UIFGAN: An unsupervised continual-learning generative adversarial network for unified image fusion
(UIFGAN:一个无监督不断学习生成对抗网络统一的图像融合)
本文提出了一种新的无监督连续学习生成对抗网络(UIFGAN)用于统一图像融合。在该模型中,针对多个图像融合任务,提出了一种生成式对抗网络,以连续学习的方式训练单个有记忆模型,而不是针对每个融合任务训练单个模型或联合训练多个任务。我们使用弹性重量整合,以避免忘记已经从先前的任务当训练多个任务顺序。在每个任务中,融合图像的生成来自生成器和鉴别器之间的对抗性的学习。同时,采用最大梯度损失函数,使融合图像能够获得两幅源图像对应区域更丰富的纹理细节,适用于大多数典型的图像融合任务。
介绍
由于设备和技术的限制,对于一种类型的传感器或在单个拍摄设置下通常难以捕获表征场景中的所有信息的图像。因此,需要通过不同的传感器或设置来拍摄多个图像以完全表示场景。但这些图像中大量的冗余信息不仅影响视觉感知,而且浪费存储空间。图像融合是提取图像中最有意义的信息并将其组合成一幅图像,是图像增强的一个重要分支,在军事和民用领域都有着重要的作用。根据成像原理,图像融合任务通常包含多曝光、多模态和多聚焦图像融合。对于不同的图像融合任务,一方面,它们通常致力于实现相似的目标,即通过综合两幅或多幅源图像的关键信息和补充信息来合成融合图像。另一方面,提取的信息变化很大。例如,在多曝光图像融合中,提取低动态范围图像的信息以获得曝光良好的高动态范围图像。多模态红外与可见光图像融合主要提取红外图像中对比度高的热辐射信息和可见光图像中丰富的纹理细节。多聚焦图像融合提取源图像中聚焦区域的信息。
在过去的几十年中,已经开发了许多方法来解决这三个图像融合任务,这些任务可以统一地归为两类。(i)传统方法。空间域和变换域[7]是这一类中最常见的融合方法。在空间域方法中,通常采用梯度信息作为活动水平测量。根据融合规则的不同,基于空间域的方法又可分为基于像素的、基于块的和基于区域的方法。在变换域方法,融合过程主要是实现根据源图像的领域转移的特点。这些方法包括稀疏表示,混合,多尺度变换,子空间等。(2)基于深度学习的方法。深度学习的能力强图像特征表示是一个成功的应用在图像融合。