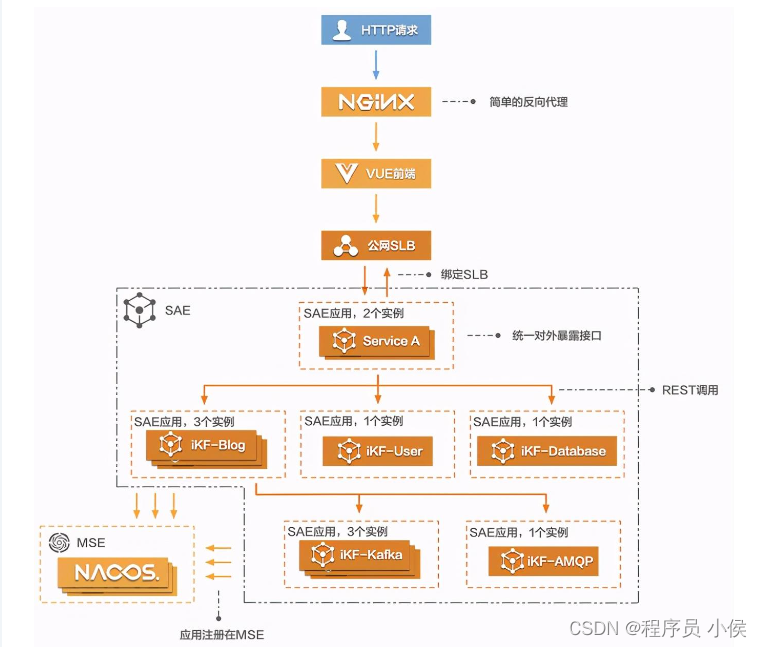
1.模型部署
首先拉取官方示例代码
git clone --recursive https://github.com/triton-inference-server/tutorials.git
cd tutorials/Conceptual_Guide/Part_1-model_deployment1.下载文本检测模型
wget https://www.dropbox.com/s/r2ingd0l3zt8hxs/frozen_east_text_detection.tar.gz
tar -xvf frozen_east_text_detection.tar.gz将得到frozen_east_text_detection.pb模型文件
将模型导出为onnx
pip install -U tf2onnx
pip install tensorflow==2.12.0
python -m tf2onnx.convert --input frozen_east_text_detection.pb --inputs "input_images:0" --outputs "feature_fusion/Conv_7/Sigmoid:0","feature_fusion/concat_3:0" --output detection.onnx转换命令的含义如下:
-
python -m tf2onnx.convert: 这部分是执行Python模块tf2onnx.convert的命令,它用于执行模型转换操作。 -
--input frozen_east_text_detection.pb: 这是您要转换的TensorFlow模型的输入文件名。frozen_east_text_detection.pb是Frozen TensorFlow模型的文件名,其中包含模型结构和权重。 -
--inputs "input_images:0": 这是指定TensorFlow模型的输入节点的参数。在TensorFlow模型中,通常有多个输入节点,这里"input_images:0"指定了模型的一个输入节点,其中input_images是输入节点的名称,:0表示该节点的输出索引。 -
--outputs "feature_fusion/Conv_7/Sigmoid:0","feature_fusion/concat_3:0": 这是指定TensorFlow模型的输出节点的参数。与输入节点类似,TensorFlow模型通常有多个输出节点,这里列出了两个输出节点的名称,用逗号分隔。 -
--output detection.onnx: 这是转换后的ONNX模型的输出文件名。detection.onnx是您希望为ONNX模型指定的输出文件名。
目的是将TensorFlow模型 frozen_east_text_detection.pb 转换为ONNX格式,并指定了输入节点和输出节点的信息,最终将转换后的模型保存为 detection.onnx 文件。
执行情况如下
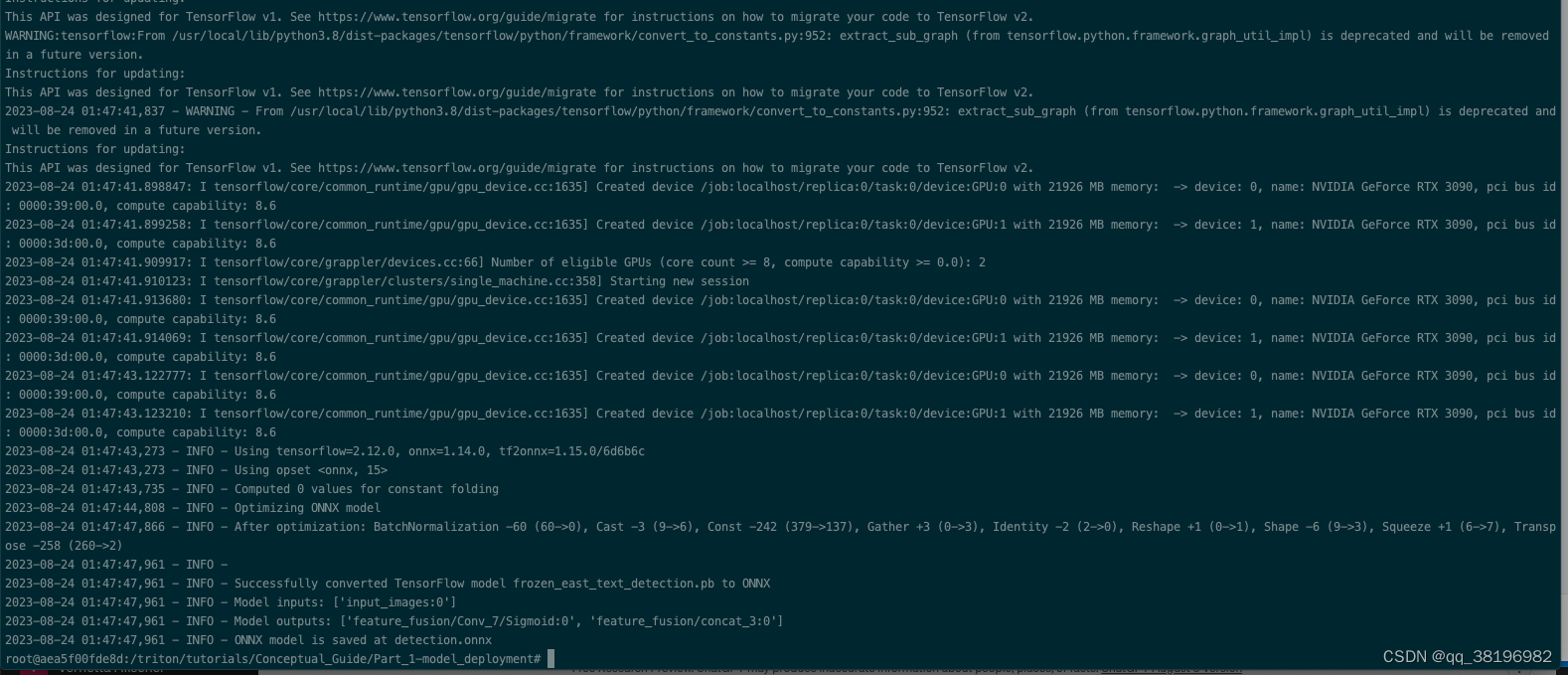
结果将得到detection.onnx模型文件
 2.下载文本识别模型
2.下载文本识别模型
下载文本识别模型权重
wget https://www.dropbox.com/sh/j3xmli4di1zuv3s/AABzCC1KGbIRe2wRwa3diWKwa/None-ResNet-None-CTC.pth将得到None-ResNet-None-CTC.pth模型文件
代码如下
将None-ResNet-None-CTC.pth模型文件转换为onnx格式,转换时要用到utils目录下的model.py文件,创建pt2onnx.py文件,文件内容如下:
import torch
from utils.model import STRModel
# Create PyTorch Model Object
model = STRModel(input_channels=1, output_channels=512, num_classes=37)
# Load model weights from external file
state = torch.load("None-ResNet-None-CTC.pth")
state = {key.replace("module.", ""): value for key, value in state.items()}
model.load_state_dict(state)
# Create ONNX file by tracing model
trace_input = torch.randn(1, 1, 32, 100)
torch.onnx.export(model, trace_input, "str.onnx", verbose=True)这段代码的解释如下:
1. `import torch`: 导入PyTorch库。
2. `from utils.model import STRModel`: 从 `utils.model` 模块中导入 `STRModel` 类。这个类可能是您自己定义的,用于创建模型。
3. `model = STRModel(input_channels=1, output_channels=512, num_classes=37)`: 创建了一个 `STRModel` 的实例,这是您定义的模型类。您为模型的构造函数传递了三个参数:`input_channels` 表示输入通道数为1,`output_channels` 表示输出通道数为512,`num_classes` 表示分类的类别数为37。
4. `state = torch.load("None-ResNet-None-CTC.pth")`: 使用PyTorch的 `torch.load` 函数从文件 "None-ResNet-None-CTC.pth" 中加载模型的权重和状态,并将其保存在 `state` 变量中。
5. `state = {key.replace("module.", ""): value for key, value in state.items()}`: 这一行代码可能用于处理加载的模型状态字典,将其中的键名中的 "module." 字符串去掉。通常,当模型在多个GPU上进行训练时,模型的状态字典中的键名可能包含 "module." 前缀,这里将其移除以适应模型。
6. `model.load_state_dict(state)`: 使用加载的状态字典 `state` 来加载模型 `model` 的权重和状态。
7. `trace_input = torch.randn(1, 1, 32, 100)`: 创建一个随机的PyTorch张量 `trace_input`,用于模型的追踪(tracing)。这个张量的形状是 (1, 1, 32, 100),表示一个输入样本,通道数为1,高度为32,宽度为100。
8. `torch.onnx.export(model, trace_input, "str.onnx", verbose=True)`: 使用PyTorch的 `torch.onnx.export` 函数将模型 `model` 转换为ONNX格式,并保存为 "str.onnx" 文件。`trace_input` 是用于模型追踪的输入,"str.onnx" 是输出的ONNX文件的名称。`verbose=True` 参数用于启用详细输出,以便查看转换过程的信息。
总之,这段代码的目的是加载一个预训练的PyTorch模型,将其转换为ONNX格式,并保存为 "str.onnx" 文件。这可以用于在其他深度学习框架或推理引擎中使用模型。
这段代码的目的是加载一个预训练的PyTorch模型,将其转换为ONNX格式,并保存为 "str.onnx" 文件。这可以用于在其他深度学习框架或推理引擎中使用模型

现在我们的文本检测模型detection.onnx和文本识别模型str.onnx都准备好了
3.设置模型存储库
1.设置文件结构
Triton 可以从一个或多个本地可访问的文件路径、Google Cloud Storage、Amazon S3 和 Azure Storage 访问模型。无论位置在哪,但模型存储库的格式都是固定的,如下:
# Example repository structure
<model-repository>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...model-name:模型的识别名称。config.pbtxt:对于每个模型,用户可以定义模型配置。此配置至少需要定义:模型输入和输出的后端、名称、形状和数据类型。对于大多数流行的后端,此配置文件是使用默认值自动生成的。model_config配置文件的完整规范可以在protobuf 定义中找到。version:版本控制使同一模型的多个版本可供使用,具体取决于所选的策略。有关版本控制的更多信息。
每个模型在模型存储库中都可以有一个或多个版本,每个版本都存储在自己的,以数字命名的子目录中,子目录的名称对应模型的版本号。未按数字命名或名称以0开头的子目录将被忽略。每个模型配置都指定一个版本策略,未指定版本策略,默认使用最新版本(即版本号为1的目录)。通过在config.pbtxt里设置version_policy可以指定要加载哪些版本。主要有3种方式:
-
全部:模型存储库中可用的模型的所有版本都可用于推理.
