一、代码重复问题处理
1、利用工厂模式 + 模板方法模式,消除 if…else 和重复代码
场景:
假设要开发一个购物车下单的功能,针对不同用户进行不同处理:
普通用户需要收取运费,运费是商品价格的 10%,无商品折扣;
VIP 用户同样需要收取商品价格 10% 的快递费,但购买两件以上相同商品时,第三件开始享受一定折扣;
内部用户可以免运费,无商品折扣。
处理方案:
AbstractCart 抽象类实现了购物车通用的逻辑,额外定义了两个抽象方法让子类去实现。其中,processCouponPrice 方法用于计算商品折扣,processDeliveryPrice 方法用于计算运费。
public abstract class AbstractCart {
//处理购物车的大量重复逻辑在父类实现
public Cart process(long userId, Map<Long, Integer> items) {
Cart cart = new Cart();
List<Item> itemList = new ArrayList<>();
items.entrySet().stream().forEach(entry -> {
Item item = new Item();
item.setId(entry.getKey());
item.setPrice(Db.getItemPrice(entry.getKey()));
item.setQuantity(entry.getValue());
itemList.add(item);
});
cart.setItems(itemList);
//让子类处理每一个商品的优惠
itemList.stream().forEach(item -> {
processCouponPrice(userId, item);
processDeliveryPrice(userId, item);
});
//计算商品总价
cart.setTotalItemPrice(cart.getItems().stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity()))).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算总运费
cart.setTotalDeliveryPrice(cart.getItems().stream().map(Item::getDeliveryPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算总折扣
cart.setTotalDiscount(cart.getItems().stream().map(Item::getCouponPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算应付价格
cart.setPayPrice(cart.getTotalItemPrice().add(cart.getTotalDeliveryPrice()).subtract(cart.getTotalDiscount()));
return cart;
}
//处理商品优惠的逻辑留给子类实现
protected abstract void processCouponPrice(long userId, Item item);
//处理配送费的逻辑留给子类实现
protected abstract void processDeliveryPrice(long userId, Item item);
}有了这个抽象类,三个子类的实现就非常简单了。普通用户的购物车 NormalUserCart,实现的是 0 优惠和 10% 运费的逻辑:
@Service(value = "NormalUserCart")
public class NormalUserCart extends AbstractCart {
@Override
protected void processCouponPrice(long userId, Item item) {
item.setCouponPrice(BigDecimal.ZERO);
}
@Override
protected void processDeliveryPrice(long userId, Item item) {
item.setDeliveryPrice(item.getPrice()
.multiply(BigDecimal.valueOf(item.getQuantity()))
.multiply(new BigDecimal("0.1")));
}
}VIP 用户的购物车 VipUserCart,直接继承了 NormalUserCart,只需要修改多买优惠策略:
@Service(value = "VipUserCart")
public class VipUserCart extends NormalUserCart {
@Override
