文章目录
- 一.常见的K8S部署方式
- 1.Minikube
- 2.Kubeadmin
- 3.二进制安装部署
- 二.二进制搭建K8S(双台master)
- 1.部署架构规划
- 2.系统初始化配置
- 3.部署 docker引擎
- 4.部署 etcd 集群
- (1)etcd简介
- (2)准备签发证书环境
- (3)etcd 集群部署
- 5.部署 Master 组件
- 6.部署 Worker Node 组件
- 7.部署网络组件
- (1)K8S 中 Pod 网络介绍
- ①K8S 中 Pod 网络通信:
- ②Overlay Network:
- ③VXLAN:
- ④Flannel:
- ⑤Flannel UDP 模式的工作原理:
- ⑥ETCD 之 Flannel 提供说明:
- ⑦VXLAN 模式:
- ⑧Flannel VXLAN 模式跨主机的工作原理:
- ⑨Kubernetes的三种网络介绍
- (2)部署 flannel
- (3)node02 节点部署
- (4)部署 CoreDNS
- (5)master02 节点部署
- 8.负载均衡部署
- 9.部署 Dashboard
- (1)Dashboard 介绍
- (2)Dashboard部署
一.常见的K8S部署方式
1.Minikube
Minikube是一个工具,可以在本地快速运行一个单节点微型K8S,仅用于学习、预览K8s的些特性使用。
部署地址: https://kubernetes.io/docs/setup/minikube
2.Kubeadmin
Kubeadmin也是一个工具,提供kubeadm init和kubeadm join,用于快速部署K8S集群,相对简单。
部署地址:https://kubernetes,io/docs/reference/setup-tools/kubeadm/kubeadm/
3.二进制安装部署
从官方下载发行版的二进制包,手动部署每个组件和自签TLS证书,组成K8S集群,新手推荐。
部署地址:https://qithub,com/kubernetes/kubernetes/releases
总:Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护和出错排错。
二.二进制搭建K8S(双台master)
1.部署架构规划
| 主机节点 | 主机地址 | 安装的软件 |
|---|---|---|
| master01 | 192.168.198.11 | apiserver、comtroller-manager、scheduler、etcd01 |
| master02 | 192.168.198.14 | |
| node01 | 192.168.198.12 | kubelet、kube-proxy、docker、etcd02 |
| node02 | 192.168.198.13 | kubelet、kube-proxy、docker、etcd03 |
| 负载均衡nginx+keepalive01(master) | 192.168.198.15 | |
| 负载均衡nginx+keepalive02(backup) | 192.168.198.16 | |
| VIP | 192.168.198.100 |
2.系统初始化配置
所有节点上操作
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#永久关闭firewalld并清空iptables所有表规则
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
三个节点分开执行
#根据规划设置主机名
#192.168.198.11上面执行
hostnamectl set-hostname master01
#192.168.198.12上面执行
hostnamectl set-hostname node01
#192.168.198.13上面执行
hostnamectl set-hostname node02
所有节点执行
#刷新bash使得修改的主机名生效
bash
#使用多行重定向将主机名对应的ip写到hosts里面加快访问速度,注意改为自己的ip
cat >> /etc/hosts << EOF
192.168.198.11 master01
192.168.198.12 node01
192.168.198.13 node02
EOF
#调整内核参数
#使用多行重定向调整内核参数,前2行为开启网桥模式后2行为关闭ipv6协议和开启路由转发
cat > /etc/sysctl.d/k8s.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
#加载内核使得配置内核参数生效
sysctl --system
#时间同步
#安装ntpdate时间同步程序,与本机的windows同步时间
yum install ntpdate -y
ntpdate time.windows.com
3.部署 docker引擎
所有 node 节点部署docker引擎192.168.198.12、192.168.198.13
#安装依赖包以便在系统上安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
#添加Docker官方源,并将它设置为docker-ce.repo文件
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#yum安装docker-ce和docker客户端以及容器io
yum install -y docker-ce docker-ce-cli containerd.io
#开机自启并现在启动docker
systemctl start docker.service
systemctl enable docker.service
4.部署 etcd 集群
(1)etcd简介
①etcd概念:
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
②etcd的特点
etcd 作为服务发现系统,有以下的特点:
简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
安全:支持SSL证书验证
快速:单实例支持每秒2k+读操作
可靠:采用raft算法,实现分布式系统数据的可用性和一致性
③etcd端口及部署注意
etcd 目前默认使用2379端口提供HTTP API服务, 2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。
etcd 在生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。
(2)准备签发证书环境
本文使用CFSSL工具签发证书
CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。 CFSSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。
CFSSL 使用配置文件生成证书,因此自签之前,需要生成它识别的 json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。
CFSSL 用来为 etcd 提供 TLS 证书,它支持签三种类型的证书:
- client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如 kube-apiserver 访问 etcd;
- peer 证书,相互之间连接时使用的证书,如 etcd 节点之间进行验证和通信。
这里全部都使用同一套证书认证。 - server 证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如 etcd 对外提供服务;本次实验使用的是server证书。
(3)etcd 集群部署
在 master01节点上操作
