一,关于 pg_database
在 PostgreSQL 中,对于在数据库集群内创建的每个数据库,其关键信息都会被保存到 pg_database 系统表中。
PostgreSQL 确保通过 pg_database 系统表持久化存储每个数据库的属性信息,以方便后续管理和使用。这也让 pg_database 成为了 PostgreSQL 数据库集群非常重要的系统表之一。
$ select * from pg_database
oid datname datdba encoding datcollate datctype datistemplate datallowconn datconnlimit datlastsysoid datfrozenxid datminmxid dattablespace datacl
13754 postgres 10 6 Chinese (Simplified)_China.936 Chinese (Simplified)_China.936 false true -1 13753 727 1 1663
16488 hello_django 10 6 Chinese (Simplified)_China.936 Chinese (Simplified)_China.936 false true -1 13753 727 1 1663
1 template1 10 6 Chinese (Simplified)_China.936 Chinese (Simplified)_China.936 true true -1 13753 727 1 1663 "{=c/postgres,postgres=CTc/postgres}"
13753 template0 10 6 Chinese (Simplified)_China.936 Chinese (Simplified)_China.936 true false -1 13753 727 1 1663 "{=c/postgres,postgres=CTc/postgres}"
16635 DDBAdmin 10 6 Chinese (Simplified)_China.936 Chinese (Simplified)_China.936 false true -1 13753 727 1 1663
pg_database表中每个字段的意义及可能的取值如下:
- datname - 数据库名称,VARCHAR类型,必须唯一,如mydb。
- datdba - 数据库所有者,OID类型,引用pg_authid表的OID,表示数据库所有者。
- encoding - 数据库字符集,INT类型,引用pg_encoding表,默认为数据库集群字符集。
- datcollate - 数据库排序规则,VARCHAR类型,默认为C或en_US.UTF-8。
- datctype - 数据库字符分类,VARCHAR类型,默认为C或en_US.UTF-8。
- datistemplate - 是否模板数据库,BOOL类型,用于标识模板数据库。
- datallowconn - 是否允许连接,BOOL类型,控制用户是否可以连接此数据库。
- datconnlimit - 连接数限制,INT类型,限制此数据库最大连接数,-1为无限。
- datlastsysoid - 数据库最后一个系统OID,OID类型,记录此数据库最大OID。
- dattablespace - 默认表空间,OID类型,引用pg_tablespace表,默认为1663(pg_default)。
- datacl - 访问权限控制,ACLITEM[], discretionary access permissions。
- datfrozenxid - 冻结事务ID,txid_snapshot类型,用于基于autocommit的VACUUM。
- dattablespace - 数据库默认表空间,OID类型,默认为pg_default(1663)。
- datacl - 访问权限控制列表,记录哪些角色可以访问此数据库。
二,datlastsysoid 字段
pg_database表中的 datlastsysoid 字段主要用于记录每个数据库里面系统对象标识符(OID)的最大值,它的主要作用是:
1,追踪数据库中系统对象创建顺序
在PostgreSQL中,所有系统对象(表、索引、视图等)都分配一个唯一的OID。该字段记录了当前数据库中最后创建的系统对象的OID号。所以它可以用于追踪一个数据库内部系统对象的创建顺序。
2,保证OID的唯一性
每个数据库都有自己的OID序列,数据库中的每个系统对象OID都是从该序列中分配。datlastsysoid的值表示了下一个OID将从什么值开始分配。这可以确保OID的唯一性。
3,加速对象定位速度
通过记录最大OID值,PostgreSQL在定位一个对象时可以从最大值开始反向扫描,从而加快对象的定位速度。
4,协助对象标识
oid结合datname可唯一标识一个数据库对象,这可以帮助跨数据库查询中明确对象所属数据库。
5,方便数据库维护
它支持对象维护操作,如VACUUM判断可回收对象、恢复数据库等。
6,标识数据库膨胀程度
该值越大,表示数据库对象越多,数据库膨胀越严重。
所以,datlastsysoid 主要是用于跟踪数据库系统对象Oid分配情况,从而帮助PostgreSQL进行对象管理,提高性能,确保Oid唯一性约束。它是数据库内部机制一个非常重要的组成部分。
在 postgresql 文档 52.15. pg_database 中就表示”datlastsysoid:对pg_dump特别有用“。主要有以下几个原因:
1,加速pg_dump的执行速度
pg_dump是PostgreSQL的逻辑备份工具,它需要扫描整个数据库获取所有对象进行导出。有了datlastsysoid的最大OID值,pg_dump就可以从最大OID开始反向扫描对象,而不用从OID=0开始逐个扫描,这样可以显著提升pg_dump的执行速度。
2,减少导出文件大小
pg_dump是将数据库中的所有对象逻辑定义导出为SQL语句。但并非所有OID都被使用,有些OID对应已经删除的对象或者从未分配。如果从0开始导出,会包含大量无效的空定义,增加文件大小。而datlastsysoid可以让pg_dump只导出有效使用的OID范围对象,减小文件大小。
3,校验导出数据完整性
根据datlastsysoid记录的最大OID,pg_dump知道导出文件包含的应该是哪些OID范围的对象,这样就可以验证导出是否完整。
所以,datlastsysoid对pg_dump的执行性能、导出文件大小和导出完整性校验都有重要帮助,这对一个重要的备份工具来说是非常有价值的信息。这也是PostgreSQL文档中特别提到它对pg_dump的用处的原因。
三,datlastsysoid 字段的初始值是固定的吗?