protected void processCouponPrice(long userId, Item item) {
if (item.getQuantity() > 2) {
item.setCouponPrice(item.getPrice()
.multiply(BigDecimal.valueOf(100 - Db.getUserCouponPercent(userId)).divide(new BigDecimal("100")))
.multiply(BigDecimal.valueOf(item.getQuantity() - 2)));
} else {
item.setCouponPrice(BigDecimal.ZERO);
}
}
}内部用户购物车 InternalUserCart 是最简单的,直接设置 0 运费和 0 折扣即可:
@Service(value = "InternalUserCart")
public class InternalUserCart extends AbstractCart {
@Override
protected void processCouponPrice(long userId, Item item) {
item.setCouponPrice(BigDecimal.ZERO);
}
@Override
protected void processDeliveryPrice(long userId, Item item) {
item.setDeliveryPrice(BigDecimal.ZERO);
}
}抽象类和三个子类的实现关系图,如下所示:

定义三个购物车子类时,我们在 @Service 注解中对 Bean 进行了命名。既然三个购物车都叫 XXXUserCart,那我们就可以把用户类型字符串拼接 UserCart 构成购物车 Bean 的名称,然后利用 Spring 的 IoC 容器,通过 Bean 的名称直接获取到 AbstractCart,调用其 process 方法即可实现通用。
@GetMapping("right")
public Cart right(@RequestParam("userId") int userId) {
String userCategory = Db.getUserCategory(userId);
AbstractCart cart = (AbstractCart) applicationContext.getBean(userCategory + "UserCart");
return cart.process(userId, items);
}我们就利用工厂模式 + 模板方法模式,不仅消除了重复代码,还避免了修改既有代码的风险。
2、利用属性拷贝工具消除重复代码
ComplicatedOrderDTO orderDTO = new ComplicatedOrderDTO();
ComplicatedOrderDO orderDO = new ComplicatedOrderDO();
BeanUtils.copyProperties(orderDTO, orderDO, "id");
return orderDO;二、接口设计
1、接口的响应要明确表示接口的处理结果
① 对外隐藏内部实现。虽然说收单服务调用订单服务进行真正的下单操作,但是直接接口其实是收单服务提供的,收单服务不应该“直接”暴露其背后订单服务的状态码、错误描述。
@Data
public class APIResponse<T> {
private boolean success;
private T data;
private int code;
private String message;
}② 设计接口结构时,明确每个字段的含义,以及客户端的处理方式。
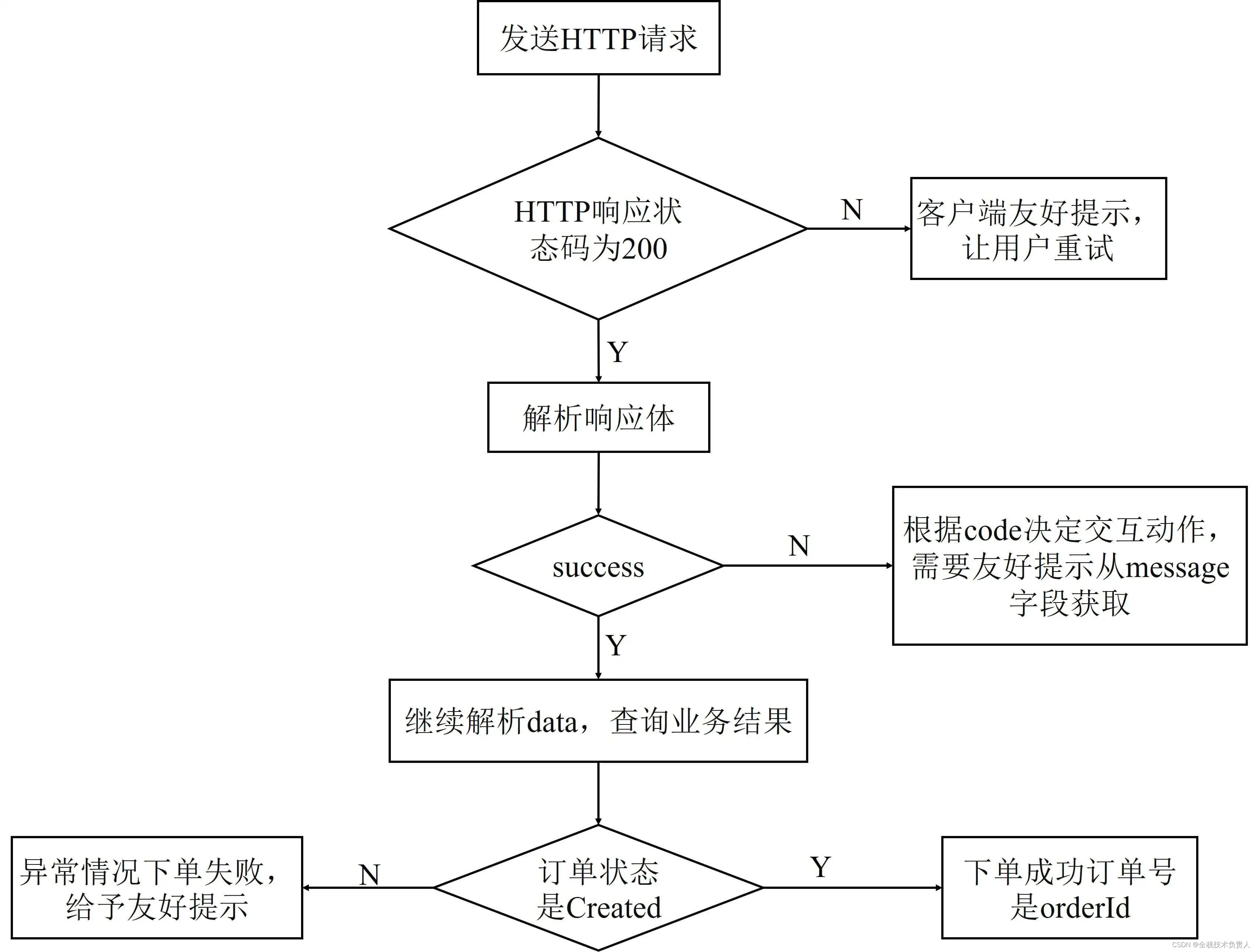
a、如果出现非 200 的 HTTP 响应状态码,就代表请求没有到收单服务,可能是网络出问题、网络超时,或者网络配置的问题。这时,肯定无法拿到服务端的响应体,客户端可以给予友好提示,比如让用户重试,不需要继续解析响应结构体。
b、如果 HTTP 响应码是 200,解析响应体查看 success,为 false 代表下单请求处理失败,可能是因为收单服务参数验证错误,也可能是因为订单服务下单操作失败。这时,根据收单服务定义的错误码表和 code,做不同处理。比如友好提示,或是让用户重新填写相关信息,其中友好提示的文字内容可以从 message 中获取。
c、success 为 true 的情况下,才需要继续解析响应体中的 data 结构体。data 结构体代表了业务数据,通常会有下面两种情况。
通常情况下,success 为 true 时订单状态是 Created,获取 orderId 属性可以拿到订单号。
特殊情况下,比如收单服务内部处理不当,或是订单服务出现了额外的状态,虽然 success 为 true,但订单实际状态不是 Created,这时可以给予友好的错误提示。
