Linux网络协议之HTTP协议(应用层)
文章目录
- Linux网络协议之HTTP协议(应用层)
- 1.HTTP协议的概念
- 2.HTTP协议中URL的理解
- 3.HTTP协议的数据流
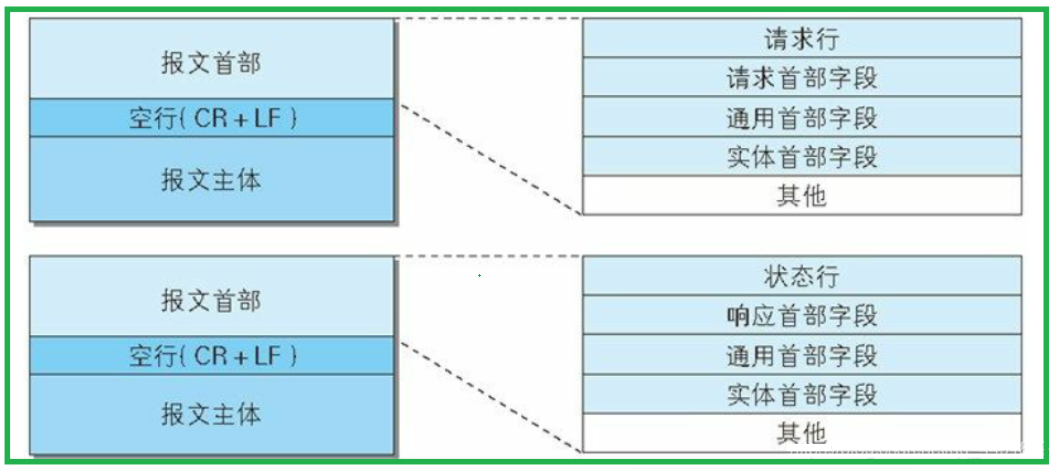
- 4.HTTP协议的格式
- 4.1 HTTP请求格式
- 4.2 HTTP响应格式
- 5.HTTP协议格式图解
- 6.HTTP协议版本
- 7.HTTP协议请求方法
- 7.1 GET方法:获取资源
- 7.2 POST方法:传输实体主体
- 7.3 PUT方法:传输文件
- 7.4 HEAD方法:获得报文首部
- 7.5 DELETE方法:删除文件
- 7.6 OPTIONS:询问支持的方法
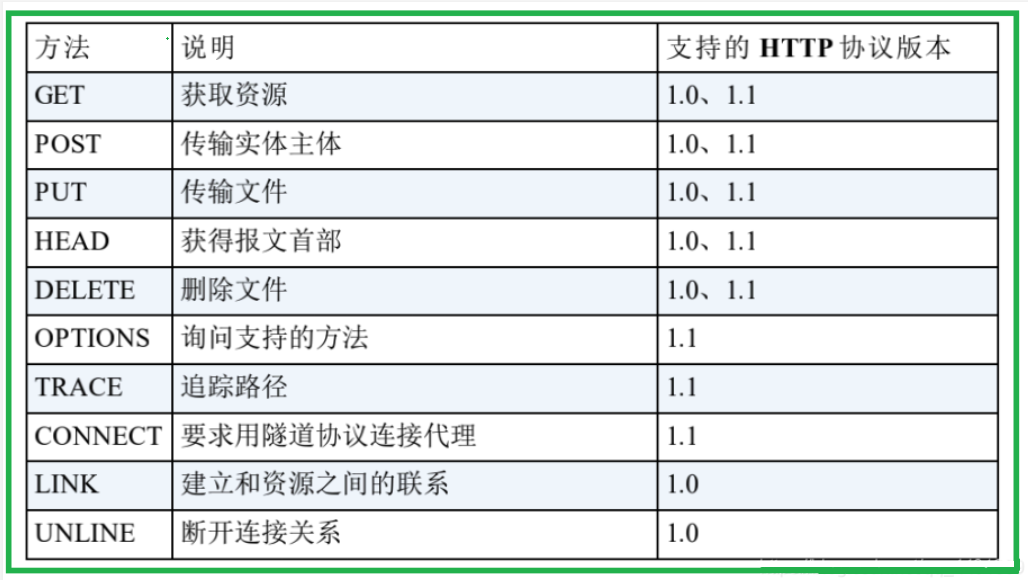
- 8.HTTP协议请求方法总结
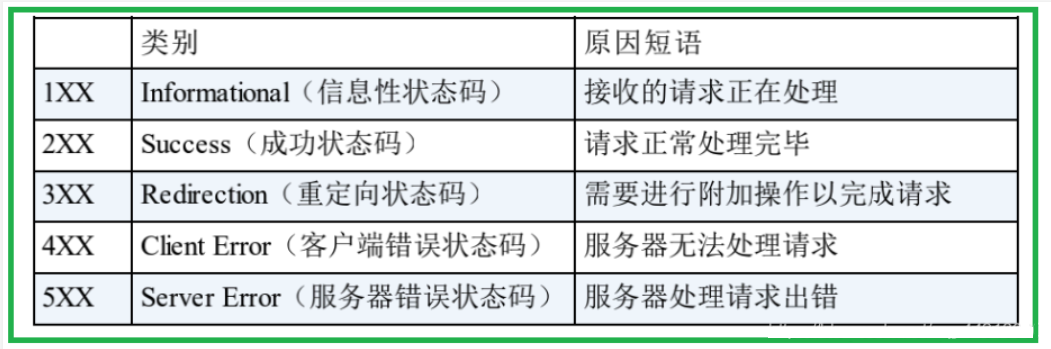
- 9.HTTP状态码理解
- 9.1 HTTP状态码类别
- 9.2 常见成功状态码(2XX)
- 9.3 常见重定向状态码(3XX)
- 9.4 常见客户端错误状态码(4XX)
- 9.5 常见的服务器错误状态码(5XX)
- 10.HTTP常见Header
- 11.HTTP协议与浏览器的交互
- 补充:HTTP与HTTPS协议的区别
- 扩展:对称加密与非对称加密
1.HTTP协议的概念
HTTP(HyperText Transfer Protocol):超⽂本传输协议- HTTP是⽆连接, ⽆状态, ⼯作在应⽤层的协议
- TCP在传输数据的时候,是需要建立连接的
- ⽆连接理解为: HTTP协议本身是没有维护连接信息的, HTTP的数据会交给⽹络协议栈传输层的TCP协议, ⽽TCP是⾯向连接的
- ⽆状态理解为: HTTP协议⾃身不对请求和响应之间的通信状态进⾏保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理
一点小思考:HTTP是无连接的,不会维护连接信息,那么它是否是可靠数据?