Prabhakar等人通过建立新的CNN引入了多曝光图像融合中的深度学习,并采用MEF-SSIM实现无监督学习。在红外和可见光图像融合等多模态融合中,Ma等人提出了FusionGAN,以在生成器和鉴别器之间建立对抗博弈,这迫使融合图像具有更多细节。而在多聚焦图像融合中,CNN用于分类聚焦和散焦区域,以生成决策图,从而获得全聚焦图像。最近,有些学者试图通过深度学习强大的图像特征表示能力将不同图像融合任务中的具体信息统一呈现。Zhang等人为了统一实现多个图像融合任务,分别对不同的融合任务进行训练,得到不同的模型,并不具有真正的通用性。Xu等人创新性地提出了U2Fusion,在CNN中针对不同任务顺序地训练单个模型,其也存在缺乏地面真实的问题。另外,多任务直接联合训练的方式会带来计算量和存储量的问题。
尽管现有的方法取得了有前途的性能,还有几个方面需要改进。首先,缺乏groundtruth融合图像深度学习的监督式学习是一种严重的阻力。真实图像人为往往缺乏权威,是费时和费力。其次,在现有的生成对抗网络(GAN)的无监督或监督学习方法,通常只有一个鉴别器是用于迫使融合图像的类似于只有一个源图像。这样可以避免由于加入鉴别器而造成的训练困难,但会导致另一幅源图像中的部分信息丢失。最后,一方面,现有方法倾向于仅保留一幅源图像的纹理细节,导致另一幅源图像的纹理细节丢失。另一方面,当同时提取两幅源图像的纹理细节时,会出现中性化现象,即融合图像中的纹理细节介于最优和最差之间,这对于不同的融合任务也不具有通用性。
为了解决上述问题,本文提出了一种连续学习的生成式对抗网络(UIFGAN)。我们不针对不同的融合任务分别训练不同的模型。相比之下,我们设计的具有弹性权重合并的连续学习GAN(elastic weight consolidation (EWC))训练了适用于多个融合任务的具有记忆的单个模型,避免了在顺序训练多个任务时忘记从先前任务中学习到的内容,即:灾难性的遗忘。对于每一个任务,我们将图像融合问题表述为发生器和鉴别器之间的特定对抗过程。给定两幅源图像,生成器可以生成融合图像。同时,采用双通道输入的鉴别器来评估融合图像是否同时与两幅源图像不可区分,在这种对抗性框架下引导融合图像更接近源图像。因此,我们的UIFGAN不需要地面实况融合图像。同时,采用一个最大梯度损失函数,使融合图像在两幅源图像中对应区域的梯度最大。因此,融合后的图像能够拥有两幅源图像更丰富的纹理细节,避免了中性化现象。在公开数据集上的大量实验结果表明,UIFGAN算法在各融合任务中均优于现有算法。
