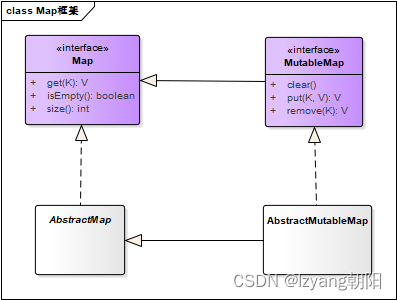
正交化(Orthogonalization)
老式电视机,有很多旋钮可以用来调整图像的各种性质,对于这些旧式电视,可能有一个旋钮用来调图像垂直方向的高度,另外有一个旋钮用来调图像宽度,也许还有一个旋钮用来调梯形角度,还有一个旋钮用来调整图像左右偏移,还有一个旋钮用来调图像旋转角度之类的。
在这种情况下,正交化指的是电视设计师设计这样的旋钮,使得每个旋钮都只调整一个性质,这样调整电视图像就容易得多,就可以把图像调到正中。
设计出正交化的控制装置,最理想的情况是和你实际想控制的性质一致,这样你调整参数时就容易得多。
确保四件事情。
1.首先,你通常必须确保至少系统在训练集上得到的结果不错,所以训练集上的表现必须通过某种评估,达到能接受的程度。
2.在训练集上表现不错之后,你就希望系统也能在开发集上有好的表现。
3.然后你希望系统在测试集上也有好的表现。
4.在最后,你希望系统在测试集上系统的成本函数在实际使用中表现令人满意。
如果你的算法在成本函数上不能很好地拟合训练集,你想要一个旋钮,、或者一组特定的旋钮,这样你可以用来确保你的可以调整你的算法,让它很好地拟合训练集,所以你用来调试的旋钮可能是训练更大的网络,或者可以切换到更好的优化算法,比如Adam优化算法,等等。
如果你的算法在训练集上做得很好,但开发集不行,然后你有一组正则化的旋钮可以调节,尝试让系统满足第二个条件。增大训练集可以是另一个可用的旋钮,它可以帮助你的学习算法更好地归纳开发集的规律。
如果它不符合第三个标准呢?如果系统在开发集上做的很好,但测试集上做得不好呢?如果是这样,那么你需要调的旋钮,可能是更大的开发集。因为如果它在开发集上做的不错,但测试集不行这可能意味着你对开发集过拟合了,你需要往回退一步,使用更大的开发集。
最后,如果它在测试集上做得很好,但无法给你的用户提供良好的体验,这意味着你需要回去,改变开发集或成本函数。因为如果根据某个成本函数,系统在测试集上做的很好,但它无法反映你的算法在现实世界中的表现,这意味着要么你的开发集分布设置不正确,要么你的成本函数测量的指标不对。
在机器学习中,如果你可以观察你的系统,如果它在训练集上做的不好、在开发集上做的不好、它在测试集上做的不好,或者它在测试集上做的不错,但在现实世界中不好,必须弄清楚到底是什么地方出问题了,然后我们刚好有对应的旋钮,或者一组对应的旋钮,刚好可以解决那个限制了机器学习系统性能的问题。
单一数字评估指标 (Single Number Evaluation Metric)
应用机器学习是一个非常经验性的过程,我们通常有一个想法,编程序,跑实验,看看效果如何,然后使用这些实验结果来改善你的想法,然后继续走这个循环,不断改进你的算法。
比如说对于一个的猫分类器,之前你搭建了某个分类器 A,通过改变超参数,还有改变训练集等手段,你现在训练出来了一个新的分类器 B,所以评估你的分类器的一个合理方式是观察它的查准率(precision)和查全率(recall)。
查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫。所以如果分类器 A 有95%的查准率,这意味着你的分类器说图片有猫的时候,有95%的机会真的是猫。
查全率就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比。实际为猫的图片中,有多少被系统识别出来?如果分类器 A 查全率是90%,这意味着对于所有的图像,比如说你的开发集都是真的猫图,分类器 A 准确地分辨出了其中的90%。
事实证明,查准率和查全率之间往往需要折衷,两个指标都要顾及到。你希望得到的效果是,当你的分类器说某个东西是猫的时候,有很大的机会它真的是一只猫,但对于所有是猫的图片,你也希望系统能够将大部分分类为猫,所以用查准率和查全率来评估分类器是比较合理的。
但使用查准率和查全率作为评估指标的时候,如果你尝试了很多不同想法,很多不同的超参数,你希望能够快速试验十几个分类器,快速选出 “最好的” 那个,如果使用查准率和查全率两个评估指标,分类器 A 在查全率上表现更好,分类器 B 在查准率上表现更好,你就无法判断哪个分类器更好,就很难去快速地二中选一或者十中选一,所以实际应用中并不推荐同时使用查准率和查全率来选择一个分类器。你只需要找到一个新的评估指标,能够结合查准率和查全率。