2、包装 API 响应体 APIResponse 的工作交由框架自动完成
① 抛出一个自定义异常:
@GetMapping("server")
public OrderInfo server(@RequestParam("userId") Long userId) {
if (userId == null) {
throw new APIException(3001, "Illegal userId");
}
if (userId == 1) {
...
//直接抛出异常
throw new APIException(3002, "Internal Error, order is cancelled");
}
//直接返回DTO
return new OrderInfo("Created", 2L);
}在 APIException 中包含错误码和错误消息:
public class APIException extends RuntimeException {
@Getter
private int errorCode;
@Getter
private String errorMessage;
public APIException(int errorCode, String errorMessage) {
super(errorMessage);
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
public APIException(Throwable cause, int errorCode, String errorMessage) {
super(errorMessage, cause);
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
}然后,定义一个 @RestControllerAdvice 来完成自动包装响应体的工作:
a、通过实现 ResponseBodyAdvice 接口的 beforeBodyWrite 方法,来处理成功请求的响应体转换。
b、实现一个 @ExceptionHandler 来处理业务异常时,APIException 到 APIResponse 的转换。
//此段代码只是Demo,生产级应用还需要扩展很多细节
@RestControllerAdvice
@Slf4j
public class APIResponseAdvice implements ResponseBodyAdvice<Object> {
//自动处理APIException,包装为APIResponse
@ExceptionHandler(APIException.class)
public APIResponse handleApiException(HttpServletRequest request, APIException ex) {
log.error("process url {} failed", request.getRequestURL().toString(), ex);
APIResponse apiResponse = new APIResponse();
apiResponse.setSuccess(false);
apiResponse.setCode(ex.getErrorCode());
apiResponse.setMessage(ex.getErrorMessage());
return apiResponse;
}
//仅当方法或类没有标记@NoAPIResponse才自动包装
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return returnType.getParameterType() != APIResponse.class
&& AnnotationUtils.findAnnotation(returnType.getMethod(), NoAPIResponse.class) == null
&& AnnotationUtils.findAnnotation(returnType.getDeclaringClass(), NoAPIResponse.class) == null;
}
//自动包装外层APIResposne响应
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
APIResponse apiResponse = new APIResponse();
apiResponse.setSuccess(true);
apiResponse.setMessage("OK");
apiResponse.setCode(2000);
apiResponse.setData(body);
return apiResponse;
}
}在这里,我们实现了一个 @NoAPIResponse 自定义注解。如果某些 @RestController 的接口不希望实现自动包装的话,可以标记这个注解:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface NoAPIResponse {