- HTTP是可靠传输的,虽然HTTP无连接,自身不会维护连接信息,但是,它的数据最终会交给传输层的TCP协议,而TCP协议是可靠传输的,因此HTTP协议是可靠传输的
2.HTTP协议中URL的理解
URL(Uniform Resource Location):统一资源定位符,其实就是我们说的"网址"
比如下图我们对URL的组成部分划分:

- http:明文传输,默认端口为80端口
- https:加密传输,默认端口是443端口(一般用ssl非对称加密方式,会对http双方发送的数据进行加密,公钥:客户端所持有,私钥:服务端所持有)
在URL的组成中,我们要注意一些字符被当作特殊意义来理解,比如下面:
比如, / ? : 等这样的字符, 已经被url当做特殊意义理解了。因此这些字符不能随意出现。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义
转义字符规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式urlencode:将字符转换成为16进制urlecode:将16进制数据转换成字符
- 比如这里我们看到我们搜索c++,这里的+就被替换成了%2B,这里的&是分隔符的意思,分割key_value键值对

最后我们来自己看看URL的组成结构,如下图:
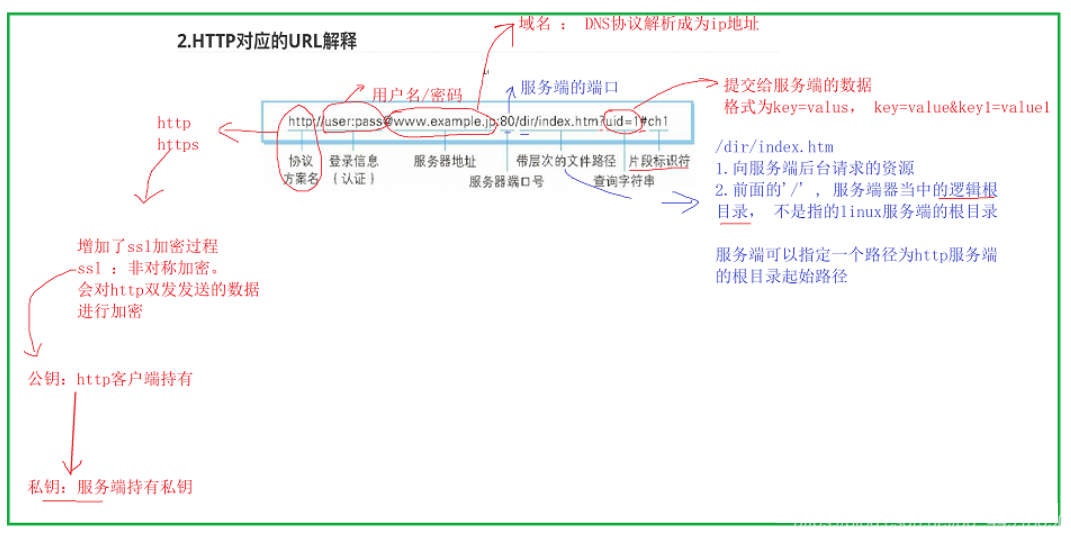
- 使⽤ http: 或 https: 等协议⽅案名获取访问资源时要指定协议类型。不区分字⺟⼤⼩写,最后附⼀个冒号(:)
- 登录信息(认证) 指定⽤户名和密码作为从服务器端获取资源时必要的登录信息(身份 认证)。此项为可选项
- 服务器地址 ,必须指定待访问的服务器地址。地址可以是类似 hackr.jp 这种 DNS 可解析的名称,或是192.168.1.1 这类 IPv4 地址 名,还可以是 [0:0:0:0:0:0:0:1] 这样⽤⽅括号括起来的 IPv6 地址名
- 服务器端⼝号 指定服务器连接的⽹络端⼝号。此项也是可选项,若⽤户省略则⾃动 使⽤默认端⼝号
- 带层次的⽂件路径 指定服务器上的⽂件路径来定位特指的资源
- 查询字符串针对已指定的⽂件路径内的资源,可以使⽤查询字符串传⼊任意参数。此项为可选项
- ⽚段标识符 使⽤⽚段标识符通常可标记出已获取资源中的⼦资源(⽂档内的某个位置)。该项为可选项
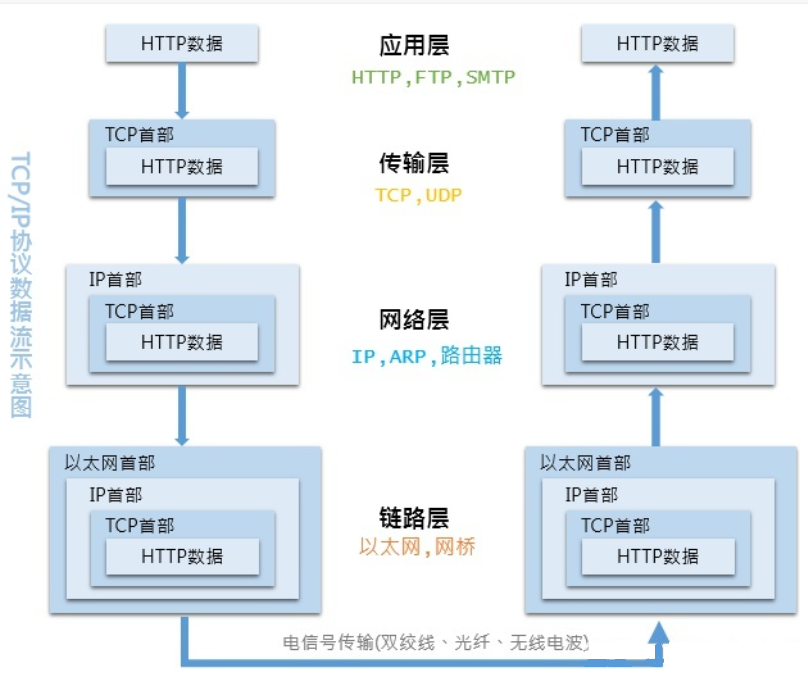
3.HTTP协议的数据流
4.HTTP协议的格式
4.1 HTTP请求格式
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建⽴通信的,服务器端在没有接收到请求之前不会发送响应
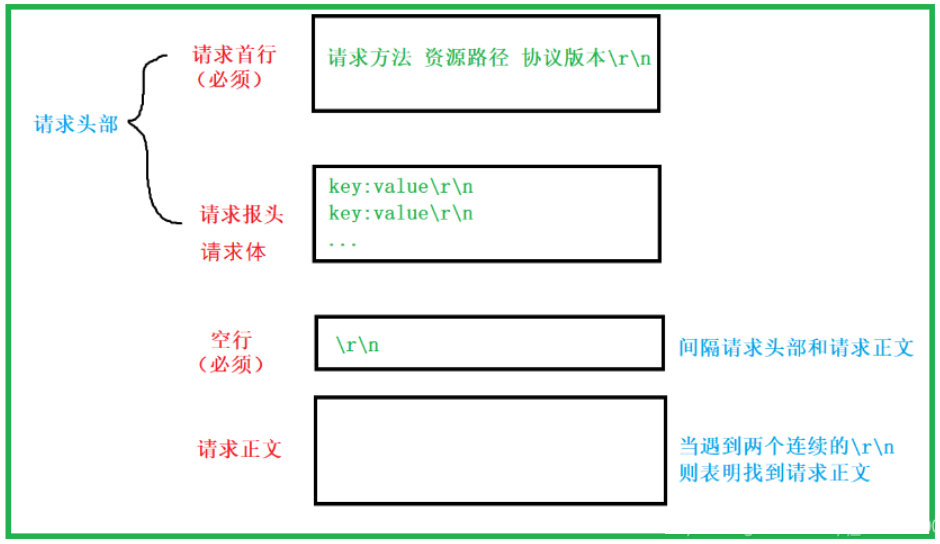
请求格式如下:
我们来验证一下这个请求格式:
- 假如我们在百度搜索C++,然后按F12打开开发者工具,此时我们会看到如下界面
- 此时打开的开发者工具框什么都没有,是因为内容已经加载过了,才打开的开发者工具,只需要刷新页面即可看到如下图所示界面:
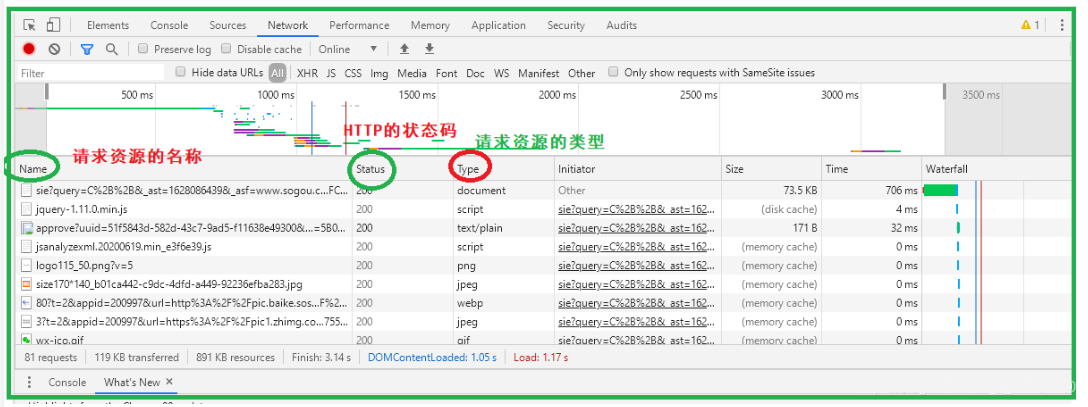
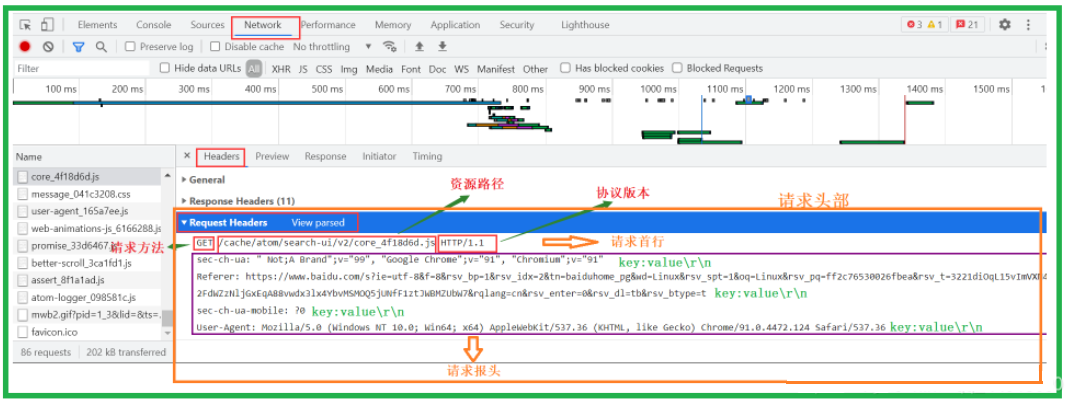
- 打开NetWork,在然后随便点开一个请求资源名称,如下图所示:
HTTP请求格式总结,如下图:
HTTP请求格式总结:
- 请求行:[请求方法]+[url]+[http版本]
- 请求报头:请求的属性,这些属性都是以key: value的形式按行陈列的
- 空行:遇到空行表示请求报头结束
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度


4.2 HTTP响应格式

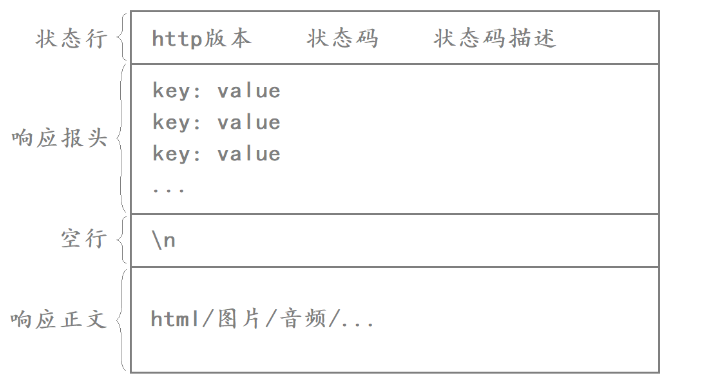
HTTP响应格式总结:
- 状态行:[http版本]+[状态码]+[状态码描述]
- 响应报头:响应的属性,这些属性都是以key: value的形式按行陈列的
- 空行:遇到空行表示响应报头结束
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。比如服务器返回了一个html页面,那么这个html页面的内容就是在响应正文当中的
5.HTTP协议格式图解
6.HTTP协议版本
HTTP协议版本到目前位置一共有四个版本
-
HTTP/0.9(不常用)HTTP/0.9 HTTP 于 1990 年问世。那时的 HTTP 并没有作为正式的标准被建立。现在的 HTTP 其实含有 HTTP1.0 之前版本的意思,因此被称为 HTTP/0.9
-
HTTP/1.0(常用)HTTP/1.0 HTTP 正式作为标准被公布是在 1996 年的 5 月,版本被命名为 HTTP/1.0,并记载于 RFC1945。虽说是初期标准,但该协议标准至今仍被广泛使用在服务器端
-
HTTP/1.1(常用)HTTP/1.1 1997 年 1 月公布的 HTTP/1.1 是目前主流的 HTTP 协议版本。当初的标准是 RFC2068,之后发布的修订版 RFC2616 就是当前的最新版本
-
HTTP/2.0(不常用)HTTP/2.0 新一代 HTTP/2.0 正在制订中,但要达到较高的使用覆盖率,仍需假以时日
7.HTTP协议请求方法
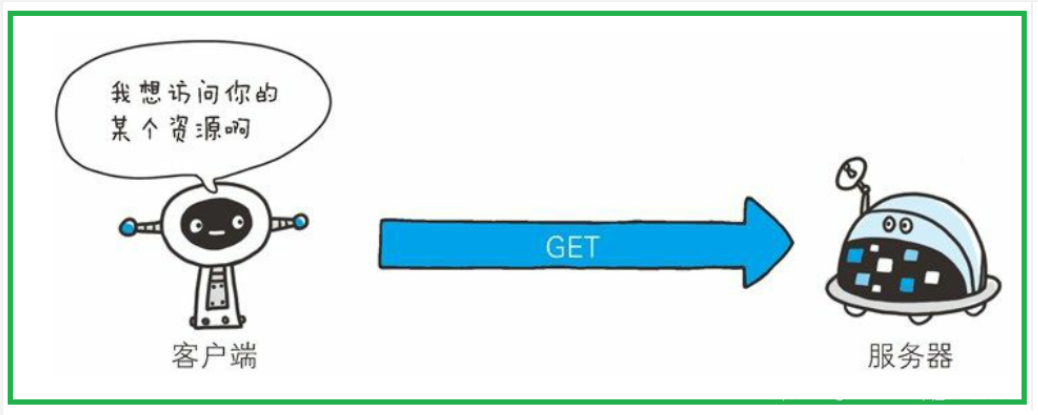
7.1 GET方法:获取资源

- GET 方法用来请求访问已被 URI 识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回
- GET既能从服务器中去获取数据,也能向服务器中提交少量数据,提交的数据在URL中
