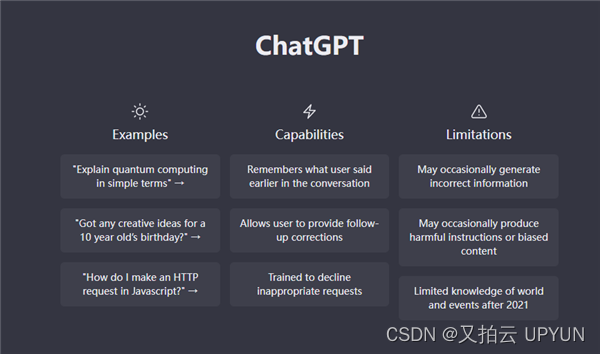
文章目录
- 前言
- 定时与邮件
- 明确目标
- 分析过程
- 爬虫
- 发送邮件
- 定时
- 代码组装
- 复习
前言
上一关我们学习了selenium,它有可视模式与静默模式这两种浏览器的设置方法,二者各有优势。
然后学习了使用.get(‘URL’)获取数据,以及解析与提取数据的方法。
在这个过程中,我们操作对象的转换过程:

除了上面的方法,还可以搭配BeautifulSoup解析提取数据,前提是先获取字符串格式的网页源代码。
HTML源代码字符串 = driver.page_source
以及自动操作浏览器的一些方法。
定时与邮件
在这一关,我们希望为一般的爬虫程序新增两个实用性比较强的功能:
第一是定时功能,即程序可以根据我们设定的时间自动爬取数据;第二是通知功能,即程序可以把爬取到的数据结果以邮件的形式自动发送到我们的邮箱。
这两个功能可以让爬虫程序定时向我们汇报。
试想一下,如果你是一位股票(或比特币)的持有者,你希望及时爬取股票(或比特币)每日的价格数据,方便你能及时卖出或买入,那每天都去启动一遍爬虫程序是极其不高效的。
而此时,如果你的爬虫程序有定时和发送邮件功能,能自动爬取每天的数据,并且只有当价格达到某个你设置的价位时,才通知你可以有所行动了,平时都不打扰你,是不是很爽?
不止如此,如果你有特别想看的演唱会,但一开售就卖完了,有定时和发送邮件功能的爬虫程序同样可以辛勤地帮你刷票,当刷到有余票时,马上通知你去购票,多好。(买火车票也是一样的道理噢)
这两个功能不仅能帮你获取这种实时变化的数据,还可以帮你获取周期性的数据。
比如,你所在的公司每周都会把周报发到官网上,而你所在的部门是由你去负责下载周报,并整理相关信息,再传递给部门成员。那如果有定时和通知功能的程序,每周你就可以静待程序把更新的周报信息爬下来,并自动发送到你邮箱。
了解这两个功能的意义后,我们就可以开始今天正式的学习了。
按照一向以来的规矩,实现一个项目的流程是这样的:
马上开始第一步:明确目标
明确目标
我们选择的项目是——自动爬取每日的天气,并定时把天气数据和穿衣提示发送到你的邮箱。
之所以选择这个相对朴实的爬虫项目,是因为天气每天都会有变化,那么在学完这一关之后,不出意外,你就可以在明早收到天气信息了。以此,亲身体验程序的作用。
你还可以把每日的天气和温馨的穿衣提示发送到你的恋人、家人、或朋友的邮箱里,这也是传递心意的一种方式。
好啦,那我们来分析一下程序实现的思路吧。
分析过程
总体上来说,可以把这个程序分成三个功能块:【爬虫】+【邮件】+【定时】
对爬虫部分,我们比较熟悉;而对通知部分,选择的是用邮件来通知,我们将使用smtplib、email库来实现这一需求;对定时功能,有一个schedule,方便好用。
这三个功能对应的是三段代码,分别写出三段代码后再组装起来,就能实现我们的项目目标。
