【C++练习】leetcode刷题训练(中等难度)
- 1.数组中的第K个最大元素
- 2.前K个高频单词
- 3.单词识别
- 4.字符串相乘
- 5.只出现1次的数字Ⅱ
- 6.栈的弹出压入序列
1.数组中的第K个最大元素

解题思路
1.典型的TOP-K问题(用堆来解决)
2.要求实现时间复杂度为O(N),而我们的优先级队列的时间复杂度为O(n*logN)差不多
3.正常应该是首先从序列中拿出k个元素放入队列中,然后将剩下的序列与堆顶比较,当大于堆顶就删除堆顶元素,将该元素入队列。但这里可以直接将全部数据都放入优先级队列中,然后直接获取第K大的元素, 因为放入优先级队列后自动排序了。默认是小堆,从小到大。
4.注意题目只要求获取第K大个元素,而不是获取前K个元素直接pop k-1次即可。
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int> pq(nums.begin(),nums.end());
while(--k)
{
pq.pop();
}
return pq.top();
}
};
2.前K个高频单词

解题思路①:用sort排序
1.统计出现的次数我们可以利用map来统计。
2.再对根据出现的次数进行排序。选出前K个单词
3.不过这里的问题是当次数相同时,如何按照字典序再排序?
4.我们想map统计完后,单词的顺序是排序好的,每个单词的个数可能相同也可能不同。但如果当单词个数不相同时,对出现的个数排序就可以完成任务,因为没有出现相同的频率,但如果单词个数出现相同时,排序完后,如果它们的相对顺序没有被改变,那么也可以完成任务,因为相对顺序就是按照字典序排的,所以这个排序得要求是稳定的。
5.还有如何进行比较排序呢?我们需要使用仿函数来修改比较规则。根据次数进行比较,并且进行降序排序。
class Solution {
public:
//要求先按照频率由高到低排序也就是出现的次数,如何统计出现的次数呢?用map统计次数
struct Greater//仿函数重构比较方式,利用出现的次数进行比较,并且降序排,大的在前面,小的在后面
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second>kv2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countmap;
for(auto &e:words)
{
countmap[e]++;
}
//已经统计完次数了接下来就要按照出现的频率来排序,不过map其实已经按照字典序的排序方法将数据排好
//只要要按照频率排序后稳定性不变,相对顺序不变就可以了,但sort稳定性不行
//注意sort无法对map排序,所以我们可以将map里的数据放进vector里
vector<pair<string,int>> v;
v(countmap.begin(),countmap.end());
stable_sort(v.begin(),v.end(),Greater());
//stable_sort排序比较稳定
vector<string> vs;
for(int i=0;i<k;i++)
{
vs.push_back(v[i].first);//选取前k个单词
}
return vs;
}
};
解决思路②:用priority_queue排序
1.经典的TOP-K问题,利用优先级队列筛选出前K个
2.首先利用map计算出各个单词出现的次数。
3.这里我们要重写一个比较器:因为我们想要用priority_queue来比较出现最多的前K个单次,但priority_queue里面存的是单词和它对应的值对键也就是次数,无法正常比较,所以我们要改写priority_queue的比较规则,通过仿函数可以将比较规则改变成自己想要的:根据单词出现的次数进行比较,当次数相同时,根据字典序进行比较。
4.从map中放入k个元素到priority_queue,当priority_queue的大小超过K时,就要pop掉一个(pop掉的是K+1中最小的那一个,不影响K结果),然后再push进入一个。知道map中元素放光。
5.这时,优先级队列中存的就是出现次数最多的前K个单词和值对键了(将priority_queue中的单词存到vector<.string>中)。但要注意优先级队列默认是小堆。是从小到大的。所以最后我们还需要逆转一下。
