深入jvm字节码
- 1.深入剖析class文件结构
- 1.1初探class文件
- 1.2 class文件结构解析
- 1.2.1 魔数
- 1.2.2 版本号
- 1.2.3 常量池
- 1.2.4 Access flags
- 1.2.5 this_class,super_name,interfaces
- 1.2.6 字段表
- 1.2.7 方法表
- 1.2.8 属性表
- 1.3使用javap查看类文件
- 2.字节码基础
- 2.1字节码概述
- 2.2java虚拟机栈和栈帧
- 2.3 字节码指令
- 2.3.1 加载和存储指令
- 2.3.2 操作数栈指令
- 2.3.3 运算和类型转换指令
- 2.3.4 控制转移指令
- 2.3.5 for循环字节码实现原理
- 2.3.6 Switch-case底层实现原理
- 2.3.7 string的switch-case实现原理
- 2.3.8 i++ 和 ++i 字节码原理
- 2.3.9 try-cache-finaly 字节码原理
- 2.3.10 try-with-resources 字节码原理
- 2.3.11 对象相关字节码指令
- 3.字节码进阶
- 3.1 方法调用指令
- 3.1.1 invokestatic
- 3.1.2 invokevirtual
- 3.1.3 invokespecial
- 3.1.4 invokeinterface
- 3.1.5 invokedynamic指令
- 3.2 Lambda表达式原理
- 3.3 泛型字节码
- 3.4 Synchronized的实现原理
- 3.5 反射的实现原理
- 3.5.1 反射源码分析
- 3.5.1 infation机制
- 4.javac编译原理
- 4.1 javac源码调试
- 4.2 javac的七个阶段
- 4.2.1 parse阶段
- 4.2.2 enter阶段
- 4.2.3 process阶段
- 4.2.4 attribute阶段
- 4.2.5 flow节点
- 4.2.6 desugar
- 4.2.7 generate阶段
- 5.从字节码的角度看Kotlin语言
- 6.ASM和javassist字节码操作工具
- 6.1.1 ASM Core Api核心类
- 6.1.2 ASM操作字节码示例
- 6.1.2.1.访问方法和字段
- 6.1.2.2 新增字段
- 6.1.2.3 新增方法
- 6.1.2.4 修改方法内容
- 6.1.2.4 AdiviceAdpater使用
- 6.1.2.5 给方法加上 try-cache
- 7.java Instrumentation 原理
- 7.1 Instrumentation简介
- 7.2 Instrumentation与 -javaagent启动参数
- 7.3 JVM Attach API介绍
- 7.4 JVM Attach API的基本使用
- 8.JSR 269 插件注解化处理原理
- 8.1 自定义 AbstractProcessor
- 8.2 抽象语法树API
- 8.3 自定义简单Lombok
- 9.软件破解和防破解
- 1.软件破解
- 2.软件防止破解
1.深入剖析class文件结构
1.1初探class文件
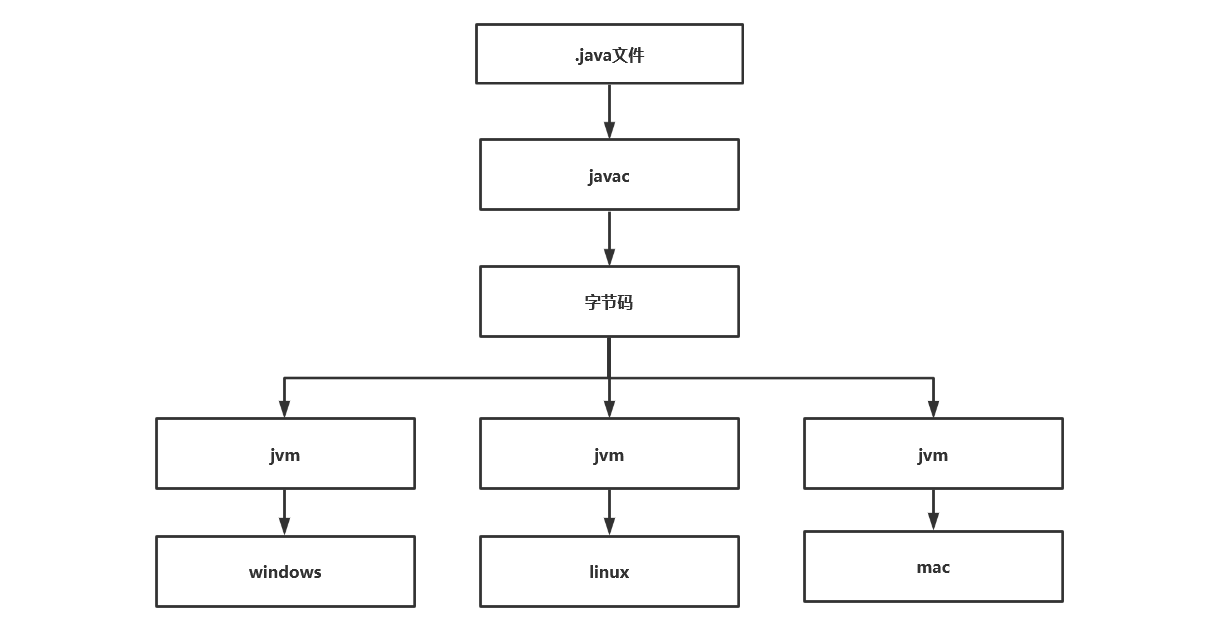
java声称一次编译,到处运行,这与他的jvm实现有关,java语言是和平台无关的,是可以跨操作系统的,但是jvm缺不能,不同的jvm帮我们屏蔽了不同的操作系统,java语言编写的同一份代码,不同的jvm虚拟机实现,会帮我们编译成不同的二进制文件。
下面我们一输出hello world 来开始我们的class文件探索之旅。
public class Hello {
public static void main(String[] args) {
System.out.println("hello world");
}
}
使用javac 命令编译 Hello.java即可得到class文件,然后再用16进制显示文件内容即可得到下面的内容。可以使用 EditPlus.exe 然后查看的时候选择utf-8的编码格式,然后点击菜单栏中的HX即可查看Hello.class的16进制文件内容。
CA FE BA BE 00 00 00 34 00 1D 0A 00 06 00 0F 09
00 10 00 11 08 00 12 0A 00 13 00 14 07 00 15 07
00 16 01 00 06 3C 69 6E 69 74 3E 01 00 03 28 29
56 01 00 04 43 6F 64 65 01 00 0F 4C 69 6E 65 4E
75 6D 62 65 72 54 61 62 6C 65 01 00 04 6D 61 69
6E 01 00 16 28 5B 4C 6A 61 76 61 2F 6C 61 6E 67
2F 53 74 72 69 6E 67 3B 29 56 01 00 0A 53 6F 75
72 63 65 46 69 6C 65 01 00 0A 48 65 6C 6C 6F 2E
6A 61 76 61 0C 00 07 00 08 07 00 17 0C 00 18 00
19 01 00 0B 68 65 6C 6C 6F 20 77 6F 72 6C 64 07
00 1A 0C 00 1B 00 1C 01 00 49 63 6F 6D 2F 73 6D
61 72 74 70 6C 67 2F 67 6F 75 72 64 2F 63 6C 6F
75 64 2F 67 67 66 77 2F 64 65 63 6C 61 72 65 2F
6F 66 66 69 63 65 4E 65 77 49 6E 73 75 72 65 64
2F 73 65 72 76 69 63 65 2F 69 6D 70 6C 2F 48 65
6C 6C 6F 01 00 10 6A 61 76 61 2F 6C 61 6E 67 2F
4F 62 6A 65 63 74 01 00 10 6A 61 76 61 2F 6C 61
6E 67 2F 53 79 73 74 65 6D 01 00 03 6F 75 74 01
00 15 4C 6A 61 76 61 2F 69 6F 2F 50 72 69 6E 74
53 74 72 65 61 6D 3B 01 00 13 6A 61 76 61 2F 69
6F 2F 50 72 69 6E 74 53 74 72 65 61 6D 01 00 07
70 72 69 6E 74 6C 6E 01 00 15 28 4C 6A 61 76 61
2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 29 56 00
21 00 05 00 06 00 00 00 00 00 02 00 01 00 07 00
08 00 01 00 09 00 00 00 1D 00 01 00 01 00 00 00
05 2A B7 00 01 B1 00 00 00 01 00 0A 00 00 00 06
00 01 00 00 00 08 00 09 00 0B 00 0C 00 01 00 09
00 00 00 25 00 02 00 01 00 00 00 09 B2 00 02 12
03 B6 00 04 B1 00 00 00 01 00 0A 00 00 00 0A 00
02 00 00 00 0A 00 08 00 0B 00 01 00 0D 00 00 00
02 00 0E
1.2 class文件结构解析
java虚拟机规定用u1,u2,u4三种数据结构来表示1,2,4字节无符号整数,相同若干条数据用集合表的形式来存储,表是一个变长结构,由表长度的表头n和紧随的n个数据组成,class文件采用类似c语言的结构体进行存储,如下图所示:
字节码结构:
| 类型 | 名称 | 说明 | 长度 | 数量 |
|---|---|---|---|---|
| u4 | magic | 识别Class文件 | 4byte | 1 |
| u2 | minor_version | 服版本号 | 2byte | 1 |
| u2 | major_version | 主版本号 | 2byte | 1 |
| u2 | constant_pool_count | 常量池计数器 | 2byte | 1 |
| cp_info | constant_pool[constant_pool_count-1] | 常量池表 | N byte | constant_pool_count-1 |
| u2 | access_flags | 访问标识 | 2byte | 1 |
| u2 | this_class | 类索引 | 2byte | 1 |
| u2 | super_class | 父类索引 | 2byte | 1 |
| u2 | interfaces_count | 接口计数器 | 2byte | 1 |
| u2 | interfaces[interfaces_count] | 接口索引集合 | 2byte | interfaces_count |
| u2 | fields_count | 字段计数器 | 2byte | 1 |
| filed_info | fields[fields_count] | 字段表 | N byte | fields_count |
| u2 | methods_count | 方法计数器 | 2byte | 1 |
| method_info | methods[methods_count] | 方法表 | N byte | methods_count |
| u2 | attributes_count | 属性计数器 | 2byte | 1 |
| attribute_info | attributes[attributes_count] | 属性表 | N byte | attributes_count |
classFile{
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count]
u2 attributes_count;
attribute_info attributes[attributes_count];
}
class文件由下面10个部分组成:

1.2.1 魔数
前4个字节表示是否是java类型的class类型文件。我们通常根据文件名来区分文件的类型,比如: .txt,.png,.jpg等使用文件名来区分文件类型这显然不靠谱,因为文件名可以随意被更改,但是使用文件内容来做文件类型的区分是怎么做到的呢?java使用前4个字节表示java文件,CA FE BA BE 就表示这是一个java文件,也就是class文件的标识。如果clas文件不是以 CA FE BA BE 开头的那么在虚拟机加载的时候,就会抛出,java.lang.ClassFoormatError错误。
1.2.2 版本号
4~7 字节,表示类的版本 00 34(十进制52) 表示是 Java 8,次版本在这里没有体现,版本兼容,jdk版本向下兼容
我们需要注意的是开发环境中的jdk版本和线上环境的jdk版本是否一致
虚拟机jdk颁布为1.k(k>=2)时,对应的Class文件格式的版本范围为:45.0-44+k.0(含两端)
| jdk版本 | 主版本(10进制) |
|---|---|
| JDK 1.1 | 45 |
| JDK 1.2 | 46 |
| JDK 1.3 | 47 |
| JDK 1.4 | 48 |
| JDK 1.5 | 49 |
| JDK 1.6 | 50 |
| JDK 1.7 | 51 |
| JDK 1.8 | 52 |
1.2.3 常量池
| Constant Type | Value | 描述 | |
|---|---|---|---|
| CONSTANT_Class | 7 | 类或接口的符号引用 | |
| CONSTANT_Fieldref | 9 | 字段的符号引用 | |
| CONSTANT_Methodref | 10 | 类中方法的符号引用 | |
| CONSTANT_InterfaceMethodref | 11 | 接口中方法的符号引用 | |
| CONSTANT_String | 8 | 字符串类型字面量 | |
| CONSTANT_Integer | 3 | 整形字面量 | |
| CONSTANT_Float | 4 | 浮点字面量 | |
| CONSTANT_Long | 5 | 长整形字面量 | |
| CONSTANT_Double | 6 | 双精度浮点字面量 | |
| CONSTANT_NameAndType | 12 | 字段或方法的符号引用 | |
| CONSTANT_Utf8 | 1 | UTF-8编码的字符串 | |
| CONSTANT_MethodHandle | 15 | 表示方法句柄 | |
| CONSTANT_MethodType | 16 | 标志方法类型 | |
| CONSTANT_InvokeDynamic | 18 | 表示一个动态方法调用点 |
在版本号之后跟的是常量池的数量。已经若干个常量池表项。常量池计数器从1开始而不是从0开始。常量池表项中用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入运行时常量池。常量池计数器就是用于记录常量池中有多少项。
为了满足后面某些常量指向常量池的索引值的数据在特定情况下需要表达 不引用常量池中的任何一项,这种情况索引值用0来表示
常量池大小:常量池是class文件中第一个出现变长的结构,既然是池,也就有大小,常量池由2个字节表示,假设常量池大小为N,常量池真正的有效索引号是1N9,也就是说如果 constant_pool_count为10,那么constant_pool数组的有效索引是1~9,0属于特殊索引,可供特殊情况下使用。
常量池项:最大包含N-1个元素,为什么是最多呢?long和double常量会占用2个索引位置,如果常量池中包含了这两种类型的元素,实际的常量池项的元素个数比N-1要小。
1.2.4 Access flags
紧随常量池区域后的是访问标记,用于标识一个类是否是 final,abstract等,由2个字节来表示,总共有16个标记为可以使用,目前只使用了其中8个如下图表格所示:
| 访问标记名 | 十六进制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 1 | 是否为public |
| ACC_FINAL | 10 | 是否为final |
| ACC_SUPER | 20 | 不在使用 |
| ACC_INTERFACE | 200 | 标识是类还是接口 |
| ACC_ABSTRACT | 400 | 是否为abstract |
| ACC_SYNTHETIC | 1000 | 编译器自动生成,不是用户源代码编译而成 |
| ACC_ANNOATATION | 2000 | 是否为注解类 |
| ACC_ENUM | 4000 | 是否为枚举类 |
1.2.5 this_class,super_name,interfaces
这三部分用来确认继承关系,this_class标识类索引,super_name表示直接父类的索引,interfaces表示类或者接口的直接父接口。
1.2.6 字段表
紧随接口索引表之后的是字段表,类中所有的字段都会被存储到这个集合中,包括静态字段和非静态字段。字段表也是一个变长的结构,filed_counts表示field的数量接下来的fileds表示字段集合,共有fileds_count个。
字段结构分为4个部分,第一部分表示access_flags表示字段访问标识,用来表示权限修饰符和static,final等,第二部分是name_index,用来表示字段名,指向常量字符串中的常量,第三部分description_index是字段描述符的索引,指向常量池中的字符串常量,最后的attributes_count,attribute_info表示属性的个数和属性集合。

**字段访问标记:**字段与类一样也有访问标记,而且比类的访问标记更加丰富共有9种。
| 访问标记名 | 十六进制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 0X0001 | 声明为public |
| ACC_PRIVATE | 0X0002 | 声明为private |
| ACC_PROTECET | 0X0004 | 声明为protected |
| ACC_STATIC | 0X0008 | 声明为static |
| ACC_FINAL | 0X0010 | 声明为final |
| ACC_VOLATILE | 0X0040 | 声明为volatile,解决内存可见性问题 |
| ACC_TRANSINENT | 0X0080 | 声明为transient表示不需要被序列化 |
| ACC_SYNTHETIC | 0X1000 | 编译器自动生成,不是用户源代码编译而成 |
| ACC_ENUM | 0X4000 | 表示这是一个枚举变量 |
字段描述符: 在jvm中定义一个int类型的变量不是用字符串int表示,而是用一个更加精简的字母I表示。
根据数据类型不同,分为三类:
- 原始类型:byte int char float double,long
- 引用类型:用L来进行表示,为了防止多个引用连续出现混乱,都用;号来进行分割比如String的描述符为:Ljava/lang/String;
- jvm使用 ‘[’ 来表示是一个数组,如果是多多维数组,也只是多加了一个 ‘[’ 而已。比如 String[ ] 的表示方式为:‘[ Ljava/lang/String;’
字段描述符映射表:
| 描述符 | 类型 |
|---|---|
| B | byte 类型 |
| C | char 类型 |
| D | double 类型 |
| F | float 类型 |
| I | int 类型 |
| J | long类型 |
| S | short 类型 |
| Z | boolean 类型 |
| L | 引用 类型 “L” + 对象全限定名+‘;’ |
| [ | 一维数组 |
**字段属性:**与字段相关的属性包括Constant Value ,Synthetic,Deprecated,Runtime-VisibleAnnotation和RuntimeInVsibleAnnotations和RuntimeInvisibleAnnotation这6个,比较常见的是Constant Value 属性,用来表示一个常量字段的值,具体在1.2.8在详细解释。
1.2.7 方法表
方法表和前面介绍的字段表非常类似,类中定义的所有方法都在这个表中,这里的表也是一个变长结构。
方法结构: 方法结构分为4个部分,第一部分表示access_flags表示字段访问标识,用来表示权限修饰符和static,final等,第二部分是name_index,用来表示方法名,指向常量字符串中的常量,第三部分description_index是方法描述符的索引,指向常量池中的字符串常量,最后的attributes_count,attribute_info表示属性的个数和属性集合。包含了很多有用的信息,比如方法内部字节码。
**方法访问标记:**方法访问标记类型更加丰富一共有12种
方法访问标记映射表:
| 方法标记 | 十六机制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 0X0001 | 声明为 public |
| ACC_PRIVATE | 0X0002 | 声明为 private |
| ACC_PROTECTED | 0X0004 | 声明为 protected |
| ACC_STATIC | 0X0008 | 声明为 static |
| ACC_FINAL | 0X0010 | 声明为 final |
| ACC_SYNCHRONIZED | 0X0020 | 声明为 synchronized |
| ACC_BRIGDE | 0X0040 | 声明为 birdge 方法 ,由编译器生成 |
| ACC_VARAGS | 0X0080 | 方法包含可变长参数,如: String args … |
| ACC_NATIVE | 0X0100 | 声明为 native |
| ACC_ABSTRACT | 0X0400 | 声明为 abstract |
| ACC_STRICT | 0X0800 | 声明为 strict ,表示使用IEEE-754规范精确浮点数 |
| ACC_STNTHETIC | 0X1000 | 这个方法由编译器自动生成,不是用户源代码生成 |
方法名与描述符:
紧随方法访问标记的是方法索引 name_index,指向常量池中的CONSTANT_Utf8_info类型的常量字符串,方法索引描述descriptor_index也是指向常量池中CONSTANT_Utf8_info类型的常量字符串,比如方法 Object foo(int i,double d,Thread t)的描述符为:“(IDLjava/lang/Thread;)Ljava/lang/Object;”
方法属性表: 方法属性表是method_info结构的最后一部分,前面介绍了方法的访问标记和方法签名,还有一些重要的细节没有出现,比如方法声明抛出的异常,方法的字节码,方法是否标记为deprecated等,属性表就是用来存储这些信息的,与方法相关的属性很多,其中比较重要的就是code和Exceptions属性,其中细节在1.2.8中进行详细介绍。
1.2.8 属性表
在方法表之后class结构的最后一部分是属性表,属性出现的地方比较广泛,不止出现在字段和方法中,在顶层class中也会出现,相比于常量池固定的14中类型,属性表类型更加灵活,不同的java虚拟机实现厂商可以自定义属性。
与其他结构类似,属性表使用2个字节表示属性的个数 attributes_count ,接下来是若干属性项的集合,可以看做为一个数组,每个属性项的attribute_info结构如下图所示:
attribute_info{
u2 attribute_name_index;
u2 attribute_length;
u1 info[attribute_length];
}
attribute_name_index是指向常量池的索引,根据这个索引可以得到attribute的名字,接下来两部分表示info数组长度和byte内容。虚拟机预定义了20多种属性,接下来我们挑选字段表相关的ConstantValue属性和方法表相关的COde进行介绍。
1.ConstantValue: ConstantValue属性出现在field_info中,用来表示静态变量的初始值,他的结构如下图所示:
ConstantValue_attribute{
u2 attribute_name-index;
u4 attribute_length;
u2 constantValue_index;
}
其中attribute_name-index是指向常量池只能值为“ConstantValue”的字符串常量项,attribute_length固定大小值为2,因为接下来的内容只会有2个字节大小,constantValue_index指向常量池中具体索引值,根据变量类型不同,constantvlaue_index指向不同类型的常量,如果变量为long类型,则 constant_index 指向CONSTANT_Loing_info类型的常量项。
2.code属性: code属性是class文件中最重要的组成部分,他包含了方法的字节码,除native和abstract方法以外,每个method都有一个code属性。他的结构如下:
Code_attribute{
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max locals;
u2 code_length;
u1 code[cdoe_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 cache_type;
}
exception_table[exception_table_length];
u2 attribute_count;
attribute_info attributes[attributes_count];
}
下面开始介绍code各个属性字段含义:
1.属性名索引(attribute_name_index):占用2个字节,指向常量池中CONSTANT_Utf8_info常量,表示属性的名字。
2.属性长度 (attribute_length):占用2个字节,表示属性值长度大小。
3.操作数栈最大深度(max_stack):方法执行的任意期间操作数栈的深度不会超过这个值,他的计算规则是有入栈指令,stack增加,有出栈指令stack减少,在整个过程中,stack的最大值就是max_stack,减少和增加一般都是1,但也有列外,LONG和DOUBLE相关指令入站会加2,VOID相关指令则为0;
4.局部变量表大小(max_locals):他的值并不等于方法中所有的局部变量数之和,当一个局部作用域结束,他内部局部变量占用的位置就可以被接下来的局部变量重复使用。