对于曾经在Python基础课学过发送邮件的同学,如果你对这部分知识比较熟悉,等下讲到邮件部分时,你可以选择跳过。不过,老师还是建议你可以简单复习一下。
第一次学习用Python发送邮件的同学,当然就是选择学习通知功能了。O(∩_∩)O~~
好啦,我们先来看爬虫部分的程序:
爬虫
直接找到中国中国气象网的天气预报网址:
http://www.weather.com.cn/weather/101010100.shtml
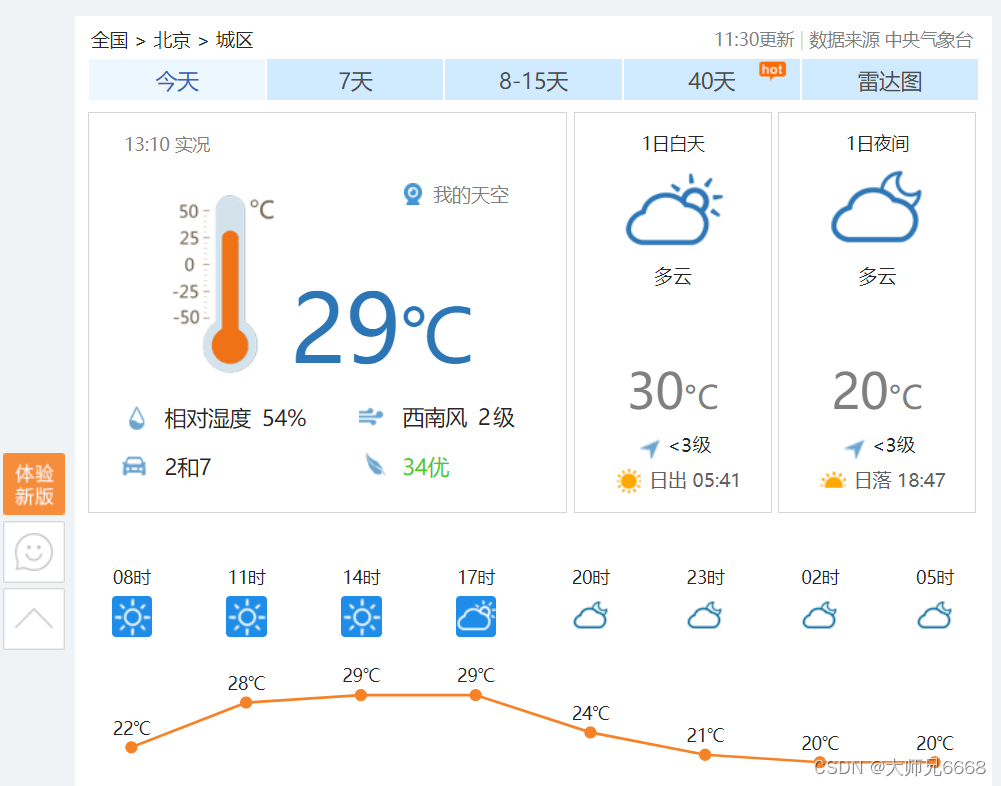
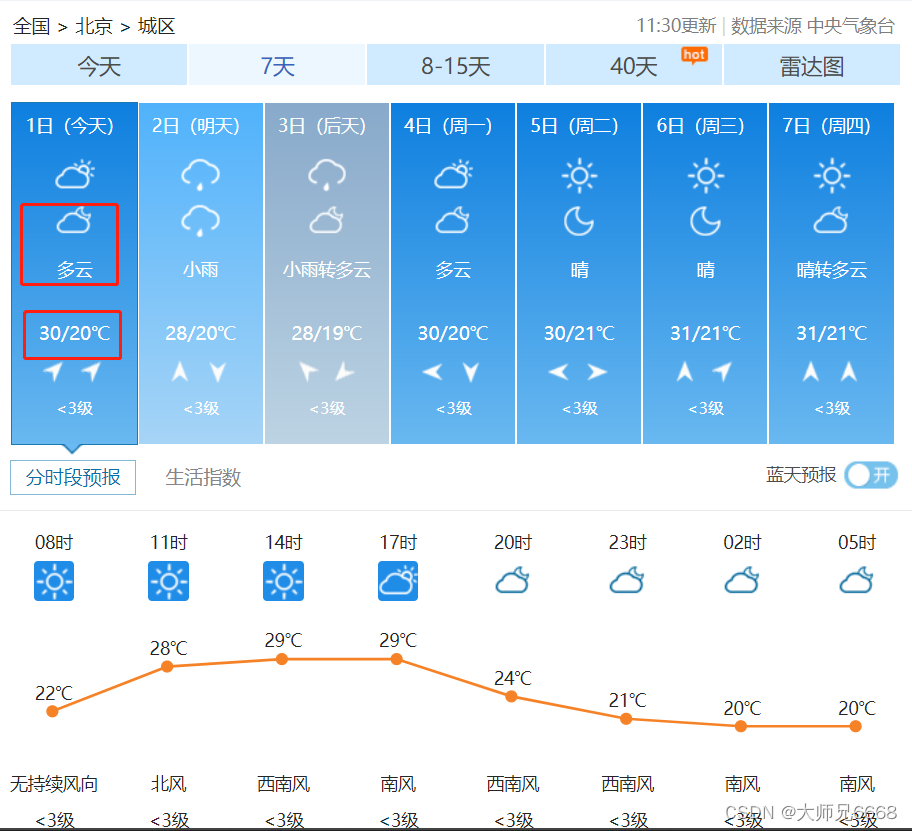
我要爬取的是北京9.1日的天气,即下图中的“30/20℃”和“多云”两个数据:
很自然地,我们点击"右键"——“检查”——“Network”,刷新页面,点看第0个请求:
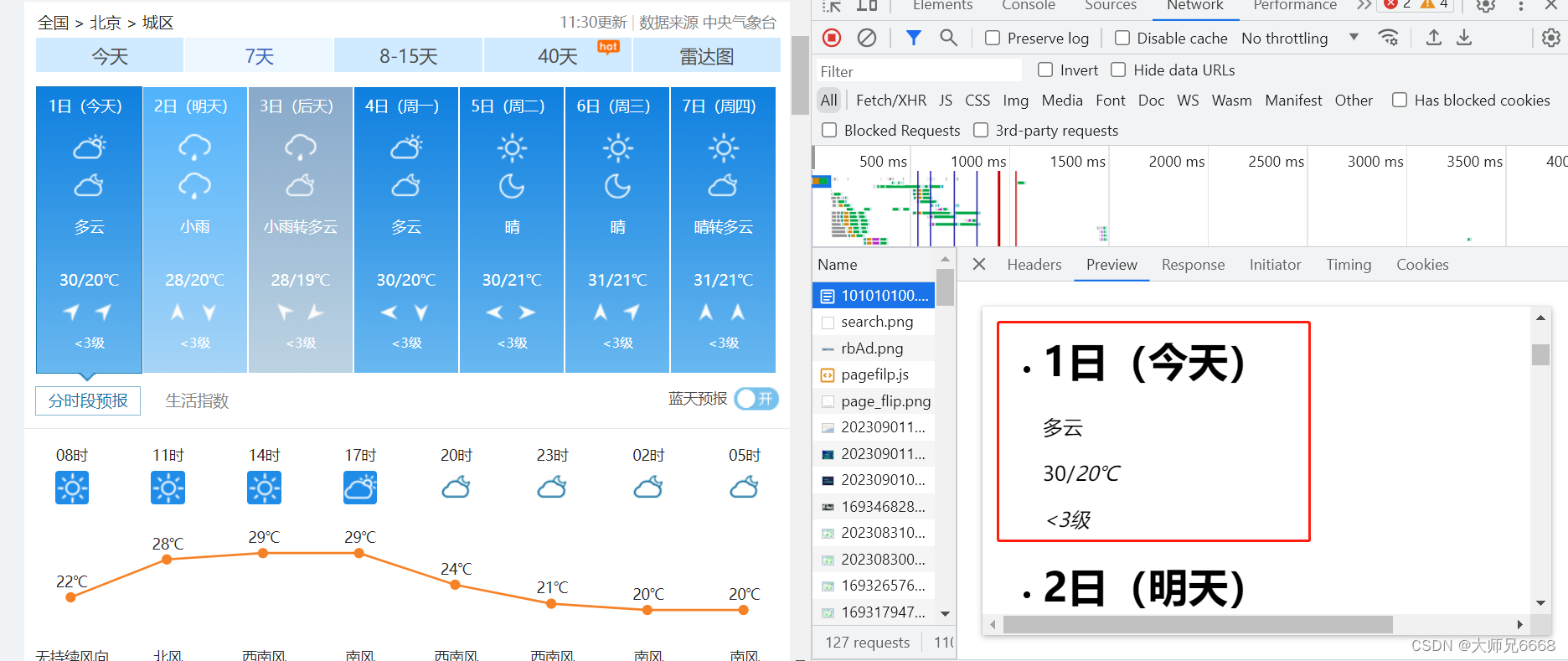
数据放在HTML里,没问题。那我们点击Elements:
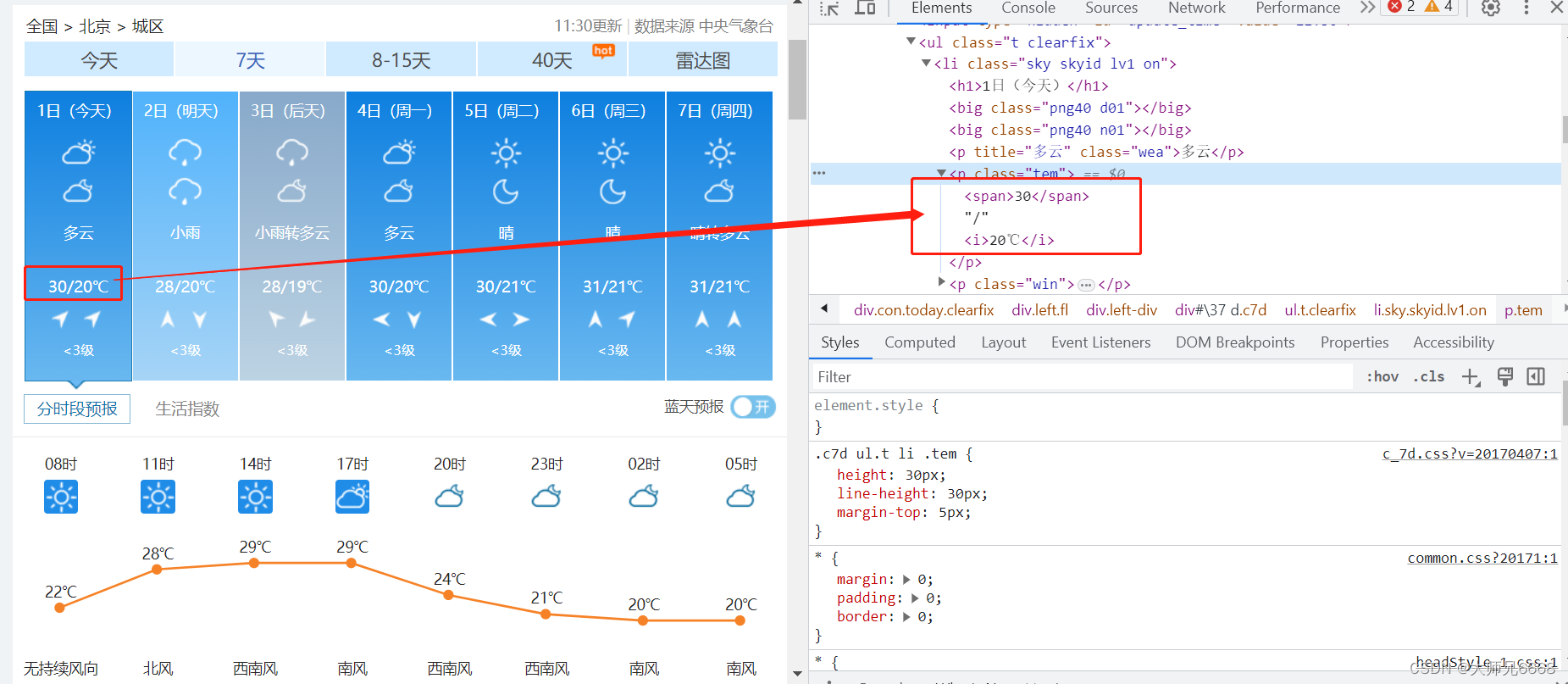
可以发现,温度数据放在<p class="tem">之下。
同样,可以发现“多云”这个数据所在的位置:
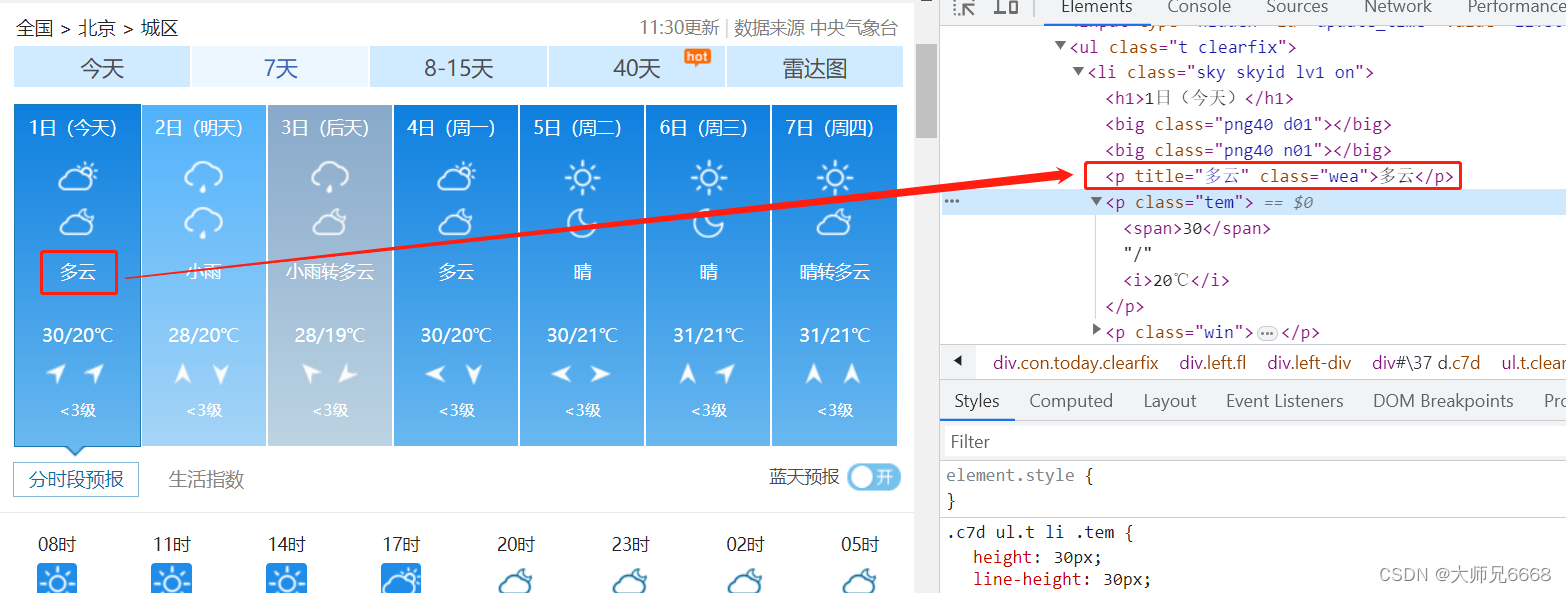
在网页源代码里面搜索观察了一番,发现可以使用class="wea"和class="tem"来匹配目标数据。
分析完成,请你阅读代码,然后点击运行:
import requests
from bs4 import BeautifulSoup
#引入requests库和BeautifulSoup库
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
#封装headers
url='http://www.weather.com.cn/weather/101010100.shtml'
#把URL链接赋值到变量url上。
res=requests.get(url,headers=headers)
#发送requests请求,并把响应的内容赋值到变量res中。
print(res.status_code)
#检查响应状态是否正常
print(res.text)
#打印出res对象的网页源代码
运行结果返回的是200,证明状态是正常的,再来看看网页源代码,滑动看看:
等等,好像出现了一些奇怪的东西…(⊙o⊙)噢,是乱码,这意味着出现了编码问题。
不过还好,我们在第1关就知道碰到编码可以怎么解决,用response.encoding属性就好。好滴,那我们在网页上点击"右键"——“查看网页源代码”,会弹出一个新的标签页,然后搜索charset,查看一下编码方式。
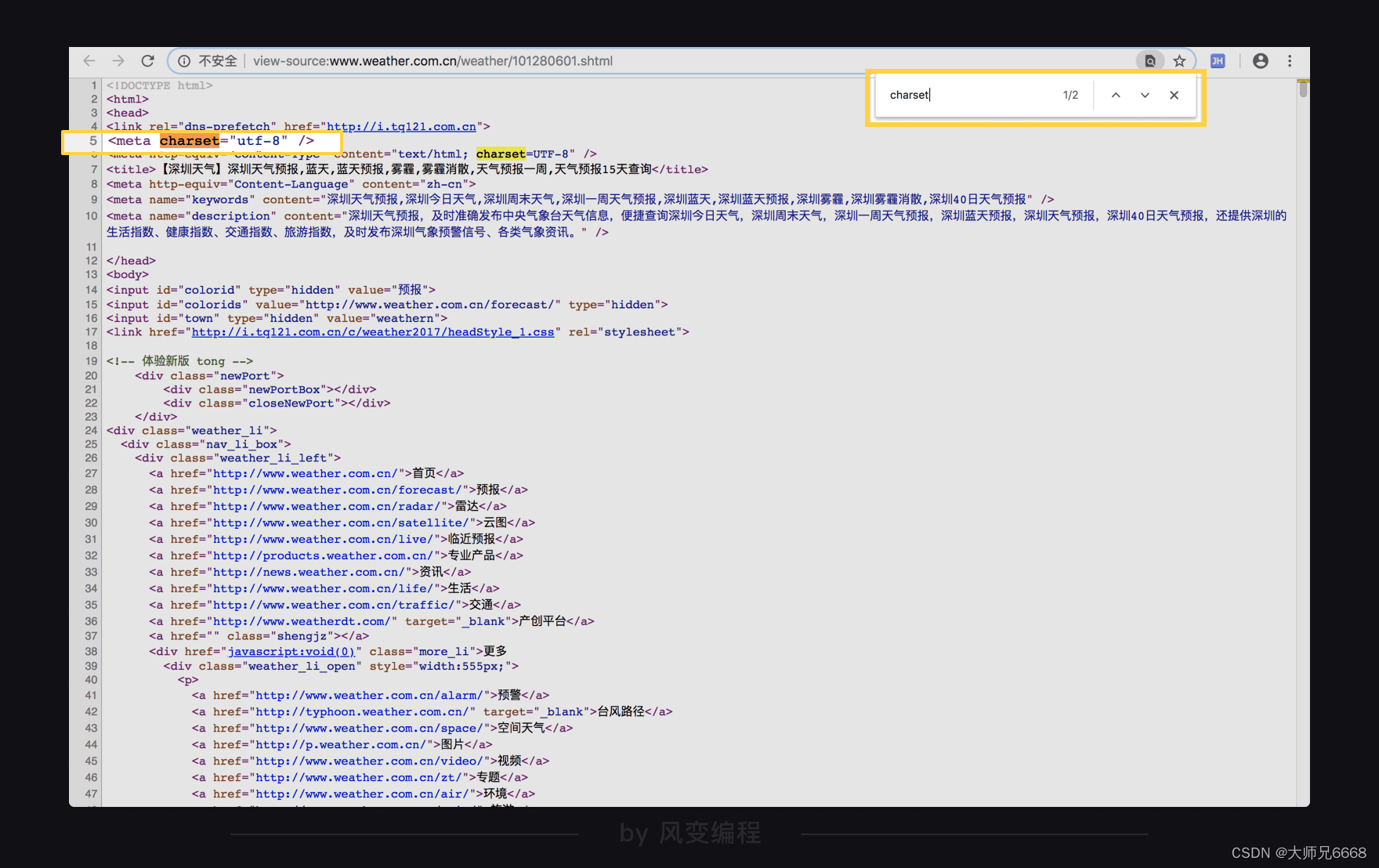
