🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
序列数据的卷积
编码卷积
使用 Conv1D 超参数进行实验
使用 NASA 天气数据
在 Python 中读取 GISS 数据
使用 RNN 进行序列建模
探索更大的数据集
使用其他循环方法
使用 Dropout
使用双向 RNN
概括
最后几章向您介绍了序列数据。您了解了如何首先使用统计方法对其进行预测,然后是使用深度神经网络的基本机器学习方法。您还探索了如何使用 Keras Tuner 调整模型的超参数。在本章中,您将了解其他技术,这些技术可以进一步增强您使用卷积神经网络和递归神经网络预测序列数据的能力。
序列数据的卷积
在第 3 章中,您了解了卷积,其中将 2D 滤波器传递到图像上以对其进行修改并可能提取特征。随着时间的推移,神经网络了解到哪些过滤器值可以有效地将对像素所做的修改与其标签相匹配,从而有效地从图像中提取特征。这同样的技术可以应用于数字时间序列数据,但有一个修改:卷积将是一维的而不是二维的。
例如,考虑图 11-1中的数字系列。

图 11-1。数字序列
一维卷积可以按如下方式对这些进行操作。将卷积视为一个 1 × 3 滤波器,滤波器值分别为 –0.5、1 和 –0.5。在这种情况下,序列中的第一个值将丢失,第二个值将从 8 转换为 –1.5,如图 11-2所示。
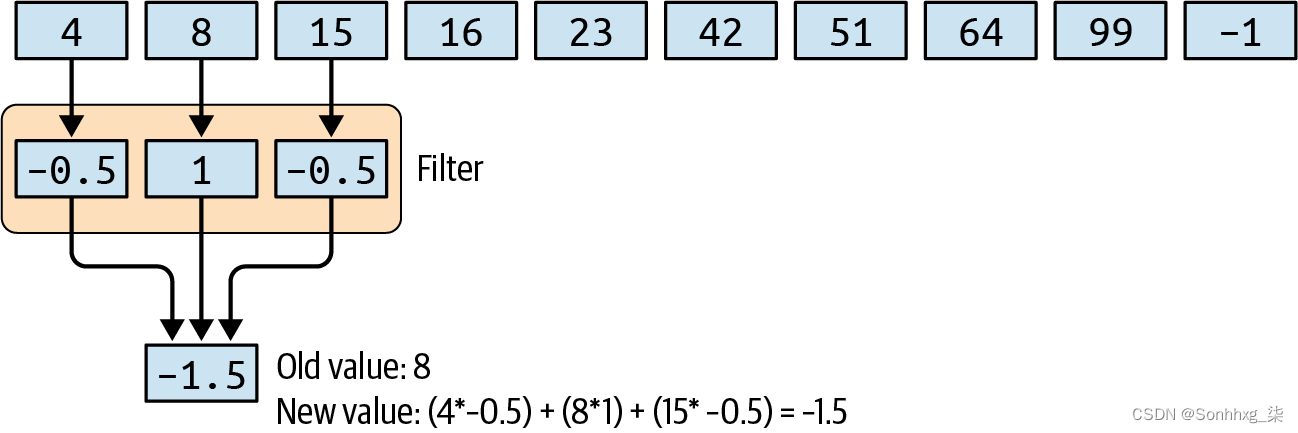
图 11-2。使用与数字序列的卷积
然后,过滤器将跨过这些值,同时计算新的值。因此,例如,在下一个步幅中,15 将被转换为 3,如图 11-3所示。
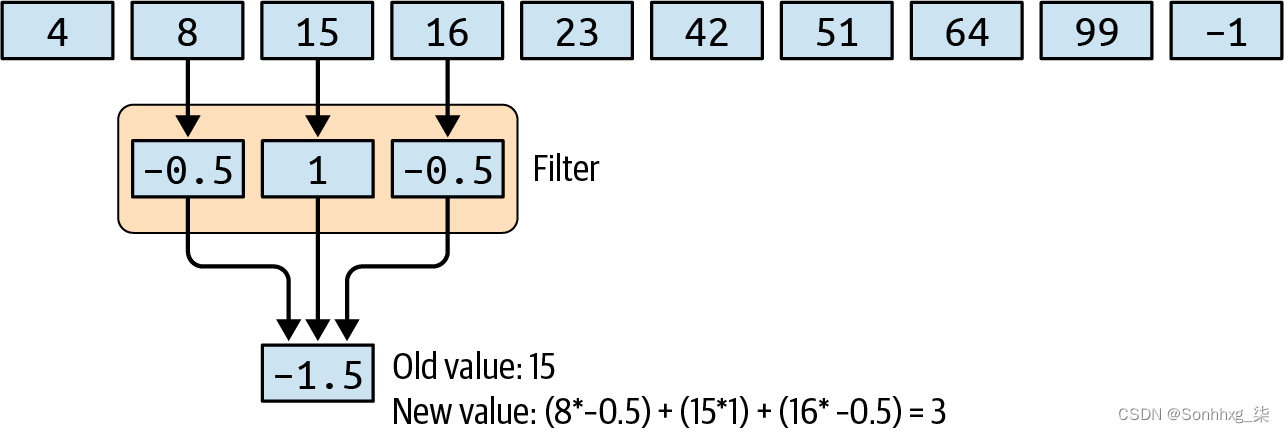
图 11-3。一维卷积的额外进步
使用这种方法,可以提取值之间的模式并学习成功提取它们的过滤器,这与图像中像素上的卷积能够提取特征的方式大致相同。在这种情况下,没有标签,但可以学习最小化总体损失的卷积。
编码卷积
前编码卷积,你必须调整你在上一章中使用的窗口数据集生成器。这是因为在对卷积层进行编码时,您必须指定维度。窗口化数据集是单一维度,但未定义为一维张量。这只需要添加一个 tf.expand_dims函数开头的声明windowed_dataset如下:
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
series = tf.expand_dims(series, axis=-1)
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer).map(
lambda window: (window[:-1], window[-1]))
dataset = dataset.batch(batch_size).prefetch(1)
return dataset现在您有了修改后的数据集,您可以在之前的密集层之前添加一个卷积层:
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=128, kernel_size=3,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.Dense(28, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
])
optimizer = tf.keras.optimizers.SGD(lr=1e-5, momentum=0.5)
model.compile(loss="mse", optimizer=optimizer)
history = model.fit(dataset, epochs=100, verbose=1)filters:是您希望该层学习的过滤器数量。它会生成这个数字,并随着时间的推移调整它们以适应您的数据。
kernel_size:是过滤器的大小——之前我们演示了一个值为 –0.5, 1, –0.5的过滤器,这将是内核大小为 3。
strides:是过滤器在扫描列表时将采取的“步骤”的大小。这通常是 1。
padding:确定关于从中删除结束数据的列表的行为。3 × 1 过滤器将“丢失”列表的第一个和最后一个值,因为它无法计算第一个的先验值或最后一个的后续值。通常,您将causal在此处使用序列数据,它只会从当前和之前的时间步长中获取数据,而不会从未来的时间步长中获取数据。因此,例如,一个 3 × 1 滤波器将采用当前时间步长以及前两个时间步长。
activation:是激活函数。在这种情况下,relu意味着有效地拒绝来自层的负值。
input_shape:与往常一样,是传递到网络中的数据的输入形状。由于这是第一层,您必须指定它。