5.code_length和code用来表示字节码相关的信息,其中code_length表示字节码指令长度,占用4个字节,code是长度为code_length的字节数组,存储真正的字节码指令。
6.exception_table_length和exception_table用来表示代码内部的异常信息,如我们属性的tr-catch语法就会生成对应异常表,exception_table_length表示接下来exception_table数组的长度,每个异常项包含四个部分,可以用下面的结构表示。‘
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 cache_type;
}
其中start_pc,end_pc,handler_pc,都是指向code自己数组的所有值,start_Pc和end_pc表示异常处理覆盖的字节码开始和结束的位置,是嘴比右开区间[start_pc,end_pc]包含start_pc不包含end_pc,handler_pc表示异常处理handler在code自己数组的起始位置,异常被捕获以后该跳转到何处继续执行。
catch_type表示需要处理的catch异常是什么类型,他用2个字节码表示,执行常量池中类型为CONSTANT_Class_info的常量项,如果catch_type等于0,则表示可以处理任意异常,可以用来实现finally。
当jcm执行到这个方法[start_pc,end_pc]范围内的字节码发生异常时,如果发生的异常是这个catch_type对应的异常或者是他的子类,则跳转到code自己数组handler_pc处继续处理。
7.attributes_count和attributes[]用来表示Code属性相关的附属属性,java虚拟机规定Code属性只能包含中四种可选属性:LineNumberTable,LocalVaribleTable,LocalVariableTypeTable,StackMaoTable,以LineNumberTable为例 ,LineNumberTable用来存放源码的行号和字节码偏移量之间对应的关系,属于调试信息,不是雷文娟运行的必须属性,默认情况下都会生成,如果没有这个属性,那么在调试时就没有办法在源码中设置断点,也没有办法在代码中抛出异常的是在堆栈错误信息中显示出错的行号。
1.3使用javap查看类文件
让我们直接去阅读16进制的class文件难度比较大,而且不利于阅读,我们可以使用jdk提供的javap工具进行查看编译后的class字节码。他的使用方式如下:
javap [options ]
用法: javap <options> <classes>
其中, 可能的选项包括:
-help --help -? 输出此用法消息
-version 版本信息
-v -verbose 输出附加信息
-l 输出行号和本地变量表
-public 仅显示公共类和成员
-protected 显示受保护的/公共类和成员
-package 显示程序包/受保护的/公共类
和成员 (默认)
-p -private 显示所有类和成员
-c 对代码进行反汇编
-s 输出内部类型签名
-sysinfo 显示正在处理的类的
系统信息 (路径, 大小, 日期, MD5 散列)
-constants 显示最终常量
-classpath <path> 指定查找用户类文件的位置
-cp <path> 指定查找用户类文件的位置
-bootclasspath <path> 覆盖引导类文件的位置
2.字节码基础
2.1字节码概述
java虚拟机的指令由一个字节长度的操作码(opcode)和紧随其后的可选操作数构成。如下所示:
<opcode> [<operand1>,operand2]
比如将整形常量是100的压入栈顶的指令是 bipush 100 ,其中bipush是操作码,100是操作数,字节码的由来是操作码的长度用一个字节来表示,因为操作码的长度只有一个字节长度,这使编译后的字节码文件非常小巧紧凑,但是也现在了JVM字节码指令最多只能有256个,目前已经使用超过200个。
大部分字节码指令是和操作类型相关的,比如ireturn 指令用于返回一个int类型的数据,dreturn指令用于反会一个double类型的数据,freturn用于返回一个float类型的数据,这也使得实际的指令类型远小于200个。
字节码使用大端序进行表示(Big-Endian)表示,即高位在前,低位在后的方式,比如字节码 getfield 00 02,表示的是 getfield 0x00<<8 | 0x02(getfield #2)
字节码并不是cpu的机器码,而是一种介于源码和机器码中的一种抽象表示方法,不过字节码可以通过JIT技术可以进一步翻译为机器码。
根据字节码的不同作用,大概可以分为如下几类:
- 加载和存储指令:比如iload将一个int类型的整形数值从局部变量表中加载到操作数栈。
- 控制转移指令:比如条件分支 ifeq;
- 对象操作:比如创建对象指令 new
- 方法调用:比如invokevirtual指令用于调用对象实例的方法;
- 运算指令和类型转换:比如加法指令 iadd
- 线程同步:monitorenter 和 monitorexit 这两条指令用于支持Synchronized关键字
- 异常处理: athrow 显示抛出异常;
2.2java虚拟机栈和栈帧
java虚拟机实现的方式比较常见的有2种,分别是基于栈和寄存器,典型的虚拟机Hotspot就是基于栈的方式进行实现的,而典型的寄存器虚拟机有LuaVm和Goole开发的Android虚拟机DalvikVM;
两者有什么不同呢?举一个两数相加的列子
java源代码如下:
int my_add(int a,int b){
return a+b;
}
使用javap查看字节码如下:
0: iload_1
1: iload_2
2: iadd
3: ireturn
实现相同的功能,使用lua代码如下:
local function my_add(a,b)
return a+b;
end
使用 luac -l -L -v -s test.lua查看lua的字节码如下所示:
[1] ADD R2 E0 R1 ; R2:Ro+R1
[2] Return R2 2 ; return R2
[3] Return R0 1 ; return
基于寄存器和栈的架构各有有点:
- 基于栈:栈的指令级的优点是移值性更好,指令更短,但不能随机访问堆栈中的元素,完成相同功能所需的指令数一般会比基于寄存器架构的要多,需要频繁的入站和出栈,不利于代码优化。
- 基于寄存器:寄存器的指令集的有点是速度快,可以充分利用寄存器,有利于程序做速度优化,但操作数需要显示指定,指令比较长。
栈帧: 在写递归程序的过程中,如果忘记写递归结束条件,就会出现 堆栈溢出异常,
Hotspot JVM是基于栈的虚拟机,每一个线程都有一个虚拟机栈来存储栈帧,创建和销毁,当线程请求分配的栈容量超过java虚拟机栈运行的最大深度时,就会抛出StackOverflowError异常,可以使用JVM命令虚拟机参数来调整栈深度大小,-Xss来指定栈的大小。
每个线程都有自己的java虚拟机栈,一个线程应用会拥有多个java虚拟机栈,每个栈都拥有自己的栈帧,栈帧是用于支持虚拟机进行方法调用和执行的数据结构,每个栈帧都拥有自己的局部变量表,操作数栈和常量池的引用
局部变量表: 每个栈帧内都包含一个局部变量表,局部变量表的大小是在编译期间就已经确定,对应class文件中方法Code属性的Max_locals字段,java虚拟机会根据max_locals字段来分配方法执行过程所需要分配的最大局部变量表容量。
操作数栈: 每个栈帧内都包含一个称为操作数栈先进后出的(LIFO),栈的大小同样也是在编译期间确定,java虚拟机提供很多字节码指令用于从局部变量表或者对实例对象的字段中复制常量或者变量到操作数栈,也有一些指令用于从操作数栈取走数据。
2.3 字节码指令
2.3.1 加载和存储指令
加载(load)和存储(store)相关的指令是使用的醉频繁的指令。分为load类和store和常量加载这三种。
- load类指令是将局部变量加载到操作数栈,比如iload_0是将局部变量表中下标为0的int类型变量加载到操作数栈上,根据不同类型的变量,还有lload,fload,dload,aload这些指令,分别表示,long,float。double,引用类型的变量。
- store类指令是将栈顶的数据存储到局部变量表中,比如istore_0,将操作数栈顶的元素存储到局部变量表中下标为0的位置,这个位置元素类型为int,根据不同类型变量的指令还有Istore,fstore,dstore,astore这些指令。
- 常量加载相关的指令,常见的有const类,push类,Ldc类,const,push类指令是将常量值直接加载到操作数栈顶,毕业iconst_0表示将整数为0加载到操作数栈上,bipush 100 是将int类型常量100加载到操作数栈上,Ldc指令是从常量池中加载对应的常量到操作数栈顶,比如Ldc#10是将常量池中下标为10的常量加载到操作数栈上。
- 为什么同时int类型常量,需要加载怎么多类型呢?这是因为使字节码更加紧凑,int了下常量是根据n的范围,使用指令如下规则:
- 若n在[-1,5]的范围内,使用iconst_n的方式,操作数栈和操作码加在一起是只占用一个自己,比如iconst_2对应的十六进制为0x05,-1比较特殊,对应的指令为iconst_m(0x02)。
- 若n在[-128-127]范围内,使用的是bipush的方式,操作数和操作码一起只占用2个字节,比如n的子为100(0x64)时 bipush 100 对应十六进制1位0x1064;
- 若n在[-32768,32767]范围内,使用sipush的方式操作数和操作码占用三个字节,比如n的值为1024(0x0400)时,对应的字节码为sipush 1024 (0x110400)
- 若n在其他范围内,使用Ldc的方式,将这范围内整数放在常量池中,比如n的值为40000时,40000被存储到常量池中,加载的指令为Ldc#i,i为常量池的索引值。
存储指令列表:
| 指令名称 | 描述 |
|---|---|
| aconst_null | 将null入栈到栈顶 |
| iconst_ml | 将int类型值-1加入到栈顶 |
| iconst_ | 将int类型值n(0-5)加入到栈顶 |
| Iconst_ | 将int类型值n(0-1)加入到栈顶 |
| fconst_ | 将int类型值n(0-2)加入到栈顶 |
| dconst_ | 将int类型值n(0-1)加入到栈顶 |
| bipush | 将范围在-128-127的整形值压入栈顶 |
| sipush | 将范围在-32768-32767的整形值压入栈顶 |
| Ldc | 将int,float,string类的常量值从常量池压入栈顶 |
| Ldc_w | 作用同Ldc,不同的是Ldc操作码是一个字节,Ld_w操作码是2个字节,即Ldc只能寻255个常量池索引值,ldc_w能寻址2个字节长度,可以覆盖常量池所有值。 |
| Ldc_2w | ldc_2w将long或double类型常量值从常量池压栈到栈顶,它的寻址范围为2个字节 |
| load | 将局部变量表中特定位置的类型为T的变量到栈顶,T可以是:i,l,f,d,a;分别表示int,long,float ,double,引用类型 |
| load | 将局部变量表中下标为n(0-3)的类型为T的变量加载到栈上T可以是:i,l,f,d,a; |
| aload | 将指定数组中指定位置的类型为T的变量加载到栈顶上,T可以为:i,l,f,d,a,b,c,s;分别表示:int,long,float,double,引用类型,boolean或者byte,char,short类型 |
| store | 将栈顶为T类型的数据存储到局部变量表的指定位置,T可以是:i,l,f,d,a; |
| store_ | 将栈顶为T类型的数据存储到局部变量表中下标为n(0-3)的位置,T可以为:i,l,f,d,a; |
| astore | 将栈顶为T的数据存储到数组的指定位置,T可以为:i,l,f,d,a,b,c,s;分别表示:int,long,float,double,引用类型,boolean或者byte,char,short类型 |
2.3.2 操作数栈指令
常见的操作数栈指令由 pop。dup,swap;
操作数栈指令:
| 指令名称 | 字节码 | 描述 |
|---|---|---|
| pop | 0x57 | 将栈顶的元素出栈,费long和double |
| pop2 | 0x58 | 弹出栈顶的一个long或double类型的数据或者两个其他类型的数据 |
| dup | 0x59 | 复制栈顶的元素并压入栈顶,后面创建对象的时候会使用到dup指令 |
| dup_x1 | 0x5A | 复制栈顶数据并将复制的数据插入到栈顶第二个元素之下 |
| dup_x2 | 0x5B | 复制栈顶数据并将复制的数据插入到栈顶第三个元素之下 |
| dup2 | 0x5C | 复制两个栈顶数据,并且将复制的数据入栈 |
| dup2_x1 | 0x5D | 复制两个栈顶数据,并将复制的数据插入到栈顶第二个元素之下 |
| dup2_x2 | 0x5E | 复制两个栈顶数据,并将复制的数据插入到栈顶第三个元素之下 |
| swap | 0x5F | 用于交互两个栈顶的元素; |
2.3.3 运算和类型转换指令
java中加减乘除相关的语法都是应用如下指令来进行实现的。
运算指令:
| operator | int | long | float | double |
|---|---|---|---|---|
| + | iadd | ladd | fadd | dadd |
| - | isub | lsub | fsub | dsub |
| / | idiv | ldiv | fdiv | ddiv |
| * | imul | lmul | fmul | dimul |
| % | ierm | lerm | ferm | derm |
| negate(-) | ineg | lneg | fneg | dneg |
| & | iand | land | - | - |
| | | ior | lor | - | - |
| ^ | ixor | lxor | - | - |
2.3.4 控制转移指令
| 指令名称 | 字节码 | 描述 |
|---|---|---|
| ifeq | 0x99 | 如果栈顶int类型变量等于0,则跳转 |
| ifne | 0x9A | 如果栈顶int类型变量不等于0,则跳转 |
| iflt | 0x9B | 如果栈顶int类型变量小于0,则跳转 |
| ifgt | 0x9C | 如果栈顶int类型变量大于等于0,则跳转 |
| ifge | 0x9D | 如果栈顶int类型变量大于0,则跳转 |
| ifle | 0x9E | 如果栈顶int类型变量小于等于0,则跳转 |
| if_icmpeq | 0x9F | 比较两个int类型的变量,相等则跳转 |
| if_icmpne | 0xA0 | 比较两个int类型的变量,不相等则跳转 |
| if_icmplt | 0xA1 | 比较两个int类型的变量,如果小于跳转 |
| if_icmpge | 0xA2 | 比较两个int类型的变量,如果大于等于跳转 |
| if_icmpgt | 0xA3 | 比较两个int类型的变量,如果大于跳转 |
| if_icmple | 0xA4 | 比较两个int类型的变量,如果小于等于则跳转 |
| if_acmpeq | 0xA5 | 比较两个引用类型的变量,如果相等则跳转 |
| if_acmpne | 0xA6 | 比较两个引用类型的变量,如果不相等则跳转 |
| goto | 0xA7 | 无条件跳转 |
| tableswitch | 0xAA | switch 条件跳转,case紧凑的情况下使用 |
| lookupswitch | 0xAB | switch 条件跳转,case稀疏的情况下使用 |
2.3.5 for循环字节码实现原理
纵观所有的字节码指令,都没有for相关的指令,那么for循环是如何实现的呢?我们以一个求个的案例进行观察,代码如下所示:
public int sum (int[] numbers){
int sum = 0;
for (int number : numbers) {
sum+= number;
}
return sum;
}
对应的字节码如下所示:我们主要是看方法中的code字节码
public int sum(int[]);
descriptor: ([I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=7, args_size=2
0: iconst_0
1: istore_2
2: aload_1
3: astore_3
4: aload_3
5: arraylength
6: istore 4
8: iconst_0
9: istore 5
11: iload 5
13: iload 4
15: if_icmpge 35
18: aload_3
19: iload 5
21: iaload
22: istore 6
24: iload_2
25: iload 6
27: iadd
28: istore_2
29: iinc 5, 1
32: goto 11
35: iload_2
36: ireturn
LineNumberTable:
line 38: 0
line 39: 2
line 40: 24
line 39: 29
line 42: 35
LocalVariableTable:
Start Length Slot Name Signature
24 5 6 number I
0 37 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
0 37 1 numbers [I
2 35 2 sum I
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 11
locals = [ class compass/token/pocket/com/service/jvm/SaveAccept, class "[I", int, class "[I", int, int ]
stack = []
frame_type = 248 /* chop */
offset_delta = 23
MethodParameters:
Name Flags
numbers
为了方便理解,这里我们先把局部变量表画出来。

解析过程:
第0~1行,把常量0加载到操作数栈上,随后通过istore_2指令将0出栈赋值给局部变量表下标为2的元素。也就是说给 sum初始化值。
第2~9行是用来初始化循环遍历控制
第2~3行:aload_1的指令是加载局部变量表中下标为1的变量参数numbers,astore_3指令的作用是将栈顶的元素存储到局部变量表中下标为3的位置上,记为 $array。
第4~6行:计算数组的长度,astore_3加载 a r r a y 到栈顶,调用 a r r a y l e n g t h 指令获取数组长度到栈顶,随后调用 i s t o r e 4 将数组长度存储到局部变量表的第 4 个索引位置,也就是 array到栈顶,调用arraylength指令获取数组长度到栈顶,随后调用istore 4 将数组长度存储到局部变量表的第4个索引位置,也就是 array到栈顶,调用arraylength指令获取数组长度到栈顶,随后调用istore4将数组长度存储到局部变量表的第4个索引位置,也就是len;
第8~9行:初始化数组遍历下班的初始值,iconst_0将0加载到操作数栈上,随后使用istore_5将栈顶的0存储到局部变量表中的第5个位置这个局部变量是数组循环下标初始值,记作 $i;
第1132是真正的循环体:1115判断是循环是否可以继续;第32是直接重新进行循环判断,如果不成立就把局部变量表中的下标为2的元素加载到操作数栈上,return回去。我们主要是介绍循环是如果实现,循环体内的细节我们就不在一一赘述,大家可以参照之前所讲的指令进行分析,循环的实现核心就是 使用判断指令 + goto 无条件指令字节码进行实现的。
2.3.6 Switch-case底层实现原理
Switch-case是怎么实现的呢?难道是通过一条一条的if else来实现的么?这显然不是,这样的话效率太低了,通过分析,我可以知道tableswitch和lookupswitch两条指令来生成switch语句的编译代码,为什么会有两条不同的指令来实现呢?我们接下来就是一探究竟。
代码如下所示:
public int chooseNear(int i){
switch ( i ){
case 100:return 0;
case 101:return 1;
case 104:return 4;
default: return -1;
}
}
字节码如下所示:
public int chooseNear(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=1, locals=2, args_size=2
0: iload_1
1: tableswitch { // 100 to 104
100: 36
101: 38
102: 42
103: 42
104: 40
default: 42
}
36: iconst_0
37: ireturn
38: iconst_1
39: ireturn
40: iconst_4
41: ireturn
42: iconst_m1
43: ireturn
LineNumberTable:
line 46: 0
line 47: 36
line 48: 38
line 49: 40
line 50: 42
LocalVariableTable:
Start Length Slot Name Signature
0 44 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
0 44 1 i I
StackMapTable: number_of_entries = 4
frame_type = 36 /* same */
frame_type = 1 /* same */
frame_type = 1 /* same */
frame_type = 1 /* same */
MethodParameters:
Name Flags
i
细心的同学可能已经发现了,代码中并没有102,103但是在字节码中缺出现了102,103,原因是编译器会对case做分析,如果case的值比较紧凑,中间有少量断层或者没有断层,会采用tableswitch来实现,如果case有大量的断层,那么会使用lookupswitch来实现。采用虚假case补齐的方式可以实现在O(1)时间复杂度的情况下查找到对应的case;
现在我们来看lookupswitch的情况,如果断层,比较大,采用的还是用虚假case补齐的方式,那么最后就会导致class文件大小增大,可能会导致程序加载过慢的情况。
代码如下:
public int chooseNear(int i){
switch ( i ){
case 1:return 0;
case 10:return 1;
case 100:return 4;
default: return -1;
}
}
对应的字节码如下:
public int chooseNear(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=1, locals=2, args_size=2
0: iload_1
1: lookupswitch { // 3
1: 36
10: 38
100: 40
default: 42
}
36: iconst_0
37: ireturn
38: iconst_1
39: ireturn
40: iconst_4
41: ireturn
42: iconst_m1
43: ireturn
LineNumberTable:
line 46: 0
line 47: 36
line 48: 38
line 49: 40
line 50: 42
LocalVariableTable:
Start Length Slot Name Signature
0 44 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
0 44 1 i I
StackMapTable: number_of_entries = 4
frame_type = 36 /* same */
frame_type = 1 /* same */
frame_type = 1 /* same */
frame_type = 1 /* same */
MethodParameters:
Name Flags
i
为了避免断层太大,虚假case过多的情况,可以使用 lookupswitch 来进行处理,他的键值都是经过排序的,在查找上可以使用二分查找法,时间复杂度在O(log n);
2.3.7 string的switch-case实现原理
通过前面的知识,我们已经知道switch-case依据case的稀疏程度,分别由tableswitch和lookupswitch来实现,但是这个两个指令都只支持整数类型,那么String的case值是如何进行实现的呢?
