CNN(Convolutional Neural Network)
本文主要来讲解卷积神经网络。所讲解的思路借鉴的是李宏毅老师的课程。
CNN,它是专门被用在影像上的。
Image Classification
我们从影像分类开始说起。
我们举例来说,它固定的输入大小是100*100的解析度(假设不会出现大小不同的照片,实际上即使大小不同,我们也可以把它变成一样大小的),然后丢到一个Model里面。我们的目标是对图像进行分类。最后输出的是一个one-hot的vector,那么这个向量的长度,就决定了你可以辨识出多少不同种类的东西(如下图)。
那么,你的Model可能会输出一个 y ′ y' y′,那我们就想要我们的 y ′ y' y′和 y ^ \hat{y} y^之间的Cross-entrpy越小越好。
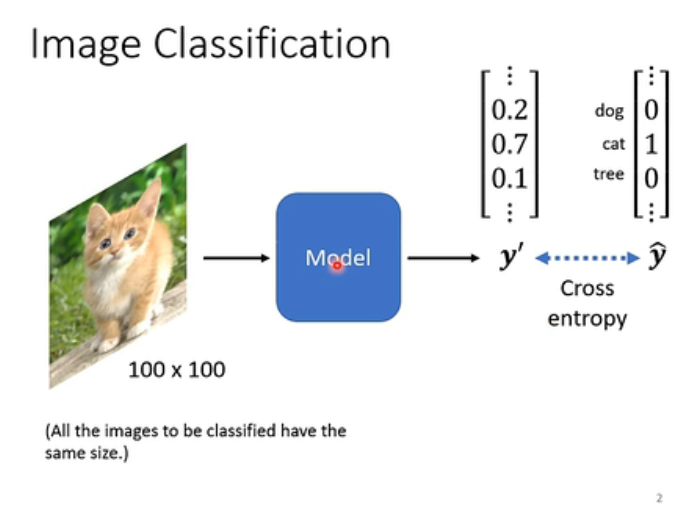
那么接下来的问题就是,我们怎么样把这个图片输入到这个Model里。
那么一张影响,对于电脑来说,就是一个三维的Tensor,分别代表图片的长、宽和通道数(即我们所说的channel),那我们把这个三位的Tensor拉直,我们就可以直接丢到我们的Network里。也就是说(我们还是假设我们图片的像素是100*100的),我们的向量是3个100 * 100向量组合起来的(如下图)。然后每一维每个颜色的数值就代表的是当前位置该颜色的强度。
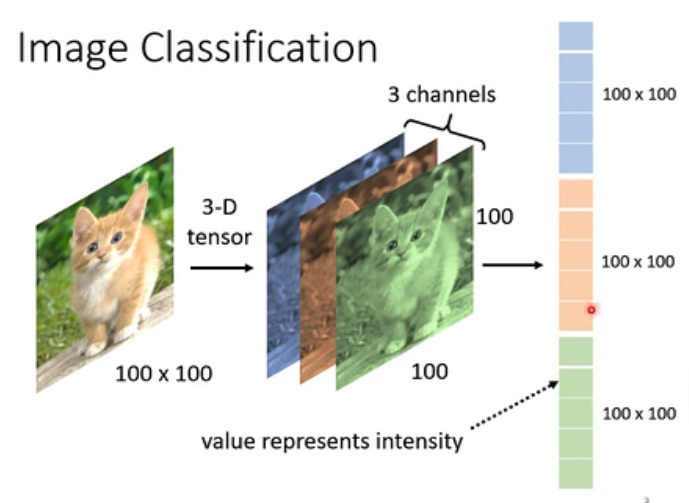
但是,问题显而易见了。如果说拉直之后,直接丢到fully connected neural里面,倘若中间第一层隐藏层有1000个神经元,那么现在在中间的这个变换矩阵中,就要有 3 ∗ 1 0 7 3*10^7 3∗107个元素。它是一个很大的数值了。我们说参数很多确实会增加模型的弹性,但是呢,它也增加了overfitting的风险。那我们有没有什么好的解决办法呢?
