一、CPU的是如何运行程序的?
本文知识来源小林Coding阅读整理思考,原文链接请见以下:
https://xiaolincoding.com/os/1_hardware/how_cpu_run.html#图灵机的工作方式
问题引入
- 程序的执行过程?例如 1+2 的具体过程是怎么样的?【→ 网络请求过程,HTTP浏览器输入url的具体执行流程】
- 位宽的概念:32、64位的OS、CPU的对比、区别,和计算能力的关系?
注:分析事物,先理清它的逻辑链,即行为,通过行为分析属性,抓本质原理。
相关知识点:
- CPU的组成、计算机组成原理;汇编语言(HCL
学习目标:
- 理解软硬件的结合,软件的抽象过程
- 在理解CPU的执行过程后,去分析 JVM 抽象层,再加入该抽象层之后,Java程序的执行逻辑又怎么样的? CPU作为最底层的工作助手,复用性最高,它是怎么去为上层保证可靠的服务,怎么去实现缓存一致性等问题(后续章节,此处暂不探讨),可借鉴至上层软件使用。
计算机的工作原理
- 图灵机
- 冯洛伊曼机
图灵机
https://baike.baidu.com/item/图灵机/2112989?fr=aladdin
为解决复杂繁琐、重复的计算问题【基本需求,计算机最初的目标也只是科学计算,随着后续的发展,抽象出来了丰富的应用软件、系统软件】,**1936年,**图灵提出来了 图灵机 模型 【只是理论的模型】,现代的计算机也根据该模型进行构建。
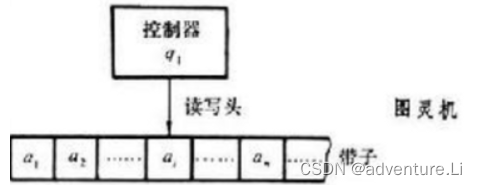
它有一条无限长的纸带【对应现在的内存,抽象人类的记忆存储】,纸带分成了一个一个的小方格,每个方格有不同的颜色【去模拟数据\程序,抽象人类捕捉到世界的信息】。有一个机器头【读写,抽象人类操作信息的工具,读→眼睛\耳朵获取信息,写→分析并记忆与脑海】在纸带上移来移去。机器头有一组内部状态,还有一些固定的程序。在每个时刻,机器头都要从当前纸带上读入一个方格信息,然后结合自己的内部状态查找程序表,根据程序输出信息到纸带方格上,并转换自己的内部状态,然后进行移动。
基本组成:
- 纸带
- 机器头
- 机器头内部状态,固定抽象,程序表,比如存储单元、控制单元以及运算单元
思考:
- 为什么图灵设计的是单纸带、读写头?且无限长、有序地去移动?
来源于时间序列?人们生活在一个线性的时间序列之中,纸带好比一个无限的时间流失,每一个格子则是该时刻捕获到的信息。而图灵机抽象的是 个人 而非人群(人群对比若系统网络、机器集群等,共同协作)。
- 机器头,读写 抽象?
读写是操作信息的行为抽象,而数据结构操作可在此基础上进行抽象为CRUD,主要是对写的抽象、细化。结合思考 并发控制,为什么读 同一资源 可以同时,互不影响,写 则可能存在影响。物体的状态性?同一时刻只能存在一种状态?【来源于物理世界】
多个粒子可以同时处于多个不同状态,一个粒子不同时刻也可以处于多个不同状态,但一个粒子同一时刻只能处于一种状态,即状态不能叠加。
1+2程序示例
- 读写头读取纸带上的数据,分析数据,获取信息。【对于该种数字运行,可抽象为数字和运算符,机器头内部会根据不同的数据做出对应的处理,例如数字则读取写入即可,遇到运算符则,进行控制器处理,再调用相关的运算器进行运算,得出结果 再写回】
- 思考,结合编译原理,去思考 token流,词法、语法、语义构建,如何通过字符编码等技术将0、1计算抽象为丰富的应用程序。
冯洛伊曼机
https://baike.baidu.com/item/冯·诺依曼机/59369302?fromModule=search-result_lemma
**1945年,时隔9年。**冯诺依曼和其他计算机科学家们提出了计算机具体实现的报告,其遵循了图灵机的设计。在图灵机基础上,提出了指令与数据都以二进制式储存在存储器里;指令根据其储存的顺序执行,采用电子元件结构设计【数字电路、模拟电路的发展,电的发展,传播快,易处理】。
关键组成:
- 运算器、控制器
- 存储器
- IO(输入输出设备)
存储器
此处对应的应该则是内存。
- 程序和数据(类型划分,指令、数据)都是存储在内存,存储的区域是线性的
- 基本单位:字节(对应8bit),每一个字节都对应一个内存地址。【字、字节、bit的概念】
对于32位计算机与64位计算机,字的大小往往不同。
32位计算机:1字=32位=4字节,64位计算机:1字=64位=8字节
注:
- 理解 存储对指令、数据的类型划分,与编程语言 对 类型体系的划分(例如int,long)【个人理解,该种语言一般为强语言类型,静态语言,减少运行时检查开销,方便内存变量布局】
- 对内存、存储数据量大小的敏感度(一般现有计算机 内存 4-32G 、磁盘上TB,对应用软件程序大小,DB文件存储大小,数据规模)
- 对不同存储层次访问速度的、时间敏感度
CPU
https://baike.baidu.com/item/中央处理器/284033?fromModule=lemma_search-box&fromtitle=CPU&fromid=120556
- 运算器(加法器、
- 控制器
- 寄存器(IR,通用寄存器) - 汇编则可直接操作
CPU的工作分为以下 5 个阶段:取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。
总线
- 地址总线,用于指定 CPU 将要操作的内存地址;
- 数据总线,用于读写内存的数据;
- 控制总线,用于发送和接收信号【读写命令】,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
IO
线路位宽、CPU位宽概念
由总线的概念可知,计算机操控数据通过数据总线进行传输数据,控制总线进行控制,一条线则只能读写一位数据(由于冯洛伊曼设计采用电路结构,二进制设计,高低电平去表示1,0)。
CPU一次性可操作的数据量则为 min(2线路位宽,2CPU位宽)
对于线路64bit,CPU32bit,去操作 64位的数据,那么则需要进行拆分地位操作。
常识补充:
https://baike.baidu.com/item/64位操作系统/9195739?fromModule=search-result_lemma
简单的说x86代表32位操作系统 x64代表64位操作系统。如果你的CPU是双核以上,那肯定支持64位操作系统了。如果你的电脑内存大于4G,那就要用64位的系统了,因为32位的Windows 7也好,Vista也好,最大都只支持3.25G的内存。而64位的windows 7最大将支持128G的内存
CPU的执行过程
CPU的工作分为以下 5 个阶段:取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。
- 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
- 第二步,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- 第三步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
程序(1+2)的指令过程
关键步骤
- 程序(1+2),以高级语言程序(C++)为例,机器是不识别字符串的,需通过编译器进行编译处理(涉及编译原理知识) ,加工为汇编语言(对于Java类,涉及JVM中间层处理,略有区别)
- 汇编语言 可直接操作硬件,寄存器,但是汇编语言也是辅助符号,机器也不能直接识别,机器只能识别 01二进制,于是 在通过 汇编器 产生为 目标程序(二进制),但是此刻还存在一些文件引入问题,还不能直接执行,
- 最后链接器,进行可执行文件,执行

编译器做了什么?
程序编译过程中,编译器通过分析代码【词法、语法 — flex,bison,DB数据库设计分析SQL时,则采用相应的词法、语法分析工具去构建】,发现 1 和 2 是数据,于是程序运行时,内存会有个专门的区域来存放这些数据,这个区域就是「数据段」。
- 划分 数据段 和 正文段 ;将数据和指令进行分离,并将其内容放在对应位置【指令间隔由类型情况去区分】
- 设置程序计数器的地址
指令、指令集
指令集,就是CPU中用来计算和控制计算机系统的一套指令的集合,而每一种新型的CPU在设计时就规定了一系列与其他硬件电路相配合的指令系统
形成汇编程序之后,由于CPU的不同,采用的指令集也可能不同,汇编语言也会有所不同。
CPU的操作也是由厂商制定时设计好了\选用了相应的指令集(也需要一套API集合),供上层使用,而上层的操作系统采用汇编进行对CPU的直接操作,OS再对其进行进一步封装,提炼抽象出OS一套的API,供上层应用、系统级软件使用。这样一过程则是层层封装、抽象的过程。
→任何问题都能通过加一个抽象层解决!