java代码:
public int chooseNear(String name){
switch ( name ){
case "java":return 100;
case "pho":return 200;
case "javascript":return 300;
default: return 400;
}
}
字节码:
public int chooseNear(java.lang.String);
descriptor: (Ljava/lang/String;)I
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=2
0: aload_1
1: astore_2
2: iconst_m1
3: istore_3
4: aload_2
5: invokevirtual #6 // Method java/lang/String.hashCode:()I
8: lookupswitch { // 3
110967: 58
3254818: 44
188995949: 72
default: 83
}
44: aload_2
45: ldc #7 // String java
47: invokevirtual #8 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
50: ifeq 83
53: iconst_0
54: istore_3
55: goto 83
58: aload_2
59: ldc #9 // String pho
61: invokevirtual #8 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
64: ifeq 83
67: iconst_1
68: istore_3
69: goto 83
72: aload_2
73: ldc #10 // String javascript
75: invokevirtual #8 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
78: ifeq 83
81: iconst_2
82: istore_3
83: iload_3
84: tableswitch { // 0 to 2
0: 112
1: 115
2: 119
default: 123
}
112: bipush 100
114: ireturn
115: sipush 200
118: ireturn
119: sipush 300
122: ireturn
123: sipush 400
126: ireturn
LineNumberTable:
line 46: 0
line 47: 112
line 48: 115
line 49: 119
line 50: 123
LocalVariableTable:
Start Length Slot Name Signature
0 127 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
0 127 1 name Ljava/lang/String;
StackMapTable: number_of_entries = 8
frame_type = 253 /* append */
offset_delta = 44
locals = [ class java/lang/String, int ]
frame_type = 13 /* same */
frame_type = 13 /* same */
frame_type = 10 /* same */
frame_type = 28 /* same */
frame_type = 2 /* same */
frame_type = 3 /* same */
frame_type = 3 /* same */
MethodParameters:
Name Flags
name
细心的同学可能已经发现,我们不是只有一个switch怎么生成了两个switch指令呢?而且一个是tableswitch还有一个是lookupswitch,其实第一个lookupswitch是调用字符串的hashCode得出字符串的hashCode方法来得到一个整形值,因为hashcode比较分散,使用的是lookupswitch,如果在字符串hashCode冲突的情况下我们还需要调用equals方法来进行比对,这样我们就得到了每个case对应的一个整形值,然后在使用第二个case来进行查找就行,因为lookupswitch计算出来的第二个case值都是连续的,所以使用tableswitch可以提高效率。
最终编译后的java代码如下所示:
public int chooseNear(String name) {
byte var3 = -1;
switch(name.hashCode()) {
case 110967:
if (name.equals("pho")) {
var3 = 1;
}
break;
case 3254818:
if (name.equals("java")) {
var3 = 0;
}
break;
case 188995949:
if (name.equals("javascript")) {
var3 = 2;
}
}
switch(var3) {
case 0:
return 100;
case 1:
return 200;
case 2:
return 300;
default:
return 400;
}
}
2.3.8 i++ 和 ++i 字节码原理
在面试的过程中,我们经常遇到++i和i++相关的陷阱问题,关于i++和++i的区别,我们通过字节码的形式来分析一下他到底是如何实现的?
i++对应的代码:
public static void foo() {
int i = 0;
for (int j = 0; j < 50; j++) {
i = i++;
}
System.out.println(String.format("i=%d",i));
}
对应的字节码:
public static void foo();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=6, locals=2, args_size=0
0: iconst_0
1: istore_0
2: iconst_0
3: istore_1
4: iload_1
5: bipush 50
7: if_icmpge 21
10: iload_0
11: iinc 0, 1
14: istore_0
15: iinc 1, 1
18: goto 4
21: getstatic #11 // Field java/lang/System.out:Ljava/io/PrintStream;
24: ldc #12 // String i=%d
26: iconst_1
27: anewarray #13 // class java/lang/Object
30: dup
31: iconst_0
32: iload_0
33: invokestatic #14 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
36: aastore
37: invokestatic #15 // Method java/lang/String.format:(Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/String;
40: invokevirtual #16 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
43: return
LineNumberTable:
line 58: 0
line 59: 2
line 60: 10
line 59: 15
line 62: 21
line 64: 43
LocalVariableTable:
Start Length Slot Name Signature
4 17 1 j I
2 42 0 i I
StackMapTable: number_of_entries = 2
frame_type = 253 /* append */
offset_delta = 4
locals = [ int, int ]
frame_type = 250 /* chop */
offset_delta = 16
第10行 iload_0把局部变量表slot=0的变量 i 加载到操作数栈上
第11行 iinc 01 对局部变量表slot=0的变量i直接加1,但是这个时候栈顶的元素还是没有变化
第14行 istore_0 将栈顶的元素出栈,赋值给局部变量表slot=0的变量,也就是 i ,此时 i 又被赋值为 0 ,前面 iinc 指令对i的加1操作被覆盖掉。
可以用伪代码表示 i = i++的执行过程
tmp = i;
i= i+1;
i = tmp;
++i对应的代码:
public static void foo() {
int i = 0;
for (int j = 0; j < 50; j++) {
i = ++i;
}
System.out.println(String.format("i=%d",i));
}
i=++i 对应的字节码还是在第10~14行,可以检测 i = ++i;先对局部变量表下标为0的变量+1,然后才把它加载到操作数栈上,随后又从操作数展示出栈赋值给局部变量表中下标为0的变量;
i=++i可以用如下伪代码表示:
i=i+1;
tmp = i;
i = tmp;
2.3.9 try-cache-finaly 字节码原理
在java中有一个非常重要的内容是tr_cache_finaly的执行顺序问题,大部分书籍都说finaly一定会执行,但是为什么会这样?我们一起来看看这个语法的实现原理。
示例代码:
public void tryCache(){
try {
int i = 1/0;
}catch (ArithmeticException e){
e.printStackTrace();
}finally {
exceptionHandler();
}
}
public void exceptionHandler(){
System.out.println("execptionHandler");
}
示例代码对应的字节码:
public void tryCache();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: iconst_1
1: iconst_0
2: idiv
3: istore_1
4: aload_0
5: invokevirtual #17 // Method exceptionHandler:()V
8: goto 30
11: astore_1
12: aload_1
13: invokevirtual #19 // Method java/lang/ArithmeticException.printStackTrace:()V
16: aload_0
17: invokevirtual #17 // Method exceptionHandler:()V
20: goto 30
23: astore_2
24: aload_0
25: invokevirtual #17 // Method exceptionHandler:()V
28: aload_2
29: athrow
30: return
Exception table:
from to target type
0 4 11 Class java/lang/ArithmeticException
0 4 23 any
11 16 23 any
LineNumberTable:
line 67: 0
line 71: 4
line 72: 8
line 68: 11
line 69: 12
line 71: 16
line 72: 20
line 71: 23
line 72: 28
line 73: 30
LocalVariableTable:
Start Length Slot Name Signature
12 4 1 e Ljava/lang/ArithmeticException;
0 31 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
StackMapTable: number_of_entries = 3
frame_type = 75 /* same_locals_1_stack_item */
stack = [ class java/lang/ArithmeticException ]
frame_type = 75 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
frame_type = 6 /* same */
public void exceptionHandler();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #11 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #20 // String execptionHandler
5: invokevirtual #16 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 76: 0
line 77: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 this Lcompass/token/pocket/com/service/jvm/SaveAccept;
可以看到其中三次调用了 exceptionHandler 方法,都是在程序return和异常throw之前,其中2次在try_cache语法return之前,一处是在抛出throw之前。
由代码可知,现在java编译器实现finaly代码块的方式是采用复制的方式,并将其内容插入到try_cache代码块中所有正常退出和异常退出之前,这也就介绍了,为什么finaly代码块一定会被执行的原因。
我们来看一个在finaly中修改值的情况:假设value = 1
java代码:
public static int tryCacheDemo(int value) {
try {
int result = 10 / 0;
return value;
} catch (Exception e) {
return value;
} finally {
value += 1;
}
}
对应的字节码文件:
public static int tryCacheDemo(int);
descriptor: (I)I
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 10
2: iconst_0
3: idiv
4: istore_1
5: iload_0
6: istore_2
7: iinc 0, 1
10: iload_2
11: ireturn
12: astore_1
13: iload_0
14: istore_2
15: iinc 0, 1
18: iload_2
19: ireturn
20: astore_3
21: iinc 0, 1
24: aload_3
25: athrow
Exception table:
from to target type
0 7 12 Class java/lang/Exception
0 7 20 any
12 15 20 any
LineNumberTable:
line 85: 0
line 86: 5
line 90: 7
line 86: 10
line 87: 12
line 88: 13
line 90: 15
line 88: 18
line 90: 20
line 91: 24
LocalVariableTable:
Start Length Slot Name Signature
5 7 1 result I
13 7 1 e Ljava/lang/Exception;
0 26 0 value I
StackMapTable: number_of_entries = 2
frame_type = 76 /* same_locals_1_stack_item */
stack = [ class java/lang/Exception ]
frame_type = 71 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
MethodParameters:
Name Flags
value
class代码
public static int tryCacheDemo(int value) {
int var2;
try {
int result = 10 / 0;
var2 = value;
return var2;
} catch (Exception var6) {
var2 = value;
} finally {
++value;
}
return var2;
}
可以看到,在运行的过程中,try-cache中的vlaue是一个临时变量,而finaly中的value是方法参数的value,他们两者不是同一个变量,所以在finaly中随意修改,都不会影响到return的值。所以开始传递的是: 1 ,最终return的还是1
在看一个列子: 这个也是同上,返回的 还是 hello
public static String tryCacheDemo() {
String str = "hello";
try {
return str;
}finally {
str = null;
}
}
用2个try-cache其实也是可以达到finaly的效果,代码如下:
public static String tryCacheDemo() {
String str = "hello";
try {
int num = 1/0;
exceptionHandler();
return str;
}catch (Exception e){
try {
exceptionHandler();
}catch (Throwable throwable){
throw throwable;
}
}
return "world";
}
2.3.10 try-with-resources 字节码原理
try-with-resources 是java7中新提案的资源释放机制,原因是提交者声称jdk源码中close释放资源时存在bug,可以让代码变的更加简洁,也可以减少代码出错的概率。
我们先来看下,使用传统的方式close资源会出现什么样的情况。
public static void file() throws IOException {
FileOutputStream stream = null;
try {
stream = new FileOutputStream("test.txt");
stream.write("hello world".getBytes());
}finally {
if (stream != null){
stream.close();
}
}
}
对应的字节码:
public static void file() throws java.io.IOException;
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=0
0: aconst_null
1: astore_0
2: new #21 // class java/io/FileOutputStream
5: dup
6: ldc #22 // String test.txt
8: invokespecial #23 // Method java/io/FileOutputStream."<init>":(Ljava/lang/String;)V
11: astore_0
12: aload_0
13: ldc #24 // String hello world
15: invokevirtual #25 // Method java/lang/String.getBytes:()[B
18: invokevirtual #26 // Method java/io/FileOutputStream.write:([B)V
21: aload_0
22: ifnull 43
25: aload_0
26: invokevirtual #27 // Method java/io/FileOutputStream.close:()V
29: goto 43
32: astore_1
33: aload_0
34: ifnull 41
37: aload_0
38: invokevirtual #27 // Method java/io/FileOutputStream.close:()V
41: aload_1
42: athrow
43: return
Exception table:
from to target type
2 21 32 any
LineNumberTable:
line 84: 0
line 86: 2
line 87: 12
line 89: 21
line 90: 25
line 89: 32
line 90: 37
line 92: 41
line 93: 43
LocalVariableTable:
Start Length Slot Name Signature
2 42 0 stream Ljava/io/FileOutputStream;
StackMapTable: number_of_entries = 3
frame_type = 255 /* full_frame */
offset_delta = 32
locals = [ class java/io/FileOutputStream ]
stack = [ class java/lang/Throwable ]
frame_type = 252 /* append */
offset_delta = 8
locals = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 1
Exceptions:
throws java.io.IOException
如果 stream.write()stream.close()都出现异常,会出现什么情况呢?调用者会收到那个异常呢?调用者会收到stream.close(),因为在之前我们讲过,finaly里的代码会被插入到所有代码的入口和出口之前,那么在try抛出的异常就被finaly的异常所覆盖掉了,这明显不是我们想看到的。
在jdk7中的Throwable中增加了addSuppress方法,当一个异常被抛出的时候,可能有其他异常因为该异常而被压制,无法正常抛出,这时可以通过addSuppress方法把被压制的异常记录下来,这些异常会出现在抛出异常的堆栈信息中,可以通过getSupperss方法进行获取这些异常,这样做的好处就是不会丢失异常,方便查找错误。
我们使用try-with-resources的方式来写:
public static void file() throws IOException {
FileOutputStream stream = null;
Exception exceptionTepm = null;
try {
stream = new FileOutputStream("test.txt");
stream.write("hello world".getBytes());
}catch (Exception e){
exceptionTepm = e;
throw e;
}finally {
if (exceptionTepm !=null && stream != null){
stream.close();
}
}
}
2.3.11 对象相关字节码指令
方法是对象初始化方法,类的构造方法,非静态变量的初始化,对象的初始化都会编译到这个方法之中。
我们先来看一个例子:
public class Initializer {
private int a=10;
public Initializer(){
int c = 30;
}
{
int b = 10;
}
}
对应的字节码:
Last modified 2022-10-17; size 400 bytes
MD5 checksum 353614bd7ea91d7f759c85f924f785d4
Compiled from "Initializer.java"
public class compass.token.pocket.com.service.jvm.Initializer
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#17 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#18 // compass/token/pocket/com/service/jvm/Initializer.a:I
#3 = Class #19 // compass/token/pocket/com/service/jvm/Initializer
#4 = Class #20 // java/lang/Object
#5 = Utf8 a
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcompass/token/pocket/com/service/jvm/Initializer;
#14 = Utf8 c
#15 = Utf8 SourceFile
#16 = Utf8 Initializer.java
#17 = NameAndType #7:#8 // "<init>":()V
#18 = NameAndType #5:#6 // a:I
#19 = Utf8 compass/token/pocket/com/service/jvm/Initializer
#20 = Utf8 java/lang/Object
{
private int a;
descriptor: I
flags: ACC_PRIVATE
public compass.token.pocket.com.service.jvm.Initializer();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: bipush 10
7: putfield #2 // Field a:I
10: bipush 10
12: istore_1
13: bipush 30
15: istore_1
16: return
LineNumberTable:
line 10: 0
line 9: 4
line 14: 10
line 11: 13
line 12: 16
LocalVariableTable:
Start Length Slot Name Signature
0 17 0 this Lcompass/token/pocket/com/service/jvm/Initializer;
16 1 1 c I
}
SourceFile: "Initializer.java"
javap 输出的字节码中 Initializer()方法对应 对象初始化方法,其中510将a赋值为10,1012行将b赋值为10,13~15赋值为30,可以看到虽然java运行我们把成员变量初始化和初始语句块仿真构造器之外,最终都统一编译进方法,为了加深印象,我们可以来看一个在变量初始化可能出现的异常。
示例代码:
public class Initializer {
private FileOutputStream os = new FileOutputStream("test.xml");
public Initializer(){
}
}
这个代码直接编译时就报错,必须抛出一个异常,我们改进如下才能进行编译通过:
public class Initializer {
private FileOutputStream os = new FileOutputStream("test.xml");
public Initializer() throws FileNotFoundException {
}
}
这个例子可以从侧面验证我们前面所说的观点。接下来我们来看对象创建相关的三条指令。
2.new,dup,invokespecial
在java中new是一个关键字,在字节码中也有一个new的指令,但是两者不是一回事,当我们创建一个对象时,发生了什么事情呢?以下面的代码为例:
Initializer initializer = new Initializer();
构造字节码:
public compass.token.pocket.com.service.jvm.Initializer();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: new #2 // class compass/token/pocket/com/service/jvm/Initializer
8: dup
9: invokespecial #3 // Method "<init>":()V
12: putfield #4 // Field initializer:Lcompass/token/pocket/com/service/jvm/Initializer;
15: return
LineNumberTable:
line 9: 0
line 10: 4
LocalVariableTable:
Start Length Slot Name Signature
0 16 0 this Lcompass/token/pocket/com/service/jvm/Initializer;
创建一个对象需要三条指令:new,dup,,方法的invokespecial调用,在JVM中实例初始化方法是,调用new指令时,只创建了一个类实例引用,将这个引用压入操作数栈顶,此时还没有调用初始化方法,使用invokespecial调用时方法后才真正调用了构造方法,那中间dup指令的作用是什么?
invokespecial会消耗操作数栈顶的类实例引用,如果想要在invokespecial调用后栈顶还有指向新建类对象实例引用,就需要在调用invokespecial之前复制一份对象类实例引用,否则调用完方法后类实例出栈以后,就再也找不回刚刚新创建的对象引用,就可以使用 putfield 指令 为指定的类的实例域赋值。
从本质上啦理解导致必须有dup指令的原因是方法没有返回值,如果方法把新建的对象引用作为返回值,也不会出现这个问题。
方法: 方法是类的静态初始化方法,类静态初始化块,静态变量,初始化都会在这个方法中。
javap输出的字节码中,static {} 表示 方法,不会被直接调用,会在四个指令触发时调用( new getsatic,puststatic,invokespecial) , 比如下面的场景:
- 创建类的实例化,比如new,反射,反序列化等
- 访问类的静态变量或者方法
- 访问类的静态字段或者对应静态字段赋值(final关键字修饰的除外)
- 初始化某个类的子类
3.字节码进阶
3.1 方法调用指令
jvm的方法调用都以invoke开头,这5条指令如下所示:
- invokestatic:用于调用静态方法
- invokespecial:用于调用实例私有方法,构造器,以及super关键调用父类实例方法等
- invokevirtual:用于调用非私有实例方法
- invokeinterface:用于调用接口方法
3.1.1 invokestatic
invokestatic:用来调用静态方法,也就是static修饰的方法,他主要调用的方法是在编译期就确定的,而且运行期间不会修改,属于静态绑定,调用invokestatic不需要将对象加载到草书栈,需要将所需要的参数入站执行invokestatic就可以执行了,例如Integer.valueOf(“20”);
3.1.2 invokevirtual
invokevirtual指令用于调用普通实例方法,他的调用模板在运行时才能根据对象的实际类型确定,在编译期间无法知道,类似于C++中的虚方法,在invokevirtual指令之前,需要将对象引用,方法参数1入栈,调用接收对象引用,方法参数都会出栈,如果有返回值,返回值会入到栈顶,比如,file.toString();
3.1.3 invokespecial
invokespecial 顾名思义,它是用老调用特色的实例方法,
- 构造方法
- private 修饰的私有方法
- super关键字调用父类方法
看到这儿有细心的同学可能就发现了 为什么有了 invokesvirtual还需要invokespecial呢?这是出于效率的考虑,invokespecial调用的方法在编译期间确定,在jdk1.0.2之前,invokespecial指令曾被命名Wieinvokenonvirtual,以区别于invokevirtual,例如private不会因为继承子类被重写,在编译期间就可以确定,所以private修饰的方法由invokespecial指令进行调用。
3.1.4 invokeinterface
invokeinterface用于调用接口方法,同invokevirtual一样,也是需要在运行时根据对象的类型确定模板方法。
方法分派原理:
java的设计收到很多C++的影响,方法的分配思路参考了C++的实现,下面我们来看下C++虚方法的实现。
当C++包含虚方法时,编译器会为这个类深层一个虚方法表,每个类都有一个指向虚方法表的指针 vptr ,虚方法表是方法指针的数组,用多态来实现,这里来看看单继承的场景。新建一个main.cpp代码清单如下:
class A{
publci:
virtual void method1();
virtual void method2();
virtual void method3();
};
void A::method1() { std::count << "method1 in A" << std::endl;}
void A::method2() { std::count << "method2 in A" << std::endl;}
void A::method3() { std::count << "method3 in A" << std::endl;}
class B {
publci:
virtual void method2() overide;
virtual void method4();
virtual void method5();
};
void A::method2() { std::count << "method1 in B" << std::endl;}
void A::method4() { std::count << "method2 in B" << std::endl;}
void A::method5() { std::count << "method3 in B" << std::endl;}
在命令行中使用g++ -std=c++11 -fdump-classhierarchy test.cpp 会输出A和B的虚方法表,输出结果如下所示:
Vtable for A
A::_ZTVlA 5u entries
0 (int (*) (...))0
8 (int (*) (...))(&_ZTVlA)
16 (int (*) (...))A::method1
24 (int (*) (...))A::method2
32 (int (*) (...))A::method3
Vtable for B
B::_ZTVlA 6u entries
0 (int (*) (...))0
8 (int (*) (...))(&_ZTVlA)
16 (int (*) (...))A::method1
24 (int (*) (...))A::method2
32 (int (*) (...))A::method3
40 (int (*) (...))A::method4
vtable除了包含虚方法表以外,还包含了两个额外的元素,这里暂时不用关系,重点看 offset16开始的虚方法,可以看到在单继承的情况下,子类B的虚方法顺序与父类A保持一致,B类虚方法表总覆写方法method2指向B的实现,B新增的方法method4按属性添加到虚方法表的末尾。
单继承的方法分派非常简单,比如有对象A*a电影method2方法是,如下所示:
A *a
a-> method2
我们并不知道a指针所执行对象的真正实例,不确定它是A类还是B类,或是其他A的子类但是可以确定没有method2方法都放在虚拟函数表的offset24的位置上,不会因为类型不同二影响调用。
在c++的单继承中,这种虚拟函数的方式实现非常高效,java类只支持单继承,在事项上与C++的虚方法表非常类似也是用一个名为vtable的机构
java代码清单:
public class A{
public void method1(){}
public void method2(){}
public void method3(){}
}
public class B extends A{
@Override
public void method2() { }
public void method4() { }
}
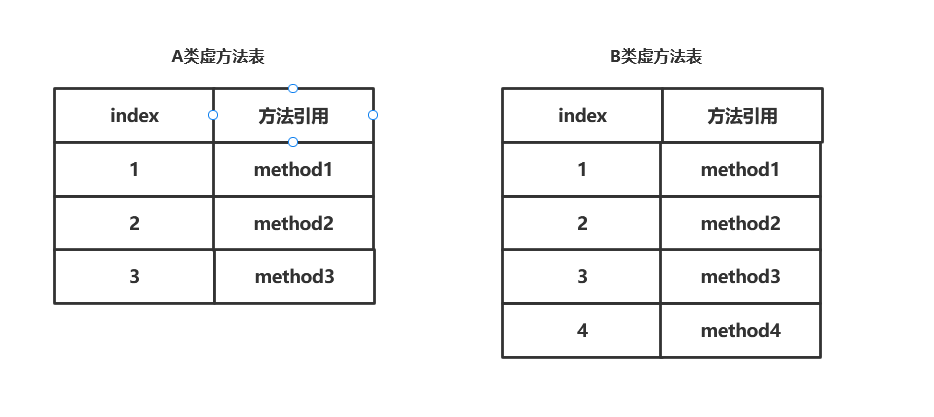
可以看到B类虚方法表中保留了父类虚方法表中的顺序只是覆盖了method2执行的方法新增了metho4,假设这是需要调用method2.invokevirtual只需要直接去找虚方法表中索引位置为2的方法即可
java的单继承规避了C++多基础的复杂性,但是支持实现多个接口,与多继承本质上没有区别,下面来看看java是如何实现的。
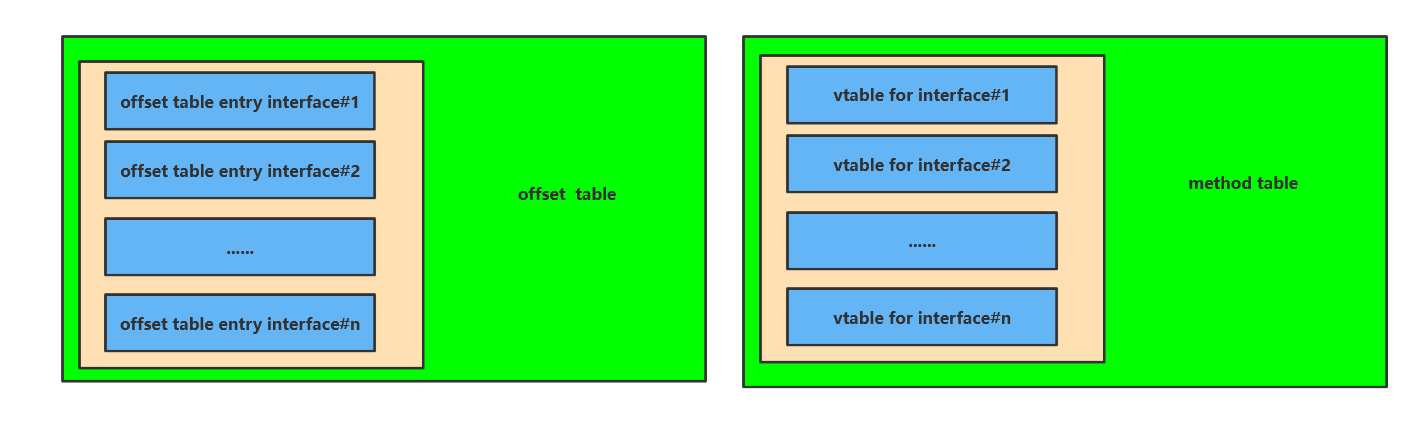
除虚方法表以外,JVM提供了名为itable的结构来支持多接口,有偏移变量表 offset table 和 方法表 method table 两部分组成,结构再hospot源码中的注释如下:
// Format of an itable
//
// ----- offset table ------
// Klass * of interface 1
// offset to vtable form start of oop / offset table entry
//...
