output-chanel的动态性。基于此,使用SE注意力实现全维度动态卷积(channel、filer、spatial、kernel)。ODConv可以插入到现行的许多CNN网络中。ODConv为各种流行的CNN骨干带来了坚实的精度提高,包括轻量级的和大型的骨干,例如,在ImageNet数据集上对MobivleNetV2|ResNet家族的3.77%∼5.71%|1.86%∼3.72%绝对前改进。由于其改进的特性学习能力,即使是一个内核的ODConv也可以与现有的动态卷积对应的多内核竞争或超越,大大减少了额外的参数。此外,ODConv在调制输出特征或卷积权值方面也优于其他注意模块。
即插即用的动态卷积ODConv 论文:Omni-Dimensional Dynamic Convolution
论文地址:Omni-Dimensional Dynamic Convolution | OpenReview
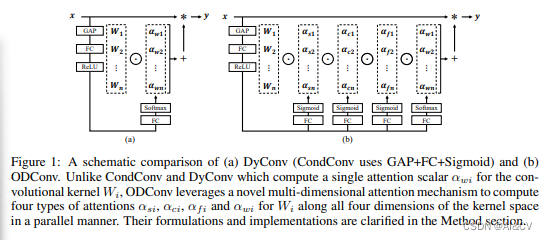
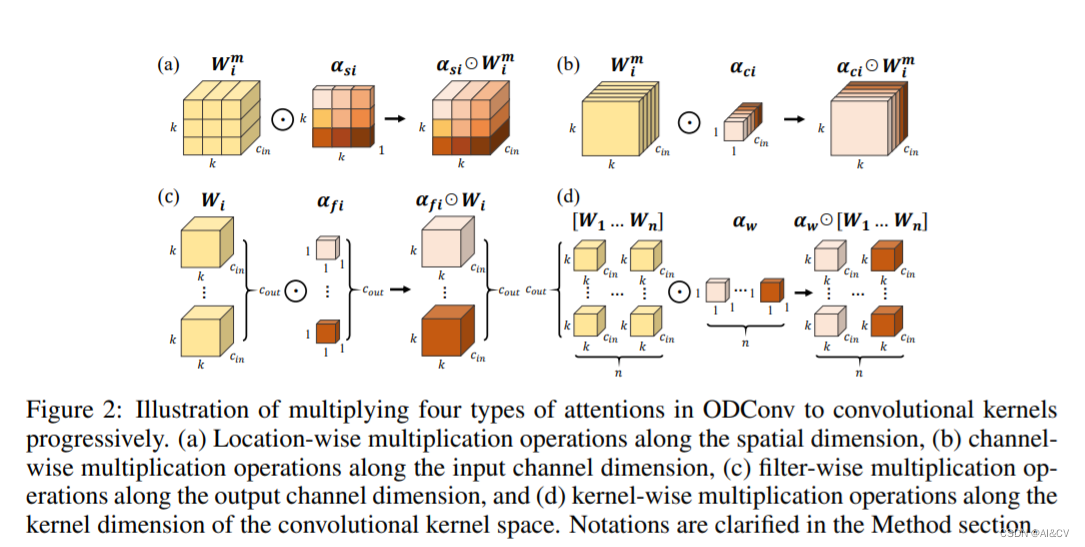
ODConv通过并行策略引入一种多维注意力机制以对卷积核空间的四个维度学习更灵活的注意力。ODConv可以描述成如下形式:其中,表示卷积核的注意力标量
表示新引入的三个注意力,分别沿空域维度、输入通道维度以及输出通道维度。这四个注意力采用多头注意力模块 计算得到
Yolov8涨点神器:ODConv+ConvNeXt提升小目标检测能力_AI小怪兽的博客-CSDN博客