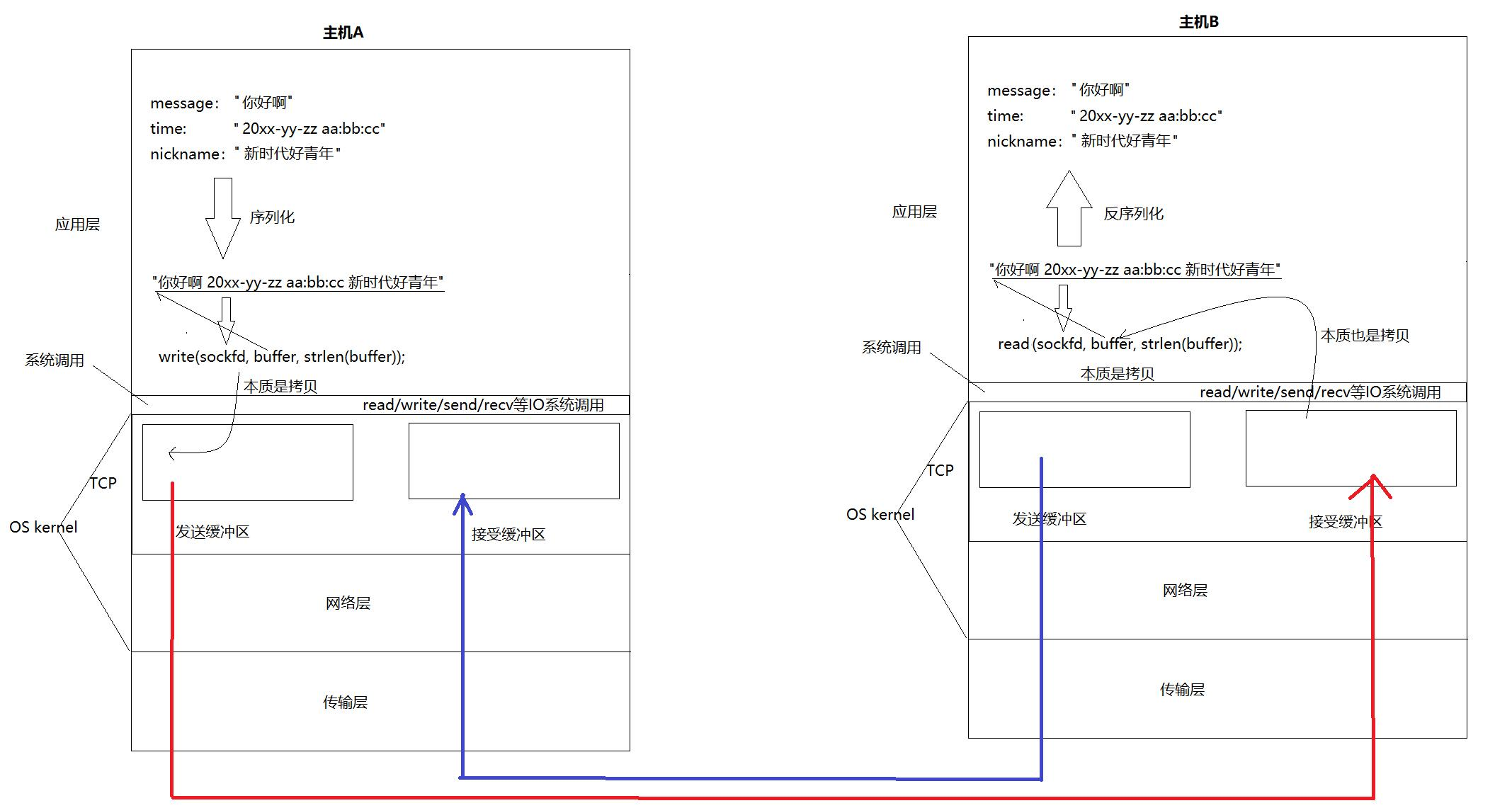
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网页内容。
一、XPath简介
XPath (XML Path Language) 最初是为了在XML文档中进行导航而设计的语言,后来被广泛应用于HTML文档的解析。与BeautifulSoup相比,XPath有以下特点:
- 语法强大:可以通过简洁的表达式精确定位元素
- 高效性能:通常比BeautifulSoup更快,特别是在处理大型文档时
- 跨平台通用:几乎所有编程语言都有XPath的实现
- 灵活性高:可以通过各种轴、谓词和函数构建复杂的选择条件
在Python中,我们主要通过lxml库来使用XPath功能。
二、安装lxml
首先,我们需要安装lxml库:
pip install lxml
安装成功后,将显示类似以下输出:
Collecting lxml
Downloading lxml-4.9.3-cp310-cp310-win_amd64.whl (3.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 8.2 MB/s eta 0:00:00
Installing collected packages: lxml
Successfully installed lxml-4.9.3
lxml是一个基于C语言的库,性能非常高,同时支持XPath 1.0标准。
三、XPath基础语法
XPath使用路径表达式来选择XML/HTML文档中的节点或节点集。这些表达式非常类似于文件系统中的路径。
1. 基本路径表达式
/html/body/div # 从根节点选择html下的body下的所有div元素
//div # 选择文档中所有的div元素,不管它们在哪个位置
/html/body/div[1] # 选择body下的第一个div元素
//div[@class='content'] # 选择带有class='content'属性的所有div元素
2. 常用路径操作符
| 操作符 | 描述 | 示例 |
|---|---|---|
/ | 从根节点选取或选取子元素 | /html/body |
// | 从当前节点选择文档中符合条件的所有元素 | //a |
. | 选取当前节点 | ./div |
.. | 选取当前节点的父节点 | ../ |
@ | 选取属性 | //div[@id] |
* | 通配符,选择任意元素 | //* |
3. 条件谓词
XPath允许我们使用方括号[]来添加条件谓词:
//div[1] # 第一个div元素
//div[last()] # 最后一个div元素
//div[position()<3] # 前两个div元素
//div[@class] # 所有有class属性的div元素
//div[@class='main'] # class属性值为'main'的div元素
//div[contains(@class, 'content')] # class属性包含'content'的div元素
//a[text()='点击这里'] # 文本内容为'点击这里'的a元素
//div[count(p)>2] # 包含超过2个p元素的div元素
4. XPath轴
XPath轴用于定义相对于当前节点的节点集:
//div/ancestor::* # div的所有祖先节点
//div/child::p # div的所有p子节点
//div/descendant::span # div的所有span后代节点
//div/following::p # div后面的所有p节点
//div/preceding::p # div前面的所有p节点
//div/following-sibling::div # div之后的所有同级div节点
四、在Python中使用XPath
Python的lxml库提供了强大的XPath支持。以下是基本用法:
from lxml import etree
import requests
# 获取HTML内容
url = "https://www.example.com"
response = requests.get(url)
html_text = response.text
# 解析HTML
html = etree.HTML(html_text)
# 或者从文件加载HTML
# html = etree.parse('example.html', etree.HTMLParser())
# 使用XPath提取数据
title = html.xpath('//title/text()') # 获取标题文本
links = html.xpath('//a/@href') # 获取所有链接的href属性
paragraphs = html.xpath('//p/text()') # 获取所有段落的文本
print(f"标题: {title[0] if title else '无标题'}")
print(f"找到 {len(links)} 个链接")
print(f"找到 {len(paragraphs)} 个段落")
输出结果:
标题: Example Domain
找到 1 个链接
找到 2 个段落
1. 提取文本内容
# 使用一个简单的HTML字符串示例
html_str = """
<html>
<head>
<title>XPath示例页面</title>
</head>