class Solution {
public:
//要求先按照频率由高到低排序也就是出现的次数,如何统计出现的次数呢?用map统计次数
struct Greater//仿函数重构比较方式:比较器
{
bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2)
{
return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);
//大于就是降序前面大,后面小
}
};
//典型的TOP-K问题
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> countmap;
priority_queue<pair<string,int>,vector<pair<string,int>>,Greater> pq;
for(auto &e:words)
{
countmap[e]++;
}
//已经统计完次数了接下来就要按照出现的频率来排序,不过map其实已经按照字典序的排序方法将数据排好
//利用优先级队列,将map中先入k个元素,当超过k个元素时,就删除一个,插入一个。等将全部将map元素插入栈里后,队列里的K个元素就是前K个
int i=0;
for(auto& e:countmap)
{
pq.push(e);
i++;
//先入K个元素
if(i>k)
{
pq.pop();
//当大于K个元素时,就pop掉堆顶的元素,反正是K+1中最小的pop掉没有影响
}
}
vector<string> v;
//队列不能使用迭代器访问遍历,只能pop出掉
while(!pq.empty())
{
v.push_back(pq.top().first);
pq.pop();
}
reverse(v.begin(),v.end());
return v;
}
};
3.单词识别
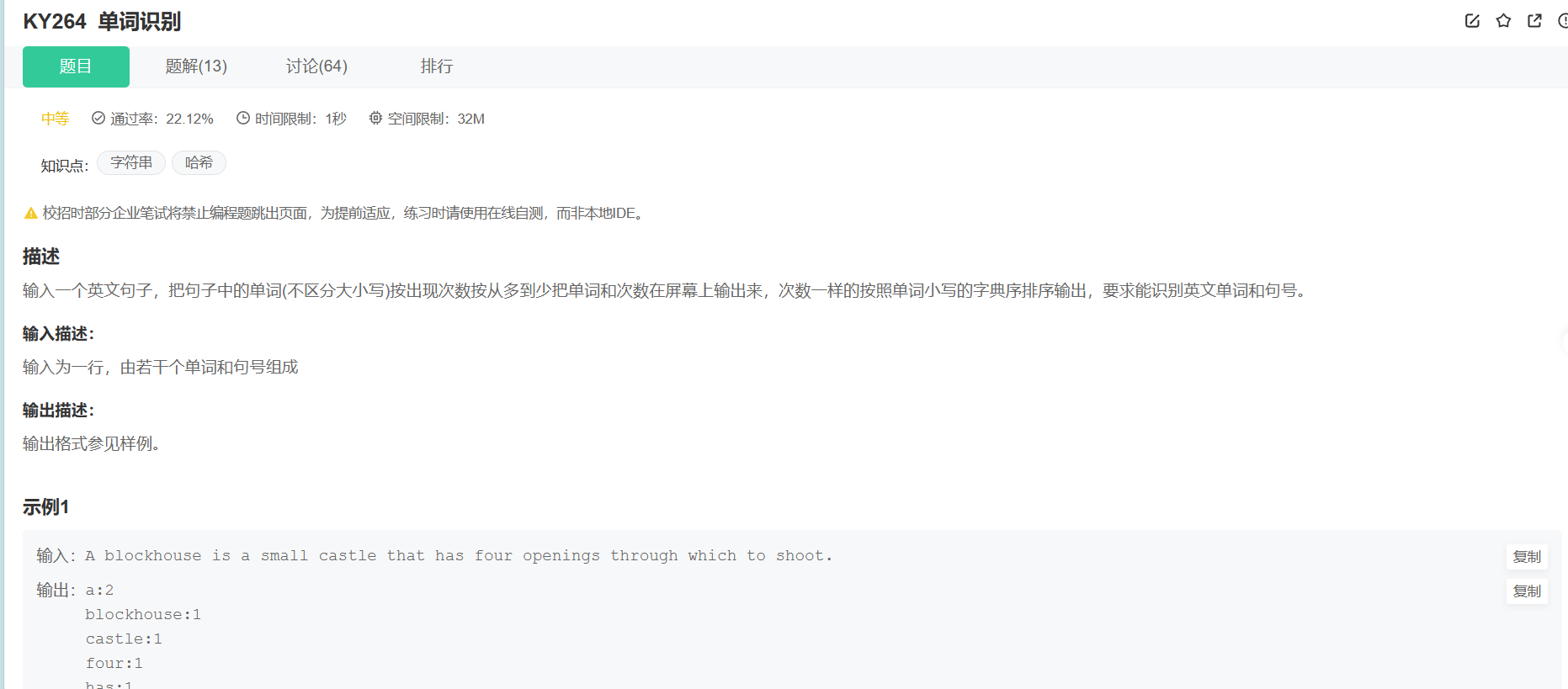
解题思路:其实本质就是上一题的解决思路,只不过多了一步。
1.首先我们需要将这句子中的单词全部分割出来。要注意输出流遇到空格和换行结束的特性,这里必须使用getline()获取一整行句子。
2.如何分割出单词呢?我们可以利用string的substr函数来切割字符串。当遇到空格或者句号,就将上次出现的位置(默认第一次是0)到这次空格或句号之前的位置上的字符剪切下来。(还有这里要注意,大小写是不区分的,这就要求我们在遍历句子时,一开始可以将遍历到的字符全部统一成小写字母),这里可以直接放入map里,一遍分割单词,一旦单词被分割出来就放入map里计数,也可以放入一个字符串数组里面,当全部单词被分割,再放入map里计数。
3.放入map里计数后,接下来的操作就和上面是一样的了,可以使用sort来排序,也可以使用priority_queue来比较,但都需要重写一个比较器,因为pair<string,int>这个值对键无法正常比较,需要我们根据需求改写比较规则。
#include <iostream>
using namespace std;
#include <vector>
#include<string>
#include<map>
#include<algorithm>
//写一个仿函数,用来控制排序的比较规则
struct Greater
{
bool operator()(pair<string, int>& kv1, pair<string, int>& kv2)
{
return kv1.second > kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);
}
};
int main()
{
//首先第一步将字母分割出来,放入数组里
string ch;
vector<string> v;
map<string, int>countmap;
while (getline(cin, ch))
{
int i = 0;
int pos = 0;
for (i = 0; i < ch.size(); i++)
{
ch[i]=tolower(ch[i]);//要求不区分大小写, 那我们就统一都弄成小写。
if (ch[i] == ' '||ch[i]=='.')