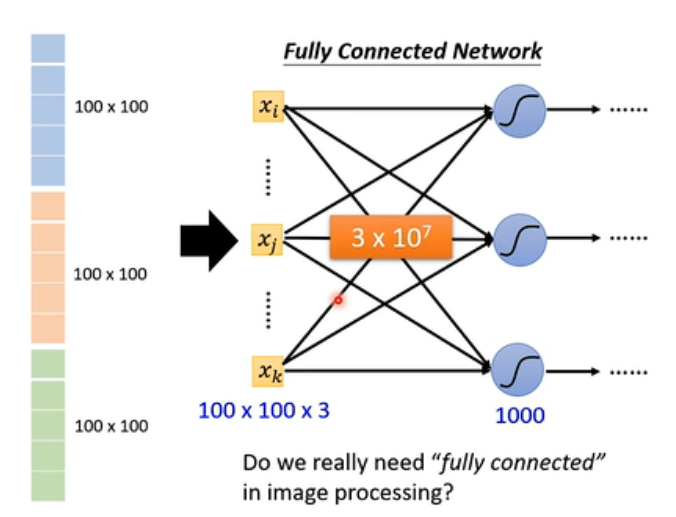
在影像这样特殊的问题上,我们会有特殊的方法。
我们可以先来观察:
观察点1:并不是图片的所有部分都需要一一去看

对于一个影像而言(比如说一个鸟,如上图),我们的神经网络怎么样才会知道它是一个鸟呢?也许说,某个神经元看到了一个鸟嘴,某个神经元看到了一个鸟眼,某个神经元又看到了一个鸟的爪子…那么就能够识别这是一只鸟了。你或许会觉得这样的方法好像很挫,但是,仔细想一想,似乎人类也是用这样的方法来去辨别这是一只鸟的吧。
所以,对于一张图片来说,我们不需要看到它一整个完全的部分,我们只需要能看到某些关键的部分,就能够辨识出这一个图片是什么东西。而这些关键的东西相对于一整个图像而言,通常就会小很多,那么我们Neural的复杂程度也就会小很多。
简化1:
通过这样一个观察,我们就能做这样的简化:
我们规定出一个Receptive field,它的大小呢可以随意(我们假设是3* 3 *3),然后,每一个neural都只关心自己的receptive field里面的东西就好了。即每一个receptive field都对应一个neural。
那这个neural怎么来考虑这个receptive field呢?我们的办法是把它拉直,就是三个3*3的向量,然后再将这3 * 3 * 3 = 27维的向量的每一个维度一个weight,然后再加上一个bias,将算出的结果输出到下一层当作输入。
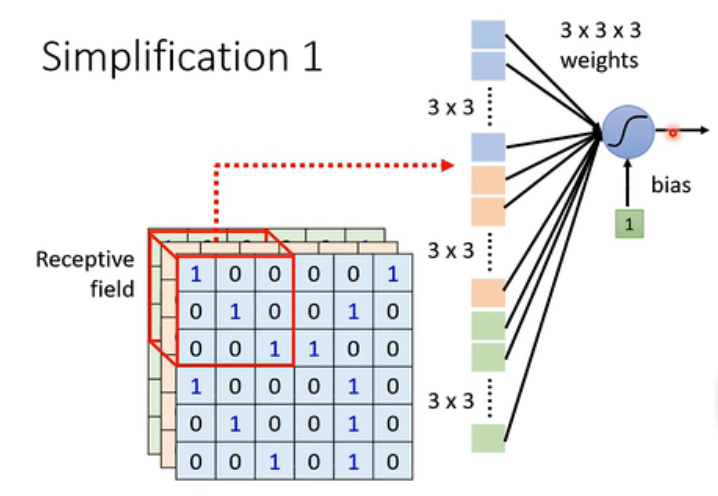
好,我们说每一个receptive field对应着一个neural,那这个receptive field是怎么定义出来的呢?答:这个是你自己来去决定的。包括它的大小,它的形状等等,并且,receptive field和receptive field之间还是可以重叠的,并且receptive field也可以仅考虑一些channel(就是不考虑三个,只考虑两个或者1个)。