不同版本的PostgreSQL中,datlastsysoid字段的初始值可能不相同。主要原因有:
1,默认OID起始值变化:
不同版本的PostgreSQL默认分配的第一个系统对象OID可能不一样:
- PostgreSQL 8.1之前,默认从16380开始分配OID
- PostgreSQL 8.1到9.0,默认从12000开始
- 9.1之后,默认从16384开始
因此初始datlastsysoid也会有差异。
2,初始化参数调整:
PostgreSQL允许通过init_catalog_relations_oid等参数调整初始OID的值,不同版本可能进行了不同的默认初始化参数设置,导致初始datlastsysoid字段值不一样。
3,模板数据库不同:
从模板创建数据库时,会继承模板数据库的datlastsysoid值。如果版本默认的模板数据库不一样,也会导致新建数据库的初始值不同。
4,分支版本差异:
一些分支版本如Greenplum等,可能调整了默认OID分配规则,也会影响到datlastsysoid的初始值。
综上,由于OID分配机制的不同、参数设置的差异以及模板数据库的变化,使得不同 PostgreSQL 版本中,新建数据库时datlastsysoid的默认初始值可能会有所不同,并不是完全固定的。
四,为什么pgadmin4要设置 datlastsysoid 为 16383
pgadmin4在 web/pgadmin/utils/constants.py 文件中定义了一个常量:
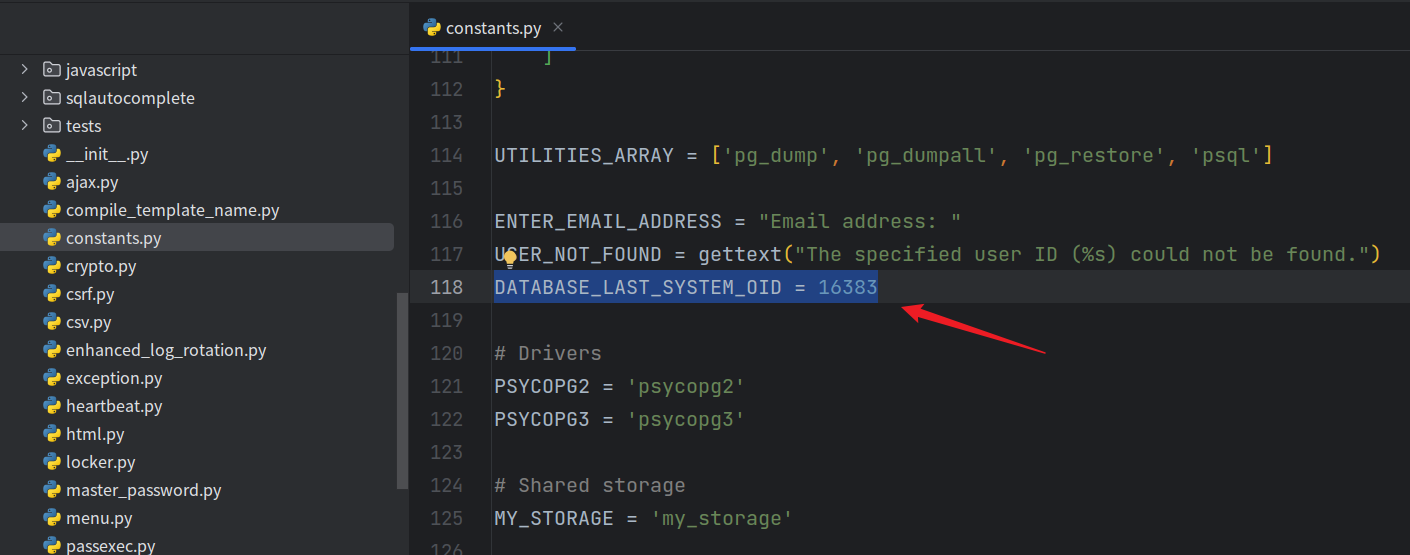
这主要是因为pgAdmin 4在设计时考虑了兼容性和性能因素,将datlastsysoid字段硬编码为一个较低的固定值,而不是动态读取每个数据库实际的最大OID。
pgAdmin 4里定义常量DATABASE_LAST_SYSTEM_OID = 16383的主要原因有:
1,确保兼容性
不同版本PostgreSQL的默认起始OID不一样,为了兼容老版本,pgAdmin选择一个较低的OID值16383。
2,避免每次连接数据库时查询
每次启动要连接数据库读取最大OID会影响性能,所以pgAdmin直接硬编码了一个较低值。
3,仅用于内部标识之用
pgAdmin作为客户端工具,只需要一个固定值用于内部标识管理,不需要每个数据库实际的最大OID。
4,避免OID不连续问题
固定较低的OID值可以避免OID不连续导致的一些非预期问题。
5,简化开发
硬编码一个常量比读取数据库动态值简单快捷,特别是要支持各种不同数据库。
所以综上,pgAdmin 4 的做法是考虑到兼容性、性能和开发效率等因素的结果,与数据库中实际的最大OID没有直接关系。
比如,在pgadmin4查询索引的属性时:
class IndexesView(PGChildNodeView, SchemaDiffObjectCompare):
"""
This class is responsible for generating routes for Index node
Methods:
...
"""
@check_precondition
def properties(self, gid, sid, did, scid, tid, idx):
"""
