目录
01. Linux线程概念
01.1 什么是线程
01.1.1 轻量级进程ID与进程ID之间的区别
01.1.2 总结(重点)
01.2 线程的优点
01.3 线程的缺点
01.4 线程异常
01.5 线程用途
02. Linux进程VS线程
02.1 进程和线程
02.2 关于多线程和多进程编程
03. Linux线程控制 -- POSIX线程库
03.01 POSIX线程库
03.02 pthread_create
编辑
03.03 什么是LWP
03.04 LWP与pthread_create创建的线程之间的关系
03.05 pthread_join
03.06 Linux查看线程方式
03.07 关于C++线程使用
03.08 线程ID及进程地址空间布局
03.09 线程终止
03.10 pthread_exit
03.11 pthread_cancel
03.12 线程等待
03.13 分离线程
04. Linux线程互斥
04.1 进程线程间的互斥相关背景概念
什么是线程互斥,为什么需要互斥
04.2 互斥量mutex
并发编程中通常会遇到三个问题 原子性问题,可见性问题,有序性问题
04.3 互斥量的接口
初始化互斥量
销毁互斥量
互斥量加锁和解锁
调用 pthread_ lock 时,可能会遇到以下情况:
04.4 关于实现互斥锁
无锁化编程有哪些常见方法
05. 可重入VS线程安全
05.1 概念
05.2 常见的线程不安全的情况
05.3 常见的线程安全的情况
05.4 常见不可重入的情况
05.5 常见可重入的情况
05.6 可重入与线程安全联系
05.7 可重入与线程安全区别
06. 常见锁概念
06.1 死锁
06.2 死锁四个必要条件
06.3 避免死锁
06.4 死锁的处理都有哪些方法
07. Linux线程同步
07.1 条件变量
信号量实现与条件变量有什么区别
07.2 同步概念与竞态条件
07.3 条件变量函数
初始化
销毁
等待条件满足
唤醒等待
为什么 pthread_cond_wait 需要互斥量?
08. 生产者消费者模型
08.1 为何要使用生产者消费者模型
08.2 生产者消费者模型优点
08.3 基于BlockingQueue的生产者消费者模型
09. POSIX信号量
09.1 概念
09.2 信号量函数
初始化信号量
销毁信号量
等待信号量
发布信号量
基于环形队列的生产消费模型
10. 线程池
10.1 概念
10.2 线程池的应用场景
10.3 线程池的作用及实现原理
10.4 线程池的关键参数
10.5 线程池示例
Task.hpp
ThreadPool.hpp
main.cpp
C语言总结在这常见八大排序在这
作者和朋友建立的社区:非科班转码社区-CSDN社区云💖💛💙
期待hxd的支持哈🎉 🎉 🎉
最后是打鸡血环节:想多了都是问题,做多了都是答案🚀 🚀 🚀
最近作者和好友建立了一个公众号
公众号介绍:
专注于自学编程领域。由USTC、WHU、SDU等高校学生、ACM竞赛选手、CSDN万粉博主、双非上岸BAT学长原创。分享业内资讯、硬核原创资源、职业规划等,和大家一起努力、成长。(二维码在文章底部哈!)
01. Linux线程概念
01.1 什么是线程
在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”。一切进程至少都有一个执行线程。线程在进程内部运行,本质是在进程地址空间内运行。在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化。透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。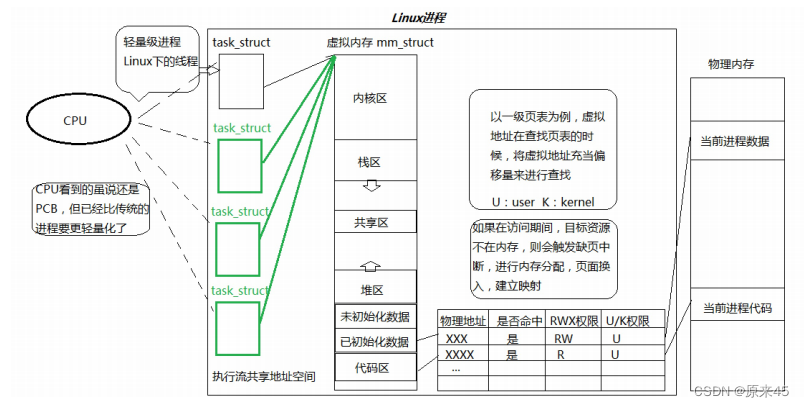
页表并不是简单得单纯去映射
页表执行的内容会去检查是否命中,就是你要访问的物理空间是否在内存里,不在就是没有命中,此时进程将不会被调度,此时页表MMU报错,会触发缺页中断,进程就从CPU拿下来,开始进行IO,把数据从外设搬到内存,然后把是否命中改为是,然后把进程切回来继续运行关于:RWX权限
我们都知道字符常量区是不可修改的,那么当时是如何加载进去的呢?