贡献
1)提出了一种基于EWC的连续学习GAN,用于训练单个有记忆的模型来完成多个图像融合任务,解决了灾难性遗忘问题以及计算和存储问题。据我们所知,这是第一次提出一个连续学习的GAN来解决统一的图像融合任务。
2)设计了一种适用于统一图像融合的无监督GAN,其鉴别器可以同时区分融合图像与两幅源图像之间的结构差异。
3)我们采用max-gradient损失函数统一的图像融合,它可以迫使融合图像获取丰富的纹理细节相应地区的两个源图像。这克服了缺点的纹理细节损失或中和现象。
相关工作
Generative adversarial network
略
Continual-learning
当面对多个学习任务时,单个模型不可避免地会遭受先前学习任务的严重灾难性遗忘问题,而联合训练多个融合任务会导致计算和存储问题。因此,训练一个无灾难性遗忘的连续学习模型在实际应用中是非常必要的。为了克服单个连续学习模型的灾难性遗忘问题,近年来提出了许多方法,这些方法可以分为以下五类:集成(ensembling)、复述(rehearsal)、双存储器(dual-memory)、稀疏编码( sparse-coding)和正则化(regularization)。
1)集成(ensembling):集成是通过在前一个模型学习到一个新任务时,增加一个新的子模型(显式或隐式)来实现的,这样多个任务实际上可以对应多个模型,最终集成多个模型的预测。但是,为每个新任务添加一个子模型对学习效率和存储都是一个巨大的挑战。Google发布的PathNet是一种典型的集合算法。
2)复述(rehearsal):Rehearsal的直观思路是通过不断复习,防止模型在学习新任务时忘记旧任务,当模型学习新任务时,混合原任务的数据,这样模型在学习新任务的同时,也兼顾了旧任务。一个明显的缺陷是模型会一直保存所有旧任务的数据,同样的数据可能会重复多次。其中,GeppNet是一种基于预演的经典算法。
3)双存储器(dual-memory):该算法结合人类记忆机制,设计了两个网络:快速存储器和慢速存储器。具体地说,新学到的知识被存储在快速记忆中,快速记忆不断地整合和转移记忆到慢速记忆中。GeppNet+STM 是一种结合了预演和双存储器的算法。
