分支和循环语句
- 1. 前言
- 2. 预备知识
- 2.1 getchar函数
- 2.2 putchar函数
- 2.3 计算数组的元素个数
- 2.4 清屏
- 2.5 程序的暂停
- 2.6 字符串的比较
- 3. 结构化
- 3.1 顺序结构
- 3.2 分支结构
- 3.3 循环结构
- 4. 真假性
- 5. 分支语句(选择结构)
- 5.1 if语句
- 5.1.1 语法形式
- 5.1.2 else和if的匹配
- 5.1.3 代码风格
- 5.2 switch语句
- 5.2.1 语法形式
- 5.2.2 break语句
- 5.2.3 default语句
- 6. 循环语句
- 6.1 while循环
- 6.1.1 语法形式
- 6.1.2 break语句
- 6.1.3 continue语句
- 6.1.4 代码举例
- 6.2 for循环
- 6.2.1 语法形式
- 6.2.2 break语句
- 6.2.3 continue语句
- 6.2.4 for循环控制循环变量
- 6.2.5 for循环的变种
- 6.3 do while循环
- 6.3.1 语法形式
- 6.3.2 break语句
- 6.3.3 continue语句
- 7. goto语句
- 7.1 语法形式
- 7.2 代码举例
- 8. 综合练习
- 8.1 打印1~100之间的奇数
- 8.2 求n的阶乘
- 8.3 二分查找(折半查找)
- 8.4 字符串从两端向中间打印
- 8.5 模拟登陆情景
- 8.6 猜数字游戏
- 8.7 把三个整数从大到小输出
- 8.8 求最大公约数
- 8.9 求最小公倍数
- 8.10 打印闰年
- 8.11 打印素数
- 8.12 统计9的个数
- 8.13 分数求和
- 8.14 求10个整数的最大值
- 8.15 打印乘法口诀表

1. 前言
大家好,我是努力学习游泳的鱼。这篇文章将会讲解C语言里的重头戏:分支和循环语句。由于这部分内容细节较多,本文可能会比较长,希望大家耐心阅读。如果短时间内看不完,可以先点下收藏,防止迷路。如果你能够掌握本篇文章的内容,你对C语言的理解就更上一层楼啦!感谢大家的支持!
2. 预备知识
2.1 getchar函数
getchar用于从键盘中读取字符,并返回读取到的字符的ASCII码值。如果遇到读取错误或者文件结束,则返回EOF。
getchar不需要传参数,返回值类型是int,对应的头文件是stdio.h。
#include <stdio.h>
int main()
{
int ch = getchar(); // 用int类型变量来接收返回值
printf("%c\n", ch);
return 0;
}
读取失败会返回EOF,在windows操作系统中,只需要按Ctrl+Z并敲回车,即可让getchar返回EOF.
2.2 putchar函数
putchar用于打印一个字符到屏幕上,使用时只需要传你要打印的字符的ASCII值。可以配合getchar使用
#include <stdio.h>
int main()
{
int ch = getchar();
putchar(ch);
// 或者直接写(这么写有风险,因为有可能读取失败)
putchar(getchar());
return 0;
}
2.3 计算数组的元素个数
假设有一个数组int arr[] = {1,2,3,4,5};我们如何用代码计算该数组的元素个数呢?很简单,用整个数组的大小除以第一个元素的大小就行了。int sz = sizeof(arr) / sizeof(arr[0]); // sz为数组的元素个数整个数组的大小是5个int,即20个字节,第一个元素是int,即4个字节,20÷4=5就算出sz为5了。
2.4 清屏
system("cls");代码可以完成清屏,其中system函数的使用需要引用头文件stdlib.h。
2.5 程序的暂停
比如Sleep(1000);可以让程序暂停1000毫秒,其中Sleep函数的使用需要引用头文件Windows.h。
2.6 字符串的比较
不能使用==来比较字符串,而应使用strcmp函数,对应的头文件是string.h。
strcmp函数可以用来比较两个字符串,如果两个字符串相等就返回0。
3. 结构化
生活中有三种结构,分别是顺序结构,分支结构和循环结构。这三种结构C语言都能支持,所以说:
C语言是一门结构化的程序设计语言。
3.1 顺序结构
即一条路走到黑,具体体现是代码会一条一条依次执行。
3.2 分支结构
C语言里有if语句和switch语句。
3.3 循环结构
C语言里有三种循环,分别是while循环,for循环和do while循环。
4. 真假性
C语言里,0表示假,非0表示真。
-1是真还是假?答案:真。因为不是0。
5. 分支语句(选择结构)
5.1 if语句
5.1.1 语法形式
初学者建议按照以下语法形式来写,不建议省略大括号。
// 单分支无else
if (表达式)
{
语句列表;
}
// 单分支有else
if (表达式)
{
语句列表1;
}
else
{
语句列表2;
}
// 多分支
if (表达式1)
{
语句列表1;
}
else if (表达式2)
{
语句列表2;
}
else
{
语句列表3
}
语句列表可以是1条或多条语句。
当表达式为真时,执行if后面大括号内的语句列表,否则执行else后面大括号内的语句列表。
如果语句列表里只有1条语句,则大括号可以省略。
举例子:
#include <stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
// 单分支无else
if (age < 18)
{
printf("未成年\n");
printf("好好学习\n");
}
// 单分支有else
if (age >= 18)
{
printf("成年\n");
}
else
{
printf("未成年\n");
printf("好好学习\n");
}
// 多分支
if (age < 18)
{
printf("青少年\n");
printf("好好学习\n");
}
else if (age >= 18 && age < 30)
{
printf("青年\n");
}
else if (age >= 30 && age < 50)
{
printf("中年\n");
}
else if (age >= 50 && age < 80)
{
printf("中老年\n");
}
else if (age >= 80 && age < 100)
{
printf("老年\n");
}
else
{
printf("老寿星\n");
}
// 省略大括号
if (age < 18)
printf("未成年\n");
else
printf("成年\n");
return 0;
}
5.1.2 else和if的匹配
以下代码执行结果是什么?