This function will show the properties of the selected schema node.
Args:
gid: Server Group ID
sid: Server ID
did: Database ID
scid: Schema ID
scid: Schema ID
tid: Table ID
idx: Index ID
Returns:
JSON of selected schema node
"""
status, data = self._fetch_properties(did, tid, idx)
if not status:
return data
return ajax_response(
response=data,
status=200
)
def _fetch_properties(self, did, tid, idx):
"""
This function is used to fetch the properties of specified object.
:param did:
:param tid:
:param idx:
:return:
"""
SQL = render_template(
"/".join([self.template_path, self._PROPERTIES_SQL]),
did=did, tid=tid, idx=idx,
datlastsysoid=self._DATABASE_LAST_SYSTEM_OID
)
status, res = self.conn.execute_dict(SQL)
if not status:
return False, internal_server_error(errormsg=res)
if len(res['rows']) == 0:
return False, gone(self.not_found_error_msg())
# Making copy of output for future use
data = dict(res['rows'][0])
# Add column details for current index
data = index_utils.get_column_details(self.conn, idx, data)
# Add Include details of the index
if self.manager.version >= 110000:
data = index_utils.get_include_details(self.conn, idx, data)
return True, data
代码中通过:
SQL = render_template(
"/".join([self.template_path, self._PROPERTIES_SQL]),
did=did, tid=tid, idx=idx,
datlastsysoid=self._DATABASE_LAST_SYSTEM_OID # 这里
)
这里的 self._DATABASE_LAST_SYSTEM_OID 就继承自定义在web/pgadmin/broswer/utils.py 文件中的父类:
# ...
from pgadmin.utils.constants import DATABASE_LAST_SYSTEM_OID
# ...
class PGChildNodeView(NodeView):
_NODE_SQL = 'node.sql'
_NODES_SQL = 'nodes.sql'
_CREATE_SQL = 'create.sql'
_UPDATE_SQL = 'update.sql'
_ALTER_SQL = 'alter.sql'
_PROPERTIES_SQL = 'properties.sql'
_DELETE_SQL = 'delete.sql'
_GRANT_SQL = 'grant.sql'
_SCHEMA_SQL = 'schema.sql'
_ACL_SQL = 'acl.sql'
_OID_SQL = 'get_oid.sql'
_FUNCTIONS_SQL = 'functions.sql'
_GET_CONSTRAINTS_SQL = 'get_constraints.sql'
_GET_TABLES_SQL = 'get_tables.sql'
_GET_DEFINITION_SQL = 'get_definition.sql'
_GET_SCHEMA_OID_SQL = 'get_schema_oid.sql'
_GET_COLUMNS_SQL = 'get_columns.sql'
_GET_COLUMNS_FOR_TABLE_SQL = 'get_columns_for_table.sql'
_GET_SUBTYPES_SQL = 'get_subtypes.sql'
_GET_EXTERNAL_FUNCTIONS_SQL = 'get_external_functions.sql'
_GET_TABLE_FOR_PUBLICATION = 'get_tables.sql'
# 这里
_DATABASE_LAST_SYSTEM_OID = DATABASE_LAST_SYSTEM_OID
去填充SQL模板:
SELECT DISTINCT ON(cls.relname) cls.oid, cls.relname as name, indrelid, indkey, indisclustered,
indisvalid, indisunique, indisprimary, n.nspname,indnatts,cls.reltablespace AS spcoid,
CASE WHEN (length(spcname::text) > 0 OR cls.relkind = 'I') THEN spcname ELSE
(SELECT sp.spcname FROM pg_catalog.pg_database dtb
JOIN pg_catalog.pg_tablespace sp ON dtb.dattablespace=sp.oid
WHERE dtb.oid = {{ did }}::oid)
END as spcname,
tab.relname as tabname, indclass, con.oid AS conoid,
CASE WHEN contype IN ('p', 'u', 'x') THEN desp.description
ELSE des.description END AS description,
pg_catalog.pg_get_expr(indpred, indrelid, true) as indconstraint, contype, condeferrable, condeferred, amname,
(SELECT (CASE WHEN count(i.inhrelid) > 0 THEN true ELSE false END) FROM pg_inherits i WHERE i.inhrelid = cls.oid) as is_inherited,
substring(pg_catalog.array_to_string(cls.reloptions, ',') from 'fillfactor=([0-9]*)') AS fillfactor
{% if datlastsysoid %}, (CASE WHEN cls.oid <= {{ datlastsysoid}}::oid THEN true ElSE false END) AS is_sys_idx {% endif %}
FROM pg_catalog.pg_index idx
JOIN pg_catalog.pg_class cls ON cls.oid=indexrelid
JOIN pg_catalog.pg_class tab ON tab.oid=indrelid
LEFT OUTER JOIN pg_catalog.pg_tablespace ta on ta.oid=cls.reltablespace
JOIN pg_catalog.pg_namespace n ON n.oid=tab.relnamespace
JOIN pg_catalog.pg_am am ON am.oid=cls.relam
LEFT JOIN pg_catalog.pg_depend dep ON (dep.classid = cls.tableoid AND dep.objid = cls.oid AND dep.refobjsubid = '0' AND dep.refclassid=(SELECT oid FROM pg_catalog.pg_class WHERE relname='pg_constraint') AND dep.deptype='i')
LEFT OUTER JOIN pg_catalog.pg_constraint con ON (con.tableoid = dep.refclassid AND con.oid = dep.refobjid)
LEFT OUTER JOIN pg_catalog.pg_description des ON (des.objoid=cls.oid AND des.classoid='pg_class'::regclass)
LEFT OUTER JOIN pg_catalog.pg_description desp ON (desp.objoid=con.oid AND desp.objsubid = 0 AND desp.classoid='pg_constraint'::regclass)
WHERE indrelid = {{tid}}::OID
AND conname is NULL