4)稀疏编码( sparse-coding):在该算法的思想中,灾难性遗忘发生在模型学习新任务(参数更新)时,它修改了对旧任务有显著影响的参数。稀疏编码在模型训练过程中人为地使模型参数稀疏(知识存储在少数神经元中),这可以减少新知识干扰旧知识的可能性。灵敏度驱动是一种经典的稀疏编码算法。
5)正规化(regularization):通过在网络参数更新时增加约束条件来实现正则化,使得网络在学习新任务时不影响先前的知识。EWC是最典型的正则化算法,它通过弹性保留先前知识的权重,仅使用一个模型就可以避免灾难性遗忘问题。
在我们的工作中,考虑到统一图像融合任务的多样性,以及模型的可移植性和高性能,我们选择EWC算法来实现连续学习模型。
方法
Continual-learning GAN
对于不同的融合任务,所提取的信息变化很大,从而导致不同的参数。在同一网络结构下,针对不同任务训练不同模型的方法并不是真正通用的。为了实现这一目标,我们采用了顺序训练不同融合任务的策略,而不是联合训练多个融合任务,因为后者会导致计算和存储问题。此外,我们引入EWC以避免由顺序训练引起的最严重的灾难性遗忘问题。序列训练的过程和数据流可以直观地显示在图1中。
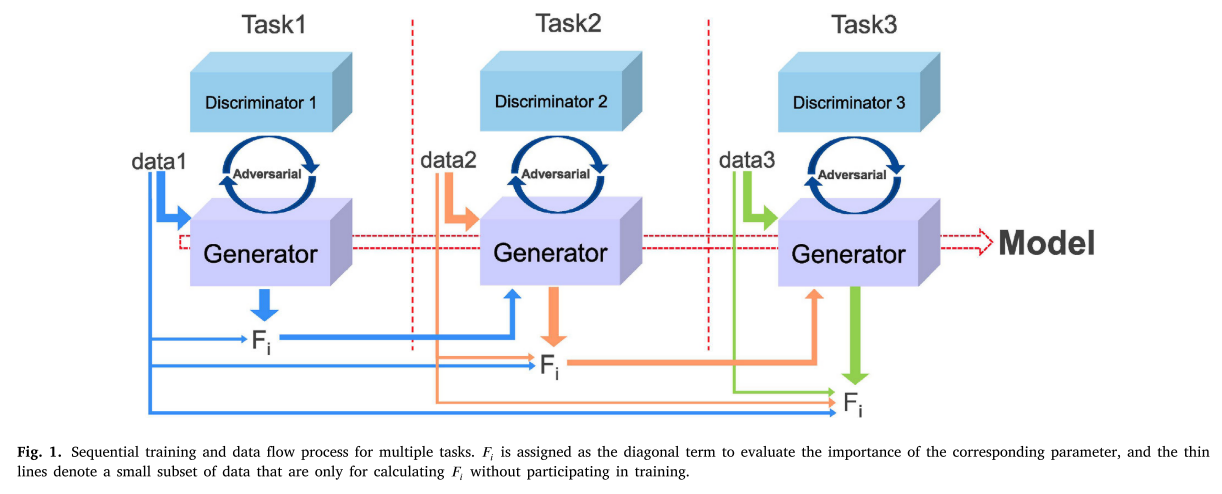
具体思路如下:首先,给定当前融合任务的数据,通过每个先前融合任务中的数据子集对先前融合任务中的参数权重进行排序。其次,在训练好的融合任务中,使用正则化项来保护参数。其次,使用正则化项来保护训练中的参数融合的任务。优化时,重量越大,变化越小,以确保它在小范围内变化不影响更大之前训练融合任务。最后,当前融合任务与先前融合任务一起被优化。
值得注意的是,在测试阶段,仅使用训练的连续学习生成器来生成融合图像,而鉴别器不参与测试阶段。为了降低训练难度,在每个融合任务中,采用一个鉴别器与唯一的生成器建立对抗关系。
Image fusion problem formulation
在一些图像融合任务,源图像三通道(如RGB)图像,而在其他图像融合任务,源图像单通道(如灰度)图像。作为一个统一的网络,我们把所有融合问题转化为单通道图像融合。传统上,三个通道的源图像从RGB颜色转到YCbCr空间。其中,我们只致力于融合能够表现结构细节的Y通道(亮度通道)和亮度变化。至于色度通道(Cb和Cr通道),它们可以以传统方式融合。最后,通过相应的颜色空间逆变换公式,将这些通道的融合分量反变换到RGB颜色空间,得到最终的融合图像。