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if (a == 1)
if (b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0;
}
要回答这个问题,首先要知道,else和if是怎么匹配的?
else是和对齐的if匹配的吗?错!请牢牢记住:
就近原则:
else是和最近的if匹配的。
所以,上面的代码中的else,看似和if(a==1)对齐,实则是和if(b==2)匹配的。也就是说,代码应该这样看:
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if (a == 1)
if (b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0;
}
如果还是不清楚,再把大括号加上:
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if (a == 1)
{
if (b == 2)
{
printf("hehe\n");
}
else
{
printf("haha\n");
}
}
return 0;
}
明白了吧?由于a是0,if(a==1)压根就不会进去,所以下面的if和else都不会执行,最终结果什么都不会输出。
所以,代码风格很重要!对于初学者,建议没事不要乱省略括号!否则可能会写出一些奇奇怪怪的问题。
那么,关于if语句有哪些需要注意的代码风格呢?
5.1.3 代码风格
下面两种写法,意思是不是相同的呢?
// 写法1
int test(int flag)
{
if (flag)
return 1;
return 0;
}
// 写法2
int test(int flag)
{
if (flag)
{
return 1;
}
else
{
return 0;
}
}
意思是完全相同的!在写法1中,如果flag为真,就返回1,没有机会返回0,如果flag为假,返回1不会执行,自然就返回0了。这和写法2效果完全相同,但是写法2明显可读性更强。
再比较下面一组代码:
int main()
{
int a = 1;
// 写法1
if (a == 5)
{
printf("true\n");
}
// 写法2
if (5 == a)
{
printf("true\n");
}
return 0;
}
仍然是意思相同的一组代码,但是写法2更好。为什么呢?理由如下:
如果不小心把==写成=了,第一种写法就变成了if(a=5)
这种写法是不会报错的,甚至还会输出true。因为a=5是一个赋值表达式,把5赋值给a,这个表达式的值就是a的值,即5。5为真,就会执行printf。此时程序出错了,但是仍然能够运行,我们还要去代码中找哪里写错了,这就得不偿失了。
如何避免这种情况呢?
建议判断变量和常量是否相等时,把常量写在左边。
当我们写成if(5==a)时,如果把==写成=,即if(5=a)编译器会直接报错,因为这种写法是把一个变量赋值给常量5,但常量是不能修改的!这在语法上就已经错的没边了。
把常量写在左边,哪怕漏掉了一个等号,也能根据错误信息很快发现错误的位置,而不是去代码中找bug找半天。
5.2 switch语句
5.2.1 语法形式
switch (整型表达式)
{
语句项;
}
语句项又是什么呢?
// 是一些case语句
// 如下:
case 整型常量表达式:
语句;
举个例子:实现这样一个功能:输入1,输出星期一,输入2,输出星期二,……,输入7,输出星期天。
错误示范:
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一\n");
case 2:
printf("星期二\n");
case 3:
printf("星期三\n");
case 4:
printf("星期四\n");
case 5:
printf("星期五\n");
case 6:
printf("星期六\n");
case 7:
printf("星期天\n");
}
return 0;
}
这么写有什么问题呢?对于上面的程序,输入1,会输出星期一到星期天。这是因为,case只能决定switch语句从哪里进去,也就是说,当day是1时,就会从case 1进去,打印星期一。接下来,代码会继续往下执行,打印星期二,星期三,直到打印星期天后switch语句才结束。
case语句:决定switch语句的入口。
但我们只想输出星期一呀。这就要break语句出场了。
5.2.2 break语句
break语句:用于跳出switch语句,决定switch语句的出口。
正确的写法是
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n");
break;
case 3:
printf("星期三\n");
break;
case 4:
printf("星期四\n");
break;
case 5:
printf("星期五\n");
break;
case 6:
printf("星期六\n");
break;
case 7:
printf("星期天\n");
break;
}
return 0;
}
此时假设我们输入3,由于case决定入口,程序就会直接跳到case 3处,打印星期三,接下来遇到了break,break决定出口,程序就跳出switch语句了。
注意:
switch语句后面的括号里必须是整型表达式。
如上面代码中的day是int类型的。
case后面跟的必须是整型常量表达式。
如上面代码中的1 2 3等等。
牢牢记住,case决定入口,break决定出口。如果没有遇到出口,代码就会继续往下执行,直到遇到break或者switch语句结束。
练习:输入1~5时输出工作日,输入6和7时输出休息日。
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
case 2:
case 3:
case 4:
case 5:
printf("工作日\n");
break;
case 6:
case 7:
printf("休息日\n");
break;
}
return 0;
}
建议在最后一个
case语句后加上break,虽然哪怕不加switch语句也结束了。
对于上面这段代码,如果不在case 7后面加break,以后在case 7后面写case 8,case 9等等,会导致case语句中功能的重叠。
5.2.3 default语句
还是上面的代码,如果输入8,程序不会有任何输出,因为没有一个case语句能够匹配。
如果我们的需求是,没有case能够匹配的情况下,输出输入错误,又应该怎么写呢?
这就需要default语句出场了。
当没有任何
case语句能够匹配时,会执行default标签下的语句。
在满足要求的情况下,default语句的位置是任意的。但是建议放在switch语句的最后,处理完正常情况再处理异常情况。
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
case 2:
case 3:
case 4:
case 5:
printf("工作日\n");
break;
case 6:
case 7:
printf("休息日\n");
break;
default:
printf("输入错误\n");
break;
}
return 0;
}
建议在
switch语句的最后都加上default,并且在default后面加上break,哪怕不做任何处理,否则可能会被误认为没有处理异常情况。
6. 循环语句
6.1 while循环
6.1.1 语法形式
对于所有循环的语法形式,有一条建议:
任何情况下都请不要省略大括号,哪怕你已经熟练了,否则可读性会非常差。
我见过一些同学写循环代码经常省略大括号,看的是真的难受。写代码不要只想着炫技,你的代码最终是写给人看的。
明白了这一点,来看看while循环的语法形式:
while (表达式)
{
语句列表;
}
语句列表可以是1条或多条语句。当只有1条语句时,大括号可以省略,但是不建议省略!
如果表达式为真,则进入循环,否则不进入。
进入循环后,会执行语句列表,如果没有遇到转向语句(如break或continue等等,后面会讲),就一直执行完大括号内的语句,接着再次判断表达式的真假,如果为真就再次执行语句列表,为假就跳出循环,以此类推。
比如:打印1~10
#include <stdio.h>
int main()
{
int i = 1;
while (i <= 10)
{
printf("%d ", i);
i++;
}
return 0;
}
代码是怎么执行的呢?先创建i并初始化为1,判断i是否<=10,由于1<=10,会进入循环,接着打印i(即1),i自增变成2。再次判断i是否<=10,由于2<=10,继续打印i(即2),i自增变成3,……,直到i变成10,判断i是否<=10,由于10<=10,继续打印i(即10),i自增变成11,再次判断i是否<=10,由于11<=10为假,跳出循环。屏幕上就打印出了1~10。
6.1.2 break语句
break语句用于永久的终止循环。当while循环体内遇到break语句,会直接跳出循环。
下面代码的执行结果是什么?