version_policy: { all: {}} -
最新:只有存储库中模型的最新“n”个版本可用于推理。该模型的最新版本是数字上最大的版本号。
version_policy: { latest: { num_versions: 2}} -
Specific:只有特别列出的模型版本可用于推理。
version_policy: { specific: { versions: [1,3]}}
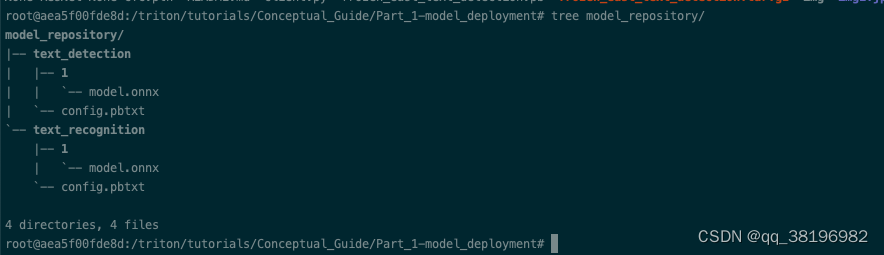
在官方示例中,已经创建了model_repository和子目录,以及config.pbtxt,只需要完成后续工作即可
mkdir -p model_repository/text_detection/1
mv detection.onnx model_repository/text_detection/1/model.onnx
mkdir -p model_repository/text_recognition/1
mv str.onnx model_repository/text_recognition/1/model.onnx此时model_repository的路径结构为
2.说一下config.pbtxt
打开model_repository/text_detection下的config.pbtxt
name: "text_detection"
backend: "onnxruntime"
max_batch_size : 0
input [
{
name: "input_images:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 3 ]
}
]
output [
{
name: "feature_fusion/Conv_7/Sigmoid:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 1 ]
}
]
output [
{
name: "feature_fusion/concat_3:0"
data_type: TYPE_FP32
dims: [ -1, -1, -1, 5 ]
}
]
- name代表模型的名称,是可选的,如果config.pbtxt里未指定模型的名称,则假定该名称与包含模该模型的模型存储库目录相同。若指定名称,则必须与包含模型的模型存储库目录的名称匹配,否则会报错。
- backend:必选,每个模型都必须与一个后端关联。对于使用 TensorRT 后端,此设置的值应为
tensorrt。同样,对于使用 PyTorch、ONNX 和 TensorFlow 后端,该backend字段应分别设置为pytorch、onnxruntime或tensorflow。对于所有其他后端,backend必须设置为后端的名称。某些后端可能还会检查platform模型分类的设置,例如,在 TensorFlow 后端中,根据模型格式platform应设置为tensorflow_savedmodel或tensorflow_graphdef。platform是否使用请参考具体后端仓库。 - platform:指定模型的运行平台,可选。未指定,Triton将根据后端的默认配置来选择运行平台,只有在需要将模型显式部署到特定硬件或平台上时才需要指定
platform字段。 - max_batch_size:可选,,但建议必填。指定模型可以处理的最大批次大小(batch size)。当模型支持动态批次大小(dynamic batch size),
max_batch_size设置为 0 ,即。动态批次大小意味着模型可以接受不同大小的批次,而不仅仅是一个特定大小的批次。这在一些应用中非常有用,因为它允许客户端根据需要发送不同大小的输入数据,而无需事先知道模型支持的批次大小。如果省略了max_batch_size,Triton Inference Server 会假定模型支持动态批处理,这意味着它可以处理不同大小的批次请求。这在某些情况下可能是有用的,但这也会使性能分析和配置管理更加复杂。 - input和output:输入和输出部分指定名称、形状、数据类型等
某些情况下,可以省略input和output部分,让 Triton 直接从模型文件中提取该信息。在这里,为了清楚起见,我们将它们包括在内,因为稍后我们需要知道客户端应用程序中输出张量的名称。
如果您的模型不支持动态批处理,仅支持特定批次大小,并且将 `max_batch_size` 设置为 0,但在实际使用中始终确保不超过特定批次大小,通常不会引发错误。 Triton Inference Server 将接受特定批次大小的请求,并在批次大小不匹配时拒绝请求。