// Klass * of interface n
// offset to vtable form start of oop / offset table entry
// --- vtable for interface 1 ---
// Method *
// cimplier entry point
// ...
// Method *
// compiler entry point
// --- vtable entry point
//--- vtable for interface 2 ---
//...
在需要调用某个接口的方法时,虚拟机会在itable的offsettable中查找对应方法表位置和方法位置,随后在method table 中查找具体的实现方法。结构图如下:
有了 itable的知识,接下来看看invokevirtual和invokespecial指令的区别,前面介绍过 invokevirtual实现依赖于java单继承的特性,子类虚拟方法表保留了父类虚方法表的顺序,但是他问java的多接口实现,这一特性无法使用,以下代码清单
public interface A{
void method1();
void method2();
}
public interface B{
void method3();
void method4();
}
public class C implements A,B{
@Override
public void method1() {
}
@Override
public void method2() {
}
@Override
public void method3() {
}
@Override
public void method4() {
}
}
public class D implements B{
@Override
public void method3() {
}
@Override
public void method4() {
}
}
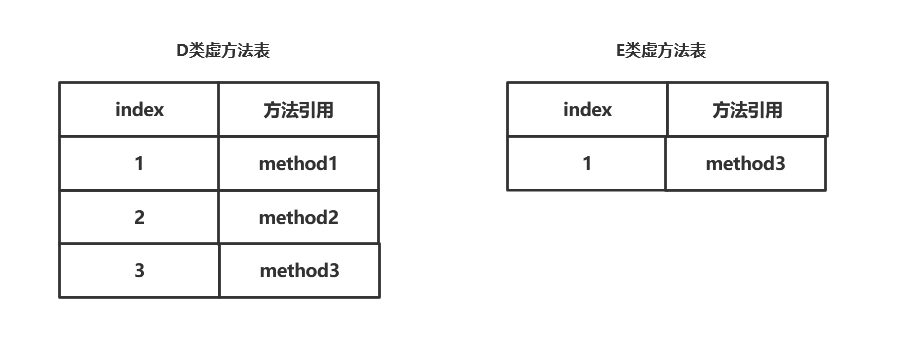
对应的itable如下图所示:
当下面有这样调用时:
public void foo(B b){
b.method3();
}
D类在method3在itable中的第三个位置,在E类中在itable的第一个位置,如果要用invokevirtual来调用method3就不能直接从固定所有位置取到对应的方法只能搜索整个itable来找到对应的方法,使用invokespecial指令来进行调用。
前介绍了vtable,itable方法分派的概念接下来使用HSDB工具来窥探JVM运行时数据,进而深入理解对象基础和多态性原理。
HSDB示例代码:
public class MyTest {
public static void main(String[] args) {
B a = new B();
a.printMe();
}
}
abstract class A {
public void printMe(){
System.out.println("hello[A]");
}
}
class B extends A{
@Override
public void printMe() {
System.out.println("hello[B]");
}
}
启动HSDB:
1.在jdk的安装路径下找到 sa-jdi.jar ,cmd进入控制台
2.在控制台中输入如下指令:java -cp sa-jdi.jar sun.jvm.hotspot.HSDB
3.在fuel菜单可以选择 attach找到一个Hotspot JVM进程,打开一个 core文件或者连接到一个远程的 debug server,attach到一个jvm进程,是最常用的选项,获取进程id可以用系统自带的ps命令,也可以用jps命令,在弹出的对话框中输入进程后默认展示当前线程列表。
 tools选项中有很多功能可以选择,比如查看类列表,查看堆信息,inspect对象内存,检测死锁等
tools选项中有很多功能可以选择,比如查看类列表,查看堆信息,inspect对象内存,检测死锁等
4.使用tools中的 class browser工具,找到B这个对象的内存地址
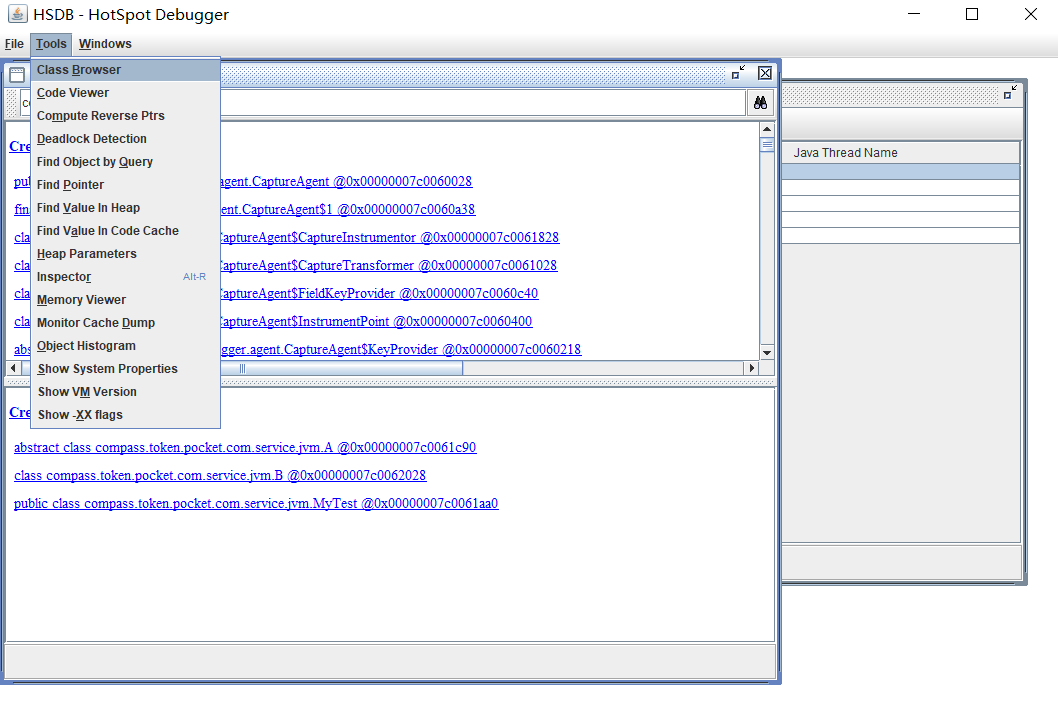
5.然后将这个B类的对象的内存地址复制下来,然后在tools中的inspector中可以查看到b对象的内存布局,可以看到vtable的大小为6,出去默认继承Object的5个方法以外,还多了一个 printMe方法,所以是6个
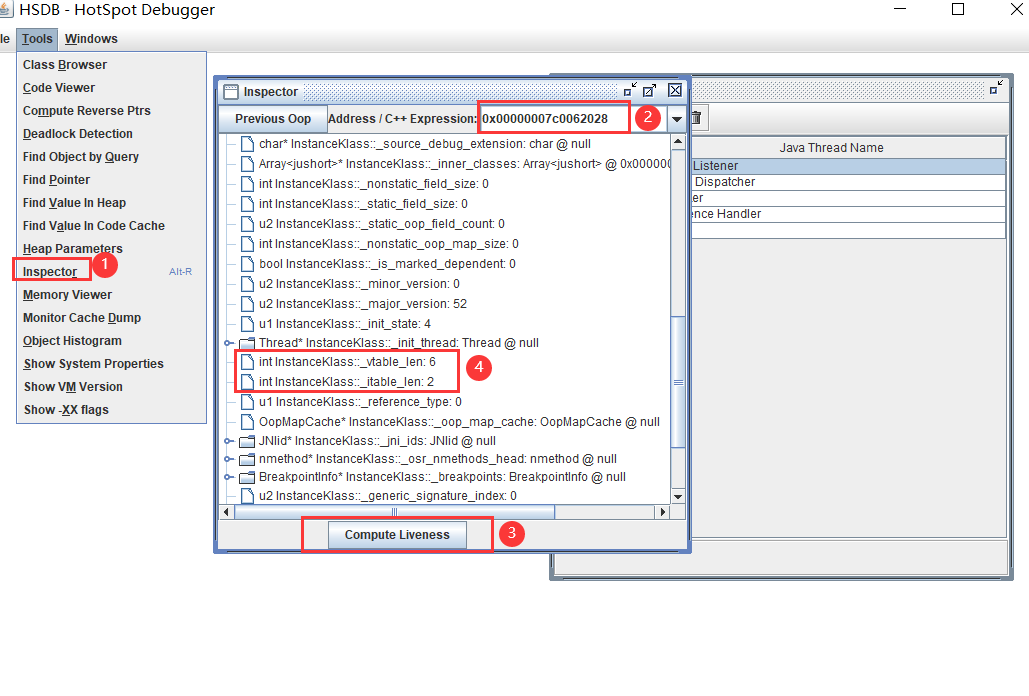
vtable,和itable机制是实现多态的基础。
- 子类会继承父类的vtable,因为java类都会继承Object类,Object中有5个方法可以被继承,所以一个空java类的vtable的大小也等于5
- 被final和static修饰的方法不会出现在vatable中,因为没有办法被子类重写和继承,同理知道private修饰的方法也不会出现在vtable中
- 接口方法的调用使用invokeinterface指令,java使用itable来实现多接口,itable由offset table和method table两部分组成,在调用接口方法时,会先在 offset table中查找method table的偏移位置,随后在method table中查找具体的接口实现。
3.1.5 invokedynamic指令
java虚拟机的指令从1.0开始到jdk7直接10余年没有新增任何指令,这期间基于jvm的语言百花齐放,出现了JRuby,Groovy,Scala等很多运行在JVM的语言,因为jvm有诸多限制,大部分情况下这些非java的语言需要很多额外的调教才能在jcm上高效运行,随着jdk7的发布,字节码指令新增了一个重量级的指令 invokedynamic指令,这个指令为多语言在jvm上的实现提供了技术支撑,接下来我们就看下invokedynamic这个指令背后的原理。
jdk7虽然在指令集中新增了这个指令,但是javac 并不会生成invokedynamic指令。知道jdk8 Lambda表达式的出现,在java中才第一次用上了这个指令。
对于jvm而言,不管什么语言都是强类型语言,他会在编译时检测传入的参数类型和返回值类型。
开始讲解invokedynamic之前需要介绍一个核心的概念,方法句柄,又称为方法句柄或方法指针,是java.lang.invok包下的一个类,他可以使得java可以和其他语言一样把函数当做参数传递进去,MethodHandle类似于Method类,他是他比Method类更加灵活,更加轻量级,下面用一个列子来看MethodHandle的用法。
public class MethodHandleTest {
//
public void print(String word){
System.out.println("hello:"+word);
}
public static void main(String[] args) throws Throwable {
MethodHandleTest test = new MethodHandleTest();
// 构造一个方法的类型,指定他的返回值,以及参数类型
MethodType methodType = MethodType.methodType(void.class, String.class);
// 寻找一个方法是MethodHandleTest类型的实例方法,名称是:print,方法描述是:methodType
MethodHandle methodHandle = MethodHandles.lookup().findVirtual(MethodHandleTest.class, "print", methodType);
// 传入对象,然后通过方法句柄进行调用
methodHandle.invoke(test,"admin");
}
}
执行以上代码会正确的输出: hello:admin
1.创建MethodType对象,MethodType用来表示方法的签名,每个MethodHandle都有一个MethodType实例,用来指定方法的返回值类型和各个参数类型
2.调用MethodHandle.lookup静态方法返回MethodHandles.Lookup对象,这个对象表示查找的上下文,根据方法不同类型通过,findStatic,findSpecial,findVirtual等方法查找方法签名为MethodType的方法句柄
3.拿到方法句柄就可以调用具体的方法了,通过传入目标方法的参数,使用 invok或者invokExact进行调用
invokedynamic指令调用流程如下:
- JVM首次执行 invokedynamic指令会调用引导方法(Bootstrap Method)
- 引导方法返回一个CallSite对象,CallSite对象内部根据方法签名进行目标方法查找,他的getTarget方法返回方法句柄(MethodHandle)对象
- 在CallSIte没有变化的情况下,MethodHandle可以值被调用,如果CallSite有变化,重新查找即可;
3.2 Lambda表达式原理
Lambda是java8中最令人激动的特性,他与匿名内部类有很多相似之处,但Lambda表达式并不是简单的创建了一个匿名内部类。我们新建一个Test类如下:
public class Test {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("hello , inner class");
}
};
runnable.run();
}
}
使用javac编译后会生成两个class文件,Test.class和Test$1.class反编译后的代码如下:
static final class Test$1 implements Runnable{
@Override
public void run(){
System.out.print("hello , inner class");
}
}
public static void main(String[] args) {
Runnable r1 = new Test$1();
r1.run();
}
可以看到匿名内部类是在编译期间生成新的class文件来实现的,接下来我们来看Lambda表达式的实现原理,修改上面的代码如下:
public class Test {
public static void main(String[] args) {
Runnable runnable = () -> System.out.println("run");
runnable.run();
}
}
使用javac编译后发现只生成了一个class,并没生成新的class,使用javap查看字节码文件内容如下:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: invokedynamic #2, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;
5: astore_1
6: aload_1
7: invokeinterface #3, 1 // InterfaceMethod java/lang/Runnable.run:()V
12: return
LineNumberTable:
line 10: 0
line 11: 6
line 12: 12
LocalVariableTable:
Start Length Slot Name Signature
0 13 0 args [Ljava/lang/String;
6 7 1 runnable Ljava/lang/Runnable;
MethodParameters:
Name Flags
args
private static void lambda$main$0();
descriptor: ()V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=2, locals=0, args_size=0
0: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #5 // String run
5: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 10: 0
}
可以看到生成的字节码中出现了一个 lambda$main$0 的静态方法,这段字节码比较简单,翻译为源码如下:
public static void lambda$main$0(){
System.out.println("run");
}
这里的main方法中出现了invokedynamic指令第0行中#2表示常量池中#2的元素,这个元素又指向了#0:23,Test部分常量池如下:
Constant pool:
#1 = Methodref #8.#26 // java/lang/Object."<init>":()V
#2 = InvokeDynamic #0:#31 // #0:run:()Ljava/lang/Runnable;
....
#31 = NameAndType #36:#43 // run:()Ljava/lang/Runnable;
BootstrapMethods:
0: #28 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
Method arguments:
#29 ()V
#30 invokestatic compass/token/pocket/com/service/jvm/Test.lambda$main$0:()V
#29 ()V
其中#0是一个特殊的查找,对应的是BoostrapMethods中的0行,可以看到这是对静态方法LambdaMetafactory()的调用,他的返回值是java.lang.invoke.CallSite对象,这个对象的getTarget方法返回目标方法句柄,核心的metafactory方法定义如下:
public static CallSite metafactory(MethodHandles.Lookup caller,
String invokedName,
MethodType invokedType,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType)
throws LambdaConversionException {
AbstractValidatingLambdaMetafactory mf;
mf = new InnerClassLambdaMetafactory(caller, invokedType,
invokedName, samMethodType,
implMethod, instantiatedMethodType,
false, EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY);
mf.validateMetafactoryArgs();
return mf.buildCallSite();
}
接下来介绍各个参数含义:
caller: 表示jvm提供的查找上下稳
invokedName: 表示函数名
samMethodType:表示函数定义接口的方法签名,表示返回值和参数类型
implMethod:表示编译时生成的Lambda表达式对应的静态方法
instantiateMethodType:一般和samMethodType一样或他是一个特例
metafactory方法内部细节是整个Lambda表达式最复杂的地方,他的源码内部创建了一个InnerClassLambdaMetafactory对象,跟进InnerClassLambdaMetafactory可以看到他在默默的生成新的内部类,类名的规则是ClassName$ L a m b d a Lambda Lambdan,其中ClassName是Lambda所在对应的类名,后面的数字按照生成的规则依次递增,如下图源码所示:
public InnerClassLambdaMetafactory(MethodHandles.Lookup caller,
MethodType invokedType,
String samMethodName,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType,
boolean isSerializable,
Class<?>[] markerInterfaces,
MethodType[] additionalBridges)
throws LambdaConversionException {
super(caller, invokedType, samMethodName, samMethodType,
implMethod, instantiatedMethodType,
isSerializable, markerInterfaces, additionalBridges);
implMethodClassName = implDefiningClass.getName().replace('.', '/');
implMethodName = implInfo.getName();
implMethodDesc = implMethodType.toMethodDescriptorString();
implMethodReturnClass = (implKind == MethodHandleInfo.REF_newInvokeSpecial)
? implDefiningClass
: implMethodType.returnType();
constructorType = invokedType.changeReturnType(Void.TYPE);
lambdaClassName = targetClass.getName().replace('.', '/') + "$$Lambda$" + counter.incrementAndGet();
cw = new ClassWriter(ClassWriter.COMPUTE_MAXS);
int parameterCount = invokedType.parameterCount();
if (parameterCount > 0) {
argNames = new String[parameterCount];
argDescs = new String[parameterCount];
for (int i = 0; i < parameterCount; i++) {
argNames[i] = "arg$" + (i + 1);
argDescs[i] = BytecodeDescriptor.unparse(invokedType.parameterType(i));
}
} else {
argNames = argDescs = EMPTY_STRING_ARRAY;
}
}
我们去获取 r 的className 输出结果如下:
public class Test {
public static void main(String[] args) {
Runnable r = () -> System.out.println("run");
r.run();
System.out.println(r.getClass().getSimpleName());
}
}
// 输出: Test$$Lambda$1/997608398
其中斜杠后面的数字 997608398 表示类对象的hashCode值,InnerClassLambdaMetafactory这个类还有一个静态代码初始块,里面有一个开关可以选择是否将生成的类dump到文件中,这部分代码如下所示:
static {
final String key = "jdk.internal.lambda.dumpProxyClasses";
String path = AccessController.doPrivileged(
new GetPropertyAction(key), null,
new PropertyPermission(key , "read"));
dumper = (null == path) ? null : ProxyClassesDumper.getInstance(path);
}
使用java -Djdk.internal.lambda.dumpProxyClasses=.Test运行Test类会发现在运行期间生成了一个新的内部类Test$$Lambda 1. c l a s s , 这个类正是由 I n n e r C l a s s L a m b d a M e t a f a c t o r y 使用 A S M 字节码技术动态生成的,他实现了 R u n n a b l e 接口,并且在 r u n 方法里调用了 T e s t 类的 l a m b d a 1.class,这个类正是由 InnerClassLambdaMetafactory 使用ASM字节码技术动态生成的,他实现了Runnable接口,并且在run方法里调用了Test类的lambda 1.class,这个类正是由InnerClassLambdaMetafactory使用ASM字节码技术动态生成的,他实现了Runnable接口,并且在run方法里调用了Test类的lambdamain$0()
这部分内容总结如下:
- Lambda 表达式声明的地方会生成一个invokedynamic指令,同时编译器会生成一个引导方法(Bootstrap method)
- 第一次执行代码invokedynamic指令时,会调用对应的引导方法,该方法会调用 LambdaMetafactory .metafactory() 动态生成内部类
- 引导方法会返回一个动态调用CallSite对象,这个CallSite对象最终会调用实现了Runnable接口的内部类
- Lambda 表达式中的内容会被编译成静态方法,前面动态生成内部类会直接调用该静态方法
- 真正执行Lambda电影的指令还是一个的invokinterface指令
Lambda为什么要基于invokedynamic指令来实现呢?