#在线直接下载方式
#准备cfssl证书生成工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo
chmod +x /usr/local/bin/cfssl*
本文使用的是的直接上传的安装软件,所有需要的资源在博客文章旁边的资源里有K8S的软件包里
#将cfssl证书签发的工具和命令(cfssl、cfssljson、cfssl-certinfo)上传到/usr/local/bin目录下并添加执行权限
#cfssl:证书签发的工具命令
#cfssljson:将 cfssl 生成的证书(json格式)变为文件承载式证书
#cfssl-certinfo:验证证书的信息
#cfssl-certinfo -cert <证书名称> #查看证书的信息
cd /usr/local/bin
chmod +x /usr/local/bin/cfssl*
#生成Etcd证书
mkdir /opt/k8s
cd /opt/k8s/
#上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中
chmod +x etcd-cert.sh etcd.sh
#创建用于生成CA证书、etcd 服务器证书以及私钥的目录
mkdir /opt/k8s/etcd-cert
#移动生成证书的脚本到存放etcd证书的目录下
mv etcd-cert.sh etcd-cert/
#进入创建的目录,执行脚本
cd /opt/k8s/etcd-cert/
#此脚本需要修改80到82行的ip地址依次为master01,node1,node2顺序保存退出
vim ./etcd-cert.sh
#执行脚本,生成CA证书、etcd 服务器证书以及私钥
./etcd-cert.sh
#查看生成的证书是否为4个.pem结尾3个.json结尾
ls /opt/k8s/etcd-cert

#上传 etcd-v3.4.9-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
cd /opt/k8s/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
#解压上传的etcd包,内容为3个.md文件一个目录,一个etcd和一个etcdctl启动控制脚本
ls etcd-v3.4.9-linux-amd64
#创建用于存放etcd配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}
#进入解压的etcd包中
cd /opt/k8s/etcd-v3.4.9-linux-amd64/
#将etcd启动和etcdctl控制脚本移动到创建的用于存放etcd命令文件的bin目录下
mv etcd etcdctl /opt/etcd/bin/
#进入创建etcd证书的目录并将本目录下所有证书全部拷贝一份到创建的用于存放etcd证书的路径ssl上
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
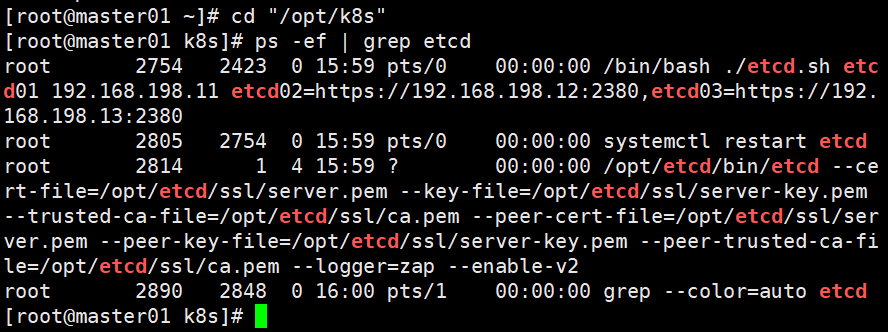
#进入存放etcd.sh部署etcd集群的脚本目录执行etcd.sh脚本 后面跟三个etcd集群的ip注意格式,进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,先操作不然不会生成system管理和配置文件,重新开启一个shell查看etcd状态
cd /opt/k8s/
./etcd.sh etcd01 192.168.198.11 etcd02=https://192.168.198.12:2380,etcd03=https://192.168.198.13:2380
#另一个窗口执行
#查看etcd集群状态是否为自己的三个etcd ip
ps -ef | grep etcd
#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ root@192.168.198.12:/opt/
scp -r /opt/etcd/ root@192.168.198.13:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.198.12:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service root@192.168.198.13:/usr/lib/systemd/system/
在 node01 节点上操作
#在 node01 节点上操作
#修改scp过来的etcd配置文件
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd02" #修改为etcd02
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.198.12:2380" #修改为node1的ip地址
ETCD_LISTEN_CLIENT_URLS="https://192.168.198.12:2379" #修改为node1的ip地址
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.198.12:2380" #修改为node1的ip地址
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.198.12:2379" #修改为node1的ip地址
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.198.11:2380,etcd02=https://192.168.198.12:2380,etcd03=https://192.168.198.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
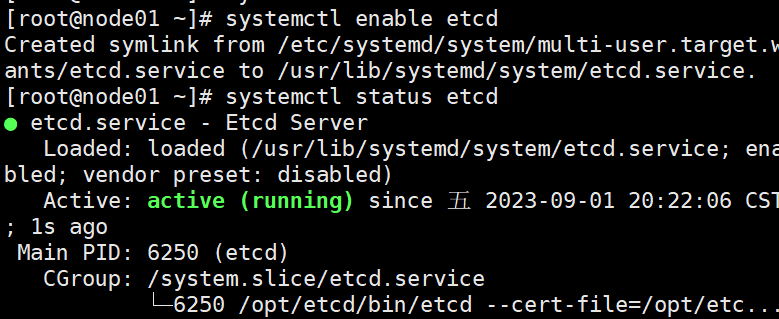
systemctl start etcd
systemctl enable etcd
systemctl status etcd
在 node02 节点上操作
#在 node02 节点上操作
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd03" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.198.13:2380" #修改为node2的ip地址
ETCD_LISTEN_CLIENT_URLS="https://192.168.198.13:2379" #修改为node2的ip地址
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.198.13:2380" #修改为node2的ip地址
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.198.13:2379" #修改为node2的ip地址
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.198.11:2380,etcd02=https://192.168.198.12:2380,etcd03=https://192.168.198.13:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
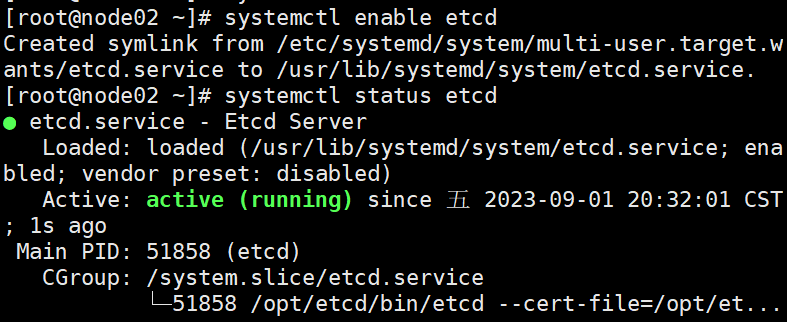
systemctl start etcd
systemctl enable etcd
systemctl status etcd
master节点执行
#master节点执行
cd /opt/k8s
#重新启动etcd集群