然而,这不是一个推荐的做法,因为将 `max_batch_size` 设置为特定批次大小会更加明确和可维护。这有助于确保您的部署是可预测的,并且可以更容易地诊断问题,例如,如果某些请求不小心超过了特定批次大小。
因此,建议将 `max_batch_size` 设置为特定批次大小,以便您的配置更加清晰和可管理。
4.启动服务并测试
1.启动服务
/opt/tritonserver/bin/tritonserver --model-repository=/triton/tutorials/Conceptual_Guide/Part_1-model_deployment/model_repository启动成功,如下:
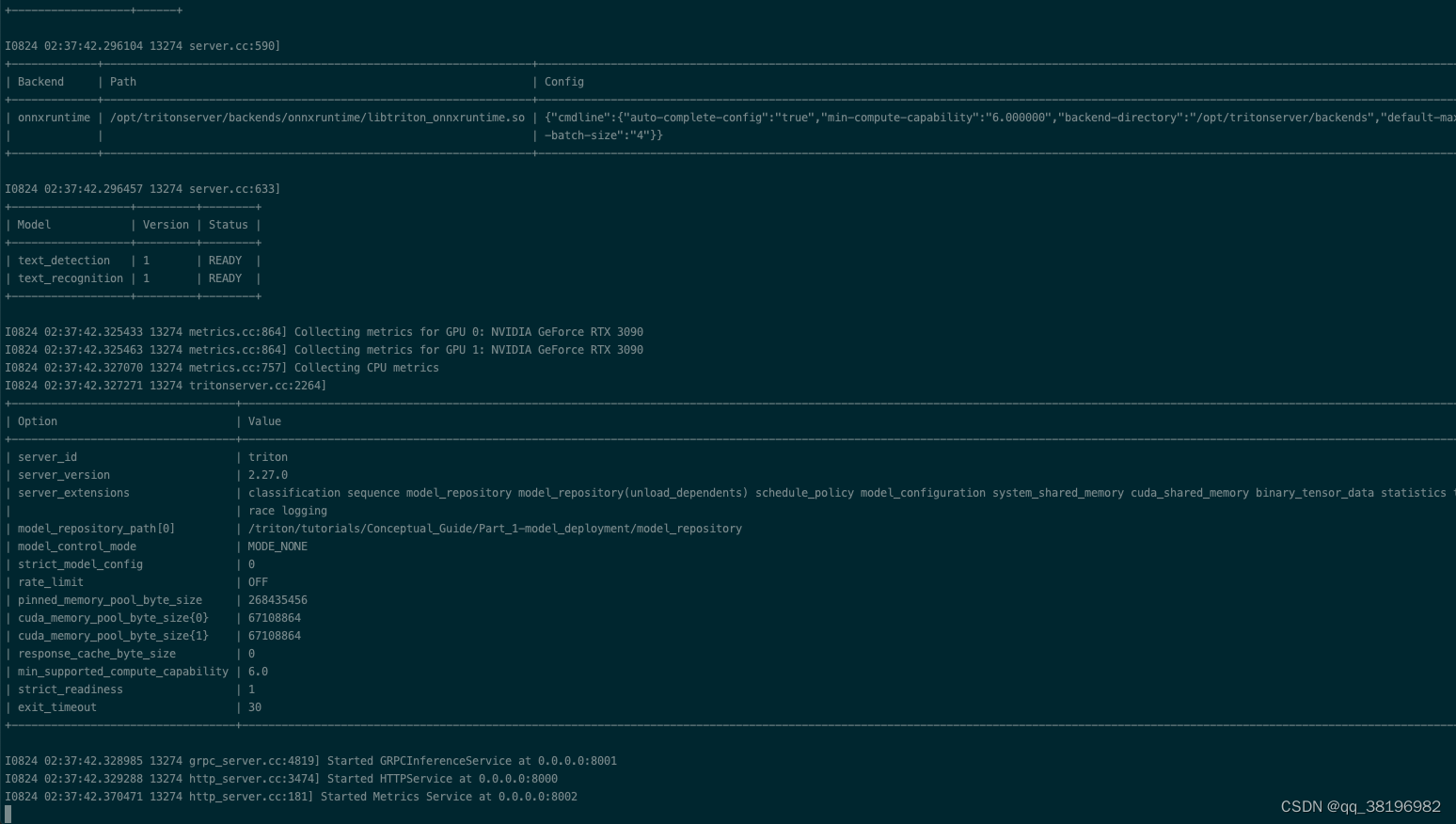
2.构建客户端应用程序
与 Triton 推理服务器交互的方式有以下三种:
- HTTP(S) API
- gRPC API
- 原生 C API
还有用 C++、Python 和 Java 封装 HTTP 和 gRPC API 的预构建客户端库。在官方示例中已经写好了client.py,直接执行即可。
识别结果是
stop
和/triton/tutorials/Conceptual_Guide/Part_1-model_deployment/img1.jpg一致

2.提高资源利用率
1.动态批处理
动态批处理是指Triton推理服务器允许将一个或多个推理请求组合成单个批次(必须动态创建)以最大化吞吐量的功能
通过在模型的config.pbtxt,添加如下参数启用动态批处理
dynamic_batching { }设置该参数之前,需要确保模型支持动态批处理,否则会导致推理失败会出错
Triton可以对传入的请求不加任何延迟,立即进行批处理,但用户可以选择为调度程序分配有限的延迟,以收集更多推理请求供动态批处理程序使用
dynamic_batching {
max_queue_delay_microseconds: 100
}假设有A、B、C、D、E五个请求,批量大小分别为4、2、2、6、2。每个批次需要花费模型Xms的处理时间。模型支持的最大批量大小为8,A和C在T=0时到达,B在T=x/3到达,D和E在T=2*x/3到达
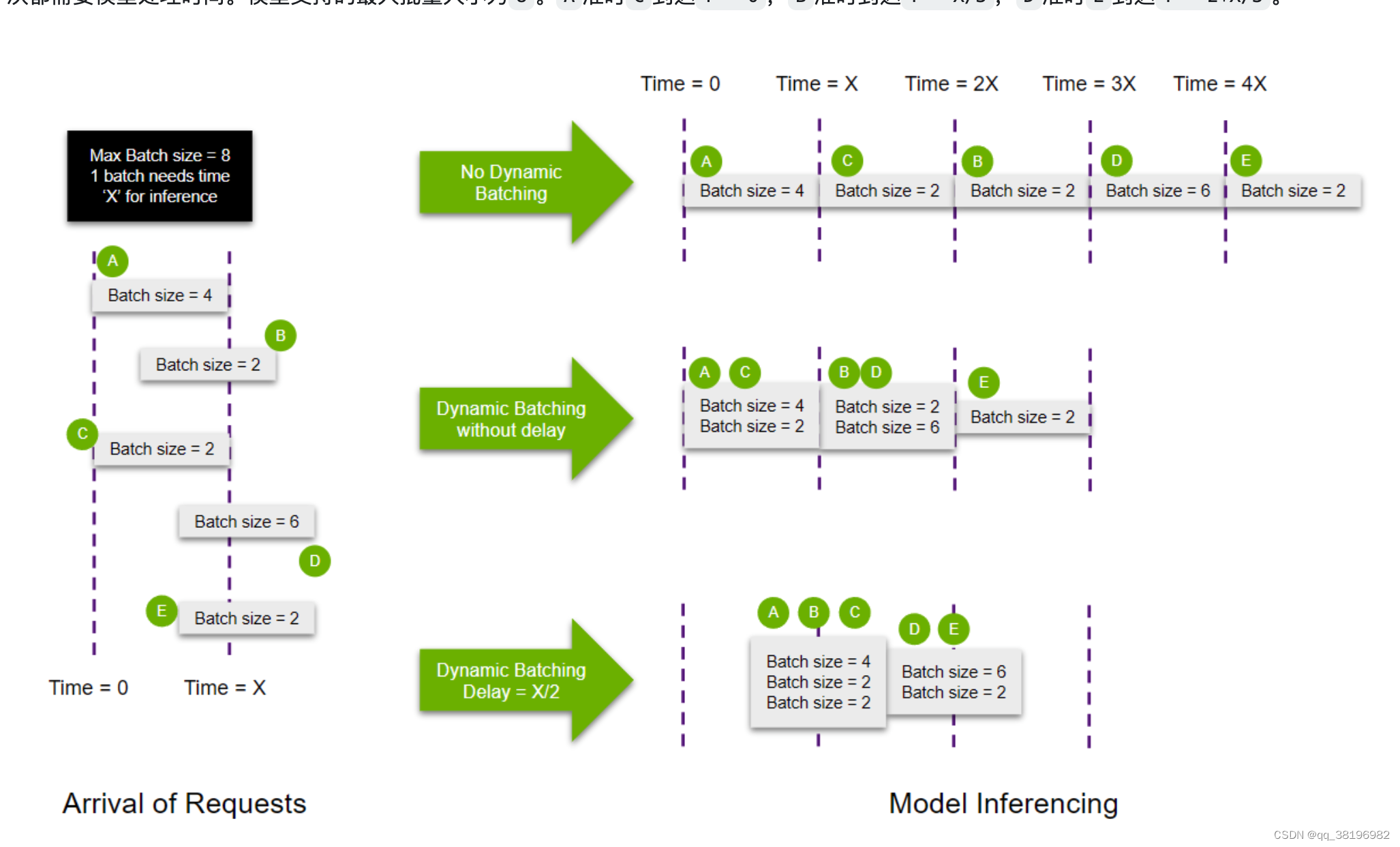
在不使用动态批处理时,所有请求顺序处理,要花费5Xms处理所有请求。
在这种情况下,使用动态批处理可以更有效地将请求打包到 GPU 内存中,从而显着加快处理时间(3X ms). 它还减少了响应的延迟,因为可以在更少的周期内处理更多的查询。delay如果考虑使用, A,B,C和D,E可以一起批处理以获得更好的资源利用率。
使用动态批处理可以改善模型服务时的延迟和吞吐量。此批处理功能主要致力于为无状态模型(在执行之间不维护状态的模型,如对象检测模型)提供解决方案。Triton 的序列批处理程序可用于管理有状态模型的多个推理请求。
2.并发模型执行
Triton推理服务器可以启动同一个模型的多个实例,从而并行处理查询。这是通过使用instance groups模型配置中的选项来启用的。
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0, 1 ]
}
] 仍然以上一个例子为例
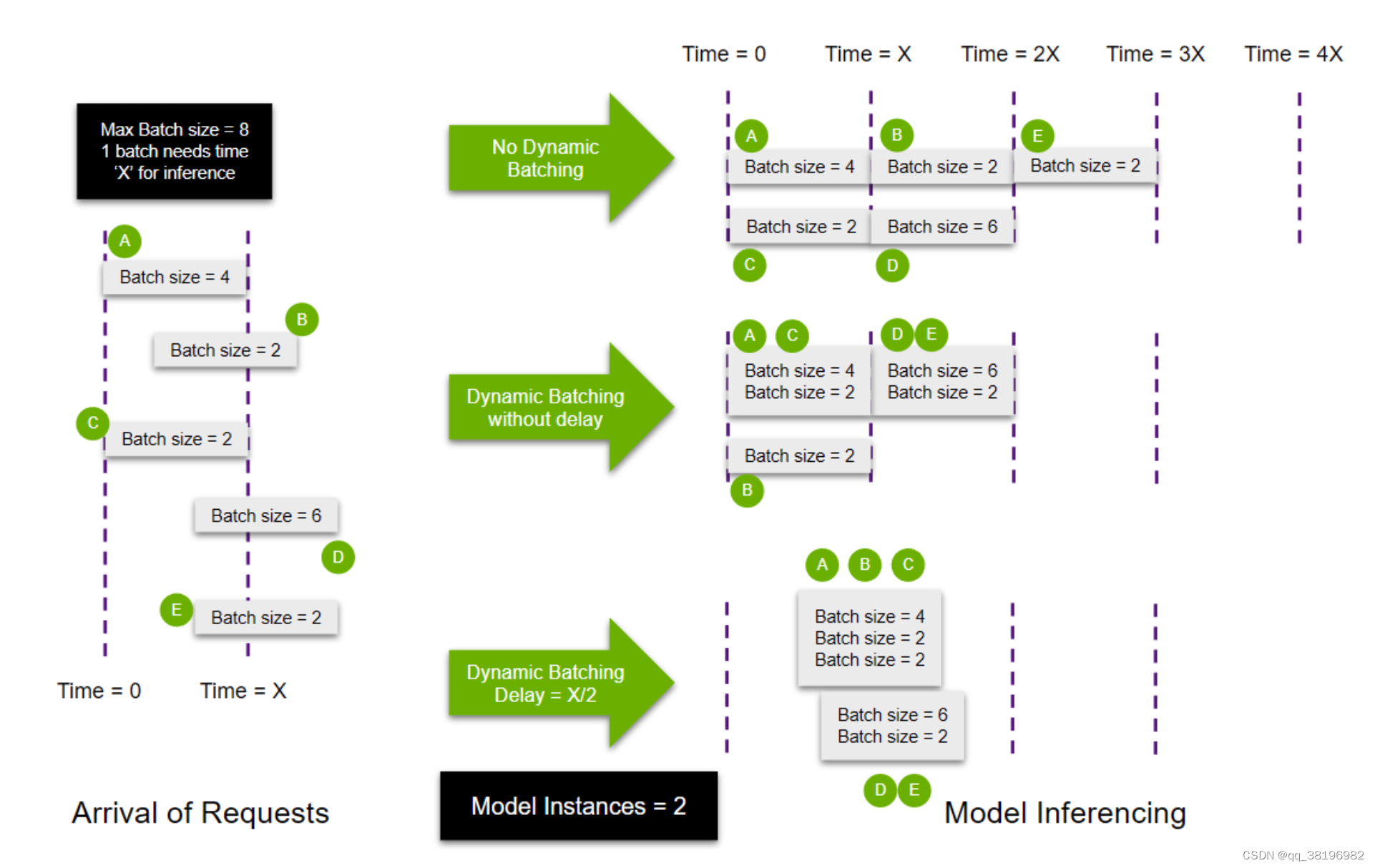
无动态批处理时 ,请求会平均分配。可以通过添加优先级来确定任何特定实例组的优先级或取消优先级
启用动态批处理时,AC同时到达,在第一个模型实例上运行。当B到达时,在第二个模型实例运行(这里我觉得官方图错了,B应该在T=X/3时刻开始运行)。DE同时到达时,等待AC处理结束放到第一个模型实例上运行
启动动态批处理且有延迟时,实例会等待T=X/2,在AC同时到达时,等待T时间才运行,前好等到B,一起作为一个批次开始运行;而DE同时到达时。实例2空闲,且DE的大小恰好等于动态批处理大小,无需等待,DE可以无延迟的在第二个实例上运行,开始推理。
动态批处理为什么可以提高性能?
1. **更高的吞吐量:** 动态批处理允许推理服务器同时处理多个推理请求,将它们分组成批次。这样,服务器可以一次性执行多个推理操作,而不是逐个处理请求。这提高了服务器的吞吐量,可以更快地完成一组请求。
2. **资源利用率提高:** 在动态批处理下,推理服务器更有效地使用计算资源,因为它将多个请求合并到一个批次中。这降低了处理请求时的开销,从而提高了资源利用率。