指令集
- 复杂指令集
- 精简指令集
RISC指令集是以后高性能CPU的发展方向。它与传统的CISC(复杂指令集)相对。相比而言,RISC的指令格式统一,种类比较少,寻址方式也比复杂指令集少。使用RISC指令集的体系结构主要有ARM、MIPS。MIPS 指令集是最早实现商用的精简指令集(RISC)之一
MIPS 的指令是一个 32 位的整数,高 6 位代表着操作码,表示这条指令是一条什么样的指令,剩下的 26 位不同指令类型所表示的内容也就不相同,主要有三种类型R、I 和 J。
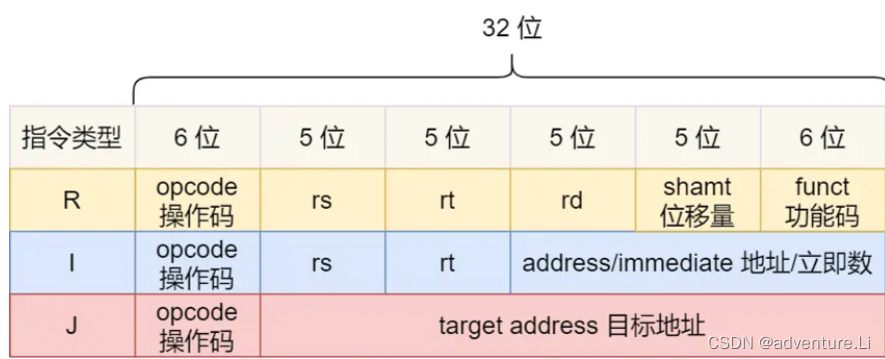
- R 指令,用在算术和逻辑操作,里面有读取和写入数据的寄存器地址。如果是逻辑位移操作,后面还有位移操作的「位移量」,而最后的「功能码」则是再前面的操作码不够的时候,扩展操作码来表示对应的具体指令的;
- I 指令,用在数据传输、条件分支等。这个类型的指令,就没有了位移量和功能码,也没有了第三个寄存器,而是把这三部分直接合并成了一个地址值或一个常数;
- J 指令,用在跳转,高 6 位之外的 26 位都是一个跳转后的地址;
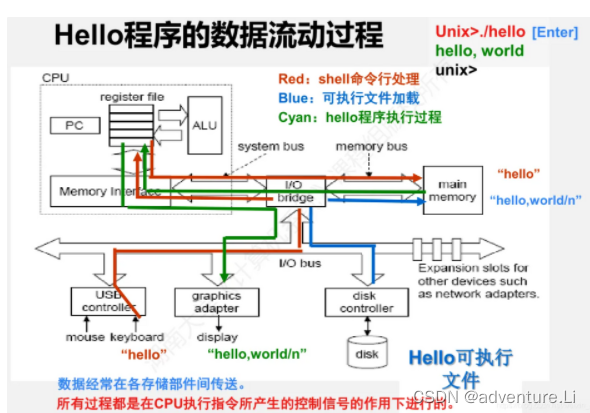
程序执行速度
时钟周期时间就是我们前面提及的 CPU 主频,主频越高说明 CPU 的工作速度就越快,例如的电脑的 CPU 是 2.4GHz,这里的 2.4 GHz 就是电脑的主频,时钟周期时间就是 1/2.4G。ns级别
可写一段程序去分析一下指令数,以及看看运行的情况。
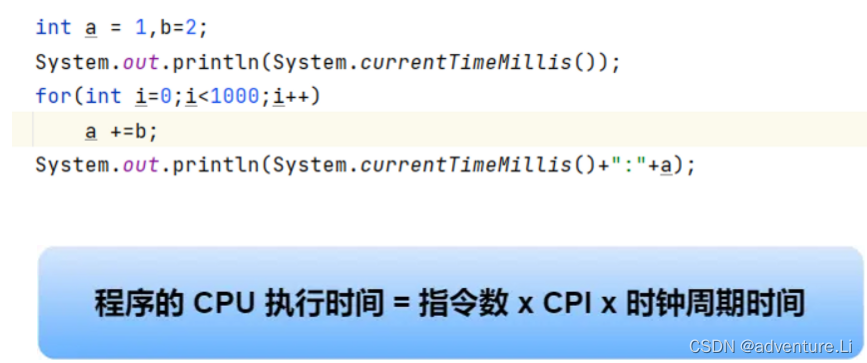
指令数 x 每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)= CPU时钟指令周期数
- 指令数,表示执行程序所需要多少条指令,以及哪些指令。这个层面是基本靠编译器来优化,毕竟同样的代码,在不同的编译器,编译出来的计算机指令会有各种不同的表示方式。【对于软件开发工程师,则需要考虑时间复杂度,尽可能少的执行指令,减少指令数】
- 每条指令的平均时钟周期数 CPI,表示一条指令需要多少个时钟周期数【】,现代大多数 CPU 通过流水线技术(Pipeline),让一条指令需要的 CPU 时钟周期数尽可能的少;
- 时钟周期时间,表示计算机主频,取决于计算机硬件。有的 CPU 支持超频技术,打开了超频意味着把 CPU 内部的时钟给调快了,于是 CPU 工作速度就变快了,但是也是有代价的,CPU 跑的越快,散热的压力就会越大,CPU 会很容易奔溃。





![[数据库]复习杂项](https://img-blog.csdnimg.cn/20200314110339802.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lreV9feHVrYWk=,size_16,color_FFFFFF,t_70#pic_center)
![[附源码]计算机毕业设计Python保护濒危动物公益网站(程序+源码+LW文档)](https://img-blog.csdnimg.cn/384c83cb93e048a6a9dd01bfa32b7907.png)