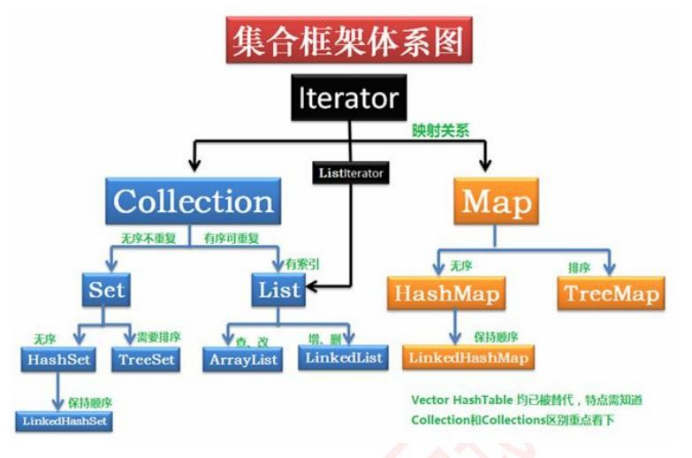
点云 3D 目标检测 - VoxelNet(CVPR 2018)
- 摘要
- 1. 引言
- 1.1 相关工作
- 1.2 贡献
- 2. VoxelNet
- 2.1 VoxelNet架构
- 2.1.1 特征学习网络
- 2.1.2 卷积中层
- 2.1.3 区域提案网络
- 2.2 损失函数
- 2.3 高效实施
- 3. 训练详情
- 3.1 网络详细信息
- 3.2 数据增强
- 4. 实验
- 4.1 KITTI验证集评估
- 4.2 KITTI测试集评估
- 5.结论
- References
声明:此翻译仅为个人学习记录
文章信息
- 标题:VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (CVPR 2018)
- 作者:Yin Zhou、Oncel Tuzel
- 文章链接:https://arxiv.org/pdf/1711.06396.pdf
摘要
精确检测3D点云中的物体是许多应用中的中心问题,例如自主导航、家政机器人和增强/虚拟现实。为了将高度稀疏的LiDAR点云与区域提案网络(RPN)连接起来,大多数现有工作都集中在手工制作的特征表示上,例如鸟瞰投影。在这项工作中,我们消除了对3D点云的手动特征工程的需求,并提出了VoxelNet,这是一种通用的3D检测网络,它将特征提取和边界框预测统一到单个阶段、端到端可训练的深度网络中。具体而言,VoxelNet将点云划分为等距的3D体素,并通过新引入的体素特征编码(VFE)层将每个体素内的一组点转换为统一的特征表示。通过这种方式,点云被编码为描述性体积表示,然后将其连接到RPN以生成检测。KITTI汽车检测基准的实验表明,VoxelNet在很大程度上优于最先进的基于LiDAR的3D检测方法。此外,我们的网络学习了具有各种几何形状的物体的有效区分表示,从而在仅基于LiDAR的行人和骑自行车者的3D检测中获得了令人鼓舞的结果。
1. 引言
基于点云的3D目标检测是各种现实世界应用的重要组成部分,如自主导航[11,14]、家政机器人[26]和增强/虚拟现实[27]。与基于图像的检测相比,LiDAR提供了可靠的深度信息,可用于准确定位目标并表征其形状[21,5]。然而,与图像不同,由于3D空间的非均匀采样、传感器的有效范围、遮挡和相对姿态等因素,LiDAR点云是稀疏的,并且具有高度可变的点密度。为了应对这些挑战,许多方法都为点云手工制作了特征表示,这些特征表示针对3D目标检测进行了调整。有几种方法将点云投影到透视图中,并应用基于图像的特征提取技术[28,15,22]。其他方法将点云光栅化为3D体素网格,并使用手工制作的特征对每个体素进行编码[41,9,37,38,21,5]。然而,这些手动设计选择引入了信息瓶颈,阻碍了这些方法有效地利用3D形状信息和检测任务所需的不变量。图像识别[20]和检测[13]任务的重大突破是由于从手工制作的特征转向机器学习的特征。

图1. VoxelNet直接在原始点云上运行(无需特征工程),并使用单个端到端可训练网络生成3D检测结果。
最近,Qi等人[29]提出了PointNet,这是一种端到端的深度神经网络,可以直接从点云中学习逐点特征。该方法在3D目标识别、3D目标部分分割和逐点语义分割任务中展示了令人印象深刻的结果。在[30]中,引入了PointNet的改进版本,使网络能够在不同的尺度上学习局部结构。为了获得满意的结果,这两种方法在所有输入点上训练特征变换器网络(∼1k个点)。由于使用激光雷达获得的典型点云包含∼100k个点,如[29,30]所述的架构训练会导致高的计算和内存需求。将3D特征学习网络扩展到数量级以上的点和3D检测任务是我们在本文中解决的主要挑战。

图2. VoxelNet架构。特征学习网络将原始点云作为输入,将空间划分为体素,并将每个体素内的点转换为表征形状信息的向量表示。该空间表示为稀疏4D张量。卷积中间层处理4D张量以聚合空间上下文。最后,RPN生成3D检测。
区域提案网络(RPN)[32]是一种高效目标检测的高度优化算法[17,5,31,24]。然而,这种方法要求数据是密集的,并以张量结构(例如图像、视频)组织,而典型的LiDAR点云并非如此。在本文中,我们缩小了点集特征学习和RPN之间的差距,用于3D检测任务。
我们提出了VoxelNet,这是一个通用的3D检测框架,它同时从点云学习辨别特征表示,并以端到端的方式预测精确的3D边界框,如图2所示。我们设计了一种新的体素特征编码(VFE)层,通过将逐点特征与局部聚集特征相结合,实现了体素内的点间交互。堆叠多个VFE层允许学习用于表征局部3D形状信息的复杂特征。具体而言,VoxelNet将点云划分为等间距的3D体素,通过堆叠的VFE层对每个体素进行编码,然后3D卷积进一步聚集局部体素特征,将点云转换为高维体积表示。最后,RPN消耗体积表示并产生检测结果。这种高效算法既得益于稀疏点结构,也得益于体素网格上的高效并行处理。
我们根据KITTI基准[11]提供的鸟瞰图检测和全3D检测任务评估VoxelNet。实验结果表明,VoxelNet在很大程度上优于最先进的基于LiDAR的3D检测方法。我们还证明,VoxelNet在从LiDAR点云检测行人和骑自行车人方面取得了非常令人鼓舞的结果。