<body>
<h1>欢迎学习XPath</h1>
<p>这是第一个段落。</p>
<p>这是第二个<b>段落</b>,包含<a href="https://example.com">链接</a>。</p>
<div class="content">
<p>这是内容区的段落。</p>
</div>
</body>
</html>
"""
html = etree.HTML(html_str)
# 提取标题文本
title_text = html.xpath('//title/text()')[0]
print(f"标题: {title_text}")
# 提取所有段落文本
p_texts = html.xpath('//p/text()')
print(f"所有段落文本: {p_texts}")
# 提取包含某些内容的标签文本
specific_texts = html.xpath('//div[contains(@class, "content")]/p/text()')
print(f"特定div内的文本: {specific_texts}")
# 提取标签及其子元素的全部文本
complex_p = html.xpath('//p[2]')[0] # 选取第二个段落
full_text = ''.join(complex_p.xpath('.//text()'))
print(f"完整的段落文本: {full_text}")
输出结果:
标题: XPath示例页面
所有段落文本: ['这是第一个段落。', '这是第二个', ',包含', '。', '这是内容区的段落。']
特定div内的文本: ['这是内容区的段落。']
完整的段落文本: 这是第二个段落,包含链接。
注意:text()函数只提取直接子文本节点的内容,不包括子元素中的文本。要获取包含子元素的全部文本,需要使用.//text()并连接结果。
2. 提取属性值
html_str = """
<html>
<body>
<a href="https://example.com" class="external" target="_blank">示例链接</a>
<img src="/images/logo.png" alt="网站Logo" width="100">
<div id="main" class="container content">主要内容</div>
<a href="https://example.org" class="link" target="_blank">另一个链接</a>
</body>
</html>
"""
html = etree.HTML(html_str)
# 提取所有链接的URL
urls = html.xpath('//a/@href')
print(f"所有链接URL: {urls}")
# 提取所有图片的地址
img_srcs = html.xpath('//img/@src')
print(f"所有图片地址: {img_srcs}")
# 提取特定元素的属性
classes = html.xpath('//div[@id="main"]/@class')
print(f"main div的class属性: {classes}")
# 提取同时满足多个条件的元素的属性
selected_attrs = html.xpath('//a[@class="link" and @target="_blank"]/@href')
print(f"符合条件的链接: {selected_attrs}")
输出结果:
所有链接URL: ['https://example.com', 'https://example.org']
所有图片地址: ['/images/logo.png']
main div的class属性: ['container content']
符合条件的链接: ['https://example.org']
3. 处理多个元素
html_str = """
<html>
<body>
<div id="nav">
<a href="/home">首页</a>
<a href="/about">关于</a>
<a href="/contact">联系我们</a>
</div>
<table>
<tr><th>姓名</th><th>年龄</th></tr>
<tr><td>张三</td><td>25</td></tr>
<tr><td>李四</td><td>30</td></tr>
</table>
</body>
</html>
"""
html = etree.HTML(html_str)
# 遍历处理所有链接
links = html.xpath('//a')
print("所有链接信息:")
for link in links:
url = link.xpath('./@href')[0] if link.xpath('./@href') else ''
text = ''.join(link.xpath('.//text()')).strip()
print(f" 链接文本: {text}, URL: {url}")
# 提取表格数据
rows = html.xpath('//table/tr')
table_data = []
print("\n表格数据:")
for row in rows:
cols = row.xpath('./td/text() | ./th/text()')
print(f" 行数据: {cols}")