}在 ResponseBodyAdvice 的 support 方法中,我们排除了标记有这个注解的方法或类的自动响应体包装。比如,对于刚才我们实现的测试客户端 client 方法不需要包装为 APIResponse,就可以标记上这个注解:
@GetMapping("client")
@NoAPIResponse
public String client(@RequestParam(value = "error", defaultValue = "0") int error)3、要考虑接口变迁的版本控制策略
① 第一,版本策略最好一开始就考虑。
URL Path 的方式最直观也最不容易出错;QueryString 不易携带,不太推荐作为公开 API 的版本策略;HTTP 头的方式比较没有侵入性,如果仅仅是部分接口需要进行版本控制,可以考虑这种方式。
② 第二,版本实现方式要统一。
框架层面实现统一。如果你使用 Spring 框架的话,可以按照下面的方式自定义RequestMappingHandlerMapping 来实现。
a、首先,创建一个注解来定义接口的版本。@APIVersion 自定义注解可以应用于方法或 Controller 上:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface APIVersion {
String[] value();
}然后,定义一个 APIVersionHandlerMapping 类继承 RequestMappingHandlerMapping。
RequestMappingHandlerMapping 的作用,是根据类或方法上的 @RequestMapping 来生成 RequestMappingInfo 的实例。我们覆盖 registerHandlerMethod 方法的实现,从 @APIVersion 自定义注解中读取版本信息,拼接上原有的、不带版本号的 URL Pattern,构成新的 RequestMappingInfo,来通过注解的方式为接口增加基于 URL 的版本号:
public class APIVersionHandlerMapping extends RequestMappingHandlerMapping {
@Override
protected boolean isHandler(Class<?> beanType) {
return AnnotatedElementUtils.hasAnnotation(beanType, Controller.class);
}
@Override
protected void registerHandlerMethod(Object handler, Method method, RequestMappingInfo mapping) {
Class<?> controllerClass = method.getDeclaringClass();
//类上的APIVersion注解
APIVersion apiVersion = AnnotationUtils.findAnnotation(controllerClass, APIVersion.class);
//方法上的APIVersion注解
APIVersion methodAnnotation = AnnotationUtils.findAnnotation(method, APIVersion.class);
//以方法上的注解优先
if (methodAnnotation != null) {
apiVersion = methodAnnotation;
}
String[] urlPatterns = apiVersion == null ? new String[0] : apiVersion.value();
PatternsRequestCondition apiPattern = new PatternsRequestCondition(urlPatterns);
PatternsRequestCondition oldPattern = mapping.getPatternsCondition();
PatternsRequestCondition updatedFinalPattern = apiPattern.combine(oldPattern);
//重新构建RequestMappingInfo
mapping = new RequestMappingInfo(mapping.getName(), updatedFinalPattern, mapping.getMethodsCondition(),
mapping.getParamsCondition(), mapping.getHeadersCondition(), mapping.getConsumesCondition(),