在机器学习文献中,结合查准率和查全率的标准方法是所谓的 F 1 F1 F1 分数。非正式的,你可以认为这是查准率 P 和查全率 R 的平均值。正式来看, F 1 F1 F1 分数的定义是这个公式: 2 1 P + 1 R \frac{2}{\frac{1}{P} + \frac{1}{R}} P1+R12
在数学中,这个函数叫做查准率 P 和查全率 R 的调和平均数。
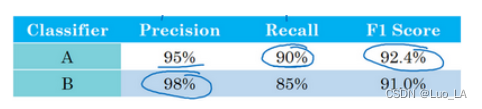
在上图这个例子中,你可以马上看出,分类器 A 的
F
1
F1
F1 分数更高。你可以快速选出分类器 A ,淘汰分类器 B 。
满足和优化指标 (Satisficing and Optimizing Metrics)
要把你顾及到的所有事情组合成单实数评估指标有时并不容易,在这些情况里,设立满足和优化指标是很重要的。
当选择一个分类器,能够最大限度提高准确度,但必须满足运行时间要求,例如对图像进行分类所需的时间必须小于等于100毫秒。所以在这种情况下,我们就说准确度是一个优化指标,因为你想要准确度最大化,你想做的尽可能准确,但是运行时间就是我们所说的满足指标,意思是它必须足够好,它只需要小于100毫秒,达到之后,你不在乎这指标有多好,或者至少你不会那么在乎。所以这是一个相当合理的权衡方式,或者说将准确度和运行时间结合起来的方式。实际情况可能是,只要运行时间少于100毫秒,你的用户就不会在乎运行时间是100毫秒还是50毫秒,甚至更快。
通过定义优化和满足指标,就可以给你提供一个明确的方式,去选择“最好的”分类器。
更一般地说,如果你要考虑 N 个指标,有时候选择其中一个指标做为优化指标是合理的。所以你想尽量优化那个指标,然后剩下 N − 1 个指标都是满足指标,意味着只要它们达到一定阈值,例如运行时间快于100毫秒,你不在乎它超过那个门槛之后的表现,但它们必须达到这个门槛。
训练/开发/测试集划分 (Train/Dev/Test Distribution)
设立训练集,开发集和测试集的方式大大影响了你或者你的团队在建立机器学习应用方面取得进展的速度。
开发(dev)集也叫做开发集(development set),有时称为保留交叉验证集(hold out cross validation set)。机器学习中的工作流程是,你尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善开发集的性能,直到最后你可以得到一个令你满意的成本,然后你再用测试集去评估。
在划分开发集和测试集时,应该将所有的数据随机洗牌,放入开发集和测试集,使得两部分数据是来自同一分布的。
开发集和测试集的大小 (Size of Dev and Test Sets)
你可能听说过一条经验法则,在机器学习中,把你取得的全部数据用70/30比例分成训练集和测试集。或者如果你必须设立训练集、开发集和测试集,你会这么分60%训练集,20%开发集,20%测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。
但在现代机器学习中,我们更习惯操作规模大得多的数据集,比如说你有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集,我们用 D 和 T 缩写来表示开发集和测试集。因为如果你有1百万个样本,那么1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时我们拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。
什么时候改变开发和测试集评估指标 (When to change dev/test sets and metrics)
前面已经讲过如何设置开发集和评估指标,就像是把目标定在某个位置,让你的团队瞄准。但有时候在项目进行途中,你可能意识到,目标的位置放错了。这种情况下,你应该移动你的目标。
方针是,如果你在指标上表现很好,在当前开发集或者开发集和测试集分布中表现很好,但你的实际应用程序,你真正关注的地方表现不好,那么就需要修改指标或者你的开发测试集。



![[maven]关于pom文件中的<relativePath>标签](https://img-blog.csdnimg.cn/115b4b8e909c4a2a83fe5dd16f9f3944.png)