1.1 相关工作
3D传感器技术的快速发展促使研究人员开发有效的表示方法,以检测和定位点云中的对象。一些早期的特征表示方法是[39,8,7,19,40,33,6,25,1,34,2]。当提供丰富而详细的3D形状信息时,这些手工制作的功能会产生令人满意的结果。然而,他们无法适应更复杂的形状和场景,也无法从数据中学习所需的不变量,导致不可控场景(如自主导航)的有限成功。
鉴于图像提供了详细的纹理信息,许多算法从2D图像推断出3D边界框[4,3,42,43,44,36]。然而,基于图像的3D检测方法的精度受限于深度估计的精度。
几种基于LIDAR的3D目标检测技术利用体素网格表示。[41,9]用从体素内包含的所有点导出的6个统计量对每个非空体素进行编码。[37]融合多个局部统计以表示每个体素。[38]计算体素网格上的截断有符号距离。[21]对3D体素网格使用二进制编码。[5] 通过计算鸟瞰图中的多通道特征图和正视图中的柱面坐标,介绍了LiDAR点云的多视图表示。其他一些研究将点云投影到透视图上,然后使用基于图像的特征编码方案[28,15,22]。
还有几种多模态融合方法将图像和激光雷达相结合,以提高检测精度[10,16,5]。与仅LiDAR的3D检测相比,这些方法提供了改进的性能,特别是对于小物体(行人、骑自行车的人)或物体距离较远时,因为相机提供的测量值比LiDAR多一个数量级。然而,需要一个与LiDAR时间同步和校准的额外摄像头限制了它们的使用,并使解决方案对传感器故障模式更加敏感。在这项工作中,我们专注于仅激光雷达检测。
1.2 贡献
-
我们为基于点云的3D检测提出了一种新颖的端到端可训练的深度架构VoxelNet,它直接在稀疏的3D点上运行,并避免了人工特征工程带来的信息瓶颈。
-
我们提出了一种实现VoxelNet的有效方法,该方法既受益于稀疏点结构,也受益于体素网格上的高效并行处理。
-
我们对KITTI基准进行了实验,并表明VoxelNet在基于LiDAR的汽车、行人和骑自行车的人的检测基准中产生了最先进的结果。
2. VoxelNet
在本节中,我们将解释VoxelNet的架构、用于训练的损失函数以及实现网络的有效算法。
2.1 VoxelNet架构
建议的VoxelNet由三个功能块组成:(1)特征学习网络,(2)卷积中间层,和(3)区域提案网络[32],如图2所示。我们将在以下章节中详细介绍VoxelNet。
2.1.1 特征学习网络
体素分区。给定一个点云,我们将3D空间细分为等间距的体素,如图2所示。假设点云包含沿Z、Y、X轴分别具有范围D、H、W的3D空间。我们相应地定义尺寸为vD、vH和vW的每个体素。生成的三维体素网格大小为D’=D/vD,H’=H/vH,W’=W/vW。这里,为了简单起见,我们假设D、H、W是vD、vH、vW的倍数。
分组。我们根据点所在的体素对点进行分组。由于距离、遮挡、对象的相对姿态和非均匀采样等因素,LiDAR点云是稀疏的,并且在整个空间中具有高度可变的点密度。因此,分组后,体素将包含可变数量的点。图2显示了一个示例,其中Voxel-1的点明显多于Voxel-2和Voxel-4,而Voxel-3不包含点。

图3. 体素特征编码层。
随机抽样。通常,高清晰度激光雷达点云由大约100k个点组成。直接处理所有点不仅增加了计算平台的内存/效率负担,而且整个空间中高度可变的点密度可能会影响检测。为此,我们从包含T个以上点的体素中随机抽取固定数量的T个点。该采样策略有两个目的:(1)计算节省(详见第2.3节);以及(2)减少了体素之间的点的不平衡,这减少了采样偏差,并增加了训练的更多变化。
堆叠体素特征编码。关键创新是VFE层链。为了简单起见,图2说明了一个体素的分层特征编码过程。在不失一般性的情况下,以下段落中我们使用VFE第1层来描述细节。图3显示了VFE第1层的体系结构。
V={pi=[xi,yi,zi,ri]T∈R4}i=1…t表示一个非空体素包含t≤T个LiDAR点,其中pi包含第i个点的XYZ坐标,ri是接收的反射率。我们首先计算局部平均值作为V中所有点的质心,表示为(vx,vy,vz)。然后将每个点pi扩展与质心的相对偏移量,得到输入特征集Vin={pi=[xi,yi,zi,ri,xi−vx、yi−vy,zi−vz]T∈R7}i=1…t。接下来,通过全连接网络(FCN)将每个pi转换为一个特征空间,在这里我们可以聚集来自点特征fi∈Rm的信息来编码包含在体素内的表面的形状。FCN由线性层、批次归一化(BN)层和整流线性单元(ReLU)层组成。在获得逐点特征表示之后,我们在与V相关联的所有fi上使用逐元素MaxPooling来获得V的局部聚集的特征f∈Rm 。最后,我们用f扩充每个fi以形成逐点连接特征如fiout=[fiT,fT]T∈R2m。因此,我们获得输出特征集Vout={fiout}i=1…t。所有非空体素以相同的方式编码,并且它们在FCN中共享相同的参数集。
我们使用VFE-i (cin,cout)表示将维度cin的输入特征转换为维度cout的输出特征的第i个VFE层。线性层学习大小为cin×(cout/2)的矩阵,逐点串联产生维度cout的输出。
因为输出特征结合了逐点特征和局部聚集特征,所以堆叠VFE层对体素内的点交互进行编码,并使最终特征表示能够学习描述性形状信息。通过FCN将VFE-n的输出转换为RC,并应用元素Maxpool(其中C是体素特征的维度)来获得体素特征,如图2所示。