mapping.getProducesCondition(), mapping.getCustomCondition());
super.registerHandlerMethod(handler, method, mapping);
}
}最后,也是特别容易忽略的一点,要通过实现 WebMvcRegistrations 接口,来生效自定义的 APIVersionHandlerMapping:
@SpringBootApplication
public class CommonMistakesApplication implements WebMvcRegistrations {
...
@Override
public RequestMappingHandlerMapping getRequestMappingHandlerMapping() {
return new APIVersionHandlerMapping();
}
}这样,就实现了在 Controller 上或接口方法上通过注解,来实现以统一的 Pattern 进行版本号控制:
@GetMapping(value = "/api/user")
@APIVersion("v4")
public int right4() {
return 4;
}加上注解后,访问浏览器查看效果:

4、接口处理方式要明确同步还是异步
① 同步上传接口 syncUpload;
② 异步上传接口 asyncUpload,搭配 syncQueryUploadTask 查询上传结果。
三、缓存设计
1、不要把 Redis 当作数据库
① 第一,从客户端的角度来说,缓存数据的特点一定是有原始数据来源,且允许丢失,即使设置的缓存时间是 1 分钟,在 30 秒时缓存数据因为某种原因消失了,我们也要能接受。当数据丢失后,我们需要从原始数据重新加载数据,不能认为缓存系统是绝对可靠的,更不能认为缓存系统不会删除没有过期的数据。
② 第二,从 Redis 服务端的角度来说,缓存系统可以保存的数据量一定是小于原始数据的。首先,我们应该限制 Redis 对内存的使用量,也就是设置 maxmemory 参数;其次,我们应该根据数据特点,明确 Redis 应该以怎样的算法来驱逐数据。
2、注意缓存雪崩问题
① 产生原因
a、第一种是,缓存系统本身不可用,导致大量请求直接回源到数据库;
b、第二种是,应用设计层面大量的 Key 在同一时间过期,导致大量的数据回源。
② 解决方案
a、差异化缓存过期时间,不要让大量的 Key 在同一时间过期。
b、让缓存不主动过期。初始化缓存数据的时候设置缓存永不过期,然后启动一个后台线程 30 秒一次定时把所有数据更新到缓存,而且通过适当的休眠,控制从数据库更新数据的频率,降低数据库压力
③ 注意点:
a、方案一和方案二是截然不同的两种缓存方式,如果无法全量缓存所有数据,那么只能使用方案一;
b、即使使用了方案二,缓存永不过期,同样需要在查询的时候,确保有回源的逻辑。正如之前所说,我们无法确保缓存系统中的数据永不丢失。
c、不管是方案一还是方案二,在把数据从数据库加入缓存的时候,都需要判断来自数据库的数据是否合法,比如进行最基本的判空检查。
3、注意缓存击穿问题
① 原因:
在某些 Key 属于极端热点数据,且并发量很大的情况下,如果这个 Key 过期,可能会在某个瞬间出现大量的并发请求同时回源,相当于大量的并发请求直接打到了数据库。这种情况,就是我们常说的缓存击穿或缓存并发问题。
② 解决方案:
a、方案一,使用进程内的锁进行限制,这样每一个节点都可以以一个并发回源数据库;
b、方案二,不使用锁进行限制,而是使用类似 Semaphore 的工具限制并发数,比如限制为 10,这样既限制了回源并发数不至于太大,又能使得一定量的线程可以同时回源。
4、注意缓存穿透问题
① 原因:
缓存回源的逻辑都是当缓存中查不到需要的数据时,回源到数据库查询。这里容易出现的一个漏洞是,缓存中没有数据不一定代表数据没有缓存,还有一种可能是原始数据压根就不存在。
② 解决方案:
a、方案一,对于不存在的数据,同样设置一个特殊的 Value 到缓存中,比如当数据库中查出的用户信息为空的时候,设置 NODATA 这样具有特殊含义的字符串到缓存中。这种方式可能会把大量无效的数据加入缓存中,如果担心大量无效数据占满缓存的话还可以考虑方案二,
b、方案二、即使用布隆过滤器做前置过滤。
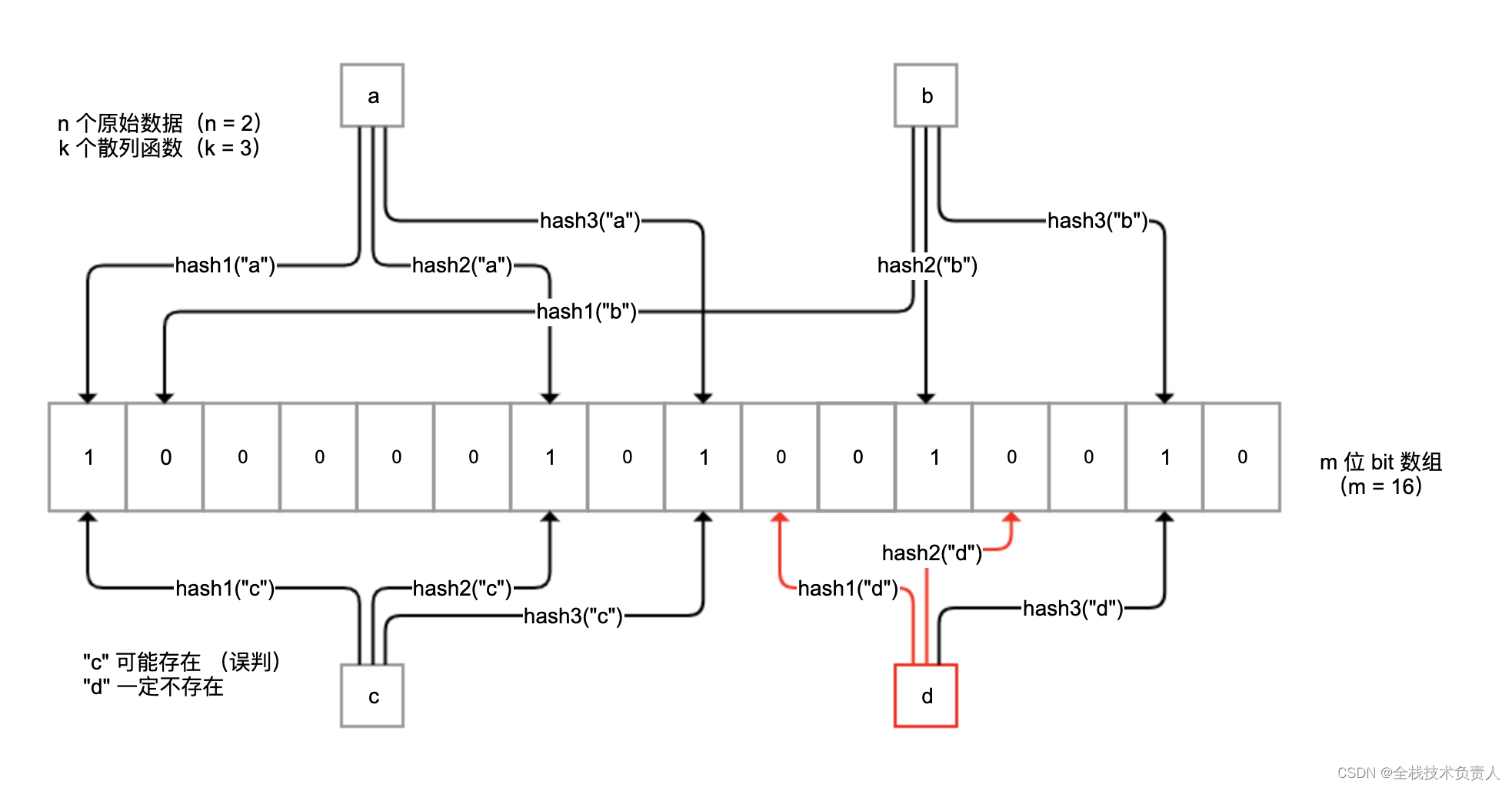
布隆过滤器是一种概率型数据库结构,由一个很长的二进制向量和一系列随机映射函数组成。它的原理是,当一个元素被加入集合时,通过 k 个散列函数将这个元素映射成一个 m 位 bit 数组中的 k 个点,并置为 1。
检索时,我们只要看看这些点是不是都是 1 就(大概)知道集合中有没有它了。如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。
5、注意缓存数据同步策略
① “先更新数据库再删除缓存,访问的时候按需加载数据到缓存。