噢,网页是用utf-8编码的。
那么只要用response.encoding转换一下编码就可以了,请你来写一写代码,定义Response对象的编码,还有检查请求的结果,并且打印网页源代码:
参考答案:
import requests
from bs4 import BeautifulSoup
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='http://www.weather.com.cn/weather/101010100.shtml'
res=requests.get(url,headers=headers)
res.encoding='utf-8'
print(res.status_code)
print(res.text)
这次没问题了哟。😄
接下来,就可以用BeautifulSoup模块解析和提取数据了,请你继续写完代码:
参考代码在这里:
import requests
from bs4 import BeautifulSoup
#引入requests库和BeautifulSoup库
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
#封装headers
url='http://www.weather.com.cn/weather/101010100.shtml'
#把URL链接赋值到变量url上。
res=requests.get(url,headers=headers)
#发送requests请求,并把响应的内容赋值到变量res中。
#用utf-8 来解析代码
res.encoding='utf-8'
bsdata=BeautifulSoup(res.text,'html.parser')
#使用bs模块解析获取到的数据
data1= bsdata.find(class_='tem')
#使用find()取出天气的温度数据
data2= bsdata.find(class_='wea')
#使用find()取出天气的文字描述
print(data1.text)
#取出变量data1中的字符串内容,并打印
print(data2.text)
#取出变量data2中的字符串内容,并打印
搞定啦(≧▽≦)/啦啦啦。
当然,每个人所在的地区都不一样,所以你要选择好你所在地区的天气网址来替换这段代码中的URL。
接下来,就可以进入到通知功能,我们选择的是用邮件来发送爬虫结果。
事实上,在基础课部分,有对发送邮件的教学。如果同学们上过基础课,并且对相关知识十分有把握的话,可以选择跳过,直接学习下面的定时模块;如果自己有点忘记的话,也可以选择复习一下。
发送邮件
进入到邮件功能部分的学习,先来模仿一下平时我们发邮件时计算机的操作:

我们的代码逻辑也会按照上图来进行,并且在其中用到两个库——smtplib和email。