3. **降低延迟:** 批处理通常比单个请求的延迟更低,因为服务器可以同时处理多个请求。这对于需要快速响应的应用程序和服务非常重要。
4. **优化硬件加速器的使用:** 对于与硬件加速器(如GPU或TPU)一起使用的模型,批处理可以更有效地利用这些加速器的并行计算能力。这意味着在相同的时间内可以处理更多的推理请求。
5. **减少通信开销:** 在某些情况下,推理请求和响应之间的通信开销可能是性能瓶颈之一。通过将多个请求合并到批次中,可以减少通信次数,从而减少了这种开销。
一般情况下,可以将动态批处理和并发模型执行一起使用
3.示例
首先下载模型
cd /triton/tutorials/Conceptual_Guide/Part_2-improving_resource_utilization
cp -r ../Part_1-model_deployment/utils/ ./
wget https://www.dropbox.com/sh/j3xmli4di1zuv3s/AABzCC1KGbIRe2wRwa3diWKwa/None-ResNet-None-CTC.pth编写getmodel.py文件获取模型
注意:需要把Part_1目录下的utils拷贝到Part_2
import torch
from utils.model import STRModel
# Create PyTorch Model Object
model = STRModel(input_channels=1, output_channels=512, num_classes=37)
# Load model weights from external file
state = torch.load("None-ResNet-None-CTC.pth")
state = {key.replace("module.", ""): value for key, value in state.items()}
model.load_state_dict(state)
# Create ONNX file by tracing model
trace_input = torch.randn(1, 1, 32, 100)
torch.onnx.export(model, trace_input, "str.onnx", verbose=True, dynamic_axes={'input.1':[0],'308':[0]})和1.2获取str.onnx的代码区别在于最后一行
在第一段代码中,torch.onnx.export函数导出模型时,并未指定动态轴。这意味着导出的ONNX模型将具有静态形状,即输入和输出的形状在模型的生命周期中将保持不变。
而在第二段代码中,使用了dynamic_axes参数,并定义了'input.1'和'308'两个轴为动态轴。这意味着在导出的ONNX模型中,这两个轴的形状可以在推理时进行动态调整。通常,这在处理序列数据时非常有用,因为序列长度可能会变化。
执行文件获得str.onnx
mkdir -p model_repository/text_recognition/1
mv str.onnx model_repository/text_recognition/1/model.onnx此时Part_2文件结构为

1.启动模型
启动模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton/tutorials/Conceptual_Guide/Part_2-improving_resource_utilization/model_repository/启动成功
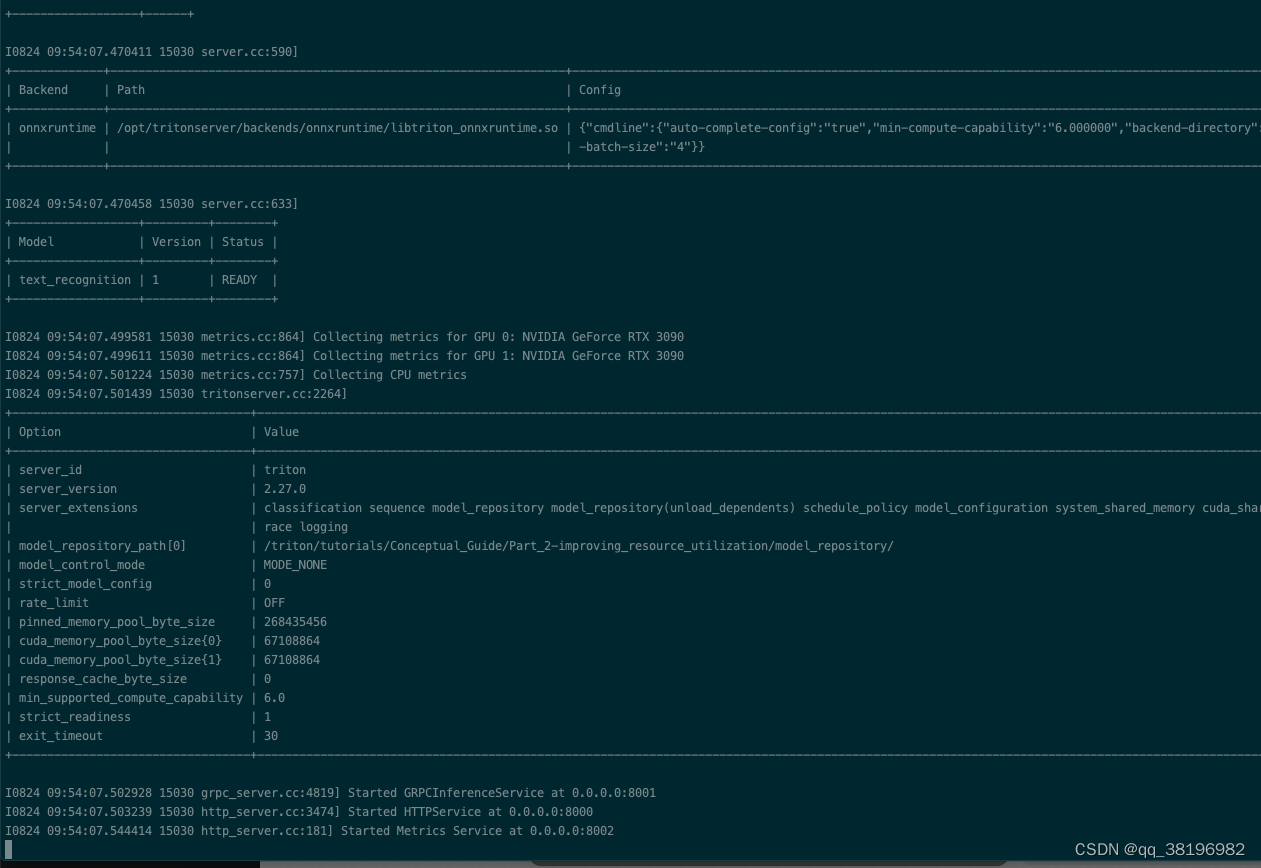 2.启动性能分析器
2.启动性能分析器
自行编译
git clone --depth 1 https://github.com/triton-inference-server/client
cd cliend
mkdir build
cd build
apt-get update
apt-get install libcurl4-openssl-dev
apt-get install libssl-dev libb64-dev
cmake -DTRITON_ENABLE_PERF_ANALYZER=ON -DTRITON_ENABLE_GPU=ON -DTRITON_ENABLE_PERF_ANALYZER_C_API=ON -DTRITON_ENABLE_PERF_ANALYZER_TS=ON -DTRITON_ENABLE_PERF_ANALYZER_TFS=ON ..