./etcd.sh etcd01 192.168.198.11 etcd02=https://192.168.198.12:2380,etcd03=https://192.168.198.13:2380
node1 node2执行
#node1 node2执行
systemctl enable --now etcd
#设置开机启动并立即启动etcd,然后回到master上查看是否成功。不是一直前台运行状态即成功
master执行
#master执行:
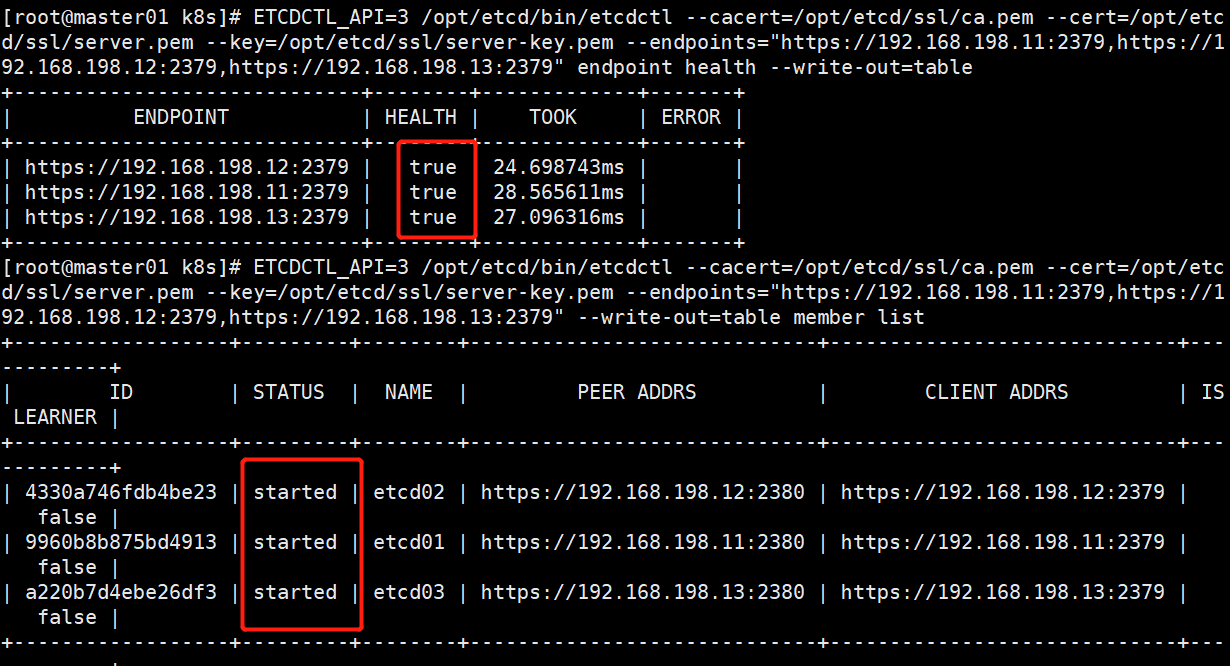
#检查etcd群集状态
#检查集群监控状态,health全部未true即可
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.198.11:2379,https://192.168.198.12:2379,https://192.168.198.13:2379" endpoint health --write-out=table
#查看etcd集群成员列表
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.198.11:2379,https://192.168.198.12:2379,https://192.168.198.13:2379" --write-out=table member list
5.部署 Master 组件
在 master01 节点上操作
#在 master01 节点上操作
#上传 master.zip 和 k8s-cert.sh 到 /opt/k8s 目录中,解压 master.zip 压缩包
cd /opt/k8s/
#解压master组件包,里面有master的4个组件脚本,添加权限
unzip master.zip
chmod +x *.sh
#创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#创建用于生成CA证书、相关组件的证书和私钥的目录
mkdir /opt/k8s/k8s-cert
#将k8s证书移动到创建的k8s的证书存放路径
mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
cd /opt/k8s/k8s-cert/
#修改脚本中的56-60行顺序是第一个为master1、第二个为master2此为master单节点可以删除、第三个为master虚拟ip、第四load balancer01(master)第五为load balancer01(backup)。第四第五可以删除。单节点master不用,若后面需要做集群需要提前规划好ip,第一个地址为master地址:192.168.198.11;第二个地址为VTP虚拟地址:配置文件里的文字部分需删除
chmod +x k8s-cert.sh
vim /opt/k8s/k8s-cert/k8s-cert.sh
#生成CA证书、相关组件的证书和私钥
./k8s-cert.sh
#显示生成的证书等一共8个.pem结尾
ls *pem


#将ca证书和apiserver证书拷贝到创建的存放证书的ssl/目录下
cp ca*pem apiserver*pem /opt/kubernetes/ssl/
#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
cd /opt/k8s/
#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
tar zxvf kubernetes-server-linux-amd64.tar.gz
#进入解压后的k8s的bin目录中将4个组件拷贝到创建的k8s存放bin文件的路径下
cd /opt/k8s/kubernetes/server/bin
cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
ln -s /opt/kubernetes/bin/* /usr/local/bin/
#本地创建 bootstrap token 认证文件,apiserver 启动时会调用,然后就相当于在集群内创建了一个这个用户,接下来就可以用 RBAC 给他授权
cd /opt/k8s/
vim token.sh
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
cat > /opt/kubernetes/cfg/token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOF
#保存后退出
chmod +x token.sh
./token.sh
#创建 bootstrap token 认证文件,apiserver 启动时会调用,然后就相当于在集群内创建了一个这个用户,接下来就可以用 RBAC 给他授权,查看是否生成了csv文件
cat /opt/kubernetes/cfg/token.csv

#二进制文件、token、证书都准备好后,开启 apiserver 服务,将apiserver.sh脚本导入到目录下
cd /opt/k8s/
./apiserver.sh 192.168.198.11 https://192.168.198.11:2379,https://192.168.198.12:2379,https://192.168.198.13:2379
#检查进程是否启动成功,过滤kube-apiserver最上面一个后面会有-etcd-servers=https://192.168.198.11:2379,https://192.168.198.12:2379,https://192.168.198.13:2379 --bind-address=192.168.198.11 --secure-port=6443此信息为正常,注意ip要改为自己的ip地址
https://blog.csdn.net/weixin_67287151/article/details/130562192
ps aux | grep kube-apiserver
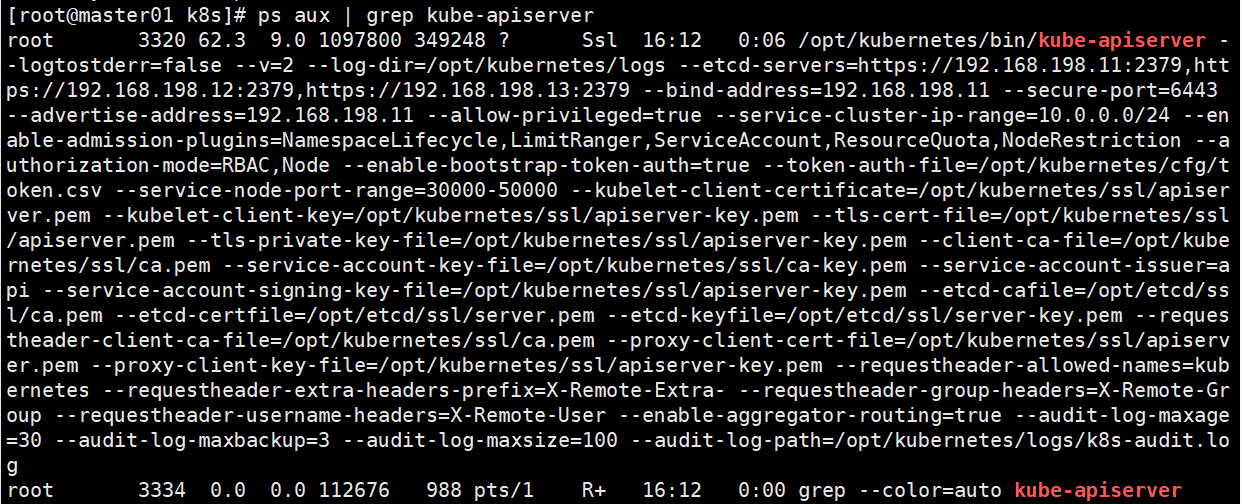
#安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证
#过滤端口只有监控本机ip的6443为正常
netstat -natp | grep 6443

#启动 scheduler 服务
cd /opt/k8s/
#修改脚本中的ip,第47行KUBE_APISERVER="https://192.168.198.11:6443"为自己的apiserver的ip地址本文是master地址,保存退出
vim scheduler.sh
#运行shceduler组件脚本,查看服务是否正常
./scheduler.sh
ps aux | grep kube-scheduler

#修改第58行的ip,KUBE_APISERVER="https://192.168.198.11:6443"为自己的apiserver的ip地址本文是master地址
vim controller-manager.sh
#启动 controller-manager 服务
./controller-manager.sh
#运行controller-manager.sh组件脚本,查看服务是否正常
ps aux | grep kube-controller-manager
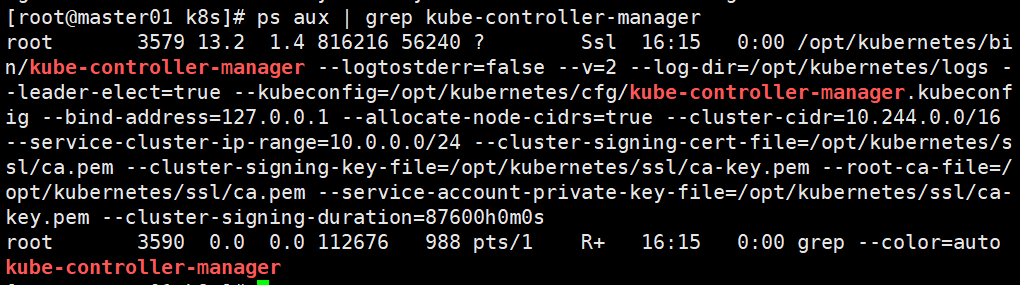
#修改第4行的ip地址,KUBE_APISERVER="https://192.168.198.11:6443"为自己的apiserver的ip地址本文是master地址
vim ./admin.sh
#生成kubectl连接集群的证书
./admin.sh
#创建集群以及用户
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
#通过kubectl工具查看当前集群组件状态
kubectl get cs