用它训练会像以前一样给你一个模型,但是要从模型中得到预测,假设输入层已经改变形状,你需要稍微修改你的预测代码。
此外,不是根据前一个窗口一个一个地预测每个值,如果您已将序列正确格式化为数据集,您实际上可以获得整个序列的单个预测。为了稍微简化一下,这里有一个辅助函数,可以根据模型预测整个系列,具有指定的窗口大小:
def model_forecast(model, series, window_size):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecast如果你想使用模型来预测这个系列,你只需将系列与一个新轴一起传入,以处理Conv1D具有额外轴的层所需的 s。你可以这样做:
forecast = model_forecast(model, series[..., np.newaxis], window_size)您可以使用预定的拆分时间将此预测拆分为验证集的预测:
results = forecast[split_time - window_size:-1, -1, 0]图 11-4显示了结果与系列的关系图。
本例中的 MAE 为 4.89,比之前的预测略差。这可能是因为我们没有适当地调整卷积层,或者可能是卷积根本没有帮助。这是您需要对数据进行的实验类型。
请注意,此数据中有一个随机元素,因此值会在会话之间发生变化。如果你使用第 10 章的代码然后单独运行这段代码,你当然会有随机波动影响你的数据,从而影响你的 MAE。
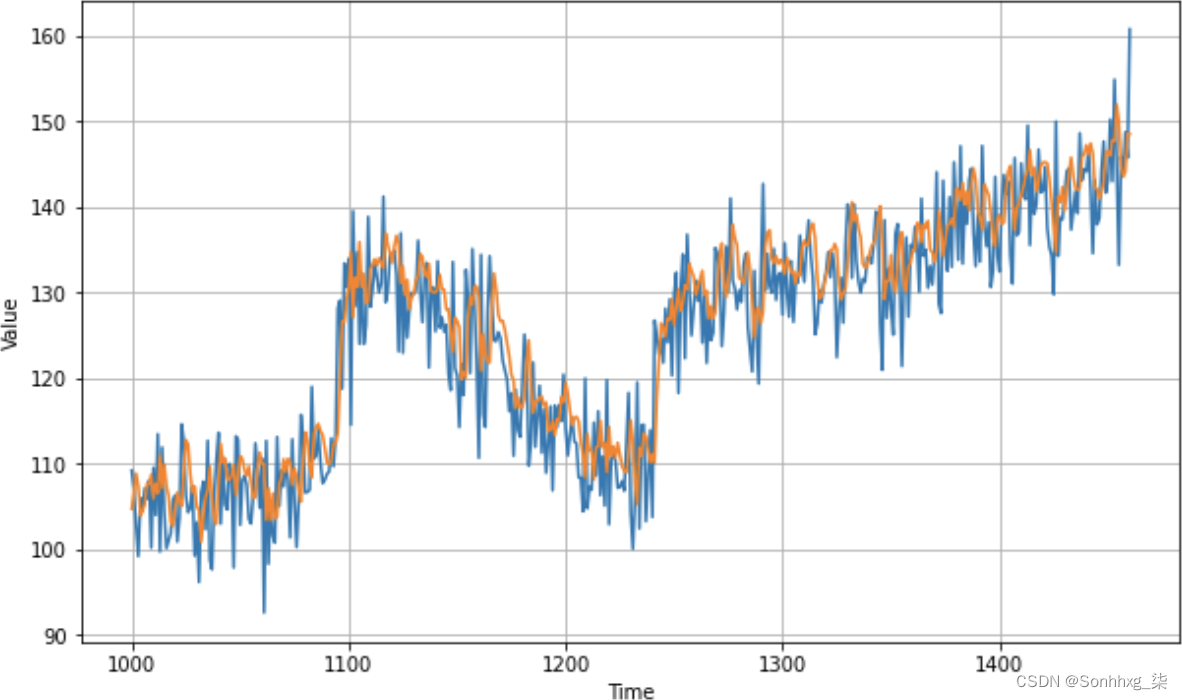
图 11-4。具有时间序列数据预测的卷积神经网络
但是在使用卷积时,问题总是会出现:为什么要选择我们选择的参数?为什么有 128 个过滤器?为什么尺寸为 3 × 1?好消息是您可以使用Keras Tuner对它们进行试验,如前所示。接下来我们将探讨这一点。
使用 Conv1D 超参数进行实验
在此示例中,您将试验过滤器数量、内核大小和步幅大小的超参数,同时保持其他参数不变:
def build_model(hp):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv1D(
filters=hp.Int('units',min_value=128, max_value=256, step=64),
kernel_size=hp.Int('kernels', min_value=3, max_value=9, step=3),
strides=hp.Int('strides', min_value=1, max_value=3, step=1),
padding='causal', activation='relu', input_shape=[None, 1]
))
model.add(tf.keras.layers.Dense(28, input_shape=[window_size],
activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='relu'))
model.add(tf.keras.layers.Dense(1))
model.compile(loss="mse",
optimizer=tf.keras.optimizers.SGD(momentum=0.5, lr=1e-5))
return model过滤器值将从 128 开始,然后以 64 为增量向上增加到 256。内核大小将从 3 开始,以 3 为增量增加到 9,步幅将从 1 开始,逐步增加到 3。
这里有很多值的组合,所以实验需要一些时间来运行。您还可以尝试其他更改,例如使用更小的起始值filters来查看它们的影响。
这是进行搜索的代码:
tuner = RandomSearch(build_model, objective='loss',
max_trials=500, executions_per_trial=3,
directory='my_dir', project_name='cnn-tune')
tuner.search_space_summary()
tuner.search(dataset, epochs=100, verbose=2)当我运行实验时,我发现 128 个过滤器,大小为 9,步幅为 1,给出了最好的结果。因此,与初始模型相比,最大的区别在于改变了过滤器的大小——这对于如此庞大的数据体来说是有意义的。过滤器大小为 3 时,只有最近的邻居有影响,而过滤器大小为 9 时,更远的邻居也会对应用过滤器的结果产生影响。这将保证进一步的实验,从这些值开始并尝试更大的过滤器尺寸和可能更少的过滤器。我会把它留给你,看看你是否可以进一步改进模型!
