来源:投稿 作者:COLDR
编辑:学姐
(内容如有错漏,可在评论区指出)
摘要
Dict-BERT为了解决BERT模型对语料中低频词(rare words)的不敏感性,通过在预训练中加入低频词词典&对应低频词定义来增强训练语言模型,并且引入了针对低频词的词语级别和句子级别的两个特殊任务。
简介
近年来,预训练语言模型在NLP领域取得了突破性的提升,其中BERT,RoBERTa,XLNet都采用了MLM任务获取了语法和语义层面的知识。但是这些模型都缺少特定领域的知识,所以难以解决特定领域的问题。 解决这种问题的现有方法是注入外部知识增强语言表达能力,这些知识,从包括语言学、常识、事实性,到领域特定知识。
具体来讲,对于一些稀有词或者未曾才出现过的词,预训练模型不能很好的学习,例如:Covid-19,可能就不会在预训练语料库中出现。
在我们的工作中,我们利用稀有词在英文词典(eg. Wiktionary)中的定义来增强预训练语言模型。我们提出了两种类型的训练前目标:
- 单词级的对比目标旨在最大化输入文本中出现的稀有词的Transformer表示与其字典定义之间的互信息。
- 句子级的区分目标旨在学习区分正确的和污染的单词定义。
总的来说,我们的主要贡献可概括如下:
- 我们是第一个将字典中的单词定义集成到PLM中的工作。
- 我们提出了两个关于输入文本序列和稀有词定义之间的词和句子级对齐的新训练任务,用词典增强语言模型。
- 在GLUE上,我们的模型比vanilla BERT平均提高了1.15%。
- 我们遵循领域自适应预训练(DAPT)设置(Gururangan et al., 2020),其中语言模型使用领域数据连续预训练。我们在8个专门的领域基准数据集上评估Dict-BERT。与BERT-DAPT和RoBERTa-DAPT设置相比,我们的方法可以平均提高F1评分+0.5%和+0.7%。
相关研究
语言模型中稀有词的表达
Wu等人[1]建议在训练前随时记录罕见词汇(TNF)。具体来说,TNF维护一个注释字典,当句子中出现生词时,将生词的上下文信息保存为注释。 当训练过程中再次出现相同的罕见词时,可以利用事先保存的笔记信息增强当前句子的语义。与Wu et al.(2021)在训练前和微调期间保持固定的生僻词词汇不同,我们的方法可以动态调整生僻词词汇,并以即插即用的方式在词典中获取和表示生僻词的定义。
预训练语言模型和知识增强方法
预训练语言模型在特定领域无法重现在开放领域中的得分,现有的知识增强方法可以总结为两类:
-
第一种方法是显示的注入知识表达,例如KG-BERT[2],直接对图结构知识进行编码,采用类似TransE[3]的算法,并获取实体的编码表示。缺点是这两种编码来自不同的空间,有割裂感。
-
第二种是隐式的通过知识相关的任务训练模型。CALM[4]提出了一种新的对比目标,将更多的常识知识打包到参数中,并联合预训练生成目标和对比目标,以增强常识语言理解和生成任务。
提出的方法(论文核心)
筛选稀有词
将所有词按词频从小到大排序,依次加入到稀有词表,直到稀有词词频和达到总词数的10%。这种办法可以随着预训练语料库的变化动态调整稀有词表。利用Wikdiction(https://www.wiktionary.org/)
Dict-BERT
为了区分两种embedding,作者设置输入文本的embedding为type0,字典定义的embedding设置为type1。
作者用(x,c)来表示一组输入文本和字典定义对。提出了两种预训练任务分别从词一级和句子级来对齐输入序列和稀有词定义。
词级互信息最大化
利用MI算法[5,6]。为了更好地对齐输入文本和字典定义的表示,需要最大化联合密度与边密度的KL散度。如公式(2)所示(这里的联合密度和边缘密度表示的含义是什么,文中没有解释。