根本原因是页表里面有对应的条目去限制你去进行读写。对于内存,任何时候都是可以去进行读写的,只不过是让不让你进行的问题。就比如往字符常量区进行写入时页表进行拦截,MMU结合页表的内容,发送异常,OS识别这个异常把他解释为信号,发给目标进程,然后终止目标进程(对于const 修饰 是编译器层面去检测拦截的)。
U/K权限:就可以区分这份代码是用户代码还是内核代码。
虚拟地址到物理地址间的转化(32位为例)
CPU内是虚拟地址32位前10位搜索页目录(就1张),然后找到二级页表,再根据虚拟地址的中间10位去搜索页表,然后二级页表对应的是page的起始地址(内存分配以页为单位)。然后剩下的12位就是页内偏移量!2的12次方刚好就是一般页的大小4KB!
如此设计的好处
1. 进程虚拟地址管理和内存管理,通过页表 + page进行解耦。
2. 分页机制 + 按需创建页表 -- 节省空间。
3. 就比如上面的是否命中(是以page为单位的),当我们找到二级页表的时候,发现右边对应的是null,那就是没有命中。
4. (页表的大小)(页表直接映射到page就可以了)综上我们发现虚拟地址到物理地址的转换是通过软(页表)硬(MMU)件结合的方式完成的。
以前创建进程是创建了PCB地址空间页表,而现在创建进程是只创建PCB,不再独立分配地址空间和页表而是这些PCB访问和指向的是同一个,所以他们看到的资源都是一样的,然后通过某种方式让他们执行/划分不同的区域,让这些执行流去访问,也就是这些创建的PCB有了自己的一小块的代码和数据,Linux中我们把这些占有小块代码和数据和使用他局部页表的一个执行流称为线程。
01.1.1 轻量级进程ID与进程ID之间的区别
因为Linux下的轻量级进程是一个pcb,每个轻量级进程都有一个自己的轻量级进程ID(pcb中的pid),而同一个程序中的轻量级进程组成线程组,拥有一个共同的线程组ID。
01.1.2 总结(重点)
1. 线程是进程内部的执行流。
2. 线程比进程粒度更细,调度成本更低。
3. 线程是CPU调度的基本单位。
1-》在进程的地址空间执行
2-》代码数据占有更少,CPU在调度的时候,地址空间不用切换,页表也不用,要切的只是当前进程(线程)使用的上下文,所以调度切换的成本更低了。
3-》现在CPU在调度的时候不是选择进程去调度而是这4个(上图)执行流中的一个。
对应以前进程OS要管,那么现在出现了线程,那也是要管的。如果是实现的真线程比如Windows,那么他就要针对进程和线程去设计独立的结构体,他们的关系等等(耦合度大,维护成本也高)但是对应Linux,他认为没有进程线程的概念区分,只有执行流!(不用再去单独给线程设计结构等)(即Linux不存在真正意义上的线程(Linux线程是用进程(PCB)模拟的))。但是注意Linux是有TCP的,他就是PCB,只不过在这里PCB和TCB是一回事。
以前我们是认为 进程 = 内核数据结构 + 对应的代码和数据
现在内核视角 进程 = 承担分配系统资源的基本实体(进程的基座属性)
-》向系统申请资源的基本单位
内部只有一个执行流的进程 -- 单执行流进程
内部有多个执行流的进程 -- 多执行流进程
进程最大的意义不是被执行,而是向系统申请资源的基本单位(PCB,地址空间,有关映射的页表,代码和数据)(执行流也是属于进程内部的资源)
Linux没有真正意义上创建线程的接口,但是Linux有原生线程库,不是OS的接口,但是默认都会带且是必带了的。但是由于他是库函数,所以我们在使用的时候要编译对应的pthread选项。
01.2 线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。
- 线程占用的资源要比进程少很多。
- 能充分利用多处理器的可并行数量。
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务。
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
注意私有并不代表不可见。
01.3 线程的缺点
性能损失一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。健壮性降低编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。缺乏访问控制进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。编程难度提高编写与调试一个多线程程序比单线程程序困难得多。01.4 线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃。
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
01.5 线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
02. Linux进程VS线程
02.1 进程和线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
- 线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器
- 栈
- errno
- 信号屏蔽字
- 调度优先级
进程的多个线程共享 同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
进程和线程的关系如下图: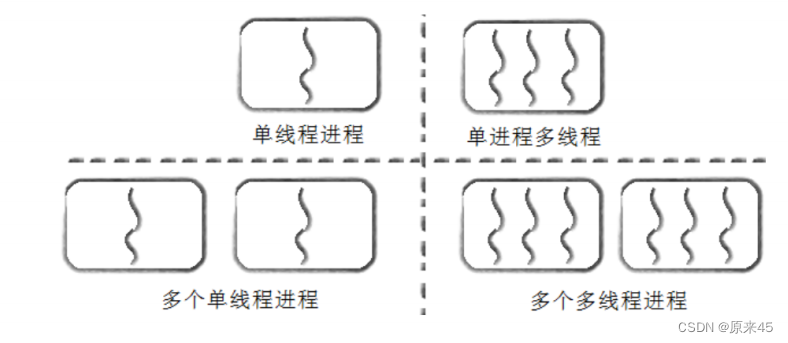
02.2 关于多线程和多进程编程