稀疏张量表示。通过仅处理非空体素,我们获得了体素特征列表,每个特征都与特定非空体素的空间坐标唯一关联。获得的体素特征列表可以表示为稀疏的4D张量,大小为C×D’×H’×W’,如图2所示。尽管点云包含100k个点,90%以上的体素通常为空。将非空体素特征表示为稀疏张量大大减少了反向传播期间的内存使用和计算成本,这是我们高效实现的关键步骤。
2.1.2 卷积中层
我们使用ConvMD(cin,cout,k,s,p)来表示M维卷积算子,其中cin和cout是输入和输出通道的数量,k、s和p是分别对应于内核大小、步长和填充大小的M维向量。当M维上的大小相同时,我们使用标量表示大小,例如k=(k,k,k)时的k。

图4. 区域提案网络架构。
每个卷积中间层依次应用3D卷积、BN层和ReLU层。卷积中间层在逐渐扩展的感受野内聚集体素特征,为形状描述添加更多上下文。卷积中间层中滤波器的详细尺寸在第3节中解释。
2.1.3 区域提案网络
最近,区域提案网络[32]已成为性能最佳的目标检测框架[38,5,23]的重要组成部分。在这项工作中,我们对[32]中提出的RPN架构进行了几个关键修改,并将其与特征学习网络和卷积中间层相结合,以形成端到端可训练流水线。
RPN的输入是卷积中间层提供的特征图。该网络的架构如图4所示。该网络具有三个完全卷积层块。每个块的第一层通过步长为2的卷积将特征图下采样一半,然后是步长为1的卷积序列(×q表示滤波器的q个应用)。在每个卷积层之后,应用BN和ReLU操作。然后,我们将每个块的输出上采样到固定的大小并进行连接,以构建高分辨率特征图。最后,将该特征图映射到期望的学习目标:(1)概率得分图和(2)回归图。

图5. 高效实施说明
2.2 损失函数
设{aipos}i=1…Npos是Npos正锚的集合,而{ajneg}j=1…Nneg是Nneg负锚的集合。我们将3D真值框参数化为 (xcg,ycg,zcg,lg,wg,hg,θg) ,其中xcg,ycg,zcg表示中心位置,lg,wg,hg表示真值框的长度、宽度和高度,θg是围绕Z轴的偏航旋转。为了从参数化为 (xcg,ycg,zcg,lg,wg,hg,θg) 的匹配正锚中检索真值框,我们定义了残差向量u*∈R7包含对应于中心位置的7个回归目标∆x,∆y,∆z、 三维∆l,∆w,∆h和旋转∆θ,其计算为:

其中 d a = ( w a ) 2 + ( l a ) 2 {d^a=\sqrt {(w^a)^2+(l^a)^2}} da=(wa)2+(la)2是锚框底部的对角线。在这里,我们的目标是直接估计定向的3D框,并归一化∆x和∆y同样的与对角线da,其不同于[32,38,22,21,4,3,5]。我们定义损失函数如下:

其中,pipos和pjneg表示正锚点aipos和负锚点ajneg的软最大输出,而ui∈R7和u*∈R7是正锚点aipos的回归输出和真值。前两项是{aipos}i=1…Npos和{ajneg}j=1…Nneg的归一化分类损失,其中Lcls代表二进制交叉熵损失,α,β是平衡相对重要性的正常数。最后一项Lreg是回归损失,我们使用SmoothL1函数[12,32]。
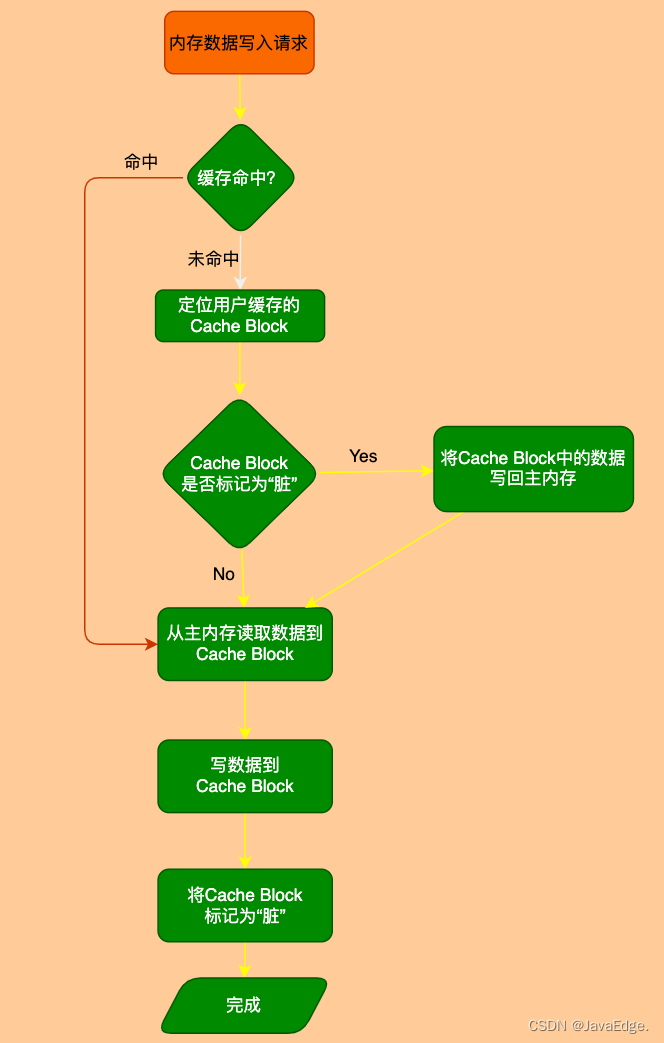
2.3 高效实施
GPU被优化用于处理密集张量结构。直接使用点云的问题是,点在空间中稀疏分布,并且每个体素具有可变数量的点。我们设计了一种将点云转换为密集张量结构的方法,其中可以在点和体素之间并行处理堆叠的VFE操作。
该方法如图5所示。我们初始化一个K×T×7维张量结构来存储体素输入特征缓冲区,其中K是非空体素的最大数量,T是每个体素的点最大数量,7是每个点的输入编码维度。这些点在处理前随机化。对于点云中的每个点,我们检查对应的体素是否已经存在。该查找操作在O(1)中使用哈希表有效地完成,其中体素坐标被用作哈希键。如果体素已经初始化,如果少于T个点,我们将该点插入体素位置,否则将忽略该点。如果未初始化体素,我们将初始化一个新的体素,将其坐标存储在体素坐标缓冲区中,并将点插入到该体素位置。体素输入特征和坐标缓冲区可以通过点列表上的一次传递来构造,因此其复杂性为O(n)。为了进一步提高存储器/计算效率,可以仅存储有限数量的体素(K)。
在构建体素输入缓冲器之后,堆叠的VFE仅涉及点级和体素级密集操作,这些操作可以在GPU上并行计算。注意,在VFE中的级联操作之后,我们将对应于空点的特征重置为零,以便它们不会影响计算的体素特征。最后,使用存储的坐标缓冲区,我们将计算出的稀疏体素结构重新组织为密集体素网格。以下卷积中间层和RPN操作在密集体素网格上工作,该网格可以在GPU上高效实现。
3. 训练详情
在本节中,我们将解释VoxelNet的实现细节和训练程序。
3.1 网络详细信息
我们的实验设置基于KITTI数据集的LiDAR规范[11]。