table_data.append(cols)
输出结果:
所有链接信息:
链接文本: 首页, URL: /home
链接文本: 关于, URL: /about
链接文本: 联系我们, URL: /contact
表格数据:
行数据: ['姓名', '年龄']
行数据: ['张三', '25']
行数据: ['李四', '30']
五、实际案例:解析百度热搜榜
让我们使用XPath来解析百度热搜榜,类似于我们之前使用BeautifulSoup所做的:
from lxml import etree
import logging
import requests
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
def parse_baidu_hot_search_xpath(html_file=None):
"""使用XPath解析百度热搜榜HTML"""
try:
if html_file:
# 从文件读取HTML
with open(html_file, "r", encoding="utf-8") as f:
html_content = f.read()
else:
# 实时获取百度热搜
url = "https://top.baidu.com/board?tab=realtime"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
html_content = response.text
# 保存到文件以备后用
with open("baidu_hot_search_new.html", "w", encoding="utf-8") as f:
f.write(html_content)
logging.info("开始使用XPath解析百度热搜榜HTML...")
# 创建HTML解析对象
html = etree.HTML(html_content)
# 使用XPath找到热搜项元素
# 注意:以下XPath表达式基于当前百度热搜页面的结构,如果页面结构变化,可能需要更新
hot_items = html.xpath('//div[contains(@class, "category-wrap_iQLoo")]')
if not hot_items:
logging.warning("未找到热搜项,可能页面结构已变化,请检查HTML内容和XPath表达式")
return []
logging.info(f"找到 {len(hot_items)} 个热搜项")
# 提取每个热搜项的数据
hot_search_list = []
for index, item in enumerate(hot_items, 1):
try:
# 提取标题
title_elements = item.xpath('.//div[contains(@class, "c-single-text-ellipsis")]/text()')
title = title_elements[0].strip() if title_elements else "未知标题"
# 提取热度(如果有)
hot_elements = item.xpath('.//div[contains(@class, "hot-index_1Bl1a")]/text()')
hot_value = hot_elements[0].strip() if hot_elements else "未知热度"
# 提取排名
rank = index
hot_search_list.append({
"rank": rank,
"title": title,
"hot_value": hot_value
})
except Exception as e:
logging.error(f"解析第 {index} 个热搜项时出错: {e}")
logging.info(f"成功解析 {len(hot_search_list)} 个热搜项")
return hot_search_list
except Exception as e:
logging.error(f"解析百度热搜榜时出错: {e}")
return []
def display_hot_search(hot_list):
"""展示热搜榜数据"""
if not hot_list:
print("没有获取到热搜数据")
return
print("\n===== 百度热搜榜 (XPath解析) =====")
print("排名\t热度\t\t标题")
print("-" * 50)
for item in hot_list:
print(f"{item['rank']}\t{item['hot_value']}\t{item['title']}")
if __name__ == "__main__":
# 尝试从之前保存的文件加载,如果没有则直接获取
try:
hot_search_list = parse_baidu_hot_search_xpath("baidu_hot_search.html")
except FileNotFoundError:
hot_search_list = parse_baidu_hot_search_xpath()
display_hot_search(hot_search_list)
输出结果(实际结果可能会因时间而不同):
2025-04-20 10:15:32,654 - INFO: 开始使用XPath解析百度热搜榜HTML...