- 多进程里,子进程可复制父进程的所有堆和栈的数据;而线程会与同进程的其他线程共享数据,但拥有自己的栈空间。
- 线程的通信速度更快,切换更快,因为他们在同一地址空间内,且还共享了很多其他的进程资源,比如页表指针这些是不需要切换的。
- 线程使用公共变量/内存时需要使用同步机制,因为他们在同一地址空间内。
- 进程因为每个都有独立的虚拟地址空间,因此通信麻烦,需要调用内核接口实现。而线程间共用同一个虚拟地址空间,通过全局变量以及传参就可实现通信,因此更加灵活方便。
- 线程拥有自己的栈空间且共享数据,资源消耗更小,且需要进程内线程间的资源管理和保护,否则会造成栈混乱。
- 线程并没有独立的虚拟地址空间,只是在进程虚拟地址空间中拥有相对独立的一块空间。
03. Linux线程控制 -- POSIX线程库
03.01 POSIX线程库
与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的要使用这些函数库,要通过引入头文<pthread.h>链接这些线程函数库时要使用编译器命令的“-lpthread”选项(之前动态库静态库的博客已经说明过为什么了哈)pthread是一个动态库,我们在程序内部调用其函数,在连接的时候发现我们是自己链接了这个库的,但是这个库并不在内存,就会把这个库加载到内存,然后通过页表映射到共享区,所以程序在虚拟地址空间执行的时候调用pthread接口就会跳转到共享区内。03.02 pthread_create
功能:创建一个新的线程原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void * (*start_routine(void*), void *arg);参数:thread:返回线程IDattr:设置线程的属性,attr为NULL表示使用默认属性start_routine:是个函数地址,线程启动后要执行的函数arg:传给线程启动函数的参数返回值:成功返回0;失败返回错误码错误检查:传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。pthreads函数出错时不会设置全局变量errno(而大部分其他POSIX函数会这样做)。而是将错误代码通过返回值返回。pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,建议通过返回值去判定,因为读取返回值要比读取线程内的errno变量的开销更小。
第二个参数是线程的属性,不关心就设置为nullptr。
03.03 什么是LWP
LWP是轻量级进程,在Linux下进程是资源分配的基本单位,线程是cpu调度的基本单位,而线程使用进程pcb描述实现,并且同一个进程中的所有pcb共用同一个虚拟地址空间,因此相较于传统进程更加的轻量化。
03.04 LWP与pthread_create创建的线程之间的关系
pthread_create是一个库函数,功能是在用户态创建一个用户线程,而这个线程的运行调度是基于一个轻量级进程实现的。
03.05 pthread_join
线程用完了也是要等待(等待一个终止的线程)。第二个参数是退出码信息。
因为线程调用的函数返回的是一级指针那我们join想拿到return的值就要用二级指针,他是输出型参数。
但是我们发现线程退出并没有看见存信号的位,直接是退出码?
是因为没必要,线程异常了就推出了,就变成了进程的问题要进程去获取。
03.06 Linux查看线程方式
ps axj 是查进程的
ps -aL(L是查线程的)(a--all)
(LWP:light weigh process 轻量级进程编号 当PID和LWP相等就说明是主线程)
03.07 关于C++线程使用
经过实验,发现C++里面的线程接口如果不带Linux下的pthread库是编译不过的,也就是说C++里面的就是封装的Linux下的原生线程库!
03.08 线程ID及进程地址空间布局
pthread_ create函数会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID和前面说的线程ID不是一回事。前面讲的线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程。pthread_ create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,属于NPTL线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。线程库NPTL提供了pthread_ self函数,可以获得线程自身的ID。pthread_t pthread_self(void);pthread_t 到底是什么类型呢?取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。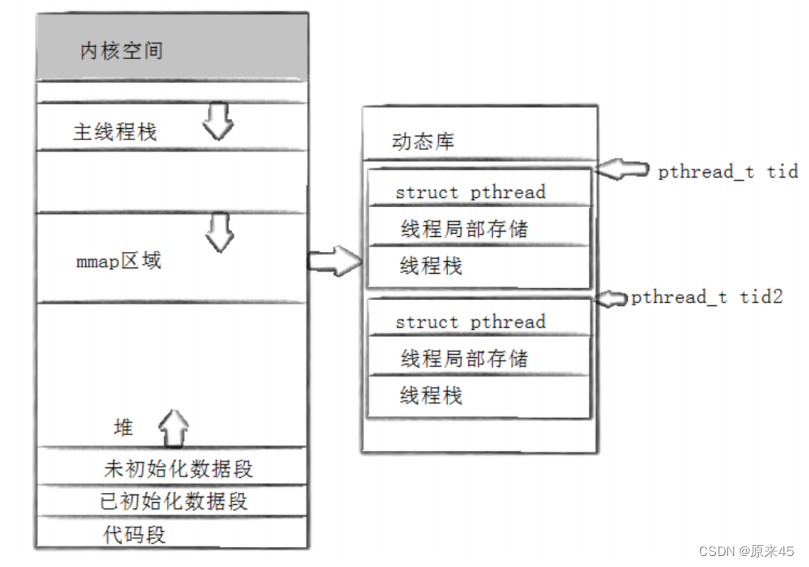
03.09 线程终止
经过代码测试
主线程退出或者暂停,新线程也会。
当新线程产生信号,进程也会退出。对于新线程先退出对主线程没有影响,但是如果主线程先退出那么新线程也会跟着退出,是因为主线程代表的就是当前进程,进程退出了那么他的代码数据等也就归还给了OS,而新线程是主线程中的一部分,是其中的一个执行流,所以也会跟着退出。
1. 所以一般我们分离线程,对应的主线程一般不要退出(这样的进程我们称为常驻内存的进程)
2. 线程分离后我们主线程就不关心他了(不用pthread_join),这也是线程的第四种退出方式 -- 延后退出03.10 pthread_exit