{
string tmp = ch.substr(pos, i-pos);//这里要注意很容易出错!
pos = i + 1;
v.push_back(tmp);
//也可以一遍分割一般放入map里计数
}
}
}
//第二利用map计算出现的次数
for (auto& e :v)
{
countmap[e]++;
}
//map无法使用sort排序放进vector中排序
vector<pair<string, int>> copy(countmap.begin(), countmap.end());
sort(copy.begin(), copy.end(), Greater());
for (auto& e : copy)
{
cout << e.first << ":" << e.second << endl;
}
}
4.字符串相乘
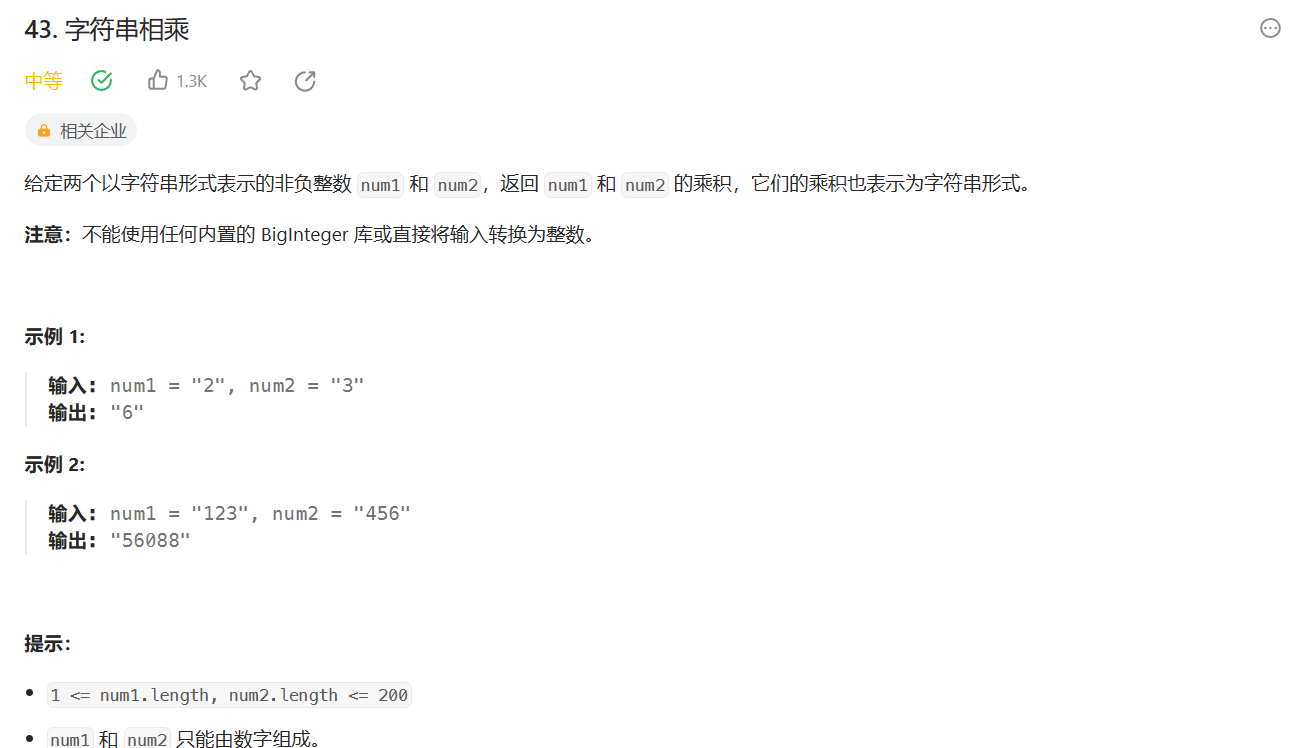
解题思路:本质是字符串相加的进阶
1.两个数相乘,我们通常喜欢用竖式乘法,所以这里我们只要模拟竖式乘法就可以,从右到左遍历乘数,然后每个乘数都乘上被乘数得到结果,最后再将这些结果相加就是最终的结果。
2.要注意的是当乘数不是最低阶时,后面要补成0的。
3.还有我通常喜欢让长度长的数放在上面,长度短的数放在下面。也就是让长度短的数字的每个数乘长度长的数字。也就是在短的数字里面遍历。但一开始我们不知道哪个数字谁长度长,谁长度短,所以需要比较一下。反正我就是想让在短的数字里遍历。这样符合我的习惯。这样就转化为n个单词相加了。
4.这里有很多细节要注意,当两个数其中一个为0那么最终结果肯定为0。
5.怎么控制不是低价的数后面要自动补0呢?我们没有必要在阶数上搞,我们可以直接在最后的结果上直接加0,阶数为十位那就加一个0,阶数为百位,就加两个0。
>
class Solution {
public:
string addStrings(string num1, string num2) {
int end1=num1.size()-1,end2=num2.size()-1;
int carry=0;
string strRet;
while(end1>=0||end2>=0)
{
int val1=end1>=0?(num1[end1]-'0'):0;
int val2=end2>=0?(num2[end2]-'0'):0;
int ret=val1+val2+carry;
carry=ret/10;
ret%=10;
strRet+=ret+'0';
--end1;
--end2;
}
if(carry==1)