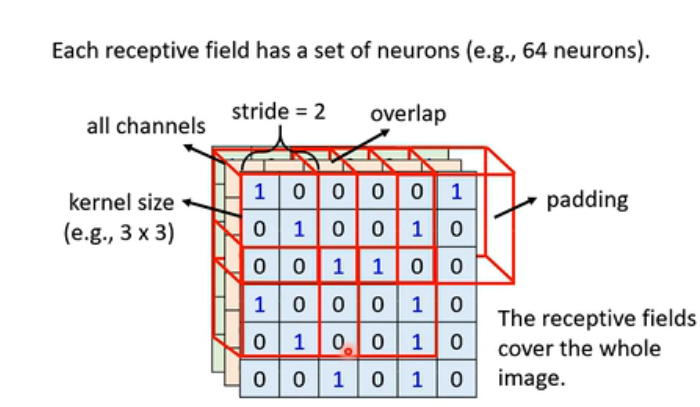
不过虽然说你可以任意设计,但是还是要来说一说最经典的receptive field的设计方式(Typical Setting):
1、会看所有的channel。所以我们将receptive field的时候,就直接去讲它的高和宽就可以了。而高和宽合起来叫做kernel size(eg., 3*3)
2、每一个receptive field往往会有一组neuron(eg.,64)去和它对应。
3、stride(eg.,1,2),即你可以按照自己的意愿移动的receptive field的步长。
4、倘若receptive field超出了影像的范围,可以做padding(补值,比如补0,或者整张影像的平均值等)
5、扫过整张图片。
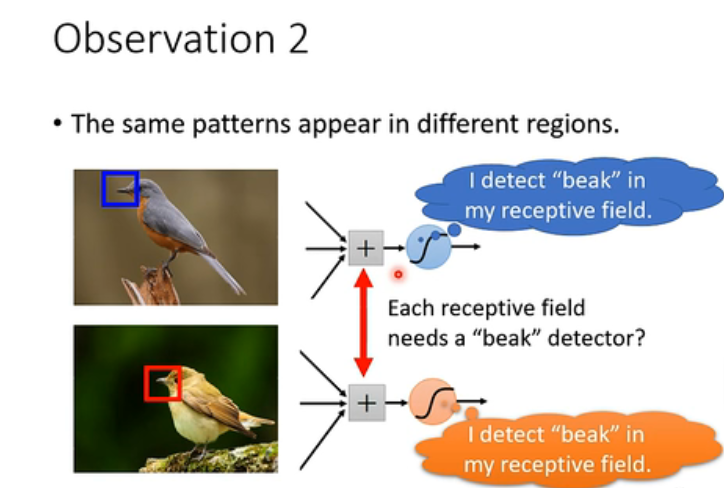
观察点2: 图片相同的样式可能出现在图片的不同的区域里
比如说我们刚刚上面说到的鸟嘴,在不同的图片里,它们都要去识别这个鸟嘴。那实际上它们做的事情是一样的,只不过它们随对应的范围是不一样的而已。但是,它们做的事情是一样的了,我们似乎就没有必要再搞两个功能相同的neural了,因为这就会造成冗余。
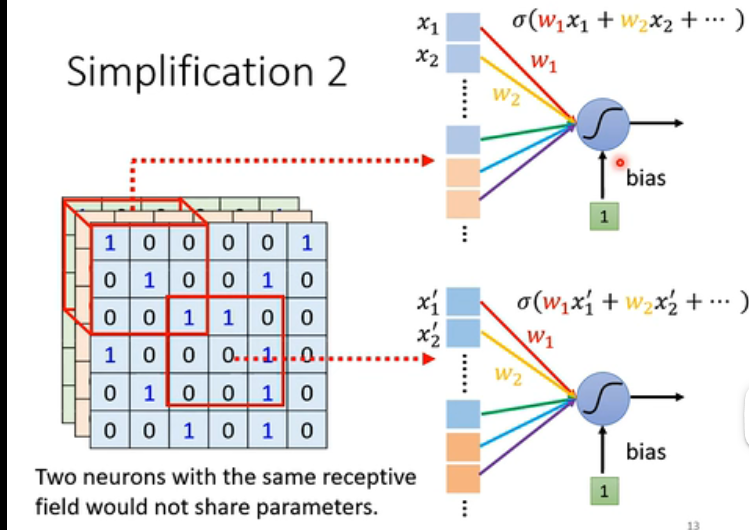
简化2:让不同的neural共享参数
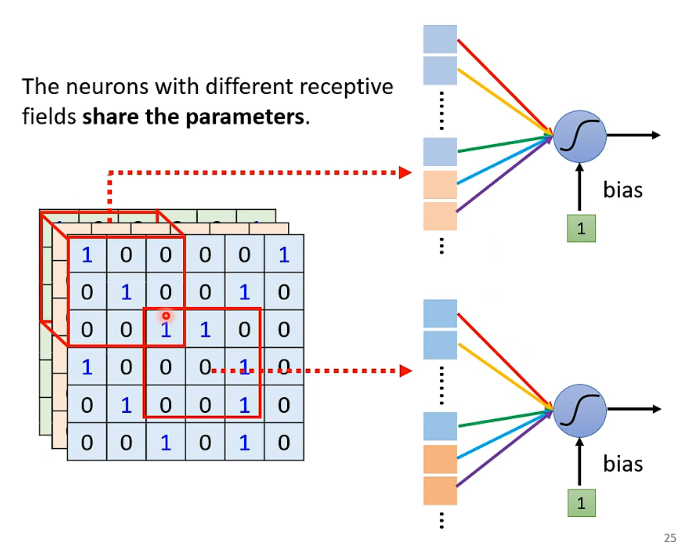