汽车检测。对于这项任务,我们考虑点云沿Z、Y、X轴范围分别为在[−3, 1] × [−40, 40]×[0, 70.4]米。投影到图像边界之外的点将被移除[5]。我们选择的体素大小为vD=0.4,vH=0.2,vW=0.2米,这导致D’=10,H’=400,W’=352。我们将T=35设置为每个非空体素中随机采样点的最大数量。我们使用两个VFE层VFE-1(7,32)和VFE-2(32,128)。最终的FCN将VFE-2输出映射到R128。因此,我们的特征学习网络生成形状为128×10×400×352的稀疏张量。为了聚集体素特征,我们使用三个卷积中间层,依次为Conv3D(128,64,3,(2,1,1),(1,1,1)),Conv3D(64,64,3,(1,1,1),(0,1,1))和Conv3D(64,64,3,(2,1,1),(1,1,1)),其产生大小为64×2×400×352的4D张量。重塑后,RPN的输入是大小为128×400×352的特征图,其中尺寸对应于3D张量的通道、高度和宽度。图4说明了该任务的详细网络架构。与[5]不同,我们只使用一种锚尺寸,la=3.9,wa=1.6,ha=1.56米,以zca=−1.0米为中心的两种旋转,0度和90度。我们的锚匹配标准如下:如果锚与真值有最高的Intersection over Union(IoU),或者其与真值之间的IoU在0.6以上(鸟瞰图中),则认为锚是正的。如果锚与所有真值框之间的IoU小于0.45,则认为锚为负。我们将锚视为不关心,当它们与真值具有0.45≤ IoU≤ 0.6。我们在方程中设置α=1.5和β=1在等式2中。
行人和骑自行车的人检测。输入范围(我们的经验观察表明,超过这个范围,行人和骑车人的激光雷达返回变得非常稀少,因此检测结果将不可靠。)沿Z、Y、X轴分别为[−3, 1] × [−20,20]×[0,48]米。我们使用与汽车检测相同的体素大小,得出D=10,H=200,W=240。我们设置T=45,以便获得更多的LiDAR点,以更好地捕获形状信息。特征学习网络和卷积中间层与汽车检测任务中使用的网络相同。对于RPN,我们对图4中的块1进行了一次修改,将第一个2D卷积中的步幅大小从2更改为1。这使得锚匹配的分辨率更高,这对于检测行人和骑车人是必要的。我们使用锚尺寸la=0.8,wa=0.6,ha=1.73米,以zca=−0.6米为中心的0度和90度旋转,用于行人检测,使用锚尺寸la=1.76,wa=0.6,ha=1.73米,zca=−0.6米为中心,旋转0度和90度以检测骑车人。具体的锚匹配标准如下:如果锚与真值具有最高的IoU,或其与真值的IoU高于0.5,则我们将其指定为正。如果锚具有每个真值的IoU小于0.35,则将其视为负。对于与真值具有0.35≤ IoU≤ 0.5,我们都视他们为无关紧要。
在训练过程中,我们使用随机梯度下降(SGD),前150个时期的学习率为0.01,后10个时期将学习率降至0.001。我们使用16个点的批量大小。
3.2 数据增强
在少于4000个训练点云的情况下,从头开始训练我们的网络将不可避免地受到过度拟合的影响。为了减少这个问题,我们引入了三种不同形式的数据增强。增强的训练数据是动态生成的,无需存储在磁盘上[20]。
定义集合M={pi=[xi,yi,zi,ri]T∈R4}i=1,…,N作为由N个点组成的整个点云。我们将3D边界框bi参数化为(xc,yc,zc,l,w,h,θ),其中xc,yc,zc是中心位置,l,w,h是长度、宽度、高度,θ是围绕Z轴的偏航旋转。我们定义Ωi={p|x∈ [xc−l/2,xc+l/2],y∈[yc−w/2,yc+w/2],z∈[zc− h/2,zc+h/2],p∈M}作为包含bi内的所有LiDAR点的集合,其中p=[x,y,z,r]表示整个集合M中的特定LiDAR点。
第一种形式的数据增强将扰动独立地应用于每个真值3D边界框以及框内的那些激光雷达点。具体来说,围绕Z轴旋转bi和相关的Ωi关于(xc,yc,zc)由均匀分布的随机变量表示∆θ ∈ [−π/10, +π/10]。然后我们添加一个转化(∆x,∆y,∆z) 到bi的XYZ分量和Ωi,其中∆x,∆y,∆z独立绘制于均值为零和标准偏差为1.0的高斯分布。为了避免物理上不可能的结果,我们在扰动后对任意两个框进行碰撞测试,如果检测到碰撞,则恢复到原始状态。由于扰动被独立地应用于每个真值框和相关的激光雷达点,因此网络能够从比原始训练数据更多的变化中学习。
其次,我们将全局缩放应用于所有真值框bi和整个点云M。具体来说,我们将XYZ坐标和每个bi的三维相乘,以及M中所有点的XYZ坐标,随机变量取自均匀分布[0.95,1.05]。引入全局尺度增强提高了网络的鲁棒性,用于检测具有不同大小和距离的目标,如基于图像的分类[35,18]和检测任务[12,17]所示。
最后,我们将全局旋转应用于所有真值框bi和整个点云M。旋转沿Z轴和围绕(0,0,0)应用。全局旋转偏移量由均匀分布采样确定[−π/4, +π/4]. 通过旋转整个点云,我们模拟车辆转弯。
4. 实验
我们在KITTI 3D目标检测基准[11]上评估VoxelNet,该基准包含7481张训练图像/点云和7518张测试图像/点云和三个类别:汽车、行人和骑自行车的人。对于每个类别,检测结果基于三个难度级别进行评估:容易、中等和困难,这些难度级别根据目标大小、遮挡状态和截断级别确定。由于测试集的真值不可用,且对测试服务器的访问受限,我们使用[4]、[3]、5]中描述的协议进行综合评估,并将训练数据细分为训练集和验证集,这产生了3712个用于训练的数据样本和3769个用于验证的数据样本。分割避免了来自相同序列的样本被包括在训练集和验证集[3]中。最后,我们还展示了使用KITTI服务器的测试结果。