make -j32 cc-clients编译完成后

另起一个窗口监控GPU使用率
watch -n0.1 nvidia-smi再起一个窗口运行性能分析器
启动性能分析器的命令为
perf_analyzer -m <model name> -b <batch size> --shape <input layer>:<input shape> --concurrency-range <lower number of request>:<higher number of request>:<step>
每次运行性能分析器的命令都是
cd /test_triton/client/build/cc-clients/install
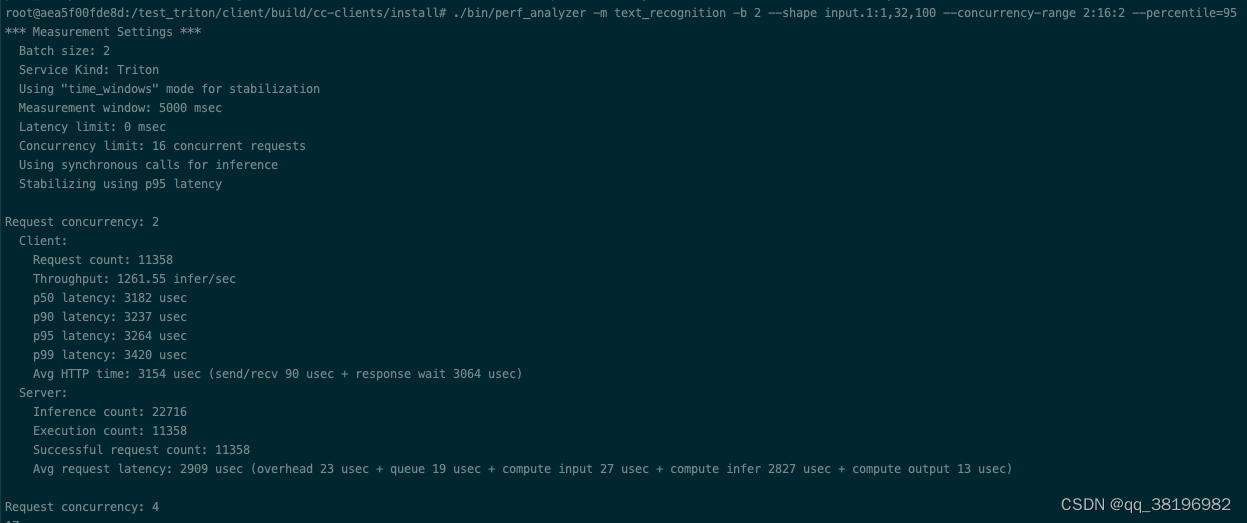
./bin/perf_analyzer -m text_recognition -b 2 --shape input.1:1,32,100 --concurrency-range 2:16:2 --percentile=95分为3种情况
1)无动态批处理,单个模型实例
此时config.pbtxt为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]另一个窗口启动性能分析器
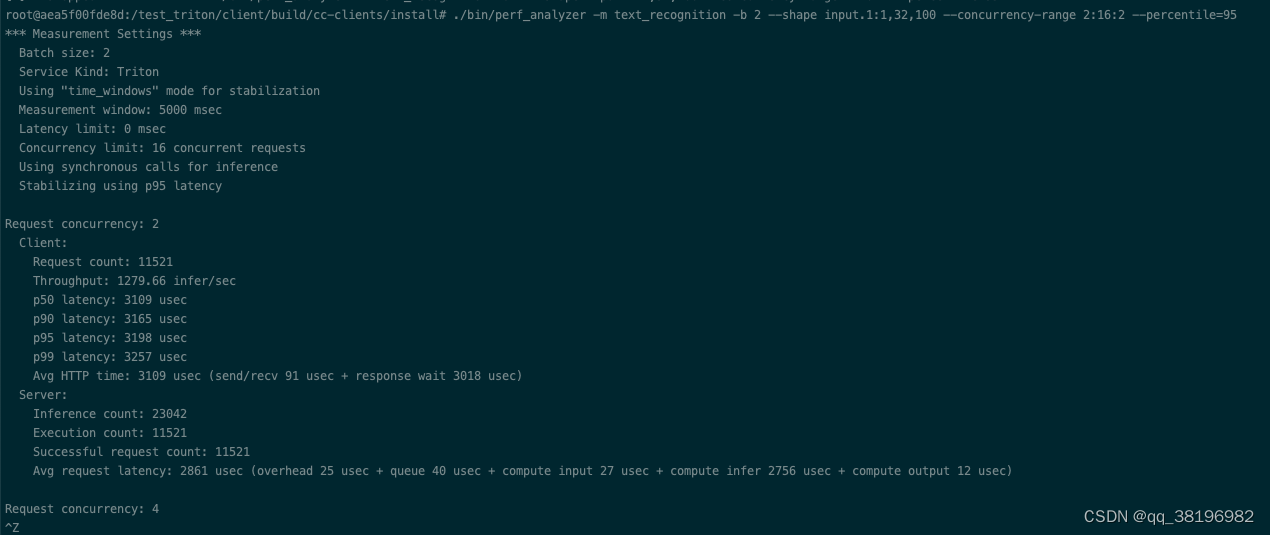
2)只有动态批处理
此时config.pbtxt为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }另一个窗口启动性能分析器
3)动态批处理+多实例
此时config.pbtxt为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }另一个窗口启动性能分析器

输出中各个指标的含义:
以下是输出的解释:
-
Batch size: 每个推理请求的批次大小,这里设置为2。
-
Service Kind: 此处设置为Triton,表示使用Triton Inference Server。
-
Using "time_windows" mode for stabilization: 用于稳定性测试的模式,以确保性能测量的一致性。
-
Measurement window: 测量窗口的持续时间,这里设置为5000毫秒(5秒)。
-
Latency limit: 延迟限制,这里设置为0毫秒。
-
Concurrency limit: 并发请求的限制,这里设置为16个并发请求。
-
Using synchronous calls for inference: 使用同步调用进行推理。
-
Stabilizing using p95 latency: 使用p95(95th percentile,第95百分位数)的延迟作为稳定性度量。
对于每个并发级别,性能指标包括:
-
Request count: 请求计数,表示发送的总请求数量。
-
Throughput: 吞吐量,表示每秒的推理请求数量。
-
p50 latency: p50延迟,表示延迟的中位数值,即50th percentile的延迟。
-
p90 latency: p90延迟,表示90th percentile的延迟。
-
p95 latency: p95延迟,表示95th percentile的延迟。
-
p99 latency: p99延迟,表示99th percentile的延迟。
-
Avg HTTP time: 平均HTTP时间,表示处理HTTP请求的平均时间,包括发送和接收HTTP请求的时间以及等待响应的时间。
-
Inference count: 推理计数,表示执行的总推理数量。
-
Execution count: 执行计数,表示执行的总次数,通常与推理计数相等。
-
Successful request count: 成功的请求计数,表示成功完成的请求数量。
-
Avg request latency: 平均请求延迟,表示请求的平均延迟时间。
从吞吐量和延迟方面比较,发现这三批数据最好的是第二次,可见,未必是性能不一定会随着GPU数量或模型实例的增加而线性增加,性能的提升受到多个因素的影响,包括硬件资源、模型复杂度、批处理大小、并发请求等
3.优化Triton配置
1.性能的影响因素
测量推理服务架构的性能是一个很复杂的问题,推理服务器在启用动态批处理和使用多个模型实例的情况下处理查询如下所示

Triton Inference Server 处理推理请求的工作流程:
1. 当客户端发送一个推理查询时,Triton 的请求处理程序会将该查询放入模型的请求队列中。
2. Triton 根据模型实例的可用性和队列中的请求,决定何时执行推理。一旦有模型实例可用,Triton 将使用已经在队列中的查询或传入的新查询来创建一个批次。这个批次的大小会根据模型配置中定义的首选批次大小来形成,以尽量充分利用硬件资源。
3. 接下来,这个批次会被转换成适合模型框架(例如PyTorch、TensorFlow、TensorRT等)运行的格式。
4. Triton 将这个批次发送到底层的模型框架运行时,模型框架运行时会执行推理操作,即模型的前向传播。
5. 推理完成后,模型框架运行时将结果返回给 Triton。
6. Triton 将这些推理结果返回给客户端,以满足客户端的推理查询。
在此过程中,造成延迟的主要因素有3个:
- 网络延迟
- 推理计算时间
- 由于模型队列中的等待时间而导致的延迟
对于推理过程中可能引起延迟的三个主要因素:
1. **网络延迟**:网络通信需要时间,因此较长的网络延迟可能会导致推理请求的响应时间增加。为了减少网络延迟,可以考虑减小数据传输的大小。例如,在处理计算机视觉模型时,可以将图像数据从float32格式转换为float16格式,这减少了传输的数据量,从而减少了网络延迟。
2. **推理计算时间**:模型的前向传播需要一定的时间,特别是对于复杂的模型或大型数据。为了加速推理计算,可以采取一系列优化措施,如层融合、减小模型精度(例如使用float16而不是float32)、融合内核等。这些技术有助于减少计算时间,从而降低延迟。
3. **队列中的延迟**:在模型服务中,请求可能会排队等待处理,这可能会导致请求等待的延迟。为了减少队列中的延迟,可以通过添加更多模型实例来提高并行性。这意味着可以同时处理更多的请求,从而减少每个请求在队列中等待的时间。
对于第三点,Triton Inference Server 提供了模型分析器,它是一个命令行工具,可帮助用户更好地了解模型的计算和内存需求,并进行性能分析。模型分析器可以执行以下任务:
- 运行自定义的配置扫描,以确定最佳配置,适用于不同的工作负载和硬件环境。
- 提供详细的性能报告、指标和图表,汇总延迟、吞吐量、GPU 资源利用率、功耗等性能方面的信息,有助于用户比较不同配置的性能。
- 允许用户根据自己的服务质量需求自定义模型部署配置,例如设置特定的延迟限制(如p99延迟限制)、GPU内存利用率要求和最小吞吐量等。
2.使用模型分析器寻找最佳配置
自行编译模型分析器
git clone https://github.com/triton-inference-server/model_analyzer