道理很简单。所谓共享参数,共享的是weight,也就是说,我们把下面的两个neural合并成一个,然后将它们的 w 1 w_1 w1、 w 2 w_2 w2…的参数共享。那么这个神经元所对应的范围就应当是下图中两部分的红色方框(即两个receptive field),怎么共享当然也可以大家自己来决定。
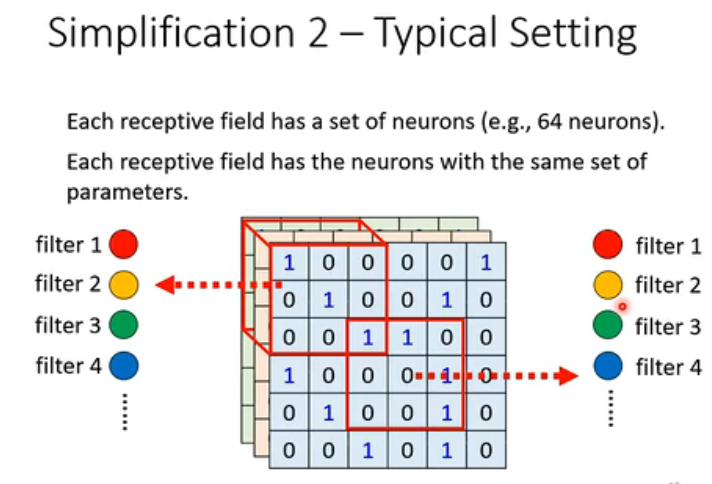
我们还是要来说一说常见的设置方法(即Typical Setting)
一个receptive field假设有64个neurons,那这些receptive field如果共享一组参数,也就是下方的两组神经元一一对应(实际上合并成了一个),红色和红色相对应合并,黄色和黄色相对应合并…
那,我们就称第一组参数为filter 1,第二组参数filter 2,第三组参数为filter 3…
我们来整理一下我们刚刚都说了些什么:
我们说,Fully-Conneected network是弹性最大的,但我们说我们只需要去看图像中重要关键的部分就可以了,所以我们就有了receptive field;然后呢,我们又说因为图片中有些特征在不同的地方实际上是相同的,所以我们又加上了Parameter Sharing,即参数共享。那receptive field加上Parameter sharing,就是Convolutional Layer(如下图)
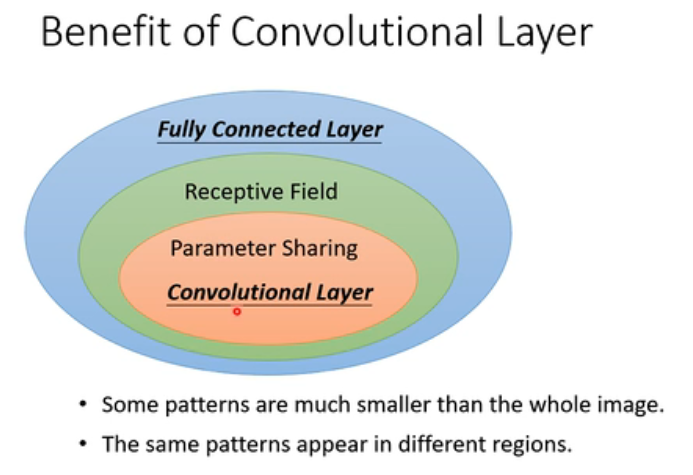
大家需要注意的是,刚刚说的这些特征都是在图像问题上才会被更好地使用,倘若所使用的范围不说图像,那就需要判断说它有没有我们刚刚所说到的这些特征。如果没有,那么它可能不适合用Convolutional Layer。
另一种介绍方式
这一种方式也是常见的介绍CNN的方式,但和刚刚我们上面所说到的意思是一样的(就是同一个东西用不同的方法介绍而已):
我们说,什么是Convolutional Layer呢?