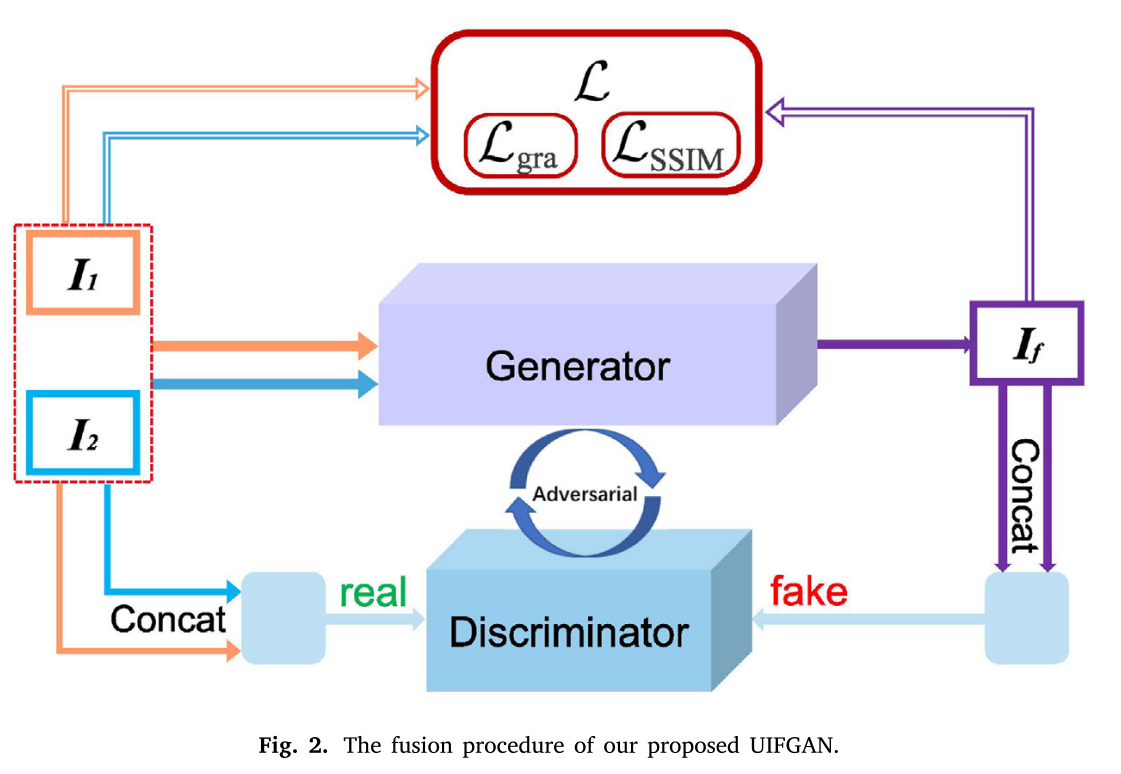
我们提出的UIFGAN的每个任务中的融合过程如图2所示。给定两个单通道源图像𝐼1和𝐼2,训练生成器(𝐺)以生成融合图像,该𝐼𝑓融合图像被鼓励是真实的并且信息量足以欺骗鉴别器。同时,我们使用双通道输入的鉴别器(𝐷)来产生标量,该标量从真实的数据估计输入的概率,即是𝐼real的而不是生成器产生的𝐼fake。通过复制𝐼𝑓产生𝐼fake,然后将他们连接起来。我们使用具有双通道输入的鉴别器来产生标量,该标量从真实的数据估计输入的概率,即,连接𝐼1和𝐼2(𝐼real)而不是生成器产生的𝐼𝑓 和 𝐼𝑓 (𝐼fake)。我们希望鉴别器能正确地识别𝐼real和𝐼fake,而生成器能生成𝐼𝑓足够真实的、串接成后能欺骗鉴别器的𝐼fake信号。生成器和鉴别器建立对抗过程。通过这种对抗过程,融合图像和两个源图像的概率分布之间的发散将同时变小。因此,优化目标函数可以定义如下: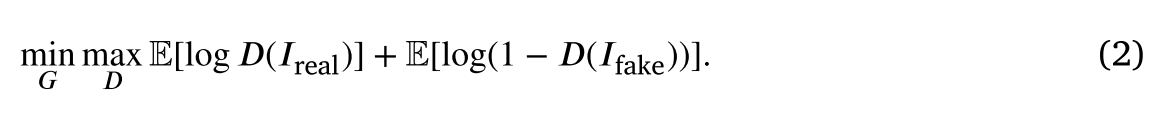 此外,考虑到纹理细节丢失或中性化现象的缺点,由于纹理细节可以用梯度分布来表征,我们采用了最大梯度损失函数(max-gradient loss function)(Lgra)。
此外,考虑到纹理细节丢失或中性化现象的缺点,由于纹理细节可以用梯度分布来表征,我们采用了最大梯度损失函数(max-gradient loss function)(Lgra)。
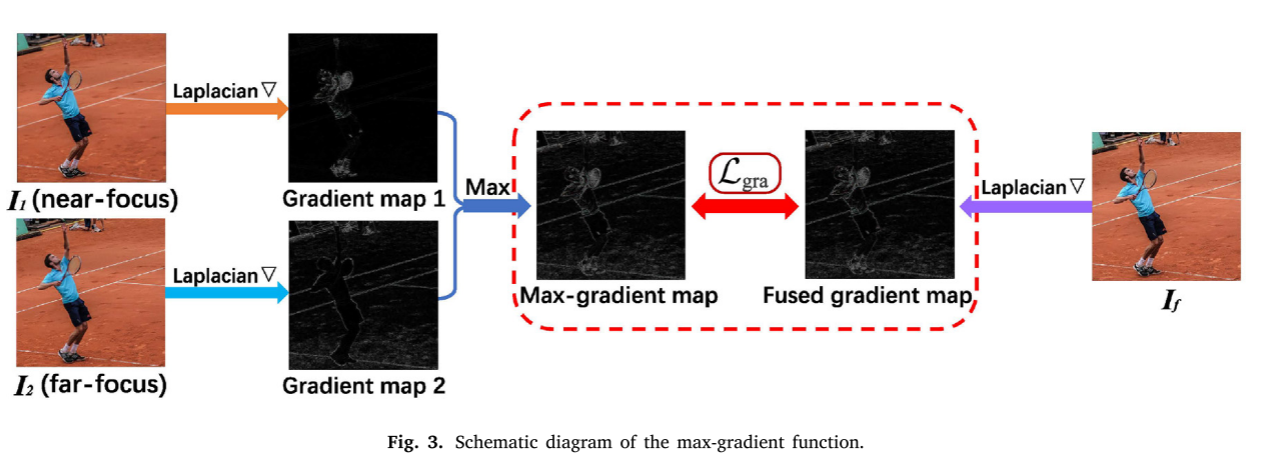
最大梯度损失函数的示意图如图3所示。特别地,利用拉普拉斯算子▽计算融合图像和两幅源图像的梯度图。在梯度图1和梯度图2中计算出对应区域的梯度绝对值最大的最大梯度图后,𝐼𝑓受Lgra约束的(融合梯度图)的梯度图将逼近最大梯度图,这迫使融合图像获得两幅源图像中对应区域更丰富的纹理细节。
Loss functions
我们工作中的损耗函数由发生器损耗L𝐺和鉴别器损耗组成LD
Loss function of the generator: L𝐺
生成器损失函数L𝐺由当前图像融合任务的融合损失L𝐹和避免灾难性遗忘的EWC损失L𝐸组成。定义L𝐺如下: 融合损失L𝐹由欺骗鉴别器的对抗损失L𝐹adv和约束融合图像与源图像在内容上相似性的内容损失L𝐹con组成,形式化如下:
融合损失L𝐹由欺骗鉴别器的对抗损失L𝐹adv和约束融合图像与源图像在内容上相似性的内容损失L𝐹con组成,形式化如下:

其中𝜆用于控制折衷。L𝐹adv来自鉴别器,其定义如下:

Eq.(4)中的L𝐹con由两项组成:结构相似性(SSIM)损失(SSIM)和最大梯度损失(Lgra),权重𝛾控制其权衡,定义如下:

其中,为了约束融合图像与源图像之间的相似性,采用SSIM损失作为三个不同因素的组合来建模失真:亮度、对比度和结构。两个图像之间的SSIM损失在数学上形式化如下:
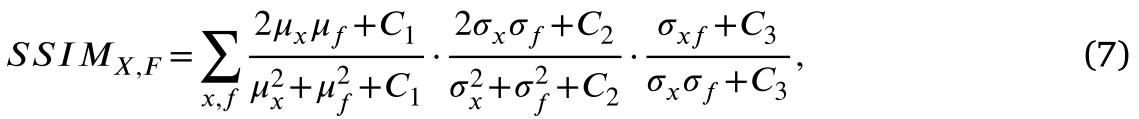
其中,𝑥和𝑓分别为源图像𝑋和融合图像𝐹的图像块,𝜇表示平均值,𝜎表示标准差,参数𝐶1、𝐶2和𝐶3用于使度量稳定。LSSIM由下式给出:
然而,只有SSIM损失会导致纹理细节损失(当𝜔= 0时)或中和现象(当𝜔〉0时)。因此,本文采用最大梯度损失法来解决上述问题,使得融合后的图像能够获得两幅源图像中对应区域更丰富的纹理细节。Lgra定义如下: 其中𝐻和𝑊分别表示融合图像的高度和宽度。为▽𝐼𝑓融合图像的梯度图(fused gradient map),𝑔max(max-gradient map)为源图像梯度图中对应区域绝对值最大的梯度,具体定义如下:
其中𝐻和𝑊分别表示融合图像的高度和宽度。为▽𝐼𝑓融合图像的梯度图(fused gradient map),𝑔max(max-gradient map)为源图像梯度图中对应区域绝对值最大的梯度,具体定义如下:
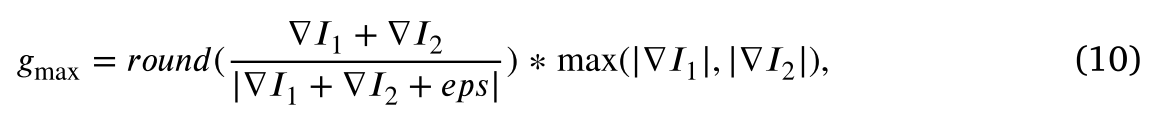
其中𝑟𝑜𝑢𝑛𝑑(·)是舍入运算,max(·)用于取两个矩阵中相应位置的最大值,▽𝐼1和▽𝐼2代表源图像𝐼1和𝐼2的梯度图。
根据Eq.(4)中的融合损失L𝐹,我们还添加了EWC损失L𝐸作为正则化项,以避免灾难性遗忘,由下式给出:

𝐹𝑖 指定为对角项,表示Fisher信息矩阵(或Hessian)的第𝑖个对角元素。此外,𝐹𝑖可以通过使用前一任务的数据计算梯度的平方来容易地近似,其公式如下:
######Loss function of the discriminator: LD