cd model_analyzer
./build_wheel.sh /test_triton/client/build/cc-clients/install/bin/perf_analyzer true编译完成如下
得到triton_model_analyzer-1.32.0.dev0-py3-none-manylinux1_x86_64.whl文件,pip安装即可
pip3 install wheels/triton_model_analyzer-1.32.0.dev0-py3-none-manylinux1_x86_64.whl或者按照如下方式直接安装
sudo apt-get update && sudo apt-get install python3-pip
sudo apt-get update && sudo apt-get install wkhtmltopdf
pip3 install triton-model-analyzer理解如何设置性能分析的目标和约束是使用该工具的关键。在进行性能分析时,用户需要明确他们希望达到的性能目标,同时也需要考虑到可能存在的限制条件。
-
Objectives(目标):用户可以根据部署目标对结果排序,这些目标可以包括吞吐量(通过量测度的工作速度)、延迟(系统响应时间)或根据特定资源限制进行定制。这意味着用户可以根据他们的需求,例如想要快速的处理速度(吞吐量)或低延迟来选择性能测量结果。
-
Online Mode 和 Offline Mode(在线模式和离线模式):Model Analyzer 工具有两种模式,Online 和 Offline。在在线模式下,用户可以指定他们的部署的延迟预算,以满足他们的需求。在离线模式下,用户可以为最小吞吐量做类似的规定。这意味着用户可以根据部署模式选择性能参数,例如对于在线部署,他们可能关心的是响应速度(延迟),而对于离线批处理,他们可能更关心处理速度(吞吐量)。
-
Constraints(约束):用户还可以选择将性能分析结果限制在特定的吞吐量、延迟或GPU内存利用率要求之内。这意味着用户可以根据他们的系统要求对性能进行限制或筛选,以满足他们的特定需求。
目标指定最终结果的排序标准。此对象类型支持以下字段:
| 选项名称 | 描述 |
|---|---|
perf_throughput | 使用吞吐量作为目标。 |
perf_latency_p99 | 使用延迟作为目标。 |
gpu_used_memory | 使用模型使用的 GPU 内存作为目标。 |
gpu_free_memory | 使用模型未使用的 GPU 内存作为目标。 |
gpu_utilization | 使用 GPU 利用率作为目标。 |
cpu_used_ram | 使用模型使用的 RAM 作为目标。 |
cpu_free_ram | 使用模型未使用的 RAM 作为目标。 |
用户使用模型分析器时需要使用2个子命令:profile和report
-
profile:
profile用于运行基准测试扫描。用户可以在此处指定扫描空间详细信息,例如每个 GPU 的实例数量、模型的最大批量大小范围、最大 CPU 利用率、发送的查询的批量大小、发送到 Triton 的并发查询数量等。profile运行这些扫描,记录每个配置的性能并保存运行检查点。将此步骤视为简单地运行大量实验并记录数据点以进行分析。此步骤将需要 60-90 分钟运行。用户可以使用该--run-config-search-mode quick标志以更少的配置进行更快的扫描。 -
report:
report子命令生成顶级配置的详细报告以及摘要。这些报告包含:- 概述发送到服务器的并发请求数量不断增加的吞吐量和延迟的图表
- GPU 内存 VS 延迟和 GPU 利用率 vs 延迟图表
- 该表概述了 p99 延迟、延迟的各个组成部分、吞吐量、GPU 利用率和 GPU 内存利用率,最多可达分析步骤中选择的最大并发请求数(默认为 1024)(
- 吞吐量与延迟图、GPU 内存与延迟图以及包含高级详细信息的表格,对顶级配置和用户选择的默认配置进行比较。
使用 Triton 的模型分析器通常会涉及两个主要步骤:`model-analyzer profile` 和 `model-analyzer report`。
1. **使用 `model-analyzer profile` 进行性能分析**:该命令会分析指定的模型或模型集合,以收集性能数据。这个命令将根据配置文件执行性能分析,并记录有关模型推理的吞吐量、延迟和其他性能指标的信息
model-analyzer profile --model-repository /workspace/model_repository --profile-models text_recognition --triton-launch-mode=local --output-model-repository-path /workspace/output/ -f perf.yaml --override-output-model-repository --latency-budget 10 --run-config-search-mode quick这个命令将使用配置文件中的设置来分析指定的模型。
2. **使用 `model-analyzer report` 生成性能报告**:一旦性能分析数据被收集和记录,接下来可以运行 `model-analyzer report` 命令,以生成性能报告。性能报告将提供关于模型的性能数据的详细信息,包括各种性能指标的图表和指标的分布情况。示例命令可能如下所示:
model-analyzer report --perf-data-directory /workspace/output/text_recognition/perf-analyzer-results --output-directory /workspace/report --full-data --show-configuration这个命令将使用性能数据目录中的数据来生成性能报告。
通过这两个步骤,可以收集、分析和可视化有关模型性能的数据,以便更好地了解模型在不同配置下的行为,从而帮助您做出优化和调整决策。
4.推理加速
模型加速是一个复杂而微妙的话题。模型的图优化、剪枝、知识蒸馏、量化等技术的可行性在很大程度上取决于模型的结构。每个主题本身都是广阔的研究领域,构建定制工具需要大量的工程投资。
为了简洁和客观,本次讨论将重点关注在使用 Triton 推理服务器部署模型时建议使用的工具和功能,而不是对生态系统进行详尽的概述。

加速建议取决于两个主要因素:
- 硬件类型:Triton 用户可以选择在 GPU 或 CPU 上运行模型。由于 GPU 提供的并行性,GPU 提供了多种性能加速途径。使用 PyTorch、TensorFlow、ONNX 运行时和 TensorRT 的模型可以利用这些优势。对于 CPU,Triton 用户可以利用 OpenVINO 后端进行加速。
- 模型类型:通常用户会利用三种不同类别的模型中的一种或多种:
Shallow models(如随机森林)、Neural Networks(如BERT 或 CNN),Large Transformer Models(通常太大而无法容纳在单个 GPU 的内存中)。每个模型类别都利用不同的优化来提高性能。
三种主要模型类别是:
1. **Shallow Models(浅层模型)**:这类模型通常包括传统的机器学习算法,如随机森林。它们通常不涉及深度神经网络,因此在内存和计算资源方面要求相对较低。这些模型适用于一些简单的任务,例如分类和回归问题。
2. **Neural Networks(神经网络)**:这是深度学习的一部分,通常包括诸如BERT(自然语言处理任务)或CNN(卷积神经网络,用于图像处理任务)等神经网络模型。它们具有多层神经元组成的深度结构,可以处理更复杂的数据和任务。它们需要更多的计算资源和内存,但在许多领域取得了出色的性能。
3. **Large Transformer Models(大型Transformer模型)**:这些是深度神经网络的一种子集,通常包括巨大的Transformer模型。它们在自然语言处理等领域表现出色,但由于其庞大的参数量,通常无法容纳在单个GPU的内存中。因此,它们需要分布式计算或专门的硬件来进行训练和推理。

1.基于GPU加速
深度学习模型的加速可以通过多种方式实现。融合层等图形级优化可以减少启动执行所需的 GPU 内核的数量。融合层使模型执行的内存效率更高,并增加了操作密度。一旦融合,内核自动调优器就可以选择正确的内核组合,以最大限度地利用 GPU 资源。同样,使用较低精度(FP16、INT8 等)和量化等技术可以大大减少内存需求并提高吞吐量。
1.直接使用TensorRT
用户可以使用三种途径将模型转换为 TensorRT:C++ API、Python API 和trtexec / polygraphy(TensorRT 的命令行工具)。请参阅本指南以获取充实的示例。
首先,将模型转换为 TensorRT 引擎。建议使用TensorRT容器来运行命令。
trtexec --onnx=model.onnx \
--saveEngine=model.plan \
--explicitBatch其次,模型已经被转换为TensorRT支持的格式,它需要被放置到模型存储库中。
最后,在配置文件 config.pbtxt 中,需要指定将使用TensorRT作为后端来运行这个特定模型。
对于用户遇到 TensorRT 不支持模型中的某些运算符的情况,有以下三种可能的选择:
-
使用框架集成:TensorRT 有两种与框架的集成:Torch-TensorRT (PyTorch) 和 TensorFlow-TensorRT (TensorFlow)。这些集成具有内置的回退机制,可以在 TensorRT 不直接支持图形的情况下使用框架后端。
-
将 ONNX 运行时与 TensorRT 结合使用:Triton 用户还可以通过 ONNX 运行时利用此回退机制(下一节将详细介绍)。
-
构建插件:TensorRT 允许构建插件并实现自定义操作。用户可以编写自己的TensorRT 插件来实现不支持的操作(推荐给专家用户)
2.使用TensorRT与Pytorch/TensowFlow的集成
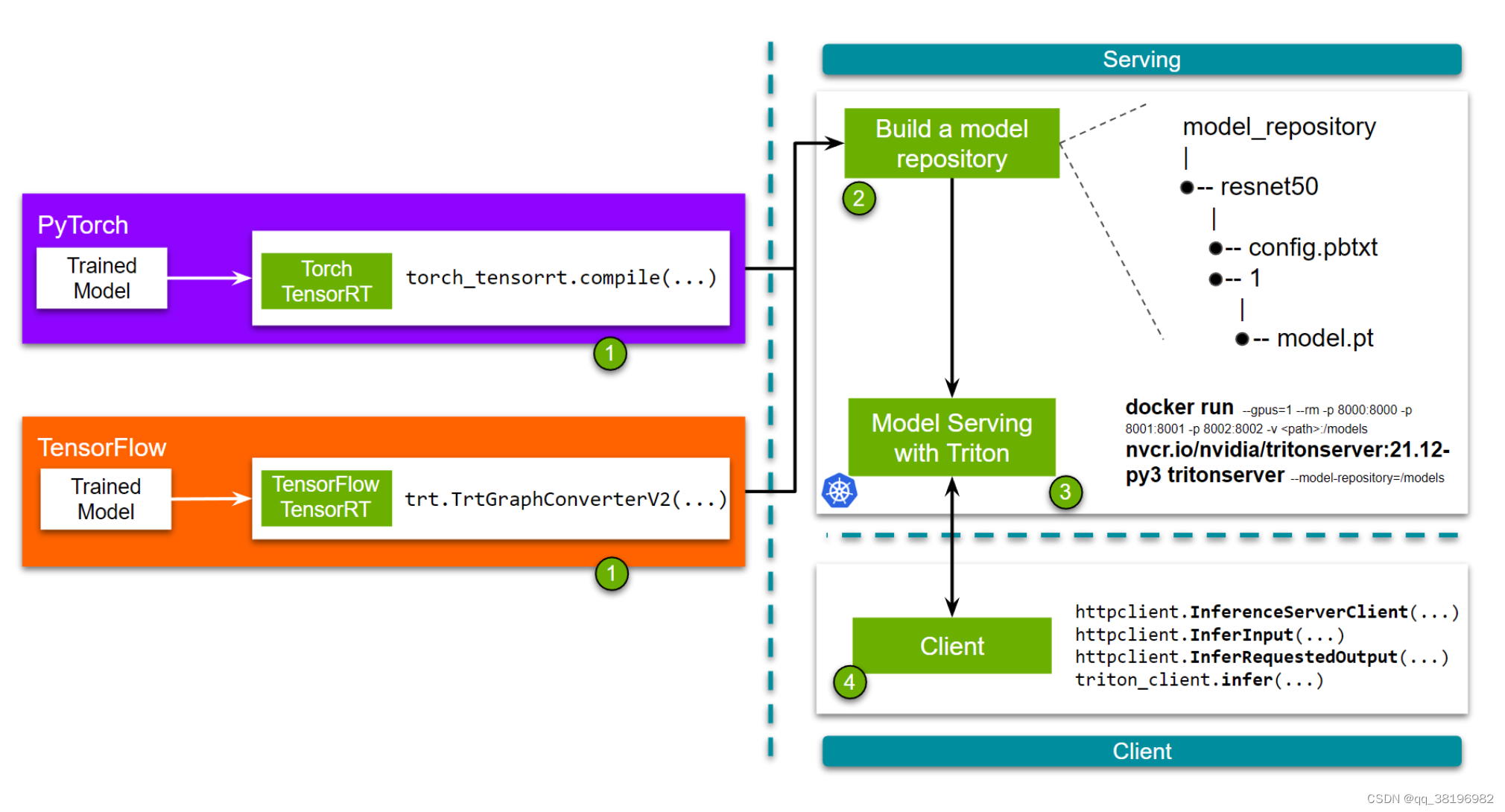
就PyTorch而言,Torch-TensorRT 是一个提前编译器,它将 TorchScript/Torch FX 转换为针对 TensorRT 引擎的模块。编译后,用户可以像使用 TorchScript 模型一样使用优化后的模型。查看Torch TensorRT入门以了解更多信息。请参阅本指南,了解详细示例,演示使用 Torch TensorRT 编译 PyTorch 模型并将其部署在 Triton 上。
TensorFlow用户可以使用 TensorFlow TensorRT,它将图分割成 TensorRT 支持和不支持的子图。然后,受支持的子图将替换为 TensorRT 优化节点,生成同时具有 TensorFlow 和 TensorRT 组件的图。请参阅本教程,了解使用 TensorFlow-TensorRT 加速模型并将其部署到 Triton Inference Server 上所需的确切步骤。
3.使用TensorRT与ONNX RunTime的集成
加速 ONNX 运行时的选项有三个:GPU 的使用TensorRT和CUDA执行提供程序以及OpenVINOCPU 的使用(将在后面的部分中讨论)。
一般来说,TensorRT 将提供比 CUDA 执行提供程序更好的优化,但是,这取决于模型的确切结构,更准确地说,它取决于正在加速的网络中使用的运算符。如果支持所有运算符,转换为 TensorRT 将产生更好的性能。当TensorRT被选择 为加速器时,所有支持的子图都由 TensorRT 加速,图的其余部分在 CUDA 执行提供程序上运行。用户可以通过在配置文件中添加以下内容来实现此目的。
optimization {
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}
}也就是说,用户还可以选择在没有 TensorRT 优化的情况下运行模型,在这种情况下,CUDA EP 是默认的执行提供程序。更多详细信息可以在这里找到。请参阅此处,获取本系列第 1-3 部分中使用的Text Recognition模型onnx_tensorrt_config.pbtxt的示例配置文件。
还有一些其他 ONNX 运行时特定的优化。有关更多信息,请参阅我们的ONNX 后端文档的这一部分。
2.基于CPU加速
Triton 推理服务器还支持使用OpenVINO对仅基于 CPU 模型加速。在config.pbtxt配置文件中,用户可以添加以下内容来启用CPU加速。
optimization {
execution_accelerators {
cpu_execution_accelerator : [{
name : "openvino"
}]
}
}虽然 OpenVINO 提供软件级优化,但考虑所使用的 CPU 硬件也很重要。CPU 包含多个内核、内存资源和互连。对于多个 CPU,这些资源可以通过 NUMA(非统一内存访问)共享。有关更多信息,请参阅Triton 文档的此部分。
3.加速浅层模型
像梯度提升决策树这样的浅层模型经常在许多pipeline中使用。这些模型通常使用XGBoost、LightGBM、Scikit-learn、cuML等库构建。这些模型可以通过 Forest Inference Library 后端部署在 Triton Inference Server 上。查看这些示例以获取更多信息。
4.加速大型transformers模型
另一方面,深度学习从业者被具有数十亿参数的基于大型 Transformer 的模型所吸引。对于这种规模的模型,通常需要不同类型的优化或跨 GPU 并行化。这种跨 GPU 的并行化(因为它们可能不适合 1 个 GPU)可以通过张量并行或管道并行来实现。为了解决这个问题,用户可以使用Faster Transformer Library和 Triton 的Faster Transformer Backend。查看此博客了解更多信息!