这个Layer它有数个的Filter,每一个Filter都是3* 3 * channel大小的tensor
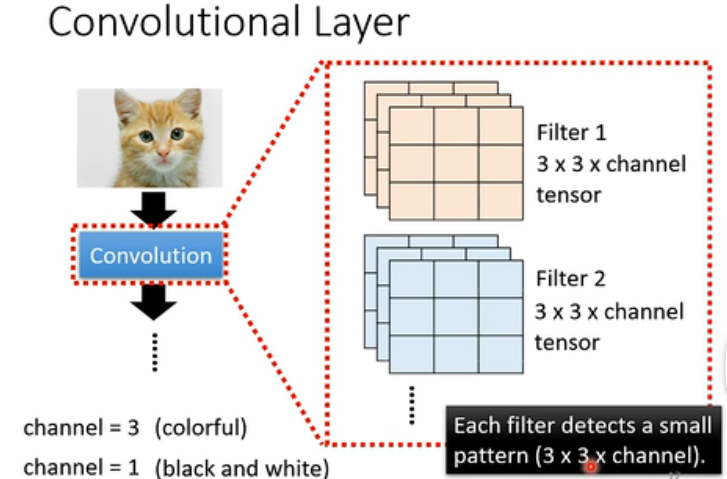
那channel数如果为3,就代表着这个图片是彩色的,如果channel数为1,就代表这个图片是黑白的。
每一个filter,就代表了它要识别的Pattern,或者说要守备的范围。
那这些filter是怎么样从图片当中抓Pattern的呢?我们来举几个例子:
我们假设现在channel = 1,然后filter里面的数值都是已知的(实际上是未知的,也就是需要通过梯度下降来去求解的,但我们为了方便观察其是怎么工作的,我们就假设它已经找出来了)
其实过程很简单,我们就让这个Filter 1和这个矩阵的左上角(3*3,和Filter一样大)相乘(将矩阵中对应的元素直接相乘,然后再相加),如下图中,经过计算得到3;然后再把这个矩形框向右移动(因为我们这里假设了Stride = 1),重复同样的操作即可。
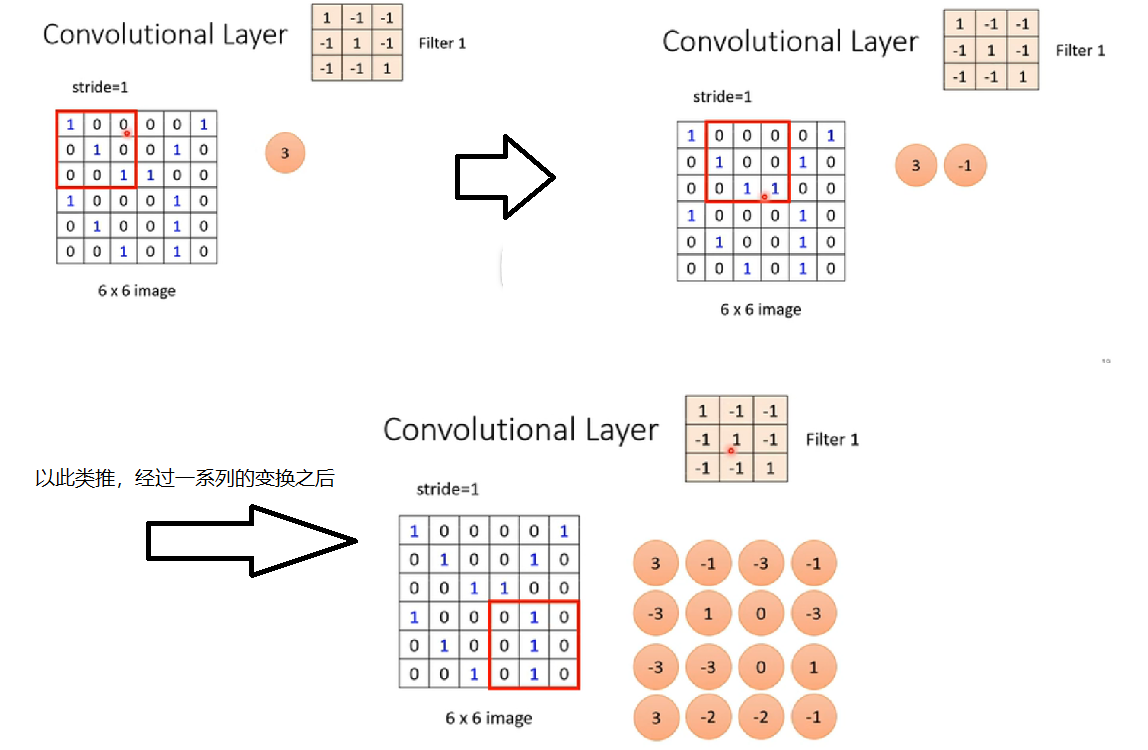
然后第二个、第三个(如果有)Filter就同理了,对每一个Filter也都进行相同的操作就可以了。
例如,我们下面也将Filter 2进行同样的操作,又得到一组数值。
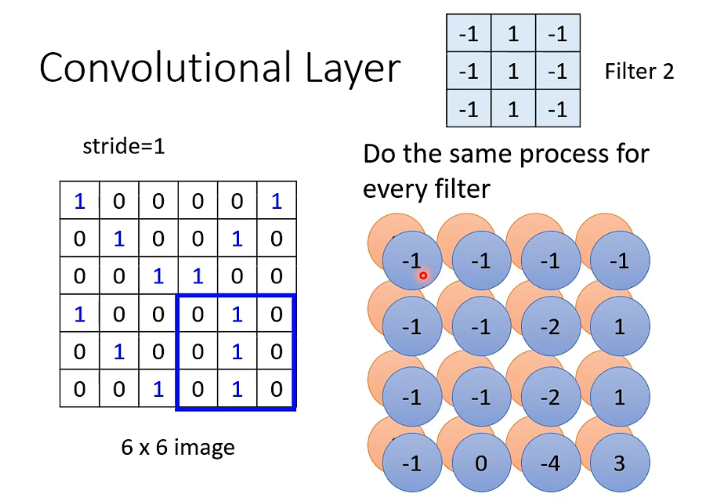