- 根据本人在网络搜集的信息来看,应该是数据集中稀有词的出现次数除以总词数,应该表示的是稀有词定义的出现次数除以总定义数,表示二者同时出现的概率。通过公式(2)衡量和的相关性。)
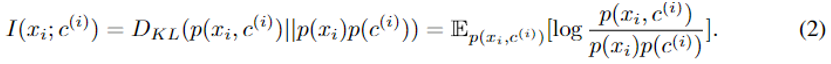
为了近似互信息,作者采用了InfoNCE[7],它是表示学习文献中最常用的估计器之一,如公式(3)所示
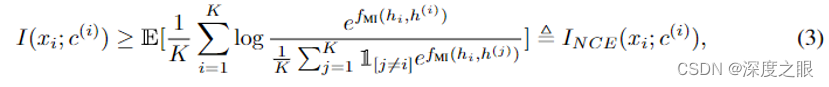
其中期望是K个独立样本来自联合分布
(Poole et al., 2019)。直观上,批评函数
衡量两个词表示之间的相似度(例如,内积)。模型应该将高值赋给正对
,将低值赋给所有负对。
我们通过对多批样本进行平均,使用蒙特卡洛估计来计算InfoNCE(Chen等人,2020年)。通过最大化编码表示之间的互信息,我们提取了输入文本序列中的罕见词及其字典定义中共同的潜在变量。
句子级定义判别
这里的关键思想是,学习区分正确和不正确的单词定义有助于语言模型捕获输入文本和字典定义的全局信息,而不是局部对齐语义表示。即在句子层的任务上,不采用为词语选择字典定义的任务,采用判断输入定义是否正确的任务训练模型。
具体来说就是对稀有词X,和其字典定义C,随机50%选择另一个稀有词的定义,替换C,作为被污染的样本。通过判断数据是否为污染数据(判断
是否和X匹配),训练模型学习整体含义)

整体结构
本文的训练任务包括MLM,MIM(词级别的互信息最大话),DD(句子级的定义匹配判别)三个任务,通过将这三个损失函数最小化来训练模型。如公式(5)所示,和
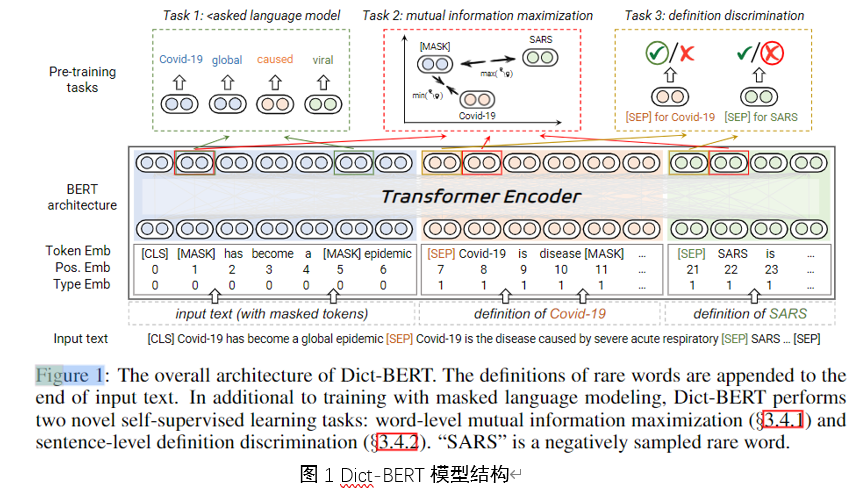
为两个超参数,控制任务的重要程度。模型结构如图1所示.
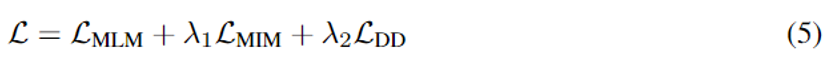
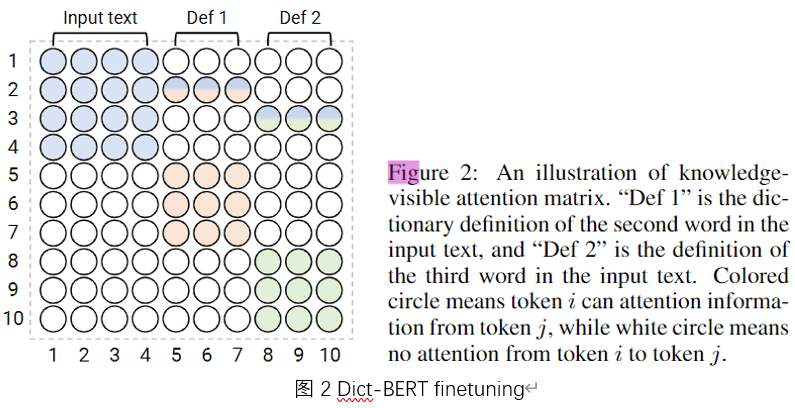
Dict-BERT的finetuning方法
预训练模型在下游任务上做微调时,也有可能遇到稀有词,为此,作者提出在下游任务数据文本序列后,附加稀有词的词典定义。但是这一操作会影响原来文本序列的意思,[CLS]的语义编码会被词典定义稀释,尤其是一个序列中有多个稀有词时。为了解决这个问题,作者提出一个可视化矩阵来限制这种影响。具体操作是,在掩码矩阵中,考虑[MASK]的所属范围,如图二所示。只有在以下情况,两个才会互相影响:(1)两个标记都属于输入文本序列,或者(2)两个标记都属于同一个稀有词的定义,或者(3)i是输入文本中的一个稀有词,而j来自它的定义时,我才能处理另一个标记j。
实验部分
选择稀有词
作者用维基百科和BookCorpus两个语料库整合成一个16G的语料集作为预训练。经过统计,该语料集共有50万左右个词汇,其中11.2万个被当作高频词,占所有单词出现次数的90%。其余39.2万个词被当作稀有词,从wikidictionary中获取这些词的定义,其中252581个(50.03%)可以找到,平均定义长度为9.57个单词。
下游任务测试
Dict-BERT-F/Dict-BERT-P表示只在训练前/微调阶段使用字典。DictBERT-PF表示在训练前和微调阶段都使用字典。此外,在训练前阶段,不含MIM的字典- bert删除了词级互信息最大化任务,不含DD的字典- bert删除了句子级定义判别任务。
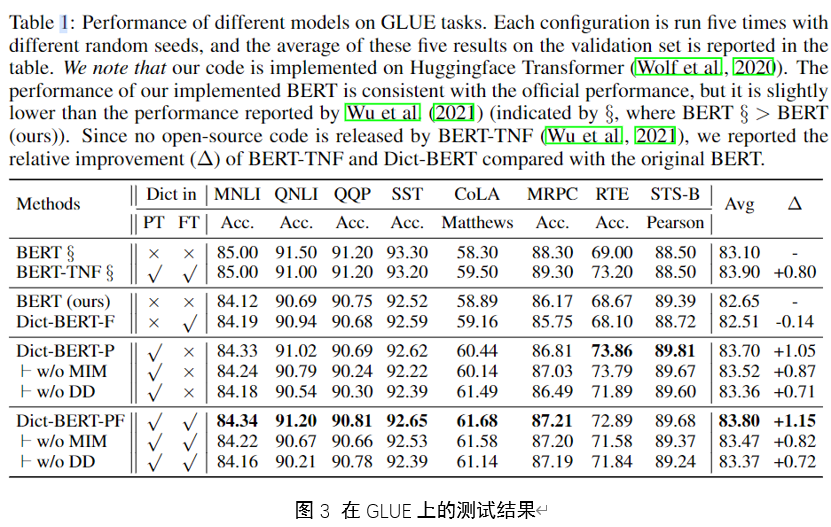
GLUE结果
在GLUE上的实验结果如图3所示,作者还提到,在GLUE榜单上的BERT分数和作者使用BERT做实验得到的分数不同。