将这些值插入模型架构中,您将得到:
dataset = windowed_dataset(x_train, window_size, batch_size,
shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=128, kernel_size=9,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.Dense(28, input_shape=[window_size],
activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
])
optimizer = tf.keras.optimizers.SGD(lr=1e-5, momentum=0.5)
model.compile(loss="mse", optimizer=optimizer)
history = model.fit(dataset, epochs=100, verbose=1)训练后,与之前创建的原始 CNN和原始 DNN相比,该模型的准确性有所提高,如图 11-5 所示。
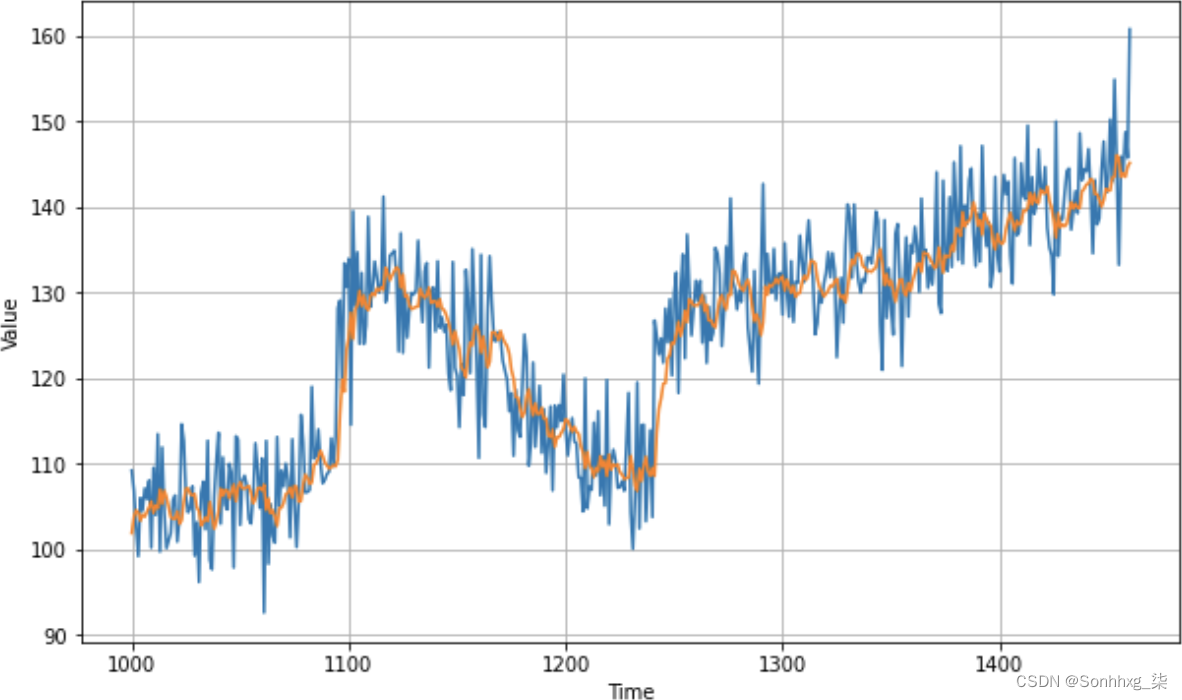
图 11-5。优化的 CNN 预测
这导致 MAE 为 4.39,这比我们在不使用卷积层的情况下得到的 4.47 略有改进。对 CNN 超参数的进一步实验可能会进一步改善这一点。
除了卷积之外,我们在使用 RNN(包括 LSTM)进行自然语言处理的章节中探索的技术在处理序列数据时可能非常强大。就其本质而言,RNN 是为维护上下文而设计的,因此以前的值可以对以后的值产生影响。接下来您将探索使用它们进行序列建模。但首先,让我们从合成数据集开始,开始研究真实数据。在这种情况下,我们将考虑天气数据。
使用 NASA 天气数据
一时间序列天气数据的重要资源是 NASA 戈达德太空研究所 (GISS) 表面温度分析。如果您点击Station Data 链接,您可以在页面右侧选择一个气象站来获取数据。例如,我选择了西雅图塔科马 (SeaTac) 机场,然后被带到了图 11-6中的页面。
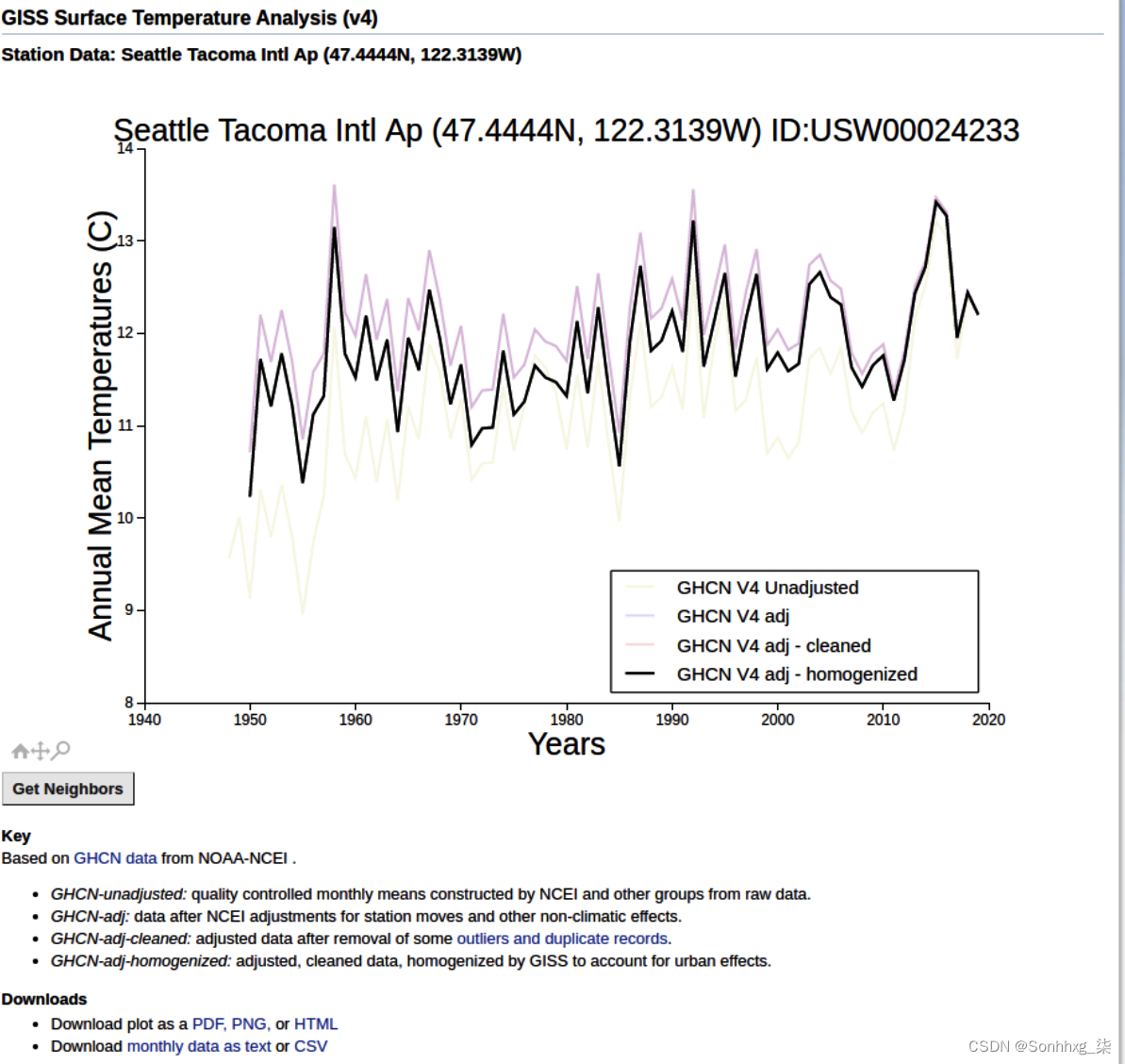
图 11-6。来自 GISS 的地表温度数据
您可以在本页底部看到以 CSV 格式下载每月数据的链接。选择此项,名为station.csv的文件将下载到您的设备。如果你打开它,你会看到它是一个数据网格,每行有一年,每列有一个月,如图 11-7 所示。
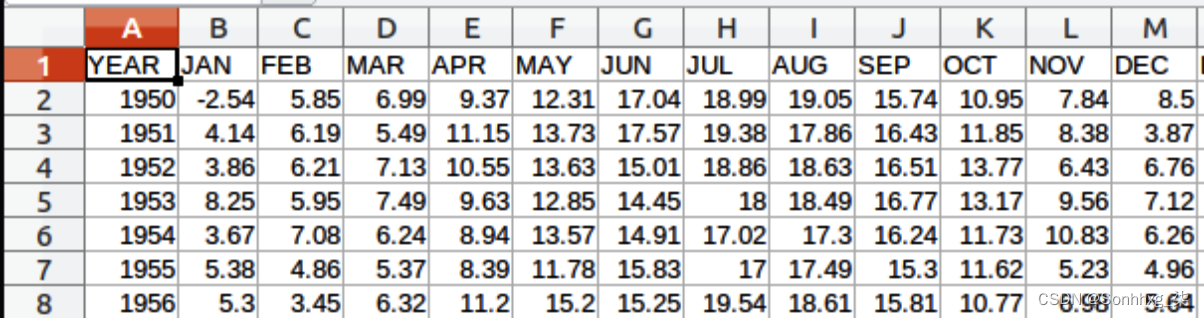
图 11-7。探索数据
由于这是 CSV 数据,因此在 Python 中很容易处理,但与任何数据集一样,请注意格式。阅读 CSV 时,您倾向于逐行阅读,通常每一行都有一个您感兴趣的数据点。在这种情况下,每行至少有 12 个感兴趣的数据点,因此您必须考虑这在读取数据时。
在 Python 中读取 GISS 数据
def get_data():
data_file = "/home/ljpm/Desktop/bookpython/station.csv"