如果需要只终止某个线程而不终止整个进程,可以有三种方法:1. 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。2. 线程可以调用pthread_ exit终止自己。3. 一个线程可以调用pthread_ cancel终止同一进程中的另一个线程。功能:线程终止原型:void pthread_exit(void *value_ptr);参数:value_ptr:value_ptr不要指向一个局部变量。返回值:无返回值,跟进程一样,线程结束的时候无法返回到它的调用者(自身)注意:pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的,不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。03.11 pthread_cancel
功能:取消一个执行中的线程原型:int pthread_cancel(pthread_t thread);参数:thread:线程ID返回值:成功返回0;失败返回错误码03.12 线程等待
为什么需要线程等待?已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。创建新的线程不会复用刚才退出线程的地址空间。功能:等待线程结束原型:int pthread_join(pthread_t thread, void **value_ptr);参数:thread:线程IDvalue_ptr:它指向一个指针,后者指向线程的返回值返回值:成功返回0;失败返回错误码调用该函数的线程将挂起等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的,总结如下:1. 如果thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值。2. 如果thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数PTHREAD_ CANCELED。3. 如果thread线程是自己调用pthread_exit终止的,value_ptr所指向的单元存放的是传给pthread_exit的参数。4. 如果对thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数。
03.13 分离线程
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
int pthread_detach(pthread_t thread);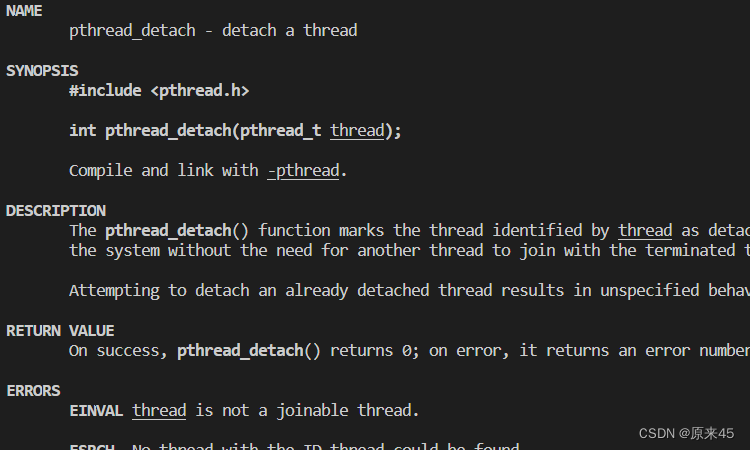
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());
joinable和分离是冲突的,一个线程不能既是joinable又是分离的。



04. Linux线程互斥
04.1 进程线程间的互斥相关背景概念
临界资源:多线程执行流共享的资源就叫做临界资源临界区:每个线程内部,访问临界资源的代码,就叫做临界区互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用。原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成。理解原子性
所谓原语的原子性操作是指一个操作中的所有动作,要么成功完成,要么全不做。也就是说,原语操作是一个不可分割的整体。为了保证原语操作的正确性,必须保证原语具有原子性。在单机环境下,操作的原子性一般是通过关闭中断来实现的。由于中断是计算机与外设通信的重要手段,关闭中断会对系统产生很大的影响,所以在实现时一定要避免原语操作花费时间过长,绝对不允许原语中出现死循环。
什么是线程互斥,为什么需要互斥
线程互斥指的是在多个线程间对临界资源进行争抢访问时有可能会造成数据二义,因此通过保证同一时间只有一个线程能够访问临界资源的方式实现线程对临界资源的访问安全性。
04.2 互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。
- 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。
- 多个线程并发的操作共享变量,会带来一些问题。
有可能因为非原子操作而造成问题的情况:
if判断, -- , ++ 等,就是一些非原子操作,因为线程切换,多线程同时访问临界资源造成数据的二义性。(x=y和++ --一样,其中涉及到了数据的运算,则涉及从内存加载数据到寄存器,在寄存器中运算,将寄存器中数据交还内存的过程因此需要加锁保护的操作中,但是x=1就可以不加锁,常量的直接赋值是一个原子操作)
比如 -- 操作并不是原子操作,而是对应三条汇编指令:
load :将共享变量ticket从内存加载到寄存器中update : 更新寄存器里面的值,执行-1操作store :将新值,从寄存器写回共享变量ticket的内存地址要解决以上问题,需要做到三点:
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量。
并发编程中通常会遇到三个问题 原子性问题,可见性问题,有序性问题
原子性:一个操作不会被打断,要么一次完成,要么不做。
可见性:一个资源被修改后,是否对其他线程是立即可见的(一个变量的修改存在一个过程,将数据从内存加载的cpu寄存器,进行运算,完毕后交还内存,但是这个过程在代码优化中可能会被编译器优化,将数据放入寄存器,则后续运算只从寄存器取数据,就节省了从内存获取数据的时间)