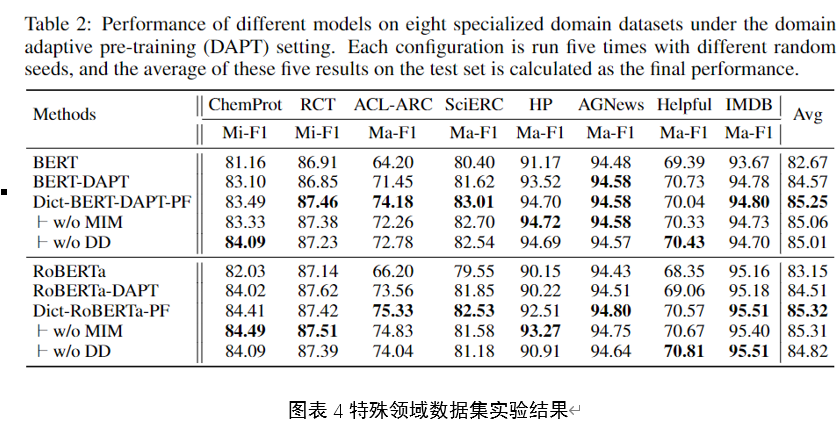
在8个针对特殊领域的数据集上的实验结果如图4所示。在特殊领域数据集上的实验,使添加稀有词的词典定义的作用更加明显。

个人总结
这篇论文是ACL2022的一篇文章,是关于知识融合预训练比较新的论文。个人认为这篇文章的问题在于,从实验部分看,模型的性能提升太小。其他知识融合预训练模型比如ERNIE-thu,ERNIE-baidu,KAPLER提升相对更加明显(虽然ERNIE-baidu主要是针对中文NLP的)。但是这篇文章给我们提供了一种新的思路,这一点还是有很多参考意义的。
参考文献
[1] Qiyu Wu, Chen Xing, Yatao Li, Guolin Ke, Di He, and Tie-Yan Liu. Taking notes on the fly helps bert pre-training. International Conference for Learning Representation (ICLR), 2021.
[2] Ye Liu, Yao Wan, Lifang He, Hao Peng, and Philip S Yu. Kg-bart: Knowledge graph-augmented bart for generative commonsense reasoning. In Conference on Artificial Intelligence (AAAI), 2021.
[3] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems (NeurIPS), 2013.
[4] Wangchunshu Zhou, Dong-Ho Lee, Ravi Kiran Selvam, Seyeon Lee, Bill Yuchen Lin, and Xiang Ren. Pre-training text-to-text transformers for concept-centric common sense. In International Conference for Learning Representation (ICLR), 2021.
[5] InfoMax principle Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
[6] Michael Tschannen, Josip Djolonga, Paul K Rubenstein, Sylvain Gelly, and Mario Lucic. On mutual information maximization for representation learning. International Conference for Learning Representation(ICLR), 2020.
[7] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
600+篇ACL论文PDF点击卡片👇关注免费领取


![[附源码]Python计算机毕业设计Django社区生活废品回收APP](https://img-blog.csdnimg.cn/a818fefbc1bd491a9b14cc7829ee3232.png)
![[附源码]Python计算机毕业设计Django室内设计类网站](https://img-blog.csdnimg.cn/01befbbb8adb4390aa3695be43fd6084.png)