表1.鸟瞰图检测的性能比较:KITTI验证集的平均精度(%)。

表2. 3D检测的性能比较:KITTI验证集的平均精度(%)。
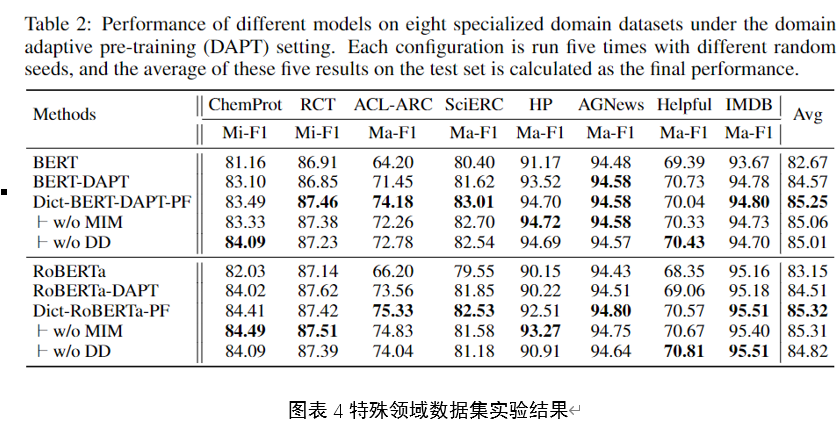
对于Car类别,我们将所提出的方法与几种性能最佳的算法进行了比较,包括基于图像的方法:Mono3D[3]和3DOP[4];基于激光雷达的方法:VeloFCN[22]和3D-FCN[21];以及多模态方法MV[5]。Mono3D[3]、3DOP[4]和MV[5]使用预训练的模型进行初始化,而我们仅使用KITTI中提供的LiDAR数据从头开始训练VoxelNet。
为了分析端到端学习的重要性,我们实现了一个强大的基线,该基线源自VoxelNet架构,但使用了手工制作的特征,而不是提出的特征学习网络。我们称这个模型为手工制作的基线(HC基线)。HC基线使用[5]中描述的鸟瞰图特征,以0.1m分辨率计算。与[5]不同,我们将高度通道的数量从4个增加到16个,以捕获更详细的形状信息——进一步增加高度通道的数目不会导致性能提高。我们将VoxelNet的卷积中间层替换为类似大小的2D卷积层,即Conv2D(16,32,3,1,1)、Conv2D(32,64,3,2,1)和Conv2D(64,128,3,1,1)。最后,VoxelNet和HC基线中的RPN相同。HC基线和VoxelNet中的参数总数非常相似。我们使用第3节中描述的相同训练程序和数据增强来训练HC基线。
4.1 KITTI验证集评估
度量。我们遵循官方的KITTI评估协议,其中,汽车类别的IoU阈值为0.7,行人和自行车类别为0.5。对于鸟瞰图和全3D评估,IoU阈值是相同的。我们使用平均精度(AP)度量来比较这些方法。
鸟瞰图中的评估。评估结果如表1所示。VoxelNet在所有三个难度级别上始终优于所有竞争方法。与最先进的[5]相比,HC基线也取得了令人满意的性能,这表明我们的基础区域提案网络(RPN)是有效的。对于鸟瞰图中的行人和骑自行车的人的检测任务,我们将所提出的VoxelNet与HC基线进行了比较。VoxelNet在这些更具挑战性的类别中产生的AP显著高于HC基线,这表明端到端学习对于基于点云的检测至关重要。
我们需要注意的是,[21]报告的容易、中等和困难水平分别为88.9%、77.3%和72.7%,但这些结果是基于6000个训练帧和1500个验证帧,它们不能直接与表1中的算法进行比较。因此,我们没有将这些结果包括在表中。
三维评估。与只需要在2D平面中精确定位物体的鸟瞰图检测相比,3D检测是一项更具挑战性的任务,因为它需要在3D空间中对形状进行更精细的定位。表2总结了比较结果。对于Car类,VoxelNet在所有难度级别上的AP显著优于所有其他方法。具体而言,仅使用LiDAR,VoxelNet在简单、中等和困难级别上显著优于基于LiDAR+RGB的最先进方法MV(BV+FV+RGB)[5],分别为10.68%、2.78%和6.29%。HC基线实现了与MV[5]方法相似的精度。

图6.定性结果。为了更好地可视化,使用LiDAR检测到的3D框被投影到RGB图像上。
在鸟瞰图评估中,我们还比较了VoxelNet与HC基线在3D行人和骑自行车的人检测方面的差异。由于3D姿态和形状的高度变化,成功检测这两个类别需要更好的3D形状表示。如表2所示,对于更具挑战性的3D检测任务(来自鸟瞰图提高8%到3D检测提高12%),这表明VoxelNet在捕获3D形状信息方面比手工制作的特征更有效。
4.2 KITTI测试集评估
我们通过向官方服务器提交检测结果,在KITTI测试集上评估了VoxelNet。结果汇总在表3中。VoxelNet在所有任务(鸟瞰图和3D检测)和所有困难方面显著优于先前发布的最先进[5]。我们要注意的是,KITTI基准测试中列出的许多其他领先方法同时使用RGB图像和LiDAR点云,而VoxelNet仅使用LiDAR。

表3.KITTI测试集的性能评估。
我们在图6中展示了几个3D检测示例。为了更好地可视化,使用LiDAR检测到的3D框被投影到RGB图像上。如图所示,VoxelNet在所有类别中提供了高度精确的3D边界框。
VoxelNet的推理时间为225ms,在TitanX GPU和1.7Ghz CPU上,体素输入特征计算需要5ms,特征学习网络需要20ms,卷积中间层需要170ms,区域建议网络需要30ms。
5.结论
基于LiDAR的3D检测中的大多数现有方法依赖于手工制作的特征表示,例如鸟瞰投影。在本文中,我们消除了手动特征工程的瓶颈,并提出了VoxelNet,这是一种用于基于点云的3D检测的新型端到端可训练深度架构。我们的方法可以直接对稀疏的3D点进行操作,并有效地捕获3D形状信息。我们还提出了VoxelNet的有效实现,它受益于点云稀疏性和体素网格上的并行处理。我们在KITTI汽车检测任务上的实验表明,VoxelNet在很大程度上优于最先进的基于LiDAR的3D检测方法。在更具挑战性的任务中,例如行人和骑自行车的人的3D检测,VoxelNet还展示了令人鼓舞的结果,表明它提供了更好的3D表示。未来的工作包括扩展VoxelNet,用于联合LiDAR和基于图像的端到端3D检测,以进一步提高检测和定位精度。