需要注意的是,更新数据库后删除缓存的操作可能失败,如果失败则考虑把任务加入延迟队列进行延迟重试,确保数据可以删除,缓存可以及时更新。因为删除操作是幂等的,所以即使重复删问题也不是太大,这又是删除比更新好的一个原因。
四、业务代码写完,就意味着生产就绪了
1、提供健康检测接口
我们应该提供一个专有的监控检测接口,并尽可能触达一些内部组件。
2、暴露应用内部信息
应用内部诸如线程池、内存队列等组件,往往在应用内部扮演了重要的角色,如果应用或应用框架可以对外暴露这些重要信息,并加以监控,那么就有可能在诸如 OOM 等重大问题暴露之前发现蛛丝马迹,避免出现更大的问题。
3、建立应用指标 Metrics 监控
一是,应用内部重要组件的指标监控,比如 JVM 的一些指标、接口的 QPS 等;
二是,应用的业务数据的监控,比如电商订单量、游戏在线人数等。
4、全链路追踪的原理是:
① 请求进入第一个组件时,先生成一个 TraceID,作为整个调用链(Trace)的唯一标识
② 对于每次操作,都记录耗时和相关信息形成一个 Span 挂载到调用链上,Span 和 Span 之间同样可以形成树状关联,出现远程调用、跨系统调用的时候,把 TraceID 进行透传(比如,HTTP 调用通过请求透传,MQ 消息则通过消息透传);
③ 把这些数据汇总提交到数据库中,通过一个 UI 界面查询整个树状调用链
五、异步处理
1、适用场景:
① 服务于主流程的分支流程。比如,在注册流程中,把数据写入数据库的操作是主流程,但注册后给用户发优惠券或欢迎短信的操作是分支流程,时效性不那么强,可以进行异步处理。
② 用户不需要实时看到结果的流程。比如,下单后的配货、送货流程完全可以进行异步处理,每个阶段处理完成后,再给用户发推送或短信让用户知晓即可。
2、问题:
① 可靠性问题
② 消息发送模式的区分问题
③ 大量死信消息堵塞队列
3、异步处理需要消息补偿闭环
① 对于异步处理流程,必须考虑补偿或者说建立主备双活流程。

蓝色的线,使用 MQ 进行的异步处理,我们称作主线,可能存在消息丢失的情况(虚线代表异步调用);
绿色的线,使用补偿 Job 定期进行消息补偿,我们称作备线,用来补偿主线丢失的消息;
考虑到极端的 MQ 中间件失效的情况,我们要求备线的处理吞吐能力达到主线的能力水平。
② 对于 MQ 消费程序,处理逻辑务必考虑去重(支持幂等),原因有几个:
a、MQ 消息可能会因为中间件本身配置错误、稳定性等原因出现重复。
b、自动补偿重复,比如本例,同一条消息可能既走 MQ 也走补偿,肯定会出现重复,而且考虑到高内聚,补偿 Job 本身不会做去重处理。
c、人工补偿重复。
③ 补偿逻辑
考虑配置补偿的频次、每次处理数量,以及补偿线程池大小等参数为合适的值,以满足补偿的吞吐量。
考虑备线补偿数据进行适当延迟。比如,对注册时间在 30 秒之前的用户再进行补偿,以方便和主线 MQ 实时流程错开,避免冲突。
诸如当前补偿到哪个用户的 offset 数据,需要落地数据库。
补偿 Job 本身需要高可用,可以使用类似 XXLJob 或 ElasticJob 等任务系统。
4、注意消息模式是广播还是工作队列
消息广播,和我们平时说的“广播”意思差不多,就是希望同一条消息,不同消费者都能分别消费;
而队列模式,就是不同消费者共享消费同一个队列的数据,相同消息只能被某一个消费者消费一次。
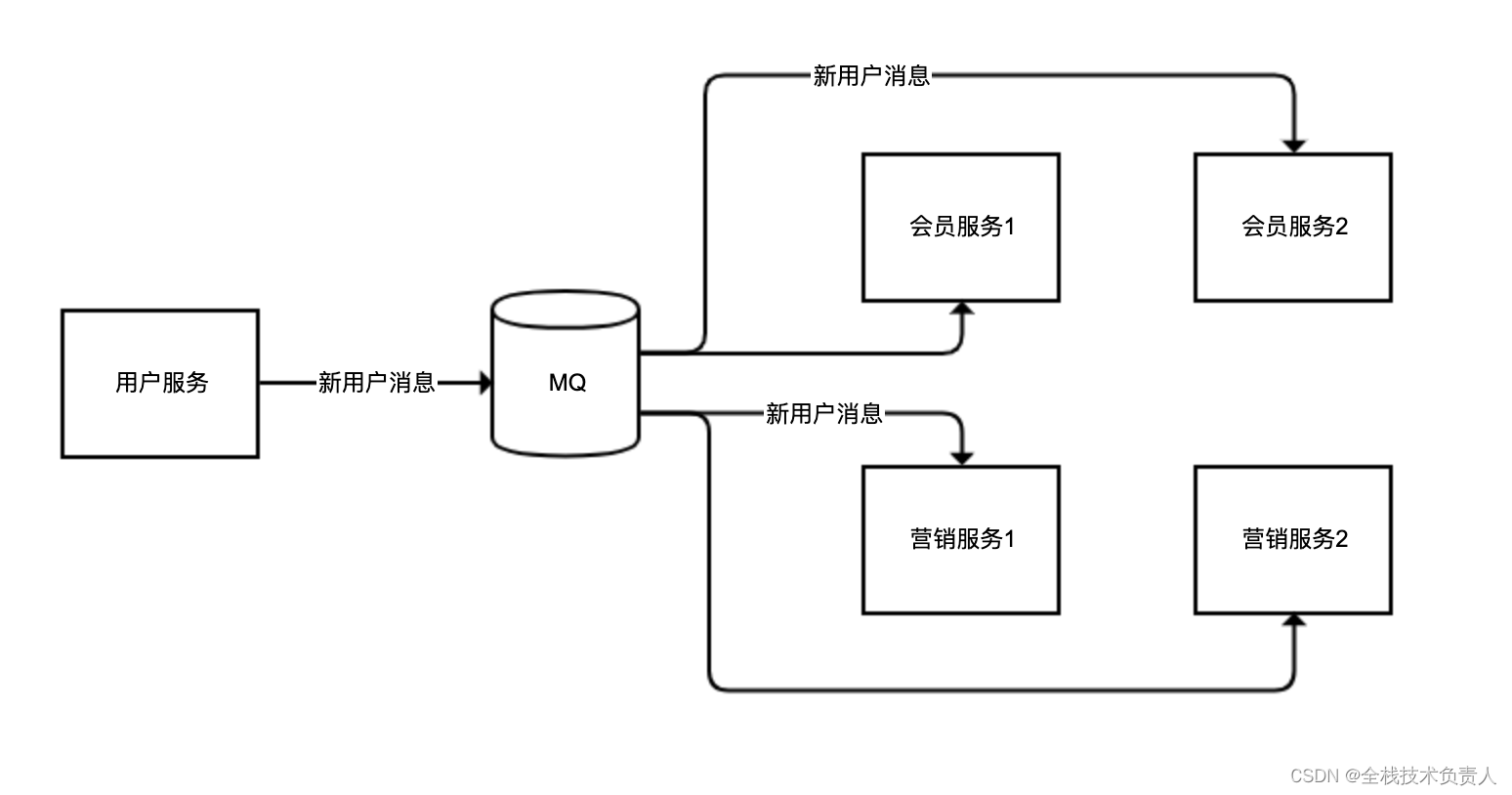
① 实现会员服务监听用户服务发出的新用户注册消息的那部分逻辑
错误示例:
//为了代码简洁直观,我们把消息发布者、消费者、以及MQ的配置代码都放在了一起
@Slf4j
@Configuration
@RestController
@RequestMapping("workqueuewrong")
public class WorkQueueWrong {
private static final String EXCHANGE = "newuserExchange";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//使用匿名队列作为消息队列
@Bean
public Queue queue() {
return new AnonymousQueue();
}
//声明DirectExchange交换器,绑定队列到交换器
@Bean
public Declarables declarables() {
DirectExchange exchange = new DirectExchange(EXCHANGE);
return new Declarables(queue(), exchange,
BindingBuilder.bind(queue()).to(exchange).with(""));
}
//监听队列,队列名称直接通过SpEL表达式引用Bean
@RabbitListener(queues = "#{queue.name}")
public void memberService(String userName) {