有序性:简单理解,程序按照写代码的先后顺序执行,就是有序的。(编译器有时候会为了提高程序效率进行代码优化,进行指令重排,来提高效率,而有序性就是禁止指令重排)
04.3 互斥量的接口
初始化互斥量
初始化互斥量有两种方法:方法1,静态分配:pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER定义的全局锁或者static修饰的可以用宏初始化,不然就调用init函数(条件变量也是一样的)方法2,动态分配:int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrictattr);参数:mutex:要初始化的互斥量attr:NULL销毁互斥量
销毁互斥量需要注意:
- 使用 PTHREAD_ MUTEX_ INITIALIZER 初始化的互斥量不需要销毁。
- 不要销毁一个已经加锁的互斥量。
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁。
int pthread_mutex_destroy(pthread_mutex_t *mutex);互斥量加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);int pthread_mutex_unlock(pthread_mutex_t *mutex);返回值:成功返回0,失败返回错误号调用 pthread_ lock 时,可能会遇到以下情况:
- 互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功。
- 发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_ lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁。
04.4 关于实现互斥锁
为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的 总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。 现在我们看lock和unlock的伪代码:
无锁化编程有哪些常见方法
- 原子操作不涉及线程安全问题。
- 形队列本身具有同步的功能,在一对一的情况下,这种同步侧面的实现了互斥的效果。
- RCU锁机制(Read - Copy - Update)-对读写锁的一种优化,读-拷贝-更新,读者可以同时读取数据,写者更新数据前先复制一份数据出来,对副本进行修改,修改完毕后更新数据,而旧版本数据等所有读者不再访问时释放。
- CAS-比较并交换(Compare - and - Swap),是一种乐观锁,认为在使用数据的过程中其它线程不会修改这个数据,故不加锁直接访问。
05. 可重入VS线程安全
05.1 概念
线程安全:多个线程并发同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现该问题。重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。线程安全指的是在多线程编程中,多个线程对临界资源进行争抢访问而不会造成数据二义或程序逻辑混乱的情况。
线程安全的实现,通过同步与互斥实现
具体同步的实现可以通过互斥锁和信号量实现、而同步可以通过条件变量与信号量实现。
05.2 常见的线程不安全的情况
- 不保护共享变量的函数
- 函数状态随着被调用,状态发生变化的函数
- 返回指向静态变量指针的函数
- 调用线程不安全函数的函数
05.3 常见的线程安全的情况
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的。
- 类或者接口对于线程来说都是原子操作。
- 多个线程之间的切换不会导致该接口的执行结果存在二义性。
05.4 常见不可重入的情况
- 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的。
- 调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构。
- 可重入函数体内使用了静态的数据结构。
05.5 常见可重入的情况
- 不使用全局变量或静态变量。
- 不使用用malloc或者new开辟出的空间。
- 不调用不可重入函数。
- 不返回静态或全局数据,所有数据都有函数的调用者提供。
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
05.6 可重入与线程安全联系
- 函数是可重入的,那就是线程安全的。
- 函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题。
- 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的。
线程安全指的是当前线程中对各项操作时安全的,但不表示内部调用的函数是安全的,两个之间并没有必然关系。
线程中不仅仅会调用函数,有可能本身内部就进行了临界资源的操作,所以线程内调用的函数可重入只是线程安全的一个要素。
一个函数一旦是线程安全的,则表示在多个线程内重入不会引发意外问题,因此也是可重入的。
05.7 可重入与线程安全区别
- 可重入函数是线程安全函数的一种。
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个重入函数若锁还未释放则会产生,死锁,因此是不可重入的。
06. 常见锁概念