以qq邮箱为例,先来看第0步:连接服务器。
连接服务器需要用到smtplib库。为什么叫这个名字呢?其实,SMTP代表简单邮件传输协议,相当于一种计算机之间发邮件的约定。
好,来看下具体怎么用smtplib库来连接服务器:
import smtplib
#smtplib是python的一个内置库,所以不需要用pip安装
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址需要是字符串的格式。
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以使用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
解释一下:第1行代码是引入库,第3行代码是qq邮箱的服务器地址,这个地址是可以通过搜索引擎查到的。
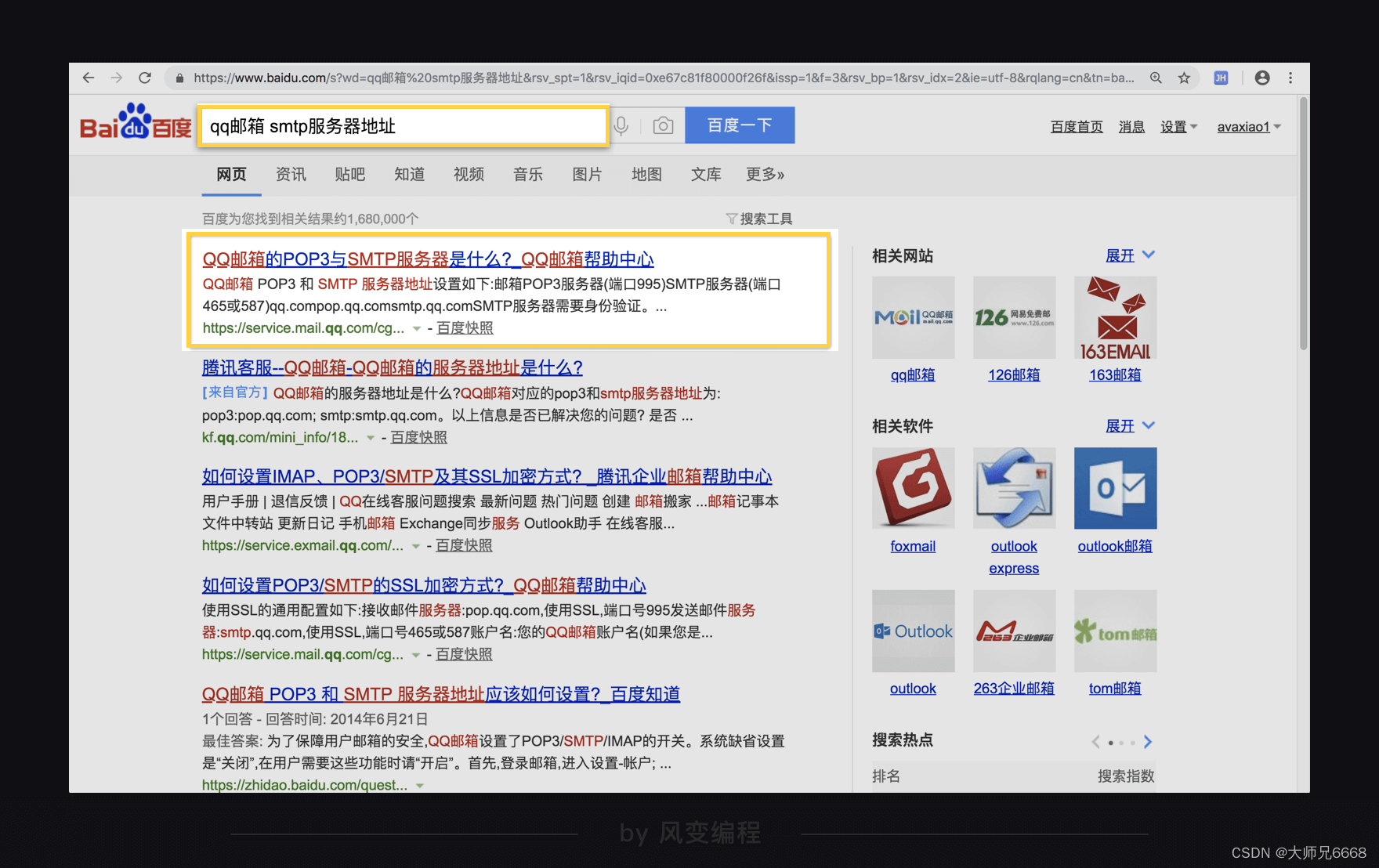
点进去第一个网址:
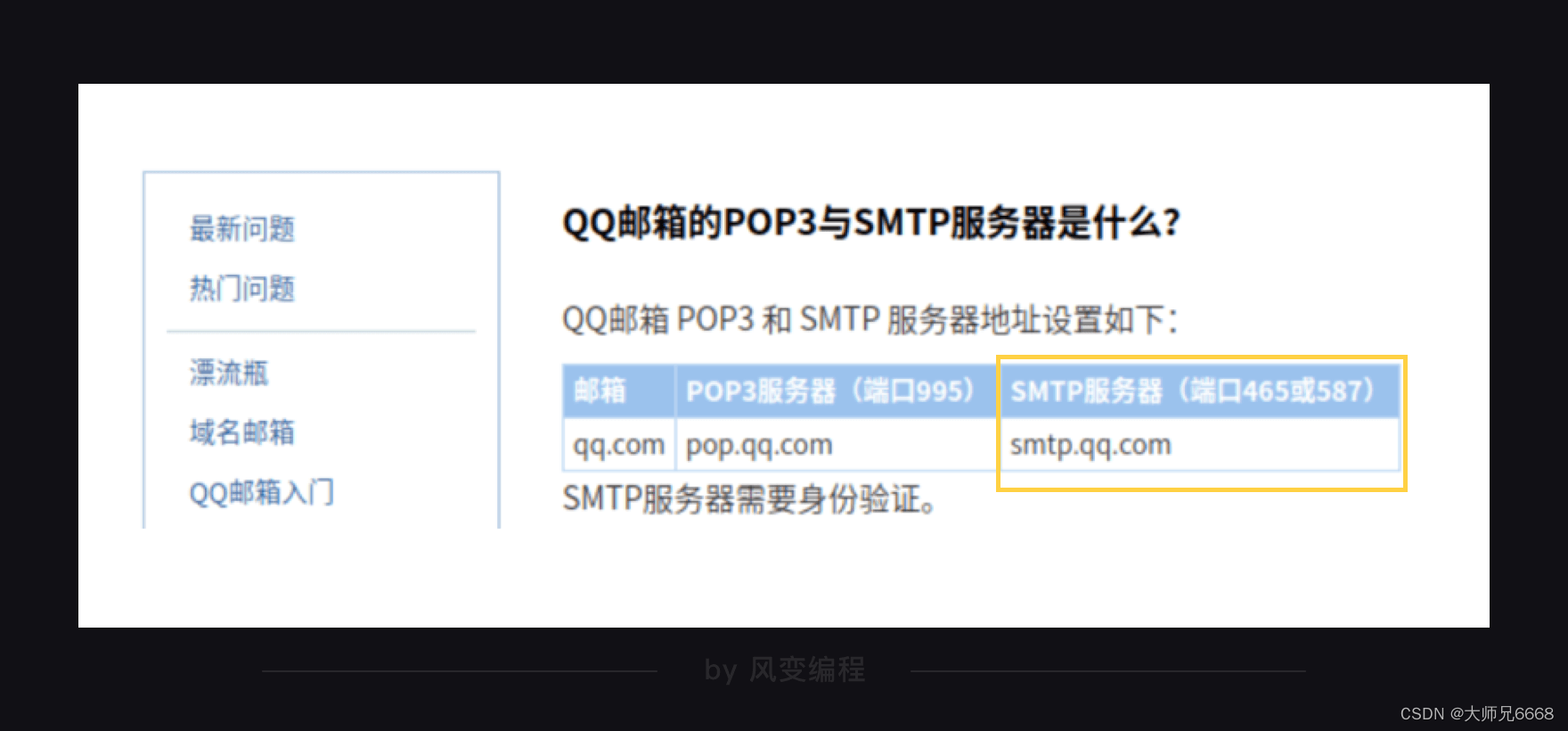
这样就拿到了qq邮箱的smtp地址。此刻,我们用的是qq邮箱,所以搜索qq邮箱的smtp服务器地址,如果你之后想用网易邮箱,也可以搜索网易邮箱的smtp服务器地址。
继续看代码的第5行:
import smtplib
#smtplib是python的一个内置模块,所以不需要用pip安装
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址需要是字符串的格式。
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
第5行代码是实例化了一个smtplib里的SMTP对象。
第7行代码是用SMTP对象的connect()方法连接服务器,第一个参数是获取到的服务器地址,第二个参数是SMTP端口号——25。
端口号的选择不是唯一的,但是25是一个最简单、最基础的端口号,所以我们填25。
连接服务器就讲完了,马上来看第1和第2步:通过账号和密码登录邮箱;填写收件人。

来看登录邮箱的代码(第11行为新增代码):
import smtplib
#smtplib是python的一个内置库,所以不需要用pip安装
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器的代码
account = input('请输入你的邮箱:')
#获取邮箱账号
password = input('请输入你的密码:')
#获取邮箱密码
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱
解释一下从11行新增的代码:第11行是用input()获取邮箱账号。第13行是用input()获取邮箱密码,但注意了,这里可不是你平时登录邮箱的密码!