{
strRet+='1';
}
reverse(strRet.begin(),strRet.end());
return strRet;
}
string multiply(string num1, string num2) {
if((num1[0]-'0')==0||(num2[0]-'0')==0)//如果其中一个数为0,那么最后结果就为0
return "0";
if(num1.size()<num2.size())//这里我相比较哪个数比较长,我想遍历长度短的数
{
swap(num1,num2);
}
string ans="0";
for (int i = num2.size()-1; i >= 0; i--)//在长度短的数里遍历
{
string s;
int ret2 = num2[i] - '0';
int binary = 0;
for (int j = num1.size()-1; j >= 0; j--)//每个数字都乘长度长的数
{
int ret1 = num1[j] - '0';
s += ((ret1 * ret2) + binary) % 10 + '0';
binary = ((ret1 * ret2) + binary) / 10;//进位
}
if(binary>0)//特性情况,当两个个数相乘,最后如果不加上这句,最后答案就只是个位上的数,十位数上的数没有加上。因为只会进入循环一次,最后的进位没有加上去。
{
s+=binary+'0';
}
reverse(s.begin(), s.end());//最后要逆转回来
int k = i;//最后可以依据在哪个位置加上几个0.
while (k <num2.size() - 1)
{
s += '0';
k++;
}
ans=addStrings(ans,s);//调用加法函数每次叠加即可。
}
return ans;
}
};
5.只出现1次的数字Ⅱ

解题思路
1.只有一个数出现一次,其他的数字都出现三次。我们从二进制位的角度来思考:整数一共有32位。二进制表示只有1或0,将相同的数的同一个二进制数全部加起来后,这个数肯定是3的整数倍的(0或者3N),即可以整除3的。
2.而这时如果再加上这个只出现一次的数的该二进制上的数,当结果模3不等于0时,就说明这个二进制位置上的数是1!
3.我们就可以通过这样的方法来确定这个只出现一次的数的每个二进制位置上是不是1。
4.通过(n>>i)&1来获取第i个二进制位上数是几(&:只有两个1&1最后等于1,其他都为0)
5.通过ans|(1<<i)来将ans第i个二进制上变成1.