因为Lambda实现方式可以有很多种,比如,内部类,method handle,danamic proxies等机制实现,未来的实现可能会改变,invokedynamic并不是在编译期间生成匿名内部类,而是提供一个稳定的二进制表示规范,把实现的机制放到代码中,如果后面要更改实现机制,只需要修改 InnerClassLambdaMetafactory 即可,而不是去修改字节码的指令的实现逻辑。
3.3 泛型字节码
泛型是jdk5引进的一种规范,好的地方是可以帮助我们发现一些明显的问题,不好的地方是因为泛型设计其实还是有一些缺陷,接下来我们来分析一下泛型是如何实现的。
public class Student<T> {
public T first;
public T last;
public Student(T first, T last) {
this.first = first;
this.last = last;
}
}
对应的字节码内容如下:
Constant pool:
#1 = Methodref #5.#25 // java/lang/Object."<init>":()V
#2 = Fieldref #4.#26 // compass/token/pocket/com/service/jvm/Student.first:Ljava/lang/Object;
#3 = Fieldref #4.#27 // compass/token/pocket/com/service/jvm/Student.last:Ljava/lang/Object;
#4 = Class #28 // compass/token/pocket/com/service/jvm/Student
#5 = Class #29 // java/lang/Object
#6 = Utf8 first
#7 = Utf8 Ljava/lang/Object;
#8 = Utf8 Signature
#9 = Utf8 TT;
#10 = Utf8 last
#11 = Utf8 <init>
#12 = Utf8 (Ljava/lang/Object;Ljava/lang/Object;)V
#13 = Utf8 Code
#14 = Utf8 LineNumberTable
#15 = Utf8 LocalVariableTable
#16 = Utf8 this
#17 = Utf8 Lcompass/token/pocket/com/service/jvm/Student;
#18 = Utf8 LocalVariableTypeTable
#19 = Utf8 Lcompass/token/pocket/com/service/jvm/Student<TT;>;
#20 = Utf8 MethodParameters
#21 = Utf8 (TT;TT;)V
#22 = Utf8 <T:Ljava/lang/Object;>Ljava/lang/Object;
#23 = Utf8 SourceFile
#24 = Utf8 Student.java
#25 = NameAndType #11:#30 // "<init>":()V
#26 = NameAndType #6:#7 // first:Ljava/lang/Object;
#27 = NameAndType #10:#7 // last:Ljava/lang/Object;
#28 = Utf8 compass/token/pocket/com/service/jvm/Student
#29 = Utf8 java/lang/Object
#30 = Utf8 ()V
{
public T first;
descriptor: Ljava/lang/Object;
flags: ACC_PUBLIC
Signature: #9 // TT;
public T last;
descriptor: Ljava/lang/Object;
flags: ACC_PUBLIC
Signature: #9 // TT;
public compass.token.pocket.com.service.jvm.Student(T, T);
descriptor: (Ljava/lang/Object;Ljava/lang/Object;)V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=3
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: aload_1
6: putfield #2 // Field first:Ljava/lang/Object;
9: aload_0
10: aload_2
11: putfield #3 // Field last:Ljava/lang/Object;
14: return
LineNumberTable:
line 12: 0
line 13: 4
line 14: 9
line 15: 14
LocalVariableTable:
Start Length Slot Name Signature
0 15 0 this Lcompass/token/pocket/com/service/jvm/Student;
0 15 1 first Ljava/lang/Object;
0 15 2 last Ljava/lang/Object;
LocalVariableTypeTable:
Start Length Slot Name Signature
0 15 0 this Lcompass/token/pocket/com/service/jvm/Student<TT;>;
0 15 1 first TT;
0 15 2 last TT;
MethodParameters:
Name Flags
first
last
Signature: #21 // (TT;TT;)V
}
其实可以从字节码层面看出来,在编译的时候进行了泛型擦除,也就是所谓的泛型最终都是Object,而引入泛型的原因就是让我们清除的知道这是什么类型,不是一个一个的Object,减少了类型转换。
我们来试着在此类中重写一下show方法: 下面的代码我们会编译的时候就报错,因为这两个泛型方法其实本质上就是 List,这也就没有达到重写的一个规则,会导致两个方法一模一样,所以会编译不通过。而且泛型不能是基础数据类型,这也就说明了为什么集合中必须是引用类型,而不是基础数据类型,因为一个基础数据类型是不能转Object的。
public class Student<T> {
public T first;
public T last;
public Student(T first, T last) {
this.first = first;
this.last = last;
}
public void show(List<T> list){
}
public void show(List<Student> list){
}
}
如果我们的一个List指定了为某种类型,那么我们可以放入其他他类型的对象么?这个答案是:完全可以的,因为我们上面说到,既然泛型最终是Object,那么集合中只要是对象类型,那么肯定是可以放入到其中的,只是我们编译器会在编译的时候给我们检测,我们可以使用反射进行测试,绕过编译期,使用泛型,让指定类型的集合放入不同的元素,示例如下:
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class Student {
public static void main(String[] args) throws Exception {
// 现在创建一个集合,表示这个集合只能装Student类型,装入其他类型会报错
List<Student> list = new ArrayList<>();
list.add(new Student());
// list.add(new Object()); // 此处会报错,类型不匹配
// 接下来我们使用反射往Student中添加一个Object类型的对象
Class<? extends List> listClass = list.getClass();
Method method = listClass.getMethod("add", Object.class);
method.invoke(list,new Object());
// 遍历list输出,结果看到Object成功的添加进去了
for (int i = 0; i < list.size(); i++) {
Object student = (Object)list.get(i);
System.out.println(student);
}
// 不能使用增强for进行遍历,因为增强for'遍历的类型都是Student类型,使用增强for会导致类型转换失败
// for (Student student : list) {}
}
}
3.4 Synchronized的实现原理
Synchronized关键字是多线程安全的一个解决方案,可以保护临界区代码的一个执行安全,保证多个线程在这这段代码块时,只有一个线程执行,等这个线程执行完毕后,后面的线程才能继续到这个临界区代码执行,我们就来分析一下这个Synchronized是如何在字节码层面进行实现的。
public class Synchronized {
private Integer counter = 0;
// 线程安全的方法,一次只能由一个线程进入执行,当前线程执行完毕后,另外的线程才能进入到该方法
private synchronized void increase() {
++counter;
}
public Integer getCount(){
return counter;
}
}
对应的字节码:
private void increase();
descriptor: ()V
flags: ACC_PRIVATE
Code:
stack=3, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: aload_0
5: aload_0
6: getfield #3 // Field counter:Ljava/lang/Integer;
9: invokevirtual #4 // Method java/lang/Integer.intValue:()I
12: iconst_1
13: iadd
14: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
17: putfield #3 // Field counter:Ljava/lang/Integer;
20: aload_1
21: monitorexit
22: goto 30
25: astore_2
26: aload_1
27: monitorexit
28: aload_2
29: athrow
30: return
Exception table:
from to target type
4 22 25 any
25 28 25 any
LineNumberTable:
line 9: 0
line 10: 4
line 11: 20
line 12: 30
LocalVariableTable:
Start Length Slot Name Signature
0 31 0 this Lcompass/token/pocket/com/service/jvm/SynchronizedTest;
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 25
locals = [ class compass/token/pocket/com/service/jvm/SynchronizedTest, class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
- 第0~2行,将thi对象引用入站,使用dup复制栈顶元素,并将它存入局部变量表为1的地方,现在栈上还留下一个this引用对象
- 第3行 monitorenter 获取栈顶this的对象引用没如果成则继续执行,如果失败就进入等待状态。
- 4~11行执行++counter
- 4~21行,将this对象入栈,调用 monitorexit 释放锁
- 425和2528监视异常,如果出现异常就跳转到25行释放锁,保证了锁一定会被释放
每个java对象都可以作为同步锁,这些锁有三种不同状态
- Synchronized修饰非静态方法监视器的是this
- Synchronized修饰的静态方法监视器的是当前类对象
- Synchronized锁同步代码块,监视器的是当前lock对象
java虚拟机保证一个minitor异常最多只能被一个线程占有,monitorenter和monitorexit是两个与监视器相关的字节码指令,当线程执行到monitorenter指令是,会尝试获取栈顶对象对应的监视器权限,也就是尝试获取对象锁,如果monitor没有被其他对象占有,当前线程会获取到临界区代码执行权,如果其他线程已经拥有monitor的所有权,那么该线程会阻塞,直到其他线程释放monitor的所有权。当获取到monitor的线程执行完临界区代码后,会是否monitor的所有权,释放锁有2种情况,一种是代码正常执行完毕,还有一种就是执行临界区代码的时候出现异常,也会释放锁,不然锁如果一直得不到释放,就会造成死锁。
3.5 反射的实现原理
3.5.1 反射源码分析
反射是java的核心特性之一,很多框架都是基于反射来实现强大的功能的,比如mybatis,spring等,java的反射机制运行我们运行时动态调用某个方法,新增对象实例,获取对象属性等。
示例代码:
public class ReflectionTest {
private static int count = 0;
public static void foo(){
new Exception("test#"+(count++)).printStackTrace();
}
public static void main(String[] args) throws Exception {
Class<?> clazz = Class.forName("compass.token.pocket.com.service.jvm.ReflectionTest");
Method method = clazz.getMethod("foo");
for (int i = 0; i < 20; i++) {
method.invoke(null);
}
}
}
运行上面的代码会发现在0~15次掉的时候,调用方式为:sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method),在第16次后调用方式变为了:sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
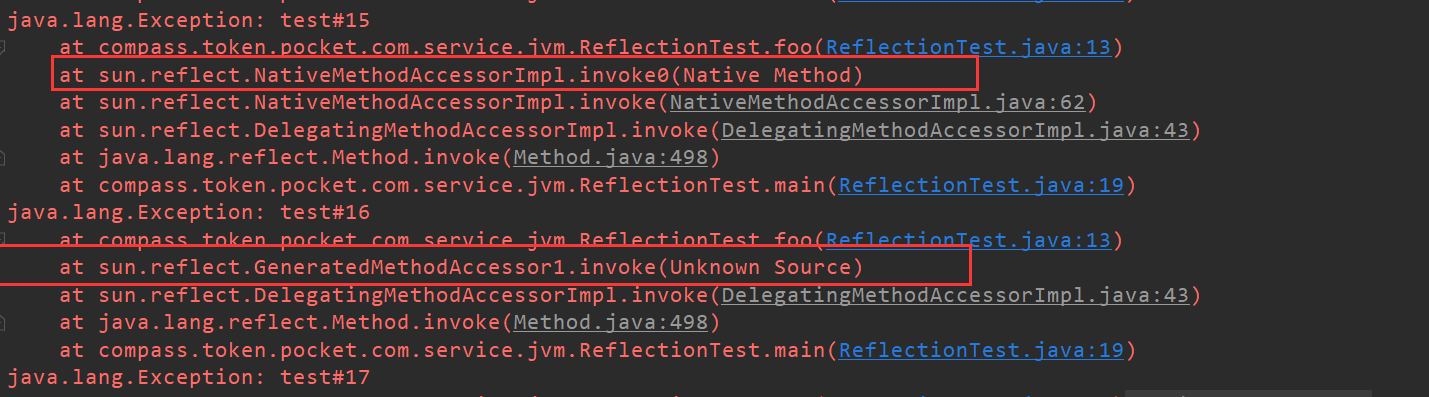
Method.invok方法调用了MethodAccessor.invok方法和MethodAccess是一个接口他的源码如下所示:
Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException;
从输出的堆栈可以看到MethodAccessor的实现类是委托的DelegatingMethodAccessorImpl,他的invok非常简单,就是把调用委托给了真正的MethodAccessorImpl实现类
abstract class MethodAccessorImpl extends MagicAccessorImpl implements MethodAccessor {
public abstract Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException;
}
通过堆栈信息可以看到在第0~15次调用中,实现类是NativeMethodAccessorImpl,从第16次开始实现类是 GeneratedMethodAccessor1,玄机就在GeneratedMethodAccessor1方法中

超过15次之后利用GeneratedMethodAccessor1来调用反射的方法,MethodAccessorGenerator的作用是通过ASM生成新的类,为什么要0~15次之后使用ASM新生成类来调用呢?这是因为出于性能的考虑,JNI native的调用方式要比动态生成类调用的方式慢20倍,由于第一次字节码生成的过程比较慢,如果第一次就是要生成字节码的方式,反而比native的调用方式慢3~4倍,为了权衡这种利弊,java引入了inflation机制,接下来我们来看下infation机制