致谢:我们感谢我们的同事Russ Webb、Barry Theobald和Jerremy Holland提供的宝贵意见。
References
[1] P. Bariya and K. Nishino. Scale-hierarchical 3d object recognition in cluttered scenes. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 1657–1664, 2010. 2
[2] L. Bo, X. Ren, and D. Fox. Depth Kernel Descriptors for Object Recognition. In IROS, September 2011. 2
[3] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. In IEEE CVPR, 2016. 2, 5, 6, 7
[4] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In NIPS, 2015. 2, 5, 6, 7
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017. 1, 2, 3, 4, 5, 6, 7, 8
[6] C. Choi, Y. Taguchi, O. Tuzel, M. Y. Liu, and S. Ramalingam. Voting-based pose estimation for robotic assembly using a 3d sensor. In 2012 IEEE International Conference on Robotics and Automation, pages 1724–1731, 2012. 2
[7] C. S. Chua and R. Jarvis. Point signatures: A new representation for 3d object recognition. International Journal of Computer Vision, 25(1):63–85, Oct 1997. 2
[8] C. Dorai and A. K. Jain. Cosmos-a representation scheme for 3d free-form objects. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(10):1115–1130, 1997. 2
[9] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 1355–1361, May 2017. 1, 2
[10] M. Enzweiler and D. M. Gavrila. A multilevel mixture-ofexperts framework for pedestrian classification. IEEE Transactions on Image Processing, 20(10):2967–2979, Oct 2011. 3
[11] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 2012. 1, 2, 5, 6
[12] R. Girshick. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), ICCV ’15, 2015. 5, 6
[13] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014. 1
[14] R. Gomez-Ojeda, J. Briales, and J. Gonzalez-Jimenez. Plsvo: Semi-direct monocular visual odometry by combining points and line segments. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4211–4216, Oct 2016. 1
[15] A. Gonzalez, G. Villalonga, J. Xu, D. Vazquez, J. Amores, and A. Lopez. Multiview random forest of local experts combining rgb and lidar data for pedestrian detection. In IEEE Intelligent Vehicles Symposium (IV), 2015. 1, 2
[16] A. Gonzlez, D. Vzquez, A. M. Lpez, and J. Amores. Onboard object detection: Multicue, multimodal, and multiview random forest of local experts. IEEE Transactions on Cybernetics, 47(11):3980–3990, Nov 2017. 3