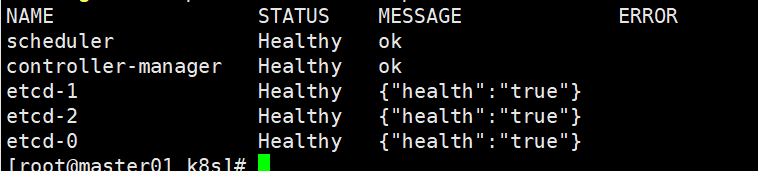
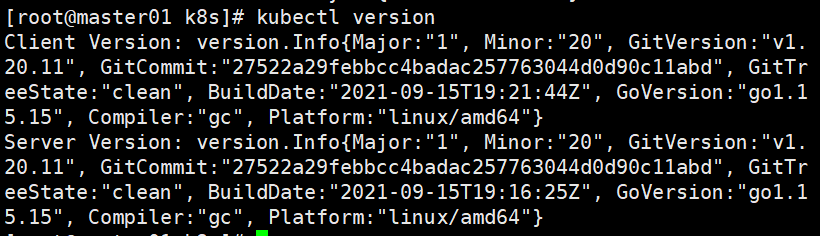
#查看版本信息
kubectl version
6.部署 Worker Node 组件
在所有 node 节点上操作
#在所有 node 节点上操作
#创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x kubelet.sh proxy.sh
在 master01 节点上操作
#在 master01 节点上操作
#把 kubelet、kube-proxy 拷贝到 node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy root@192.168.198.12:/opt/kubernetes/bin/
scp kubelet kube-proxy root@192.168.198.13:/opt/kubernetes/bin/
#上传 kubeconfig.sh 文件到 /opt/k8s/kubeconfig 目录中,生成 kubeconfig 的配置文件
mkdir /opt/k8s/kubeconfig
cd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
./kubeconfig.sh 192.168.198.11 /opt/k8s/k8s-cert/
#把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 2个授权文件拷贝到 node 节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.198.12:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.198.13:/opt/kubernetes/cfg/
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
若以上的RBAC授权失败,请执行以下操作

在 node01 节点上操作
#在 node01 节点上操作
#启动 kubelet 服务
cd /opt/
#此处是本机node01地址
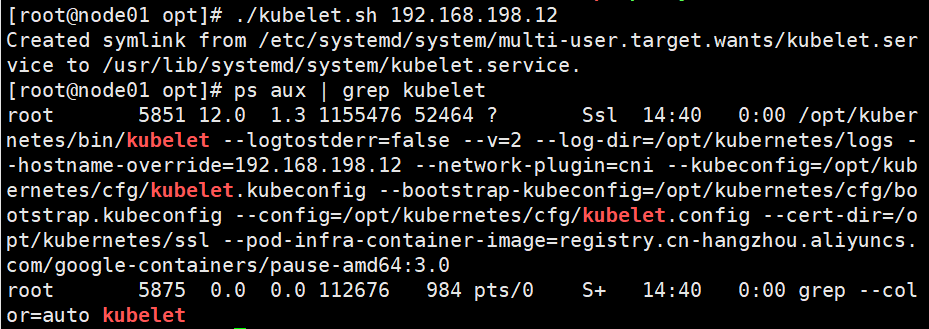
./kubelet.sh 192.168.198.12
ps aux | grep kubelet
在 master01 节点上操作
#在 master01 节点上操作,通过 CSR 请求
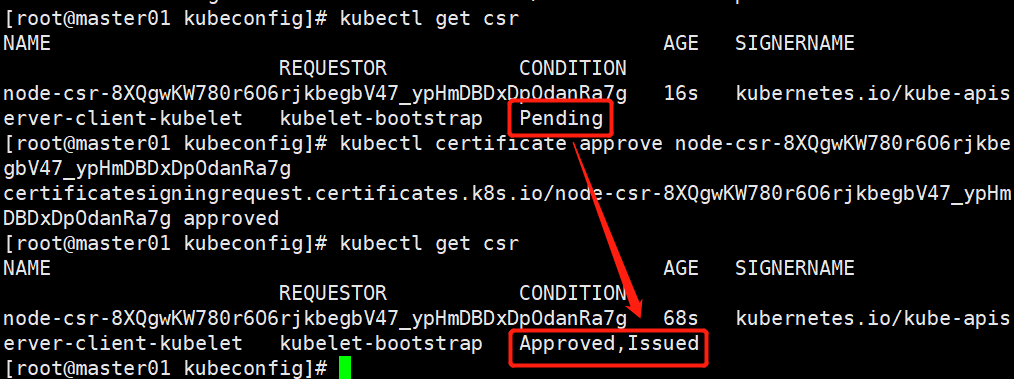
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-8XQgwKW780r6O6rjkbegbV47_ypHmDBDxDpOdanRa7g 16s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
#通过 CSR 请求,注意此处是前面node的节点签发证书kubectl certificate approve
kubectl certificate approve node-csr-8XQgwKW780r6O6rjkbegbV47_ypHmDBDxDpOdanRa7g
#Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr
#查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
kubectl get node

在 node01 节点上操作
#在 node01 节点上操作
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#启动proxy服务
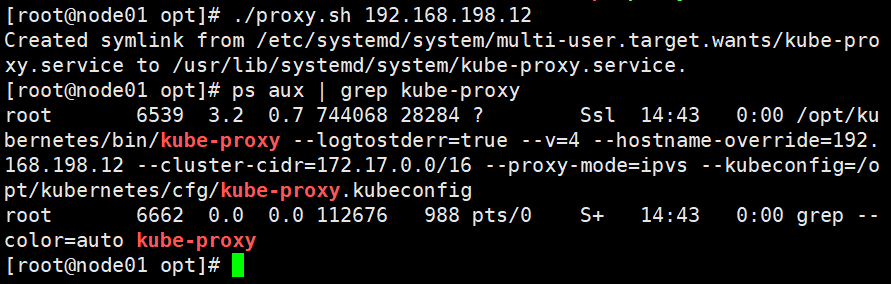
cd /opt/
./proxy.sh 192.168.198.12
ps aux | grep kube-proxy
7.部署网络组件
(1)K8S 中 Pod 网络介绍
①K8S 中 Pod 网络通信:
●Pod 内容器与容器之间的通信
在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命名空间,相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。
●同一个 Node 内 Pod 之间的通信
每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0/cni0 网桥,网段相同,所以它们之间可以直接通信。
●不同 Node 上 Pod 之间的通信
Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的通信只能通过宿主机的物理网卡进行。
要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。因此要满足两个条件:Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。
②Overlay Network:
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来。
通过Overlay技术(可以理解成隧道技术),在原始报文外再包一层四层协议(UDP协议),通过主机网络进行路由转发。这种方式性能有一定损耗,主要体现在对原始报文的修改。目前Overlay主要采用VXLAN。
③VXLAN:
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
④Flannel:
Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,目前支持 UDP、VXLAN、Host-gw 3种数据转发方式。
⑤Flannel UDP 模式的工作原理:
node跨节点通信
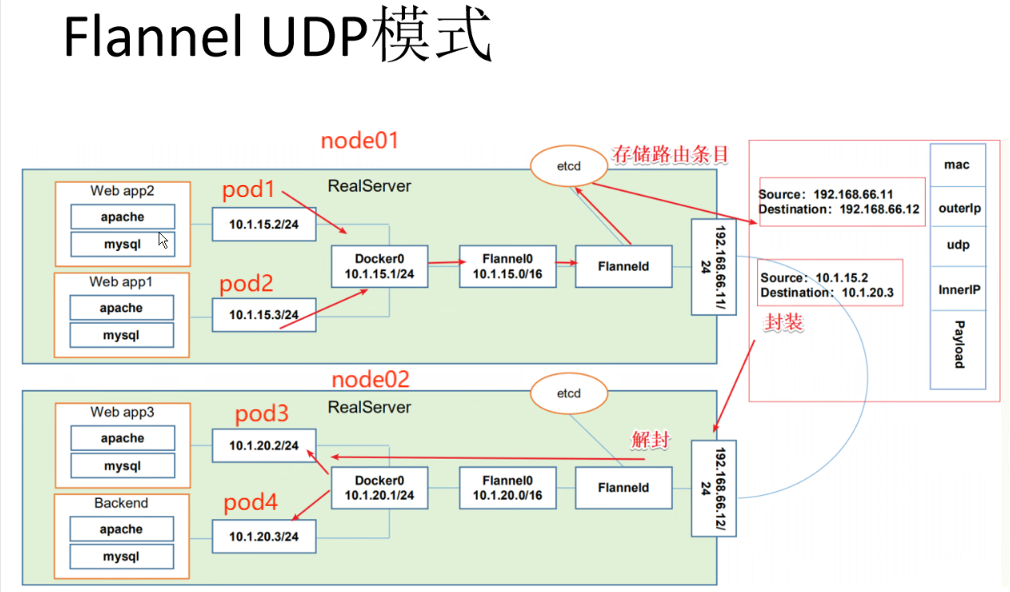
数据从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel0 接口,flanneld 服务监听在 flannel0 虚拟网卡的另外一端。
Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 A 的 flanneld 服务将原本的数据内容封装到 UDP 报文中, 根据自己的路由表通过物理网卡投递给目的节点主机 B 的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel0 接口, 之后被转发到目的主机的 docker0/cni0 网桥,最后就像本机容器通信一样由 docker0/cni0 转发到目标容器。
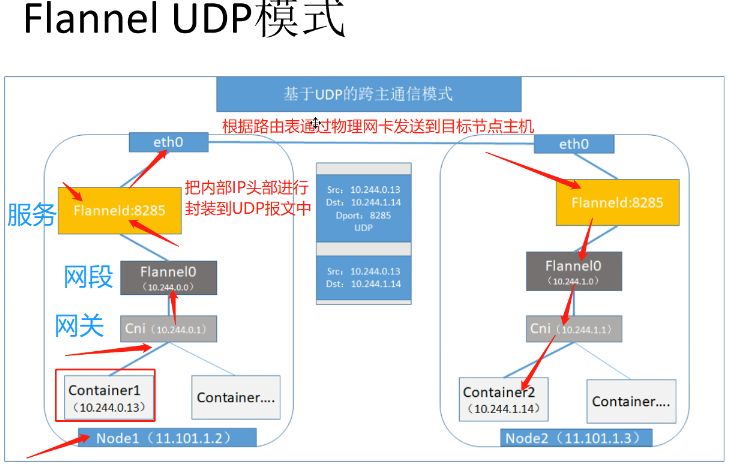
⑥ETCD 之 Flannel 提供说明:
存储管理Flannel可分配的IP地址段资源
监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
由于 UDP 模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的 VXLAN 模式差。
⑦VXLAN 模式:
VXLAN 模式使用比较简单,flannel 会在各节点生成一个 flannel.1 的 VXLAN 网卡(VTEP设备,负责 VXLAN 封装和解封装)。
VXLAN 模式下封包与解包的工作是由内核进行的。flannel 不转发数据,仅动态设置 ARP 表和 MAC 表项。
UDP 模式的 flannel0 网卡是三层转发,使用 flannel0 时在物理网络之上构建三层网络,属于 ip in udp ;VXLAN 模式是二层实现,overlay 是数据帧,属于 mac in udp 。