3.5.1 infation机制
很多情况下反射只会调用1~2次,jvm于是想了一个办法,设置了一个 sum.reflect.infation 的阈值,默认等于15,当反射方法调用超过15之后就会使用ASM来生成新的类,保证后面比native要快,调用使用次数小于15的情况下,直接使用native的方式,没有额外的类生成,校验,加载的开销,这种方式称为inflation机制。
jvm与inflation相关的属性有2个,一个是刚刚提到的 sum.reflect.infation,还有一个是是否禁用inflation的属性 sun.reflect.noIflation属性,默认为false,如果设置为true,那么从第0次开始就直接生成新的类进行调用,不会使用native的方式进行调用。
4.javac编译原理
我们来看一下javac是如何把java源文件编译成符合java虚拟机规范的class文件的,编译过程如下:
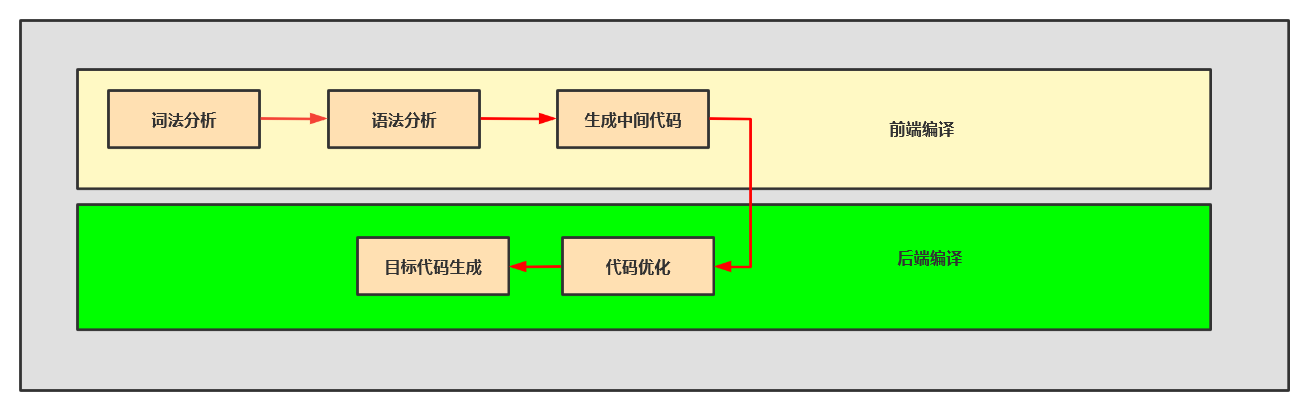
javac这种将源文件转为字节码的过程在编译原理上属于前端编译,不涉及目标机器码相关diam的生成和优化,在jdk中的javac本身用的是java语言编写的,在某种意义上实现了javac语言的自举,javac没有使用类似YACC,Lex这样的生成器工具,所有的词法分析等功能都是自己实现的,代码比较精简和高效。
4.1 javac源码调试
javac源码的调试过程比较简单,它本身就是java语言编写的,对于我们理解内部逻辑也比较友好,在Intelllij IDE和jdk8下完成,分为如下几个步骤
- 首先找到javac的源码,下载并导入,从openjdk的网站上下javac的源码,导入到 Intellij IDE中。
- 在idea的启动类项中配置如下:
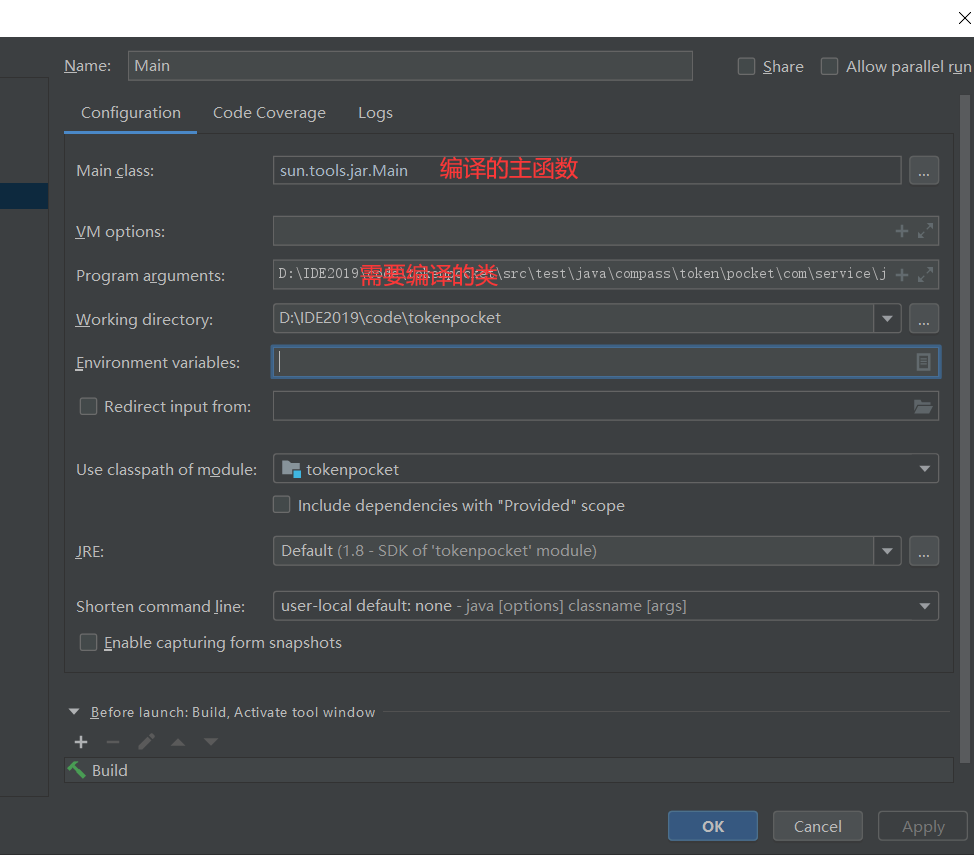
-
找到javac 主函数入口,代码在 src/com/sun/tools/javac/Main.java运行main方法正常情况控制台会输出如下内容:
4.2 javac的七个阶段
javac的编译分为七个过程,如下图所示:

- parse:读取java源文件,做词法分析和语法分析
- enter:生成符号表
- procces:处理注解
- attribute:检测语法合法性,常量折叠
- flow:数据流分析
- desugar:去除语法糖
- generate:生成字节码
4.2.1 parse阶段
parse阶段主要作用是读取,java源文件,并做词法分析和语法分析,词法分析将源代码拆分为一个个词法记号(token),这个过程又被称为扫描(scan),比如代码 i=1+2 会被拆分为5个部分 i,=,1,+,2这个过程会将空格,注释,空行对程序执行没有意义的代码排除掉,词法分析同我们理解英语意义,比如英文句子 “ you are handsome” 在我们的大脑会被拆分为 you ,are ,handsome 三个单词。
javac的词法分析器是由 sun.tools.java.Scanner 类实现的 ,以语句 int k = i+k 为例引入。
示例代码如下:
public static void main(String[] args) throws Exception {
ScannerFactory scannerFactory = ScannerFactory.instance(new Context());
Scanner scanner = scannerFactory.newScanner("int k = i+k;", false);
scanner.nextToken();
System.out.println(scanner.token().kind); // int
scanner.nextToken();
System.out.println(scanner.token().name()); // k
scanner.nextToken();
System.out.println(scanner.token().kind); // =
scanner.nextToken();
System.out.println(scanner.token().name()); // i
scanner.nextToken();
System.out.println(scanner.token().kind); // +
scanner.nextToken();
System.out.println(scanner.token().name()); // j
scanner.nextToken();
System.out.println(scanner.token().kind); // ;
}
Scanner 会读取源文件中的内容,将其解析为java语言的token序列。词法分析之后是进行语法分,语法分析的基础上分析单词之间的关系,将其转换为计算机易于理解的形式,生成抽象语法树(Abstract Synttax Tree),AST 是一个数状结构,树的每个节点都是一个语法单元,抽象语法树是后续的语义分析,语法校验,代码生成的基础。
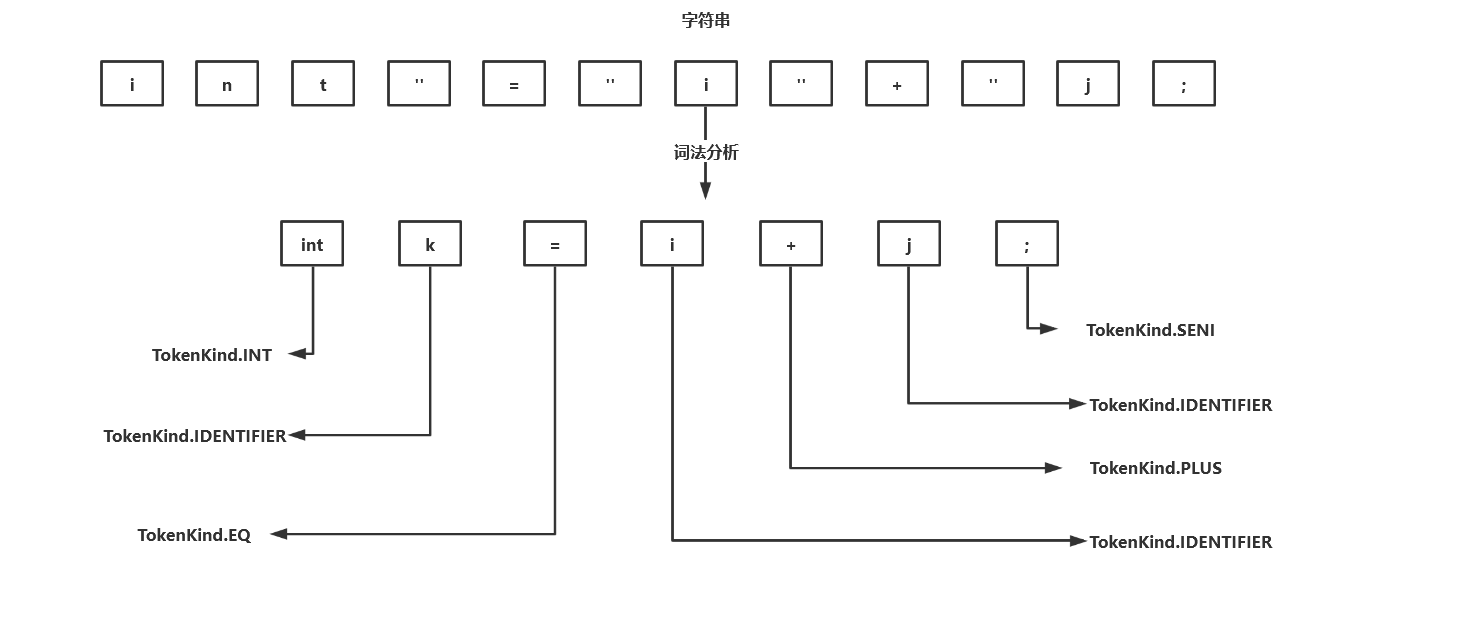
与其他语言一样,javac也是采用递归下降法来生成抽象语法树的,主要功能是由 com.sun.tools.javac.parser.JavacParser 来完成的,语句:" int k = i + j ; ",对应的AST如图
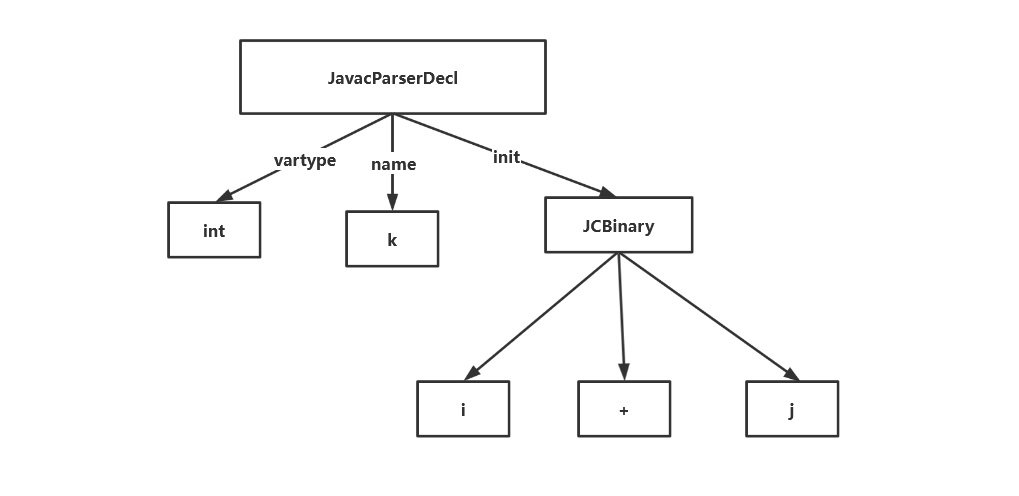
4.2.2 enter阶段
enter阶段的主要作用就是解析和填充符号表,主要由com.sun.tools.javac.comp.Enter和com.sun.tools.javac.comp.MemberEnter来实现的,符号表由标识符,标识类型,作用域,等信息构成的记录表,在遍历抽象语法树时遇到类型,变量,方法定义时,会将他们的信息存储到符号表中,方便后续快速查询。
public class HelloWorld {
int x = 5;
char y = 'A';
public long add(long a, long b){
return a+b;
}
}
java使用Symbol类来标识符号,每个符号都包含名称,类别,类型这三个关键属性
- name: 表示符号名,比如 x,y,add都是符号名
- kind:表示符号类型,上面diam中的x的符号都是Kinds.VAR,表示这是一个变量,add符号类型是Kinds.MTH表示这个一个方法符号
- type:表示变量的类型,比如上面的x符号的类型是int类型,add方法的符号类型为null,对应java这种静态类型语言来说,在编译期救护确定变量的类型
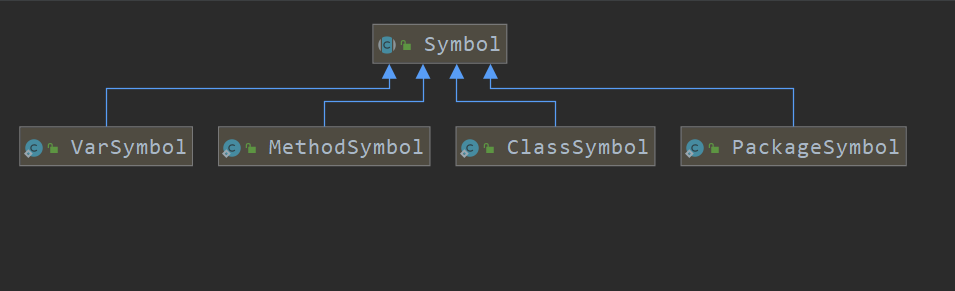
Symbol 是一个抽象类,常见的实现类有:VarSymbol,MethodSymbol,ClassSymbol,PackageSymbol等
Symbol 定义了符号是什么?作用域(Scope)则指定了符号的有效范围,由 com.sun.tools.javac.code.Scope 类进行实现。
4.2.3 process阶段
process计算用来做注解处理的,这个步骤是由 com.sun.tools.javac.processing.JavacProcessingEnvironment 类完成的,从jdk6开始,javac支持编译阶段用户处理自定义注解,大名鼎鼎的lombok就是利用这个特性去生成get和set方法的,通过注解的方式处理去生成目标类,后面的章节会带大家首先一个简易的ombok。
4.2.4 attribute阶段
attribute阶段是语义分析的一部分,主要由com.sun.tools.javac.comp.Attr实现,这个阶段会做语义合法性检测,,常量折叠等,由com.sun.tools.javac.comp包下的:Check,Resolve,Infer,ConstFold几个类辅助实现
比如校验下面这些场景:
- 校验方法的返回值是否和方法声明的返回值一样
- 检测相同类中是否有存在相同签名的方法存在,java中运行重载,但是不允许方法签名一样的方法存在
4.2.5 flow节点
flow节点主要是用于处理数据流分析,主要由com.sun.tools.javac.comp.Flow类实现,很多编译期的校验都在这个阶段完成,下面举几个场景的场景
- 校验非void方法是否所有退出分支都有返回值返回
- 检测受检异常是被捕获或显示抛出去
- 检测局部变量使用前是否被初始,java总的局部变量在未赋值情况下使用会被赋默认值,但是局部变量不会,在使用之前必须先赋值
- 检测final是否重复赋值,保证final的语义
- 检测是否有不可达的语句,也就是说在return 之后再写代码,但是永远得不到执行
4.2.6 desugar
java的语法糖没有Kotlin那么丰富,每次随着版本的更新都会加入很多语法糖,下面这些某种意义上来说都算语法糖:泛型,内部类,try-catch-resource,foreatch,原始类型和包装类型之间的隐式转换,字符串swiitch实现,i++,++i,变长参数等实现。
desugar的过程就是解除语法糖,主要由 desugarcom.sun.tools.javac.comp.TransTypes 和 com.sun.tools.javac.comp.Lower去实现的,TransTypes 类是用来擦除泛型和插入响应类型的转换代码,Lower是用来处理泛型之外的其他语法糖,场景场景如下:
- 在desugar阶段泛型就会被擦除,在有时需要自动为原始类和包装类型转换,添加拆箱,装箱。
- 去除死逻辑代码块,也就是说if(false)里面的代码,这种根本不可达的代码会被解析掉,不编译到class中
- switch的String和枚举也是在desugar阶段完成的
4.2.7 generate阶段
generate阶段的主要作用是变量抽象语法树,生成最终的class文件,由 com.sun.tools.javac.jvm.Gen 来实现的。
场景的场景如下:
- 初始化代码块并手机到 和中,static代码块和static修饰的变量也会收集到方法中去
- 把字符串拼接转换为StringBuilder.append的方式来实现
- 为Synchronized关键字生成异常表,保证线程一定会释放锁
- switch-case 中tableswtich和lookupswitch指令的选择
5.从字节码的角度看Kotlin语言
因为我没有接触安卓开发,也没有接触Kotlin语言,所以不进行阅读,暂时跳过,后面需要再回来补上
6.ASM和javassist字节码操作工具
前面几章我们介绍了字节码基础知识,从这一张开始我们将学习如何操作字节码文件,如何修改class的文件内容?
当我们需要修改一个class文件时,我们可以选择自己解析这个class,在符合java字节码规范前提下进行字节码改造,如果你编写过class文件解析的代码,就会发现这个过程非常烦死,更别提新增方法,手动计算max_stack等操作了。
ASM最开始是2000年Eric Bruneton在INRIA(法国国立计算机及自动化研究院)读博期间完成的一个作品,那个时候包含java.lang.reflect.Proxy包的jdk1.3还没发布,ASM被作用代码生成器生成动态代理类,经过多年的发展,ASM被诸多框架采用,称为字节码操作领域事实的标准。
简单的API背后ASM自动帮我们做了很多的事情,比如维护常量池索引,计算最大栈max_stack,局部变量表大小max_locals等,除此之外,还有下面这些优点:
- 架构设计轻巧,使用方便
- 更新速度快,支持最新的java版本
- 速度非常快,在动态代理class的生成和转换是,尽可能确保运行中的应用不会被ASM拖慢
- 非常可靠,久经考验,很多著名的框架源代码都在使用,比如cglib,Mybatis,FastJson等,其他字节码操作框架会生成许多的中间类和对象,耗费巨大的内存运行缓慢,ASM提供两种生成和转换类的方法:基于事件core API和基于对象的Tree API,则两种方式可以用XML解析的SAX和DOM的方式来处理
SAX解析XML采用的是事件驱动,不需要异常解析完整个文档,而是按照内容顺序解析文档,如果解析时符合特定的事件就回调一些函数来处理事件,SAX运行时是单向的,流式的,解析过的部分无法在不重新开始的情况下再次读取,ASM的Core API与这种方式类似
maven依赖
1.2 核心项目
1.2.1 org.objectweb.asm 和 org.objectweb.asm.signature
包定义了基于事件的API,并提供了类分析器和写入器组件。它们包含在 asm.jar 中。
1.2.2 org.objectweb.asm.util
包,位于asm-util.jar中,提供各种基于核心 API 的工具,可以在开发和调试 ASM 应用程序时使用。
1.2.3 org.objectweb.asm.commons
包提供了几个很有用的预定义类转换器,它们大多是基于核心 API 的。这个包包含在 asm-commons.jar中。
1.2.4 org.objectweb.asm.tree
包,位于asm-tree.jar 存档文件中,定义了基于对 象的 API,并提供了一些工具,用于在基于事件和基于对象的表示方法之间进行转换。
1.2.5 org.objectweb.asm.tree.analysis
包提供了一个类分析框架和几个预定义的 类 分析器,它们以树 API 为基础。这个包包含在 asm-analysis.jar 文件中。
1.3.1 asm-all和asm-parent
asm-all包含了asm-parent,asm-parent 包含了所有的依赖。
一般来讲,使用者希望导入一个总的jar,其中包含子项目的jar。但是asm-all目前只停留在version 5.2,而最新子项目版本已经是8.1,不推荐使用。
<dependency>
<groupId>org.ow2.asm</groupId>
<artifactId>asm-all</artifactId>
<version>5.2</version>
</dependency>
6.1.1 ASM Core Api核心类
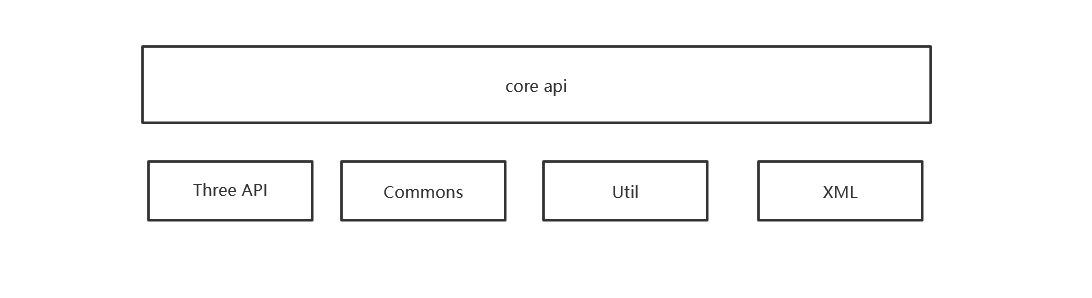
ASM包 由Core API,Thee API,Commons,Util,XML几部分组成如图所示:
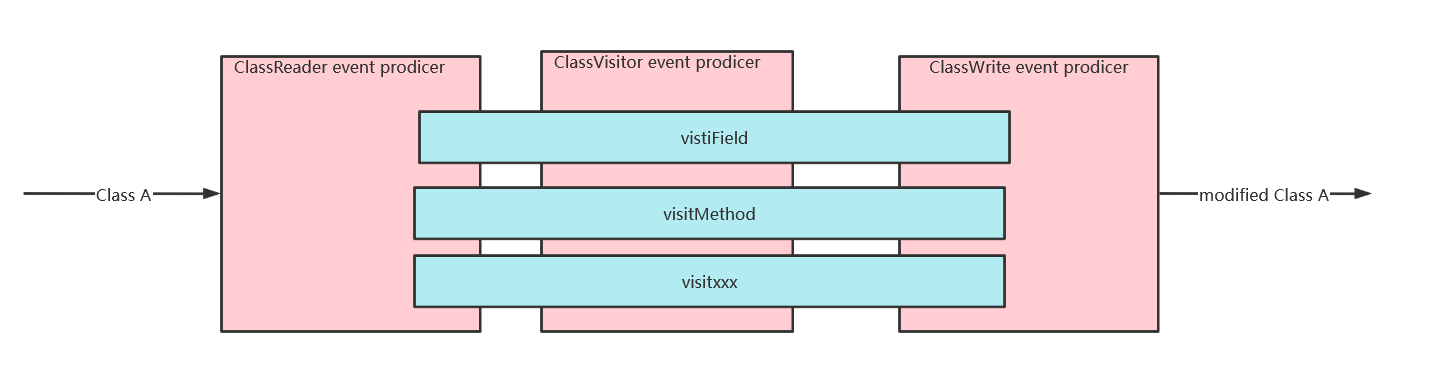
Core API 中最重要的就是三个类 ClassReader,ClassVisitor,ClassWriter,字节码操作都是跟这三个类打交道。
ClassReader:是字节码读取和分析引擎,负责解析Class类,采用类似于SAX的事件读取机制,每当有事件发生时,触发响应的ClassVisitor,MethodVisitor等做相应的处理。
ClassVisitor:是一个抽象类,使用时需要继承这个类,ClassRead的accept方法需要传入一个ClassVisitor对象,ClassReader在解析class文件的过程中遇到不同的节点时会调用ClassVisitor不同的visit方法,比如visitAttribute,visitInnerClass,visitField,visitMethod,visitEnd方法等
在上述的visit过程中,还会产生一些子过程,比如visiAnnotation会触发AnnotationVisitor的调用,visitMethod会触发MethodVisitor的调用,正是在这些visit的过程中,我们得以有机会去修改各个子节点的字节码。
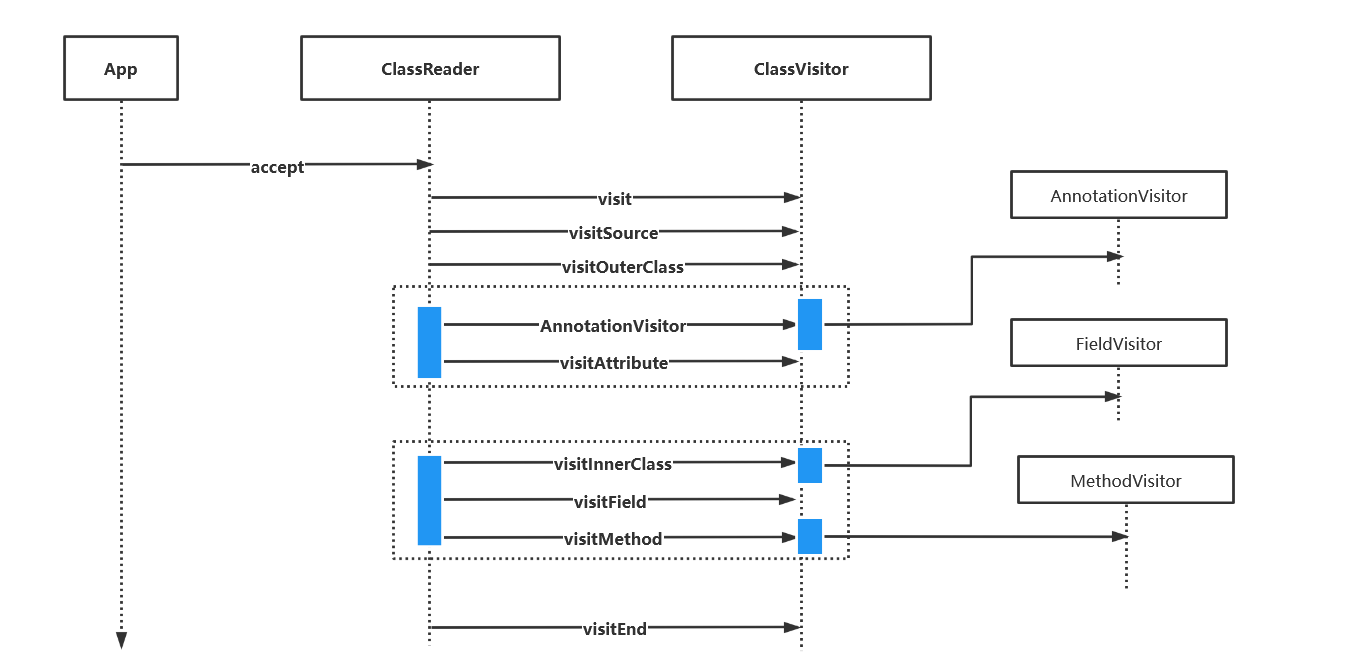
visit方法最先被调用,接着调用零次或一次visitSource方法,调用零次或一次visitOuterClass方法,接下来按任意顺序多次调用visitAnnotation和visitAttribute方法再按任意属性多次调用visitInnerClass,visitField,visiMethod方法,最后调用visiEnd。
调用时序图如下:
ClassWriter类是ClassVisitor抽象类的一个实现类,在ClassVisitor的visit方法中可以对原始的字节码做修改,ClassWriter的toByteArray方法则把最终修改字节码以byte数组的形式返回,简单示例如下:
public class FooClassVisitor extends ClassVisitor {
...
vistxxx()函数
...
