由来
该算法最早在文本挖掘领域被提出,用于找到文本的隐含语义。
核心思想是通过隐含特征(latent factor) 联系用户兴趣和物品。
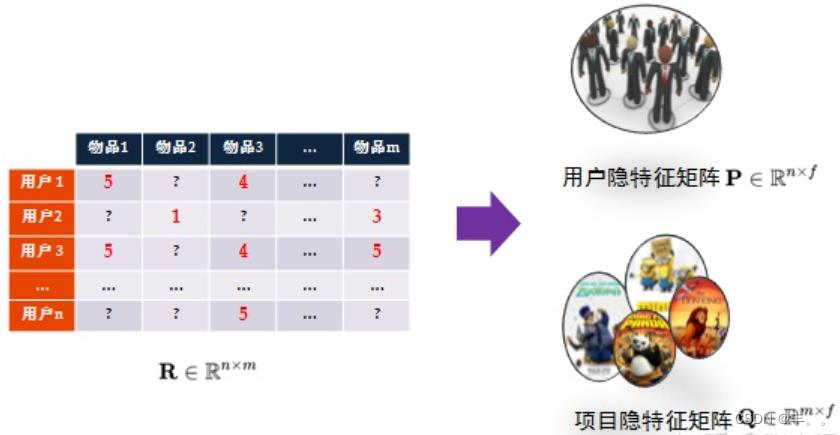
参数
f:隐向量维度,决定隐向量表达能力强弱
n:用户数
m:物品数
求解方法:
• 特征值分解
• 奇异值分解参考这篇博客
• 梯度下降参考这篇博客
原理
基于兴趣分类的方法,可以对物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品
注意下方公式,用于表达预测值

• 对于一个用户,用他所有没有过行为的物品作为负样本。
• 对于一个用户,从他没有过行为的物品中均匀采样出一些物品作为负样本。
• 对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
• 对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,偏重采样不热门的物品。因为一般来说,除了生活必须品,没有买的才是需要的。
采样原则:
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
代码实现(参考)

为了文章的逻辑性,这里再把公式放一遍

结合上面的公式,我们进一步来看以下公式:
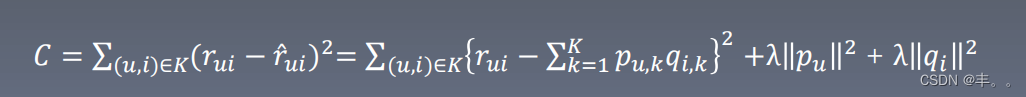
其中
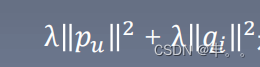
是惩罚项,即是用来防止过拟合的正则化项
然后我们使用随机梯度下降算法最小化损失函数求得参数

即







![[附源码]Node.js计算机毕业设计工资管理系统PPTExpress](https://img-blog.csdnimg.cn/c1562d7f87424eab9b0f64cb9c5b488e.png)
![[2022-12-17]神经网络与深度学习 hw9 - bptt](https://img-blog.csdnimg.cn/d3f51f868cf64b109580b1e4c394374f.png)
![[ 数据结构 -- 手撕排序算法第二篇 ] 冒泡排序](https://img-blog.csdnimg.cn/857becdeaf3b4f7a981da7eb40335ccb.png)

![[附源码]Python计算机毕业设计Django万佳商城管理系统](https://img-blog.csdnimg.cn/cf1182f66a1b43399a5fe19654c445c0.png)