2025-04-20 10:15:32,789 - INFO: 找到 30 个热搜项
2025-04-20 10:15:32,846 - INFO: 成功解析 30 个热搜项
===== 百度热搜榜 (XPath解析) =====
排名 热度 标题
--------------------------------------------------
1 4522302 世界首个"人造子宫"获批临床试验
2 4325640 暑假别只顾玩 这些安全知识要牢记
3 4211587 李嘉诚家族被曝已移居英国
... ... ...
六、XPath高级用法
1. 逻辑运算符
XPath支持多种逻辑运算符来组合条件:
html_str = """
<html>
<body>
<div class="main" id="content">主内容</div>
<div class="main">次要内容</div>
<div class="sidebar">侧边栏内容</div>
<div class="hidden">隐藏内容</div>
</body>
</html>
"""
html = etree.HTML(html_str)
# 使用and: 同时满足多个条件
elements = html.xpath('//div[@class="main" and @id="content"]')
print(f"同时满足class='main'和id='content'的元素数量: {len(elements)}")
print(f"内容: {elements[0].xpath('string(.)')}")
# 使用or: 满足任一条件
elements = html.xpath('//div[@class="main" or @class="sidebar"]')
print(f"class为'main'或'sidebar'的元素数量: {len(elements)}")
# 使用not: 否定条件
elements = html.xpath('//div[not(@class="hidden")]')
print(f"class不为'hidden'的div元素数量: {len(elements)}")
输出结果:
同时满足class='main'和id='content'的元素数量: 1
内容: 主内容
class为'main'或'sidebar'的元素数量: 3
class不为'hidden'的div元素数量: 3
2. 字符串函数
XPath提供了多种处理字符串的函数:
html_str = """
<html>
<body>
<div class="content-main">内容1</div>
<div class="sidebar-content">内容2</div>
<div id="section-1">第一节</div>
<div id="section-2">第二节</div>
<p>这是一个短句。</p>
<p>这是一个非常长的段落,包含了很多文字内容,用于测试string-length函数。</p>
</body>
</html>
"""
html = etree.HTML(html_str)
# contains: 检查是否包含子字符串
elements = html.xpath('//div[contains(@class, "content")]')
print(f"class属性包含'content'的div元素: {[e.xpath('string(.)') for e in elements]}")
# starts-with: 检查是否以某字符串开头
elements = html.xpath('//div[starts-with(@id, "section")]')
print(f"id属性以'section'开头的div元素: {[e.xpath('string(.)') for e in elements]}")
# string-length: 检查字符串长度
short_p = html.xpath('//p[string-length(text()) < 10]')
long_p = html.xpath('//p[string-length(text()) > 10]')
print(f"文本长度小于10的p元素数量: {len(short_p)}")
print(f"文本长度大于10的p元素数量: {len(long_p)}")
输出结果:
class属性包含'content'的div元素: ['内容1', '内容2']
id属性以'section'开头的div元素: ['第一节', '第二节']
文本长度小于10的p元素数量: 1
文本长度大于10的p元素数量: 1
3. 位置函数
XPath提供了多种与元素位置相关的函数:
html_str = """
<html>
<body>
<div>第一个div</div>
<div>第二个div</div>
<div>第三个div</div>
<div>第四个div</div>
<div>第五个div</div>
</body>
</html>
"""
html = etree.HTML(html_str)
# position(): 获取当前位置
first_element = html.xpath('//div[position()=1]')
print(f"第一个div的内容: {first_element[0].xpath('string(.)')}")
# last(): 获取最后位置
last_element = html.xpath('//div[position()=last()]')
print(f"最后一个div的内容: {last_element[0].xpath('string(.)')}")
# 选择范围
range_elements = html.xpath('//div[position()>1 and position()<5]')
print(f"第2到第4个div: {[e.xpath('string(.)') for e in range_elements]}")
输出结果:
第一个div的内容: 第一个div
最后一个div的内容: 第五个div
第2到第4个div: ['第二个div', '第三个div', '第四个div']
4. 组合多个XPath