vxlan隧道方案:默认配置,利用内核级别的vxlan的封装host之间的传送包——好用
⑧Flannel VXLAN 模式跨主机的工作原理:
- 数据帧从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel.1 接口
- flannel.1 收到数据帧后添加 VXLAN 头部,封装在 UDP 报文中
- 主机 A 通过物理网卡发送封包到主机 B 的物理网卡中
- 主机 B 的物理网卡再通过 VXLAN 默认端口 4789 转发到 flannel.1 接口进行解封装
- 解封装以后,内核将数据帧发送到 cni0,最后由 cni0 发送到桥接到此接口的容器 B 中。
⑨Kubernetes的三种网络介绍
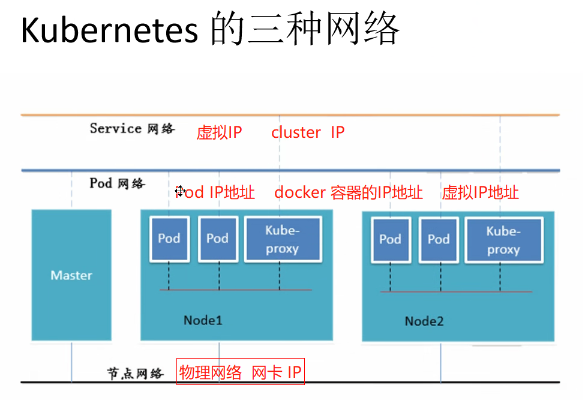
总:flannel三种网络模式
vxlan隧道方案: 默认配置,三层,利用内核级别的vxlan的封装host之间的传送包 好用,基于udp
host-gw路由网关 : 二层网络配置 不支持 云环境 ,通过在hst路由表中直接创建到其他主机subnet的路由条目
udp:在用户态实现的数据封装和解封装
(2)部署 flannel
在 node01 节点上操作
#在 node01 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir /opt/cni/bin -p
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
在 node02 节点上操作
#在 node02 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir /opt/cni/bin -p
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
在 master01 节点上操作
#在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
#加载上传的flannel的yml文件部署 CNI 网络
kubectl apply -f kube-flannel.yml
#用于在Kubernetes集群中获取kube-system命名空间中所有Pod的状态信息
kubectl get pods -n kube-system

#查看节点状态为ready正常
kubectl get nodes

(3)node02 节点部署
在 node01 节点上操作
#在 node01 节点上操作
cd /opt/
scp kubelet.sh proxy.sh root@192.168.198.13:/opt/
scp kubelet.sh proxy.sh root@192.168.198.11:/opt/
scp -r /opt/cni root@192.168.198.13:/opt/
在 node02 节点上操作
#在 node02 节点上操作
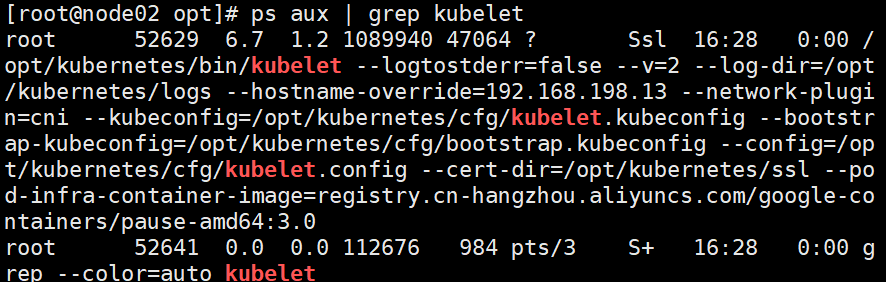
#启动kubelet服务
cd /opt/
chmod +x kubelet.sh
./kubelet.sh 192.168.198.13
ps aux | grep kubelet
在 master01 节点上操作
#在 master01 节点上操作
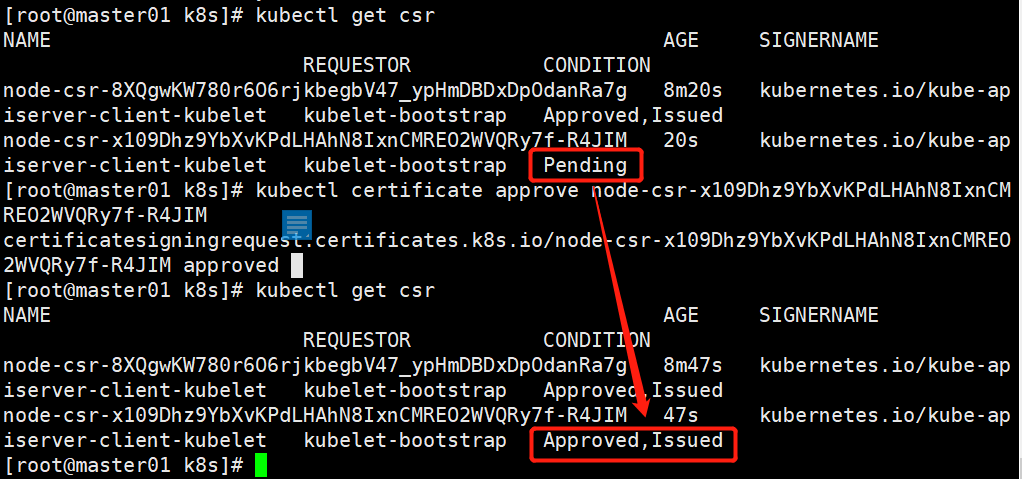
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-8XQgwKW780r6O6rjkbegbV47_ypHmDBDxDpOdanRa7g 8m20s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
node-csr-x109Dhz9YbXvKPdLHAhN8IxnCMREO2WVQRy7f-R4JIM 20s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
#通过 CSR 请求,注意kubectl certificate approve后面跟的是前面查询的节点
kubectl certificate approve node-csr-x109Dhz9YbXvKPdLHAhN8IxnCMREO2WVQRy7f-R4JIM
#查看
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-8XQgwKW780r6O6rjkbegbV47_ypHmDBDxDpOdanRa7g 8m47s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
node-csr-x109Dhz9YbXvKPdLHAhN8IxnCMREO2WVQRy7f-R4JIM 47s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
在node02上执行
#加载 ipvs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#使用proxy.sh脚本启动proxy服务
cd /opt/
chmod +x proxy.sh
./proxy.sh 192.168.198.13
在master01上执行
#查看群集中的节点状态
kubectl get nodes

(4)部署 CoreDNS
在所有 node 节点上操作
#在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar
在 master01 节点上操作
#在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
kubectl apply -f coredns.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6954c77b9b-7cgzv 1/1 Running 0 8s

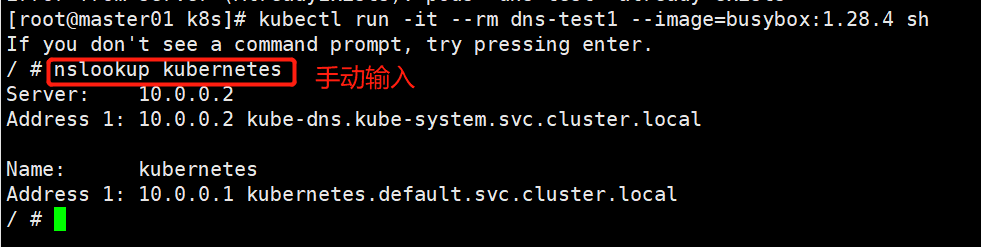
#DNS 解析测试
kubectl run -it --rm dns-test1 --image=busybox:1.28.4 sh
#执行后需要等待
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
(5)master02 节点部署
在 master01 节点上操作
#从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
scp -r /opt/etcd/ root@192.168.198.14:/opt/
scp -r /opt/kubernetes/ root@192.168.198.14:/opt
scp -r /root/.kube root@192.168.198.14:/root
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@192.168.198.14:/usr/lib/systemd/system/
#修改配置文件kube-apiserver中的IP
vim /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://192.168.198.11:2379,https://192.168.198.12:2379,https://192.168.198.13:2379 \ #修改为master01、node01、node02地址
--bind-address=192.168.198.14 \ #修改为master02地址
--secure-port=6443 \
--advertise-address=192.168.198.14 \ #修改为master02地址
......