#include <stdio.h>
int main()
{
int i = 1;
while (i <= 10)
{
if (5 == i)
break;
printf("%d ", i);
i++;
}
return 0;
}
答案:``i为1,2,3,4时进入循环,由于5==i均为假,不会执行break,屏幕上打印1 2 3 4,接着i为5时进入循环,5==i为真,执行break,直接跳出循环。
6.1.3 continue语句
continue用于终止本次循环。当while循环体内遇到continue语句,会跳过本次循环后面的代码,直接进行下一次循环的入口判断。
#include <stdio.h>
int main()
{
int i = 1;
while (i <= 10)
{
if (5 == i)
continue;
printf("%d ", i);
i++;
}
return 0;
}
对于这段代码,i为1 2 3 4时正常打印,i为5时,5==i为真,执行continue,就跳过了本次循环后面的打印和自增,再次来到判断i<=10,由于i仍然是5,i<=10为真,再次进入循环体,判断5==i仍然为真,continue后,仍然跳过了本次循环后面的打印和自增,来到循环的判断,此时i还是5。由于每次都会跳过i的自增,i永远没有机会变成6,也就造成了死循环。
6.1.4 代码举例
下面代码是什么意思呢?
#include <stdio.h>
int main()
{
int ch = 0;
while ((ch = getchar()) != EOF)
{
putchar(ch);
}
return 0;
}
循环每次会从键盘读取一个字符放到ch中去,如果读取成功(即getchar返回的不是EOF),就把这个字符打印出来。如果读取失败(getchar返回EOF),就跳出循环。
假设有一个场景,输入密码,然后输入Y确认。下面这段代码有没有什么问题呢?
#include <stdio.h>
int main()
{
char passwd[20] = {0};
printf("请输入密码:>");
scanf("%s", passwd);
printf("请确认密码(Y/N)\n");
int ch = getchar();
if ('Y' == ch)
printf("确认成功\n");
else
printf("确认失败\n");
return 0;
}
如果运行这段代码,输入123456并敲回车,效果是这样的:
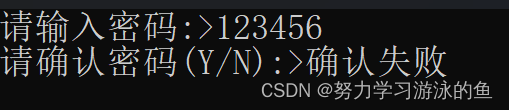
并没有等你输入Y或N,就直接显示确认失败。这是为什么呢?
因为:scanf和getchar读取数据时,不是从键盘中直接读取的,而是从缓冲区中读取的。当我们输入123456并敲回车时,缓冲区中就有了123456\n其中\n是由于你敲了个回车,而这个回车会触发scanf读取数据,scanf会把缓冲区中前面的123456拿走,放到数组passwd里,此时缓冲区里还剩一个\n没有处理。接着getchar读取数据时,发现缓冲区里还有一个\n,就二话不说把\n拿走了,放到了ch里。接着if语句判断,ch是\n呀,与Y不相同,于是就走了else,打印出确认失败。这就是为什么你还没有输入Y或N,就直接打印确认失败了。
如何解决这个问题呢?这就需要在输入Y或N前清理缓冲区。前面的写法中,由于处理不掉123456\n中的最后一个\n而出问题,那只需要加一个getchar处理掉最后这个\n不就行了吗。
#include <stdio.h>
int main()
{
char passwd[20] = {0};
printf("请输入密码:>");
scanf("%s", passwd);
// 处理掉\n
getchar();
printf("请确认密码(Y/N)\n");
int ch = getchar();
if ('Y' == ch)
printf("确认成功\n");
else
printf("确认失败\n");
return 0;
}

这样看似没问题了,实际上还存在问题。
如果我们输入123456,按空格,再输入abcdef,接着敲回车,仍然会出现还没输入Y或N就确认失败的情况。
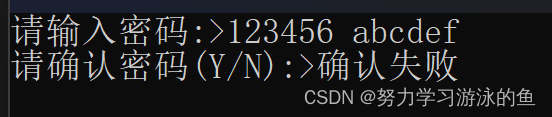
这又是为什么呢?其实,这是由于清理缓冲区的力度不够。
在我们输入后,缓冲区里就有了123456 abcdef,scanf配合%s读取字符串时,会拿走空格之前的123456,也就是说,此时缓冲区中仍然有很多字符,用一个getchar来处理是不够的,应该用多个getchar,这就需要循环出场啦。
最合理的写法是:
#include <stdio.h>
int main()
{
char passwd[20] = {0};
printf("请输入密码:>");
scanf("%s", passwd);
// 清理缓冲区
int tmp = 0;
while ((tmp = getchar()) != '\n')
{
;
}
printf("请确认密码(Y/N)\n");
int ch = getchar();
if ('Y' == ch)
printf("确认成功\n");
else
printf("确认失败\n");
return 0;
}
由于第一次输入时,缓冲区的最后一定是个\n,只需要一直用getchar读取字符,直到读取到\n才停止。这样就完美解决了前面的问题。
6.2 for循环
6.2.1 语法形式
for (初始化语句; 判断表达式; 调整语句)
{
语句列表;
}
语句列表可以是一条或多条语句,如果是一条语句可以省略大括号,但是不建议省略大括号。
初始化语句负责初始化循环变量。
判断表达式负责判断是否进行下一轮循环。
调整语句负责在一次循环结束后调整循环变量。
实际执行时,会先执行初始化语句,接着看判断表达式的真假,如果为假,就不进入循环,如果为真,就进入循环。若进入循环,执行完语句列表后,会接着执行调整语句,然后看判断表达式的真假,如果为假,就跳出循环,如果为真,则继续下一轮循环,执行循环体内的语句列表,以此类推。
比如,我们要在屏幕上打印1~10。
#include <stdio.h>
int main()
{
int i = 0;
for (i=1; i<=10; i++)
{
printf("%d ", i);
}
return 0;
}
这段代码会先创建i并初始化为0,接着执行for循环,先把i赋值为1,判断i<=10为真,进入循环,打印i,接着来到i++,i变成2,判断i<=10为真,进入循环,打印i,接着来到i++,i变成3,判断i<=10为真,进入循环,打印i,……,i变成10,判断i<=10为真,进入循环,打印i,接着来到i++,i变成11,判断i<=10为假,跳出循环。请好好体会一下这一个过程。
6.2.2 break语句