log.info("memberService: welcome message sent to new user {} from {}", userName, System.getProperty("server.port"));
}
} 结果:同一个会员服务两个实例都收到了消息:
RabbitMQ 直接交换器和队列的绑定关系
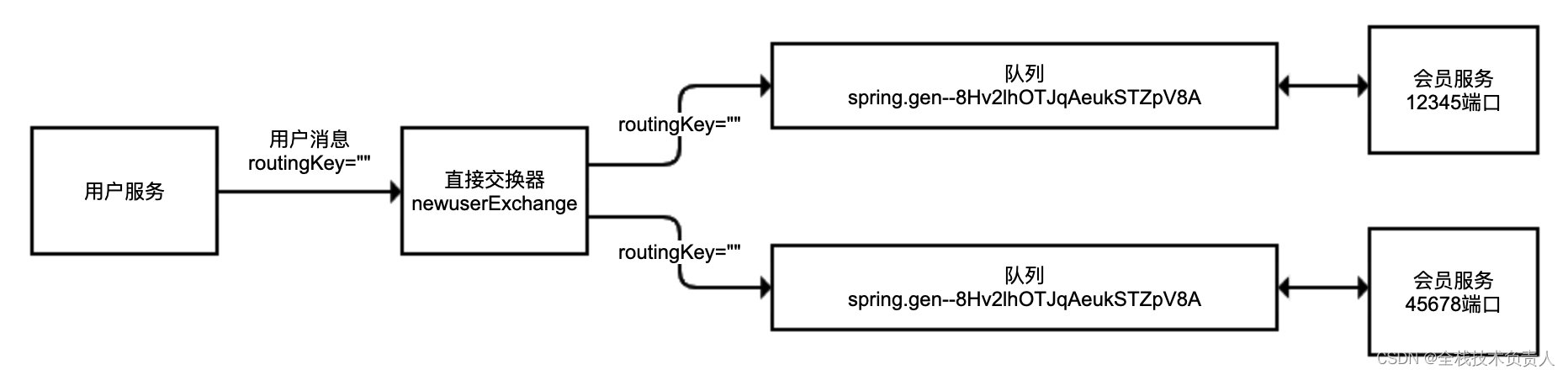
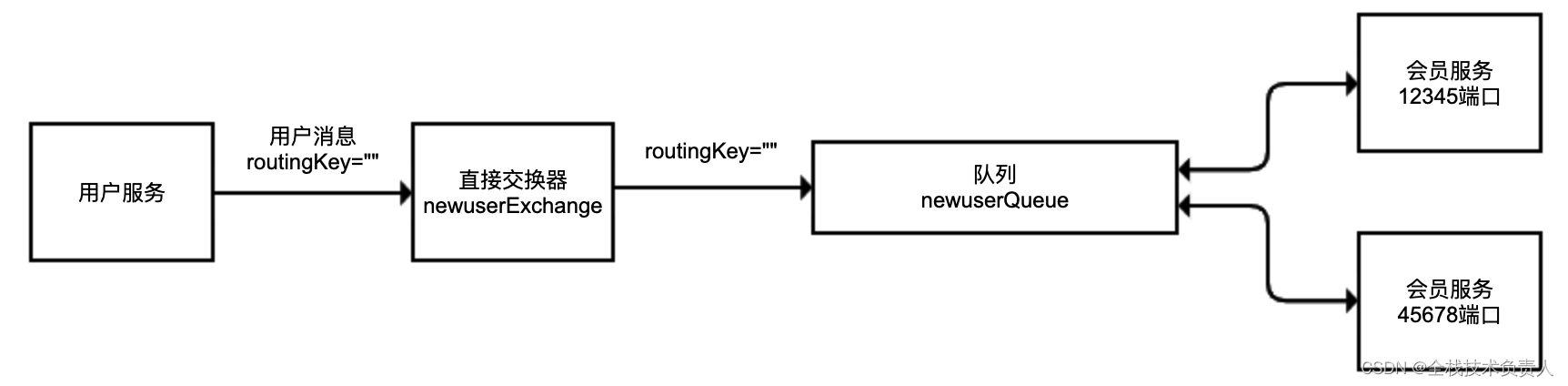
解决问题:对于会员服务不要使用匿名队列,而是使用同一个队列即可。把上面代码中的匿名队列替换为一个普通队列:
private static final String QUEUE = "newuserQueue";
@Bean
public Queue queue() {
return new Queue(QUEUE);
}
② 进一步完整实现用户服务需要广播消息给会员服务和营销服务的逻辑
我们声明了一个队列和一个广播交换器 FanoutExchange,然后模拟两个用户服务和两个营销服务:
错误示例:
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutwrong")
public class FanoutQueueWrong {
private static final String QUEUE = "newuser";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//声明FanoutExchange,然后绑定到队列,FanoutExchange绑定队列的时候不需要routingKey
@Bean
public Declarables declarables() {
Queue queue = new Queue(QUEUE);
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
return new Declarables(queue, exchange,
BindingBuilder.bind(queue).to(exchange));
}
//会员服务实例1
@RabbitListener(queues = QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
//会员服务实例2
@RabbitListener(queues = QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
//营销服务实例1
@RabbitListener(queues = QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
//营销服务实例2
@RabbitListener(queues = QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}一条用户注册的消息,要么被会员服务收到,要么被营销服务收到,显然这不是广播
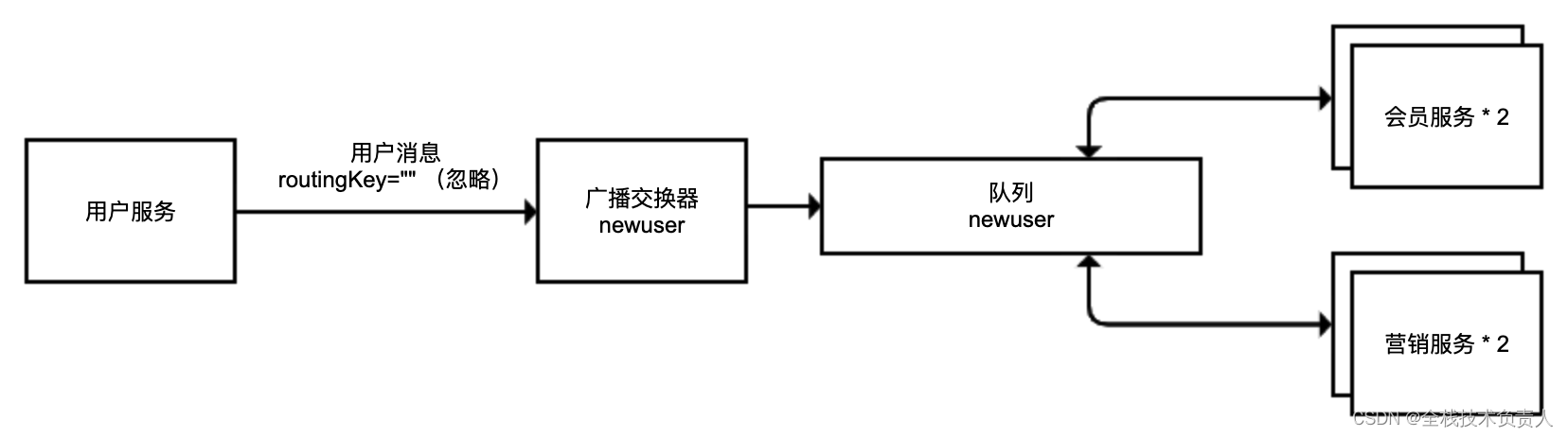
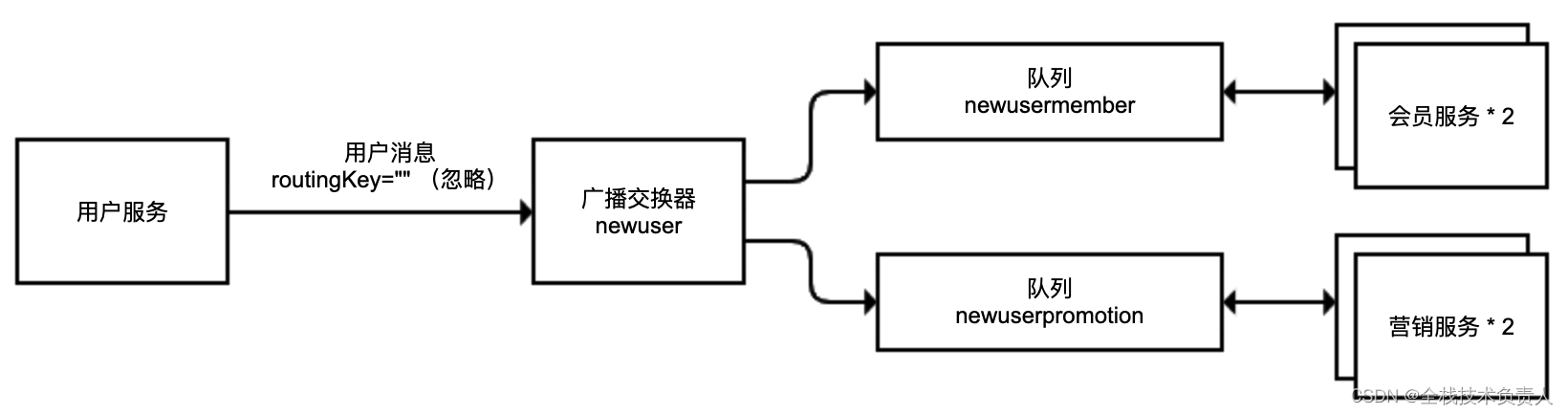
解决方案:我们把队列进行拆分,会员和营销两组服务分别使用一条独立队列绑定到广播交换器即可
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutright")
public class FanoutQueueRight {
private static final String MEMBER_QUEUE = "newusermember";
private static final String PROMOTION_QUEUE = "newuserpromotion";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
@Bean
public Declarables declarables() {
//会员服务队列
Queue memberQueue = new Queue(MEMBER_QUEUE);
//营销服务队列
Queue promotionQueue = new Queue(PROMOTION_QUEUE);
//广播交换器
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
//两个队列绑定到同一个交换器
return new Declarables(memberQueue, promotionQueue, exchange,
BindingBuilder.bind(memberQueue).to(exchange),
BindingBuilder.bind(promotionQueue).to(exchange));
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}