在 master02节点上操作
hostnamectl set-hostname master02
bash
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#在 master02 节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service
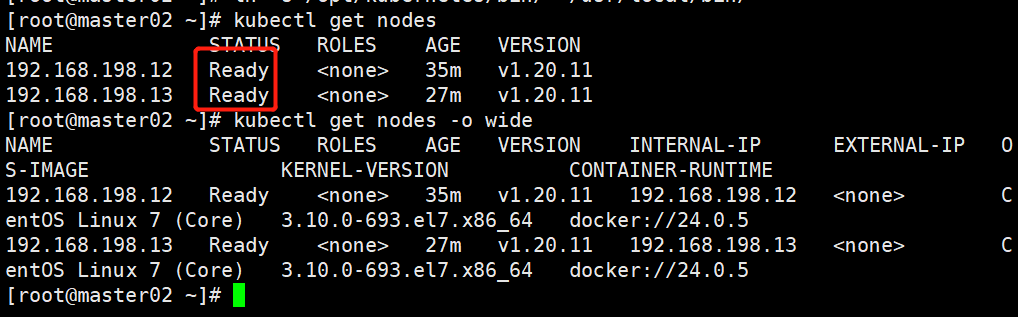
#查看node节点状态
ln -s /opt/kubernetes/bin/* /usr/local/bin/
kubectl get nodes
kubectl get nodes -o wide #-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名
#此时在master02节点查到的node节点状态仅是从etcd查询到的信息,而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来
8.负载均衡部署
#配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
在nginx+keepalive01、nginx+keepalive02节点上操作
hostnamectl set-hostname kp01
hostnamectl set-hostname kp02
bash
systemctl stop firewalld
systemctl disable firewalld
#配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y
#修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
#添加以下配置
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.198.11:6443;
server 192.168.198.14:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
http {
......
#检查配置文件语法
nginx -t
#启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx
此处报错
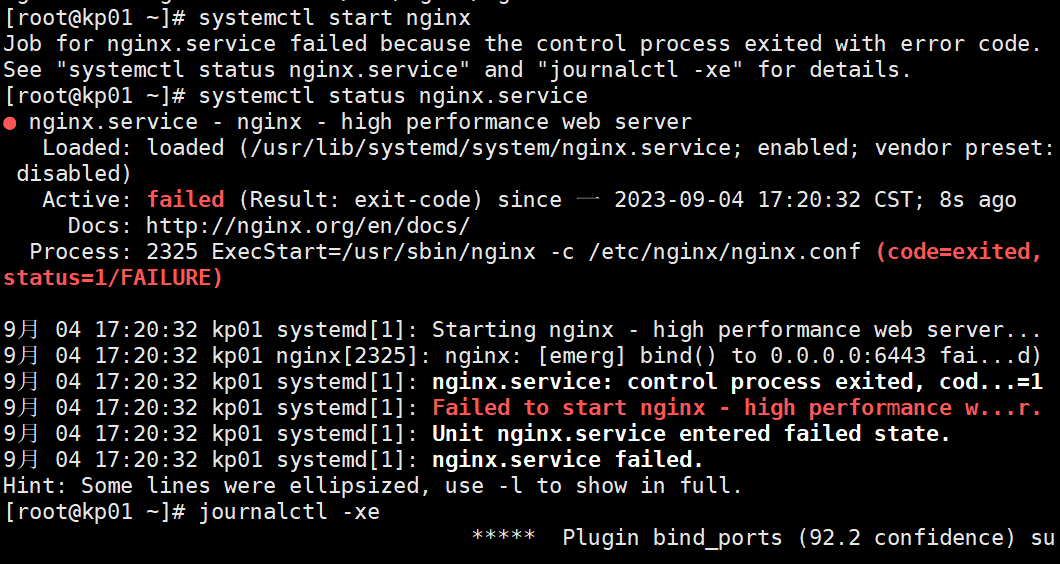
nginx.service - nginx - high performance web server
Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since 一 2023-09-04 17:20:32 CST; 8s ago
Docs: http://nginx.org/en/docs/
Process: 2325 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=1/FAILURE)9月 04 17:20:32 kp01 systemd[1]: Starting nginx - high performance web server…
9月 04 17:20:32 kp01 nginx[2325]: nginx: [emerg] bind() to 0.0.0.0:6443 fai…d)
9月 04 17:20:32 kp01 systemd[1]: nginx.service: control process exited, cod…=1
9月 04 17:20:32 kp01 systemd[1]: Failed to start nginx - high performance w…r.
9月 04 17:20:32 kp01 systemd[1]: Unit nginx.service entered failed state.
9月 04 17:20:32 kp01 systemd[1]: nginx.service failed.
Hint: Some lines were ellipsized, use -l to show in full.解决问题:
根据提供的日志信息可以看到,系统尝试启动 nginx 服务时出现了错误。错误提示信息为 “nginx: [emerg] bind() to 0.0.0.0:6443 failed”,这表明在绑定端口 6443 时出现了问题。
根据错误提示,可能的原因是 SELinux 设置阻止了 nginx 绑定到该端口。您可以尝试以下解决方法:
修改 SELinux 策略:使用以下命令允许 nginx 绑定到端口 6443:
semanage port -a -t http_port_t -p tcp 6443
#启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx


#部署keepalived服务
yum install keepalived -y
#修改keepalived配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
#接收邮件地址
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
#邮件发送地址
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER #lb01节点的为 NGINX_MASTER,lb02节点的为 NGINX_BACKUP
}
#添加一个周期性执行的脚本
vrrp_script check_nginx {
script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}
vrrp_instance VI_1 {
state MASTER #lb01节点的为 MASTER,lb02节点的为 BACKUP