这个密码需要我们去到这里获取:请打开https://mail.qq.com/,登录你的邮箱。然后点击位于顶部的【设置】按钮,选择【账户设置】,然后下拉到这个位置。

就像上面的一样,把首个SMTP服务开启。这时,QQ邮箱会提供给你一个授权码,注意保护好你的授权码:
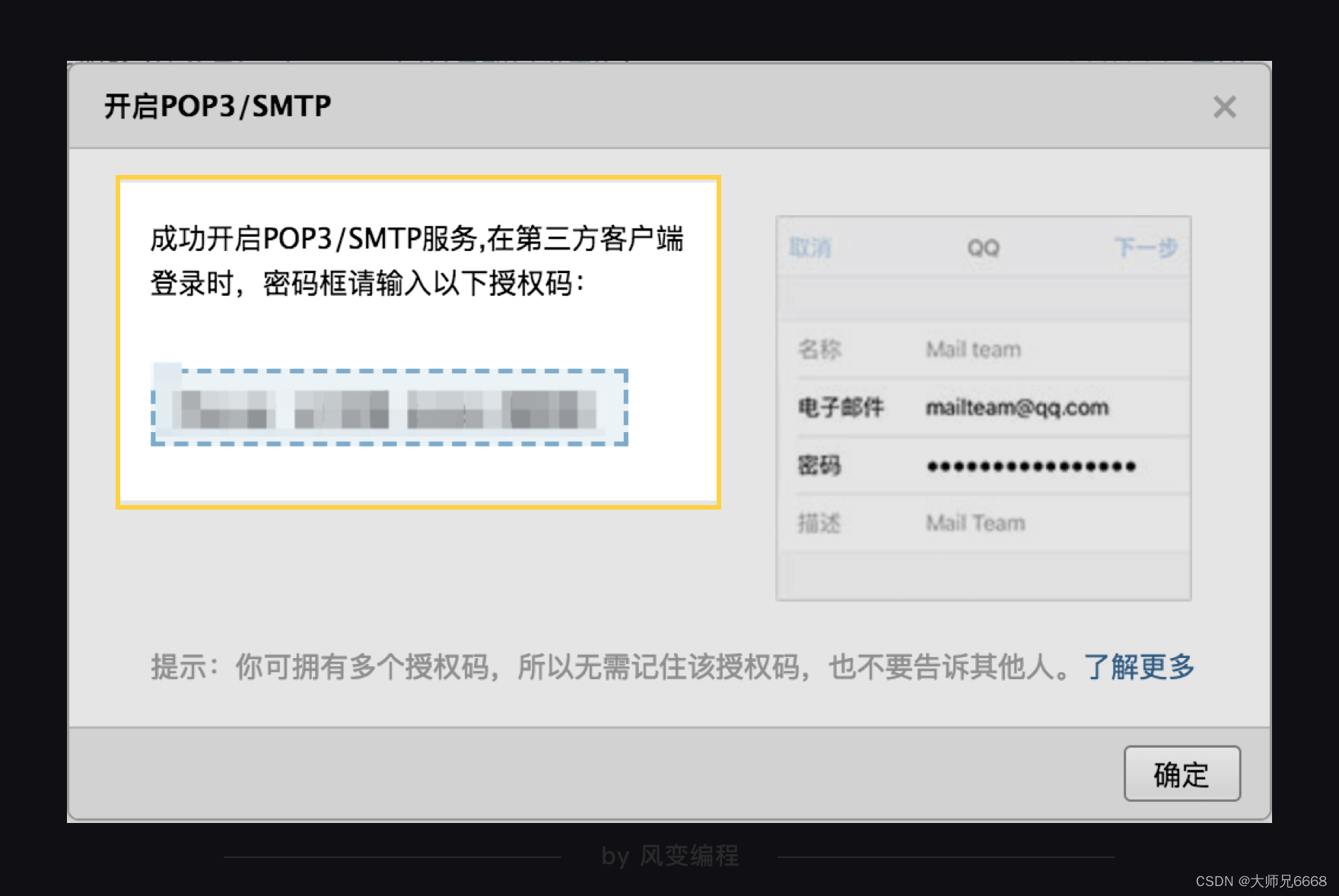
接下来,在你使用SMTP服务登录邮箱时,就可以输入这个授权码作为密码登录了。
然后看上面第18行代码,就是获取收件人的邮箱,没有太多可说的。
至此,第1步和第2步都完成了。

继续看第3步和第4步:填写主题和撰写正文,在这里需要用到email库。
来看用法:
from email.mime.text import MIMEText
from email.header import Header
#引入Header和MIMEText模块
content=input('请输入邮件正文:')
#输入你的邮件正文
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码.
subject = input('请输入你的邮件主题:')
#用input()获取邮件主题
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边,是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
解释一下:第1行和第2行代码是引入了email库中的MIMEText模块和Header模块。
第4行代码是用input()函数获取邮件正文,第6行代码是实例化一个MIMEText的邮件对象,这样我们就构造了一个纯文本邮件了。
这个MIMEText对象有三个参数,一个是邮件正文;另一个是文本格式,一般设置为plain纯文本格式;最后一个是编码,设置为utf-8,因为utf-8是最流行的万国码。
继续看第8行代码,是用input()函数获取邮件主题,第10行代码比较重要,我们仔细讲解一下:message[‘Subject’] = Header(subject, ‘utf-8’)
等号右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码。
等号左边的message[‘Subject’]的变量是一个a[‘b’]的代码形式,它长得特别像字典根据键取值的表达,但是这里的message是一个MIMEText类的对象,并不是一个字典,那message[‘Subject’]是什么意思呢?
其实,字典和类在结构上,有相似之处。请看下图:
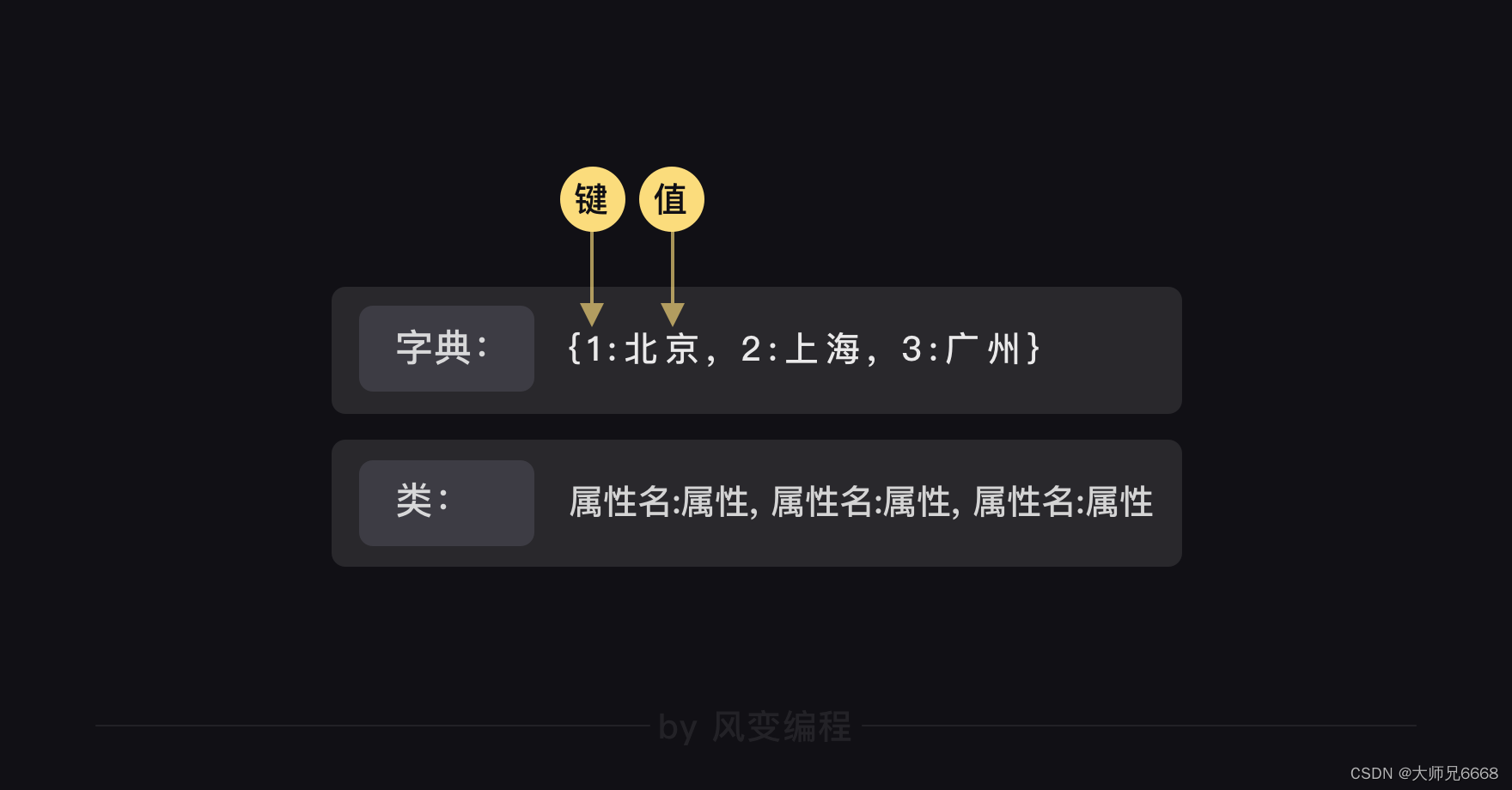
字典里面的元素是【键】和【值】一一对应,而类里面的【属性名】和【属性】也是一一对应的。我们可以根据字典里的【键】取到对应的【值】,同样的,也可以根据类里面的【属性名】取到【属性】。
所以message[‘Subject’]就代表着根据MIMEText类里面的Subject的属性名取到该属性。
需要注意的是,不是每一个类都可以这样访问其属性的,之所以能这样访问是因为这个MIMEText的类实现了这个功能。
所以,message[‘Subject’] = Header(subject, ‘utf-8’) 就是在为message[‘Subject’]这个属性赋值。
好啦,到现在,我们就明白如何填写主题和撰写正文了。

接下来就是最后两步:发送邮件和退出邮箱了。
来看代码(从33行开始看):
import smtplib
#smtplib是python的一个内置库,所以不需要用pip安装
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器的代码
account = input('请输入你的邮箱:')
#获取邮箱账号
password = input('请输入你的密码:')
#获取邮箱密码
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱
from email.mime.text import MIMEText
from email.header import Header
#引入Header和MIMEText模块
content=input('请输入邮件正文:')
#输入你的邮件正文
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码.