break用于永久终止循环。当for循环体内遇到break,会直接跳出循环。
#include <stdio.h>
int main()
{
int i = 0;
for (i=1; i<=10; i++)
{
if (5 == i)
break;
printf("%d ", i);
}
return 0;
}
上面的代码当i变成5时,判断5==i为真,执行break,会直接跳出循环。输出结果是,屏幕上打印1 2 3 4
6.2.3 continue语句
continue语句用于终止本次循环。当for循环体内遇到continue语句,会直接跳过本次循环后面的代码,来到循环的调整部分。
#include <stdio.h>
int main()
{
int i = 0;
for (i=1; i<=10; i++)
{
if (5 == i)
continue;
printf("%d ", i);
}
return 0;
}
上面的代码中,当i变成5时,5==i为真,执行continue,会直接跳到i++,i变成6,接着打印6 7 8 9 10。输出结果是:1 2 3 4 6 7 8 9 10
6.2.4 for循环控制循环变量
建议:
1.不可在
for循环体内修改循环变量,防止for循环失去控制。
2.建议for循环控制变量的取值采用“前闭后开”的写法。
采取前闭后开的写法时,可读性更强。如:
// 前闭后开的写法 [0, 10)
for (i=0; i<10; i++)
{}
// 两边都是闭区间 [0, 9]
for (i=0; i<=9; i++)
{}
上面的写法能够一眼看出会循环10次。
一个经典的例子是打印数组:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i < 10; i++) // 这里采取前闭后开的写法
{
printf("%d ", arr[i]);
}
return 0;
}
6.2.5 for循环的变种
for循环的初始化,判断,调整部分都是可以省略的,但是不建议初学者省略。如果省略判断部分,则判断部分恒为真。
for (;;)
{}
下面的代码执行结果是多少?
#include <stdio.h>
int main()
{
int count = 0;
int i = 0;
int j = 0;
for (i = 0; i < 10; i++)
{
for (j = 0; j < 10; j++)
{
++count;
}
}
printf("count = %d\n", count);
return 0;
}
很简单,外层循环10次,内层循环10次,最后count=100。
那如果省略掉初始化呢?
#include <stdio.h>
int main()
{
int count = 0;
int i = 0;
int j = 0;
for (; i < 10; i++)
{
for (; j < 10; j++)
{
++count;
}
}
printf("count = %d\n", count);
return 0;
}
当i为1时,i<10成立,j从0变到9都满足j<10,会使count自增,j变成10后不满足j<10,跳出内层循环,i变成2后,i<10成立,此时j还是10!不满足j<10,不会进入内层循环,接着i变成3 4 5 6 7 8 9,j都是10,都不会进入内层循环,所以最后count=10。
我们还可以使用多个变量控制循环,如
int x = 0;
int y = 0;
for (x=0, y=0; x<2 && y>5; ++x, y++)
{}
6.3 do while循环
6.3.1 语法形式
do
{
语句列表;
} while (判断表达式);
语句列表是一条或多条语句。如果只有一条语句,则大括号可以省略(但不建议省略)。
do while循环中,会不管三七二十一先执行大括号里的语句列表,接着根据判断表达式的真假性,决定是否再次执行语句列表。
由于do while无论如何都会执行一次语句列表,一般很少使用。就使用频率来说,for循环最多,其次是while循环,do while循环最少。
举个例子:打印1~10。
#include <stdio.h>
int main()
{
int i = 1;
do
{
printf("%d ", i);
++i;
} while (i <= 10);
return 0;
}
循环会不管三七二十一先打印i,接着i自增变成2,然后判断i<=10为真,继续打印,自增变成3,再判断i<=10仍然为真,打印,自增变成4,……自增变成10,判断i<=10为真,打印,自增变成11,i<=10为假,跳出循环。屏幕上就打印了1~10。
6.3.2 break语句
理解了while循环和for循环的break和continue后,do while循环的break和continue就很简单了,基本大同小异。
break用于永久的终止循环。当do while循环体内遇到break语句,会直接跳出循环。
#include <stdio.h>
int main()
{
int i = 1;
do
{
if (5 == i)
break;
printf("%d ", i);
++i;
} while (i <= 10);
return 0;
}
上面这段代码,当i为5时遇到break,没来得及打印,直接跳出循环,此时屏幕上打印了1~4。
6.3.3 continue语句
continue用于终止本次循环。当do while循环体内遇到continue,会跳过本次循环后面的代码,直接来到循环的判断部分。
#include <stdio.h>
int main()
{
int i = 1;
do
{
if (5 == i)
continue;
printf("%d ", i);
++i;
} while (i <= 10);
return 0;
}
先打印1~4,当i为5时,遇到continue,直接跳到判断i<=10,为真,继续执行循环体,又遇到continue,跳到判断,仍为真,因为每次都跳过了i的自增,所以i永远是5,就死循环了。
7. goto语句
C语言中提供了可以随意滥用的
goto语句和标记跳转的标号。
从理论上goto语句是没有必要的,实践中没有goto语句也可以很容易的写出代码。
7.1 语法形式
goto flag; // flag名字可以任意
// 执行完goto就会直接跳到这里,
flag: // 有可能在goto的前面也有可能在后面,但是不能跨函数!
某些场合下
goto语句还是用得着的,最常见的用法就是终止程序在某些深度嵌套的结构的处理过程。
如:一次跳出两层或多层循环。
多层循环这种情况使用break是达不到目的的。它只能从最内层循环退出到上一层循环。
goto语句真正适用的场景如下:
for (...)
{
for (...)
{
for (...)