5.工作示例
首先准备模型
cd /triton/tutorials/Conceptual_Guide/Part_3-optimizing_triton_configuration
cp -r ../Part_2-improving_resource_utilization/model_repository/ ./其次,根据模型的ONNX版本,选择合适的ONNX后端配置文件,有3种情况
- 使用CUDA执行提供程序在GPU上加速ONNX RT执行:ORT_cuda_ep_config.pbtxt
- 在GPU上使用TRT加速执行ONNX RT:ORT_TRT_config.pbtxt
- 在CPU上使用OpenVINO加速执行ONNX RT:ORT_openvino_config.pbtxt
使用 ONNX RT 时,无论执行提供程序如何,都需要考虑一些常规优化。这些可以是图形级优化,或者选择用于并行执行的线程的数量和行为或一些内存使用优化。每个选项的使用都高度依赖于所部署的模型。
启动模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton/tutorials/Conceptual_Guide/Part_3-optimizing_triton_configuration/model_repository启动性能分析器
cd /test_triton/client/build/cc-clients/install
./bin/perf_analyzer -m text_recognition -b 8 --shape input.1:1,32,100 --concurrency-range 64性能分析器输出为:
*** Measurement Settings ***
Batch size: 8
Service Kind: Triton
Using "time_windows" mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using average latency
Request concurrency: 64
Client:
Request count: 7052
Throughput: 3132.89 infer/sec
Avg latency: 163419 usec (standard deviation 3592 usec)
p50 latency: 163172 usec
p90 latency: 168173 usec
p95 latency: 169580 usec
p99 latency: 172601 usec
Avg HTTP time: 163407 usec (send/recv 117 usec + response wait 163290 usec)
Server:
Inference count: 56416
Execution count: 7052
Successful request count: 7052
Avg request latency: 162977 usec (overhead 26 usec + queue 142562 usec + compute input 47 usec + compute infer 20325 usec + compute output 16 usec)
Inferences/Second vs. Client Average Batch Latency
Concurrency: 64, throughput: 3132.89 infer/sec, latency 163419 usec将该数据作为基准数据,作为后续比较的基础
1.ONNX RT 在 GPU 上执行 CUDA执行提供者
config.pbtxt内容为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }
parameters { key: "cudnn_conv_algo_search" value: { string_value: "0" } }
parameters { key: "gpu_mem_limit" value: { string_value: "4294967200" } }启动性能分析器
cd /test_triton/client/build/cc-clients/install
./bin/perf_analyzer -m text_recognition -b 8 --shape input.1:1,32,100 --concurrency-range 64性能分析器输出为:
*** Measurement Settings ***
Batch size: 8
Service Kind: Triton
Using "time_windows" mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using average latency
Request concurrency: 64
Client:
Request count: 7017
Throughput: 3116.86 infer/sec
Avg latency: 163496 usec (standard deviation 7550 usec)
p50 latency: 163417 usec
p90 latency: 170242 usec
p95 latency: 172470 usec
p99 latency: 176169 usec
Avg HTTP time: 163485 usec (send/recv 287 usec + response wait 163198 usec)
Server:
Inference count: 56136
Execution count: 7017
Successful request count: 7017
Avg request latency: 162846 usec (overhead 26 usec + queue 142346 usec + compute input 75 usec + compute infer 20382 usec + compute output 16 usec)
Inferences/Second vs. Client Average Batch Latency
Concurrency: 64, throughput: 3116.86 infer/sec, latency 163496 usec2.ONNX RT 在 GPU 上执行 TRT加速
config.pbtxt内容为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }
optimization {
graph : {
level : 1
}
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt",
parameters { key: "precision_mode" value: "FP16" },
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}
}
启动性能分析器
cd /test_triton/client/build/cc-clients/install
./bin/perf_analyzer -m text_recognition -b 8 --shape input.1:1,32,100 --concurrency-range 64性能分析器输出为:
*** Measurement Settings ***
Batch size: 8
Service Kind: Triton
Using "time_windows" mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using average latency
Request concurrency: 64
Client:
Request count: 11661
Throughput: 5179.44 infer/sec
Avg latency: 87968 usec (standard deviation 9274 usec)
p50 latency: 86528 usec
p90 latency: 100159 usec
p95 latency: 106134 usec
p99 latency: 114655 usec
Avg HTTP time: 87945 usec (send/recv 181 usec + response wait 87764 usec)
Server:
Inference count: 93288
Execution count: 11661
Successful request count: 11661
Avg request latency: 87040 usec (overhead 46 usec + queue 85521 usec + compute input 92 usec + compute infer 1348 usec + compute output 33 usec)
Inferences/Second vs. Client Average Batch Latency
Concurrency: 64, throughput: 5179.44 infer/sec, latency 87968 usec但是Triton这次输出了如下
2023-08-25 10:21:15.049787670 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] TensorRT encountered issues when converting weights between types and that could affect accuracy.
2023-08-25 10:21:15.049823087 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] If this is not the desired behavior, please modify the weights or retrain with regularization to adjust the magnitude of the weights.
2023-08-25 10:21:15.049835004 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] Check verbose logs for the list of affected weights.
2023-08-25 10:21:15.049846754 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] - 31 weights are affected by this issue: Detected subnormal FP16 values.
2023-08-25 10:21:15.049872213 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] - 23 weights are affected by this issue: Detected values less than smallest positive FP16 subnormal value and converted them to the FP16 minimum subnormalized value.
2023-08-25 10:21:15.055939312 [W:onnxruntime:log, tensorrt_execution_provider.h:60 log] [2023-08-25 10:21:15 WARNING] CUDA lazy loading is not enabled. Enabling it can significantly reduce device memory usage. See `CUDA_MODULE_LOADING` in https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#env-vars3.ONNX RT 在 CPU 上执行 OpenVINO加速
config.pbtxt内容为
name: "text_recognition"
backend: "onnxruntime"
max_batch_size : 8
input [
{
name: "input.1"
data_type: TYPE_FP32
dims: [ 1, 32, 100 ]
}
]
output [
{
name: "308"
data_type: TYPE_FP32
dims: [ 26, 37 ]
}
]
instance_group [
{
count: 2
kind: KIND_GPU
}
]
dynamic_batching { }
optimization { execution_accelerators {
cpu_execution_accelerator : [ {
name : "openvino"
} ]
}}启动性能分析器
cd /test_triton/client/build/cc-clients/install
./bin/perf_analyzer -m text_recognition -b 8 --shape input.1:1,32,100 --concurrency-range 64性能分析器输出为:
*** Measurement Settings ***
Batch size: 8
Service Kind: Triton
Using "time_windows" mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using average latency
Request concurrency: 64
Client:
Request count: 6689
Throughput: 2971.7 infer/sec
Avg latency: 172257 usec (standard deviation 5532 usec)
p50 latency: 171915 usec
p90 latency: 179786 usec
p95 latency: 181834 usec
p99 latency: 185119 usec
Avg HTTP time: 172248 usec (send/recv 111 usec + response wait 172137 usec)
Server:
Inference count: 53520
Execution count: 6690
Successful request count: 6690
Avg request latency: 171827 usec (overhead 25 usec + queue 150309 usec + compute input 50 usec + compute infer 21426 usec + compute output 16 usec)
Inferences/Second vs. Client Average Batch Latency
Concurrency: 64, throughput: 2971.7 infer/sec, latency 172257 usec通过性能分析器可以发现后三批数据相对于第一批数据具有更高的吞吐量,这通常被认为是性能改进的指标。所以,从吞吐量的角度来看,后三批数据的性能都优于第一批数据。但是,延迟方面的表现不一定更好,因为延迟可能在不同的批次之间有所波动。要全面评估性能,需要根据具体的部署需求和目标来确定哪个批次的性能更适合
第三批数据(平均吞吐量:5179.44 次推理/秒,平均延迟:87968 微秒)可以被认为是性能最好的批次,因为它具有最高的吞吐量和相对较低的延迟。
6.模型导航器
上面的部分描述了转换模型和使用不同的加速器,并提供了“一般指南”,以建立关于在考虑优化时采取哪条“路径”的直觉。这些都是手动探索,需要花费大量时间。要检查转化覆盖率并探索可能的优化子集,用户可以使用模型导航器工具。






![java八股文面试[多线程]——为什么不能用Excuters创建线程池](https://img-blog.csdnimg.cn/12962fb3f5e84a90bf837f8d0e3ee7ae.png)