知识图谱可以帮助机器理解世界,提高人工智能模型的性能。它还可以用于数据挖掘、信息检索、问答系统和语义搜索等领域,提高系统的准确性和可理解性。知识图谱的建模方式和技术也可以用于生物信息学和社交网络分析等领域。
知识图谱背景
在给出知识图谱的定义之前,我们先分开讨论一下什么是知识,什么是图谱。
什么是知识
首先看一下什么是知识。有读者可能会提出这样的问题,在大数据时代,人类拥有海量的数据,这是不是代表人类可以随时随地利用无穷无尽的知识呢?答案是否定的。
知识是人类在实践中认识客观世界(包括人类自身)的成果,它包括事实、信息、描述以及在教育和实践中获得的技能。知识是人类从各个途径中获得的经过提升、总结与凝炼的系统的认识。
因此,可以这样理解,知识是人类对信息进行处理之后的认识和理解,是对数据和信息的凝炼、总结后的成果。
举一个简单的例子,226.1厘米,229厘米,都是客观存在的孤立的数据。此时,数据不具有任何意义,仅表达一个客观事实。而“姚明臂展226.1厘米”“姚明身高229厘米”是事实型的陈述,属于信息的范畴。
知识,则是对信息层面的抽象和归纳,把姚明的身高、臂展,及其他属性整合起来,就得到了对于姚明的一个认知,也可以进一步了解到姚明的身高是比普通人高的。
什么是图谱
那么什么是图谱?图谱的英文是Graph,直译过来就是“图”的意思。在图论(数学的一个研究分支)中,图表示一些事物(Object)与另一些事物之间相互连接的结构。
一张图通常由一些结点(Vertice或Node)和连接这些结点的边(Edge)组成。“图”这一名词是由詹姆斯·约瑟夫·西尔维斯特在1878年首次提出的。下图是一个非常简单的图,它由6个结点和7条边组成。
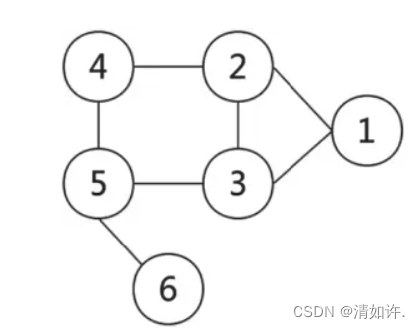
从字面上看,知识图谱就是用图的形式将知识表示出来。图中的结点代表语义实体或概念,边代表结点间的各种语义关系。
我们再将姚明的一些基本信息,用计算机所能理解的语言表示出来,构建一个简单的知识图谱。比如,<姚明,国籍,中国>表示姚明的国籍是中国,其中“姚明”和“中国”是两个结点,而结点间的关系是“国籍”。
这是一种常用的基于符号的知识表示方式——资源描述框架(Resource Description Framework,RDF),它把知识表示为一个包含主语(Subject)、谓语(Predicate)和宾语(Object)的三元组<S,P,O>。
语义网络由剑桥语言研究所的Richard H. Richens提出,前文中已经简单介绍了语义网络的含义。它是一种基于图的数据结构,是一种知识表示的手段,可以很方便地将自然语言转化为图来表示和存储,并应用在自然语言处理问题上,例如机器翻译、问答等。
到了20世纪80年代,研究人员将哲学概念本体(Ontology)引入计算机领域,作为“概念和关系的形式化描述”, 后来,Ontology也被用于为知识图谱定义知识体系(Schema)。
而真正对知识图谱产生深远影响的是Web的诞生。Tim Berners-Lee在1989年发表的“Information Management: A Proposal”[4]中提出了Web的愿景, Web应该是一个以“链接”为中心的信息系统(Linked Information System),以图的方式相互关联。
Tim认为“以链接为中心“和“基于图的方式”,相比基于树的固定层次化组织方式更加有用,从而促成了万维网的诞生。我们可以这样理解,在Web中,每一个网页就是一个结点,网页中的超链接就是边。但其局限性是显而易见的,比如,超链接只能说明两个网页是相互关联的,而无法表达更多信息。
1994年,在第一届国际万维网大会上,Tim又指出,人们搜索的并不是页面,而是数据或事物本身,由于机器无法有效地从网页中识别语义信息,因此仅仅建立Web页面之间的链接是不够的,还应该构建对象、概念、事物或数据之间的链接。
随后在1998年,Tim正式提出语义网(Semantic Web)的概念。语义网是一种数据互连的语义网络,它仍然基于图和链接的组织方式,但图中的结点不再是网页,而是实体。
通过为全球信息网上的文档添加“元数据”(Meta Data),让计算机能够轻松理解网页中的语义信息,从而使整个互联网成为一个通用的信息交换媒介。我们可以将语义网理解为知识的互联网(Web of Knowledge)或者事物的互联网(Web of Thing)。
2006年,Tim又提出了链接数据(Linked Data)的概念,进一步强调了数据之间的链接,而不仅仅是文本的数据化。后文还会介绍链接开放数据(Linked Open Data,LOD)项目,它也是为了实现Tim有关链接数据作为语义网的一种实现的设想。
随后在2012年,Google基于语义网中的一些理念进行了商业化实现,其提出的知识图谱概念也沿用至今。
可以看到,知识图谱的概念是和Web、自然语言处理(NLP)、知识表示(KR)、数据库(DB)、人工智能(AI)等密切相关的。 所以我们可以从以下几个角度去了解知识图谱。
-