06.1 死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。06.2 死锁四个必要条件
互斥条件:一个资源每次只能被一个执行流使用。请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放。不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺。循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系。06.3 避免死锁
- 破坏死锁的四个必要条件。
- 加锁顺序一致。
- 避免锁未释放的场景。
- 资源一次性分配。
06.4 死锁的处理都有哪些方法
- 鸵鸟策略 对可能出现的问题采取无视态度,前提是出现概率很低。
- 预防策略 破坏死锁产生的必要条件。
- 避免策略 银行家算法,分配资源前进行风险判断,避免风险的发生。
- 检测与解除死锁 分配资源时不采取措施,但是必须提供死锁的检测与解除手段。
- 银行家算法 的将系统运行分为两种状态:安全/非安全,有可能出现风险的都属于非安 全。(银行家算法是避免出现死锁的一种算法(并非预防的方法))(银行家算法的思 想是为了避免出现“环路等待”条件)
07. Linux线程同步
07.1 条件变量
- 当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
- 例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
- 条件变量进行同步的条件判断由外部的共享资源条件判断实现,因此需要搭配互斥锁使用。
- 条件变量的控制判断需要使用循环进行,避免在多个线程同时被唤醒的情况下,A线程加锁成功访问资源,其他线程卡在锁处,而A线程一旦解锁,其他线程抢到锁在资源访问条件不满足的情况下访问资源,因此被唤醒后加锁成功则需要重新进行判断,条件满足则访问,不满足则需要重新陷入休眠。
- 条件变量的使用中不同的角色需要等待在不同的条件变量等待队列中,防止角色误唤醒,比如生产者唤醒生产者的情况,因此需要分开等待,分开唤醒。
信号量实现与条件变量有什么区别
- 条件变量提供了一个pcb阻塞队列以及阻塞和唤醒线程的接口用于实现同步,但是什么时候该唤醒以及什么时候该阻塞线程由程序员进行控制,而这个控制通常需要一个共享资源的条件判断完成,因此条件变量还需要搭配互斥锁使用,来保护这个共享资源的条件判断及操作。
- 信号量提供一个pcb等待队列,以及一个实现了原子操作的对资源进行计数的计数器,通过自身计数器实现同步的条件判断,因此不需要搭配互斥锁使用,而且信号量在初始化计数为1的情况下也可以模拟实现互斥操作。
07.2 同步概念与竞态条件
同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步。竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解。线程同步指的是线程间对数据资源进行获取,有可能在不满足访问资源条件的情况下访问资源而造成程序逻辑混乱,因此通过进行条件判断来决定线程在不能访问资源时休眠等待或满足资源后唤醒等待的线程的方式实现对资源访问的合理性。07.3 条件变量函数
初始化
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);参数:cond:要初始化的条件变量attr:NULL销毁
int pthread_cond_destroy(pthread_cond_t *cond)等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);参数:cond:要在这个条件变量上等待mutex:互斥量唤醒等待
唤醒所有等待此资源的线程
int pthread_cond_broadcast(pthread_cond_t *cond);唤醒单个等待此资源的线程int pthread_cond_signal(pthread_cond_t *cond);为什么 pthread_cond_wait 需要互斥量?
- 条件等待是线程间同步的一种手段,如果只有一个线程,条件不满足,一直等下去都不会满足,所以必须要有一个线程通过某些操作,改变共享变量,使原先不满足的条件变得满足,并且友好的通知等待在条件变量上的线程。
- 条件不会无缘无故的突然变得满足了,必然会牵扯到共享数据的变化。所以一定要用互斥锁来保护。没有互斥锁就无法安全的获取和修改共享数据。
PS:解锁和等待是一个原子操作。

08. 生产者消费者模型
3种角色(生产者,消费者,商场),两种关系(互斥同步),一个交易场所(商场)。
08.1 为何要使用生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。08.2 生产者消费者模型优点
- 解耦
- 支持并发
- 支持忙闲不均
08.3 基于BlockingQueue的生产者消费者模型
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)。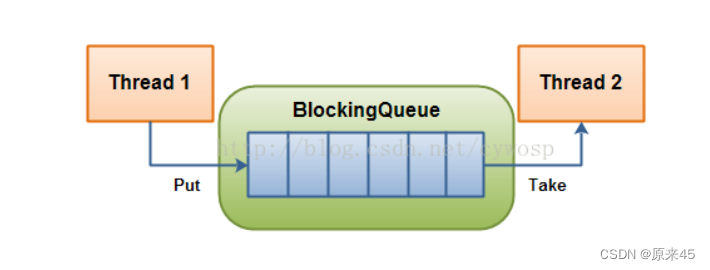 重新理解生产者消费者模型
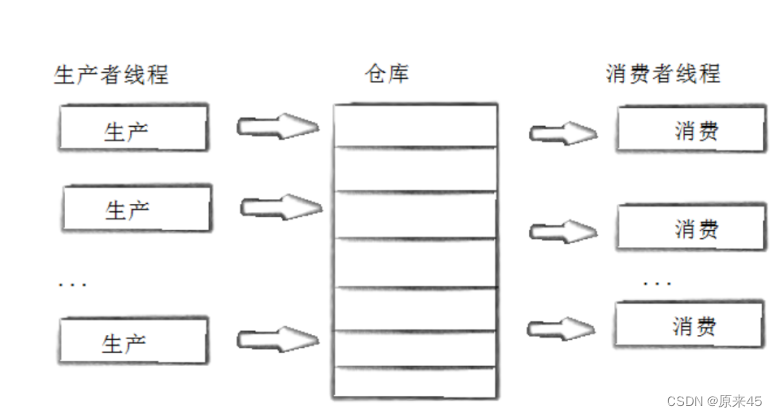
重新理解生产者消费者模型
制作任务要花时间,处理任务也要花时间
所以并不要狭隘地去任务生产者消费者模型就是生产者放任务和消费者消费任务(这里确实是串行的,有锁),而是要把生产者生产和消费者消费这一个大过程一起看待,这是并发执行的!