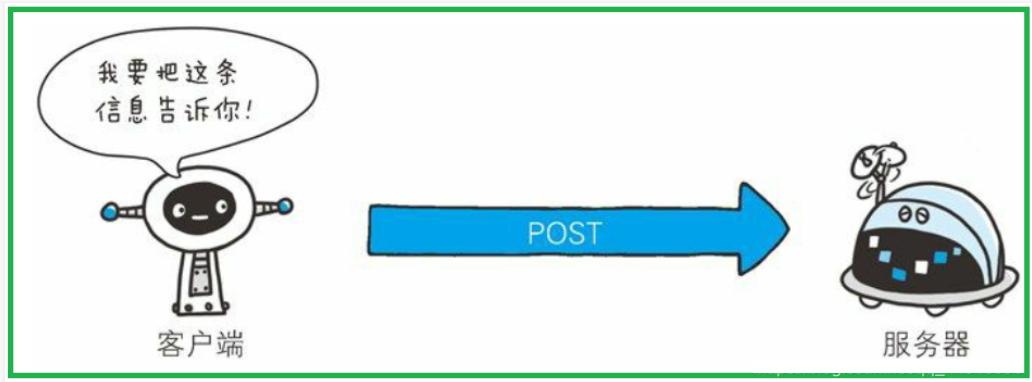
7.2 POST方法:传输实体主体
- 虽然用 GET 方法也可以传输实体的主体,但一般不用 GET 方法进行传输,而是用 POST 方法。虽说 POST 的功能与 GET 很相似,但 POST 的主要目的并不是获取响应的主体内容
- POST:给服务器提交某些数据,提交的数据在正文中
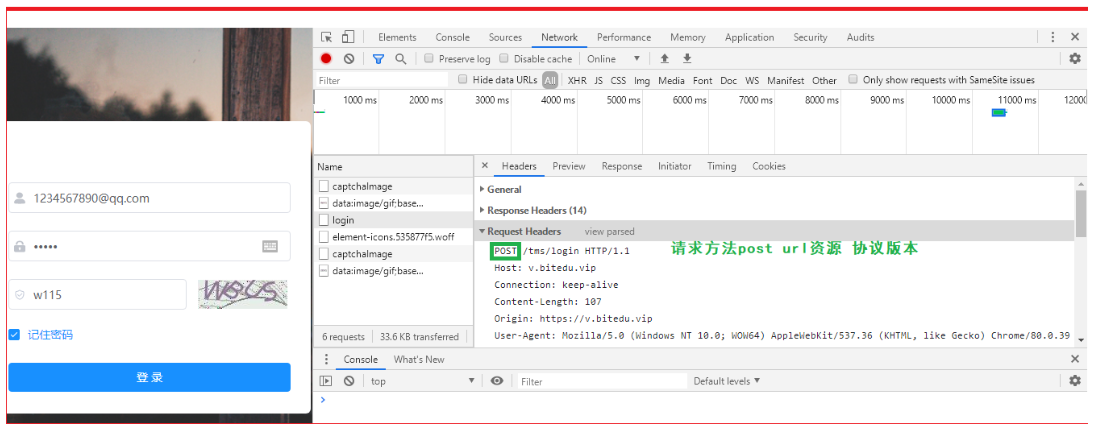
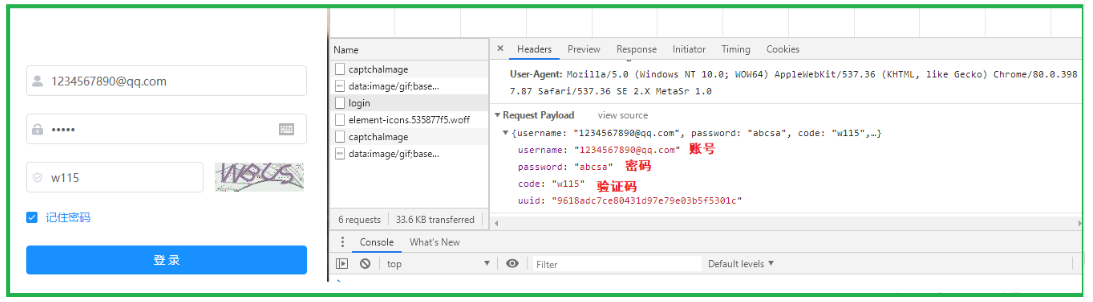
我们来举个例子:假设我们要在某个网页进行登录,使用POST请求就会将我们的账号,密码放在请求正文中进行提交
如下图所示我们可以看到POST请求,且在请求正文中可以看到刚才输入的账号密码和验证码:
7.3 PUT方法:传输文件
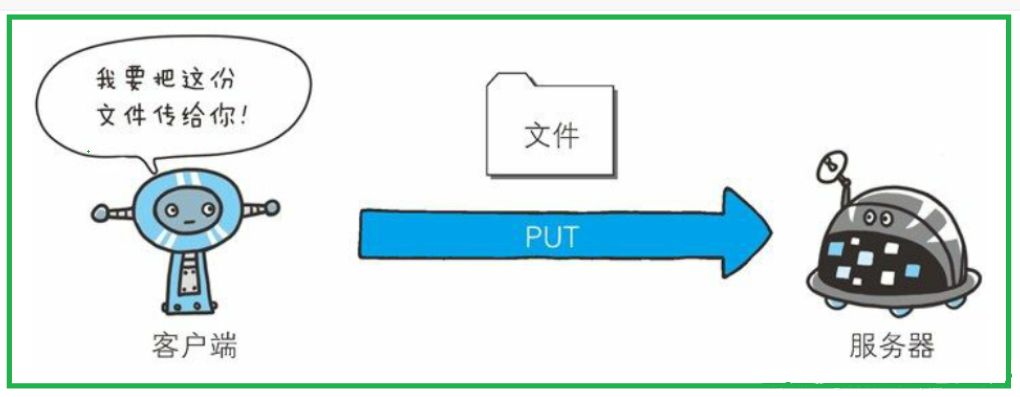
- PUT⽅法⽤来传输⽂件。就像 FTP 协议的⽂件上传⼀样,要求在请求报⽂的主体中包含⽂件内容,然后保存到请求 URI 指定的位置
- 但是,鉴于 HTTP/1.1 的 PUT ⽅法⾃身不带验证机制,任何⼈都可以上传⽂件 , 存在安全性问题,因此⼀般的 Web ⽹站不使⽤该⽅法
7.4 HEAD方法:获得报文首部
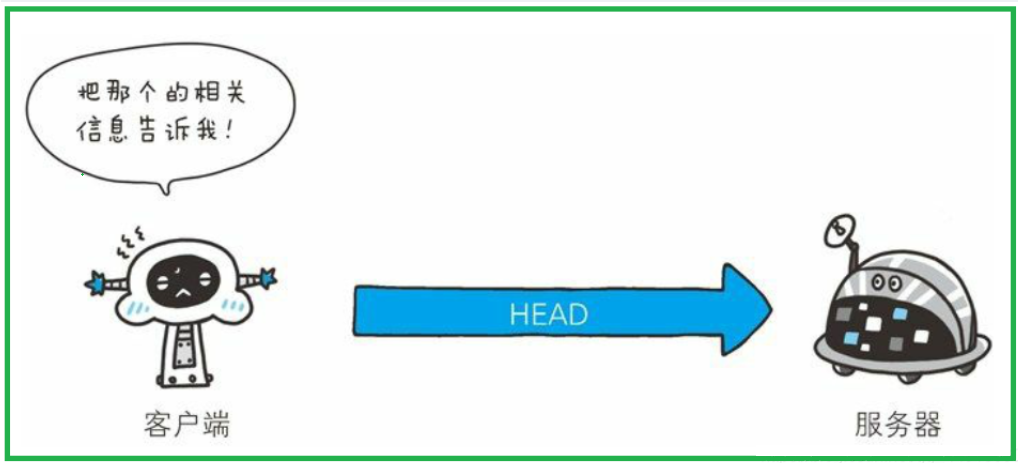
- HEAD方法和GET方法一样,只是不返回报文主体部分,用来确认资源的有效性
- HEAD方法是不需要服务端返回响应正文的,使用HEAD方法,服务器只会返回响应首行、响应报头、空行
7.5 DELETE方法:删除文件
-
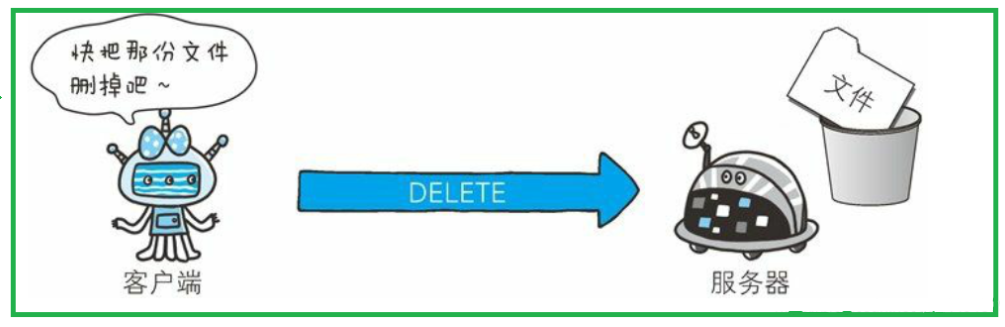
DELETE ⽅法⽤来删除⽂件,是与 PUT 相反的⽅法
-
但是, HTTP/1.1 的 DELETE ⽅法本身和 PUT ⽅法⼀样不带验证机制,所以⼀般的 Web ⽹站也不使⽤ DELETE ⽅法
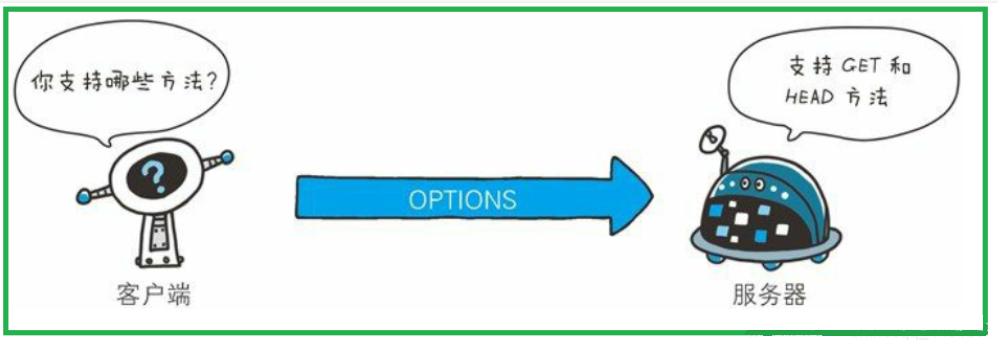
7.6 OPTIONS:询问支持的方法
-
OPTIONS方法用来查询针对请求URL指定的资源支持的方法
-
即客户端询问当前服务器都支持哪些方法
8.HTTP协议请求方法总结
9.HTTP状态码理解
9.1 HTTP状态码类别
9.2 常见成功状态码(2XX)
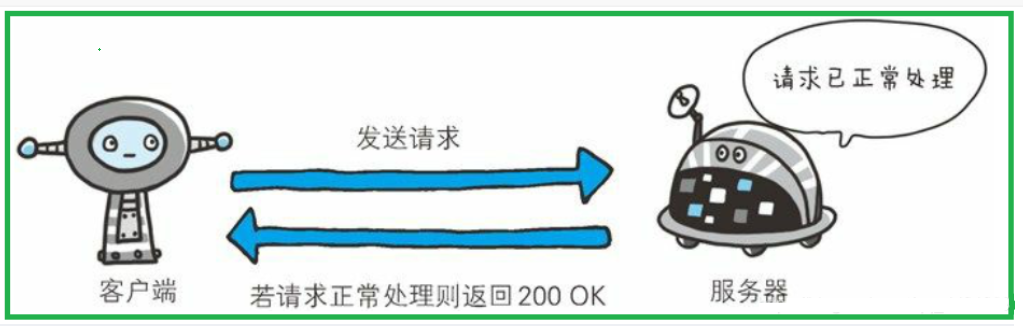
2XX 的响应结果表明请求被正常处理了
常见的三种成功状态码:200、204、206
-
200(OK)状态码
- 表示从客户端发来的请求在服务器端被正常处理了
-
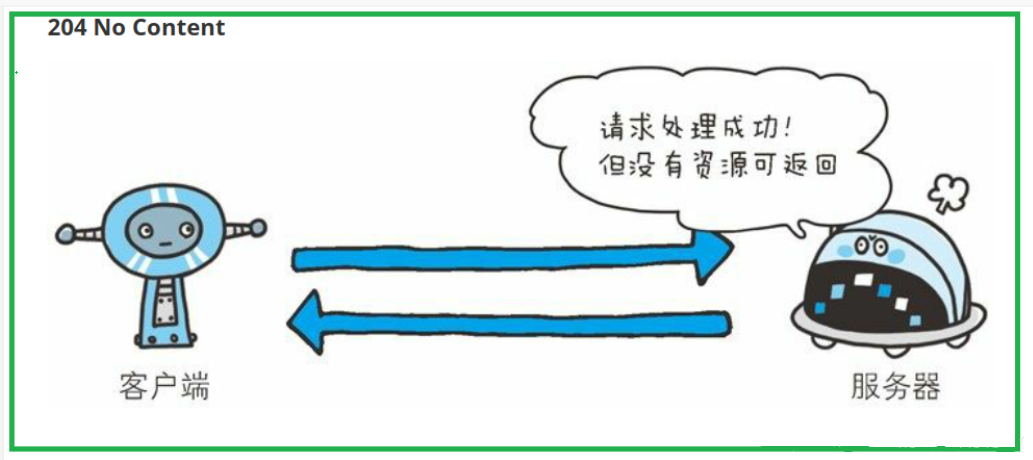
204(No Content)状态码