{
if (disaster)
goto error;
}
}
}
...
error:
if (disaster)
{
// 处理错误情况
}
7.2 代码举例
下面我们写一个关机程序。
只要程序运行起来,电脑就在1分钟内关机,如果输入:我是猪,就取消关机。
首先我们要知道如何关机或者取消关机。
设置1分钟后关机的代码:system("shutdown -s -t 60");
取消关机任务的代码:system(shutdown -a);
需要注意,system是一个库函数,是用来执行系统命令的。对应的头文件是stdlib.h。
还需要注意,字符串是不能用==来比较是否相等的,需要用的strcmp函数。
完整实现的代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char input[20] = { 0 };
system("shutdown -s -t 60");
again:
printf("请注意,你的电脑在1分钟内关机,如果输入:我是猪,就取消关机\n");
scanf("%s", input);
if (strcmp(input, "我是猪") == 0)
{
system("shutdown -a");
}
else
{
goto again;
}
return 0;
}
但是,我们可以很简单地用循环实现同样的功能。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char input[20] = { 0 };
system("shutdown -s -t 60");
while (1)
{
printf("请注意,你的电脑在1分钟内关机,如果输入:我是猪,就取消关机\n");
scanf("%s", input);
if (strcmp(input, "我是猪") == 0)
{
system("shutdown -a");
break;
}
}
return 0;
}
你可以把这个代码编译生成的可执行程序发给你的好朋友玩玩。需要注意的是,编译前记得把模式从debug改成release,否则你好朋友的电脑的环境可能运行不了。
8. 综合练习
8.1 打印1~100之间的奇数
我们如何判断一个数是不是奇数呢?奇数÷2后会余1,即如果n是奇数,则n%2==1
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
// 判断n是不是奇数
if (n%2 == 1)
{
printf("%d是奇数\n", n);
}
return 0;
}
解题思路:产生1~100之间的数,如果是奇数就打印。
#include <stdio.h>
int main()
{
int i = 0;
// 产生1~100之间的数
for (i=1; i<=100; i++)
{
// 判断i是不是奇数,是奇数就打印
if (i%2 == 1)
{
printf("%d ", i);
}
}
return 0;
}
就这题而言,有个更简单的解法。1~100之间的奇数不就是1 3 5 7 9...这是个等差数列,公差为2,循环调整部分每次加2不就行了。
#include <stdio.h>
int main()
{
int i = 0;
for (i=1; i<=100; i+=2)
{
printf("%d ", i);
}
return 0;
}
所以说,掌握了核心技术,写起代码就是爽!
8.2 求n的阶乘
解题思路:产生1~n的数,再乘起来即可。
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
int i = 0;
int ret = 1;
for (i = 1; i <= n; i++)
{
ret *= i;
}
printf("%d\n", ret);
return 0;
}
衍生问题:求1!+2!+3!+...+10!。
解题思路:用n产生1~10,每次求n的阶乘并加起来。
#include <stdio.h>
int main()
{
int n = 0;
int sum = 0;
for (n = 1; n <= 10; n++)
{
int i = 0;
int ret = 1; // 这里ret必须创建在外层循环里面!
for (i = 1; i <= n; i++)
{
ret *= i;
}
sum += ret;
}
printf("sun = %d\n", sum);
return 0;
}
n为1时,内层循环求1的阶乘,加到sum上,n为2时,内层循环求2的阶乘,加到sum上,n为3时,内层循环求3的阶乘,加到sum上。由于n会从1变到10,就求出了1~10的阶乘的和。
这种写法有一个错误的版本,如果把ret放在外层循环的外面,求出的结果就是错的,你知道为什么吗?
#include <stdio.h>
int main()
{
int n = 0;
int sum = 0;
int ret = 1; // 创建在外层循环外面
for (n = 1; n <= 10; n++)
{
int i = 0;
for (i = 1; i <= n; i++)
{
ret *= i;
}
sum += ret;
}
printf("sun = %d\n", sum);
return 0;
}
这是因为,每次ret并不会重置为1,这就导致,每次求n的阶乘时,不是从1开始乘到n,而是从n-1的阶乘开始,乘上1到n。举个例子就明白了。当n为2时,内层循环会算出2的阶乘,保存到ret上,接着n变成3,仔细看代码,接下来做的事情是,产生1到3并乘到ret上去,但是ret是定义在外层循环外面的,一次外层循环后,ret并没有重新创建,此时ret仍然还是前面求出来的2的阶乘,所以实际上做的事情是在2的阶乘上乘上1到3,这就不是3的阶乘了,正确的算法应该是在1上乘上1到3,仔细体会这两者的区别。
那为什么前面那种写法就是对的呢?因为ret是创建在外层循环里面的。一次外层循环结束后,ret会被重新创建并初始化为1,就不会保留上一次循环留下来的值了。当然,如果想把ret创建在外层循环外面也是可以的,但要在循环里面对其进行初始化。
#include <stdio.h>
int main()
{
int n = 0;
int sum = 0;
int ret = 1;
for (n = 1; n <= 10; n++)
{
ret = 1; // 要把ret重置为1
int i = 0;
for (i = 1; i <= n; i++)
{
ret *= i;
}
sum += ret;
}
printf("sun = %d\n", sum);
return 0;
}
不过,把ret创建在外头也是有好处的。每次保留下来上一次循环求出来的阶乘,也就是说,保留的是n-1的阶乘,我们算n的阶乘,直接在n-1的阶乘上乘以n不就行了吗。
改进后的代码如下:
#include <stdio.h>
int main()
{
int n = 0;
int sum = 0;
int ret = 1;
for (n = 1; n <= 10; n++)
{
ret *= n;
sum += ret;
}
printf("sun = %d\n", sum);
return 0;
}
这么写是不是简单多了?原来是两层循环,这样写只有一层循环,代码的效率就提升了不少。学习了时间复杂度,你就会明白,后一种写法把时间复杂度从O(N2)优化到了O(N)。
8.3 二分查找(折半查找)
问题:如何在一个有序数组中查找具体的某个数字?
