LangChain与LangGraph回调函数指南
回调函数概述
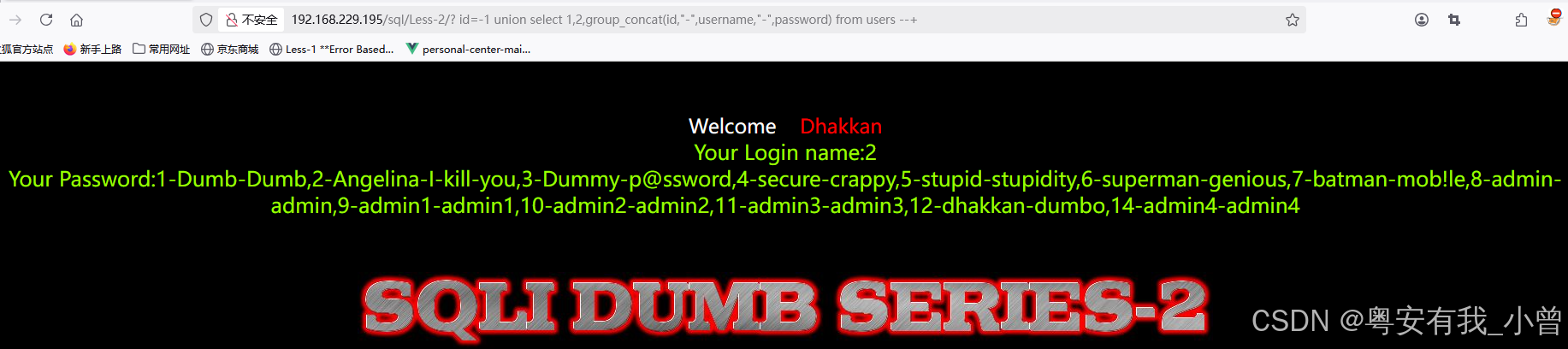
LangChain和LangGraph共享同一套回调系统,通过BaseCallbackHandler类提供了丰富的生命周期钩子,可用于监控、调试和跟踪AI应用的执行过程。
回调函数流程图
LangChain回调函数
以下是所有可用的回调函数及其触发时机:
1. 链(Chain)回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_chain_start | 链开始执行时 | serialized, inputs |
on_chain_end | 链执行完成时 | outputs |
on_chain_error | 链执行出错时 | error |
2. LLM回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_llm_start | LLM调用开始时 | serialized, prompts |
on_llm_new_token | 流式生成中接收到新token时 | token, chunk |
on_llm_end | LLM调用结束时 | response |
on_llm_error | LLM调用出错时 | error |
3. 聊天模型回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_chat_model_start | 聊天模型开始生成时 | serialized, messages |
4. 工具(Tool)回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_tool_start | 工具调用开始时 | serialized, input_str |
on_tool_end | 工具调用完成时 | output |
on_tool_error | 工具调用出错时 | error |
5. 检索器(Retriever)回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_retriever_start | 检索器开始检索时 | serialized, query |
on_retriever_end | 检索器完成检索时 | documents |
on_retriever_error | 检索器检索出错时 | error |
6. 代理(Agent)回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_agent_action | 代理决定执行操作时 | action |
on_agent_finish | 代理完成所有操作时 | finish |
7. 通用回调
| 回调函数 | 触发时机 | 参数 |
|---|
on_text | 文本处理开始时 | text |
on_retry | 重试操作时 | retry_state |
on_custom_event | 自定义事件发生时 | name, data |
LangGraph中的回调使用
LangGraph与LangChain共享同一套回调系统,没有额外的专用回调函数。在LangGraph中:
- 图(Graph)被实现为LangChain的Chain,因此图的执行触发
on_chain_start和on_chain_end - 图中的每个节点也可能触发相应的回调(如LLM节点触发LLM回调)
LangGraph的调试选项
除了使用回调,LangGraph还提供了专门的调试功能:
from langgraph.graph import StateGraph
graph = StateGraph()
compiled_graph = graph.compile(debug=True)
实现自定义回调处理器
基本回调处理器
from langchain_core.callbacks import BaseCallbackHandler
from uuid import UUID
from typing import Any, Dict, List, Optional
class CustomHandler(BaseCallbackHandler):
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
"""链开始执行时调用"""
print(f"开始执行链:{serialized.get('name', '未命名')}")
print(f"输入:{inputs}")
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
"""链执行完成时调用"""
print(f"链执行完成,输出:{outputs}")
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""LLM开始执行时调用"""
print(f"开始执行LLM:{serialized.get('name', '未命名')}")
print(f"提示词:{prompts[0][:50]}...")
使用回调处理器
from langchain_core.callbacks import BaseCallbackHandler
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph
handler = CustomHandler()
model = ChatOpenAI()
response = model.invoke("你好", {"callbacks": [handler]})
graph = StateGraph()
compiled_graph = graph.compile()
result = compiled_graph.invoke({"input": "你好"}, {"callbacks": [handler]})
内置回调处理器
LangChain提供了几个内置的回调处理器:
- StdOutCallbackHandler:将信息打印到标准输出
- StreamingStdOutCallbackHandler:流式打印文本到标准输出
from langchain_core.callbacks import StdOutCallbackHandler
from langchain_openai import ChatOpenAI
handler = StdOutCallbackHandler()
model = ChatOpenAI()
response = model.invoke("生成一个故事", {"callbacks": [handler]})
注意事项
- 回调方法名必须准确匹配,不能自定义
- 未实现的回调方法不会影响执行
- 可以通过设置属性如
ignore_llm = True来忽略特定类型的回调 - 异步环境应使用
AsyncCallbackHandler