那假如说我有64个这个的Filter,那就是有64群这个的数据。那经过Filter算出来的这些数呢,它们也有自己的名字,叫做Feature Map
那如果是多层的卷积神经网络,如下图所示,如果说,我们总共有64个Filter,假设本身它的channel数是1,那结合我们上面的分析得知,经过第一层卷积层之后,它会有64张二维的图像叠在一起。所以,它的通道数就变成了64,即channel = 64。
那么,第一个卷积层它们得到的结果,我们也可以看成是一个图像。只不过,它的通道数是64。那接下来在第二层上的Filter的深度就是64
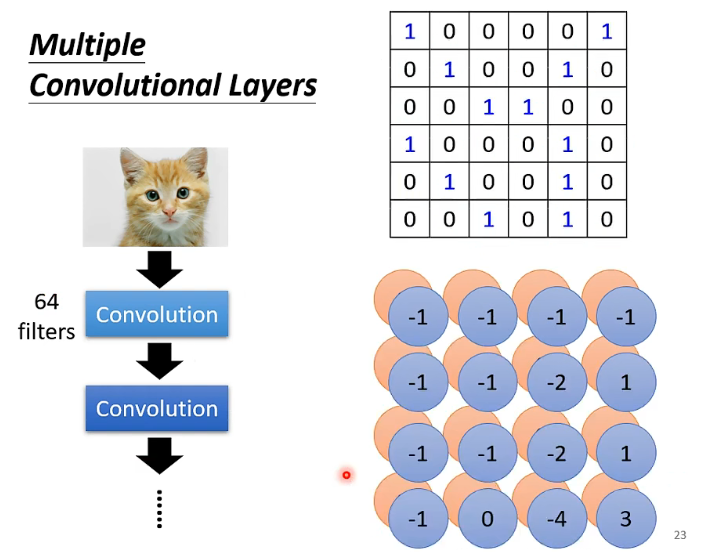
那现在有一个问题,就是如果我们一直让我们的Filter 是3*3,会不会让我们的图像难以识别较大范围的Pattern呢?其实想一想,如果按照这样一种方式下去,它的不会的。因为可以设想一下,在第二次的卷积层一个3 *3的话,对应在第一层卷积层上应该是5 * 5,对应到原图像上就会是7 * 7。那如果我们继续往下叠卷积层,就是说我如果把卷积层弄得再多一点,那最终同样是一个Filter,对应到原图像上就会更加宽广。
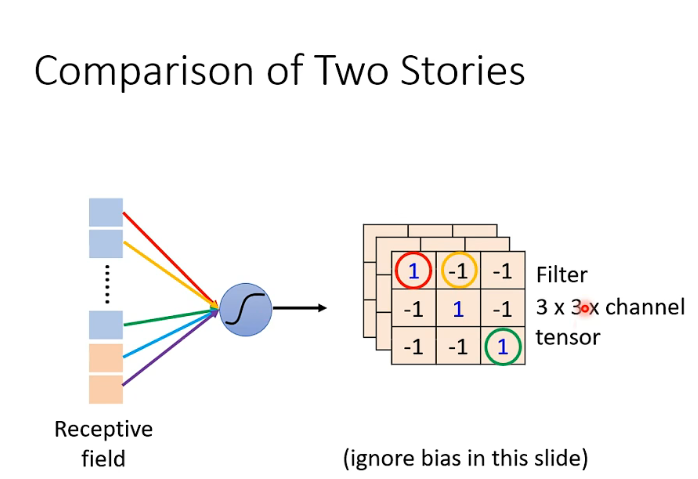
对比这两种方式