subject = input('请输入你的邮件主题:')
#用input()获取邮件主题
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边,是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
qqmail.sendmail(account, receiver, message.as_string())
#发送邮件,调用了sendmail()方法,写入三个参数,分别是发件人,收件人,和字符串格式的正文。
qqmail.quit()
#退出邮箱
解释一下:第33行代码的意思是调用sendmail()发送邮件,括号里面有三个参数,第0个是发件人的邮箱地址,第1个是收件人的邮箱地址,第2个是正文,但必须是字符串格式,所以用as_string()函数转换了一下。
但是我们希望发送成功后能显示“邮件发送成功”,失败的时候能提示我们“邮件发送失败”,可以使用try语句来实现。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
到此,发送邮件的程序就完成了,一起看看完整的代码。
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMEText和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
关于如何用Python发送邮件,就讲到这里。
考虑到信息的安全问题,一定不要将你的邮箱账号和密码写在代码中发布到网上!!!
另外,更多的功能(比如发送附件等)同学们可以在课外主动学习。😁
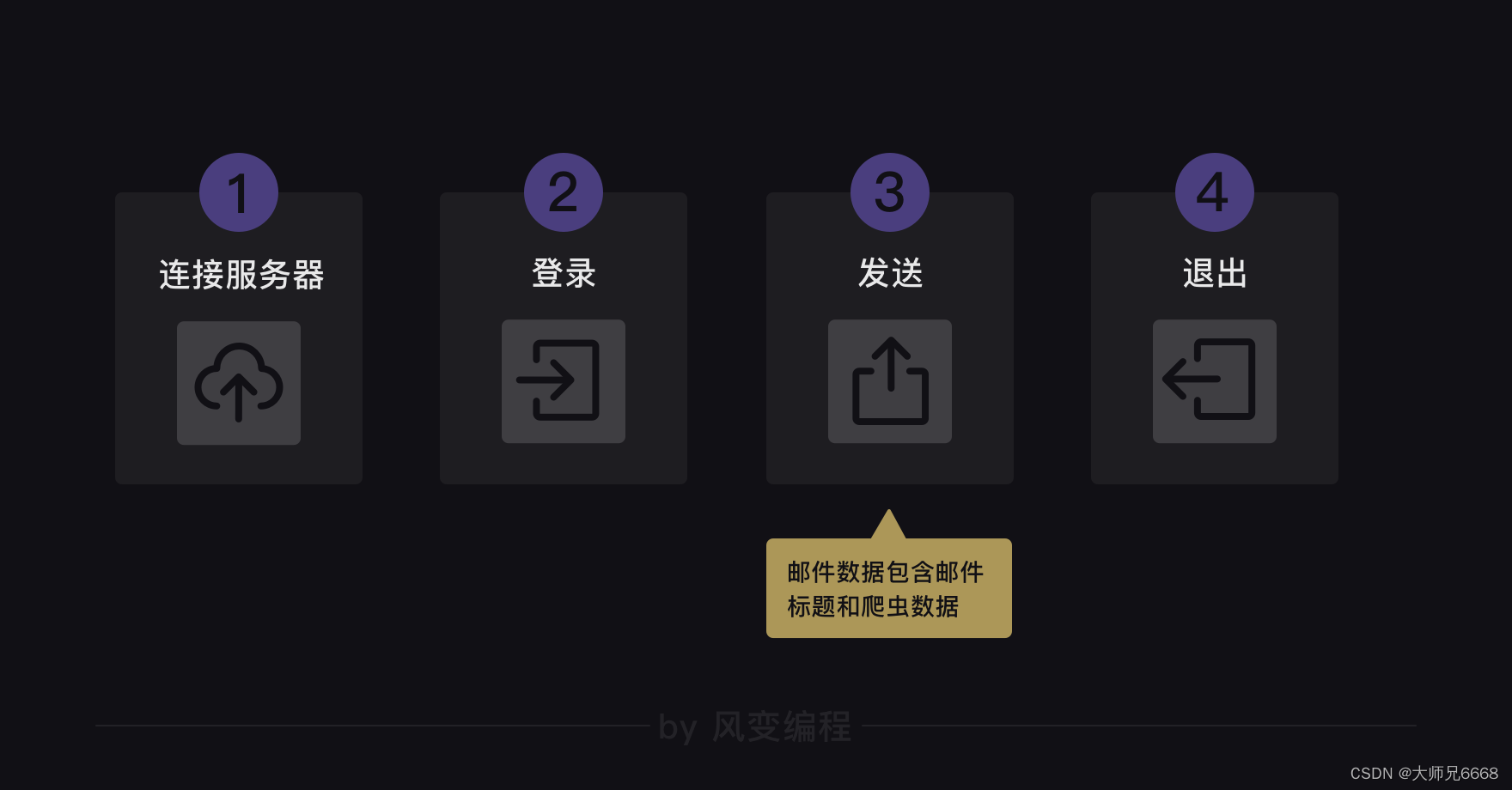
好,我们可以再次试着梳理一下刚刚的流程:
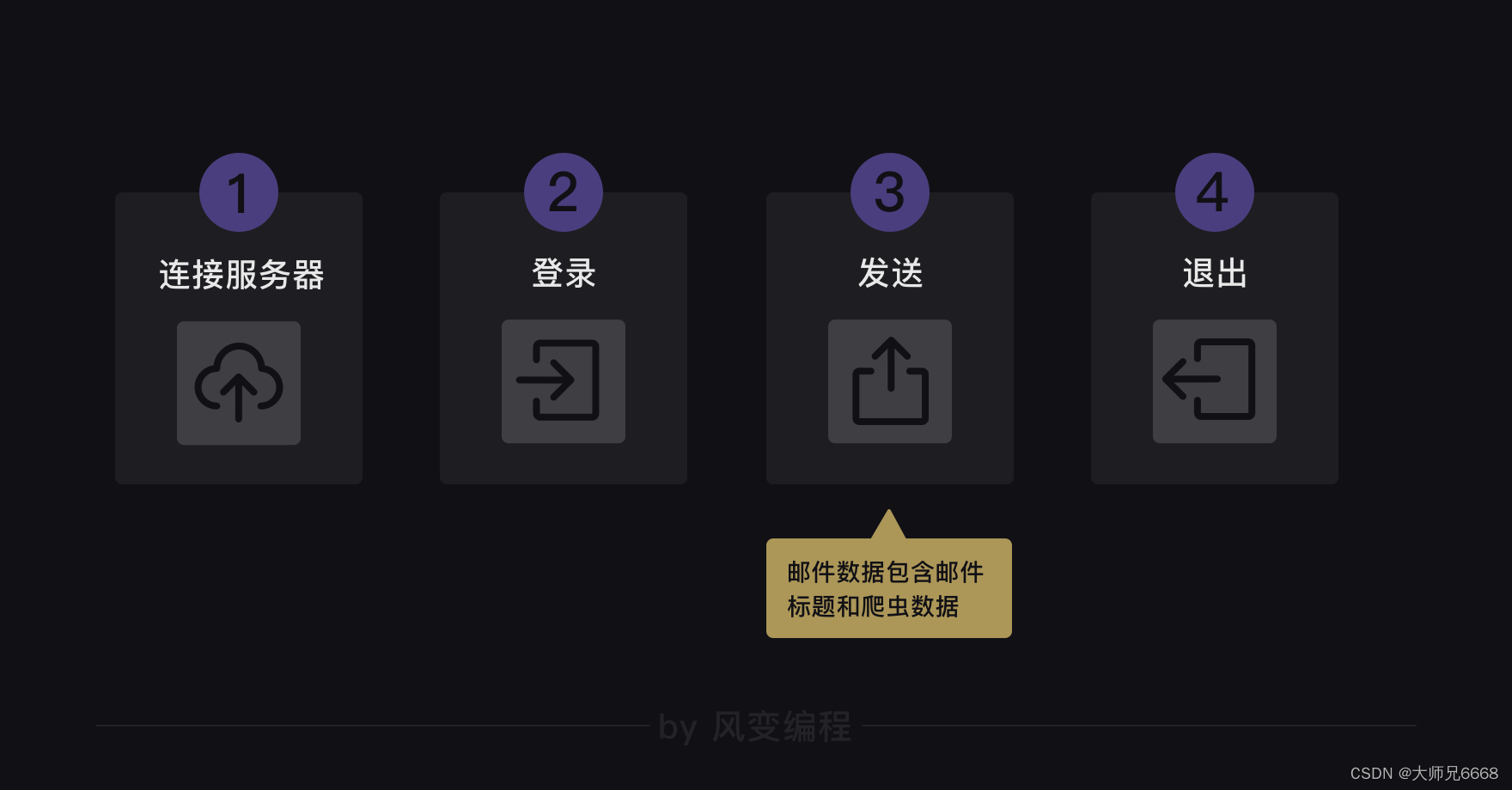
首先是连接服务器和登录,然后就是发送,发送的内容是邮件数据。邮件数据由两部分构成,一部分是邮件的主题,一部分是邮件的正文(即爬虫获取到的数据)。
当然,发送的动作里必须填写收件人,发送完毕后就可以退出邮箱了。
而smtplib库主要负责的是横向的连接服务器、登录、发送和退出;而email库主要负责的是邮件主题和正文。
好,现在,咱们来看看如何实现爬虫的定时功能。
定时
关于时间,其实Python有两个内置的标准库——time和datetime(我们在基础课也学过time.sleep())。
但在这里,我们不准备完全依靠标准库来实现,而准备选取第三方库——schedule。
原因在于:标准库一般意味着最原始最基础的功能,第三方库很多是去调用标准库中封装好了的操作函数。比如schedule,就是用time和datetime来实现的。
而对于我们需要的定时功能,time和datetime当然能实现,但操作逻辑会相对复杂;而schedule就是可以直接解决定时功能,代码比较简单,这是我们选择schedule的原因。
这并不意味着time和datetime比schedule差,只是这个项目场景下,我们倾向于调用schedule。
马上来看代码,官方文档上的代码也很简洁,你可以先尝试着自己阅读一下,思考后点击enter继续:
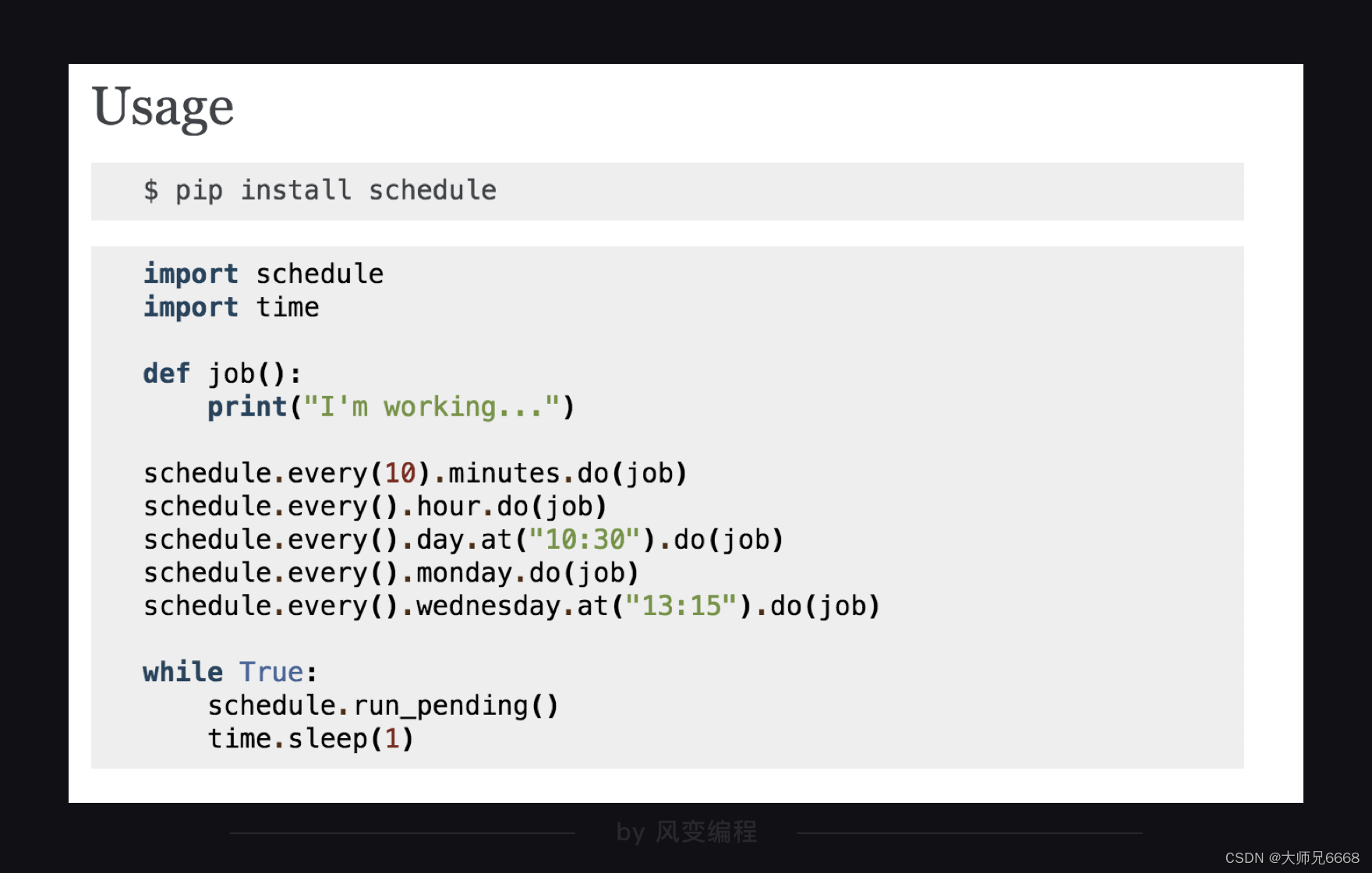
最上面的一行很好理解,因为是第三方库,所以需要安装。下面的代码我们放到代码框里好好研究一下:
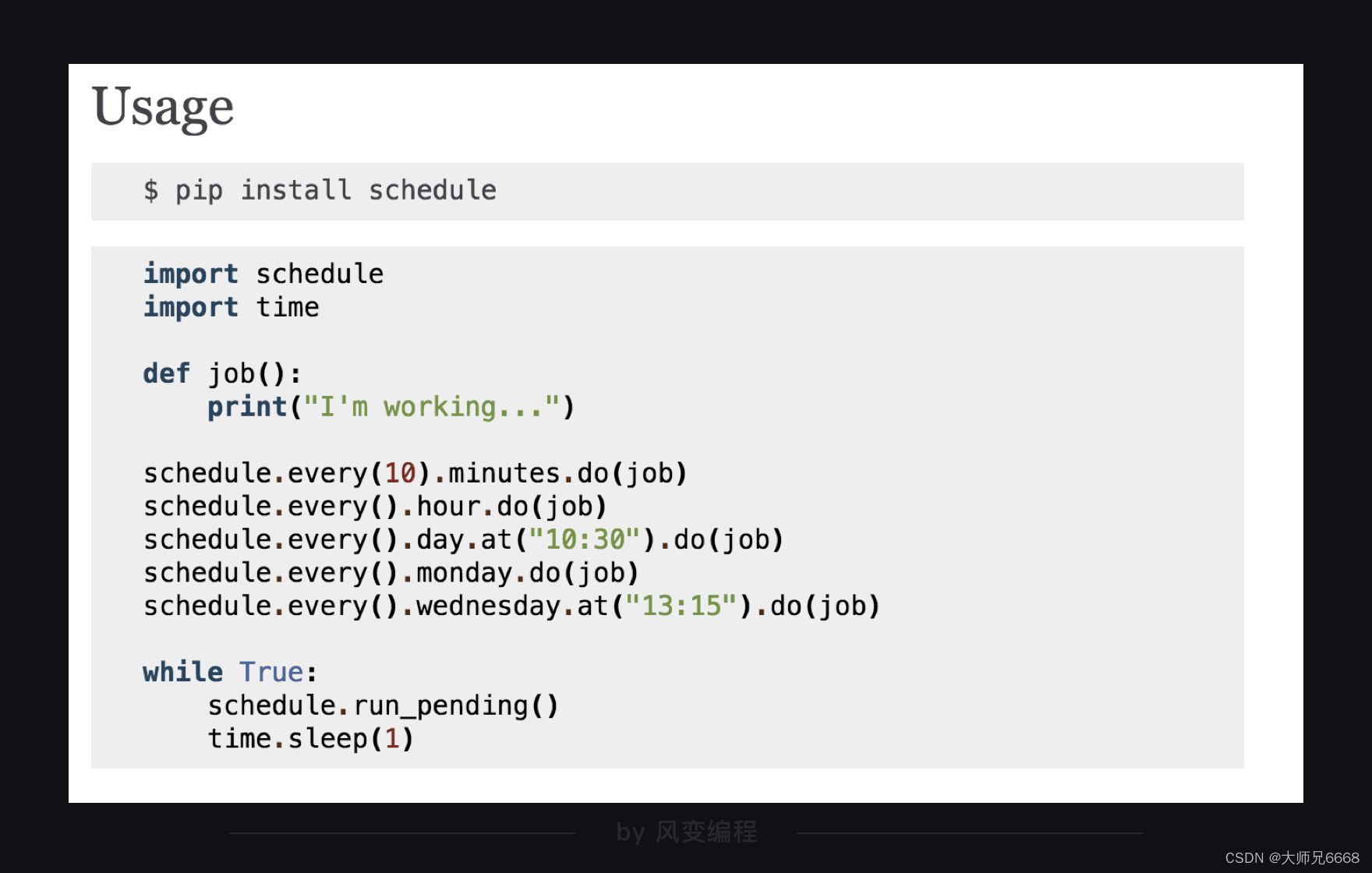
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
第1行和第2行,是引入schedule和time。
第5行和第6行,是定义了一个叫job()的函数,调用这个函数时,函数会打印I’m working…。
第9行-13行都是相关的时间设置,你可以根据自己的需要来确定。
第15-17行是一个while循环,是去检查上面的任务部署情况,如果任务已经准备就绪,就去启动执行。其中,第17行的time.sleep(1)是让程序按秒来检查,如果检查太快,会浪费计算机的资源。
其实,就算不懂具体的代码什么意思,我们先试着来用,发现诶,成功了,再去研究,也是不错的。
为了展示一下schedule的作用,我们看下面这段代码:是每两秒就运行job()函数。
import schedule
import time
#引入schedule和time模块
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(2).seconds.do(job) #每2s执行一次job()函数
while True:
schedule.run_pending()
time.sleep(1)
运行结果:

好啦,定时功能我们也都搞定了。也就是说,第二步分析过程,我们也搞定了。
代码组装
因为刚刚在分析过程里面,就已经分别搞定了三段程序,所以在这一部分,只要组合起来就好啦。