- 请求处理成功了,但没有资源要返回(没有正文)
-
206(Partial Content)状态码
- 客户端进行了范围请求,服务器成功执行这一请求

9.3 常见重定向状态码(3XX)
3XX响应结果表明浏览器需要进行附加操作以完成请求
常见的三种重定向状态码:301、302、303
-
301(Moved Permanently) 永久性重定向
- 告诉服务器某一资源已被永久放在另一个URL中,以后访问需访问新的URL
-
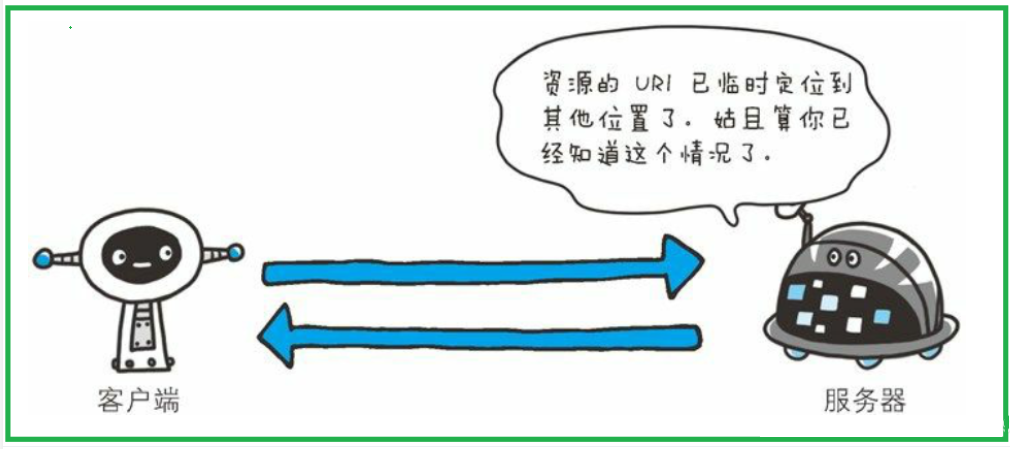
302(Found) 临时性重定向
- 客户端要请求的资源临时被放到新的服务器中,以后访问此资源还是访问这个旧服务器
-
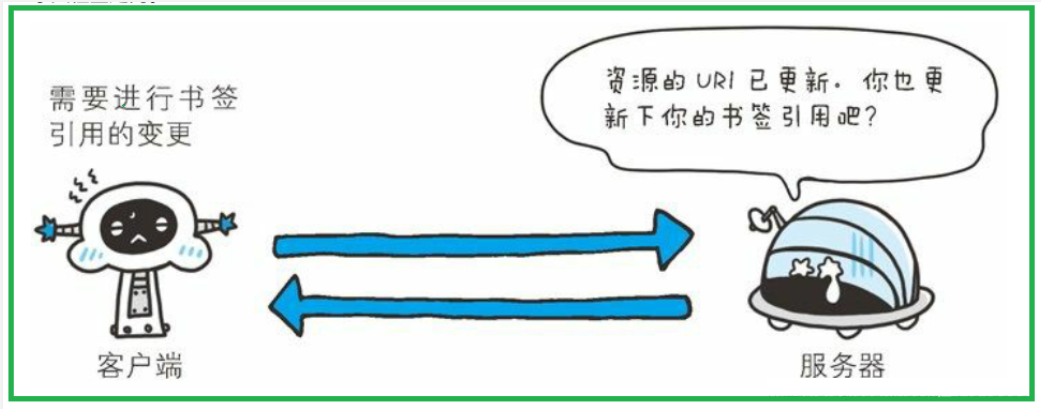
303(See Other)
- 要访问的资源已经更新了

9.4 常见客户端错误状态码(4XX)
4XX的响应结果表明客户端发生错误
常见四种客户端错误状态码:400、401、403、404
-
400(Bad Request)
- 服务端无法理解客户端发送的请求:请求格式错误

-
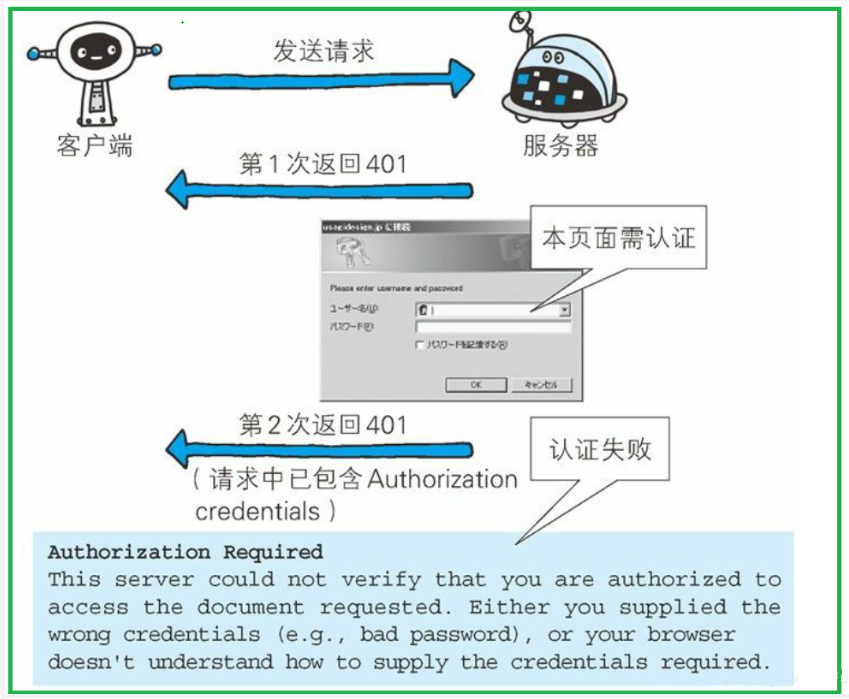
401(Unauthorized)
- 认证失败
-
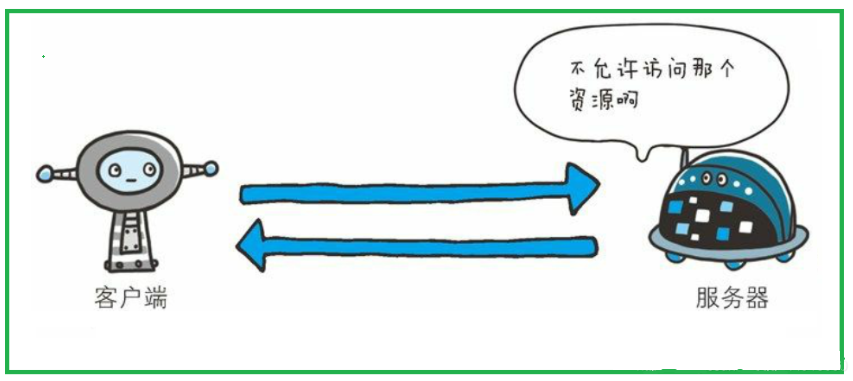
403(Forbidden)
- 客户端请求访问某一资源被服务器拒绝了,即没有资格(权限)访问某一资源
-
404(Not Found)
- 服务器无法找到客户端请求的资源

9.5 常见的服务器错误状态码(5XX)
5XX的响应结果表明服务器处理请求出错
常见的两种服务器错误状态码:500、503
-
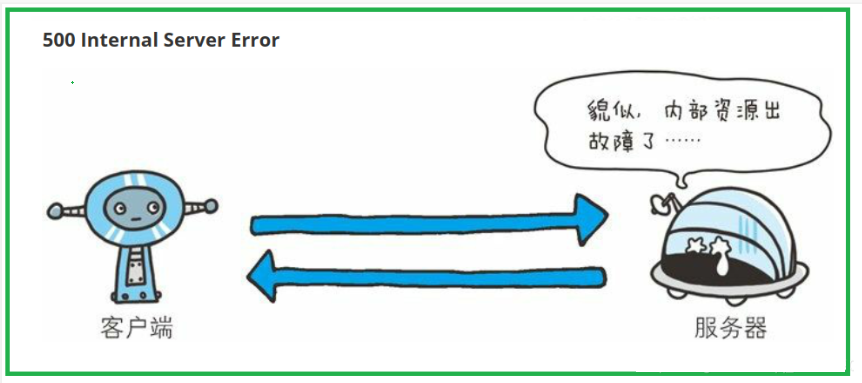
500(Internal Server Error)
- 该状态码表明服务器端在执行请求时发生错误,也有可能是Web应用存在的bug或某些临时的故障
-
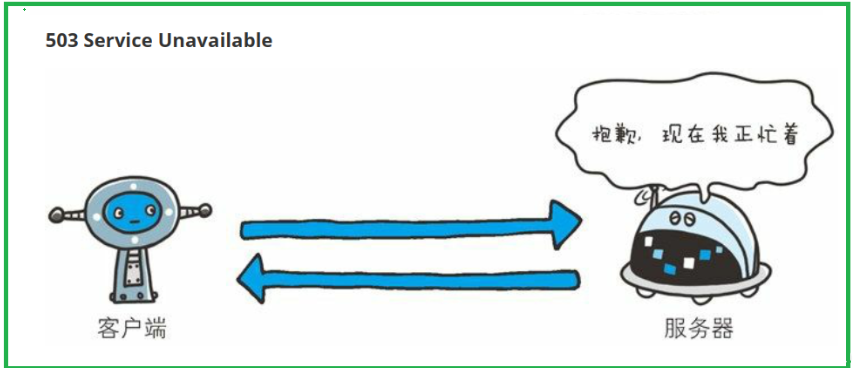
503(Service Unavailable)
- 服务器繁忙
10.HTTP常见Header
HTTP常见的Header如下:
Content-Type:数据类型(text/html等)Content-Length:正文的长度Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上User-Agent:声明用户的操作系统和浏览器的版本信息Referer:当前页面是哪个页面跳转过来的Location:搭配3XX状态码使用,告诉客户端接下来要去哪里访问Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能
其中:cookie和session都是用来跟踪浏览器用户身份的会话方式