interface ens33 #指定网卡名称 ens33
virtual_router_id 51 #指定vrid,两个节点要一致
priority 100 #lb01节点的为 100,lb02节点的为 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.198.100/24 #指定 VIP
}
track_script {
check_nginx #指定vrrp_script配置的脚本
}
}
#创建nginx状态检查脚本
vim /etc/nginx/check_nginx.sh
#!/bin/bash
#egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID,即脚本运行的当前进程ID号
count=$(ps -ef | grep nginx | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
chmod +x /etc/nginx/check_nginx.sh
#启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
systemctl start keepalived
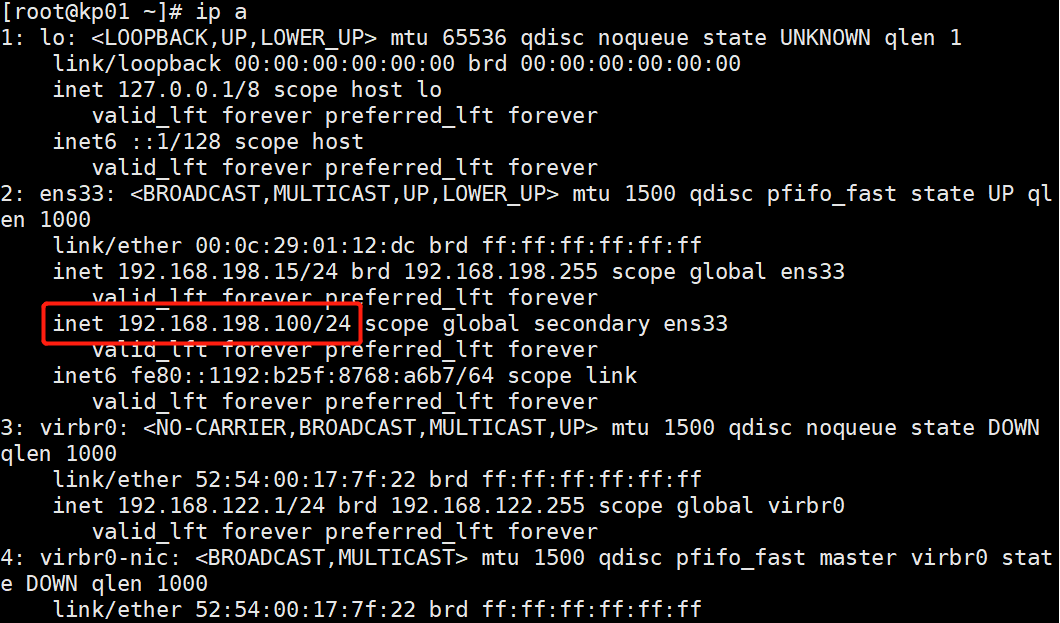
systemctl enable keepalived
ip a #查看VIP是否生成
node01、node02节点操作
#修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
cd /opt/kubernetes/cfg/
vim bootstrap.kubeconfig
server: https://192.168.198.100:6443
vim kubelet.kubeconfig
server: https://192.168.198.100:6443
vim kube-proxy.kubeconfig
server: https://192.168.198.100:6443
#重启kubelet和kube-proxy服务
systemctl restart kubelet.service
systemctl restart kube-proxy.service
在 nginx+keepalived01 上操作
#在 lb01 上查看 nginx 和 node 、 master 节点的连接状态
netstat -natp | grep nginx
tcp 0 0 0.0.0.0:6443 0.0.0.0:* LISTEN 55404/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 55404/nginx: master
tcp 0 0 192.168.198.15:45054 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.15:45032 192.168.198.11:6443 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45030 192.168.198.11:6443 ESTABLISHED 55408/nginx: worker
tcp 0 0 192.168.198.15:45044 192.168.198.11:6443 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45046 192.168.198.11:6443 ESTABLISHED 55406/nginx: worker
tcp 0 0 192.168.198.15:45024 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32804 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.15:45064 192.168.198.11:6443 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45426 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45424 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45428 ESTABLISHED 55406/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45434 ESTABLISHED 55406/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45388 ESTABLISHED 55408/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32800 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.15:45062 192.168.198.11:6443 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45018 192.168.198.11:6443 ESTABLISHED 55408/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32774 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32808 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45048 