你可能会想:遍历一下不就行了嘛。
#include <stdio.h>
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
int k = 7;
// 查找k
int i = 0;
for (i=0; i<sz; i++)
{
if (arr[i] == k)
{
printf("找到了,下标是%d\n", i);
break;
}
}
if (i == sz)
{
printf("找不到了\n");
}
return 0;
}
但是这种写法,就完全忽略了“有序”两个字,因为无序数组也能够这么查找。
这里介绍一个非常厉害的算法:二分查找(也叫折半查找)。
二分查找(折半查找):我们在一个有序数组里查找一个确定的数,每次可以先找到中间那个数,如果要查找的数比中间的数大,那么就去右边找,反之去左边找,直到找到为止。
比如,一个数组存储的数据是[1 2 3 4 5 6 7 8 9 10],假设要查找7。数组的左下标是0,右下标是9,计算(0+9)/2得4,以4为下标的数是5,由于要查找的7比5大,说明要在5的右边找,要查找的下标的范围就从[0,9]缩小为[5,9],其中5=4+1。接着计算[5,9]的中间下标(5+9)/2=7,以7为下标的数是8,由于要查找的7比8小,说明要在8的左边找,要查找的下标的范围就从[5,9]缩小为[5,6],其中6=7-1。接着计算[5,6]的中间下标(5+6)/2=5,以5为下标的数是6,由于要查找的7比6大,说明要在6的右边找,要查找的下标的范围就从[5,6]缩小为[6,6],其中6=5+1。接着计算[6,6]的中间下标(6+6)/2=6,以6为下标的数是7,和要查找的7相等,就找到啦。由于[6,6]范围内只有一个数据,如果这一个数据都和要查找的数据不相等,那就找不到了。
明白了二分查找的思路,我们还要把它转换成代码。由于逻辑较为复杂,我会一段一段写并加以分析。
首先创建数组:int arr[] = {1,2,3,4,5,6,7,8,9,10};
定义要查找的元素(假设是7):int k = 7;
由于我们每次要用中间元素的下标跟k比较,我们需要左下标和右下标才能计算中间元素的下标,其中一开始左下标是数组的左下标,即0,右下标是数组的元素个数(假设是sz)减1。
int left = 0;
int right = sz - 1;
但我们不知道数组的元素个数呀,所以需要计算。int sz = sizeof(arr) / sizeof(arr[0]);
接着我们需要进行二分查找。二分查找可能需要进行多次,这就有了循环的可能。不过目前我们先写一次查找。
计算中间元素的下标,即左下标和右下标的平均值。
int mid = (left+right) / 2;这么计算有一个问题,如果left和right比较大,加起来后有可能导致越界,那怎么办呢?有朋友可能说了,运用结合律,这么写:int mid = left/2 + right/2;但是这么写的话,如果left是3,right是5,3和5的平均值应该是4,但是3/2+5/2=1+2=3,那就出问题了。所以最好的写法是:int mid = left + (right-left) / 2;
这种写法是如何想出来的呢?请你闭上眼睛,想象一下,有两条绳子,一长一短,我们如何能让两条绳子一样长呢?只需要比一比,长的那条绳子比短的那条绳子多出来多少,把多的那部分平分为两半,在补给短的绳子就行了,这就是上面这行代码的由来。
有了中间元素的下标,我们还需要和要查找的k比较,才知道是去左边找还是去右边找。
if (arr[mid] < k)
{}
else if (arr[mid] > k)
{}
else
{}
这分别代表哪三种情况呢?如果中间的元素比k要小,说明k在右边,那要查找的范围就变成了原来范围的右半边。原来的范围是[left,right]那现在的范围是什么呢?有朋友会说,是[mid,right],但是事实上,是[mid+1,right],因为arr[mid]已经比k要小了,自然就不用查找了。也就是说,原来范围的right不变,left要变成mid+1。同理,如果中间的元素比k要大,说明k在左边,原来的left不变,right要变成mid-1。大于小于都讨论了,剩下的就是等于了,那就找到了,由于此时arr[mid]==k,也就是说找到的下标就是mid。
if (arr[mid] < k)
{
left = mid + 1;
}
else if (arr[mid] > k)
{
right = mid - 1;
}
else
{
printf("找到了,下标是:%d", mid);
}
但是不一定找一次就能找到呀,可能会找很多次,这就需要一个循环。这里用while循环会比较合适。循环的条件是什么呢?二分查找的过程中,每次都会砍掉一半,体现在代码上,left和right会逐渐逼近,但是left会始终在right的左边,也就是left<right,而当left==right时,区间还有一个元素可以查找,如果这一个元素都不是我们能要找的元素,那就找不到了。所以循环的条件是:left<=right。还有一点要注意,要在循环里面计算mid,因为每次都需要一个新的mid。当我们找到了,就没必要继续找了,直接break出去。
while (left <= right)
{
int mid = left + (right - left) / 2;
if (arr[mid] < k)
{
left = mid + 1;
}
else if (arr[mid] > k)
{
right = mid - 1;
}
else
{
printf("找到了,下标是:%d\n", mid);
break;
}
}
当循环结束,有两种可能,第一种是找到之后break出去,此时一定有left<=right,另一种是找呀找呀,发现找不到,此时已经不满足left<=right了(即满足left>right),才跳出循环。所以循环结束后,还要加一个是否找到的判断。
if (left > right)
{
printf("找不到了\n");
}
完整的代码如下:
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int k = 7;
// 查找k
int sz = sizeof(arr) / sizeof(arr[0]);
int left = 0;
int right = sz - 1;
while (left <= right)
{
int mid = left + (right - left) / 2;
if (arr[mid] < k)
{
left = mid + 1;
}
else if (arr[mid] > k)
{
right = mid - 1;
}
else
{
printf("找到了,下标是:%d\n", mid);
break;
}
}
if (left > right)
{
printf("找不到了\n");
}
return 0;
}
8.4 字符串从两端向中间打印
假设有一个字符串:Hello, World!!!!!