在Python中,我们可以组合多个XPath表达式来提取不同类型的元素:
html_str = """
<html>
<body>
<h1>主标题</h1>
<h2>副标题1</h2>
<p>段落1</p>
<h2>副标题2</h2>
<p>段落2</p>
<h3>小标题</h3>
<p>段落3</p>
</body>
</html>
"""
html = etree.HTML(html_str)
# 使用|操作符组合XPath
elements = html.xpath('//h1 | //h2 | //h3')
print(f"所有标题元素: {[e.xpath('string(.)') for e in elements]}")
# 分别提取然后合并结果
titles = html.xpath('//h1/text()') + html.xpath('//h2/text()')
print(f"主标题和副标题: {titles}")
输出结果:
所有标题元素: ['主标题', '副标题1', '副标题2', '小标题']
主标题和副标题: ['主标题', '副标题1', '副标题2']
七、如何构建正确的XPath表达式?
在实际爬虫开发中,构建正确的XPath表达式是一项关键技能。以下是一些实用技巧:
1. 使用浏览器开发者工具
现代浏览器的开发者工具通常提供XPath支持:
- 在Chrome或Firefox中右键点击元素,选择"检查"
- 在元素面板中右键点击HTML代码,选择"Copy" > “Copy XPath”
- 获取浏览器生成的XPath表达式(注意:浏览器生成的XPath通常很长且不够通用,可能需要手动优化)
例如,对于百度首页的搜索框,Chrome可能生成这样的XPath:
//*[@id="kw"]
2. 手动优化XPath表达式
浏览器生成的XPath通常不够理想,我们需要手动优化:
- 找到元素的独特标识(如id、特定的class等)
- 尽量使用相对路径而非绝对路径
- 使用
contains()等函数处理动态变化的属性值
例如,浏览器可能生成:
/html/body/div[3]/div[2]/div[1]/div[4]/div[1]/div/div[2]/div[3]/div/div/div[1]/div
优化后可能变为:
//div[@id='main-content']//div[contains(@class, 'item')]
下面是一个对比示例:
# 浏览器生成的XPath(过于具体,容易因页面结构变化而失效)
specific_xpath = "/html/body/div[1]/div[3]/div[1]/div/div[2]/form/span[1]/input"
# 优化后的XPath(更具通用性和可维护性)
optimized_xpath = "//input[@id='kw' or @name='wd']"
3. 使用XPath测试工具
有多种工具可以帮助测试XPath表达式:
- Chrome插件:XPath Helper、XPath Finder等
- 在线工具:如XPath Tester
- 在Python中实时测试:使用
lxml和一个小测试脚本
# 在Python中测试XPath表达式的简单脚本
def test_xpath(html_str, xpath_expr):
from lxml import etree
html = etree.HTML(html_str)
result = html.xpath(xpath_expr)
print(f"XPath: {xpath_expr}")
print(f"匹配元素数量: {len(result)}")
if len(result) > 0:
if isinstance(result[0], str):
print(f"第一个匹配结果: {result[0]}")
else:
print(f"第一个匹配元素的文本: {result[0].xpath('string(.)')}")
return result
# 使用示例
html_content = """<div class="container"><span class="title">测试标题</span></div>"""
test_xpath(html_content, "//span[@class='title']")
test_xpath(html_content, "//div/span/text()")
输出结果:
XPath: //span[@class='title']
匹配元素数量: 1
第一个匹配元素的文本: 测试标题
XPath: //div/span/text()
匹配元素数量: 1
第一个匹配结果: 测试标题
4. 从特殊到一般
构建XPath的一个好策略是先找到一个特定元素,然后逐步泛化:
html_str = """
<html>
<body>
<div id="products">
<div class="product item-123" data-category="electronics">
<h3>手机</h3>
<p class="price">¥1999</p>
</div>
<div class="product item-456" data-category="electronics">
<h3>平板电脑</h3>
<p class="price">¥2999</p>
</div>
<div class="product item-789" data-category="books">
<h3>Python编程</h3>
<p class="price">¥89</p>
</div>
</div>
</body>
</html>
"""
html = etree.HTML(html_str)
# 1. 先构建非常具体的XPath(只匹配一个元素)
specific_xpath = "//div[@id='products']/div[@class='product item-123' and @data-category='electronics']"
result = html.xpath(specific_xpath)
print(f"具体XPath匹配结果数: {len(result)}")