我们一个一个功能来封装,首先是爬虫的代码,封装前的代码是这样的:
import requests
from bs4 import BeautifulSoup
#引入requests库和BeautifulSoup库
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
#封装headers
url='http://www.weather.com.cn/weather/101010100.shtml'
#把URL链接赋值到变量url上。
res=requests.get(url,headers=headers)
#发送requests请求,并把响应的内容赋值到变量res中。
#用utf-8 来解析代码
res.encoding='utf-8'
bsdata=BeautifulSoup(res.text,'html.parser')
#使用bs模块解析获取到的数据
data1= bsdata.find(class_='tem')
#使用find()取出天气的温度数据
data2= bsdata.find(class_='wea')
#使用find()取出天气的文字描述
print(data1.text)
#取出变量data1中的字符串内容,并打印
print(data2.text)
#取出变量data2中的字符串内容,并打印
想请你来试着封装一下:请你把已有的爬取天气数据的代码,封装成一个函数。
参考答案是这样的:
import requests
from bs4 import BeautifulSoup
def weather_spider():
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='http://www.weather.com.cn/weather/101010100.shtml'
res=requests.get(url,headers=headers)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
data1= soup.find(class_='tem')
data2= soup.find(class_='wea')
tem=data1.text
weather=data2.text
return tem,weather
第4行代码:定义这个函数叫weather_spider();第14行代码:设置函数返回的变量是tem和weather。其他代码都是和封装前一致的。
接着是邮件的程序,封装前的代码是这样的:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
mailhost='smtp.qq.com'
qqmail = smtplib.SMTP()
qqmail.connect(mailhost,25)
account = input('请输入你的邮箱:')
password = input('请输入你的密码:')
qqmail.login(account,password)
receiver=input('请输入收件人的邮箱:')
content=input('请输入邮件正文:')
message = MIMEText(content, 'plain', 'utf-8')
subject = input('请输入你的邮件主题:')
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
请你自己先试着封装一下,再次提醒一下,封装好函数即可,注意:不要调用和运行这个函数。
参考答案是这样的:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
account = input('请输入你的邮箱:')
password = input('请输入你的密码:')
receiver = input('请输入收件人的邮箱:')
def send_email(tem,weather):
mailhost='smtp.qq.com'
qqmail = smtplib.SMTP()
qqmail.connect(mailhost,25)
qqmail.login(account,password)
content= '亲爱的,今天的天气是:'+tem+weather
message = MIMEText(content, 'plain', 'utf-8')
subject = '今日天气预报'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
看第5-7行:定义account、password和receiver为全局变量,即用input()获取到的数据。
第9行:定义了函数的名字叫send_email(),定义了两个参数tem和weather。当然,等下需要把爬虫获取到的温度信息和天气信息传递给该函数的参数。