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.15:45052 192.168.198.11:6443 ESTABLISHED 55406/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45432 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32806 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45040 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.15:45056 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32780 ESTABLISHED 55407/nginx: worker
tcp 0 0 192.168.198.15:45058 192.168.198.11:6443 ESTABLISHED 55405/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.13:45394 ESTABLISHED 55408/nginx: worker
tcp 0 0 192.168.198.100:6443 192.168.198.12:32798 ESTABLISHED 55405/nginx: worker
在 master01 节点上操作
#测试创建pod
kubectl run nginx --image=nginx
pod/nginx created
#查看Pod的状态信息
kubectl get pods
#ContainerCreating 正在创建中
NAME READY STATUS RESTARTS AGE
nginx 0/1 ContainerCreating 0 7s
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 71s
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-nf9sk 0/1 ContainerCreating 0 33s #正在创建中
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-nf9sk 1/1 Running 0 80s #创建完成,运行中
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 91s 10.244.0.3 192.168.198.12 <none> <none>
#READY为1/1,表示这个Pod中有1个容器
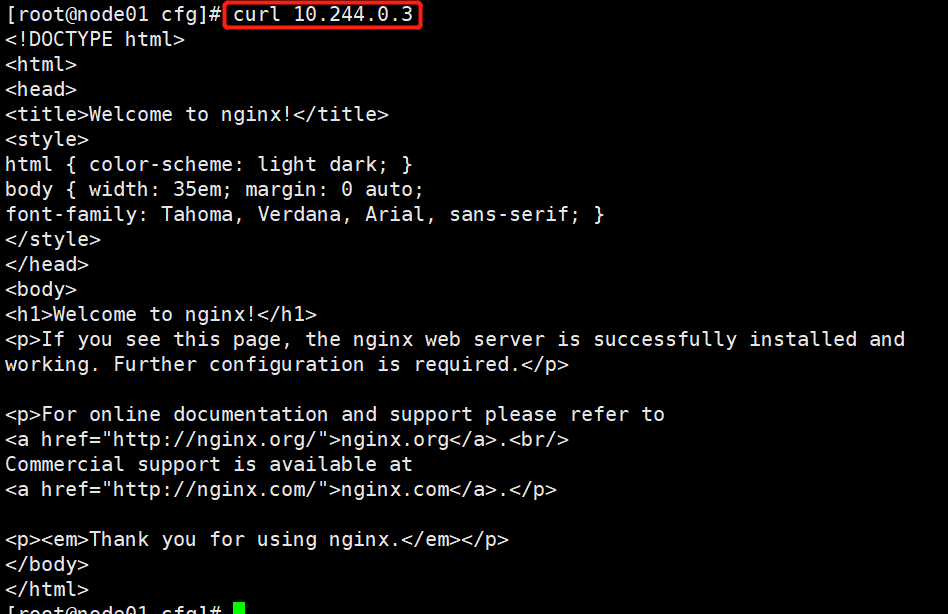
#在对应网段的node节点上操作,可以直接使用浏览器或者curl命令访问,此处是由上面查询到的 192.168.198.12 是node01节点进行查看访问
curl 10.244.0.3
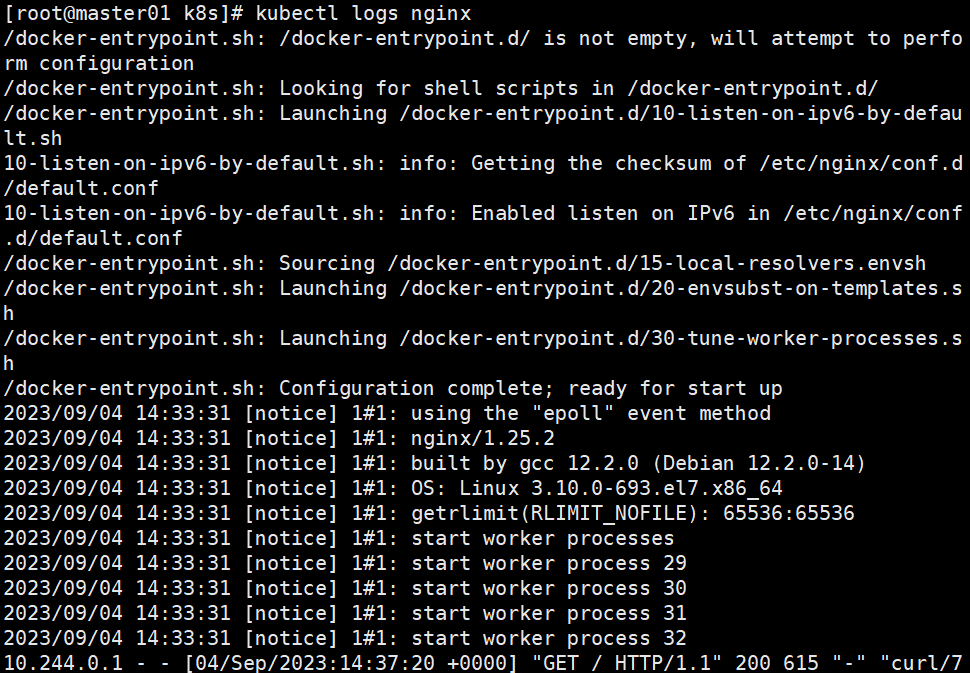
#这时在master01节点上查看nginx日志
kubectl logs nginx
9.部署 Dashboard
(1)Dashboard 介绍
仪表板是基于Web的Kubernetes用户界面。您可以使用仪表板将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,并管理集群本身及其伴随资源。您可以使用仪表板来概述群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如deployment,job,daemonset等)。例如,您可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。仪表板还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
(2)Dashboard部署
在 master01 节点上操作
#在 master01 节点上操作
#上传 recommended.yaml 文件到 /opt/k8s 目录中
cd /opt/k8s
vim recommended.yaml
#默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: NodePort
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
port: 443
targetPort: 8443
nodePort: 30001 #添加
type: NodePort #添加
selector:
k8s-app: kubernetes-dashboard
kubectl apply -f recommended.yaml
#创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
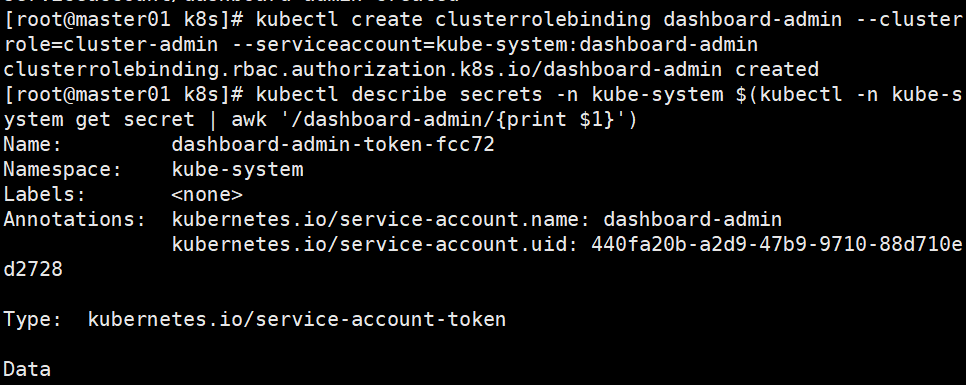
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
#使用输出的token登录Dashboard,node01地址或者node02地址
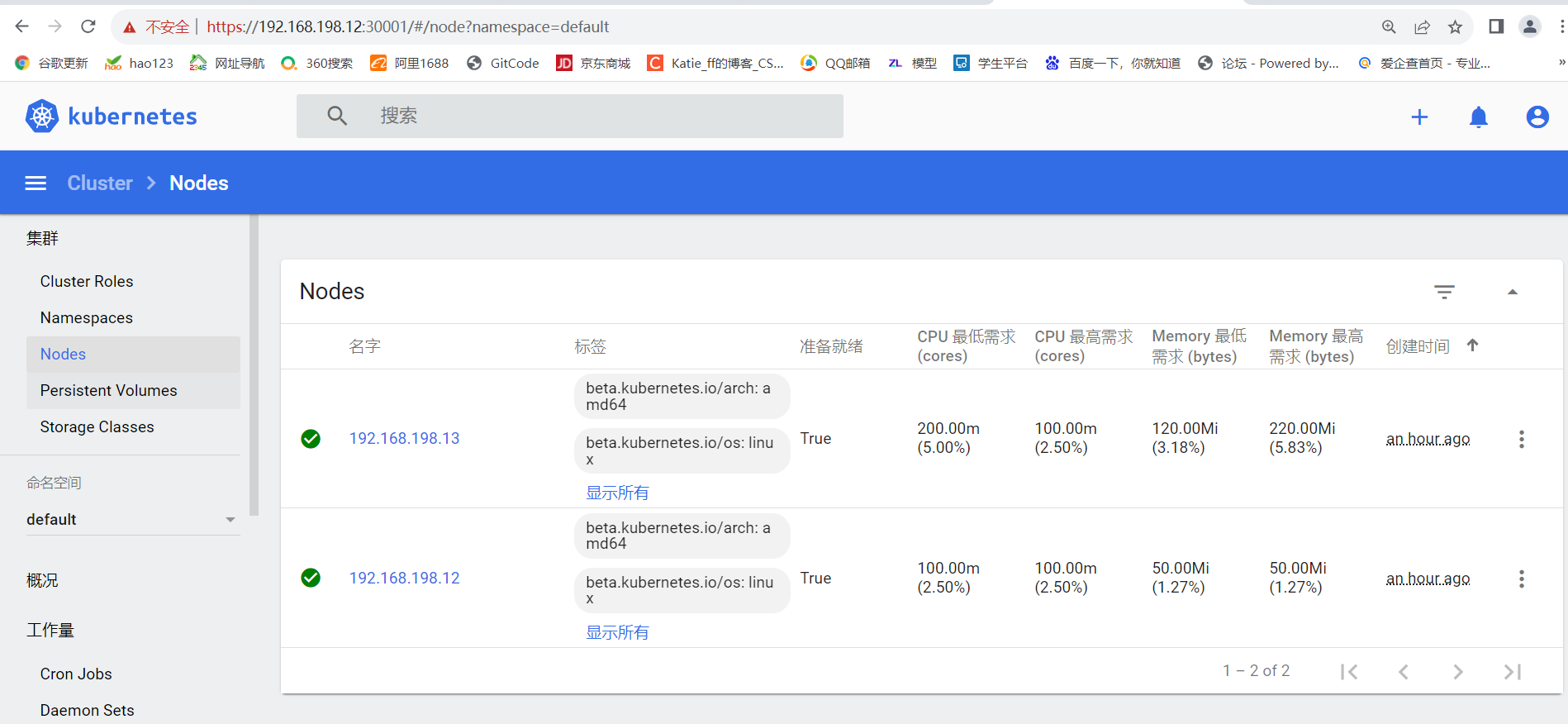
https://192.168.198.12:30001/
出现这个界面后直接停在页面输入this is unsafe (不用空格),回车即可
#将下面这条命令执行出来的token复制到以下,随后点击登录
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
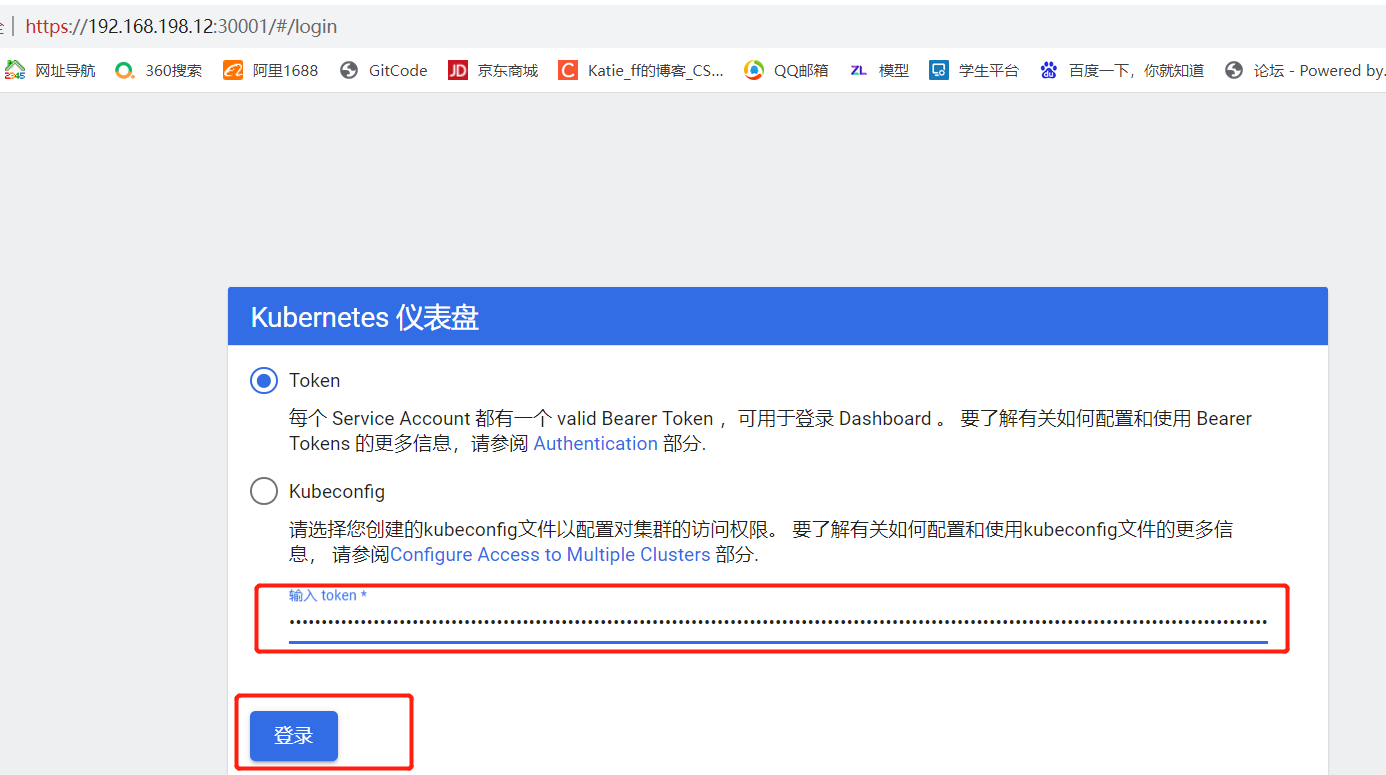
已搭建成功