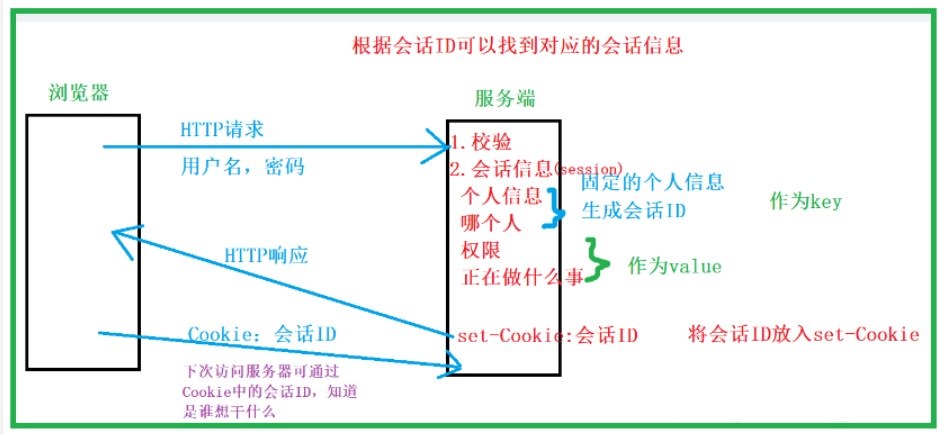
Cookie的工作原理:
- 浏览器端第一次发送请求到服务器端
- 服务器端创建Cookie,该Cookie中包含用户的信息,然后将该Cookie发送到浏览器端
- 浏览器端再次访问服务器端时会携带服务器端创建的Cookie
- 服务器端通过Cookie中携带的数据区分不同的用户
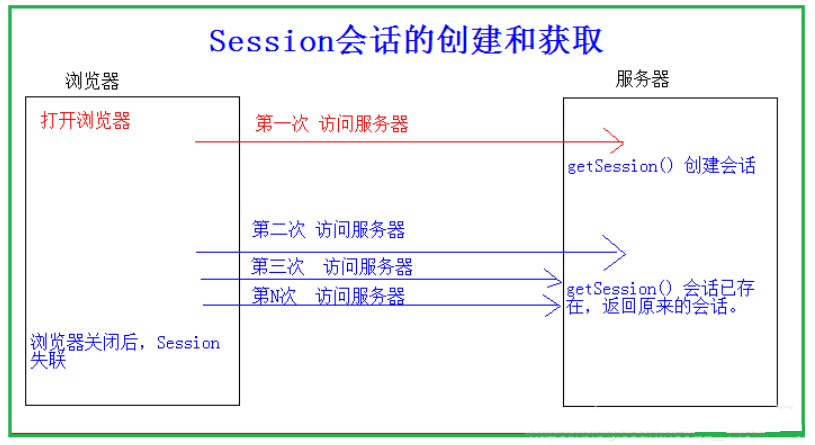
Session的工作原理:
- 浏览器端第一次发送请求到服务器端,服务器端创建一个Session,同时会创建一个特殊的Cookie(name为JSESSIONID的固定值,value为session对象的ID),然后将该Cookie发送至浏览器端
- 浏览器端发送第N(N>1)次请求到服务器端,浏览器端访问服务器端时就会携带该name为JSESSIONID的Cookie对象
- 服务器端根据name为JSESSIONID的Cookie的value(sessionId),去查询Session对象,从而区分不同用户。name为JSESSIONID的Cookie不存在(关闭或更换浏览器),返回1中重新去创建Session与特殊的Cookiename为JSESSIONID的Cookie存在,根据value中的SessionId去寻找session对象value为SessionId不存在(Session对象默认存活30分钟),返回1中重新去创建Session与特殊的Cookievalue为SessionId存在,返回session对象


Cookie和Session的区别对比:
cookie数据存放在客户的浏览器上,session数据放在服务器上cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用sessionsession会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
11.HTTP协议与浏览器的交互
我们用一个代码来演示:比如实现一个最简单的HTTP服务器, 只在网页上输出 “hello world”; 只要我们按照HTTP协议的要求构造数据, 就很容易能做到
#include<iostream>
#include<sys/types.h>
#include<sys/socket.h>
#include<errno.h>
#include<stdio.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sstream>
using namespace std;
int main()
{
int sockfd=socket(AF_INET,SOCK_STREAM,0);
if(sockfd<0)
{
perror("socket");