[17] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, June 2016. 2, 6
[18] A. G. Howard. Some improvements on deep convolutional neural network based image classification. CoRR, abs/1312.5402, 2013. 6
[19] A. E. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3d scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 21(5):433–449, 1999. 2
[20] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012. 1, 6
[21] B. Li. 3d fully convolutional network for vehicle detection in point cloud. In IROS, 2017. 1, 2, 5, 7
[22] B. Li, T. Zhang, and T. Xia. Vehicle detection from 3d lidar using fully convolutional network. In Robotics: Science and Systems, 2016. 1, 2, 5, 7
[23] T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. IEEE ICCV, 2017. 4
[24] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In ECCV, pages 21–37, 2016. 2
[25] A. Mian, M. Bennamoun, and R. Owens. On the repeatability and quality of keypoints for local feature-based 3d object retrieval from cluttered scenes. International Journal of Computer Vision, 89(2):348–361, Sep 2010. 2
[26] Y.-J. Oh and Y. Watanabe. Development of small robot for home floor cleaning. In Proceedings of the 41st SICE Annual Conference. SICE 2002., volume 5, pages 3222–3223 vol.5,
Aug 2002. 1
[27] Y. Park, V. Lepetit, and W. Woo. Multiple 3d object tracking for augmented reality. In 2008 7th IEEE/ACM International Symposium on Mixed and Augmented Reality, pages 117–120, Sept 2008. 1
[28] C. Premebida, J. Carreira, J. Batista, and U. Nunes. Pedestrian detection combining RGB and dense LIDAR data. In IROS, pages 0–1. IEEE, Sep 2014. 1, 2
[29] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017. 1
[30] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017. 1
[31] J. Redmon and A. Farhadi. YOLO9000: better, faster, stronger. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 2
[32] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, pages 91–99. 2015. 2, 3, 4, 5
[33] R. B. Rusu, N. Blodow, and M. Beetz. Fast point featurehistograms (fpfh) for 3d registration. In 2009 IEEE International Conference on Robotics and Automation, pages 3212–3217, 2009. 2
[34] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake. Real-time human pose recognition in parts from single depth images. In CVPR 2011, pages 1297–1304, 2011. 2