{% if idx %}AND cls.oid = {{idx}}::OID {% endif %}
ORDER BY cls.relname
最终会执行:
SELECT DISTINCT ON(cls.relname) cls.oid, cls.relname as name, indrelid, indkey, indisclustered,
indisvalid, indisunique, indisprimary, n.nspname,indnatts,cls.reltablespace AS spcoid,
CASE WHEN (length(spcname::text) > 0 OR cls.relkind = 'I') THEN spcname ELSE
(SELECT sp.spcname FROM pg_catalog.pg_database dtb
JOIN pg_catalog.pg_tablespace sp ON dtb.dattablespace=sp.oid
WHERE dtb.oid = 13799::oid)
END as spcname,
tab.relname as tabname, indclass, con.oid AS conoid,
CASE WHEN contype IN ('p', 'u', 'x') THEN desp.description
ELSE des.description END AS description,
pg_catalog.pg_get_expr(indpred, indrelid, true) as indconstraint, contype, condeferrable, condeferred, amname,
(SELECT (CASE WHEN count(i.inhrelid) > 0 THEN true ELSE false END) FROM pg_inherits i WHERE i.inhrelid = cls.oid) as is_inherited,
substring(pg_catalog.array_to_string(cls.reloptions, ',') from 'fillfactor=([0-9]*)') AS fillfactor
, (CASE WHEN cls.oid <= 16383::oid THEN true ElSE false END) AS is_sys_idx FROM pg_catalog.pg_index idx
JOIN pg_catalog.pg_class cls ON cls.oid=indexrelid
JOIN pg_catalog.pg_class tab ON tab.oid=indrelid
LEFT OUTER JOIN pg_catalog.pg_tablespace ta on ta.oid=cls.reltablespace
JOIN pg_catalog.pg_namespace n ON n.oid=tab.relnamespace
JOIN pg_catalog.pg_am am ON am.oid=cls.relam
LEFT JOIN pg_catalog.pg_depend dep ON (dep.classid = cls.tableoid AND dep.objid = cls.oid AND dep.refobjsubid = '0' AND dep.refclassid=(SELECT oid FROM pg_catalog.pg_class WHERE relname='pg_constraint') AND dep.deptype='i')
LEFT OUTER JOIN pg_catalog.pg_constraint con ON (con.tableoid = dep.refclassid AND con.oid = dep.refobjid)
LEFT OUTER JOIN pg_catalog.pg_description des ON (des.objoid=cls.oid AND des.classoid='pg_class'::regclass)
LEFT OUTER JOIN pg_catalog.pg_description desp ON (desp.objoid=con.oid AND desp.objsubid = 0 AND desp.classoid='pg_constraint'::regclass)
WHERE indrelid = 24580::OID
AND conname is NULL
AND cls.oid = 24604::OID ORDER BY cls.relname
这个SQL主要是在查询pg_index和pg_class等系统表,获取指定表的索引信息。
具体来看:
- 从pg_index表JOIN pg_class表获取所有索引信息
- JOIN pg_class、pg_namespace获取索引对应的表信息
- LEFT JOIN pg_tablespace获取索引的表空间
- JOIN pg_am获取索引访问方法信息
- JOIN pg_depend和pg_constraint获取索引相关的约束信息
- LEFT JOIN pg_description获取注释信息
- WHERE条件筛选出indrelid=24580的表相关联的索引,也就是表OID为24580的这个表的所有索引
并且conname IS NULL排除有约束名称的约束索引,只取普通索引
cls.oid = 24604过滤只取OID=24604的这个索引
最后ORDER BY cls.relname按索引名称排序
返回的各个字段如索引名称、索引所属表、索引键列、索引方法、约束信息等都很直接明了。
整体上,这条SQL是非常全面地获取一张表的全部索引详细信息,包括键列、表空间、访问方法、约束、注释等,能够通过这个查询充分了解这个表的索引情况。
其中 CASE WHEN cls.oid <= 16383::oid THEN true ElSE false END 这个CASE WHEN表达式的作用是将索引的 oid 字段进行判断,如果索引的oid小于等于16383,则返回true,否则返回false。
然后将这个结果作为一个新的字段is_sys_idx返回。
这里之所以要判断oid是否<=16383,是因为PostgreSQL在内部对系统定义的索引和用户定义的索引进行了区分:
- 系统定义的索引,oid<=16383
- 用户定义的索引,oid>16383
所以这个CASE WHEN表达式实际上是在判断该索引是否是一个系统自带的索引,还是一个用户后期自定义创建的索引。
这个信息在判断索引的来源和性质上还是很有帮助的。