f = open(data_file)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
temperatures=[]
for line in lines:
if line:
linedata = line.split(',')
linedata = linedata[1:13]
for item in linedata:
if item:
temperatures.append(float(item))
series = np.asarray(temperatures)
time = np.arange(len(temperatures), dtype="float32")
return time, series这将在指定的路径(您的路径当然会有所不同)打开文件并将整个文件作为一组行读入,其中行拆分是换行符 ( \n)。然后它将循环遍历每一行,忽略第一行,并根据逗号字符将它们拆分为一个名为linedata. 此数组中从 1 到 13 的项目将以字符串形式表示一月到二月的值。这些值被转换为浮点数并添加到名为 的数组temperatures中。完成后,它将变成一个名为 的 Numpy 数组,并且将创建series另一个名为 的 Numpy 数组,其大小与 相同。由于它是使用 创建的,因此第一个元素将为 1,第二个为 2,依此类推。因此,此函数将返回timeseriesnp.arangetime从 1 到数据点的数量,series作为当时的数据。
现在如果你想要一个标准化的时间序列,你可以简单地运行这个代码:
time, series = get_data()
mean = series.mean(axis=0)
series-=mean
std = series.std(axis=0)
series/=std这可以像以前一样分为训练集和验证集。根据数据大小选择拆分时间——在本例中我有大约 840 个数据项,所以我在 792 处拆分(保留四年的数据点用于验证):
split_time = 792
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]因为数据现在是一个 Numpy 数组,您可以使用与以前相同的代码从中创建一个窗口数据集来训练神经网络:
window_size = 24
batch_size = 12
shuffle_buffer_size = 48
dataset = windowed_dataset(x_train, window_size,
batch_size, shuffle_buffer_size)
valid_dataset = windowed_dataset(x_valid, window_size,
batch_size, shuffle_buffer_size)这应该使用与windowed_dataset本章前面的卷积网络相同的功能,增加了一个新的维度。使用 RNN、GRU 和 LSTM 时,您将需要这种形状的数据。
使用 RNN 进行序列建模
现在如果您在窗口数据集中拥有来自 NASA CSV 的数据,那么创建模型来为其训练预测器就相对容易了。(训练一个好的模型有点困难!)让我们从一个使用 RNN 的简单、朴素的模型开始。这是代码:
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(100, return_sequences=True,
input_shape=[None, 1]),
tf.keras.layers.SimpleRNN(100),
tf.keras.layers.Dense(1)
])您可以使用与之前相同的超参数来编译和拟合模型,或者使用 Keras Tuner 看看是否可以找到更好的。为简单起见,您可以使用这些设置:
optimizer = tf.keras.optimizers.SGD(lr=1.5e-6, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer, metrics=["mae"])
history = model.fit(dataset, epochs=100, verbose=1,
validation_data=valid_dataset)即使一百个时期也足以了解它如何预测值。图 11-8显示了结果。
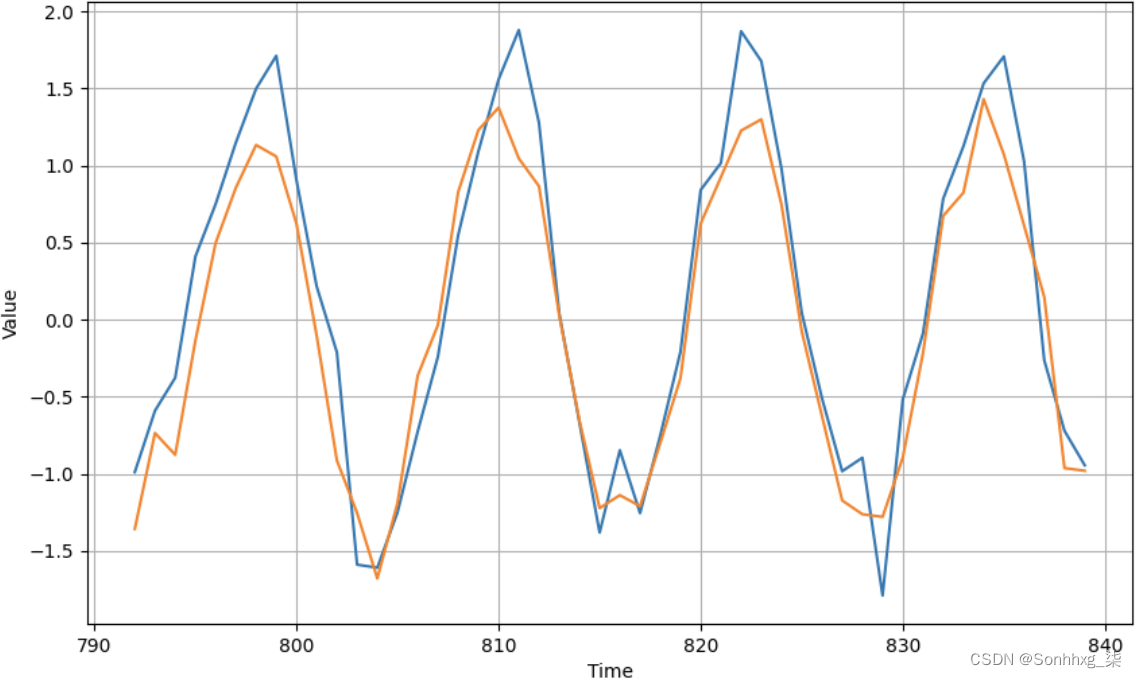
图 11-8。SimpleRNN 的结果
如您所见,结果非常好。它可能在峰值处有点偏离,并且当模式发生意外变化时(例如在时间步长 815 和 828 处),但总体上还不错。现在让我们看看如果我们训练它 1,500 个时期会发生什么(图 11-9)。
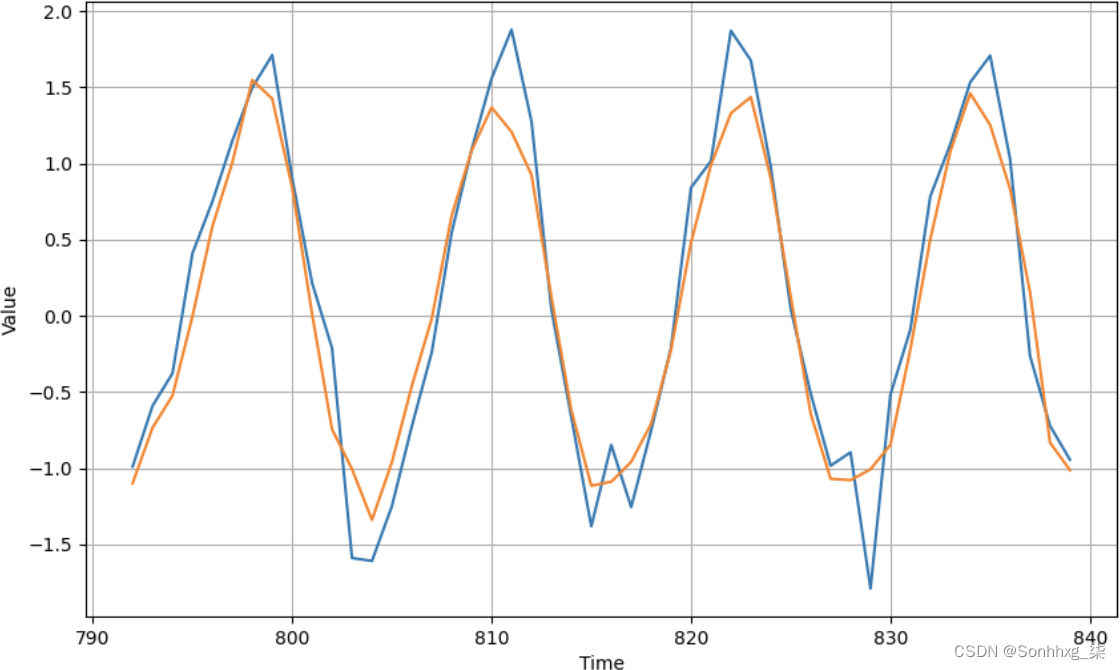
图 11-9。RNN 训练了超过 1,500 个时期
除了一些峰值被平滑之外,没有太大区别。如果你查看验证集和训练集的损失历史,它看起来像图 11-10。
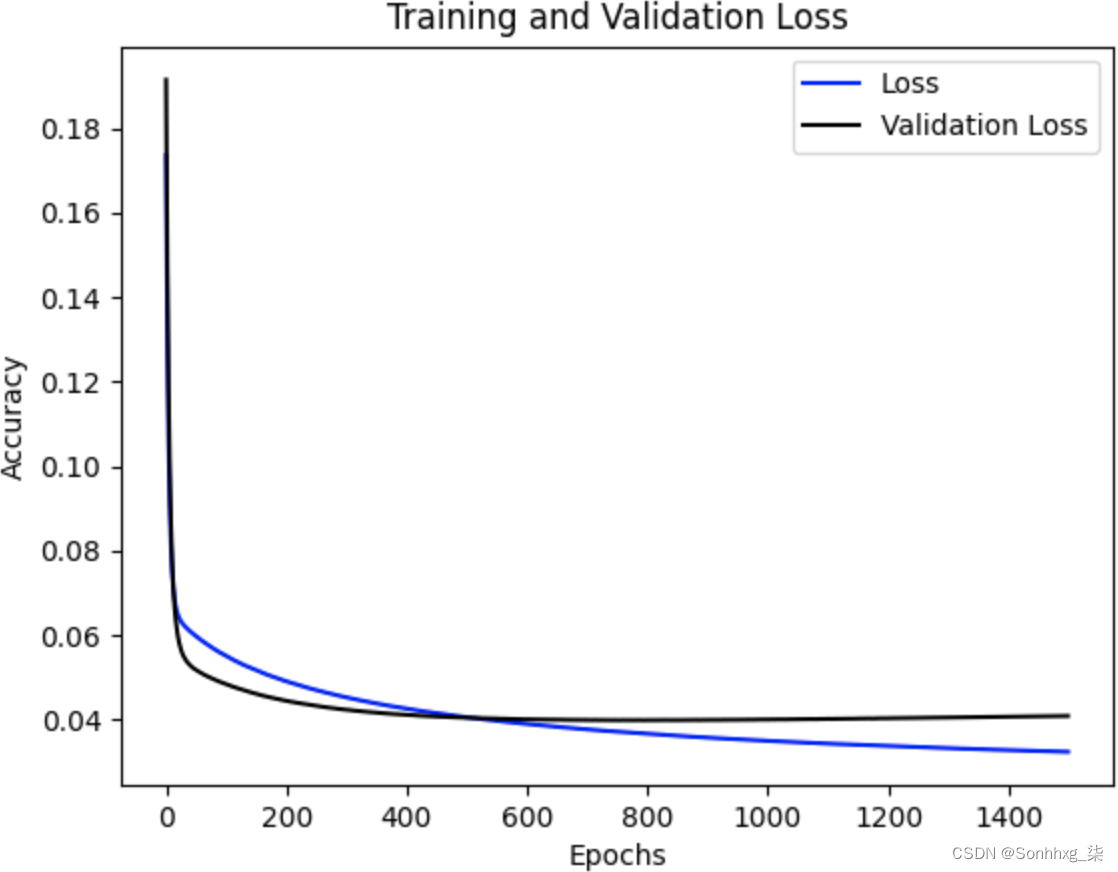
图 11-10。SimpleRNN 的训练和验证损失
如您所见,训练损失和验证损失之间存在良好的匹配,但随着时期的增加,模型开始在训练集上过度拟合。也许更好的纪元数是五百左右。
原因之一可能是这些数据是月度天气数据,具有很强的季节性。另一个是有一个非常大的训练集和一个相对较小的验证集。接下来,我们将探索使用更大的气候数据集。
探索更大的数据集
我已经准备好数据,剥离标题并删除无关的空格。这样就很容易阅读这样的代码:
def get_data():
data_file = "tdaily_cet.dat.txt"
f = open(data_file)
data = f.read()
f.close()
lines = data.split('\n')
temperatures=[]
for line in lines:
if line:
linedata = line.split(' ')
temperatures.append(float(linedata[1]))
series = np.asarray(temperatures)
time = np.arange(len(temperatures), dtype="float32")
return time, series该数据集包含 90,663 个数据点,因此,在训练您的模型之前,请确保对其进行适当拆分。我使用了 80,000 的分割时间,留下 10,663 条记录进行验证。此外,适当更新窗口大小、批量大小和随机播放缓冲区大小。这是一个例子:
window_size = 60
batch_size = 120
shuffle_buffer_size = 240其他一切都可以保持不变。正如您在图 11-11中所见,经过一百个时期的训练后,针对验证集的预测图看起来相当不错。

图 11-11。对真实数据的预测图
这里有很多数据,所以让我们放大到最近一百天的数据(图 11-12)。
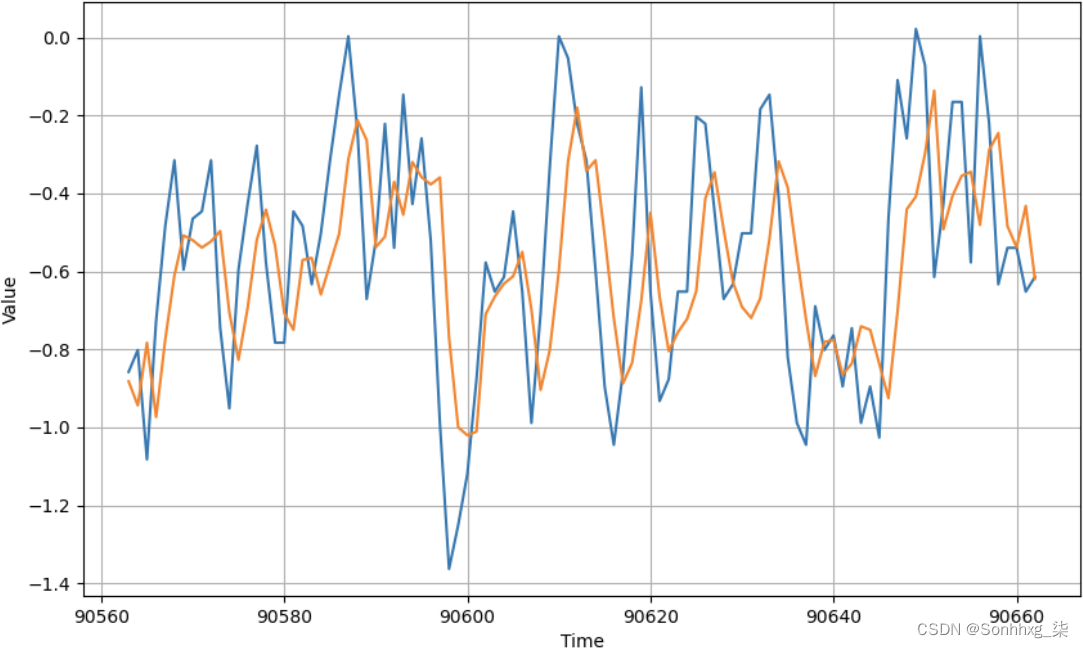
图 11-12。一百天数据的结果
虽然图表总体上遵循数据曲线,并且使趋势大致正确,但还差得很远,尤其是在极端情况下,因此还有改进的余地。
同样重要的是要记住我们对数据进行了标准化,因此虽然我们的损失和 MAE 可能看起来很低,但这是因为它们基于标准化值的损失和 MAE,这些标准化值的方差比真实值低得多。因此,图 11-13显示的损失小于 0.1,可能会让您产生一种错误的安全感。
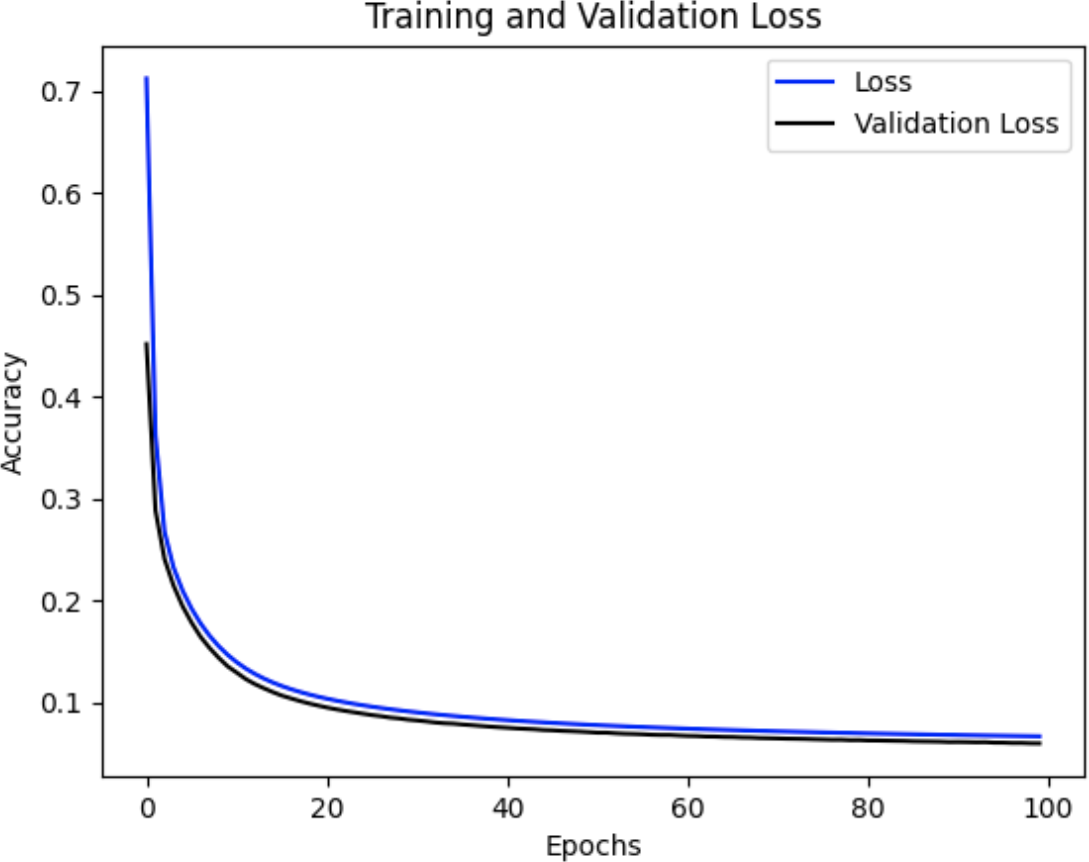
图 11-13。大型数据集的损失和验证损失
要对数据进行非规范化,您可以执行规范化的逆操作:首先乘以标准差,然后加回均值。此时,如果您愿意,您可以像之前那样计算预测集的真实 MAE。
使用其他循环方法
在除了SimpleRNN,TensorFlow 还有其他循环层类型,例如作为门控循环单元 (GRU) 和长短期记忆层 (LSTM),在第 7 章中讨论。当TFRecord您对本章中一直使用的数据使用基于 的架构时,如果您想进行试验,只需放入这些 RNN 类型就变得相对简单。
因此,举例来说,如果您考虑之前创建的简单朴素 RNN:
model = tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(100, input_shape=[None, 1],
return_sequences=True),
tf.keras.layers.SimpleRNN(100),
tf.keras.layers.Dense(1)
])用 GRU 替换它变得非常简单:
model = tf.keras.models.Sequential([
tf.keras.layers.GRU(100, input_shape=[None, 1], return_sequences=True),
tf.keras.layers.GRU(100),
tf.keras.layers.Dense(1)
])对于 LSTM,它是相似的:
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(100, input_shape=[None, 1], return_sequences=True),
tf.keras.layers.LSTM(100),
tf.keras.layers.Dense(1)
])值得尝试这些层类型以及不同的超参数、损失函数和优化器。没有放之四海而皆准的解决方案,因此在任何给定情况下最适合您的方法将取决于您的数据以及您对该数据进行预测的要求。
使用 Dropout
如果如果您在模型中遇到过度拟合,其中训练数据的 MAE 或损失比验证数据好得多,您可以使用 dropout。正如第 3 章在计算机视觉背景下讨论的那样,使用 dropout 时,相邻神经元在训练期间被随机丢弃(忽略)以避免熟悉偏差。使用 RNN 时,还可以使用循环丢失参数。