我们想一开始在屏幕打印一串#,再逐渐从两端向中间展示这个字符串。
思路:可以定义两个数组,一个数组存储Hello,World!!!!!,另一个数组存储一串#,每次把前者两端的字符拿到后者中去并打印后者。每次拿完后暂停1秒,再清屏。
#include <stdio.h>
#include <string.h>
#include <Windows.h>
#include <stdlib.h>
int main()
{
char arr1[] = "Hello, World!!!!!";
char arr2[] = "#################";
int left = 0;
int right = strlen(arr1) - 1;
while (left <= right)
{
arr2[left] = arr1[left];
arr2[right] = arr1[right];
printf("%s\n", arr2);
Sleep(1000);
system("cls");
++left;
--right;
}
printf("%s\n", arr2);
return 0;
}
8.5 模拟登陆情景
输入密码,假设密码是123456若输入错误3次,则退出程序。
注意判断密码是否正确的代码应使用strcmp函数,不能直接使用==比较字符串。
#include <stdio.h>
#include <string.h>
int main()
{
char passwd[20] = { 0 };
int i = 0;
for (i = 0; i < 3; i++)
{
printf("请输入密码:>");
scanf("%s", passwd);
if (strcmp(passwd, "123456") == 0)
{
printf("密码正确\n");
break;
}
else
{
printf("密码错误,重新输入\n");
}
}
if (3 == i)
{
printf("三次密码均输入错误,退出程序\n");
}
return 0;
}
8.6 猜数字游戏
首先我们需要学会如何使用C语言生成一个随机数。
使用
rand函数生成一个0~32767的随机数。使用rand函数不需要传参数。rand函数会直接返回生成的随机数。rand函数对应的头文件是stdlib.h。
调用rand函数之前需要调用srand函数来设置随机数生成器的起点,srand函数只能调用一次。srand函数需要传一个unsigned int类型的参数,该参数是一个随机数,一般建议传时间戳。srand函数对应的头文件也是stdlib.h。
使用time函数生成一个时间戳。如果你不想保存这个时间戳,只需要给time函数传一个空指针NULL即可。time函数会返回对应的时间戳,类型是time_t。
如果要把time函数返回的时间戳传给srand,需要强制类型转换成unsigned int。
写一个演示代码来生成随机数。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main()
{
srand((unsigned int)time(NULL));
int ret = rand();
printf("ret = %d\n", ret);
return 0;
}
回归正题。猜数字游戏的要求是:
- 电脑随机生成一个数字(
1~100)。 - 玩家猜数字。玩家猜小了,就告知猜小了。玩家猜大了,就告知猜大了。直到猜对为止。
- 游戏可以一直玩。
对于第一点,我们可以写int ret = rand() % 100 + 1;因为%100之后得到0~99,再+1即可得到1~100。
对于第二点,只需要一个while循环配合if语句。
对于第三点,可以使用do while循环。因为这个游戏至少要进去一次,使用do while循环最合适。
参考代码如下:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void menu()
{
printf("************************\n");
printf("***** 1. play *****\n");
printf("***** 0. exit *****\n");
printf("************************\n");
}
void game()
{
int ret = rand() % 100 + 1;
int guess = 0;
while (1)
{
printf("猜数字:>");
scanf("%d", &guess);
if (guess > ret)
{
printf("猜大了\n");
}
else if (guess < ret)
{
printf("猜小了\n");
}
else
{
printf("恭喜你,猜对了\n");
break;
}
}
}
int main()
{
int input = 0;
srand((unsigned int)time(NULL));
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
game();
break;
case 0:
printf("退出游戏\n");
break;
default:
printf("选择错误,重新选择!\n");
break;
}
} while (input);
return 0;
}
注意:
srand函数在一个程序中只能被调用一次。就上面的代码而言,srand函数是写在main函数里的,所以只会被调用一次。int ret = rand() % 100 + 1;必须放在while循环外面,否则每次循环都会生成一个新的随机数。- 猜大了和猜小了的提示不要搞反了!
8.7 把三个整数从大到小输出
假设我有三个数,如何从大到小输出呢?
解题思路:假设三个数是a,b,c,我输出总得有一个顺序吧,比如先打印a,接着打印b,再打印c。那是不是就是要把最大的放a里,中间的数放b里,最小的放c里?
我们可以先比较a和b,如果a比b大,那就是我们想要的,如果a比b小,那就交换a和b,这样就把a和b中较大的数放在了a里了。同理再把a和c中较大的放在a里,但个数中最大的就放在a里了。然后比较b和c,把大的放b里,小的放c里就行了。
那如何交换两个变量呢?假设交换a和b,只需要创建一个临时变量,把a放临时变量里,再把b放在a里,最后把临时变量中原来a的值放在b里就行了。
int tmp = a;
a = b;
b = tmp;
完整的代码如下:
#include <stdio.h>
int main()
{
int a = 0;
int b = 0;
int c = 0;
scanf("%d %d %d", &a, &b, &c);
if (a < b)
{
int tmp = a;
a = b;
b = tmp;
}
if (a < c)
{
int tmp = a;
a = c;
c = tmp;
}
if (b < c)
{
int tmp = b;
b = c;
c = tmp;
}
printf("%d %d %d\n", a, b, c);
return 0;
}
8.8 求最大公约数
如何求两个数的最大公约数呢?
比如,24和18的最大公约数怎么求呢?
可以先找到小的那个数,即18,最大公约数不可能比18大,所以我们就挨个挨个地试,18是不是最大公约数?17是不是?16呢?15呢?直到试出来为止。
#include <stdio.h>
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
// 找出较小值
int m = a < b ? a : b;
while (1)
{
if (a % m == 0 && b % m == 0)
break;
--m;
}
printf("%d\n", m);
return 0;
}
不过这种方法效率太低了。有一种厉害的算法:辗转相除法,可以更高效地解决这个问题。
简单来说,辗转相除法就是反复地取模(操作符是%)。求a和b的最大公约数,只需要先a模b得到c,如果c不是0,就再b模c得到d,如果d不是0,就d模e得到f……假设后面一直取模,当x模y刚好得到0,那么y就是最大公约数。
这种解法不需要先比较大小。如果a比b大,自然可以一直取模。如果a比b小,假设a是18,b是24,那么a模b得到c(即18),再b模c时(此时就是24模18),这和一开始就是24和18的效果是一样的。
如何实现辗转相除法呢?可以使用while循环,每次计算a模b的值,如果是0,那么b就是最大公约数。如果不是0呢?就需要把模出来的值记录下来(记为m),然后把b的值给a,把m的值给b,此时再算a模b,就是在算b模m了,这样就能一直循环下去了。当a模b得到0时,跳出循环,此时b就是最大公约数。
#include <stdio.h>
int main()
{
int a = 0;
int b = 0;
int m = 0;
scanf("%d %d", &a, &b);
while (m = a % b)
{
a = b;
b = m;
}
printf("%d\n", b);
return 0;
}
当然,我们可以用函数来实现。
#include <stdio.h>
int get_greatest_common_divisor(int x, int y)
{
int m = 0;
while (m = x % y)
{
x = y;
y = m;
}
return y;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
int ret = get_greatest_common_divisor(a, b);
printf("ret = %d\n", ret);
return 0;
}
8.9 求最小公倍数
和最大公约数大同小异。
解题思路:假设求18和24的最小公倍数。较大的数是24,最小公倍数不可能比24小,所以就一个一个试。24是不是最小公倍数?25是不是?26呢?直到试对为止。
#include <stdio.h>
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
// 求较大值
int m = a > b ? a : b;
while (1)
{
if (m % a == 0 && m % b == 0)
break;
++m;
}
printf("%d\n", m);
return 0;
}
当然,一个一个去试也太慢了。最小公倍数一定是其中一个数的整数倍。比如a和b的最小公倍数一定是a的整数倍,那就只需要试a,2×a,3×a,……就行了。
#include <stdio.h>
int main()
{
int a = 0;
int b = 0;
int m = 0;
scanf("%d %d", &a, &b);
for (m = a; m % b != 0; m += a)
{
;
}
printf("%d\n", m);
return 0;
}
除此之外,我们还可以这么做:
假设求a和b的最小公倍数,只需要算a×b÷(a和b的最大公约数)。这就可以复用上面写的函数了。
#include <stdio.h>
// 最大公约数
int get_greatest_common_divisor(int x, int y)
{
int m = 0;
while (m = x % y)
{
x = y;
y = m;
}
return y;
}
// 最小公倍数
int get_least_common_multiple(int x, int y)
{
int m = get_greatest_common_divisor(x, y);
return x * y / m;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
int ret = get_least_common_multiple(a, b);
printf("%d\n", ret);
return 0;
}
8.10 打印闰年
题目:打印1000~2000之间的闰年。
解题思路:只需要用for循环产生1000到2000,是闰年就打印。
如何判断是不是闰年呢?