09. POSIX信号量
09.1 概念
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但POSIX可以用于线程间同步。信号量是一个计数器,用了衡量临界资源中资源的数目,申请信号量的本质叫做预定某种信号量资源,当申请信号量成功时,信号量所对应的资源才可以被你唯一去使用。
sem_t 就是我们的信号量(semaphore)
信号量是一种挂起等待的计数器P:sem_wait
V:sem_post09.2 信号量函数
初始化信号量
#include <semaphore.h>int sem_init(sem_t *sem, int pshared, unsigned int value);参数:pshared:0表示线程间共享,非零表示进程间共享value:信号量初始值销毁信号量
int sem_destroy(sem_t *sem);等待信号量
功能:等待信号量,会将信号量的值减1int sem_wait(sem_t *sem); //P()发布信号量
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。int sem_post(sem_t *sem);//V()基于环形队列的生产消费模型
环形队列采用数组模拟,用模运算来模拟环状特性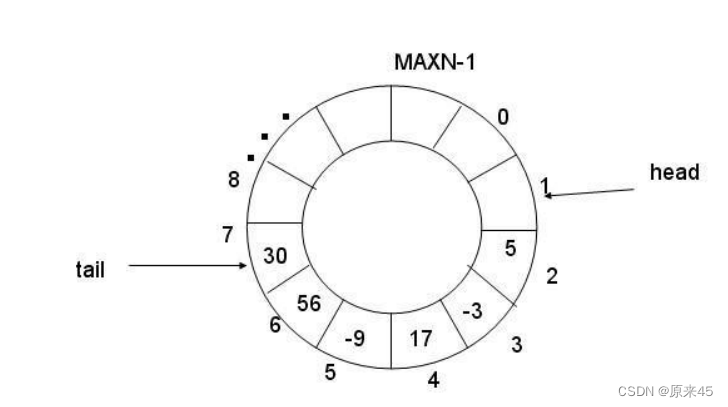 环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留一个空的位置,作为满的状态。
环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留一个空的位置,作为满的状态。
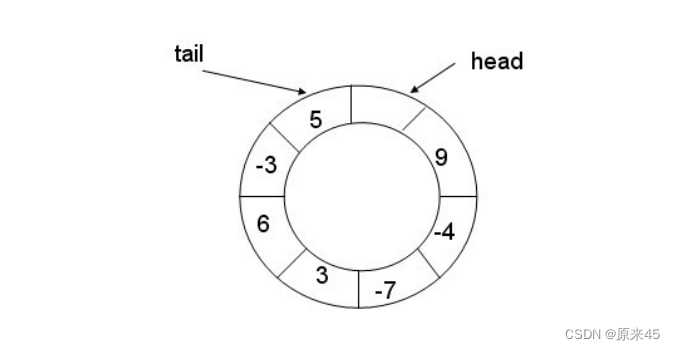
但是我们现在有信号量这个计数器,就很简单的进行多线程间的同步过程 。
10. 线程池
10.1 概念
一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。10.2 线程池的应用场景
1. 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。2. 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。3. 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限,出现错误。10.3 线程池的作用及实现原理
线程池通过一个线程安全的阻塞任务队列加上一个或一个以上的线程实现,线程池中的线程可以从阻塞队列中获取任务进行任务处理,当线程都处于繁忙状态时可以将任务加入阻塞队列中,等到其它的线程空闲后进行处理。
可以避免大量线程频繁创建或销毁所带来的时间成本,也可以避免在峰值压力下,系统资源耗尽的风险;并且可以统一对线程池中的线程进行管理,调度监控。
降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消(线程池中更多是对已经创建的线程循环利用,因此节省了新的线程的创建与销毁的时间成本)。
提高线程的可管理性:线程池可以统一管理、分配、调优和监控(线程池是一个模块化的处理思想,具有统一管理,资源分配,调整优化,监控的优点)。
降低程序的耦合程度: 提高程序的运行效率(线程池模块与任务的产生分离,可以动态的根据性能及任务数量调整线程的数量,提高程序的运行效率)。
10.4 线程池的关键参数
- 线程池中线程最大数量 -- 防止资源耗尽,或线程过多性能降低
- 线程安全的阻塞队列 -- 用于任务排队缓冲
- 线程池中线程的存活时间 -- 长时间空闲则退出线程节省资源
- 线程池中阻塞队列的最大节点数量 -- 防止任务过多,资源耗尽
10.5 线程池示例
1. 创建固定数量线程池,循环从任务队列中获取任务对象,2. 获取到任务对象后,执行任务对象中的任务接口Task.hpp
#pragma once #include <iostream> #include <string> class Task { public: Task(int one = 0, int two = 0, char op = '0') : elemOne_(one), elemTwo_(two), operator_(op) {} int operator() () { return run(); } int run() { int result = 0; switch (operator_) { case '+': result = elemOne_ + elemTwo_; break; case '-': result = elemOne_ - elemTwo_; break; case '*': result = elemOne_ * elemTwo_; break; case '/': { if (elemTwo_ == 0) { std::cout << "div zero, abort" << std::endl; result = -1; } else { result = elemOne_ / elemTwo_; } } break; case '%': { if (elemTwo_ == 0) { std::cout << "mod zero, abort" << std::endl; result = -1; } else { result = elemOne_ % elemTwo_; } } break; default: std::cout << "非法操作: " << operator_ << std::endl; break; } return result; } int get(int *e1, int *e2, char *op) { *e1 = elemOne_; *e2 = elemTwo_; *op = operator_; } private: int elemOne_; int elemTwo_; char operator_; };ThreadPool.hpp