return 0;
}
struct sockaddr_in addr;
addr.sin_port=htons(20000);
addr.sin_family=AF_INET;
addr.sin_addr.s_addr=inet_addr("172.16.0.9");
int ret=bind(sockfd,(struct sockaddr*)&addr,sizeof(addr));
if(ret<0)
{
perror("bind");
return 0;
}
ret=listen(sockfd,1);
if(ret<0)
{
perror("listen");
return 0;
}
struct sockaddr_in cli_addr; //客户端的协议栈
socklen_t cli_addrlen=sizeof(cli_addr);
int newsockfd=accept(sockfd,(struct sockaddr*)&cli_addr,&cli_addrlen);
if(newsockfd<0)
{
perror("accept");
return 0;
}
cout<<"accept new connect form client:"<<inet_ntoa(cli_addr.sin_addr)<<" "<<ntohs(cli_addr.sin_port);
while(1)
{
char buf[1024]={0};
ssize_t recv_size=recv(newsockfd,buf,sizeof(buf)-1,0);
if(recv_size<0)
{
perror("recv");
continue;
}
else if(recv_size==0)
{
cout<<"peer close connect!"<<endl;
close(newsockfd);
return 0;
}
cout<<"buf:"<<buf<<endl;
memset(buf,'\0',sizeof(buf));
string body="<html><h1>hello world</h1></html>";
stringstream ss;
ss<<"HTTP/1.1 200 OK\r\n";
ss<<"Content-Type: text/html\r\n";
ss<<"Content-length: "<<body.size()<<"\r\n";
// ss<<"HTTP/1.1 302 Found\r\n";
// ss<<"Location: https://www.baidu.com/\r\n";
ss<<"\r\n";
send(newsockfd,ss.str().c_str(),ss.str().size(),0);
send(newsockfd,body.c_str(),body.size(),0);
}
close(sockfd);