- 能被
4整除,并且不能被100整除是闰年。 - 能被
400整除是闰年。
纯用if else来写是这样的:
#include <stdio.h>
int main()
{
int y = 0;
for (y = 1000; y <= 2000; y++)
{
if (y % 4 == 0)
{
if (y % 100 != 0)
{
printf("%d ", y);
}
}
if (y % 400 == 0)
{
printf("%d ", y);
}
}
return 0;
}
如果你会用逻辑操作符,可以这样写:
#include <stdio.h>
int main()
{
int y = 0;
for (y = 1000; y <= 2000; y++)
{
if (((y % 4 == 0) && (y % 100 != 0)) || (y % 400 == 0))
{
printf("%d ", y);
}
}
return 0;
}
8.11 打印素数
题目:打印100~200之间的素数。
解题思路:产生100~200之间的数,是素数就打印。
什么是素数?素数就是质数,只能被1和它本身整除的数字。
如何判断一个数字i是不是素数?
很简单,拿2到(i-1)的数字去试除i,
- 如果
i被整除,就说明i不是素数 - 如果
2到(i-1)的数字都不能整除i,说明i是素数。
这就需要一个循环产生2到(i-1)的数字,当该循环结束后,就全都试除完了,此时如何判断是否有整除现象呢?我们可以定义一个flag并初始化为1,一旦整除就置成0。如果循环结束后flag仍为1,就说明没有一个数能够整除,就说明i是素数。
int main()
{
int i = 0;
for (i = 100; i <= 200; ++i)
{
int flag = 1; // 假设i是素数
int j = 0;
for (j = 2; j < i; j++)
{
if (i % j == 0)
{
// i不是素数
flag = 0;
break;
}
}
if (1 == flag)
{
// i是素数
printf("%d ", i);
}
}
return 0;
}
这是最容易想到的写法,还可以做一些优化。
如果一个数i=a×b,那么a个b中至少有一个数小于或等于i的算术平方根。
比如16=2×8=4×4,16的算术平方根是4,这两种写法中都至少有一个数小于或等于4。
所以试除的时候就不需要从2一直试到(i-1),只需要试到i的算术平方根就行了。
C语言提供了
sqrt函数用于开平方,使用时需要引用头文件math.h。
还有一个小点可以优化:偶数一定不是素数,所以只需要判断所有的奇数就行了。
#include <stdio.h>
#include <math.h>
int main()
{
int i = 0;
for (i = 101; i < 200; i += 2)
{
int flag = 1; // 假设i是素数
int j = 0;
for (j = 2; j <= sqrt(i); j++)
{
if (i % j == 0)
{
// i不是素数
flag = 0;
break;
}
}
if (1 == flag)
{
// i是素数
printf("%d ", i);
}
}
return 0;
}
8.12 统计9的个数
题目:统计1~100中9的个数。
解题思路:要么个位是9,要么十位是9。若i个位是9,则i%10==9。若i十位是9,则i/10==9。只需要产生1~100的数,再根据上面的两种情况分类讨论就行了。
#include <stdio.h>
int main()
{
int i = 0;
int count = 0;
for (i = 1; i <= 100; i++)
{
if (i % 10 == 9)
++count;
if (i / 10 == 9)
++count;
}
printf("count = %d\n", count);
return 0;
}
8.13 分数求和
题目:计算1/1-1/2+1/3-1/4+...+1/99-1/100。
思路:产生1~100的数作为分母,再用一个flag变量产生正负交替的效果。
注意:对于/操作符,如果两个操作数都是整数,最终的结果也是整数,只有一端是小数,算出来的结果才是小数。
#include <stdio.h>
int main()
{
int i = 0;
double sum = 0;
int flag = 1;
for (i = 1; i <= 100; i++)
{
sum = sum + (1.0 / i) * flag;
flag = -flag;
}
printf("sum = %lf\n", sum);
return 0;
}
8.14 求10个整数的最大值
思路:可以先假设第一个数是最大值,接着拿后面9个数和这个数比,如果有比假设的最大值大的数,就更新最大值。
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int i = 0;
for (i = 0; i < 10; i++)
{
scanf("%d", &arr[i]);
}
int max = arr[0];
for (i = 1; i < 10; i++)
{
if (arr[i] > max)
{
max = arr[i];
}
}
printf("max = %d\n", max);
return 0;
}
8.15 打印乘法口诀表
解题思路:用变量i产生行数,用变量j产生列数。
如果想要打印时能够尽可能对齐,可以使用%-2d的格式来打印乘积。其中负号表示左对齐,2表示至少打印两位,不够就用空格补齐。
#include <stdio.h>
int main()
{
int i = 0;
for (i = 1; i <= 9; i++)
{
int j = 0;
for (j = 1; j <= i; j++)
{
printf("%d*%d=%-2d ", i, j, i * j);
}
printf("\n");
}
return 0;
}