#include <iostream> #include <pthread.h> #include <sys/prctl.h> #include <queue> #include "Task.hpp" using std::cout; using std::endl; // 1. 有一个队列去存储任务 -- 临界资源 // 2. 有一个条件变量和一个互斥锁去控制线程的同步与互斥 template <class T> class ThreadPool { public: ThreadPool(int ThreadNum) : TheadNum_(ThreadNum) { pthread_mutex_init(&mutex_, nullptr); pthread_cond_init(&cond_, nullptr); } ~ThreadPool() { pthread_mutex_destroy(&mutex_); pthread_cond_destroy(&cond_); } public: // 所有的线程来到这里准备开始抢任务去执行 static void *Routine(void *args) { pthread_detach(pthread_self()); // 线程分离 不关心返回值不用join // static函数 所以传this过来访问类内函数 ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args); prctl(PR_SET_NAME, "follower");//记住这个,可以改线程名 cout<<"Routine :"<<pthread_self()<<endl; while (true) { tp->LockQueue(); // 他是函数,可能调用失败,往后执行 2. 或者其他原因伪唤醒 // 把if改成while就可以了,因为while有条件检测的能力 while (!tp->HaveTask()) { cout<<"while..."<<endl; tp->WaitForTask(); } cout<<"start task "<<pthread_self()<<endl; // 到这就说明有任务来了,该线程去处理 T t = tp->pop(); // 拿到阻塞队列的任务 tp->UnLockQueue(); // for debug int one, two; char op; t.get(&one, &two, &op); //规定,所有的任务都必须有一个run方法 cout << "新线程完成计算任务: " << one << op << two << "=" << t.run() << "\n"; } return nullptr; } void start() { while (TheadNum_--) { pthread_t tmp; pthread_create(&tmp, nullptr, Routine, this); } } //push 和 pop 的加锁和解锁要仔细想想 //push 是在 main 函数里面push的,一下是只有一个的 //但是pop不加锁是因为pop调用的时候本身就已经有锁了,所以 //再次加锁就会产生死锁现象! void push(T t) { LockQueue(); cout<<"主线程 push "<<pthread_self()<<endl; TaskQueue_.push(t); ChoiceThreadToHandler(); UnLockQueue(); } private: void LockQueue(){pthread_mutex_lock(&mutex_);}; void UnLockQueue() { pthread_mutex_unlock(&mutex_); }; void WaitForTask() { pthread_cond_wait(&cond_, &mutex_); }; void ChoiceThreadToHandler() { pthread_cond_signal(&cond_); }; bool HaveTask() { return !TaskQueue_.empty(); } T pop() { cout<<"pop "<<pthread_self()<<endl; T head = TaskQueue_.front(); TaskQueue_.pop(); return head; } private: int TheadNum_; // 线程池个数 pthread_mutex_t mutex_; pthread_cond_t cond_; std::queue<T> TaskQueue_; };main.cpp
#include "ThreadPool.hpp" #include "Task.hpp" #include <ctime> #include <thread> #include <string> #include <sys/types.h> #include <unistd.h> // 如何对一个线程进行封装, 线程需要一个回调函数,支持lambda // class tread{ // }; int main() { prctl(PR_SET_NAME, "master"); const std::string operators = "+/*/%"; ThreadPool<Task> tp(5); tp.start(); sleep(1); srand((unsigned long)time(nullptr) ^ getpid() ^ pthread_self()); // 派发任务的线程 while (true) { int one = rand() % 50; int two = rand() % 10; char oper = operators[rand() % operators.size()]; cout << "主线程派发计算任务: " << one << oper << two << "=?"<<endl; Task t(one, two, oper); tp.push(t); sleep(1); } return 0; }
最后的最后,创作不易,希望读者三连支持💖
赠人玫瑰,手有余香💖






![[附源码]计算机毕业设计Python“小世界”私人空间(程序+源码+LW文档)](https://img-blog.csdnimg.cn/48cba93da3ad4beea55a442403d4d1b9.png)