实际上,这两种方式是一模一样的。我们在第一种方式里讲解的共享参数,就是第二种方式里Filter的计算。只不过呢,在第二种方式里没有Bias。不过其实用第二种方式也可以是有Bias的,只不过我们刚刚没有提到,忽略掉了。
那我们说的Share the parameters,就是把一整个图片扫一遍,也就是我们在第一种方式里说的不同的receptive field。把全部图片扫一遍的这个过程,实际上就是叫做Convolution。
发现三:Pooling
我们会发现,Subsamlping并不会改变图像中的物体
举例来说,你把一个图像中偶数的Column都拿掉,奇数的Row都拿掉,那么你最后的图片是原来的 1 4 \frac{1}{4} 41,但是不会影响图片里面是什么东西。也就是把原来的图片给缩小了。

这个Pooling它没有要learn的东西的,就是说,它就只是一个Operator,它的行为都是固定好的,没有要和Data去互动的东西。
Pooling实际上也有很多不同的版本啦。比如Max Pooing。
举例来说,Max Pooling,我们把最后得到的图像,2 * 2一组且分开,然后每组留下最大的数。
留下谁是你自己决定的,因为是MaxPooling,所以你就留下最大的数,那如果是MinPooling,那就留下最小的数。也不一定是要2 * 2一组,你也可以3 * 3一组。就是说,这些都很灵活的。
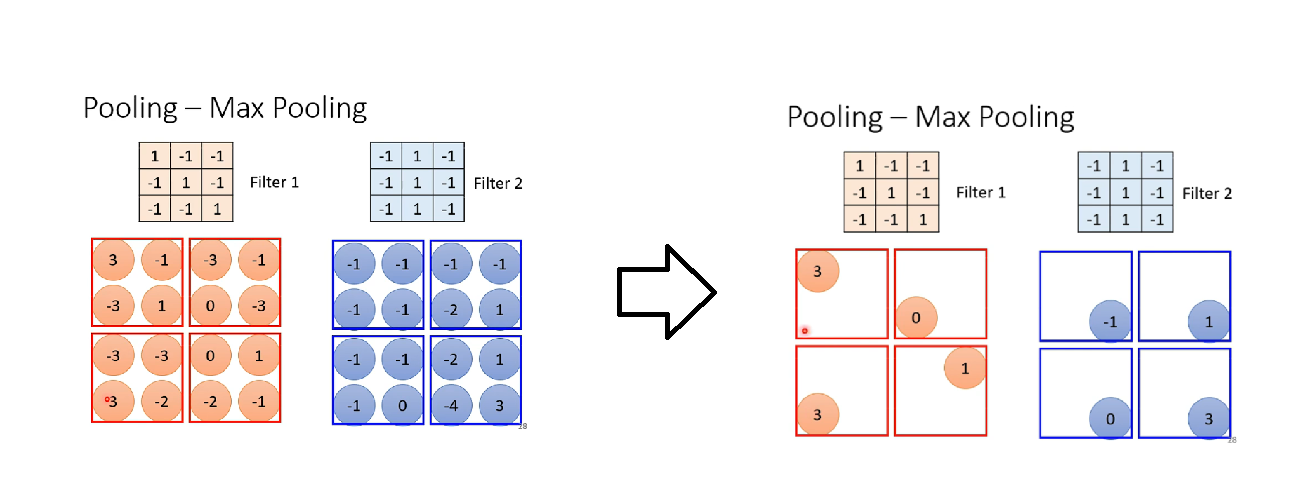