# 2. 然后逐步泛化
# 2.1 移除一些具体的约束
less_specific_xpath = "//div[@id='products']/div[contains(@class, 'product')]"
result = html.xpath(less_specific_xpath)
print(f"稍微泛化的XPath匹配结果数: {len(result)}")
# 2.2 进一步泛化,仅保留核心特征
general_xpath = "//div[contains(@class, 'product')]"
result = html.xpath(general_xpath)
print(f"进一步泛化的XPath匹配结果数: {len(result)}")
# 3. 筛选特定类别的产品
electronics_xpath = "//div[contains(@class, 'product') and @data-category='electronics']"
result = html.xpath(electronics_xpath)
print(f"电子产品数量: {len(result)}")
输出结果:
具体XPath匹配结果数: 1
稍微泛化的XPath匹配结果数: 3
进一步泛化的XPath匹配结果数: 3
电子产品数量: 2
八、XPath与CSS选择器的对比
XPath和CSS选择器是两种最常用的元素定位方法,它们各有优缺点:
| 特性 | XPath | CSS选择器 |
|---|---|---|
| 向上遍历 | 支持(如../、ancestor::) | 有限支持 |
| 基于文本选择 | 支持(如//a[text()='点击']) | 不直接支持 |
| 复杂条件 | 很强大(支持逻辑运算、函数等) | 相对有限 |
| 语法简洁度 | 相对复杂 | 通常更简洁 |
| 性能 | 一般稍慢但功能强大 | 通常更快但功能有限 |
让我们通过一个实际例子来对比:
html_str = """
<html>
<body>
<div id="menu">
<ul>
<li><a href="/home" class="nav-link">首页</a></li>
<li><a href="/products" class="nav-link active">产品</a></li>
<li><a href="/download" class="button">下载</a></li>
</ul>
</div>
<div id="content">
<h1>产品列表</h1>
<div class="product">产品1</div>
<div class="product">产品2</div>
<div class="product">产品3</div>
</div>
</body>
</html>
"""
html = etree.HTML(html_str)
# 使用XPath
active_link_xpath = html.xpath('//a[contains(@class, "active")]')
download_button_xpath = html.xpath('//a[contains(text(), "下载") and @class="button"]')
parent_li_xpath = html.xpath('//a[@class="nav-link active"]/parent::li')
print("XPath结果:")
print(f"活跃链接文本: {active_link_xpath[0].xpath('string(.)')}")
print(f"下载按钮链接: {download_button_xpath[0].get('href')}")
print(f"活跃链接的父元素: {etree.tostring(parent_li_xpath[0], encoding='unicode')}")
# 使用CSS选择器(通过lxml)
from lxml.cssselect import CSSSelector
sel = CSSSelector('a.nav-link.active')
active_link_css = sel(html)
sel = CSSSelector('a.button') # 无法直接按文本过滤
download_button_css = sel(html)
print("\nCSS选择器结果:")
print(f"活跃链接文本: {active_link_css[0].xpath('string(.)')}")
print(f"下载按钮链接: {download_button_css[0].get('href')}")
# CSS选择器不能直接选择父元素
输出结果:
XPath结果:
活跃链接文本: 产品
下载按钮链接: /download
活跃链接的父元素: <li><a href="/products" class="nav-link active">产品</a></li>
CSS选择器结果:
活跃链接文本: 产品
下载按钮链接: /download
九、常见问题与解决方案
1. XPath没有找到预期元素
可能原因:
- XPath表达式不正确
- 元素在加载时不存在(JavaScript动态生成)
- 命名空间问题(XML特有)
解决方案:
- 检查HTML源码,确认元素存在
- 使用浏览器开发工具验证XPath
- 尝试使用更宽松的XPath(如使用
contains()而非精确匹配) - 如果是动态内容,考虑使用Selenium
# 问题示例
html_str = """
<div class="item item-type-A">项目A</div>
<div class="item item-type-B">项目B</div>
"""
html = etree.HTML(html_str)
# 不推荐: 精确匹配可能因类名顺序或变化而失效
bad_result = html.xpath('//div[@class="item-type-A item"]')
print(f"精确匹配结果数: {len(bad_result)}") # 可能为0
# 推荐: 使用contains()更灵活
good_result = html.xpath('//div[contains(@class, "item-type-A")]')