从Web的角度来看,像建立文本之间的超链接一样,构建知识图谱需要建立数据之间的语义链接,并支持语义搜索,这样就改变了以前的信息检索方式,可以以更适合人类理解的语言来进行检索,并以图形化的形式呈现。
-
从NLP的角度来看,构建知识图谱需要了解如何从非结构化的文本中抽取语义和结构化数据。
-
从KR的角度来看,构建知识图谱需要了解如何利用计算机符号来表示和处理知识。
-
从AI的角度来看,构建知识图谱需要了解如何利用知识库来辅助理解人类语言,包括机器翻译问题的解决。
-
从DB的角度来看,构建知识图谱需要了解使用何种方式来存储知识。
由此看来,知识图谱技术是一个系统工程,需要综合利用各方面技术。国内的一些知名学者也给出了关于知识图谱的定义。这里简单列举了几个。
电子科技大学的刘峤教授给出的定义是:
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体–关系–实体”三元组,以及实体及其相关属性–值对,实体之间通过关系相互联结,构成网状的知识结构
清华大学的李涓子教授给出的定义是:
知识图谱以结构化的方式描述客观世界中概念、实体及其关系,将互联网的信息表示成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力
浙江大学的陈华钧教授对知识图谱的理解是:
知识图谱旨在建模、识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型,已经被广泛应用于搜索引擎、智能问答、语言理解、视觉场景理解、决策分析等领域。
东南大学的漆桂林教授给出的定义是:
知识图谱本质上是一种叫作语义网络的知识库,即一个具有有向图结构的知识库,其中图的结点代表实体或者概念,而图的边代表实体/概念之间的各种语义关系[7]。
当前,无论是学术界还是工业界,对知识图谱还没有一个唯一的定义,本文的重点也不在于给出理论上的精确定义,而是尝试从工程的角度,讲解如何构建有效的知识图谱。有一些常见概念,这里列举如下。
-
实体:对应一个语义本体,例如“姚明”“中国”等。
-
属性:描述一类实体的特性(例如“身高”:姚明的身高是229厘米)。
-
关系:对应语义本体之间的关系,将实体连接起来(例如“国籍”:姚明的国籍是中国)。
有些学者也将属性定义为关系,属于属性关系的一种。但本文将属性和关系作为两种不同的概念区别对待。
知识图谱的作用
知识结构化
把领域中异构的知识结构化,构建知识间关联。主要解决领域内数据分散在多个系统,数据多样、复杂,孤岛化,且单一数据价值不高的应用场景。很显然结构化的知识,天然的把领域知识做了显性化沉淀和关联。构建起来了一张图。可以利用原生图的特征,支撑数据的挖掘,分析。
主要应用
1).做关系发展,实体探索,借助于图可视化工具发现一些潜在信息,潜在的关联。利用这些信息,来辅助决策。主要涉及的技术点:1.前端ui设计,前端图渲染技术。结合业务需求的定制化图展示(出于业务分析目的,按一定的属性,类型等约束进行展示)2.路径查询,探索多个实体间的路径关系。典型的产品:天眼查
2).社团发现
发现一些相似的实体。广泛用于团伙发现,同类推荐场景。广泛用于金融行业反欺诈场景,社交推荐。主要技术点:社团搜索
3).追溯源头
将多方数据打通,基于图中的边做拓展,即可实现源头的追溯。
机器语言认知
知识图谱有丰富的语义关系,概念,属性,关系等这些语义关系可以很好的应用到nlp相关任务上,例如分词,短语理解,文本理解等任务上。通过知识图谱可以让机器能更好的去理解自然语言,进一步的更好的理解用户的意图,文本的含义。
主要应用:
1).基础nlp任务,例如分词,文本理解;
2).对用户画像数据,对各种标签数据做数据增强。
3).搜索,问答的意图理解,推荐的用户,物品的理解;
3.提供行业背景知识。做知识引导,解决问题。
应用:垂直领域内的深度应用,比如智能客服系统,智能外呼系统利用知识图谱可以精准的回答用户的问题,可以进行复杂问题的回答。一些垂直行业内常用的传统专家系统,通过赋予他们一定的背景知识,可以很好的提升效果。
知识图谱赋能可解释人工智能
可解释,是强人工智能的一个重要特征。 当前以深度学习模型为主的人工智能应用,虽然从结果上看效果还不错。但是模型本身就是一个黑盒的不具备可解释性,这就导致在很多需要有解释性的行业,没法使用复杂的深度学习模型。比如在司法领域,医疗诊断领域,金融领域某些场景。
可解释性的应用也会很好地提升用户对系统的信任感,提升用户满意度。问答场景下,推荐场景下都可以加入解释功能。
应用:尤其是在司法,医疗领域
其他应用
基于知识图谱的推理,综合利用图谱中的概念上下位关系、属性类型及约束、图模型中实体间的关联关系,结合业务场景定义的关系推理规则等。可以用来做一些不一致性检测、推断补全,知识发现,商品溯源,辅助推理决策等各类推理应用。










![[激光原理与应用-60]:激光器 - 光学 - 光的四大理论框架与其层次:几何光学、波动光学、电磁光学、电子光学](https://img-blog.csdnimg.cn/255216ad005943f9a16ba679b7bb17d8.png)