UIFGAN中的鉴别器的作用是同时将融合图像与两幅源图像区分开来。通过鉴别器的损失来计算分布之间的詹森-香农散度(Jensen–Shannon divergence),以识别输入是否是不真实的,并且因此促使融合图像是真实的并且信息量足以匹配真实分布,即,𝐼real。鉴别器的损失函数如下LD: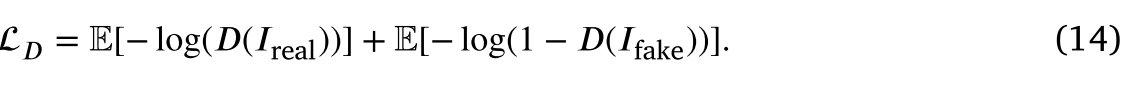
Network architectures
Generator architecture
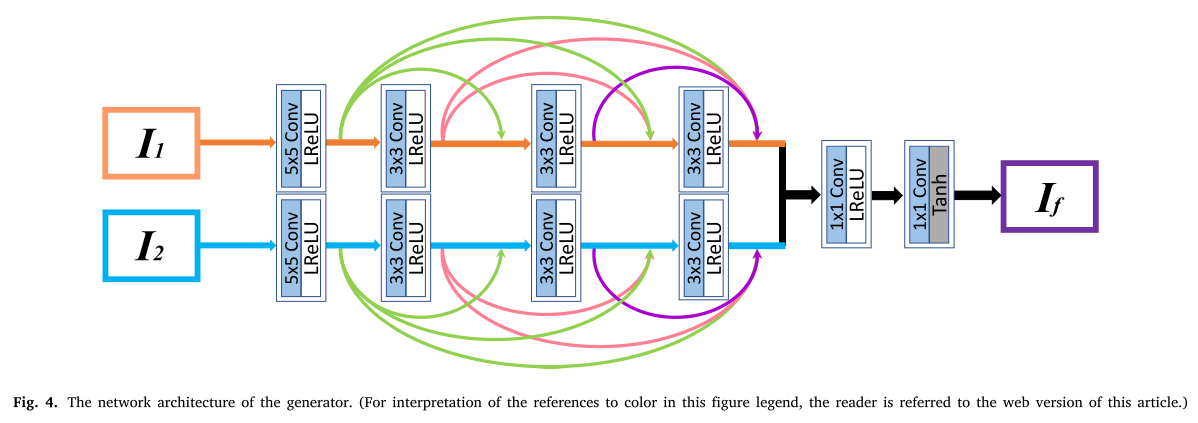
发生器的网络结构如图4所示。在生成器中引入了伪连体网络的思想。对于两幅不同的源图像,我们采用不同的参数提取出两个分支的不同特征,适合处理差异较大的源图像。此外,如绿色、红色和紫色箭头所示,我们在每个分支中的每一层与其他层之间以前馈的方式建立一个短的直接连接,这类似于DenseNet。在这两个分支中使用了leaky ReLU。最后,将两个分支中所有卷积层的输出级联到最后两个卷积层,重构融合图像。特别地,所有卷积层的步长都被设置为1,最后两个卷积层的核大小为1 × 1以进行维数约简。值得注意的是,填充模式在所有卷积层中均设置为“相同",即特征图的大小在发生器中不会改变,与源图像的大小相同。
Discriminator architecture
我们的UIFGAN中使用了PatchGAN。鉴别器将输入映射到𝑁×𝑁的patches。𝑋𝑖𝑗的值表示每个色块为真实样本的概率。𝑋𝑖𝑗的平均值是鉴频器的最终输出。
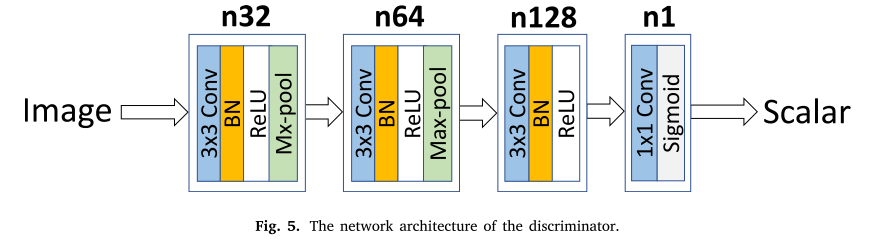
具体地说,𝑁设为8。如图5所示,在鉴别器中有四个卷积层。该算法将所有卷积层的步长设置为2,在最后一层采用sigmoid激活函数生成标量,该标量估计来自源图像而不是生成器的输入概率。






![[ MySQL ] 使用 MySQL Workbentch 进行MySQL数据库备份 / 还原(Part 3:备份.sql文件方式)](https://img-blog.csdnimg.cn/a6c9c2a48c47486f9a9d82320a3cbc04.png)
![基础算法系列之基础(二)[大数问题]](https://img-blog.csdnimg.cn/d36f91d237aa4f9891da47bb5836a58d.png)