}
ClassReader classReader = new ClassReader(bytes);
ClassWriter classWriter = new ClassWriter(classReader, ClassWriter.COMPUTE_MAXS|ClassWriter.COMPUTE_FRAMES);
FooClassVisitor fooClassVisitor = new FooClassVisitor(classWriter);
fooClassVisitor.accept(classWriter,0)
上面的代码中,ClassReader负责读取类文件的字节数组,accept调用之后ClassReader会把解析class文件过程中的事件源源不断的通知给ClassVisitor对象调用不同的visit方法。ClassVisitor可以在这些visit方法中对字节码进行修改ClassWriter可以生成最终修改过的字节码,这三个类的核心关系如下:
6.1.2 ASM操作字节码示例
6.1.2.1.访问方法和字段
ASM的访问者模式可以使我们很方便的访问文件中感兴趣的部分,比如类的字段,方法列表等,以下面的Test类为例:
public class Test {
public int a = 0;
public int b = 1;
public void test1() {
}
public void test2() {
}
}
使用javac编译上面的内容,然后将上面的class文件读取为byte数组,接下来代码示例:
import aj.org.objectweb.asm.*;
import java.io.*;
public class FooClassVisitor {
/**
* 输入流转为byte数组
* @param inStream 输入流
* @return byte[]
* @author compass
* @date 2022/10/24 2:26
* @since 1.0.0
**/
public static byte[] readInputStream(InputStream inStream) {
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
//创建一个Buffer字符串
byte[] buffer = new byte[1024];
//每次读取的字符串长度,如果为-1,代表全部读取完毕
int len = 0;
//使用一个输入流从buffer里把数据读取出来
try {
while ((len = inStream.read(buffer)) != -1) {
//用输出流往buffer里写入数据,中间参数代表从哪个位置开始读,len代表读取的长度
outStream.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
try {
outStream.close();
} catch (IOException e) {
e.printStackTrace();
}
//把outStream里的数据写入内存
return outStream.toByteArray();
}
public static void main(String[] args) throws FileNotFoundException {
File file = new File("Test.class路径");
FileInputStream in = new FileInputStream(file);
byte[] bytes = readInputStream(in);
ClassReader classReader = new ClassReader(bytes);
ClassWriter classWriter = new ClassWriter(0);
ClassVisitor classVisitor = new ClassVisitor( Opcodes.ASM5, classWriter){
@Override
public FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
System.out.println("field:"+name);
return super.visitField(access, name, descriptor, signature, value);
}
@Override
public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
System.out.println("method:"+name);
return super.visitMethod(access, name, descriptor, signature, exceptions);
}
};
classReader.accept(classVisitor,ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG);
}
}
输出结果如下:
field:a
field:b
method:<init>
method:test1
method:test2
值得注意的是:ClassReader类中的accept方法的第二个反射flags,是UI个位掩码,可以选择组合值有下面这些:
- SKIP_CODE: 跳过类文件中方法体中的code属性(方法字节码,异常表等)
- SKIP_DEBUG:跳过类文件中的调试信息,比如行号信息等
- SKIP_FRAMES:跳过StackMapTable属性
- EXPAND_FRAMES:展开StackMapTable属性
上面例子flags为:ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG ,因为这里只要求输出字段名和方法,覆写了visiField和visitMethod方法,不需要解析code属性和调试信息
6.1.2.2 新增字段
前面提到过 ClassVisitor是一个抽象类,我们可以选择只对关心的事情进行处理,对于不关心的事情我们可以选择不覆写
前面介绍的都是Core API的用法,使用Tree API的方式也可以完成同样的效果,代码如下所示:
我们现在使用 Tree API往Test中新增一个字段 username
public static void main(String[] args) throws Exception {
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassNode cn = new ClassNode();
cr.accept(cn,ClassReader.SKIP_DEBUG|ClassReader.SKIP_CODE);
FieldNode fn = new FieldNode(Opcodes.ACC_PUBLIC, "show", "java/lang/String", null, null);
cn.fields.add(fn);
ClassWriter cw = new ClassWriter(0);
cn.accept(cw);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
6.1.2.3 新增方法
新增一个方法如下:
public void login(int var1, String var2) {
}
public static void main(String[] args) throws Exception {
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassWriter cw = new ClassWriter(0);
ClassVisitor cv = new ClassVisitor(Opcodes.ASM5, cw) {
@Override
public void visitEnd() {
super.visitEnd();
MethodVisitor mv = cv.visitMethod(Opcodes.ACC_PUBLIC, "login", "(ILjava/lang/String;)V", "", null);
if (mv!=null) mv.visitEnd();
}
};
cr.accept(cv,ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
6.1.2.4 移除方法和字段
假设有如下类:
public class Test {
public int a = 0;
public int b = 1;
public void show(int a,String b) {
}
}
我们需要删除字段a和方法show
public static void main(String[] args) throws Exception{
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassWriter cw = new ClassWriter(0);
ClassVisitor cv = new ClassVisitor(Opcodes.ASM5, cw) {
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
// 如果方法名称为show则返回一个null
if (name.equals("show")){
System.out.println("删除show方法");
return null;
}
return super.visitMethod(access, name, desc, signature, exceptions);
}
@Override
public FieldVisitor visitField(int access, String name, String desc, String signature, Object value) {
// 如果字段名称为a就删除掉
if (name.equals("a")){
System.out.println("删除a字段");
return null;
}
return super.visitField(access, name, desc, signature, value);
}
};
cr.accept(cv,ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
6.1.2.4 修改方法内容
前面我们有接触到MethodVisitor类,这个类主要用来处理访问一个方法触发的事件,与ClassVisitor一样,他有很多visit方法,这些方法也有一定的调用顺序。
(visiParameter)*
[visitAnnotationDefault]
(visitAnnotation | visiParameterAnnotation|visiAttaibute)*
[
visitCode(
visitFrame | visit<i>X</i>Insn | visiLabel | visiInsnAnnotation | visitLocalVariableAnnotation | visiLineNumber
)*
]
visiEnd
其中visiCode和visiMax可以作为方法体中具体字节码的开始和结束,visiEnd是MethodVisitor所有事件的结束,以下面的方法为例,把方法的返回值改为a+100
public class Test {
public int add(int a) {
return a;
}
}
public static void main(String[] args) throws Exception {
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassWriter cw = new ClassWriter(0);
ClassVisitor cv = new ClassVisitor(Opcodes.ASM5, cw) {
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
// 删除掉原有的add方法
if (name.equals("add")){
return null;
}
return super.visitMethod(access, name, desc, signature, exceptions);
}
@Override
public void visitEnd() {
MethodVisitor mv = cv.visitMethod(Opcodes.ACC_PUBLIC, "add", "(I)I", null, null);
mv.visitCode();
mv.visitIincInsn(Opcodes.ILOAD,1);
mv.visitIincInsn(Opcodes.BIPUSH,100);
mv.visitInsn(Opcodes.IADD);
mv.visitInsn(Opcodes.IRETURN);
// 触发计算
mv.visitMaxs(0,0);
mv.visitEnd();
}
};
cr.accept(cv,0);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
6.1.2.4 AdiviceAdpater使用
AdiviceAdpater是一个抽象类,继承于MethodVisitor,可以很方便的在方法开始和结束前插入代码,他的两个核心方法如下所示:
onMethodEnter:方法开始或构造器方法中父类的构造器调用以后被回调
onMethodExit:正常退出和异常退出时被调用,正常退出指的是遇到RETRUN,ARETRUN,LRETRUN等方法正常退出的情况,异常退出指的是遇到ATHROW指令时,有异常退出方法的情况。
public static void main(String[] args) throws Exception {
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES|ClassWriter.COMPUTE_MAXS);
ClassVisitor cv = new ClassVisitor(Opcodes.ASM5, cw) {
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
if (!name.equals("foot")){
return mv;
}
return new AdviceAdapter(Opcodes.ASM5,mv,access,name,desc) {
@Override
protected void onMethodEnter() {
System.out.println("enter:"+name);
super.onMethodEnter();
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
mv.visitLdcInsn("enter:"+name);
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
}
@Override
protected void onMethodExit(int opcode) {
System.out.println("exit:"+name);
super.onMethodExit(opcode);
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
if (opcode == Opcodes.ATHROW){
mv.visitLdcInsn("error exit:"+name);
}else {
mv.visitLdcInsn("normal exit:"+name);
}
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
}
} ;
}
};
cr.accept(cv,0);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
6.1.2.5 给方法加上 try-cache
很显然上面的代码无法捕获异常时输出的 error exit ,比如把 foot的代码稍作修改一下
public void foot(){
System.out.println("step-1");
int number = 2/0;
System.out.println("step-2");
}
经过这样的改写后,并没输出预期的 error exit,因为在字节码中并没有显示的ATHROW指令抛出异常,自然无法添加独有的语句,为了达到这个效果,需要将方法体用try-finaly包裹起来
这里需要介绍新的类,Label类,与他的英文含义一样,可以给字节码指令打标签,标记特定的字节码位置,用于后续的跳转等,新增一个Label可以用MethodVisitor的visitLabel方法,如下所示:
public static void main(String[] args) throws Exception {
String fileName = "compass.token.pocket.com.test.Test";
String outPath = "";
ClassReader cr = new ClassReader(fileName);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES|ClassWriter.COMPUTE_MAXS);
ClassVisitor cv = new ClassVisitor(Opcodes.ASM5, cw) {
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
if (!name.equals("foot")){
return mv;
}
Label startLabel = new Label();
return new AdviceAdapter(Opcodes.ASM5,mv,access,name,desc) {
@Override
protected void onMethodEnter() {
System.out.println("enter:"+name);
super.onMethodEnter();
mv.visitLabel(startLabel);
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
mv.visitLdcInsn("enter:"+name);
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
}
@Override
public void visitMaxs(int maxStack, int naxLocals) {
// 生成异常表
Label endLabel = new Label();
mv.visitTryCatchBlock(startLabel,endLabel,endLabel,null);
mv.visitLabel(endLabel);
// 生成异常处理代码块
finallyBlock(Opcodes.ATHROW);
mv.visitInsn(Opcodes.ATHROW);
super.visitMaxs(maxStack, naxLocals);
}
private void finallyBlock(int code) {
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
if (code == Opcodes.ATHROW){
mv.visitLdcInsn("error exit:"+name);
}else {
mv.visitLdcInsn("normal exit:"+name);
}
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
}
@Override
protected void onMethodExit(int opcode) {
super.onMethodExit(opcode);
// 处理正常返回的场景
if (opcode!=Opcodes.ATHROW) finallyBlock(opcode);
}
} ;
}
};
cr.accept(cv,0);
byte[] bytes = cw.toByteArray();
FileOutputStream stream = new FileOutputStream(new File(outPath));
stream.write(bytes);
stream.flush();
stream.close();
}
经过处理最终生成的字节码就如下所示:
public void foot() {
try {
System.out.print("enter:foot");
System.out.println("step-1");
int number = 2 / 0;
System.out.println("step-2");
System.out.print("normal exit:foot");
} catch (Throwable var3) {
System.out.print("error exit:foot");
throw var3;
}
}
7.java Instrumentation 原理
7.1 Instrumentation简介
这一小节我们来介绍 Instrumentation 机制, Instrumentation 看起来比较神秘,日常中很多工具都是基于 Instrumentation 来实现的,例如:
- APM产品:Poinpoint,Sky Walking,newrelic等
- 热部署,intellij idea的HotSwap,Jrebel等
- java诊断工具:Arthas 等
jdk从1.5版本开始引入了java.lang.instrument包,开发者可以更方便的实现字节码增强,其核心功能是由 java.lang.Instrumentation 提供,这个接口的方法提供了注册类文件转换器,获取所有已加载的类等功能,允许我们堆已加载和未加载的类进行修改,实现aop,性能监控等功能,Instrumentation 的常用方法如下所示:
**void addTransformer(ClassFileTransformer transformer, boolean canRetransform) **
void retransformClasses(Class<?>… classes) throws UnmodifiableClassException
Class[] getAllLoadedClasses()
boolean isRedefineClassesSupported()
addTransformer方法给 Instrumentation 注册一个类型为 ClassFileTransformer 的类文件转换器,ClassFileTransformer 只有一个方法 transfrom方法,接口定义如下:
byte[] transform( ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer ) throws IllegalClassFormatException;
loader: 要转换的类的类加载器
className:表示当前加载的类全限定名称
classBeingRedefined:如果这是由重定义或重新转换触发的,则*被重新定义或重新转换的类;*如果这是一个类加载
protectionDomain:被定义或重定义的类的保护域
classfileBuffer:待加载类文件字节数组
其中className参数表示当前加载类的全限定类名,classFIleBuffer参数是待加载类文件的字节数组,掉用addTransformer注册tranformer以后后续所有的jvm加载类都会被tranform方法拦截,这个方法接收原类文件字节数组,在这个方法中可以对这个类文件字节数组做修改,然后返回转换过后的class字节码数组,如果tranform返回的是null,表示不对此类做任何处理,由jvm加载这个修改过后的类文件,如果返回的不是null,jvm会应用返回的字节数组替换原来的字节数组。
Instrumentation接口的retransformClass方法堆JVM已经加载过的类进行重新触发加载,getAllLoadedClasses方法用于当前JVM加载的所有类对象,isRetransformCoassSupported方法返回一个boolean值表示当前JVM是否支持类重新转换的特性,Instrumentation有2种使用方式,一种是在JVM启动运行的时候添加一个Agent的jar包,第二种方式是在JVM运行以后的任意时刻通过AttachAPI远程加载Agent的jar包。
7.2 Instrumentation与 -javaagent启动参数
Instrumentation的第一种使用方式是通过JVM的启动参数来启动一个定向的使用方式如下:
java -javaagent:myAgent.jar MyMain
为了能让JVM识别到Agent的入口类,需要在jar包的MANIFEST.MF文件中指定Premain-Class等信息,一个典型的生成好的MANIFEST.MF内容如下所示:
Premain-class:me.geek01.javaagent.AgentMain
Agent-Class:me.geek01.javaagent.AgentMain
Can-Redfine-Classes:true
Can-Retransform-Classes:true
其中AgentMain类有一个静态的premain方法,JVM在类加载时会先执行AgentMain类的premain方法,再执行java程序本身的main方法,这就是premain名字的来源,在premain方法中可以对class文件进行修改,这种机制可以称为是虚拟机级别的AOP,无须对原有的应用做任何修改就可以实现类的动态修改和增强。
premain的方法签名如下所示:
public static void premain(String agentArgument,InstrumentRation instrumentation) throws Execpton
第一个参数agentArgument是agent的启动参数,可以在jvm启动时指定以下面的启动方式为例,他的agentArgument的值为 “appId:agent-demo.agentType:singleJar”
java -javaagent:<jarfile>=appIdLagent-demo,agentTypeLsingleJar test.jar
第二个参数instrumentation是java.lang,instrument,Instrumentation的实例,可以通过addTransformer方法设置一个ClassFIleTransformer
静态Instrumentation的处理过程如下,JVM启动后会执行Agent.jar总的premain方法,在premain中可以调用Instrumentation对象的addTranformer方法注册ClassFIleTransformer。当JVM加载类时,会将类文件的字节码数组专递给transformer的transform方法,在transform方法中可以对类文件进行解析和修改,随后jvm就可以加载转换过后的类文件,整个流程如下图所示
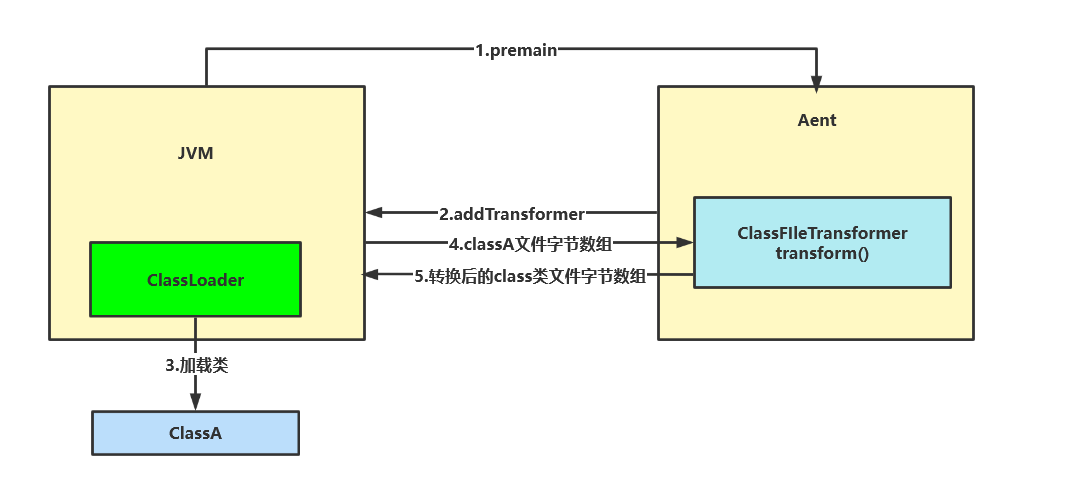
下面使用Instrumentation的方式实现一个简单的方法调用堆栈跟踪,在每个方法计入和结束的地方都打印一行日志,通过调用过程实现追踪效果,测试代码如下:
public class MyTest {
public static void main(String[] args){
}
public void foo(){
barOne();
barTwo();
}
private void barTwo() {
}
private void barOne() {
}
}
这里需要用到之前的ASM知识,新建一个AdviceAdpter的子类,MyMethodVisitor,覆写onMethodEnter,onMethodExit方法,核心实现逻辑如下:
public class MyMethodVisitor extends AdviceAdapter {
protected MyMethodVisitor(int api, MethodVisitor mv, int access, String name, String desc) {
super(api, mv, access, name, desc);
}
@Override
protected void onMethodEnter() {
// 在方法开始前插入 <<<enter xx
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
mv.visitLdcInsn(" <<<enter xx");
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
super.onMethodEnter();
}
@Override
protected void onMethodExit(int opcode) {
// 在方法结束前插入 <<<enter xx
mv.visitFieldInsn(Opcodes.GETSTATIC,"java/lang/System","out","Ljava/lang/PrintStream");
mv.visitLdcInsn(" <<<exit xx");
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL,"java/io/PrintSteam","print","(Ljava/lang/String;)V",false);
super.onMethodExit(opcode);
}
}
接下来新建一个MyClassFileTransformer,这个类实现了 ClassFileTransformer接口,在ClassFileTransformer接口中使用ASM实现对clss文件的转换
public class MyClassFileTransformer implements ClassFileTransformer {
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] bytes) throws IllegalClassFormatException {
try {
className = className.replaceAll("/",".");
System.out.println("className = "+className);
String agentTestName = "com.comapss.app.test.AgentTest";
if (!agentTestName.equals(className)){
return null;
}
System.out.println("className* = "+className);
ClassReader cr = new ClassReader(bytes);
ClassWriter cw = new ClassWriter(cr, ClassWriter.COMPUTE_FRAMES);
MyClassVisitor cv = new MyClassVisitor(cw);
cr.accept(cv,ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG);
return cw.toByteArray();
}catch (Exception e){
e.printStackTrace();
System.out.println("exception:"+className);
return null;
}
}
}
接下来新建一个 AgentMain类,在其中实现premain方法的逻辑,将MyClassFileTransformer注册到 Instrumentation 中
public class AgentMain {
public static void premain(String agentArgs, Instrumentation instrumentation) {
instrumentation.addTransformer(new MyClassFileTransformer(),true);
}
}
接下来将 这个项目打包为jar包,maven配置如下
<build>
<finalName>agent</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>single</goal>
</goals>
<phase>package</phase>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<!--自动添加META-INF/MANIFEST.MF -->
<manifest>
<addClasspath>true</addClasspath>
</manifest>
<manifestEntries>
<Agent-Class>com.compass.core.AgentMainRun</Agent-Class>
<Premain-Class>com.compass.core.AgentMainRun</Premain-Class>
<Can-Redefine-Classes>true</Can-Redefine-Classes>
<Can-Retransform-Classes>true</Can-Retransform-Classes>
</manifestEntries>
</archive>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