class Solution {
public:
int singleNumber(vector<int>& nums) {
int single=0;
for(int i=0;i<32;i++)
{
int ret=0;
//每次循环下下来要更新为0
for(auto& e:nums)
{
ret+=(e>>i)&1;
//获取nums中每个数的第i个二进制位上的数,然后全部相加起来
}
//因为三个相同的数,要么是全是0,要么全是1,相加起来要么是0,要么是3N,所以当只出现一次的数第i二进制位置是1时,
//最后的结果模3就不为0,当只出现一次的第i位置是0时,最后结果模完还是0
if(ret%3!=0)
{
//表明只出现一个数的第i位置是1
single=single|(1<<i);
//(1<<i)表示让第i位置上数字为1
}
}
return single;
}
};
6.栈的弹出压入序列
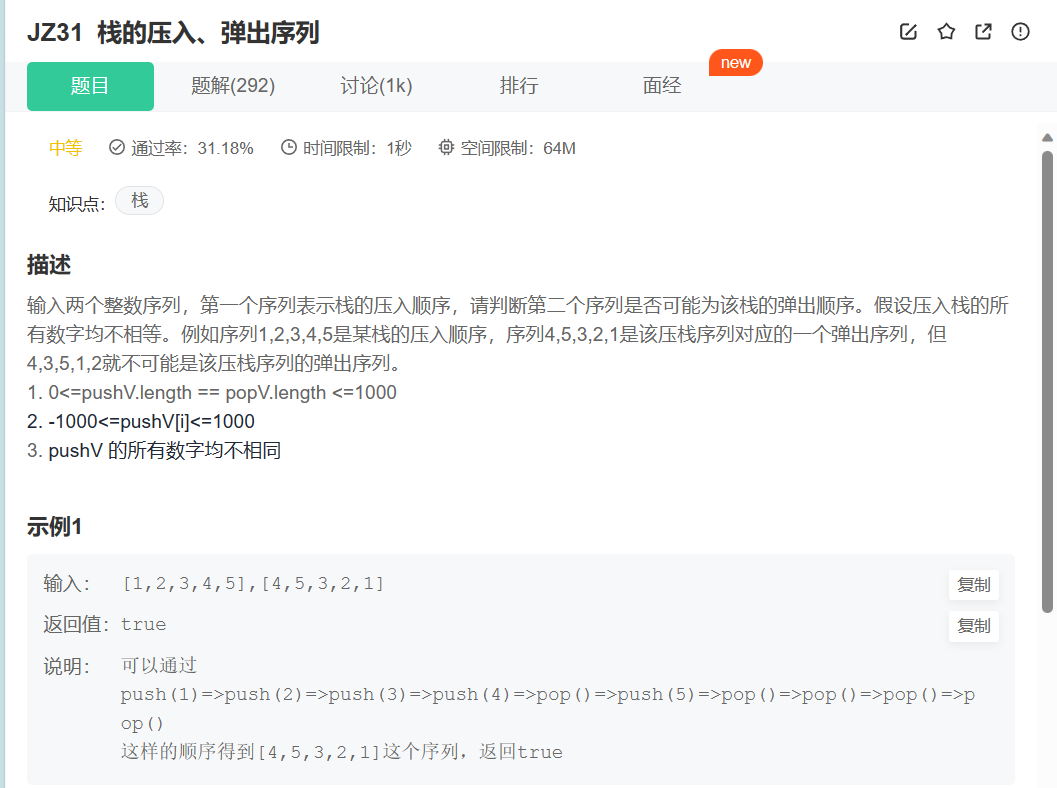
解题思路
1.给了入栈序列,和出栈序列,要求判断出栈序列是否合法。
2.那么我们可以模拟一下出栈,就是利用栈,根据出栈序列,来将元素入栈,比较一下,看最后是否能将栈里出空。
3.首先先入栈一个元素,然后和出栈序列中的第一个相比较,当不相同时,就继续入栈。
4.当入栈的元素和出栈序列相同时,那么就可以将栈顶元素删掉,并且对比下一个出栈序列。不过这里会存在着持续出栈的可能,就是当栈顶元素删除掉后,发现现在的栈顶元素与下一个出栈序列相同,那么就继续删除栈顶,再比较下一个出栈序列。这里会存在会将栈里元素出空,或者出栈序列与栈顶元素不相同,这时候就又要回去重写入栈。
5.也就是会存在两种情况:一种是持续出一种是不匹配。而持续出有可能会导致栈被出空,而出现这两种种情况都需要重新回去继续入栈。
bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {
int pushi=0,popi=0;
stack<int> st;
//当根据入栈元素没有了,就结束了。如果这时,根据正确的出栈顺序最后栈里是空的
while(pushi<pushV.size())
{
//首先先入栈一个
st.push(pushV[pushi++]);
//然后与出栈顺序比较
if(st.top()!=popV[popi])//如果不匹配就继续入
{
continue;
}
else//匹配可能会持续出
{
//因为可以能不一定只出一个可能持续出,所以要写一个循环
//但前提是栈里不为空,要是栈里被持续出空了就不要再进行下去了,再回去入栈.也有可能出完一个后,下面一个不匹配了,也要回去继续入栈。
while(!st.empty()&&st.top()==popV[popi])//持续出的要求就是top()要和出栈序列相同,并且栈不为空
{
st.pop();
popi++;
}
}
}
return st.empty();
}
//根据出栈结果模拟入栈过程,如果最后入栈序列到头,出栈还未完成则就不正常
//不匹配还不入了就说明结束了