DeepWalk Concept
图表示Graph Embedding based on Random Walk
-> Graph GNN based neighbor aggregation.
Graph Embedding使用低维稠密向量的形式表示图中的节点,使得在原始图中相似的节点在低维表达空间中也相似。
DeepWalk关键基础是Random Walk和word2vec,word2vec关键基础是SkipGram
->DeepWalk通过Random Walk方式在图中进行节点采样
-> node sequence来模拟语料库中的语料,进而使用word2vec学习图中节点与节点的共线关系
-> 相邻节点的权重矩阵,进而学习到节点的向量表示。
Random Walk
Random Walk用于随机生成一条节点序列node sequence。
随机游走是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
word2vec~CBOW model
词袋模型,CBOW的目标是根据上下文contextual words来预测当前中心词的概率,且上下文所有单词对当前中心词出现的概率影响权重是一样的,如在袋子中取词,取出足够数量的词就可以了,与取出词的先后顺序无关。
word2vec~skip-gram model
根据中心词来预测上下文词概率。
V,语料库词汇量
N,隐藏层神经单元数量 = word embedding size
C,窗口大小,是预测单词的最大的上下文位置,那么总共的上下文词位置数目K=2c,比如预测上下文单词窗口为2,那么我们将会在(t-2), (t-1), (t+1), (t+2)的上下文位置预测contextual word。
|v|,输入向量维度,one-hot编码
[|v|, N],hidden layer权重矩阵W的维度,权重矩阵每一列对应着一个神经元,执行Σ加权求和操作。
H[N],hidden layer输出向量,维度是N。
W’,输出层的权重矩阵,维度是[N, |v|]。
U,输出层的输出向量,概率向量,维度是|v|,没有激活成0-1向量。
输入:only one中心词v-dimensional one-hot向量。
输出:2*c上下文词的one-hot vectors!
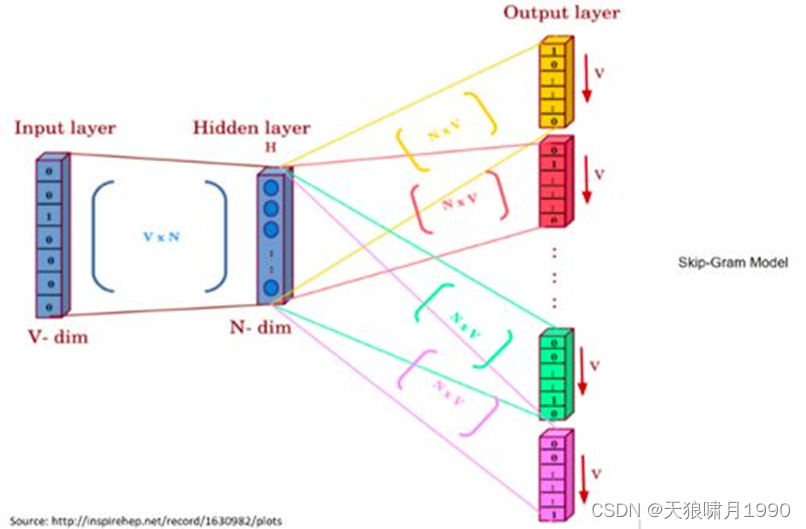
w(t)是中心词,也叫输入词input word,其中只有一个隐藏层,它执行权重矩阵和输入向量w(t)之间的点积运算。隐藏层中不需要使用激活函数。
然后,隐藏层中的点积运算结果被传送到输出层,输出层计算隐藏层输出向量和输出层权重矩阵之间的点积。
最后,使用softmax函数来计算在给定上下文位置中,输出层输出单词向量出现在w(t)上下文中的概率。
skip-gram steps
1) 利用one-hot编码将语料库单词转化为one-hot向量,这些向量维度[1,|V|]。
2) 输入中心词one-hot向量w(t)从|v|神经元被传递到hidden layer
3) 隐藏层执行权重矩阵W[|V|, N]和输入向量w(t)之间的点积运算。[1, V]*[V, N] -> [1, N]隐藏层不适用激活函数,所以H会直接传递到输出层。
4) 输出层执行H[1,N]和输出权重矩阵W'之间的点积运算,得到output vector u
5) 使用softmax函数,得到激活后的输出相邻output vector y。
如果要预测2c=K个上下文位置的contextual words,那么对于一个给定中心词w(t),要生成K个相同的contextual word vector,与真实的K个one-hot vector对比,继而进行反向传播更新权重,那么对于语料库中v个单词,总共的计算次数为|v|*K。
6) 通过交叉熵损失函数loss function来进行BP反向传播,更新权重矩阵W和W'。











![[附源码]Nodejs计算机毕业设计基于的学生事务管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/112ce9be309848b3916f3938d36fe268.png)