第14行:是把邮件正文写为天气数据。其他代码基本一致。
好现在只剩定时功能了,可以和上面两个程序组合在一块儿了。
import requests
import smtplib
import schedule
import time
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header
account = input('请输入你的邮箱:')
password = input('请输入你的密码:')
receiver = input('请输入收件人的邮箱:')
def weather_spider():
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='http://www.weather.com.cn/weather/101010100.shtml'
res=requests.get(url,headers=headers)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
tem1= soup.find(class_='tem')
weather1= soup.find(class_='wea')
tem=tem1.text
weather=weather1.text
return tem,weather
def send_email(tem,weather):
mailhost='smtp.qq.com'
qqmail = smtplib.SMTP()
qqmail.connect(mailhost,25)
qqmail.login(account,password)
content= tem+weather
message = MIMEText(content, 'plain', 'utf-8')
subject = '今日天气预报'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
def job():
print('开始一次任务')
tem,weather = weather_spider()
send_email(tem,weather)
print('任务完成')
schedule.every().day.at("07:30").do(job)
while True:
schedule.run_pending()
time.sleep(1)
这段代码比较长,不着急,我们慢慢地看哈。
第1-7行是把所有引入都放到程序的顶部;从9-11行,把获取数据也放到函数的外面;然后13-39行,我们都讲过了。
从41行开始,定义一个函数叫job();42行是打印’开始一次任务’,为了记录和显示任务的开始。
第43行,是调用爬虫函数weather_spider(),然后把这个函数内部return的两个变量tem、weather赋值给job()函数里面的变量tem,weather;第44行是调用函数send_email(),并且把参数传入。
第45行打印’任务完成’,表示这部分程序运行正常。
47-50行都是定时功能我们见过的函数,我们设定的是每天早上七点半把天气信息传递给收件人。
好啦,代码我们就组装完毕啦~~(≧▽≦)/~里面还是有很多小细节的,强烈建议学完后你自己再写一遍。
复习
关于邮件,它是这样一种流程:

我们要用到smtplib和email库,前者负责连接服务器、登录、发送和退出的流程。后者负责邮件的标题与正文。
最后一个示例代码,是这个模样:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMEText和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
对于定时,我们选取了schedule模块,它的用法非常简洁,官方文档里是这样讲述:
下面的代码是示例:
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
到此,这一关的任务就圆满完成了,我们学习了用Python发邮件,用Python定时执行一个程序,并且完成了一个每日爬取天气并把结果发送到邮箱的程序。给你比个大拇哥。
不过,老师有个小小的提醒,如果你想要明早真正收到天气信息的话,需要做两件事:
首先,让该程序在本地电脑运行,而不是在课程系统里运行,因为课程的系统是会销毁程序的进程的。
其次,保持程序一直运行的状态,和电脑在一直开机的状态。因为如果程序结束或者电脑关机了的话,就不会定时爬取天气信息了。
事实上,在程序员真实的开发环境中,程序一般都会挂在远端服务器,因为远端服务器24小时都不会关机,就能保证定时功能的有效性了。如果你也想让程序挂在远端服务器的话,需要自己去做一些额外的学习。
好啦,这一关就完成啦。下一关,我们会学习一个新技能——协程。它能够成倍提高我们的代码运行速度,当你遇到海量数据抓取的任务时,它能够为你提供有力的帮助。
我们下一关见!