print(f"使用contains()的结果数: {len(good_result)}") # 应为1
输出结果:
精确匹配结果数: 0
使用contains()的结果数: 1
2. XPath返回空列表但元素明显存在
可能原因:
- HTML中存在命名空间(通常在XML或XHTML中更常见)
- 特殊字符或编码问题
- 大小写敏感性问题
解决方案:
- 检查HTML是否包含命名空间声明
- 使用更通用的匹配方式(如
contains()) - 尝试使用小写标签名(HTML标签名不区分大小写)
# 命名空间问题示例
xml_with_ns = """
<root xmlns:h="http://www.w3.org/TR/html4/">
<h:table>
<h:tr>
<h:td>数据1</h:td>
<h:td>数据2</h:td>
</h:tr>
</h:table>
</root>
"""
xml = etree.XML(xml_with_ns.encode())
# 不处理命名空间会失败
no_ns_result = xml.xpath('//table')
print(f"不处理命名空间的结果数: {len(no_ns_result)}") # 结果为0
# 正确处理命名空间
namespaces = {'h': 'http://www.w3.org/TR/html4/'}
with_ns_result = xml.xpath('//h:table', namespaces=namespaces)
print(f"处理命名空间后的结果数: {len(with_ns_result)}") # 结果为1
输出结果:
不处理命名空间的结果数: 0
处理命名空间后的结果数: 1
3. 提取文本内容不完整
可能原因:
- 元素内包含子元素,而
text()只提取直接文本节点 - 文本分散在多个标签中
解决方案:
- 使用
.//text()获取所有后代文本节点 - 连接所有文本节点并清理
html_str = """
<div class="product">
这是产品描述的开始
<span class="highlight">重点特性</span>
还有一些其他描述
<ul>
<li>特性1</li>
<li>特性2</li>
</ul>
结束语
</div>
"""
html = etree.HTML(html_str)
# 方法1: 只提取直接文本节点(不完整)
direct_text = html.xpath('//div[@class="product"]/text()')
print("只提取直接文本节点的结果:")
print(direct_text)
print(f"连接后: {''.join(direct_text).strip()}")
# 方法2: 提取所有后代文本节点(完整)
all_text = html.xpath('//div[@class="product"]//text()')
print("\n提取所有后代文本节点的结果:")
print(all_text)
print(f"连接后: {''.join(all_text).strip()}")
# 方法3: 使用string()函数(推荐方式)
string_method = html.xpath('string(//div[@class="product"])')
print("\n使用string()函数的结果:")
print(f"处理后: {string_method.strip()}")
输出结果:
只提取直接文本节点的结果:
['\n 这是产品描述的开始\n ', '\n 还有一些其他描述\n ', '\n 结束语\n']
连接后: 这是产品描述的开始 还有一些其他描述 结束语
提取所有后代文本节点的结果:
['\n 这是产品描述的开始\n ', '重点特性', '\n 还有一些其他描述\n ', '\n ', '特性1', '\n ', '特性2', '\n ', '\n 结束语\n']
连接后: 这是产品描述的开始重点特性还有一些其他描述特性1特性2结束语
使用string()函数的结果:
处理后: 这是产品描述的开始 重点特性 还有一些其他描述 特性1 特性2 结束语
十、总结
XPath是一个强大的工具,特别适合处理结构复杂的HTML文档。以下是使用XPath的一些建议:
-
平衡精确性和健壮性:
- 过于精确的XPath容易因页面结构变化而失效
- 过于宽松的XPath可能匹配到不需要的元素
- 尽量找到平衡,使用关键属性和位置信息
-
优先使用id和class等稳定属性:
//div[@id='main']比//div[5]更稳定//div[contains(@class, 'content')]比完全匹配更灵活
-
使用相对路径代替绝对路径:
- 使用
//寻找目标容器,然后使用相对路径.//在容器内寻找 - 这样即使页面整体结构变化,只要容器特征保持不变,XPath仍然有效
- 使用
-
处理可能的异常情况:
- 总是检查返回结果是否为空
- 使用try-except捕获可能的异常
- 为关键数据提供默认值
-
编写清晰、可维护的XPath:
- 将复杂的XPath分解为多个步骤
- 为复杂的XPath添加注释
- 考虑使用变量存储中间结果
来看一个综合实践的例子:
from lxml import etree
import logging
logging.basicConfig(level=logging.INFO)
def extract_product_info(html_content):
"""从HTML中提取产品信息的示例,展示XPath最佳实践"""
try:
html = etree.HTML(html_content)
# 1. 首先找到产品容器
product_containers = html.xpath('//div[contains(@class, "product-item")]')
logging.info(f"找到 {len(product_containers)} 个产品")
products = []
for container in product_containers:
try:
# 2. 对每个容器使用相对XPath
# 使用.//来查找容器内的元素
name_elements = container.xpath('.//h3[contains(@class, "product-name")]')