[35] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 6
[36] S. Song and M. Chandraker. Joint sfm and detection cues for monocular 3d localization in road scenes. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3734–3742, June 2015. 2
[37] S. Song and J. Xiao. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision, Proceedings, pages 634–651, Cham, 2014. Springer International Publishing. 1, 2
[38] S. Song and J. Xiao. Deep Sliding Shapes for amodal 3D object detection in RGB-D images. In CVPR, 2016. 1, 2, 4, 5
[39] F. Stein and G. Medioni. Structural indexing: efficient 3-d object recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 14(2):125–145, 1992. 2
[40] O. Tuzel, M.-Y. Liu, Y. Taguchi, and A. Raghunathan. Learning to rank 3d features. In 13th European Conference on Computer Vision, Proceedings, Part I, pages 520–535, 2014. 2
[41] D. Z. Wang and I. Posner. Voting for voting in online point cloud object detection. In Proceedings of Robotics: Science and Systems, Rome, Italy, July 2015. 1, 2
[42] Y. Xiang, W. Choi, Y. Lin, and S. Savarese. Data-driven 3d voxel patterns for object category recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2015. 2
[43] M. Z. Zia, M. Stark, B. Schiele, and K. Schindler. Detailed 3d representations for object recognition and modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(11):2608–2623, 2013. 2
[44] M. Z. Zia, M. Stark, and K. Schindler. Are cars just 3d boxes? jointly estimating the 3d shape of multiple objects. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pages 3678–3685, June 2014. 2

![[附源码]Node.js计算机毕业设计工资管理系统PPTExpress](https://img-blog.csdnimg.cn/c1562d7f87424eab9b0f64cb9c5b488e.png)
![[2022-12-17]神经网络与深度学习 hw9 - bptt](https://img-blog.csdnimg.cn/d3f51f868cf64b109580b1e4c394374f.png)
![[ 数据结构 -- 手撕排序算法第二篇 ] 冒泡排序](https://img-blog.csdnimg.cn/857becdeaf3b4f7a981da7eb40335ccb.png)

![[附源码]Python计算机毕业设计Django万佳商城管理系统](https://img-blog.csdnimg.cn/cf1182f66a1b43399a5fe19654c445c0.png)



![[附源码]Python计算机毕业设计Django社区生活废品回收APP](https://img-blog.csdnimg.cn/a818fefbc1bd491a9b14cc7829ee3232.png)
![[附源码]Python计算机毕业设计Django室内设计类网站](https://img-blog.csdnimg.cn/01befbbb8adb4390aa3695be43fd6084.png)