5、别让死信堵塞了消息队列
① 问题:
但在很多时候,消息队列的堆积堵塞,是因为有大量始终无法处理的消息。
最终 MQ 可能因为数据量过大而崩溃。
② 解决方案:

Spring AMQP 提供了非常方便的解决方案:
① 首先,定义死信交换器和死信队列。其实,这些都是普通的交换器和队列,只不过被我们专门用于处理死信消息。
② 然后,通过 RetryInterceptorBuilder 构建一个 RetryOperationsInterceptor,用于处理失败时候的重试。这里的策略是,最多尝试 5 次(重试 4 次);并且采取指数退避重试,首次重试延迟 1 秒,第二次 2 秒,以此类推,最大延迟是 10 秒;如果第 4 次重试还是失败,则使用 RepublishMessageRecoverer 把消息重新投入一个“死信交换器”中。
③ 最后,定义死信队列的处理程序。这个案例中,我们只是简单记录日志。
六、取长补短之 NoSQL vs MySQL
1、对比了缓存数据库 Redis、时间序列数据库 InfluxDB、搜索数据库 ES 和 MySQL 的性能。我们看到:
① Redis 对单条数据的读取性能远远高于 MySQL,但不适合进行范围搜索。
② InfluxDB 对于时间序列数据的聚合效率远远高于 MySQL,但因为没有主键,所以不是一个通用数据库。
③ ES 对关键字的全文搜索能力远远高于 MySQL,但是字段的更新效率较低,不适合保存频繁更新的数据。
2、设计了一个包含多个数据库系统的、能应对各种高并发场景的一套数据服务的系统架构,其中包含了同步写服务、异步写服务和查询服务三部分,分别实现主数据库写入、辅助数据库写入和查询路由。
我们按照服务来依次分析下这个架构。
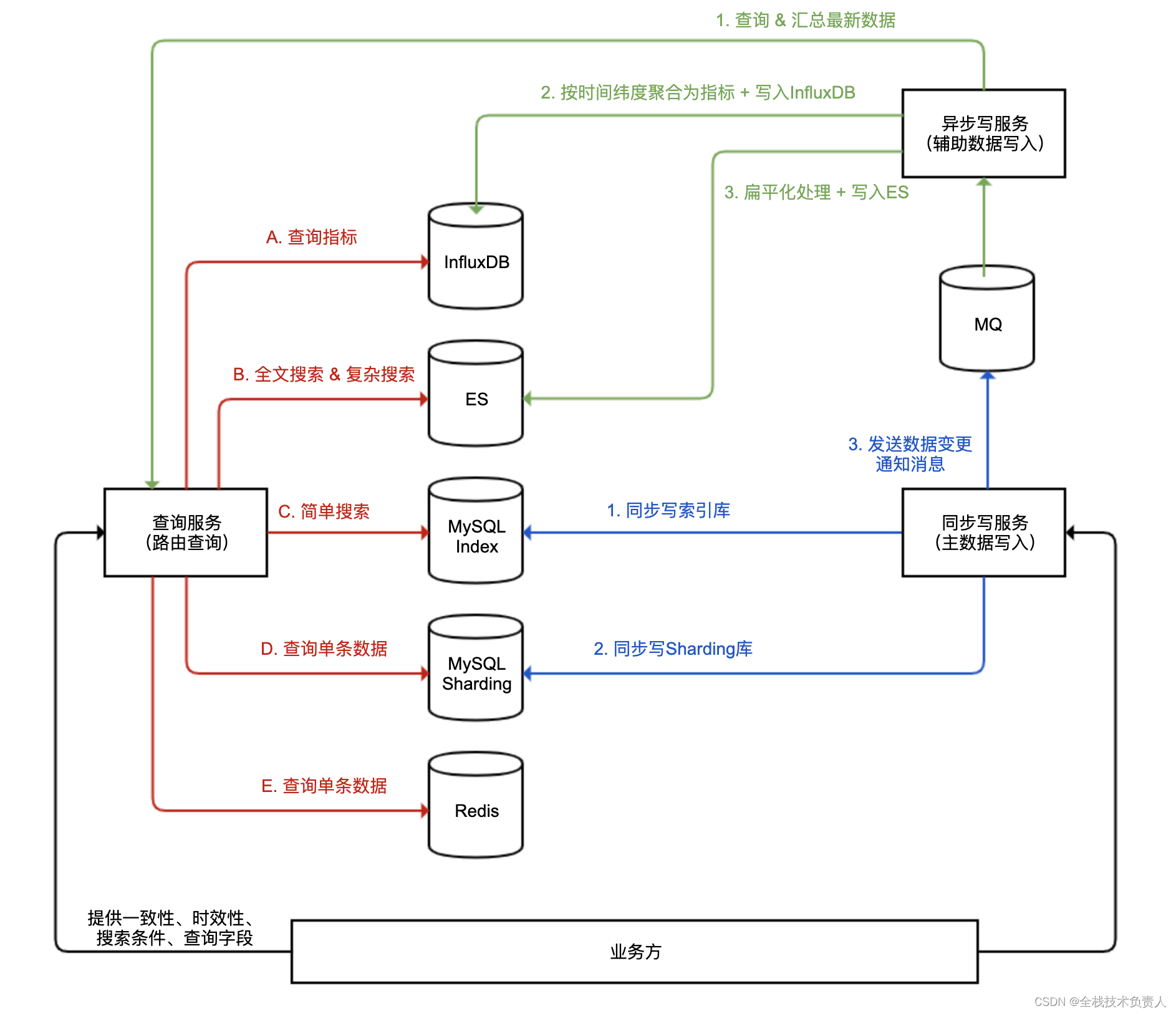
3、要的业务主数据只能保存在 MySQL 这样的关系型数据库中,原因有三点:
① RDBMS 经过了几十年的验证,已经非常成熟;
② RDBMS 的用户数量众多,Bug 修复快、版本稳定、可靠性很高;
③ RDBMS 强调 ACID,能确保数据完整。
4、有两种类型的查询任务可以交给 MySQL 来做,性能会比较好,这也是 MySQL 擅长的地方:
① 按照主键 ID 的查询。直接查询聚簇索引,其性能会很高。但是单表数据量超过亿级后,性能也会衰退,而且单个数据库无法承受超大的查询并发,因此我们可以把数据表进行 Sharding 操作,均匀拆分到多个数据库实例中保存。我们把这套数据库集群称作 Sharding 集群。
② 按照各种条件进行范围查询,查出主键 ID。对二级索引进行查询得到主键,只需要查询一棵 B+ 树,效率同样很高。但索引的值不宜过大,比如对 varchar(1000) 进行索引不太合适,而索引外键(一般是 int 或 bigint 类型)性能就会比较好。因此,我们可以在 MySQL 中建立一张“索引表”,除了保存主键外,主要是保存各种关联表的外键,以及尽可能少的 varchar 类型的字段。这张索引表的大部分列都可以建上二级索引,用于进行简单搜索,搜索的结果是主键的列表,而不是完整的数据。由于索引表字段轻量并且数量不多(一般控制在 10 个以内),所以即便索引表没有进行 Sharding 拆分,问题也不会很大。
5、同步写服务
写入两种 MySQL 数据表和发送 MQ 消息的这三步
6、异步写服务
选用了 ES 和 InfluxDB 这两种辅助数据库,因此整个异步写数据操作有三步:
① MQ 消息不一定包含完整的数据,甚至可能只包含一个最新数据的主键 ID,我们需要根据 ID 从查询服务查询到完整的数据。
② 写入 InfluxDB 的数据一般可以按时间间隔进行简单聚合,定时写入 InfluxDB。因此,这里会进行简单的客户端聚合,然后写入 InfluxDB。
③ ES 不适合在各索引之间做连接(Join)操作,适合保存扁平化的数据。比如,我们可以把订单下的用户、商户、商品列表等信息,作为内嵌对象嵌入整个订单 JSON,然后把整个扁平化的 JSON 直接存入 ES。
7、查询服务
① 如图中红色线所示,我们需要根据一定的上下文条件(比如查询一致性要求、时效性要求、搜索的条件、需要返回的数据字段、搜索时间区间等)来把请求路由到合适的数据库,并且做一些聚合处理:
② 需要根据主键查询单条数据,可以从 MySQL Sharding 集群或 Redis 查询,如果对实时性要求不高也可以从 ES 查询。
③ 按照多个条件搜索订单的场景,可以从 MySQL 索引表查询出主键列表,然后再根据主键从 MySQL Sharding 集群或 Redis 获取数据详情。
④ 各种后台系统需要使用比较复杂的搜索条件,甚至全文搜索来查询订单数据,或是定时分析任务需要一次查询大量数据,这些场景对数据实时性要求都不高,可以到 ES 进行搜索。此外,MySQL 中的数据可以归档,我们可以在 ES 中保留更久的数据,而且查询历史数据一般并发不会很大,可以统一路由到 ES 查询。
⑤ 监控系统或后台报表系统需要呈现业务监控图表或表格,可以把请求路由到 InfluxDB 查询。