return 0;
}
编译, 启动服务. 在浏览器中输入 http://[ip]:[port], 就能看到显示的结果 “Hello World”
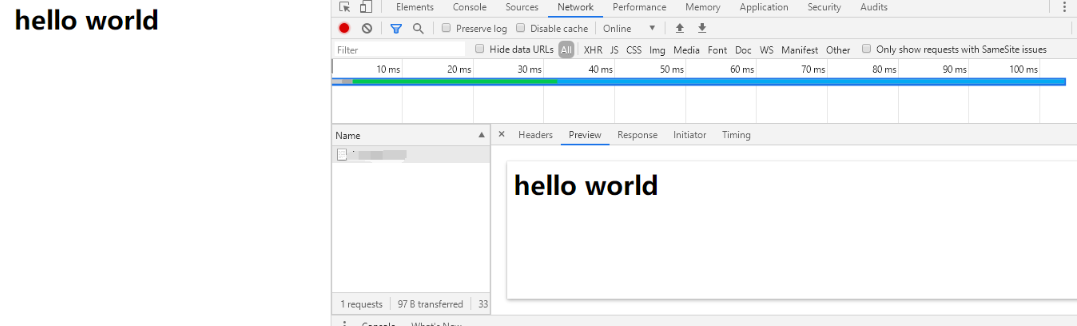
此处我们使用 9090 端口号启动了HTTP服务器. 虽然HTTP服务器一般使用80端口,但这只是一个通用的习惯. 并不是说HTTP服务器就不能使用其他的端口号
把返回的状态码改成303等, 看浏览器上分别会出现什么样的效果
//修改上面的代码77-79行如下:
ss<<"HTTP/1.1 302 Found\r\n";
ss<<"Location: https://www.baidu.com/\r\n";
ss<<"\r\n";
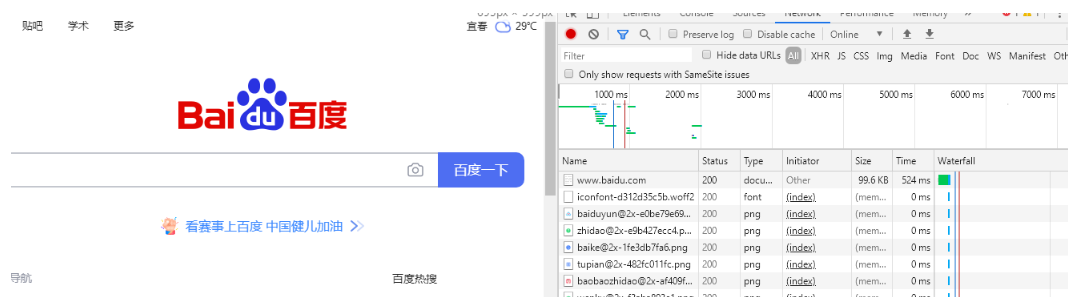
这里jiu发生了重定向的结果!
补充:HTTP与HTTPS协议的区别
- 早期很多公司刚起步的时候,使用的应用层协议都是HTTP,而HTTP无论是用GET方法还是POST方法传参,都是没有经过任何加密的,因此早期很多的信息都是可以通过抓包工具抓到的,也就体现了HTTP的不安全性
- 为了解决这个问题,于是出现了HTTPS协议,HTTPS实际就是在应用层和传输层协议之间加了一层加密层(SSL与TLS),这层加密层本身也是属于应用层的,它会对用户的个人信息进行各种程度的加密。HTTPS在交付数据时先把数据交给加密层,由加密层对数据加密后再交给传输层
- 当然,通信双方使用的应用层协议必须是一样的,因此对端的应用层也必须使用HTTPS,当对端的传输层收到数据后,会先将数据交给加密层,由加密层对数据进行解密后再将数据交给应用层

- 此时数据只有在用户层(应用层)是没有被加密的,而在应用层往下以及网络当中都是加密的,这就叫做HTTPS
扩展:对称加密与非对称加密
加密的方式可以分为对称加密和非对称加密:
对称加密:采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密非对称加密:采用公钥和私钥来进行加密和解密,用其中一个密钥进行加密就必须用另一个密钥进行解密- 一般而言,对称加密的效率比非对称加密的效率高,少用一个密钥嘛






![[数据库]复习杂项](https://img-blog.csdnimg.cn/20200314110339802.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lreV9feHVrYWk=,size_16,color_FFFFFF,t_70#pic_center)
![[附源码]计算机毕业设计Python保护濒危动物公益网站(程序+源码+LW文档)](https://img-blog.csdnimg.cn/384c83cb93e048a6a9dd01bfa32b7907.png)