运行: java -javaagent:agent-jar-with-dependencies.jar -jar agent-jar-with-dependencies.jar
7.3 JVM Attach API介绍
在jdk5中,只能在jvm启动时指定一个javaagent,在premain中操作字节码,这种 Instrumentation 的局限性比较大,从jdk6开始就引入了 Attach API ,可以在jvm启动后任意时刻,通过 Attach API 远程加载 Agent的jar包,比如大名鼎鼎的arthas就是基于Attach API实现的,加载agent的jar包只是Attach API的功能之一,我们常用的 jstack,jps,jamp都是使用Attach API来实现的。
7.4 JVM Attach API的基本使用
下面以以一个实际例子来演示
在测试代码中有一个main方法,每三秒输出foo方法的返回值,接下来动态 Attach上MyTestMain进程,修改foo的字节码,让方法foo返回50
public class MyTestMain {
public static void main(String[] args) throws InterruptedException {
while (true){
System.out.println(foo());
TimeUnit.SECONDS.sleep(2);
}
}
public static int foo(){
return 100;
}
}
1.编写自定义的MyClassFileTransformer
public class MyClassFileTransformer implements ClassFileTransformer {
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] bytes) throws IllegalClassFormatException {
try {
className = className.replaceAll("/",".");
System.out.println("className = "+className);
if (className.equals("com.compass.core.agentmain.MyTestMain")){
ClassReader cr = new ClassReader(bytes);
ClassWriter cw = new ClassWriter(cr,ClassWriter.COMPUTE_FRAMES);
ClassVisitor cv = new MyClassVisitor(cw);
cr.accept(cv,ClassReader.SKIP_CODE|ClassReader.SKIP_DEBUG);
return cw.toByteArray();
}else {
return bytes;
}
}catch (Exception e){
e.printStackTrace();
System.out.println("exception:"+className);
return null;
}
}
}
2.MyMethodVisitor
public class MyMethodVisitor extends AdviceAdapter {
protected MyMethodVisitor(int api, MethodVisitor mv, int access, String name, String desc) {
super(api, mv, access, name, desc);
}
@Override
protected void onMethodEnter() {
mv.visitIntInsn(Opcodes.BIPUSH,50);
mv.visitInsn(Opcodes.RETURN);
}
}
3.MyClassVisitor
public class MyClassVisitor extends ClassVisitor {
public MyClassVisitor(ClassVisitor classVisitor) {
super(Opcodes.ASM5,classVisitor);
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
if (name.equals("foo")) {
return new MyMethodVisitor(Opcodes.ASM5,mv,access,name,desc);
}else {
return mv;
}
}
}
4.AgentMainRun
public class AgentMainRun {
public static void agentmain(String agentArgs, Instrumentation instrumentation){
System.err.println(" agentMain called");
instrumentation.addTransformer(new com.compass.core.agentmain.MyClassFileTransformer());
Class[] classList = instrumentation.getAllLoadedClasses();
for (int i = 0; i < classList.length; i++) {
Class clazz = classList[i];
System.err.println(" className="+clazz.getName());
if (clazz.getName().equals("com.compass.core.agentmain.MyTestMain")){
System.err.println("className:"+clazz.getSimpleName());
try {
instrumentation.retransformClasses(clazz);
System.err.println(MyTestMain.foo());
break;
}catch (Exception e){
e.printStackTrace();
}
}
}
}
}
5.AttachMainTest
public class AttachMainTest {
public static void main(String[] args) throws Exception {
String jar = "D:\\IDE2019\\code\\agents\\agent\\target\\agent.jar";
System.out.println("running JVM start ");
List<VirtualMachineDescriptor> list = VirtualMachine.list();
for (VirtualMachineDescriptor vmd : list) {
//如果虚拟机的名称为 xxx 则 该虚拟机为目标虚拟机,获取该虚拟机的 pid
//然后加载 agent.jar 发送给该虚拟机
System.out.println(vmd.displayName());
if (vmd.displayName().endsWith("com.comapss.app.test.AttachMain")) {
VirtualMachine virtualMachine = VirtualMachine.attach(vmd.id());
virtualMachine.loadAgent(jar);
virtualMachine.detach();
}
}
}
}
因为是夸进程进行通信,Attach的发起端是一个独立的java程序,这个java程序会调用 VirtualMachine.attach 方法开始和目标JVM进行夸进程通信。
8.JSR 269 插件注解化处理原理
注解第一次是在jdk1.5中引入进来的,当时的开发者只能在运行期间处理注解,jdk1.6引入了JSR 269 规范,允许开发者在编译期间处理注解,可以读取,修改,添加,抽象语法树中的内容,只要想像力够丰富,可以完成java很多不支持的新特性,甚至创建新的语法糖。
javac的前2个节点parse和enter两个阶段,生成了抽象语法树,接下来annotation procss(注解处理节点)JSR 就发生在这个阶段,经过注解处理有的输出一个修改过后的AST,交给下游继续处理,最终生成class文件。
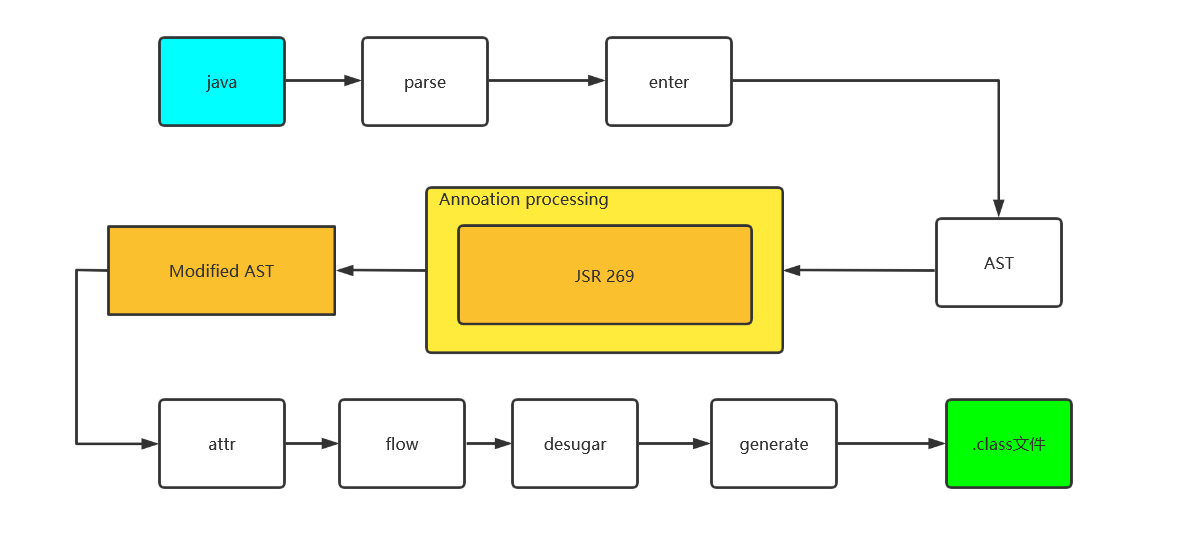
实现注解处理器的第一步是继承 Abstract Processor类,实现process方法,如下面的清单所示: 需要借助jdk的 tools.jar
8.1 自定义 AbstractProcessor
@SupportedAnnotationTypes("me.annotations.Data")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class DataAnnotationProcessor extends AbstractProcessor {
private JavacTrees javacTrees;
private TreeMaker treeMaker;
private Names names;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
javacTrees = JavacTrees.instance(processingEnv);
Context context = ((JavacProcessingEnvironment) processingEnv).getContext();
treeMaker = TreeMaker.instance(context);
names = Names.instance(context);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
return false;
}
}
@SupportedAnnotationTypes 表示支持的注解的权限的名称
@SupportedSourceVersion 表示支持的最高jdk版本
AbstractProcessor有两个核心的方法 init和 pocess方法来挖槽一些初始化操作,比如核心的 JavacTrees,TreeMaker,Names等,这个三个类在后面会经常用到。process 用来做语法树的修改。
8.2 抽象语法树API
抽象语法树的核心操作类是: JCTree,TreeMaker,Names
- Names类提供了访问标识符的方法
- JCTree语法树的元素基础类
- TreeMaker 封装了创建语法树节点的方法
Names介绍:
Names类提供了访问标识符Name的方法,它最常用的是fromString,用来从一个字符串获取Name对象
public Name fromString(String name) {
return this.table.fromString(name);
}
// 例如: Name name = names.fromString("this");
JCTree介绍:
JCTree是语法树元素的基类,实现了Tree接口,他有两个核心的字段,pos和type字段,其中,pos字段表示当前节点在语法树中的位置,type表示节点类型,JCTree的子类众多,场景的有:JCExpression,JCMethod,JCModifiers接下来介绍几个常用的子类
- JCStatement 类用来声明语句,常见的子类有,JCReturn(表示return语句),JCBlock(表示代码块),JCCLassDecl,JCVariable,Deel,JCTry,JCIf等
JCBlock部分源码如下:
public static class JCBlock extends JCTree.JCStatement implements BlockTree {
public long flags;
public List<JCTree.JCStatement> stats;
public int endpos = -1;
protected JCBlock(long var1, List<JCTree.JCStatement> var3) {
this.stats = var3;
this.flags = var1;
}
其中flags表示代码块的访问标记,state字段是一个 JCStatement类的列表,表示代码块内的所有语句
JCCLassDecl: 表示类定义元素的节点,它的部分源码如下所示:
public static class JCClassDecl extends JCTree.JCStatement implements ClassTree {
// 表示方法上的修饰符:public,private等
public JCTree.JCModifiers mods;
// 表示类名
public Name name;
// 表示泛型参数列表
public List<JCTree.JCTypeParameter> typarams;
// 表示继承父类信息
public JCTree.JCExpression extending;
// 表示实现接口列表信息
public List<JCTree.JCExpression> implementing;
// 表示所有的变量和方法列表
public List<JCTree> defs;
// 表示包名和类名
public ClassSymbol sym;
JCVariableDecl: 类表示变量语法树的节点:
public static class JCVariableDecl extends JCTree.JCStatement implements VariableTree {
public JCTree.JCModifiers mods;
public Name name;
public JCTree.JCExpression nameexpr;
public JCTree.JCExpression vartype;
public JCTree.JCExpression init;
public VarSymbol sym;
protected JCVariableDecl(JCTree.JCModifiers var1, Name var2, JCTree.JCExpression var3, JCTree.JCExpression var4, VarSymbol var5) {
// 表示变量的访问修饰符 public,private等
this.mods = var1;
// 表示变量名
this.name = var2;
// 表示变量类型
this.vartype = var3;
// 表示变量的初始化语句,可能是一个固定值也可能是一个表达式
this.init = var4;
this.sym = var5;
}
}
JCTry类表示 try-cache-finaly 语句
public static class JCTry extends JCTree.JCStatement implements TryTree {
// try 语句块
public JCTree.JCBlock body;
// 是JCCatch对象列表,表示多个try语句块
public List<JCTree.JCCatch> catchers;
// 表示finaly语句块
public JCTree.JCBlock finalizer;
public List<JCTree> resources;
public boolean finallyCanCompleteNormally;
}
JCIf 表示if else语句
public static class JCIf extends JCTree.JCStatement implements IfTree {
// 表示条件语句
public JCTree.JCExpression cond;
// 表示if部分
public JCTree.JCStatement thenpart;
// 表示else部分
public JCTree.JCStatement elsepart;
}
JCForLoop 表示循环语句:
public static class JCForLoop extends JCTree.JCStatement implements ForLoopTree {
// 表示循环的初始化
public List<JCTree.JCStatement> init;
// 表示循环条件
public JCTree.JCExpression cond;
// 每次循环后的操作表达式
public List<JCTree.JCExpressionStatement> step;
// 循环体
public JCTree.JCStatement body;
}
JCExpression: 表示表达式语法树节点
- JCAssing: 复制表达式
- JCIdent:标识符表达式
- JCBinary:二元运算符表达式
- JCLiteral:字面量运算符
JCMethodDecl: 用来表示方法的定义,部分源码如下所示:
public static class JCMethodDecl extends JCTree implements MethodTree {
public JCTree.JCModifiers mods;
public Name name;
public JCTree.JCExpression restype;
public List<JCTree.JCTypeParameter> typarams;
public JCTree.JCVariableDecl recvparam;
public List<JCTree.JCVariableDecl> params;
public List<JCTree.JCExpression> thrown;
public JCTree.JCBlock body;
public JCTree.JCExpression defaultValue;
public MethodSymbol sym;
protected JCMethodDecl(JCTree.JCModifiers var1, Name var2, JCTree.JCExpression var3, List<JCTree.JCTypeParameter> var4, JCTree.JCVariableDecl var5, List<JCTree.JCVariableDecl> var6, List<JCTree.JCExpression> var7, JCTree.JCBlock var8, JCTree.JCExpression var9, MethodSymbol var10) {
// 表示方法的修饰符 public,private等
this.mods = var1;
// 表示方法名
this.name = var2;
// 表示返回类型
this.restype = var3;
// 表示方法泛型参数列表
this.typarams = var4;
// 表示方法参数列表
this.params = var6;
this.recvparam = var5;
// 表示方法抛出的异常
this.thrown = var7;
// 表示方法体
this.body = var8;
this.defaultValue = var9;
this.sym = var10;
}
}
TreeMaker:介绍
TreeMaker 类封装了创建语法树节点的方法,是处理注解中最核心的类,前面介绍过,JCTree包含一个pos字段表示当前语法树节点在抽象语法树中的位置,所以我们不能能够new关键字来创建JCTree,只能使用包含了抽象语法树上下文件的 TreeMaker对象来创建JCTre,他常用的方法有下面这些:
- TreeMaker.Modifers 用于生成一个标记访问 JCModifiers
- TreeMaker.Binary 用于生成二元操作符 JCBinary
- TreeMaker.Ident 用于创建标识符语法树抽象节点 JCLIdent
- TreeMaker.Select 用于创建一个字段或方法访问
- TreeMaker.Return 用于创建Return语句语法树节点
- TreeMaker.Assing 用于生成赋值语法树节点
- TreeMaker.Block 用于生成代码块语法树节点JCblock
- TreeMaker.Exec 创建执行这个语句的语法树节点返回宇哥JCExpressionStatement对象
- TreeMaker.VarDef 用于生成变量语法树节点 JCVariableDecl
- TreeMaker.MethodDef 用于生成方法语法树节点 JCMethodDecl
8.3 自定义简单Lombok
使用的是idea工具进行开发,使用的jdk版本为1.8,因为我们是自己手写的idea提示会报错,但是能正常运行,因为lombok是idea针对于他有插件提示,我们的没有,但是也不影响正常使用。
1.我们需要使用到jdk安装路径下lib包下的tools.jar,我们可以收到加入到项目依赖,也可以在maven中直接引入。我们直接使用idea新建一个普通的maven项目,然后配置如下,最后将这个项目打包一下,在别的项目中引入即可。
1.maven配置
还有一个是 com.google.auto.service 这个是使用SPI机制的一个依赖,关于spi可以自行百度了解,这里就不再进行展开。
关键核心接口:AbstractProcessor,这个就是在编译期处理注解的一个接口,然后我们可以通过实现这个接口通过修改字节码文件,最终在字节码文件中生成get和set方法。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>lombok</groupId>
<artifactId>com.compass.lombok</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.sun</groupId>
<artifactId>tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>C:/Program Files/Java/jdk1.8.0_251/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.0-rc5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.自定义Data注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Data {
}
3.然后写一个 DataAnnotationProcessor 继承AbstractProcessor即可,在注解处理节点去修改抽象语法树
import com.compass.lombok.annotation.Data;
import com.google.auto.service.AutoService;
import com.sun.source.tree.Tree;
import com.sun.tools.javac.api.JavacTrees;
import com.sun.tools.javac.code.Flags;
import com.sun.tools.javac.code.Type;
import com.sun.tools.javac.processing.JavacProcessingEnvironment;
import com.sun.tools.javac.tree.JCTree;
import com.sun.tools.javac.tree.TreeMaker;
import com.sun.tools.javac.tree.TreeTranslator;
import com.sun.tools.javac.util.*;
import javax.annotation.processing.*;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import java.util.Set;
/**
* @author compass
* @date 2022-10-13
* @since 1.0
**/
@AutoService(Processor.class)
@SupportedAnnotationTypes("com.compass.lombok.annotation.Data")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class DataAnnotationProcessor extends AbstractProcessor {
private JavacTrees javacTrees;
private TreeMaker treeMaker;
private Names names;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
Context context = ((JavacProcessingEnvironment) processingEnv).getContext();
javacTrees = JavacTrees.instance(context);
treeMaker = TreeMaker.instance(context);
names = Names.instance(context);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
Set<? extends Element> set = roundEnv.getElementsAnnotatedWith(Data.class);
for (Element element : set) {
javacTrees.getTree(element).accept(new TreeTranslator(){
@Override
public void visitClassDef(JCTree.JCClassDecl jcClassDecl) {
jcClassDecl.defs.stream()
.filter(it->it.getKind().equals(Tree.Kind.VARIABLE))
.map(it->(JCTree.JCVariableDecl) it).forEach(it->{
jcClassDecl.defs = jcClassDecl.defs.prepend(genGetterMethod(it));
jcClassDecl.defs = jcClassDecl.defs.prepend(genSetterMethod(it));
});
super.visitClassDef(jcClassDecl);
}
});
}
return true;
}
private JCTree.JCMethodDecl genGetterMethod(JCTree.JCVariableDecl jcVariableDecl){
JCTree.JCIdent _this = treeMaker.Ident(names.fromString("this"));
Name name = jcVariableDecl.getName();
JCTree.JCFieldAccess select = treeMaker.Select(_this, name);
JCTree.JCReturn returnStatement = treeMaker.Return(select);
ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();
statements.append(returnStatement);
JCTree.JCModifiers modifiers = treeMaker.Modifiers(Flags.PUBLIC);
Name getMethodName = getGetMethodName(jcVariableDecl.getName());
JCTree.JCExpression returnMethodType = jcVariableDecl.vartype;
JCTree.JCBlock body = treeMaker.Block(0, statements.toList());
List<JCTree.JCTypeParameter> methodGenericParamList = List.nil();
List<JCTree.JCVariableDecl> parameterList = List.nil();
List<JCTree.JCExpression> throwList = List.nil();
return treeMaker.MethodDef(modifiers, getMethodName, returnMethodType, methodGenericParamList, parameterList, throwList, body, null);
}
public JCTree.JCMethodDecl genSetterMethod(JCTree.JCVariableDecl jcVariableDecl){
JCTree.JCIdent _this = treeMaker.Ident(names.fromString("this"));
Name name = jcVariableDecl.getName();
JCTree.JCFieldAccess select = treeMaker.Select(_this, name);
JCTree.JCAssign statementAssign = treeMaker.Assign(select, treeMaker.Ident(jcVariableDecl.getName()));
JCTree.JCExpressionStatement statement = treeMaker.Exec(statementAssign);
ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();
statements.append(statement);
JCTree.JCVariableDecl params = treeMaker.VarDef(
treeMaker.Modifiers(Flags.PARAMETER, List.nil()),
jcVariableDecl.name,
jcVariableDecl.vartype,
null
);
JCTree.JCModifiers modifiers = treeMaker.Modifiers(Flags.PUBLIC);
Name setMethodName = getSetMethodName(jcVariableDecl.getName());
JCTree.JCExpression returnMethodType = treeMaker.Type(new Type.JCVoidType());
JCTree.JCBlock body = treeMaker.Block(0, statements.toList());
List<JCTree.JCTypeParameter> methodGenericParamList = List.nil();
List<JCTree.JCVariableDecl> parameterList = List.of(params);
List<JCTree.JCExpression> throwList = List.nil();
return treeMaker.MethodDef(modifiers, setMethodName, returnMethodType, methodGenericParamList, parameterList, throwList, body, null);
}
private Name getGetMethodName(Name name){
String filedName = name.toString();
return names.fromString("get"+filedName.substring(0,1).toUpperCase()+filedName.substring(1));
}
private Name getSetMethodName(Name name){
String filedName = name.toString();
return names.fromString("set"+filedName.substring(0,1).toUpperCase()+filedName.substring(1));
}
}
其实到这里就编写完毕了,这里去动态修改字节码,然后生成了get和set方法,至于其他的方法那就后面再说,此案例参照于《深入jvm字节码》进行编写。
最后在maven项目中打包,然后在你需要的项目引入即可,最后通过spi机制和注解处理机制,在你的项目中找到有标注Data注解类,的时候,就生成对应的get和set方法
9.软件破解和防破解
1.软件破解
java程序很多都是可以破解的,比如idea,我们java程序员大多数都是,用的破解版,当然我们个人使用没有关系,但是在公司还是用正版。
破解方式1:直接找到源代码,然后反编译class,然后在修改class,重新启动软件,达到破解的目的
破解方式2:基于我们之前学的javaagent,使用代理的方式,修改核心字节码内容,达到破解的目的,比如说找到,软件中对应的权限许可方法,直接将返回值改为true即可,我们就可以正常使用。
2.软件防止破解
软件防止破解1:对生成的class字节码进行加密,对破解的难度提高
软件防止破解2:对应代码进行混淆,执行流程混淆,变量名,类名,方法名等混淆

![[附源码]计算机毕业设计Python仓储综合管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/000e30ce3be64f25b2de4c8d8bab8124.png)