有什么不同?回想一下,在使用 RNN 时,您通常有一个输入值,神经元计算一个输出值和一个传递给下一个时间步的值。Dropout 将随机丢弃输入值。Recurrent dropout 将随机丢弃传递给下一步的循环值。
例如,考虑图 11-14中所示的基本递归神经网络架构。
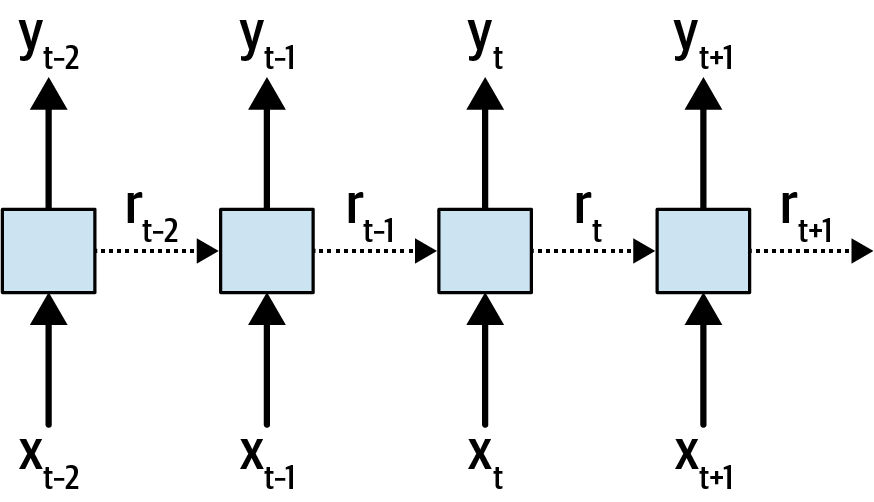
图 11-14。递归神经网络
在这里,您可以看到在不同时间步 ( x ) 下层的输入。当前时间为t,显示的步骤为t – 2 到t + 1。同时显示步骤 ( y ) 的相关输出。在时间步长之间传递的循环值由虚线表示并标记为r。
使用dropout将随机丢弃x输入。使用循环丢弃会随机丢弃r个循环值。
您可以在Yarin Gal 和 Zoubin Ghahramani的论文“A Theoretically Grounded Application of Dropout in Recurrent Neural Networks”中从更深层次的数学角度了解更多关于循环丢失的工作原理。
Gal 在他关于深度学习不确定性的研究中讨论了使用循环 dropout 时需要考虑的一件事,他在其中证明了应该在每个时间步应用相同的 dropout 单元模式,并且应该在每一步。虽然辍学通常是随机的,但 Gal 的工作内置于 Keras 中,因此在使用时tf.keras保持他的研究推荐的一致性。
要添加 dropout 和 recurrent dropout,您只需在图层上使用相关参数即可。例如,将它们添加到之前的简单 GRU 中将如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.GRU(100, input_shape=[None, 1], return_sequences=True,
dropout=0.1, recurrent_dropout=0.1),
tf.keras.layers.GRU(100, dropout=0.1, recurrent_dropout=0.1),
tf.keras.layers.Dense(1),
])每个参数取一个介于 0 和 1 之间的值,表示要丢弃的值的比例。值为 0.1 将丢弃必要值的 10%。
使用 dropout 的 RNN 通常需要更长的时间才能收敛,所以一定要训练它们更多的 epoch 来测试这一点。图 11-15显示了训练前述 GRU 的结果,其中每层的 dropout 和 recurrent dropout 设置为 0.1,超过 1,000 个 epoch。
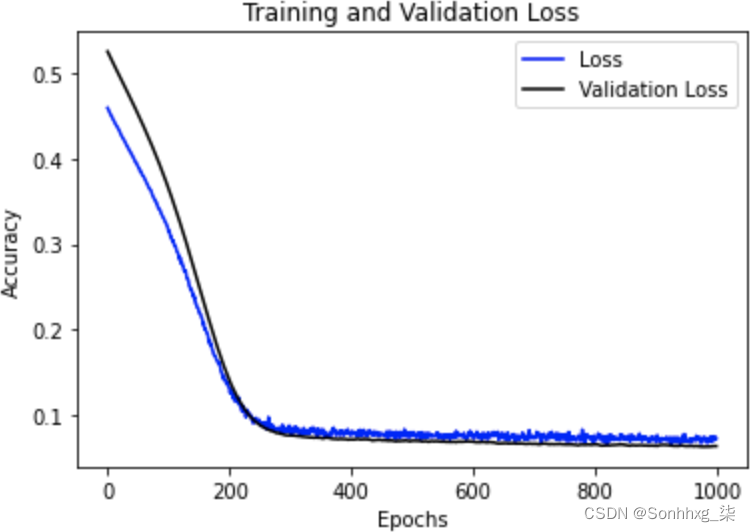
图 11-15。使用 dropout 训练 GRU
如您所见,损失和 MAE 迅速下降,直到大约第 300 个时期,之后它们继续下降,但下降幅度很大。使用 dropout 时,您经常会在损失中看到这样的噪声,这表明您可能想要调整 dropout 的数量以及损失函数的参数,例如学习率。正如您在图 11-16中所见,该网络的预测结果非常好,但仍有改进的空间,因为预测的峰值比实际峰值低得多。