然后,我们在实际的运作中,往往是先经过Convolution提取特征,然后再经过Pooling,再Pooling的过程中,Channel数是不变的。
然后,一般往往会重复Convolution和Pooling这样的一组操作。
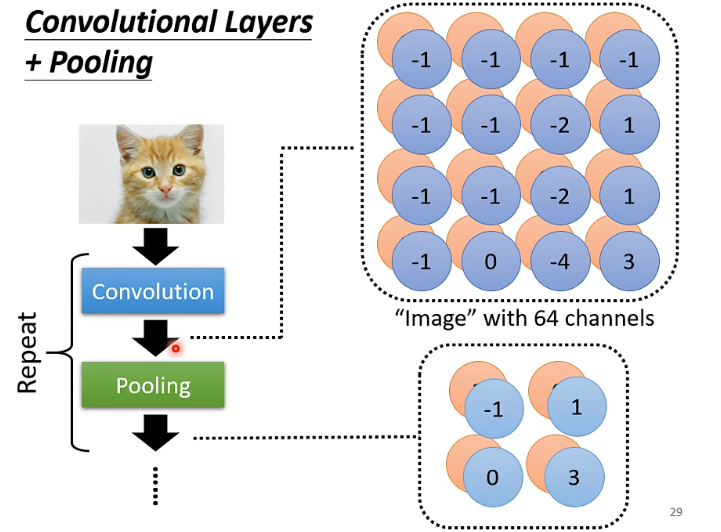
不过由于Pooling可能对你的图像还是会有比较大的损害的,所以近年来,随着算力资源的不断增强(Pooling的存在也就是为了简化计算的,本质上也是在提取特征),往往很多人都会选择Convoltion从头到底。这样,可以最大限度地保留图片的关键信息不受破坏。
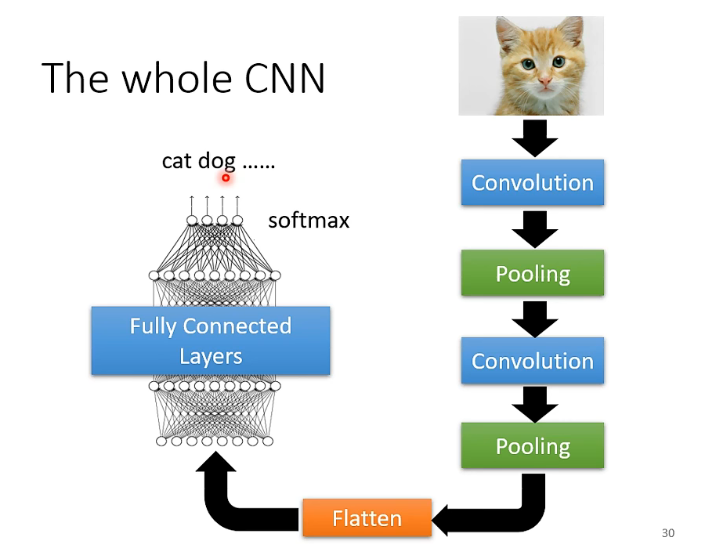
那么对于一整个CNN而言,在经过若干个Convolution和Pooling之后,会将得到的矩阵Flatten,字面意思是扁平化,就是拉直。然后把它丢到Fully connected Layers里面,最后再经过softmax的操作,就得到的分类的结果。
voltion从头到底。这样,可以最大限度地保留图片的关键信息不受破坏。
那么对于一整个CNN而言,在经过若干个Convolution和Pooling之后,会将得到的矩阵Flatten,字面意思是扁平化,就是拉直。然后把它丢到Fully connected Layers里面,最后再经过softmax的操作,就得到的分类的结果。