name = name_elements[0].xpath('string(.)').strip() if name_elements else "未知产品"
# 3. 使用或逻辑处理不同结构的可能性
price = ""
price_elements = container.xpath(
'.//span[contains(@class, "price") or contains(@class, "product-price")]'
)
if price_elements:
price = price_elements[0].xpath('string(.)').strip()
# 4. 处理可能不存在的元素
img_src = ""
img_elements = container.xpath('.//img')
if img_elements and 'src' in img_elements[0].attrib:
img_src = img_elements[0].get('src')
products.append({
"name": name,
"price": price,
"image": img_src
})
except Exception as e:
logging.error(f"处理产品时出错: {e}")
continue
return products
except Exception as e:
logging.error(f"解析HTML时出错: {e}")
return []
# 测试数据
test_html = """
<div class="products-list">
<div class="product-item" id="p1">
<img src="/images/product1.jpg" alt="产品1">
<h3 class="product-name">智能手机</h3>
<span class="price">¥2999</span>
</div>
<div class="product-item" id="p2">
<img src="/images/product2.jpg" alt="产品2">
<h3 class="product-name">平板电脑</h3>
<span class="product-price">¥3999</span>
</div>
<div class="product-item" id="p3">
<h3 class="product-name">蓝牙耳机</h3>
<span class="price">¥499</span>
<!-- 这个产品没有图片 -->
</div>
</div>
"""
# 运行测试
products = extract_product_info(test_html)
print("\n提取的产品信息:")
for product in products:
print(f"名称: {product['name']}")
print(f"价格: {product['price']}")
print(f"图片: {product['image']}")
print("-" * 30)
输出结果:
INFO:root:找到 3 个产品
提取的产品信息:
名称: 智能手机
价格: ¥2999
图片: /images/product1.jpg
------------------------------
名称: 平板电脑
价格: ¥3999
图片: /images/product2.jpg
------------------------------
名称: 蓝牙耳机
价格: ¥499
图片:
------------------------------
十一、XPath与其他解析方法的结合使用
在实际项目中,有时候结合使用多种解析方法会更高效:
from lxml import etree
from bs4 import BeautifulSoup
html_str = """
<div id="content">
<div class="item">
<h3>项目1</h3>
<p>描述1</p>
</div>
<div class="item">
<h3>项目2</h3>
<p>描述2</p>
</div>
</div>
"""
# 先使用XPath定位大的容器
html = etree.HTML(html_str)
container = html.xpath('//div[@id="content"]')[0]
# 将容器转换为字符串,然后用BeautifulSoup处理
container_html = etree.tostring(container, encoding='unicode')
soup = BeautifulSoup(container_html, 'lxml')
# 用BeautifulSoup的方法继续处理
items = soup.find_all('div', class_='item')
print("通过混合方法提取的结果:")
for item in items:
title = item.h3.text
desc = item.p.text
print(f"标题: {title}, 描述: {desc}")
输出结果:
通过混合方法提取的结果:
标题: 项目1, 描述: 描述1
标题: 项目2, 描述: 描述2
这种混合方法结合了XPath的强大选择能力和BeautifulSoup的易用性。
最后我想说
通过本文,我们详细介绍了XPath在网页数据提取中的应用。从基础语法到高级用法,从实际案例到常见问题解决,我们展示了XPath强大的选择能力和灵活性。虽然相比于BeautifulSoup,XPath的语法可能略显复杂,但它提供了更强大的功能,特别是在处理复杂页面结构时。
通过实践我们可以看到,使用XPath可以精确定位网页中的任何元素,提取文本、属性和结构化数据。同时,本文也强调了构建稳健XPath表达式的重要性,以确保爬虫程序能够应对网页结构的变化。
在实际爬虫开发中,应根据具体需求选择合适的解析工具,有时甚至可以结合使用多种工具,以发挥各自的优势。
下一篇:【Python爬虫详解】第五篇:使用解析库提取网页数据——PyQuery