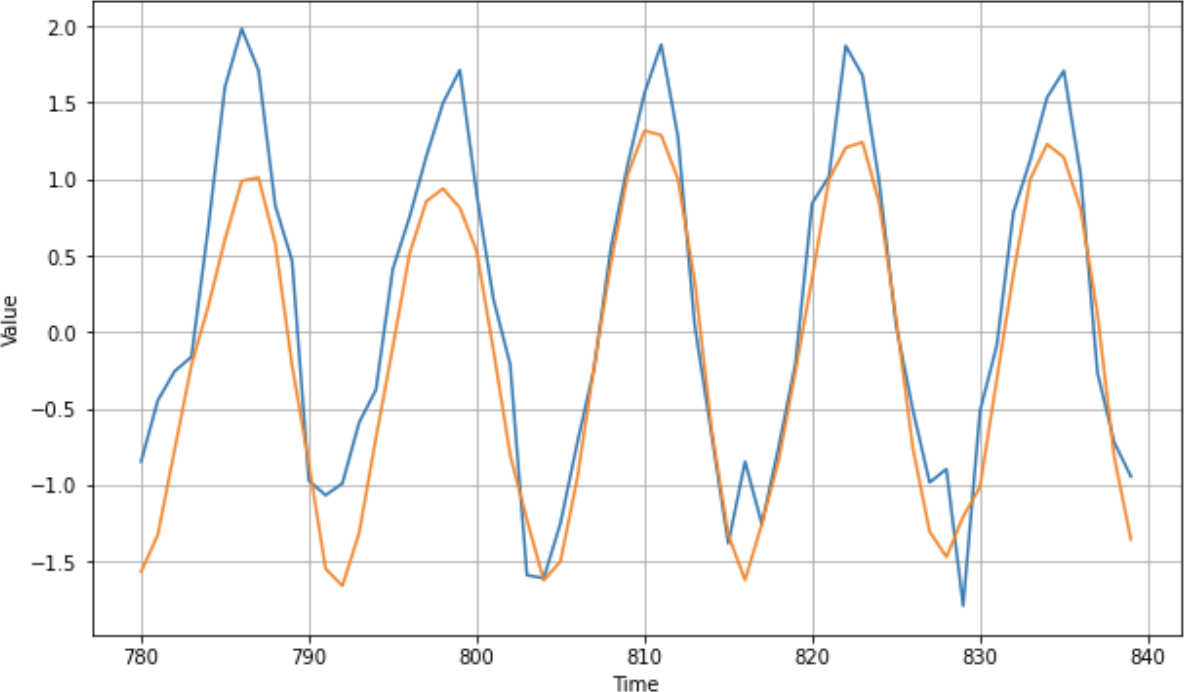
图 11-16。使用带 dropout 的 GRU 进行预测
正如您在本章中看到的,使用神经网络预测时间序列数据是一个困难的命题,但调整它们的超参数(特别是使用 Keras Tuner 等工具)可能是改进模型及其后续预测的有效方法。
使用双向 RNN
幸运的是,编写代码很简单。例如,考虑上一节中的 GRU。要实现这种双向,您只需包裹每个 GRU 层在tf.keras.layers.Bidirectional通话中。这将有效地在每个步骤上训练两次——一次以原始顺序使用序列数据,一次以相反的顺序使用它。然后在继续下一步之前合并结果。
这是一个例子:
model = tf.keras.models.Sequential([
tf.keras.layers.Bidirectional(
tf.keras.layers.GRU(100, input_shape=[None, 1],return_sequences=True,
dropout=0.1, recurrent_dropout=0.1)),
tf.keras.layers.Bidirectional(
tf.keras.layers.GRU(100, dropout=0.1, recurrent_dropout=0.1)),
tf.keras.layers.Dense(1),
])图 11-17显示了在时间序列上使用带 dropout 的双向 GRU 进行训练的结果图。如您所见,这里没有重大差异,MAE 最终也很相似。然而,对于更大的数据系列,您可能会看到相当大的准确性差异,另外调整训练参数——特别是window_size获得多个季节——会产生相当大的影响。
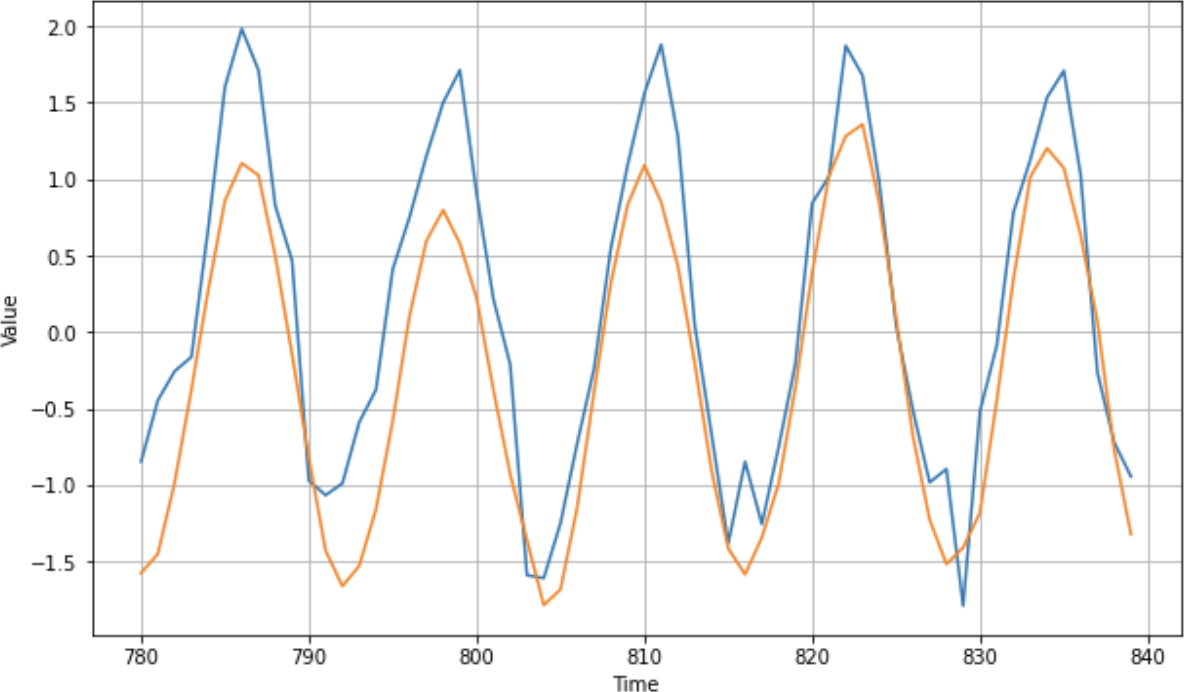
图 11-17。使用双向 GRU 进行训练
该网络的 MAE(在归一化数据上)约为 0.48,主要是因为它似乎在高峰值上表现不太好。使用更大的窗口和双向性对其进行再训练会产生更好的结果:它的 MAE 显着降低,约为 0.28(图 11-18)。
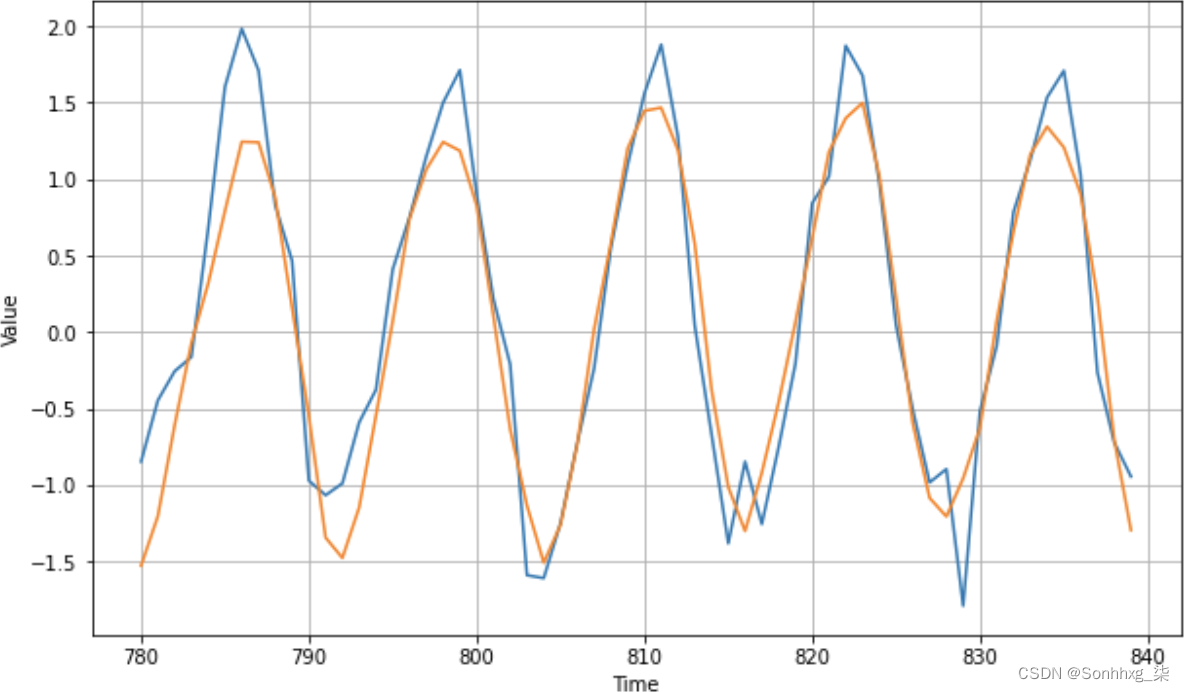
图 11-18。更大的窗口,双向 GRU 结果
如您所见,您可以尝试不同的网络架构和不同的超参数来改进整体预测。理想的选择在很大程度上取决于数据,因此您在本章中学到的技能将帮助您处理特定的数据集!
概括
在本章中,您探索了用于构建模型以预测时间序列数据的不同网络类型。您构建了第 10 章中的简单 DNN ,添加了卷积,并试验了循环网络类型,例如简单的 RNN、GRU 和 LSTM。您了解了如何调整超参数和网络架构以提高模型的准确性,并且练习了使用一些真实世界的数据集,包括一个具有数百年温度读数的海量数据集。您现在已准备好开始为各种数据集构建网络,并充分了解优化它们所需的知识!













![[数据库]复习杂项](https://img-blog.csdnimg.cn/20200314110339802.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lreV9feHVrYWk=,size_16,color_FFFFFF,t_70#pic_center)